
Недавно в комментариях к одному из постов в Варим ML меня спросили, какие навыки и знания нужны, чтобы у нас работать. Вопрос на самом деле очень важный - без правильного ответа невозможно нормально выстроить процессы найма и развития сотрудников. Можно быстро набросать дефолтный список - питончик, ML/DL, докер, и на этом закончить, но я решил зарыться в вопрос пообстоятельнее. Конечно, существуют самые разные родмапы, но лично мне они кажутся излишне общими, а я захотел поразмышлять именно про те скиллы, которые необходимы для работы в Цельсе, а главное про их необходимый уровень.

Свойства навыков
Начну с того, что у навыков и знаний есть некоторые важные свойства, которые важно понимать и учитывать. От комбинации этих свойств зависит:
насколько глубоко скилл нужно проверять на собеседовании
как выстраивать процесс образования и хранения знаний по этому навыку
как подбирать оптимальный командный билд, чтоб закрыть потребности в разных областях знаниях
как выстраивать собственный процесс развития
Вот эти свойства:
Частота использования в каждодневной работе. Что-то пишем на Питоне мы все каждый день, а вот имплементируем какую-то статью, к которой “забыли” выложить код, гораздо реже. Это необязательно коррелирует с важностью навыка, но влияет, например, на скорость и сложность его освоения.
Learning curve и возможность обучения на практике. Вряд ли мы возьмём на работу человека вообще без ML-базы и навыков программирования. При этом научиться пользоваться конкретной библиотекой можно за несколько дней.
Минимальный адекватный и рекомендуемый уровни. Когда мы пишем в вакансии “Docker”, это не предполагает какого-то глубокого понимания различий нетворк-драйверов, в 95% случаев достаточно уметь писать multi-stage докер-файлы и знать основные команды.
Взаимодействие с другими навыками. Будет большим преувеличением сказать, что мы каждый день зарываемся в конспекты по линейной алгебре. Но без математического фундамента сложно построить систему знаний, которая позволит быстро читать статьи и ухватывать их суть. Так что не стоит сразу выбрасывать из своего роадмапа навыки, которые редко используются на практике напрямую.
Уникальность. Какие-то вещи хотя бы на минимальном уровне нужно знать всем, тогда как другие будут выделять вас из толпы и обеспечивать уникальную роль в компании. Если вы будете экспертом по какой-то конкретной области или инструменту - это точно будет притягивать к вам людей и поднимет ваши шансы на карьерное продвижение.
“Активность”. Скилл может находиться в активной оперативной памяти, а может требовать определённого времени на восстановление. Хорошая аналогия - горячее и холодное хранилище в S3. К некоторым знаниям важен быстрый доступ, а другие можно и загуглить или подсмотреть в личной или общей базе знаний.
Роли и уровни
Конечно, же набор необходимых скиллов зависит от уровня и роли сотрудника в отделе.
Вообще говоря, я хейтер грейдовой системы, мне кажется, зачастую в этом больше карго-культа, чем полезности, хотя в крупных компаниях совсем без грейдов, наверное, не обойтись. У нас в отделе грейдовая система сейчас осталась только в виде бюрократического рудимента. Безусловно, это не отменяет того факта, что разные сотрудники обладают разным уровнем знаний и опыта, и это отражается и на ожиданиях от их навыков. Например, неопытный специалист-студент на первых порах будет в рамках рабочих задач больше заниматься аналитикой данных, а нюансы продакшна и сложных нейронных архитектур в основном постигать через другие активности (ликбезы, презентации, ИПР). Соответственно, будет здорово, если у человека в активном запасе будут нужные навыки - pandas, plotly, SQL, ну и математическая и ML-база для более быстрого усвоения знаний.
Набор необходимых инструментов меняется и для разных специализаций. У нас в отделе только три формально закреплённых позиции - тимлид, ML-инженер и дата-инженер. Фактически же внутри команды люди часто специализируются в определённой области. Кто-то берёт на себя большинство инфраструктурных задач, кто-то владеет всей инфой о данных, а кто-то генерит большую часть ML-гипотез.
Навыки
Теперь давайте пройдёмся по конкретным скиллам, обсудим их значение в нашей компании, а заодно я расскажу о том, как постигал те или иные навыки, и рекомендую ли я такой способ.
Python
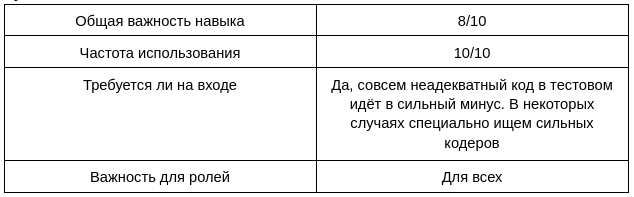
Каждый человек в нашем отделе должен писать более-менее вменяемый код на питоне. При этом уровень владения языком, архитектурные навыки, владение асихнронным программированием и в целом элегантность и чистота кода внутри отдела отличаются достаточно сильно. С момента основания компании я всегда ценил ML-знания и интуицию больше, чем качество кода, и это, безусловно, сыграло нам и в плюс, и в минус. Очень хорошо, что в отделе в какой-то момент появились код-задроты, которые жёстко дрючили всех на код-ревью и в целом пропагандировали написание более чистого и архитектурно адекватного кода. Сейчас мы стараемся, чтобы в каждой команде был хотя бы один сильный прогер и clean code advocate, который мотивирует и тянет за собой менее искушённых членов команды.
Я питончик изучал самостоятельно через личные, учебные и рабочие проекты, а также читал книжки типа The Hitchhiker’s Guide to Python, Effective Python и Fluent Python. В целом такой способ даёт достаточно широкий кругозор и набор знаний, необходимый для решения большинства задач, но меня нельзя назвать хорошим программистом, отсутствие фундаментального образования в моём коде чувствуется. Если вы хотите специализироваться на инженерных задачах, я бы рекомендовал уделить этой стороне больше внимания.
Контейнеризация

В эту группу входят все навыки, связанные с Docker, Docker Compose, Kubernetes, Helm. Чаще всего достаточно базового уровня - написание докерфайлов и ямликов, основы кубика, умение ориентироваться в куб-дашборде и подправлять хелм-чарты по необходимости. Что-то более глубокое обычно требуется в 1 случае из 100, да и там, скорее, подскажет девопс.
Учился аналогично питону - писал своё, смотрел на хорошие Докерфайлы, методом проб и ошибок разворачивал кубик-кластер с ElasticSearch для своей лабы, читал документацию, посмотрел пару курсов. Для каждодневной работы хватает.
Другие software-навыки

Очень обширный раздел, в который я включил практически весь арсенал различных технологий, которые мы так или иначе используем в нашей работе - базы данных (PostgreSQL, MongoDB), брокеры сообщений (RabbitMQ, Redis), API-фреймворки (Flask, FastAPI), облачные ресурсы, работа с данными (Airflow, DVC), Elasticsearch. Базовый уровень владения основными технологиями очень помогает в работе, но более глубокое погружение обычно закрепляется за людьми с уклоном в инженерию.
DS-библиотеки

Некоторые библиотеки играют важную поддерживающую роль практически в любом нашем проекте - pandas, numpy, matplotlib/plotly, scikit-learn, optuna. Какое-то мастерское владение обычно не требуется, но опыт реализации типовых задач позволяет решать некоторые проблемы значительно быстрее. При этом если ваша работа в основном связана с анализом данных, то значимость этих скиллов вырастает на порядок. Быстро сделать качественный EDA, найти странные данные, построить красивые графики, сформировать отчёт для коллег - здесь точно нужны внимательность и усидчивость, но владение основными инструментами сделает работу значительно приятнее и уменьшит вероятность ошибок.
Помимо практического опыта и документацию, могу порекомендовать классическую библию по Pandas с перохвостой тупайей на обложке. А по всем алгоритмам из scikit-learn нам когда-то читал крутую серию лекций мой коллега по каналу Миша Киндулов. Может быть, когда-нибудь он сделает серию постов, если вы его попросите =)
Специфические инструменты

К этой группе относятся специфические инструменты, использующиеся в компании - например, трекер и оркестратор экспериментов (ClearML), хранилище знаний (Notion), CI/CD-платформа (Azure Devops). Опыт работы с похожими инструментами приветствуется, но абсолютно не обязателен. При этом крайне полезно иметь в отделе хотя бы одного человека, который глубже разбирается в инструменте. Например, я у нас отвечаю за ClearML.
В этой секции хочу упомянуть ещё один бесценный источник знаний о конкретных инструментов, особенно это актуально для продуктов, которые находятся в активной разработке - Слак-пространство с разработчиками. Я состою и активно задаю в вопросы в коммьюнити по ClearML и BentoML.
Общая IT-грамотность

Владение командной строкой, накатывание куды, настройка окружений, git, владение трюками любимой IDE и многие другие навыки сделают вашу жизнь ощутимо легче. При этом - в большинстве случаев владения на начально-среднем уровне вполне достаточно, а для типовых сценариев у нас написаны инструкции. Ребята после универа без продакшн-опыта достаточно быстро набивают все эти шишки при содействии коллег и туториалов.
Если вы столкнулись с какой-то проблемой и смогли её побороть - настоятельно рекомендую полностью описать её, скопировать решение в какую-то базу знаний (личную, команды, компании). Воспитание в команде этой привычки спасает тимлида от большого количества головной боли.
Математическая подготовка

Как-то раз я сходил на собеседование ради поддержания навыка и любопытства, и меня там в конце стали спрашивать вопросы типа “формула нормального распределения”, “что такое ранг матрицы и векторный базис”, “какой критерий обратимости матрицы”. Честно говоря, на все эти вопросы я гораздо быстрее и чётче ответил бы лет 10 назад, но что-то мне подсказывает, что хуже как ML-специалист я не стал. На мой взгляд, математические знания - это классический пример важного пассивного навыка. Можно не помнить 95% материала, но если при чтении статьи, вы сталкиваетесь с каким-то знакомым концептом или термином, одного быстрого гуглежа должно хватить для активации нужной области памяти. Мы на собесах никогда не задаём вопросы на определения или теоремы, зато всегда копаем вглубь разных алгоритмов и сеток. Отсутствие фундаментального понимания принципов их работы сильно показательнее отсутствия в активной памяти формул распределения. По крайней мере для нашей работы.
Математическую подготовку я получал на классических курсах теорвера, линейки, матана и матстатистики в школе и универе, чему несказанно рад и доволен.
Общие ML-знания

Звучит очень широко, с точки зрения практики я бы выделил следующие темы - ML-метрики и лоссы, организация корректного валидационного пайплайна под задачу, градиентный спуск, регуляризация, основные виды моделей (можно пробежаться по документации scikit-learn для примерного списка) и принципы их работы, особенности разных видов задач (включая мультикласс, мультилейбл и ординальную регрессию), способы feature selection.
Если ещё и подкрепить некоторые их этих тем практическим опытом - будет шикарно. Я бы не недооценивал важность классических универских курсов - некоторыми я делился в своём посте про образование.
Общие DL-знания
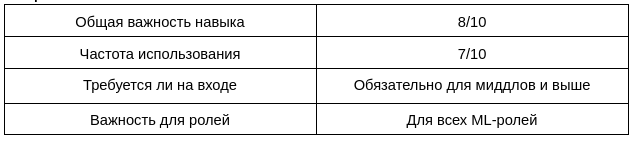
Если вы можете взять несколько базовых архитектур нейронных сетей для разных задач и на пальцах рассказать, какие в них есть компоненты и слои - уже очень хорошо. Вот пример подобного разбора для Faster-RCNN, что-то подобное мы иногда просим сделать и на собесах. Набор тем и сеток будет отличаться для разных областей и прикладных задач. Джентльменский набор для CV - конволюции и их вариации, разные нормализации, RNN, attention и трансформеры, основные архитектуры в задачах детекции и сегментации.
DL-кругозор

Подозреваю, что эта секция может стать одной из самых противоречивых, но я считаю наличие DL-кругозора, багажа прочитанных и реализованных статей, опыта в разных областях ML одним из важнейших навыков для крепкого DL-специалиста. Самые крутые наши специалисты практически для любой задачи за 15 минут набросают целый ряд рабочих идей - от бейзлайна до космолёта.
Прокачивается (на словах) просто - чтением и конспектированием статей, внедрением в рабочие проекты.
Имплементация гипотез

Навык имплементации гипотез вбирает в себя несколько других:
если гипотеза оригинальная или кода нет - умение переводить идею в дизайн, а затем в код
если гипотеза украденная - умение читать и понимать статьи, а также читать чужой код и issues на гитхабе
хорошее владение DL-фреймворком типа PyTorch
ML system design

Термин, который набрал очень серьёзную популярность в последние годы. Я его понимаю как умение перевести бизнес-задачу в такую архитектуру ML-системы, которая максимизирует риск успеха проекта. На собесах это наш любимый вопрос - даём бизнес-описание задачи, доступные данные и другие важные ограничения. А кандидат должен раскрутить, как эту задачку можно было бы решить - от бейзлайна до продакшна.
Прокачивается в основном с опытом и с расширением кругозора, из материалов могу отметить курс Стэнфорда, курс Димы Колодезева на ODS, а также книги типа ML Design Patterns.
Здравый смысл, адекватность, критическое мышление и интуиция

Долго думал, включать ли эти “навыки” как отдельную секцию, хотя на самом деле это чуть ли не самые важные вещи в работе любого ML-специалиста. Умение опираться на свой и чужой опыт, делать правильные выводы, отбрасывать “шумные сигналы”, вовремя останавливаться и не останавливаться невовремя - всё это очень сильно влияет на итоговые успехи проектов и людей. Наверное, частично какие-то из этих способностей заложены в нас с рождения и детства, но ведение записей, анализ причин успехов и провалов проектов и идей, общение с умными людьми, чтение книг точно не вредят. О важности адекватности и здравого смысла в DS речь идёт и в этом видео Антона Мальцева.
Софт-скиллы

По-настоящему гигантская категория, в которую при желании можно запихать вообще всё - от навыков общения с другими людьми то опыта управления командами и проектами. Мы начинаем анализировать, подходит ли нам человек по этим самым таниственным софт-скиллам уже в момент первого контакта. Отдельно смотрим на то, как человек отвечает на вопросы, как рассуждает, как оформляет тестовое. Бывали случаи, что мы брали людей, которые не прошли бы чисто по своим ML-скиллам, но они покорили нас своими рассуждениями и гибкостью ума. Я большой поклонник игр в стиле "футбольный менеджер" - там тоже часто имеет смысл взять более перспективного, талантливого и командного игрока. Всё, конечно же, зависит от ваших целей.
В рамках данного поста не хочу подробно разбирать, что я считаю наиболее важным, но хочу отдельно отметить важность навыка письменного и устного выражения мыслей. Тренируйтесь! Пишите разные тексты, пишите техдизайн для задач, выступайте на внутренних митапах - эффективность вашего труда будет расти. В наших перф-ревью часто мелькает именно пожелание тренировать навык донесения своих мыслей. Ещё полезные софт-навыки можно подглядеть в роадмапе тимлидов.
Под конец
Не могу не оставить дисклеймер - всё написанное отражает мою личную когнитивно искажённую позицию, а также задачи и потребности нашей компании. В первую очередь нужно понять, что вообще вам интересно, что драйвит и заводит. Затем определить свою минимальную базу скиллов, которую нужно поддерживать в адекватном состоянии, и продумать, что выделит вас как уникального спеца. Ну и не забывайте, что никто не может знать всего - ставьте чёткие цели и не комплексуйте по поводу слабых мест.
Комментарии (6)

eksei4
00.00.0000 00:00+1Отличная статья! Чётко изложены требования/ожидания. Думаю, многим будет полезно для подготовки к собесу не только в вашу компанию)
Как, кстати, у вас обстоят дела с открытыми позициями в области DL (CV)?

crazyfrogspb1 Автор
00.00.0000 00:00Спасибо! На данный момент дела обстоят не очень - вакансий нет =) Мы довольно сильно росли в своё время (сейчас в отделе больше 20 человек), так что сейчас период, когда продажи догоняют этот рост.
eksei4
00.00.0000 00:00+1Спасибо за ответ :) вы крутые! Желаю вам успехов и процветания!! В мос эксперименте и за его пределами!!

AzIdeaL
00.00.0000 00:00+1"...Уникальность... НЕ= карьерное продвижение..."
Но зато, когда "... Если вы столкнулись с какой-то проблемой (?) и смогли её побороть (!) - настоятельно рекомендую полностью описать её (на бланке гос.образца, для регистрации решения в базу знаний (Роспатент). Воспитание в команде этой привычки спасает тимлида от большого количества головной боли))
KValery
Спасибо за статью с адекватным взглядом.
crazyfrogspb1 Автор
спасибо, приятно! а что именно вам показалось адекватным по сравнению с другими мнениями?