
В моём предыдущем посте мы впервые погрузились в мир эксплойтинга браузеров, рассмотрев несколько сложных тем, которые были необходимы для освоения фундаментальных знаний. В основном мы изучили внутреннюю работу JavaScript и V8, разобравшись, что такое объекты map и shape, как эти объекты структурированы в памяти; мы рассмотрели базовые оптимизации памяти наподобие маркировки указателей и сжатия указателей. Также мы затронули тему конвейера компилятора, интерпретатора байт-кода и оптимизации кода.
Если вы ещё не прочитали тот пост, то крайне рекомендую это сделать. В противном случае вы можете запутаться и совершенно не разберётесь в некоторых из тем, представленных в этом посте, поскольку мы продолжаем изучение на основе знаний из первой части, расширяя их.
В сегодняшнем посте мы вернёмся к конвейеру компилятора и ещё глубже разберём некоторые из рассмотренных ранее концепций: байт-код V8, компиляцию кода и оптимизацию кода. В целом, мы рассмотрим происходящее внутри Ignition, Sparkplug и TurboFan, поскольку они критически важны для понимания того, как определённые «фичи» могут привести к появлению багов, которые можно эксплойтить.
Мы обсудим следующие темы:
- Модель безопасности Chrome
- Многопроцессная архитектура «песочницы»
- Isolate and Context движка V8
- Интерпретатор Ignition
- Разбираемся с байт-кодом V8
- Разбираемся с регистровой машиной
- Sparkplug
- 1:1 Mapping
- TurboFan
- Компиляция Just-In-Time (JIT)
- Спекулятивная оптимизация и предохранители типов
- Feedback Lattice
- Промежуточное представление «море узлов»
- Стандартные оптимизации
- Typer
- Анализ диапазонов
- Bounds Checking Elimination (BCE)
- Устранение избыточности
- Другие оптимизации
- Оптимизация контроля
- Анализ псевдонимов и глобальное перечисление значений
- Dead Code Elimination (DCE)
- Распространённые уязвимости компилятора JIT
Итак, прочитав этот длинный и страшный список сложных тем, давайте глубоко вдохнём и приступим!
Примечание: многие подсвеченные пути кода являются ссылками. При нажатии на эти ссылки вы попадёте в соответствующую часть исходного кода Chromium, чтобы изучить его внимательнее.
Кроме того, уделите время чтению комментариев к коду. Исходный код Chromium, несмотря на свою сложность, содержит довольно неплохие комментарии, которые помогут вам в понимании того, что это за часть кода и что она делает.
Модель безопасности Chrome
Прежде чем мы погрузимся в разбор сложностей конвейера компилятора, процесса выполнения оптимизаций и мест возможного возникновения багов, сначала нам нужно сделать шаг назад и рассмотреть картину в целом. Хотя конвейер компилятора играет важную роль в выполнении JavaScript, это лишь одна часть головоломки всей архитектуры браузеров.
Как мы видели, V8 может работать как автономное приложение, но в целом в браузере V8 на самом деле встроен в Chrome и используется другим движком при помощи привязок. Из-за этого нам нужно разобраться в нюансах обработки кода на JavaScript в приложении, так как эта информация критически важна для понимания проблем безопасности внутри браузера.
Чтобы мы могли увидеть эту «картину в целом» и собрать воедино все кусочки пазла, нам нужно начать с понимания модели безопасности Chrome. Ведь в конечном итоге эта серия постов посвящена внутренностям браузера и его эксплойтингу. Поэтому чтобы лучше понять, почему одни баги тривиальнее других, и почему эксплойт всего лишь одного бага может не привести к прямому удалённому исполнению кода, нам нужно понять архитектуру Chromium.
Как мы знаем, движки JavaScript — неотъемлемая часть исполнения JavaScript-кода в системах. Хотя они играют очень важную роль в обеспечении скорости и эффективности браузеров, также они могут открывать возможности для вылетов браузера, зависания приложений и даже угроз безопасности. Однако движки JavaScript — это не единственная часть браузера, которая может иметь проблемы или уязвимости. Множество других компонентов, например, API, движки рендеринга HTML и CSS, тоже могут иметь проблемы со стабильностью и уязвимости, которые потенциально можно подвергнуть эксплойтингу, случайно или намеренно.
Практически невозможно создать движок JavaScript или рендеринга, который никогда не вылетает. Также практически невозможно создавать подобные движки так, чтобы они были полностью безопасны и защищены от багов и уязвимостей, особенно потому, что большинство этих компонентов программируется на языке C++ со статической типизацией, которому приходится работать с динамической природой веб-приложений.
Как же Chrome справляется с этой «невозможной» задачей эффективной работы браузера, параллельно обеспечивая безопасность самого браузера, системы и её пользователей? Двумя способами: при помощи многопроцессной архитектуры и «песочницы».
Многопроцессная архитектура «песочницы»
Многопроцессная архитектура Chromium — это архитектура, использующая множество процессов для защиты браузера от проблем нестабильности и багов, которые могут возникать из-за движка JavaScript, движка рендеринга или других компонентов. Chromium также ограничивает доступ между этими процессами, позволяя общаться друг с другом только отдельным процессам. Такой тип архитектуры можно рассматривать как внедрение в приложение защиты памяти и управления доступом.
В целом, браузеры имеют один основной процесс, выполняющий UI и управляющий всеми остальными процессами. Он называется browser process или browser для краткости. Процессы, занимающиеся веб-контентом, называются renderer process или renderer. Эти процессы рендеринга используют Blink — опенсорсный движок рендеринга Chrome. Blink реализует множество других библиотек, помогающих ему работать, например, Skia — опенсорсную библиотеку 2D-графики и, разумеется, V8 для JavaScript.
И тут всё становится немного сложнее. В Chrome каждое новое окно или вкладка открываются в новом процессе, который обычно бывает новым процессом рендеринга. Этот новый процесс рендеринга имеет глобальный объект
RenderProcess, управляющий общением с родительским процессом браузера и хранящий глобальное состояние веб-страницы или приложения в этом окне или вкладке. В свою очередь, основной процесс браузера хранит соответствующий объект RenderProcessHost для каждого рендерера, управляющий состоянием браузера и общением с рендерером.Чтобы выполнять общение между этими процессами, Chromium использует или легаси-систему IPC, или Mojo. Я не буду вдаваться в подробности их работы, потому что, откровенно говоря, архитектура и схема обмена данными в Chrome сами по себе могут стать темой для отдельного поста. Читатель может пройти по ссылкам и провести собственное исследование.
Чтобы нагляднее представить то, о чём мы только что говорили, команда разработчиков Chromium создала показанную ниже схему с высокоуровневым описанием многопроцессной архитектуры.

Кроме того, что каждый из этих рендереров находится в собственном процессе, Chrome также пользуется возможностью ограничения доступа процессов к системным ресурсам при помощи «песочниц». Создавая «песочницу» для каждого из процессов, Chrome может гарантировать, что доступ рендереров к сетевым ресурсам будет осуществляться только через диспетчер сетевых сервисов, выполняемый в основном процессе. Кроме того, он может ограничивать доступ процессов к файловой системе, а также к дисплею, кукам и вводу пользователя.
В целом, это ограничивает возможности атакующего при получении возможности удалённого исполнения кода в процессе рендерера. По сути, без эксплойтинга или добавления в цепочку другого бага, или выхода из «песочницы» он не сможет вносить сохраняющиесяся в компьютере изменения или получить доступ к информации из других окон и вкладок, например, к вводу пользователя и кукам.
Здесь я не буду вдаваться в подробности, поскольку это отвлечёт нас от темы поста. Однако я крайне рекомендую подробно прочитать документацию Chromium Windows Sandbox Architecture, чтобы не только понимать принципы архитектуры, но и лучше разобраться в схеме обмена данными брокера и целевого процесса.
Как же всё это выглядит на практике? Мы можем увидеть практический пример, зайдя в Chrome, открыв две вкладки и запустив Process Monitor. Изначально мы увидим, что Chrome имеет один родительский процесс (browser) и несколько дочерних, как показано на скриншоте.
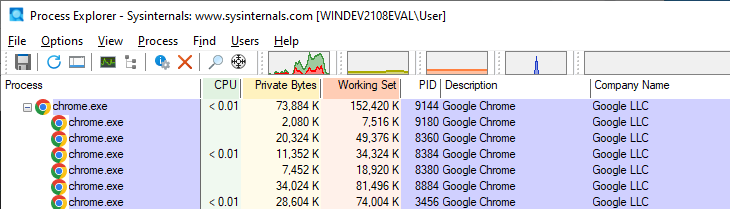
Если теперь мы посмотрим на основной родительский процесс и сравним его с дочерним, то заметим, что другие процессы выполняются с другими параметрами командной строки. В нашем примере мы видим, что дочерний процесс (справа) имеет тип renderer и соответствует родительскому процессу browser (слева). Здорово, правда?

После этого объяснения вы можете задать вопрос: как всё это связано с V8 и JavaScript? Ну, если вы были внимательны, то могли заметить в описании движка рендерера Blink ключевой момент: он реализует V8.
Если вы, как хороший студент, уделили время чтению документации Blink, то немного о нём узнали. В документации говорится, что Blink выполняется в каждом процессе рендерера и имеет один основной поток, обрабатывающий JavaScript, DOM, CSS, вычисления стиля и расположения элементов. Кроме того, Blink может создавать множество потоков «воркеров» для выполнения дополнительных скриптов, расширений и так далее.
В общем случае каждый поток Blink выполняет собственный экземпляр V8. Почему? Ну, как вы знаете, в отдельном окне или вкладке может выполняться очень много кода JavaScript — не только для страницы, но и для различных iframe с рекламой, кнопками и так далее. В итоге, каждый из этих скриптов и iframe имеет отдельный контекст JavaScript, поэтому должен быть способ предотвратить манипуляции одного скрипта с объектами в другом.
Чтобы «изолировать» контекст одного скрипта от другого, V8 реализует концепцию под названием Isolate and Context, о которой мы сейчас и поговорим.
Isolate and Context движка V8
В V8 Isolate — это концепция экземпляра или «виртуальной машины», представляющей одну среду исполнения JavaScript. Она включает в себя диспетчер кучи, сборщик мусора и так далее. В Blink isolate и потоки имеют соотношение 1:1, где один isolate связан с основным потоком, а другой isolate связан с одним потоком воркера.
Context соответствует глобальному корневому объекту, который хранит состояние виртуальной машины и используется для компиляции и исполнения скриптов в одном экземпляре V8. Грубо говоря, один объект окна соответствует одному контексту. А поскольку каждый фрейм имеет объект окна, в процессе рендерера потенциально может быть множество контекстов. Isolate и контексты на протяжении срока жизни isolate имеют соотношение 1:N, конкретный isolate или экземпляр интерпретирует и компилирует множество контекстов.
Это значит, что каждый раз, когда нужно исполнить JavaScript, мы должны убедиться, что находимся в соответствующем контексте при помощи GetCurrentContext(), иначе произойдёт или утечка объектов JavaScript, или их перезапись, что потенциально может вызвать проблему безопасности.
В Chrome объект среды выполнения
v8::Isolate реализован в v8/include/v8-isolate.h, а объект v8::Context реализован в v8/include/v8-context.h. Воспользовавшись нашими знаниями, мы можем на высоком уровне визуализировать среду выполнения и наследование контекста в Chrome: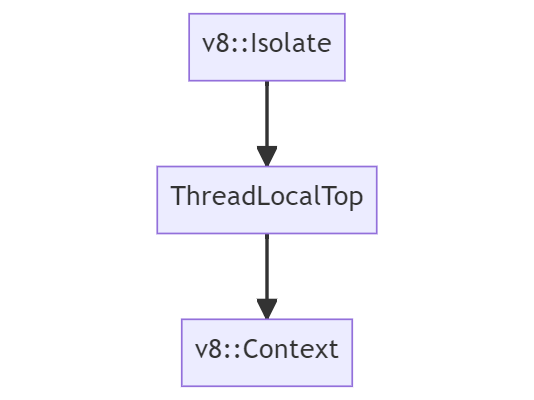
Если бы хотите узнать подробнее о работе Isolate and Context, то рекомендую прочитать Design of V8 Bindings и Getting Started with Embedding V8.
Интерпретатор Ignition
Теперь, получив общее понимание архитектуры Chromium, и осознавая, что весь код JavaScript не исполняется в одном экземпляре движка V8, мы наконец можем вернуться в конвейер компилятора и продолжить погружение в тему.
Мы начнём с разбора интерпретатора V8 под названием Ignition.
В качестве повтора первой части статьи давайте взглянем на высокоуровневую схему конвейера компиляции V8, чтобы знать, где именно мы находимся внутри этого конвейера.

В части первой мы уже рассказывали о токенах и абстрактных синтаксических деревьях (AST), а также вкратце рассмотрели то, как парсится AST с последующей трансляцией в байт-код внутри интерпретатора. Сейчас я хочу рассказать о байт-коде V8, так как генерируемый интерпретатором байт-код — критически важный строительный кирпичик, составляющий любую функциональность JavaScript. Кроме того, когда Ignition компилирует байт-код, он также собирает данные профилирования и обратной связи при каждом выполнении функции JavaScript. Эти данные обратной связи в дальнейшем используются TurboFan для генерации оптимизированного для JIT машинного кода.
Но прежде чем мы начнём разбираться, как структурирован байт-код, нам нужно понять, как Ignition реализует свою «регистровую машину». Каждый байт-код представляет свои вводы и выводы в виде операндов регистра, поэтому нам нужно знать, где эти вводы и выводы располагаются в стеке. Это поможет нам лучше визуализировать и понять фреймы стека, которые создаются в V8.
Разбираемся с регистровой машиной
Как мы знаем, интерпретатор Ignition — это интерпретатор на основе регистров с регистром-аккумулятором. Эти «регистры» на самом деле не являются традиционными регистрами машины, как можно подумать. Это отдельные слоты в регистровом файле, распределяемом как часть фрейма стека функции. По сути, они являются «виртуальными» регистрами. Как мы увидим ниже, байт-коды могут указывать эти регистры ввода и вывода, с которыми могут оперировать их аргументы.
Ignition состоит из набора обработчиков байт-кода, написанных высокоуровневым машинно-независимым ассемблерным кодом. Эти обработчики реализованы классом
CodeStubAssembler и скомпилированы бэкендом TurboFan при компиляции браузера. В целом, каждый из этих обработчиков занимается конкретным байт-кодом, а затем передаёт управление обработчику следующего байт-кода.Пример обработчика байт-кода
LdaZero, или «Load Zero to Accumulator» («записать ноль в аккумулятор») из v8/src/interpreter/interpreter-generator.cc представлен ниже.// LdaZero
// Запись литерального "0" в аккумулятор.
IGNITION_HANDLER(LdaZero, InterpreterAssembler)
{
TNode<Number> zero_value = NumberConstant(0.0);
SetAccumulator(zero_value);
Dispatch();
}Когда V8 создаёт новый isolate, он загружает обработчики из файла снэпшота, созданного во время сборки. Isolate также содержит глобальную таблицу вызовов интерпретатора, содержащую указатель объекта кода на каждый обработчик байт-кода, индексированный по значению байт-кода. В общем случае эта таблица вызовов является простым enum.
Чтобы байт-код был выполнен Ignition, функция JavaScript сначала преобразуется в байт-код из AST
BytecodeGenerator. Этот генератор обходит AST и создаёт соответствующий байт-код для каждого узла AST, вызывая функцию GenerateBytecode.Этот байт-код затем ассоциируется с функций (которая является объектом JSFunction) в поле свойства, называемом объектом
SharedFunctionInfo. Затем code_entry_point функций JavaScript присваивается встроенная заглушка InterpreterEntryTrampoline.Вход в заглушку
InterpreterEntryTrampoline выполняется при вызове функции JavaScript, она отвечает за подготовку соответствующего фрейма стека интерпретатора, а также вызывает обработчик байт-кода интерпретатора для первого байт-кода функции. Затем при помощи интерпретатора Ignition он начинает исполнение или «интерпретацию» функции, происходящую в файле исходников v8/src/builtins/x64/builtins-x64.cc.В частности, в строках 1255-1387 файла
builtins-x64.cc функции Builtins::Generate_InterpreterPushArgsThenCallImpl и Builtins::Generate_InterpreterPushArgsThenConstructImpl отвечают за дальнейшее построение фрейма стека интерпретатора, передавая аргументы и состояние функции в стек.Я не буду особо вдаваться в генератор байт-кода, однако если вы хотите расширить свои знания, то рекомендую прочитать раздел Ignition Design Documentation: Bytecode Generation, дающий лучшее представление о том, как это работает изнутри. В этом разделе я хочу подробнее рассказать о распределении регистров и создании фрейма стека для функции.
Как же генерируется этот фрейм стека?
При генерации байт-кода
BytecodeGenerator также распределяет регистры в регистровом файле функции для локальных переменных, указателей объектов контекста и временных значений, необходимых для вычисления выражений.Заглушка
InterpreterEntryTrampoline обрабатывает изначальное создание фрейма стека, а затем распределяет пространство в фрейме стека для регистрового файла. Эта заглушка также записывает undefined во все регистры этого регистрового файла, чтобы сборщик мусора (Garbage Collector, GC) не видел никаких невалидных (то есть немаркированных) указателей при обходе стека.Байт-код работает с этими регистрами, указывая это в своих операндах, после чего Ignition загружает или сохраняет данные из конкретного слота стека, связанного с регистром. Так как индексы регистров напрямую отображаются на слоты фрейма стека функции, Ignition может непосредственно получать доступ к другим слотам в стеке, например, к контексту и аргументам, переданным вместе с функцией.
Пример того, как выглядит фрейм стека для функции, показан ниже (изображение создано командой Chromium). Обратите внимание на «Interpreter Stack Frame». Это стек фрейма, созданный заглушкой
InterpreterEntryTrampoline.
Как видите, все аргументы функции отмечены красным, а локальные переменные и временные переменные для вычисления выражений — зелёным.
Светло-зелёная часть содержит текущий объект контекста Isolates, счётчик указателей вызывающего оператора и указатель на объект
JSFunction. Этот указатель на JSFunction также известен как замыкание, ссылающееся на контекст функций, объект SharedFunctionInfo, а также на другие методы доступа наподобие FeedbackVector. Ниже показан пример того, как этот JSFunction выглядит в памяти.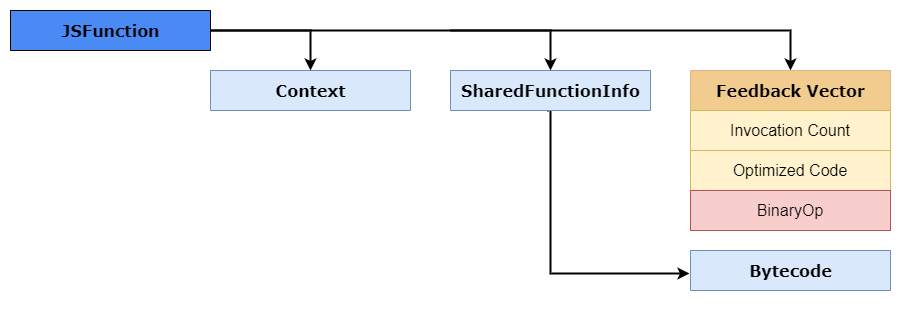
Также можно заметить, что в фрейме стека отсутствует регистр накопителя. Так получилось, потому что регистр аккумулятора при вызовах функций постоянно изменяется, в этом случае он хранится в интерпретаторе как регистр состояния. На этот регистр состояния указывает Frame Pointer (FP), который также хранит указатель стека и счётчик фрейма.

Вернувшись к первому примеру фрейма стека, вы также заметите, что там есть указатель на Bytecode Array. Этот
BytecodeArray представляет собой последовательность байт-кодов интерпретатора для конкретной функции в фрейме стека. Изначально каждый байт-код является enum, где индекс байт-кода хранит соответствующий обработчик (как и говорилось ранее).Пример этого
BytecodeArray показан в v8/src/objects/code.h, а фрагмент этого кода представлен ниже.// BytecodeArray представляет собой последовательность байт-кодов интерпретатора.
class BytecodeArray
: public TorqueGeneratedBytecodeArray<BytecodeArray, FixedArrayBase> {
public:
static constexpr int SizeFor(int length) {
return OBJECT_POINTER_ALIGN(kHeaderSize + length);
}
inline byte get(int index) const;
inline void set(int index, byte value);
inline Address GetFirstBytecodeAddress();
inline int32_t frame_size() const;
inline void set_frame_size(int32_t frame_size);Как видите, функция
GetFirstBytecodeAddress() отвечает за получение первого адреса байт-кода в массиве. Как она находит этот адрес?Давайте вкратце рассмотрим байт-код, сгенерированный для
var num = 42.d8> var num = 42;
[generated bytecode for function: (0x03650025a599 <SharedFunctionInfo>)]
Bytecode length: 18
Parameter count 1
Register count 3
Frame size 24
Bytecode age: 0
000003650025A61E @ 0 : 13 00 LdaConstant [0]
000003650025A620 @ 2 : c4 Star1
000003650025A621 @ 3 : 19 fe f8 Mov <closure>, r2
000003650025A624 @ 6 : 66 5f 01 f9 02 CallRuntime [DeclareGlobals], r1-r2
000003650025A629 @ 11 : 0d 2a LdaSmi [42]
000003650025A62B @ 13 : 23 01 00 StaGlobal [1], [0]
000003650025A62E @ 16 : 0e LdaUndefined
000003650025A62F @ 17 : aa ReturnНе беспокойтесь о том, что значит каждый из этих байт-кодов, мы объясним это чуть позже. Посмотрите на первую строку массива байт-кодов, она сохраняет
LdaConstant. Слева мы видим 13 00. Шестнадцатеричное число 0x13 — это перечислитель байт-кода, обозначающий, где должен находиться обработчик этого байт-кода.После получения
SetBytecodeHandler() будет вызвана с байт-кодом, операндами и enum её обработки. Эта функция находится внутри файла v8/src/interpreter/interpreter.cc; пример этой функции показан ниже.void Interpreter::SetBytecodeHandler(Bytecode bytecode,
OperandScale operand_scale,
CodeT handler) {
DCHECK(handler.is_off_heap_trampoline());
DCHECK(handler.kind() == CodeKind::BYTECODE_HANDLER);
size_t index = GetDispatchTableIndex(bytecode, operand_scale);
dispatch_table_[index] = handler.InstructionStart();
}
size_t Interpreter::GetDispatchTableIndex(Bytecode bytecode,
OperandScale operand_scale) {
static const size_t kEntriesPerOperandScale = 1u << kBitsPerByte;
size_t index = static_cast<size_t>(bytecode);
return index + BytecodeOperands::OperandScaleAsIndex(operand_scale) *
kEntriesPerOperandScale;
}Как видите,
dispatch_table_[index] вычисляет индекс байт-кода из таблицы вызовов, которая хранится в физическом регистре, и в итоге инициирует или финализирует функцию Dispatch() для выполнения байт-кода.Массив байт-кодов также содержит Constant Pool Pointer, хранящий объекты кучи, на которые в сгенерированном байт-коде ссылаются как на константы, например, строки и integer. Пул констант является
FixedArray указателей на объекты кучи. Пример этого указателя на BytecodeArray и его пул констант объектов кучи показан ниже.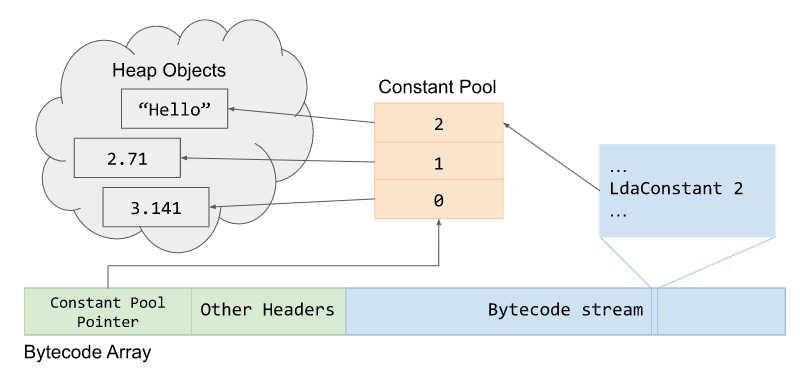
Прежде чем продолжить, я хотел бы также упомянуть, что заглушка
InterpreterEntryTrampoline имеет фиксированные регистры машины, используемые Ignition. Эти регистры расположены внутри файла v8/src/codegen/x64/register-x64.h.Пример этих регистров показан ниже, к интересующим нас добавлены комментарии.
// Определяет методы {RegisterName} для типов регистров.
DEFINE_REGISTER_NAMES(Register, GENERAL_REGISTERS)
DEFINE_REGISTER_NAMES(XMMRegister, DOUBLE_REGISTERS)
DEFINE_REGISTER_NAMES(YMMRegister, YMM_REGISTERS)
// Даёт псевдонимы регистрам для соответствия стандартам вызова.
constexpr Register kReturnRegister0 = rax;
constexpr Register kReturnRegister1 = rdx;
constexpr Register kReturnRegister2 = r8;
constexpr Register kJSFunctionRegister = rdi;
// Указывает на текущий объект контекста
constexpr Register kContextRegister = rsi;
constexpr Register kAllocateSizeRegister = rdx;
// Сохраняет косвенный регистр аккумулятора интерпретатора
constexpr Register kInterpreterAccumulatorRegister = rax;
// Текущее смещение выполнения в BytecodeArray
constexpr Register kInterpreterBytecodeOffsetRegister = r9;
// Указывает на начало интерпретируемого объекта BytecodeArray
constexpr Register kInterpreterBytecodeArrayRegister = r12;
// Указывает на таблицу вызовов интерпретатора, используемую для вызова обработчика следующего байт-кода
constexpr Register kInterpreterDispatchTableRegister = r15;Разобравшись с этим, погрузимся в изучение байт-кода V8 и того, как операнд байт-кода взаимодействует с регистровым файлом.
Разбираемся с байт-кодом V8
Как говорилось в части первой, в V8 есть несколько сотен байт-кодов, и все они определены в файле заголовка
v8/src/interpreter/bytecodes.h. Как мы вскоре увидим, каждый из этих байт-кодов указывает свои операнды ввода и вывода в виде регистров регистрового файла. Кроме того, многие из опкодов начинаются с Lda или Sta, где a обозначает аккумулятор.Например, давайте рассмотрим определение байт-кода
LdaSmi:V(LdaSmi, ImplicitRegisterUse::kWriteAccumulator, OperandType::kImm)Как видите,
LdaSmi записывает (Load) (отсюда Ld) значение в регистр аккумулятора. В данном случае он записывает операнд kImm, являющийся signed byte, который соответствует Smi, или Small Integer в имени байт-кода. В итоге, этот байт-код записывает small integer в регистр аккумулятора.Стоит заметить, что список операндов и их типов определён в файле заголовка
v8/src/interpreter/bytecode-operands.h.Итак, имея эту базовую информацию, давайте рассмотрим байт-код настоящей функции на JavaScript. Для начала запустим
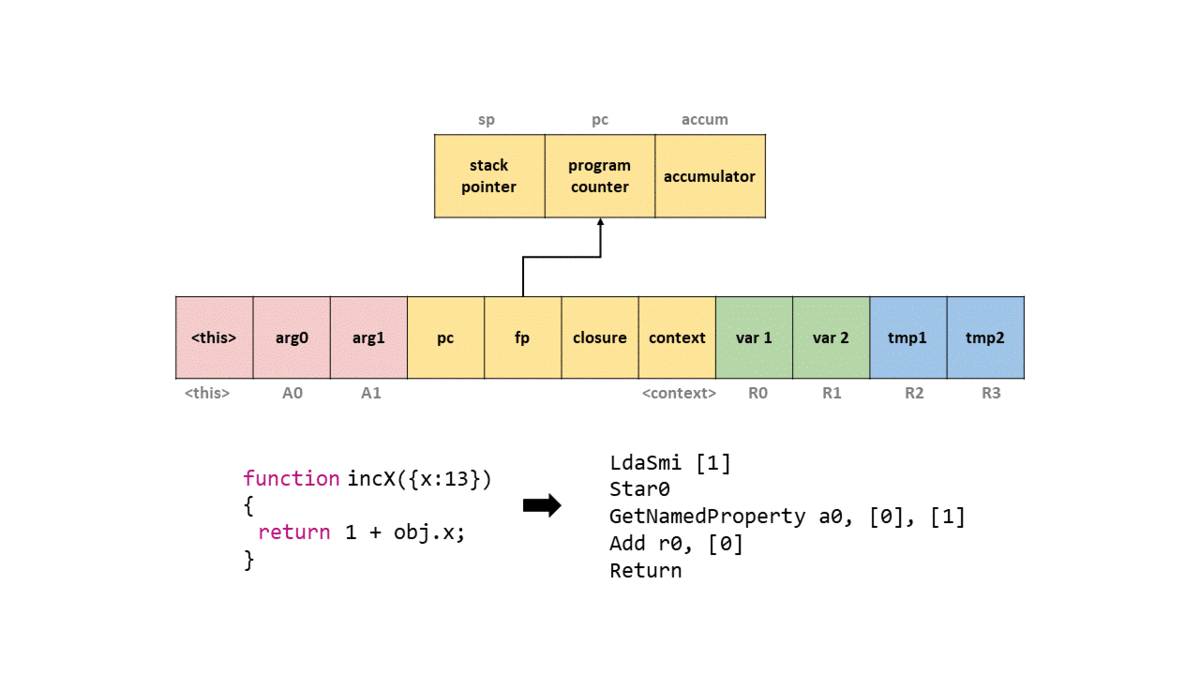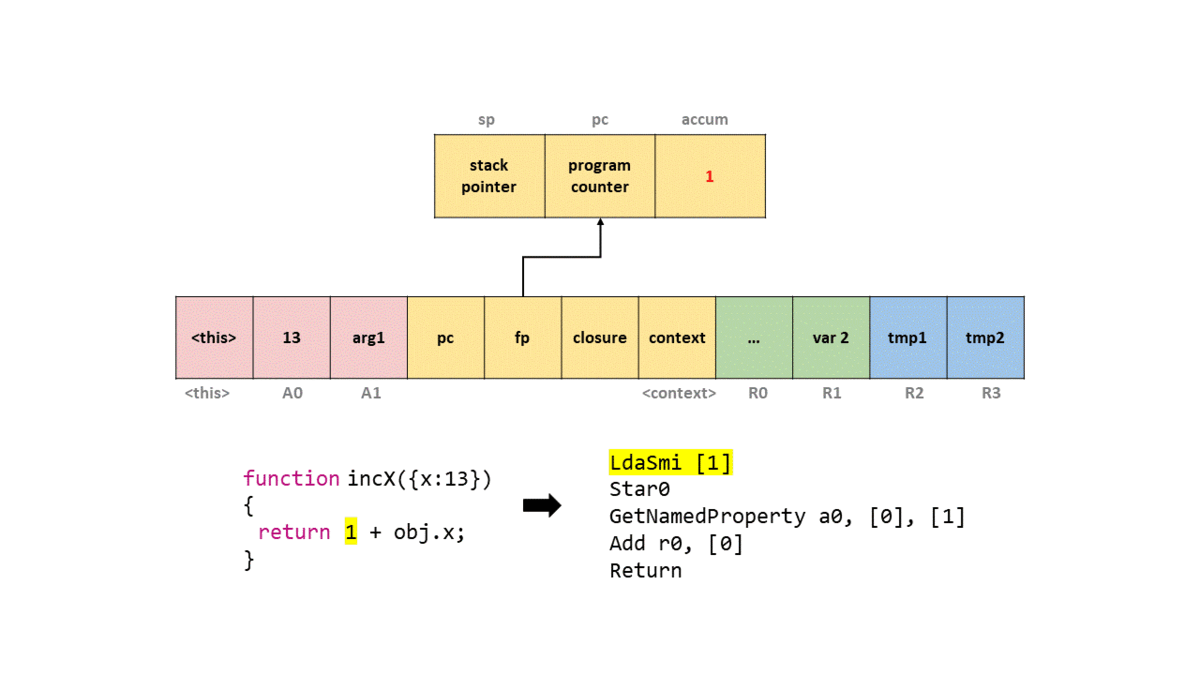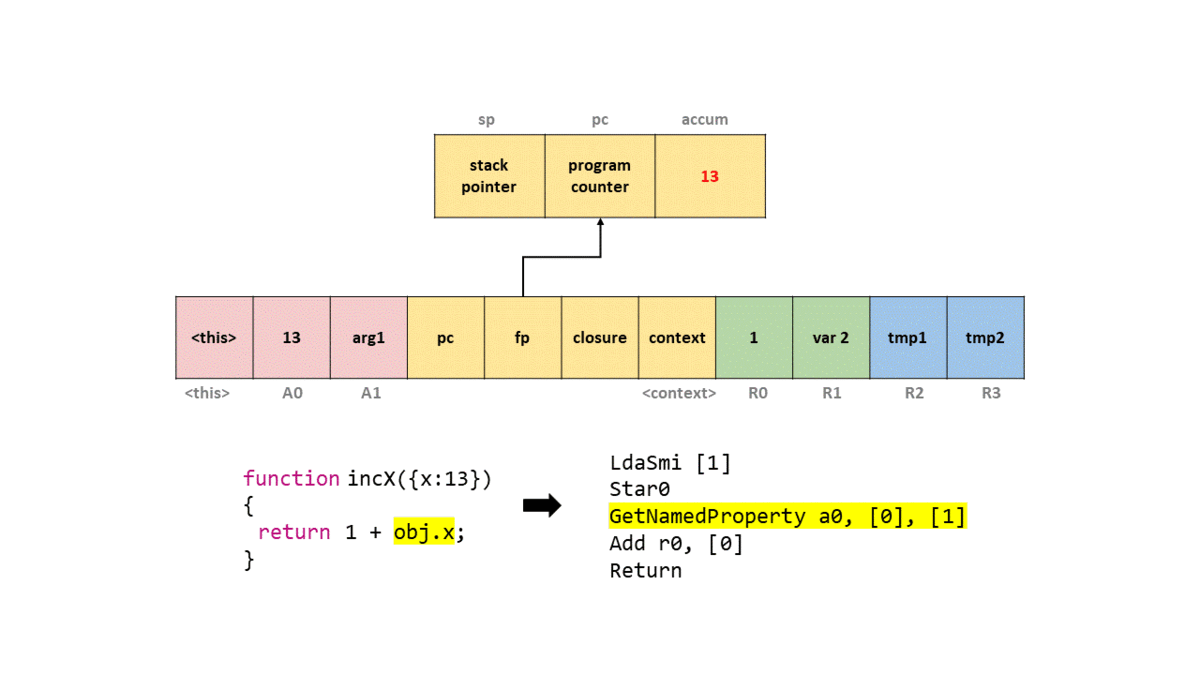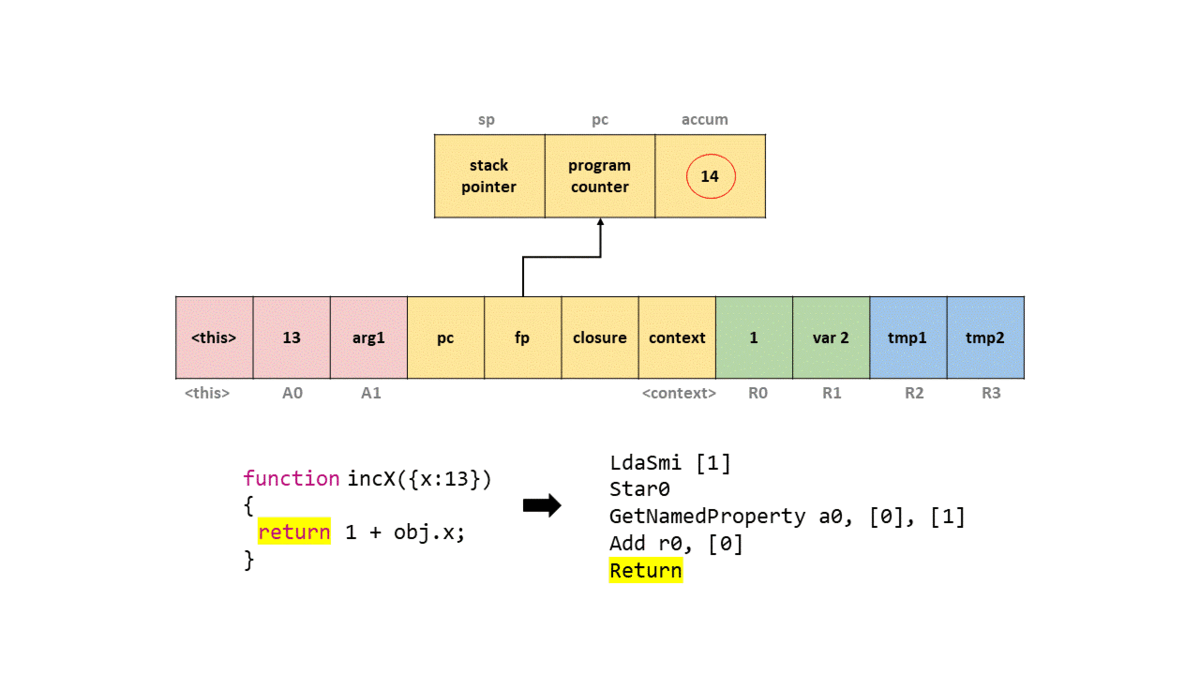
d8 с флагом --print-bytecode, чтобы можно было просматривать байт-код. После этого введём произвольный код на JavaScript и несколько раз нажмём на Enter. Это нужно потому, что V8 является «ленивым» движком, поэтому не будет компилировать то, что ему не нужно. Но поскольку мы используем string и числа в первый раз, он компилирует библиотеки наподобие Stringify, что поначалу приводит к огромному количеству выводимых данных.После этого создадим простую функцию JavaScript
incX, которая будет выполнять инкремент свойства объекта x на единицу, и возвращать его. Функция будет выглядеть так.function incX(obj) { return 1 + obj.x; }Это сгенерирует байт-код, но не будем о нём беспокоиться. Теперь давайте вызовем эту функцию с объектом, у которого свойству x присвоено свойство, и просмотрим сгенерированный код.
d8> incX({x:13});
...
[generated bytecode for function: incX (0x026c0025ab65 <SharedFunctionInfo incX>)]
Bytecode length: 11
Parameter count 2
Register count 1
Frame size 8
Bytecode age: 0
0000026C0025ACC6 @ 0 : 0d 01 LdaSmi [1]
0000026C0025ACC8 @ 2 : c5 Star0
0000026C0025ACC9 @ 3 : 2d 03 00 01 GetNamedProperty a0, [0], [1]
0000026C0025ACCD @ 7 : 39 fa 00 Add r0, [0]
0000026C0025ACD0 @ 10 : aa Return
Constant pool (size = 1)
0000026C0025AC99: [FixedArray] in OldSpace
- map: 0x026c00002231 <Map(FIXED_ARRAY_TYPE)>
- length: 1
0: 0x026c000041ed <String[1]: #x>
Handler Table (size = 0)
Source Position Table (size = 0)
14Нас интересует только часть, относящаяся к байт-коду. Сначала обратим внимание, что этот байт-код находится в объекте
SharedFunctionInfo, о котором мы говорили выше! Мы видим, что вызывается LdaSmi, записывающая small integer со значением 1 в регистр аккумулятора.Далее мы вызываем
Star0, сохраняющую (поэтому и St) значение в аккумулятор (поэтому и a) в регистре r0. То есть в этом случае мы записываем 1 в r0.Байт-код
GetNameProperty получает именованное свойство из a0 и сохраняет его в аккумулятор, который будет иметь значение 13. a0 относится к i-тому аргументу функции. То есть если мы передали a,b,x и хотим записать x, то в операнде байт-кода должно быть указано a2, поскольку нам нужен второй аргумент функции (вспомним, что это массив аргументов). В этом случае a0 будет искать именованное свойство в таблице, где индекс 0 отображается на x. - length: 1
0: 0x026c000041ed <String[1]: #x>Если вкратце, это байт-код, записывающий
obj.x. Другой операнд [0] называется feedback vector (вектор обратной связи), он содержит информацию среды выполнения и данные shape объекта, используемые TurboFan для оптимизации.Далее мы прибавляем (
Add) значение в регистре r0 к аккумулятору, что даёт нам значение 14. Затем мы вызываем Return, который возвращает значение в аккумуляторе, и выходим из функции.Чтобы вы могли представить это в фрейме стека, я создал GIF того, что происходит в упрощённом стеке с каждой командой байт-кода.
Как видите, хотя байт-коды немного загадочны, после того, как мы разберёмся, что делает каждый из них, их будет довольно легко понять и исследовать. Если вы хотите больше узнать о байт-коде V8, рекомендую прочитать JavaScript Bytecode – v8 Ignition Instructions, в котором рассматривается большая часть операций.
Sparkplug
Теперь, когда у нас есть приличное понимание того, как Ignition генерирует и исполняет наш код на JavaScript в виде байт-кода, настало время рассмотреть часть конвейера компилятора V8, относящуюся к компиляции. Начнём мы с Sparkplug, поскольку его довольно легко понять, ведь он выполняет лишь небольшую модификацию уже сгенерированного байт-кода и стека в целях оптимизации.
Как мы знаем из части первой, Sparkplug — это очень быстрый неоптимизирующий компилятор движка V8, расположенный между Ignition и TurboFan. По сути, Sparkplug на самом деле не компилятор, а больше похож на транспилятор, преобразующий байт-код Ignition в машинный код для его нативного выполнения. Кроме того, это неоптимизирующий компилятор, поэтому он не вносит особых оптимизаций, поскольку этим занимается TurboFan.
Так почему же Sparkplug настолько быстр? Он быстр, потому что жульничает. Во-первых, компилируемые им функции уже были скомпилированы в байт-код, и, как мы знаем, Ignition уже проделал всю сложную работу с переменной дискретностью, управлением потоком и так далее. В этом случае, Sparkplug выполняет компиляцию из байт-кода, а не из исходников на JavaScript.
Во-вторых, Sparkplug не создаёт промежуточного представления (intermediate representation, IR), как это делает большинство компиляторов (о чём мы узнаем позже). В данном случае. Sparkplug выполняет компиляцию в машинный код за один линейный проход по байт-коду. Это явление имеет общее название 1:1 mapping.
Любопытно, что Sparkplug, по сути, во многом является простым оператором
switch внутри цикла for, который выполняет вызовы фиксированного байт-кода, а затем генерирует машинный код. Эту реализацию можно увидеть в файле исходников v8/src/baseline/baseline-compiler.cc.Пример функции генерации машинного кода Sparkplug показан ниже.
switch (iterator().current_bytecode()) {
#define BYTECODE_CASE(name, ...) \
case interpreter::Bytecode::k##name: \
Visit##name(); \
break;
BYTECODE_LIST(BYTECODE_CASE)
#undef BYTECODE_CASE
}Как же Sparkplug генерирует этот машинный код? Разумеется, он снова жульничает. Sparkplug сам по себе генерирует очень мало кода, вместо этого он просто вызывает встроенные функции байт-кода, вход в которые обычно выполняется
InterpreterEntryTrampoline с последующей обработкой в v8/src/builtins/x64/builtins-x64.cc.Вспомним, что когда мы говорили о Ignition, в объекте
JSFunction упоминалось замыкание, связанное с «оптимизированным кодом». По сути, Sparkplug хранит там встроенную функцию байт-кода, а при выполнении функции вместо вызова байт-кода мы вызываем непосредственно встроенную функцию.Теперь вы уже наверно думаете, что Sparkplug, по сути, является просто интерпретатором с громким именем, и вы не ошибаетесь. Sparkplug фактически занимается просто сериализацией исполнения интерпретатора, вызывая те же встроенные функции. Однако это позволяет функции JavaScript работать быстрее, поскольку благодаря этому мы можем избежать излишних затрат в интерпретаторе наподобие декодирования опкодов и поиска в таблице вызовов байт-кода, что позволяет нам уменьшить объём использования CPU, перейдя из движка эмуляции к нативному исполнению.
Чтобы чуть больше узнать о том, как работают эти встроенные функции, рекомендую прочитать Short Builtin Calls.
1:1 Mapping
1:1 mapping Sparkplug связано не только с тем, как оно компилирует байт-код Ignition в разновидность машинного кода; это связано и с фреймами стека. Как мы знаем, каждой части конвейера компилятора нужно хранить состояние функции. И как мы уже видели в V8, состояния функций JavaScript сохраняются в фреймы стека Ignition сохранением текущей вызываемой функции, контекста, с которой она вызывается, количества переданных аргументов, указателя на массив байт-кодов, и так далее.
Как мы знаем, Ignition — это интерпретатор на основе регистров. Он имеет виртуальные регистры, используемые для аргументов функций, а также как вводы и выводы для операндов байт-кода. Чтобы Sparkplug был быстрым и ему не приходилось самостоятельно заниматься распределением регистров, он повторно использует фреймы регистров Ignition, что, в свою очередь, позволяет Sparkplug «отзеркаливать» поведение интерпретатора и стек. Благодаря этому Sparkplug не требуется никакое отображение между двумя фреймами, поэтому эти фреймы стека совместимы почти 1:1.
Стоит заметить, что я сказал «почти» — существует одно небольшое различие между фреймами стека Ignition и Sparkplug. И это различие заключается в том, что Sparkplug не нужно хранить слот смещения байт-кода в регистровом файле, поскольку код Sparkplug создаётся непосредственно из байт-кода. Вместо этого он заменяет его на кэшированный вектор обратной связи.
Пример сравнения этих двух фреймов стека показан на изображении ниже, взятом из документации по Ignition.
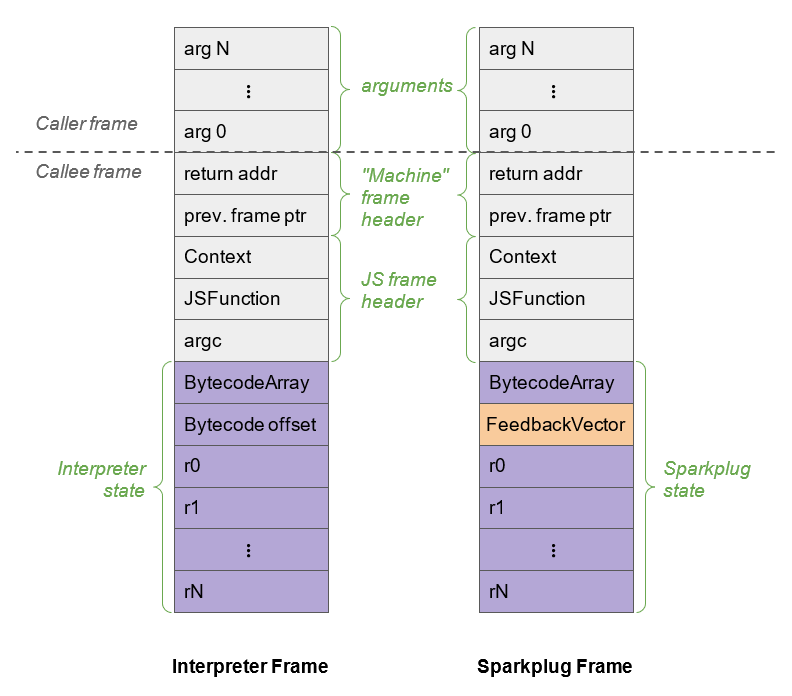
Так зачем же Sparkplug нужно создавать и хранить структуру фрейма стека, схожего с фреймом стека Ignition? По одной причине, и это основная причина того, как работают Sparkplug и Turbofan — они выполняют так называемую on-stack replacement (OSR) (замену в стеке). OSR — это возможность замены текущего исполняемого кода другой версией. В данном случае, когда Ignition видит, что функция JavaScript используется часто, он отправляет её в Sparkplug для ускорения.
После того, как Sparkplug сериализирует байт-коды в их встроенные функции, он заменяет фрейм стека интерпретатора для этой конкретной функции. При обходе и исполнении стека код переходит непосредственно в Sparkplug, а не исполняется в эмулируемом стеке Ignition. А поскольку фреймы «отзеркаливаются», это, по сути, позволяет V8 переключаться между кодом интерпретатора и Sparkplug практически с нулевыми лишними тратами на трансляцию фрейма.
Прежде чем мы двинемся дальше, мне бы хотелось упомянуть аспект безопасности Sparkplug. В общем случае, вероятность проблемы безопасности в самом сгенерированном коде мала. Угроза безопасности в Sparkplug выше в том, как интерпретируется структура фреймов стека Ignition, что может привести к type confusion или к исполнению кода в стеке.
Один из примеров подобного — Issue 1179595, имевшая потенциальное RCE из-за недопустимой проверки количества регистров. Также сложность есть и в том, как Sparkplug выполняет инвертирование битов RX/WX. Однако я не буду вдаваться в подробности, поскольку на самом деле это не очень важно и такие баги не играют важной роли в нашей серии статей.
Итак, теперь мы понимаем, как работают Ignition и Sparkplug. Настало время углубиться в конвейер компилятора и в понимание оптимизирующего компилятора TurboFan.
TurboFan
TurboFan — это компилятор Just-In-Time (JIT) движка V8, сочетающий интересную концепцию непосредственного представления «море узлов» (Sea of Nodes) с многоуровневым конвейером трансляции и оптимизации, помогающим TurboFan генерировать более качественный машинный код из байт-кода. Если вы в процессе чтения статьи изучаете код и документацию, то знаете, что TurboFan — это гораздо больше, чем просто компилятор.
TurboFan отвечает за обработчики байт-кода интерпретатора, встроенные функции, заглушки кода и встроенную систему кэша при помощи своего макроассемблера! Когда я говорил, что TurboFan — самая важная часть конвейера компилятора, это была не шутка.
Как же работают оптимизирующие компиляторы наподобие TurboFan?
Оптимизирующие компиляторы работают при помощи так называемого профилировщика, который мы вкратце рассмотрели в части первой. По сути, этот профилировщик работает заранее, он ищет код, который можно оптимизировать (мы называем этот код или функцию JavaScript горячим). Это возможно благодаря сбору метаданных, «сэмплов» функций JavaScript и стека при помощи изучения информации, собранной встроенными кэшами и вектором обратной связи.
Затем компилятор создаёт структуру данных промежуточного представления (IR), которая используется для создания оптимизированного кода. Весь этот процесс изучения кода с последующей компиляцией машинного кода называется компиляцией Just-in-Time (JIT).
Компиляция Just-In-Time (JIT)
Как мы знаем, исполнение байт-кода в виртуальной машине интерпретатора медленнее, чем исполнение ассемблерного кода на нативной машине. Так получается, потому что JavaScript динамичен, и он требует много лишних затрат на поиск свойств, проверку объектов, значений и так далее; кроме того, всё работает в эмулируемом стеке.
Разумеется, Map и встроенное кэширование (Incline Caching, IC) помогают устранить часть этих затрат, ускоряя динамический поиск свойств, объектов и значений, но они всё равно не могут обеспечить максимальной производительности. Так получается потому, что каждое из IC работает само по себе и не знает о своих соседях.
Для примера возьмём Map — если мы добавим свойство к известному shape, то нам всё равно придётся следовать по таблице переходов и искать или добавлять дополнительные shape. Если в какой-то функции или объекте нам нужно это делать множество раз, даже при известном shape, то мы, по сути, тратим вычислительные такты на многократное повторение этих операций.
Поэтому когда в коде есть функция JavaScript, исполняемая множество раз, то может оказаться выгодным потратить время на передачу функции в компилятор и её компиляцию в машинный код, что позволит исполнять её намного быстрее.
Для примера рассмотрим этот код:
function hot_function(obj) {
return obj.x;
}
for (let i=0; i < 10000; i++) {
hot_function({x:i});
}Функция
hot_function просто получает объект и возвращает значение его свойства x. Далее мы исполняем эту функцию примерно 10 раз, и для каждого объекта мы просто передаём новое значение integer для свойства x. В данном случае, поскольку функция используется множество раз, а общий shape объекта не меняется, V8 может решить, что лучше просто передать её вверх по конвейеру (это называется tier-up) для компиляции, чтобы она выполнялась быстрее.Мы можем увидеть это в действии в
d8, трассировав оптимизацию при помощи флага --trace-opt. Давайте сделаем это, а заодно добавим команду --allow-natives-syntax, чтобы можно было исследовать, как выглядит код функции до и после оптимизации.Начнём с запуска
d8, а затем подготовим нашу функцию. Далее используем %DisassembleFunction с hot_function, чтобы увидеть её тип. У вас должно получиться что-то похожее.d8> function hot_function(obj) {return obj.x;}
d8> %DisassembleFunction(hot_function)
0000027B0020B31D: [CodeDataContainer] in OldSpace
- map: 0x027b00002a71 <Map[32](CODE_DATA_CONTAINER_TYPE)>
- kind: BUILTIN
- builtin: InterpreterEntryTrampoline
- is_off_heap_trampoline: 1
- code: 0
- code_entry_point: 00007FFCFF5875C0
- kind_specific_flags: 0Как видите, изначально этот объект кода исполняется Ignition, поскольку является
BUILTIN, и обрабатывается InterpreterEntryTrampoline. Если мы исполним эту функцию 10 тысяч раз, то её оптимизирует TurboFan.d8> for (let i=0; i < 10000; i++) {hot_function({x:i});}
[marking 0x027b0025aa4d <JSFunction (sfi = 0000027B0025A979)> for optimization to TURBOFAN, ConcurrencyMode::kConcurrent, reason: small function]
[compiling method 0x027b0025aa4d <JSFunction (sfi = 0000027B0025A979)> (target TURBOFAN) OSR, mode: ConcurrencyMode::kConcurrent]
[completed compiling 0x027b0025aa4d <JSFunction (sfi = 0000027B0025A979)> (target TURBOFAN) OSR - took 1.691, 81.595, 2.983 ms]
[completed optimizing 0x027b0025aa4d <JSFunction (sfi = 0000027B0025A979)> (target TURBOFAN) OSR]
9999Как видите, в дело вступает TurboFan, он начинает компилировать функцию для оптимизации. Обратите внимание на несколько ключевых моментов в трассировке оптимизации. Как видно в строке первой трассировки оптимизации, мы помечаем
SFI, или SharedFunctionInfo функции JSFunction для оптимизации.Вспомним из изучения Ignition, что SFI содержит байт-код нашей функции. TurboFan использует этот байт-код для генерации IR, а затем оптимизирует её до машинного кода.
Ниже встречается упоминание
OSR, или замены в стеке. TurboFan делает практически то же самое, что и Sparkplug при оптимизации байт-кода. Он заменяет фрейм стека реальным фреймом стека JIT или системы, который во время выполнения будет указывать на оптимизированный код. Это позволяет функции при следующем вызове переходить напрямую к оптимизированному коду, а не исполняться в эмулируемом стеке Ignition.Если мы повторно выполним
%DisassembleFunction для функции hot_function, то должны увидеть, что теперь она оптимизирована, а точка входа кода в SharedFunctionInfo указывает а оптимизированный машинный код.d8> %DisassembleFunction(hot_function)
0000027B0025B2B5: [CodeDataContainer] in OldSpace
- map: 0x027b00002a71 <Map[32](CODE_DATA_CONTAINER_TYPE)>
- kind: TURBOFAN
- is_off_heap_trampoline: 0
- code: 0x7ffce0004241 <Code TURBOFAN>
- code_entry_point: 00007FFCE0004280
- kind_specific_flags: 4Внимательный читатель мог заметить нечто интересное при трассировке оптимизации функции. Если приглядеться, то можно заметить, что TurboFan срабатывает не сразу, а через несколько секунд, или спустя несколько тысяч итераций цикла. Почему?
Причина в том, что TurboFan ожидает «разогрева» кода. Как вы помните из нашего обсуждения Ignition и Sparkplug, мы вкратце упоминали вектор обратной связи. Этот вектор хранит данные среды выполнения объекта, а также информацию из встроенных кэшей; при этом он собирает так называемую type feedback (обратную связь типов).
Это критически важно для TurboFan, ведь поскольку JavaScript динамический, мы никак не можем хранить информацию статического типа. К тому же, до выполнения мы не знаем тип значения. Компилятор JIT на самом деле должен делать обоснованные предположения об использовании и поведении компилируемого им кода, например, тип функции, тип передаваемых переменных и так далее. По сути, компилятор делает множество допущений, или спекуляций.
Именно поэтому оптимизирующие компиляторы изучают информацию, собранную встроенными кэшами, и используют вектор обратной связи, чтобы принимать обоснованные решения о том, что нужно сделать с кодом, чтобы он был быстрым. Это называется Speculative Optimization (спекулятивной оптимизацией).
Спекулятивная оптимизация и предохранители типов
Как же спекулятивная оптимизация помогает нам превратить код JavaScript в высокооптимизирированный машинный код? Чтобы объяснить это, давайте начнём с примера.
Допустим, у нас есть простое вычисление для функции
add вида return 1 + i. В ней мы возвращаем значение, прибавляя 1 к i. Не зная, какой тип имеет i, нам нужно следовать реализации стандарта ECMAScript для семантики среды выполнения EvaluateStringOrNumericBinaryExpression.
Как видите, после вычисления левой и правой ссылок и вызова GetValue для левого и правого значения нашего операнда нам нужно следовать стандарту ECMAScript для ApplyStringOrNumericBinaryOperator, чтобы можно было вернуть значение.

Если вам это ещё не очевидно, без знания типа переменной
i, будь то integer или string, мы не сможем реализовать всё это вычисление за несколько машинных команд, однако оно должно быть быстрым.Именно здесь в дело вступает спекулятивная оптимизация — TurboFan полагается на информацию вектора обратной связи, чтобы сделать предположения о возможных типах
i.Например, если спустя несколько сотен прогонов мы поищем в векторе обратной связи байт-код
Add и будем знать, что i — это число, то нам не придётся обрабатывать вычисления ToString или даже ToPrimitive. В таком случае, оптимизатор сможет получить команду IR и заявить, что i и возвращаемое значения — это просто числа, и сохранить их таким образом. Это минимизирует количество машинных команд, которые нам нужно генерировать.Как же выглядят эти векторы обратной связи в случае нашей функции?
Если вы вспомните упоминание объекта
JSFunction или замыкания, то вспомните и то, что замыкание связывало нас со слотом вектора обратной связи, а также с SharedFunctionInfo. В векторе обратной связи есть интересный слот, называющийся слотом BinaryOp, который фиксирует обратную связь о вводах и выводах двоичных операций наподобие +, -, * и так далее.Мы можем проверить, что находится внутри нашего вектора обратной связи и увидеть этот конкретный слот, выполнив функцию
%DebugPrint для функции add. Ваши результаты должны быть похожими на мои.d8> function add(i) {return 1 + i;}
d8> for (let i=0; i<100; i++) {add(i);}
d8> %DebugPrint(add)
DebugPrint: 0000019A002596F1: [Function] in OldSpace
- map: 0x019a00243fa1 <Map[32](HOLEY_ELEMENTS)> [FastProperties]
- prototype: 0x019a00243ec9 <JSFunction (sfi = 0000019A0020AA45)>
- elements: 0x019a00002259 <FixedArray[0]> [HOLEY_ELEMENTS]
- function prototype:
- initial_map:
- shared_info: 0x019a0025962d <SharedFunctionInfo add>
- name: 0x019a00005809 <String[3]: #add>
- builtin: InterpreterEntryTrampoline
- formal_parameter_count: 1
- kind: NormalFunction
- context: 0x019a00243881 <NativeContext[273]>
- code: 0x019a0020b31d <CodeDataContainer BUILTIN InterpreterEntryTrampoline>
- interpreted
- bytecode: 0x019a0025a89d <BytecodeArray[9]>
- source code: (i) {return 1 + i;}
- properties: 0x019a00002259 <FixedArray[0]>
...
- feedback vector: 0000019A0025B759: [FeedbackVector] in OldSpace
- map: 0x019a0000273d <Map(FEEDBACK_VECTOR_TYPE)>
- length: 1
- shared function info: 0x019a0025962d <SharedFunctionInfo add>
- no optimized code
- tiering state: TieringState::kNone
- maybe has maglev code: 0
- maybe has turbofan code: 0
- invocation count: 97
- profiler ticks: 0
- closure feedback cell array: 0000019A00003511: [ClosureFeedbackCellArray] in ReadOnlySpace
- map: 0x019a00002981 <Map(CLOSURE_FEEDBACK_CELL_ARRAY_TYPE)>
- length: 0
- slot #0 BinaryOp BinaryOp:SignedSmall {
[0]: 1
}
...Здесь есть несколько интересных моментов. Количество вызовов показывает нам количество запусков функции
add, а если мы взглянем в вектор обратной связи, то увидим ровно один слот, являющийся BinaryOp, о которой мы говорили. Заглянув в этот слот, мы увидим, что он содержит текущий тип обратной связи SignedSmall, который ссылается на SMI.Вспомним, что эта информация обратной связи интерпретируется не V8, а TurboFan, и, как мы знаем, SMI — это знаковое 32-битное значение (об этом говорилось в разделе про маркировку указателей в первой части).
В целом, эти спекуляции при помощи векторов обратной связи отлично помогают ускорять код, устраняя ненужные машинные команды для разных типов. К сожалению, довольно небезопасно просто применять к динамическим объектам команды, сосредоточенные исключительно на одном типе.
Что же произойдёт, если посередине оптимизированной функции мы передадим вместо числа строку? Если такое произойдёт, мы получим уязвимость вида type confusion. Чтобы защититься от потенциально неверных допущений, TurboFan перед выполнением определённых команд добавляет перед ними так называемый предохранитель типа.
Этот предохранитель типа выполняет проверки, чтобы убедиться, что shape передаваемого нами объекта имеет правильный тип. Это происходит до того, как объект достигает оптимизированных операций. Если объект не соответствует ожидаемому shape, то выполнение оптимизированного кода не может продолжаться. В таком случае мы «выбрасываемся» из ассемблерного кода и возвращаемся к неоптимизированному байт-коду внутри интерпретатора, продолжая выполнение там. Это называется деоптимизацией.
Ниже показан пример предохранителя типа и перехода к деоптимизации в оптимизированном ассемблерном коде.
REX.W movq rcx,[rbp-0x38] ; Запись i в rcx
testb rcx,0x1 ; Проверка, является ли rcx SMI
jnz 00007FFB0000422A <+0x1ea> ; При неудачной проверке происходит выходДеоптимизации из-за предохранителей типов не ограничены проверкой несоответствия типов объектов. Они также работают с арифметическими операциями и проверкой границ.
Например, если наш оптимизированный код был оптимизирован для арифметических операций над 32-битными целыми числами, и происходит переполнение, то мы можем произвести деоптимизацию, чтобы вычисления обрабатывал Ignition, защитившись таким образом от потенциальных проблем с безопасностью на машине. Такие проблемы, способные привести к деоптимизации, называются «побочными эффектами» (о них мы подробнее поговорим позже).
Что касается процесса оптимизации, мы также можем увидеть деоптимизацию в действии внутри
d8 при помощи флага --trace-deopt. Давайте повторно добавим функцию add и запустим следующий цикл.for (let i=0; i<10000; i++) {
if (i<7000) {
add(i);
} else {
add("string");
}
}Мы просто позволяем оптимизировать функцию под числа, а спустя семь тысяч итераций начинаем передавать строку, что должно привести к «выбросу». Ваши результаты должны быть похожими на мои.
d8> function add(i) {return 1 + i;}
d8> for (let i=0; i<10000; i++) {if (i<7000) {add(i);} else {add("string");}}
[marking 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)> for optimization to TURBOFAN, ConcurrencyMode::kConcurrent, reason: small function]
[compiling method 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)> (target TURBOFAN) OSR, mode: ConcurrencyMode::kConcurrent]
[completed compiling 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)> (target TURBOFAN) OSR - took 1.987, 70.704, 2.731 ms]
[completed optimizing 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)> (target TURBOFAN) OSR]
[bailout (kind: deopt-eager, reason: Insufficient type feedback for call): begin. deoptimizing 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)>, 0x7ffb00004001 <Code TURBOFAN>, opt id 0, node id 63, bytecode offset 40, deopt exit 3, FP to SP delta 96, caller SP 0x00ea459fe250, pc 0x7ffb00004274]
[compiling method 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)> (target TURBOFAN) OSR, mode: ConcurrencyMode::kConcurrent]
[completed compiling 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)> (target TURBOFAN) OSR - took 0.325, 121.591, 1.425 ms]
[completed optimizing 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)> (target TURBOFAN) OSR]
"1string"Как видите, функции оптимизируются, а позже срабатывает «выброс». Это деоптимизирует код обратно к байт-коду из-за недостаточного типа при вызове. Затем происходит что-то интересное. Функция оптимизируется снова. Почему?
Функция по-прежнему «горячая» и ей нужно пройти ещё несколько тысяч итераций. Собрав в обратную связь типов и число, и строку, TurboFan возвращается назад и оптимизирует код во второй раз. Но на этот раз он добавляет код, позволяющий выполнять обработку строк. В данном случае, будет добавлен второй предохранитель типа, поэтому второй прогон кода оптимизирован и для числа, и для строки!
Хороший пример и объяснение этого можно посмотреть в видео Inside V8: The choreography of Ignition and TurboFan.
Также мы можем увидеть эту обновлённую обратную связь в слоте
BinaryOp, выполнив команду %DebugPrint для нашей функции add. Вы должны увидеть нечто подобное показанному ниже.d8> %DebugPrint(add)
DebugPrint: 000003E20025970D: [Function] in OldSpace
- map: 0x03e200243fa1 <Map[32](HOLEY_ELEMENTS)> [FastProperties]
- prototype: 0x03e200243ec9 <JSFunction (sfi = 000003E20020AA45)>
- elements: 0x03e200002259 <FixedArray[0]> [HOLEY_ELEMENTS]
- function prototype:
- initial_map:
- shared_info: 0x03e20025962d <SharedFunctionInfo add>
- name: 0x03e200005809 <String[3]: #add>
- builtin: InterpreterEntryTrampoline
- formal_parameter_count: 1
- kind: NormalFunction
- context: 0x03e200243881 <NativeContext[273]>
- code: 0x03e20020b31d <CodeDataContainer BUILTIN InterpreterEntryTrampoline>
- interpreted
- bytecode: 0x03e20025aca5 <BytecodeArray[9]>
- source code: (i) {return 1 + i;}
- properties: 0x03e200002259 <FixedArray[0]>
...
- feedback vector: 000003E20025ACF1: [FeedbackVector] in OldSpace
- map: 0x03e20000273d <Map(FEEDBACK_VECTOR_TYPE)>
- length: 1
- shared function info: 0x03e20025962d <SharedFunctionInfo add>
- no optimized code
- tiering state: TieringState::kNone
- maybe has maglev code: 0
- maybe has turbofan code: 0
- invocation count: 5623
- profiler ticks: 0
- closure feedback cell array: 000003E200003511: [ClosureFeedbackCellArray] in ReadOnlySpace
- map: 0x03e200002981 <Map(CLOSURE_FEEDBACK_CELL_ARRAY_TYPE)>
- length: 0
- slot #0 BinaryOp BinaryOp:Any {
[0]: 127
}Как видите,
BinaryOp теперь хранит тип обратной связи Any, а не SignedSmall или String. Почему? Это связано с так называемой Feedback Lattice.Feedback Lattice
Feedback lattice (сетка обратной связи) хранит возможные состояния обратной связи для операции. Она начинается с
None, показывающего, что сетка пока ничего не видела, а потом спускается к состоянию Any, показывающему, что она видела сочетание входящих и выходящих данных. Состояние Any обозначает, что функция считается полиморфной, а любое другое состояние показывает, что функция мономорфна, поскольку она создала только конкретное значение.Если вы хотите побольше узнать о разнице между мономорфным и полиморфным кодом, крайне рекомендую прочитать потрясающую статью What’s up with Monomorphism?.
Ниже я представил визуальный пример того, как приблизительно выглядит feedback lattice.

Эта сетка работает схожим образом с сеткой массива из первой части статьи. Обратная связь может продвигаться только вниз по сетке. Если мы переходим от Number к Any, то никогда не сможем вернуться назад. Если же по какой-то волшебной причине мы возвращаемся, то рискуем попасть в так называемую петлю деоптимизации, при которой оптимизирующий компилятор постоянно потребляет недопустимую обратную связь и вываливается из неоптимизированного кода.
Подробнее о проверках типов можно прочитать в файле
v8/src/compiler/use-info.h. Кроме того, если вы хотите больше узнать о системе обратной связи и встраиваемом кэше V8, то рекомендую посмотреть видео с докладом Майкла Стэнтона V8 and How It Listens to You.Промежуточное представление «море узлов»
Теперь, когда мы знаем, как собирается обратная связь типов для того, чтобы TurboFan мог делать свои спекулятивные допущения, давайте посмотрим, как TurboFan создаёт из этой обратной связи своё специализированное промежуточное представление (IR). IR генерируется потому, что эта структура данных абстрагируется от сложности кода, что, в свою очередь, упрощает выполнение оптимизаций компилятора.
IR «море узлов» TurboFan основано на static single assignment (SSA) — свойстве IR, требующем, чтобы каждой переменной присваивалось значение только один раз, и перед её использованием она была определена. Это полезно для таких оптимизаций, как redundancy elimination (устранение избыточности).
Ниже показан пример SSA для нашей функции
add.// функция add(i) {return 1 + i;}
var i1 = argument
var r1 = 1 + i1
return r1Этот вид SSA затем преобразуется в формат графа, схожего с графом потока управления (CFG), где используются узлы и рёбра, представляющие код и его зависимости между вычислениями. Подобный тип графа позволяет TurboFan использовать его и для анализа потока данных, и для генерации машинного кода.
Давайте же посмотрим, как выглядит это «море узлов». Для этого мы воспользуемся нашим примером с
hot_function. Начнём с создания нового файла JavaScript и добавим в него следующее.function hot_function(obj) {
return obj.x;
}
for (let i=0; i < 10000; i++) {
hot_function({x:i});
}После этого мы пропустим этот скрипт через
d8 с флагом --trace-turbo, что позволит нам оттрассировать и сохранить IR, сгенерированное JIT TurboFan. Ваши результаты должны быть похожи на показанные ниже. В конце прогона должен сгенерироваться файл JSON, имеющий имя в формате turbo-*.json.C:\dev\v8\v8\out\x64.debug>d8 --trace-turbo hot_function.js
Concurrent recompilation has been disabled for tracing.
---------------------------------------------------
Begin compiling method add using TurboFan
---------------------------------------------------
Finished compiling method add using TurboFanПосле завершения перейдите к Turbolizer в веб-браузере, нажмите
CTRL + L и загрузите свой файл JSON. Этот инструмент поможет визуализировать граф моря узлов, сгенерированный TurboFan.Увиденный вами граф должен быть очень похож на мой.
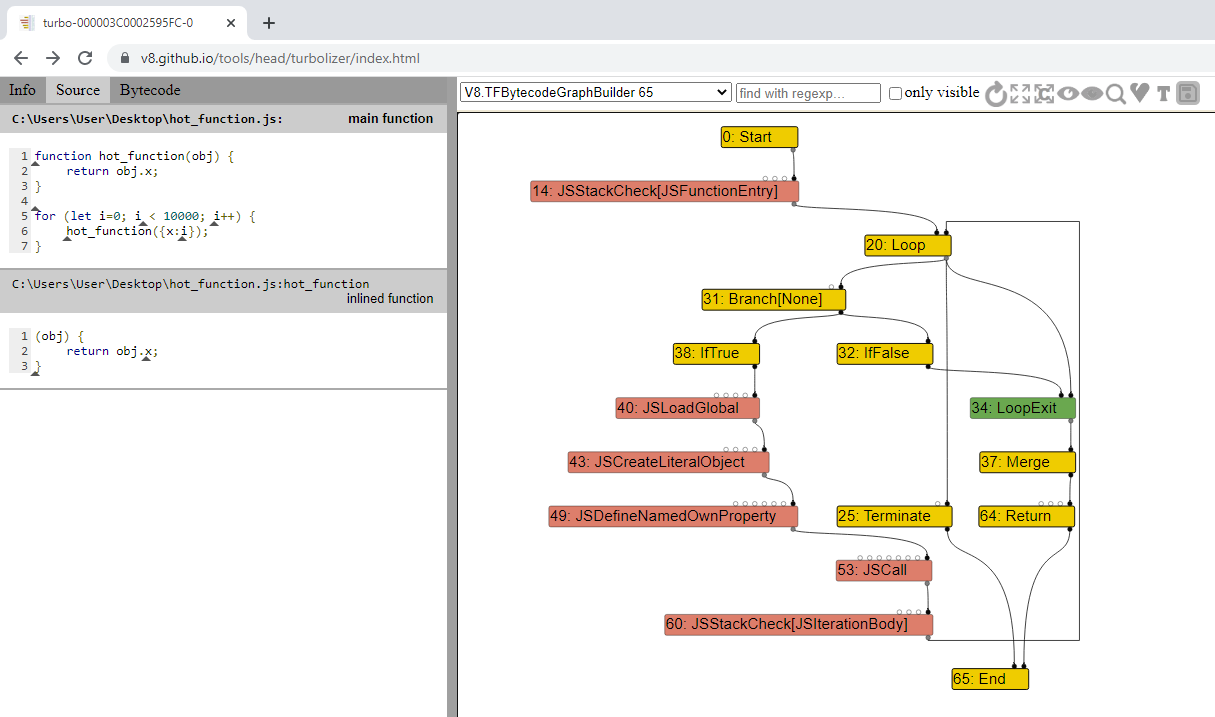
В Turbolizer слева показан исходный код, а справа (не показано на изображении) находится оптимизированный машинный код, сгенерированный TurboFan. В середине находится граф моря узлов.
Пока многие узлы скрыты, а отображены только узлы управления, что является стандартным поведением. Если нажать на поле «Show All Nodes» вправа от символа «Обновить», то будут показаны все узлы.
Поэкспериментировав с Turbolizer и изучив граф, вы заметите, что в нём есть пять разных цветов узлов, обозначающих следующее:
- Жёлтый: эти узлы обозначают узлы управления, то есть то, что может изменить «поток» скрипта, например, конструкцию if/else.
- Голубой: эти узлы обозначают значение, которое может иметь или возвращать определённый узел, например, константы кучи или встроенные значения.
-
Красный: обозначает семантику перегруженных операторов JavaScript, например, любые действия, выполняемые на уровне JavaScript (
JSCall,JSAddи так далее). Они напоминают байт-кодовые операции. - Синий: обозначает операции на уровне виртуальной машины, например, распределения, проверки границ, загрузку данных, загрузку данных из стека и так далее. Этот тип полезен для отслеживания потребляемой Turbofan обратной связи.
- Зелёный: соответствует уровню отдельных машинных команд.
Как видите, каждый узел в этом море узлов может обозначать арифметические операции, загрузки, сохранения, вызовы константы и так далее. Также существует три типа рёбер (обозначенных стрелками между каждыми из узлов), выражающие зависимости. Это следующие рёбра:
- Управление: точно так же, как и в CFG, эти рёбра обеспечивают ветвление и циклы.
- Значение: точно так же, как и в графах потоков данных, эти рёбра обозначают зависимости значений и вывод.
- Эффект: описывают операции упорядочивания, например, считывание или запись состояний.
Зная это, давайте немного развернём граф и взглянем на несколько других узлов, чтобы понять, как работает поток. Учтите, что я скрыл несколько отдельных узлов, которые не очень нам важны.

Как видите, жёлтые узлы — это узлы управления, регулирующие поток функции. Изначально у нас есть узел
Loop, сообщающий нам, что мы входим в цикл. Далее рёбра управления указывают на узлы Branch и LoopExit. Имя Branch говорит само за себя, это ветвление цикла в операторы True/False.Если подняться по узлу
Branch вверх, то можно увидеть, что он имеет узел SpeculativeNumberLessThan, имеющий ребро значения, указывающее на NumberConstant со значением 10000. Это соответствует нашей функции, поскольку мы выполняем цикл 10 тысяч раз. Так как этот узел зелёный, он является машинной командой и означает предохранитель типа для цикла. В узле SpeculativeNumberLessThan можно видеть, что есть ребро эффекта, указывающее на LoopExitEffect; это значит, что если число больше 10 тысяч, мы выполняем выход из цикла, потому что допущение было только что нарушено.Пока значение меньше 10 тысяч, а
SpeculativeNumberLessThan является истинным, мы будем записывать объект и вызывать JSDefineNamedOwnProperty, что даст смещение объекта до свойства x. Затем мы вызываем JSCall, чтобы прибавить 1 к значению свойства и вернуть значение. От этого узла у нас также есть узел эффекта, идущий к SpeculativeSafeIntegerAdd. Этот узел имеет ребро значения, указывающее на узел NumberConstant, имеющий значение 1, которое является математическим сложением, выполняемым при возврате значения.Снова подметим, что у нас есть узел
SpeculativeSafeIntegerAdd, проверяющий, действительно ли арифметика сложения прибавляет SMI, а не что-то другое, в противном случае он вызовет предохранитель типа и выполнит деоптимизацию.Узел
Phi — это, по сути, узел SSA, объединяющий два (или больше) потенциальных значения, вычисленных в разных ветвях. В этом случае он объединяет оба потенциальных integer.Как видите, зная основы, разобраться в этих графах не так уж сложно.
В левом верхнем углу окна моря узлов, показано, что выбрана
V8.TFBytecodeGraphBuilder. Эта опция отображает сгенерированное IR из байт-кода без применённых оптимизаций. В раскрывающемся меню можно выбрать другие проходы оптимизации, которым подвергается код, для отображения соответствующего IR.Стандартные оптимизации
Итак после изучения моря узлов TurboFan у вас должно появиться достаточное понимание того, как ориентироваться в сгенерированном IR и понимать его. Далее мы можем углубиться в понимание некоторых стандартных оптимизаций TurboFan. Эти оптимизации влияют на исходный граф, созданный из байт-кода.
Поскольку получившийся граф благодаря предохранителям типов имеет информацию статического типа, оптимизации выполняются в более классическом предварительном стиле и повышают скорость выполнения или уменьшают объём занимаемой кодом памяти. После оптимизации плучившийся граф опускается до уровня машинного кода (это называется «lowering»), а затем записывается в область исполняемой памяти для исполнения движком V8 при вызове скомпилированной функции.
Стоит заметить, что это опускание может происходить на нескольких этапах, и между ними могут добавляться дальнейшие оптимизации, что делает этот конвейер компилятора довольно гибким.
А теперь давайте рассмотрим некоторые из этих стандартных оптимизаций.
Typer (типизатор)
Одна из самых ранних фаз оптимизации называется
TyperPhase, она выполняется функцией OptimizeGraph. Эта фаза выполняет трассировку кода и выявляет окончательные типы операций с объектами кучи, например, Int32 + Int32 = Int32.При выполнении
Typer он посещает каждый узел графа и пытается «уменьшить» его, стремясь упростить логику операции. Затем он делает соответствующий вызов typer узла, чтобы ассоциировать с ним Type. Например, в нашем случае константы integer внутри цикла и арифметика return посетит Typer::Visitor::TypeNumberConstant, который возвращает тип Range, как показано в примере кода из v8/src/compiler/types.cc.Type Type::Constant(double value, Zone* zone) {
if (RangeType::IsInteger(value)) {
return Range(value, value, zone);
} else if (IsMinusZero(value)) {
return Type::MinusZero();
} else if (std::isnan(value)) {
return Type::NaN();
}А что с узлами спекуляций?
Они обрабатываются
OperationTyper. В нашем случае арифметические спекуляции для возврата нашего значения вызовут OperationTyper::SpeculativeSafeIntegerAdd, который назначит типу диапазон «безопасных integer», например, Int64. Этот тип будет проверяться, и если при выполнении он не будет являться Int64, то произойдёт деоптимизация. По сути, это позволяет арифметическим операциям иметь положительные и отрицательные возвращаемые значения и предотвращает потенциальные проблемы положительного и отрицательного переполнения.Зная это, давайте теперь рассмотрим фазу оптимизации
V8.TFTyper, чтобы изучить граф и ассоциированные с узлами типы.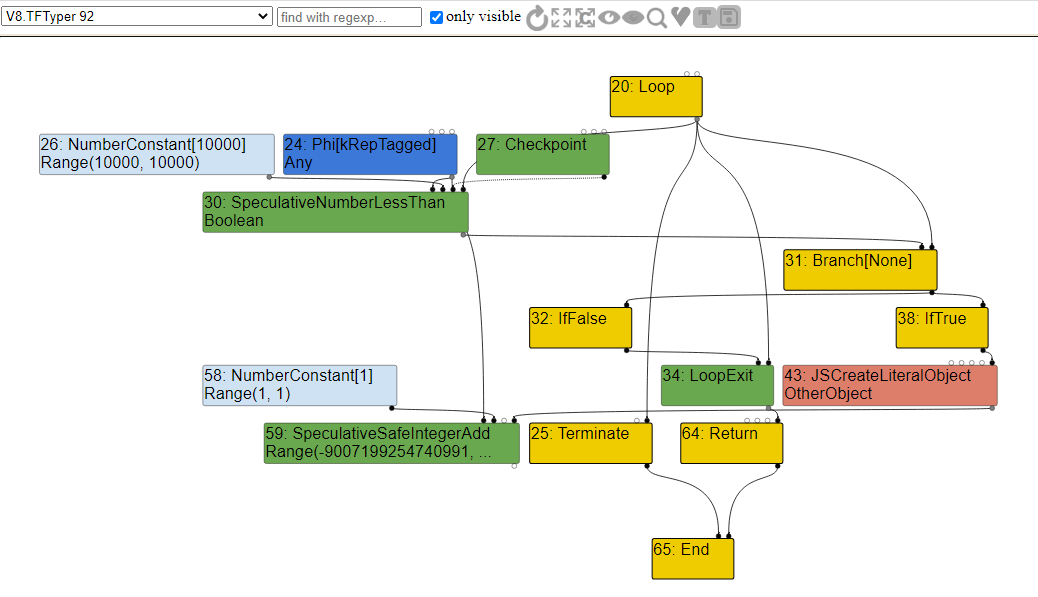
Анализ диапазонов
В процессе оптимизации
Typer компилятор выполняет трассировку кода, выявляет диапазон операций и вычисляет границы получаемых значений. Это называется анализом диапазонов.На показанном выше графе мы встретились с типом
Range, в частности, для узла SpeculativeSafeIntegerAdd, имеющего диапазон переменной Int64. Это было сделано потому, что оптимизатор анализа диапазонов вычисляет min и max складываемых или возвращаемых значений.В данном случае мы возвращаем значение
i из свойства объекта x плюс 1. Обратная связь типов знала только то, что возвращаемое число — это integer, она не могла определить, в каком диапазоне будет находиться значение. Поэтому чтобы ошибаться в безопасную сторону, она решила для предотвращения проблем назначить максимально возможное значение.Давайте ещё раз взглянем на этот анализ диапазонов, рассмотрев следующий код:
function hot_function(obj) {
let values = [0,13,1337]
let a = 1;
if (obj == "leet")
a = 2;
return values[a];
}Как видите, в зависимости от типа передаваемого параметра
obj, если obj является строкой, равной слову leet, то a будет равно 1337, в противном случае оно будет равно 13. Эта часть хода будет подвергнута SSA и объединена в узел Phi, который будет содержать диапазон того, чем может быть a. Константам устанавливается диапазон, равный их жёстко заданному значению, однако эти константы из-за арифметических вычислений будут влиять на наши спекулятивные диапазоны.Если мы посмотрим на граф, созданный из этого кода после анализа диапазонов, то увидим следующее.
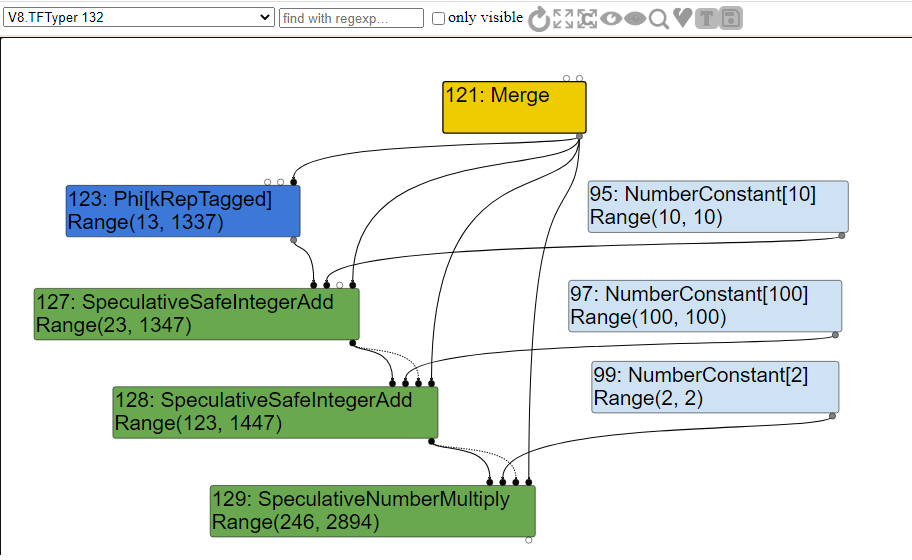
Как видите, благодаря SSA у нас есть узел
Phi. При анализе диапазонов typer посещает функцию узла TypePhi и создаёт объединение операндов 13 и 1337, что позволяет нам иметь диапазон возможных значений a.Для спекулятивных узлов
OperationTyper вызывает функцию AddRanger, которая вычисляет min и max границы для типа Range. В данном случае мы видим, что typer вычисляет диапазон возвращаемых значений для обеих возможных итераций a после арифметических операций.Если анализ диапазонов завершится сбоем и мы получим значение, не ожидаемое компилятором, произойдёт деоптимизация. Всё достаточно понятно!
Bounds Checking Elimination (BCE)
Ещё одна стандартная оптимизация, используемая при помощи
Typer в фазе упрощённого опускания — это операция CheckBounds, применяемая к спекулятивным узлам для CheckBound. Эта оптимизация обычно применяется к операциям доступа к массивам, если после анализа диапазонов точно проверено, что индекс массива находится в границах массива.Однако команда разработчиков reason Chromium решила отключить эту оптимизацию, чтобы усилить проверку границ TurboFan на баги typer. Существуют «баги», позволяющие обойти эту защиту, но мы не будем в это вдаваться. Если вы хотите узнать об этих багах подробнее, то рекомендую прочитать Circumventing Chrome’s Hardening of Typer Bugs.
Как бы то ни было, давайте посмотрим, как такой тип оптимизации работал бы на следующем примере кода:
function hot_function(obj) {
let values = [0,13,1337]
let a = 1;
if (obj == "leet")
a = 2;
return values[a];
}Как видите, этот пример очень похож на код, который мы использовали в анализе диапазонов. Мы снова получаем параметр
hot_function, и если объект соответствует строке «leet», мы присваиваем a значение 2 и возвращаем значение 1337, в противном случае присваиваем a значение 1 и возвращаем значение 13.В особенности обратите внимание на то, что
a никогда не равно 0, поэтому мы никогда не вернём 0, или, по крайней мере, никогда не должны этого делать. Если посмотреть на граф, это создаёт интересный случай. Давайте рассмотрим часть IR, относящуюся к escape-анализу.
Как видите, у нас есть ещё один узел
Phi, объединяющий потенциальные значения a, и ещё есть узел CheckBounds, используемый для проверки границ массива. Если мы находимся в диапазоне 1 или 2, то вызываем LoadElement для считывания элемента из массива, в противном случае вываливаемся, поскольку проверка границ не ожидает индекса 0.Возможно, вы задаётесь вопросом, почему
LoadElement имеет тип Signed31, а не Signed32. Signed31 обозначает, что первый бит используется для знака. Это значит, что в случае 32-битного знакового integer мы на самом деле работаем с 31 битом значений вместо 32. Кроме того, как мы видим, LoadElement имеет ввод FixedArray HeapConstant с длиной 3. Этот массив будет нашим массивом values.После выполнения escape-анализа мы переходим к фазе упрощённого опускания. Эта фаза опускания изменяет все описания значений в правильное машинное описание, диктуемое самими машинными операторами. Код этой фазы находится в файле
v8/src/compiler/simplified-lowering.cc. Именно в этой фазе выполняется bounds checking elimination (устранение проверок границ).Как же компилятор решает сделать узел
CheckBounds избыточным?Для каждого узла
CheckBounds вызывается функция VisitCheckBounds. Эта функция отвечает за проверку того, что минимальный диапазон индекса равен или больше нуля, и что его максимальный диапазон не превышает длины массива. Если проверка истинна, тогда он вызывает DeferReplacement, помечающий узел для удаления.Пример функции
VisitCheckBounds до усиливающего защиту коммита 7bb6dc0e06fa158df508bc8997f0fce4e33512a5 показан ниже. void VisitCheckBounds(Node* node, SimplifiedLowering* lowering) {
CheckParameters const& p = CheckParametersOf(node->op());
Type const index_type = TypeOf(node->InputAt(0));
Type const length_type = TypeOf(node->InputAt(1));
if (length_type.Is(Type::Unsigned31())) {
if (index_type.Is(Type::Integral32OrMinusZero())) {
// Отображение -0 на 0, а значений в диапазоне [-2^31,-1] на
// диапазон [2^31,2^32-1], что тоже будет считаться out-of-bounds,
// потому что {length_type} ограничен Unsigned31.
VisitBinop(node, UseInfo::TruncatingWord32(),
MachineRepresentation::kWord32);
if (lower()) {
if (lowering->poisoning_level_ ==
PoisoningMitigationLevel::kDontPoison &&
(index_type.IsNone() || length_type.IsNone() ||
(index_type.Min() >= 0.0 &&
index_type.Max() < length_type.Min()))) {
// Проверка границ избыточна, если мы уже знаем, что
// индекс находится в границах [0.0, length[. (Имеется в виду полуоткрытый конец диапазона, который российские разработчки чаще обозначают круглой скобкой прим. переводчика.)
DeferReplacement(node, node->InputAt(0)); // <= Удаляет узлы
} else {
NodeProperties::ChangeOp(
node, simplified()->CheckedUint32Bounds(p.feedback()));
}
}
...
}Как видите, диапазон
CheckBound состоит из конструктора if, где Range(1,2).Min() >= 0 и Range(1,2).Max() < 3. В этом случае узел 46 из приведённого выше графа окажется избыточным и будет удалён.Если вы посмотрите на обновлённый код после коммита, то увидите небольшое изменение. Вызов
DeferReplacement был удалён, и вместо него мы заменяем узел узлом CheckedUint32Bounds. Если эта проверка завершается неудачно, TurboFan вызывает kAbortOnOutOfBounds, который прерывает проверку границ и аварийно завершает выполнение вместо деоптимизации.Новый код показан ниже:
void VisitCheckBounds(Node* node, SimplifiedLowering* lowering) {
CheckBoundsParameters const& p = CheckBoundsParametersOf(node->op());
FeedbackSource const& feedback = p.check_parameters().feedback();
Type const index_type = TypeOf(node->InputAt(0));
Type const length_type = TypeOf(node->InputAt(1));
// Преобразования при их необходимости будут обрабатываться
// representation changer, а не более низкоуровневыми операторами Checked*Bounds.
CheckBoundsFlags new_flags =
p.flags().without(CheckBoundsFlag::kConvertStringAndMinusZero);
if (length_type.Is(Type::Unsigned31())) {
if (index_type.Is(Type::Integral32()) ||
(index_type.Is(Type::Integral32OrMinusZero()) &&
p.flags() & CheckBoundsFlag::kConvertStringAndMinusZero)) {
// Отображение значений в диапазоне [-2^31,-1] на диапазон [2^31,2^32-1],
// что тоже будет считаться out-of-bounds, поскольку {length_type}
// ограничен Unsigned31. Также это преобразует -0 в 0.
VisitBinop<T>(node, UseInfo::TruncatingWord32(),
MachineRepresentation::kWord32);
if (lower<T>()) {
if (index_type.IsNone() || length_type.IsNone() ||
(index_type.Min() >= 0.0 &&
index_type.Max() < length_type.Min())) {
// Проверка границ избыточна, если мы уже знаем, что
// индекс находится в границах [0.0, length[.
// TODO(neis): переместить это в TypedOptimization?
new_flags |= CheckBoundsFlag::kAbortOnOutOfBounds; // <= Аварийное завершение и вылет
}
ChangeOp(node,
simplified()->CheckedUint32Bounds(feedback, new_flags)); // <= Замена узла
}
...
}Если взглянуть на часть графа, выполняющую упрощённое опускание, мы и в самом деле увидим, что узел
CheckBounds теперь был заменён узлом CheckedUint32Bounds, как и написано в коде, а значения всех остальных узлов «понижены» до описания в машинном коде.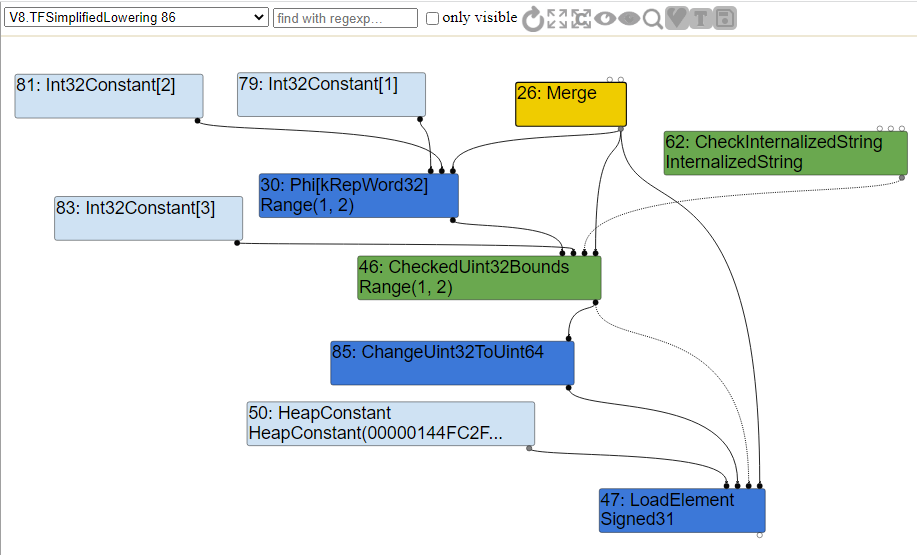
Устранение избыточности
Ещё один популярный класс оптимизаций, схожий с BCE, называется redundancy elimination (устранением избыточности). Его код расположен внутри
v8/src/compiler/redundancy-elimination.cc, он отвечает за устранение избыточных проверок типов. По сути, класс RedundancyElimination — это преобразователь графа, пытающийся удалить или скомбинировать избыточные проверки в цепочке эффектов.Цепочка эффектов — это, практически, порядок операций между рёбрами эффектов для функций загрузки и сохранения. Например, если мы попытаемся загрузить свойство из объекта и выполнить прибавление к нему вида
obj[x] = obj[x] + 1, то цепочка эффектов будет выглядеть так: JSLoadNamed => SpeculativeSafeIntegerAdd => JSStoreNamed. TurboFan должен гарантировать, что порядок внешнего влияния этих узлов не будет изменён, в противном случае могут использоваться неправильные предохранители.Преобразователь-уменьшитель, как описано в
v8/src/compiler/graph-reducer.h, пытается упростить отдельный узел на основании его оператора и входящих данных. Существует несколько типов преобразователей, например, свёртывание констант, в котором при сложении двух констант мы свёртываем их в одну, например, 3 + 5 станет одним узлом константы со значением 8, и упрощение выражения, в котором при сложении с узлом без эффектов мы оставляем один узел, например, при x + 0 у нас останется только узел x.Мы можем трассировать подобные типы редуцирования при помощи флага
--trace_turbo_reduction. Если запустить описанную выше функцию hot_function с этим флагом, то мы получим следующий результат.C:\dev\v8\v8\out\x64.debug>d8 --trace_turbo_reduction hot_function.js
- Replacement of #12: Parameter[-1, debug name: %closure](0) with #41: HeapConstant[0x00c800259781 <JSFunction hot_function (sfi = 000000C800259679)>] by reducer JSContextSpecialization
- Replacement of #34: JSLoadProperty[sloppy, FeedbackSource(#2)](14, 30, 5, 4, 35, 31, 26) with #47: LoadElement[tagged base, 8, Signed31, kRepTaggedSigned|kTypeInt32, FullWriteBarrier](44, 46, 46, 26) by reducer JSNativeContextSpecialization
- Replacement of #42: Checkpoint(33, 31, 26) with #31: Checkpoint(33, 21, 26) by reducer CheckpointElimination
- In-place update of #36: NumberConstant[0] by reducer Typer
... вырезано ...
- In-place update of #26: Merge(24, 27) by reducer BranchElimination
- In-place update of #43: CheckMaps[None, 0x00c80024dcb9 <Map[16](PACKED_SMI_ELEMENTS)>, FeedbackSource(INVALID)](61, 62, 26) by reducer RedundancyElimination
- Replacement of #43: CheckMaps[None, 0x00c80024dcb9 <Map[16](PACKED_SMI_ELEMENTS)>, FeedbackSource(INVALID)](61, 62, 26) with #62: CheckInternalizedString(2, 18, 8) by reducer LoadElimination
- In-place update of #44: LoadField[JSObjectElements, tagged base, 8, Internal, kRepTaggedPointer|kTypeAny, PointerWriteBarrier, mutable](61, 62, 26) by reducer RedundancyElimination
- Replacement of #44: LoadField[JSObjectElements, tagged base, 8, Internal, kRepTaggedPointer|kTypeAny, PointerWriteBarrier, mutable](61, 62, 26) with #50: HeapConstant[0x00c800259811 <FixedArray[3]>] by reducer LoadElimination
- In-place update of #45: LoadField[JSArrayLength, tagged base, 12, Range(0, 134217725), kRepTaggedSigned|kTypeInt32, NoWriteBarrier, mutable](61, 62, 26) by reducer RedundancyElimination
- Replacement of #45: LoadField[JSArrayLength, tagged base, 12, Range(0, 134217725), kRepTaggedSigned|kTypeInt32, NoWriteBarrier, mutable](61, 62, 26) with #59: NumberConstant[3] by reducer LoadElimination
... вырезано ...Этот флаг создаёт много интересного вывода; как видите, исполняется множество разных преобразователей и удалений. Мы вкратце расскажем о некоторых из них ниже, но я хочу, чтобы вы внимательнее посмотрели на некоторые из этих редукций.
Например, на эту:
In-place update of #43: CheckMaps[None, 0x00c80024dcb9 <Map[16](PACKED_SMI_ELEMENTS)>, FeedbackSource(INVALID)](61, 62, 26) by reducer RedundancyEliminationДа, всё верно —
CheckMaps была обновлена, а затем удалена из-за преобразователя RedundancyElimination. Это произошло потому, что устранение избыточности выявило, что вызов CheckMaps был избыточной проверкой, и удалило все проверки по тому же пути потока управления, кроме самой первой.Наверно, кто-то из вас может подумать: «Разве это не уязвимость безопасности?» На этот вопрос можно ответить «возможно» и «когда как».
Прежде чем я начну объяснять это чуть подробнее, давайте рассмотрим следующий пример кода:
function hot_function(obj) {
return obj.a + obj.b;
}Как видите, этот код довольно прост. Он получает один объект и возвращает сумму значений из свойства
a и свойства b. Если взглянуть на граф оптимизации Typer, мы увидим следующее.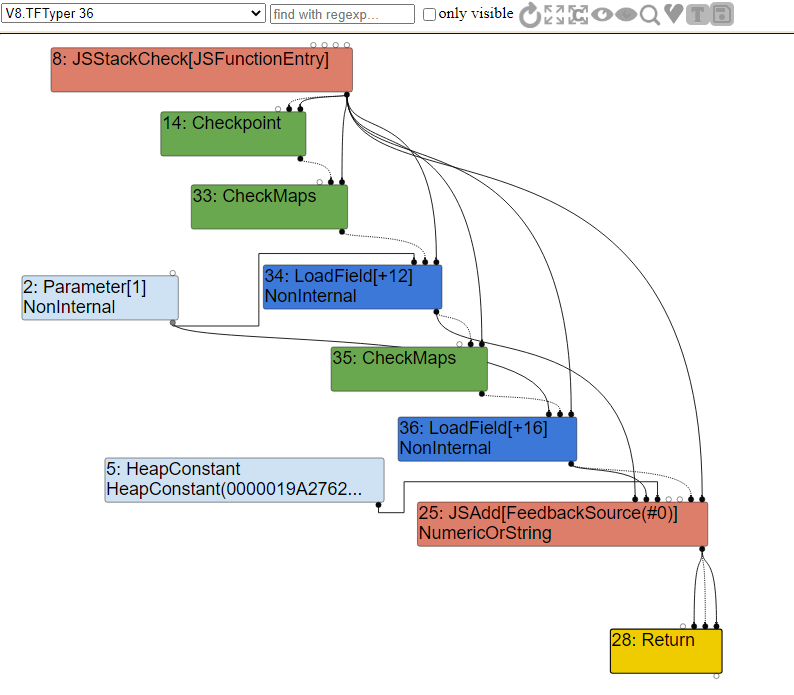
Как видите, при входе в функцию мы сначала вызываем
CheckMaps, чтобы проверить, что map передаваемого объекта имеет свойства a и b. Если эта проверка проходит, мы вызываем LoadField для загрузки в смещение 12 от константы Parameter, то есть свойства a переданного объекта obj.Сразу после этого мы выполняем ещё один вызов
CheckMaps для повторной валидации map, а затем загружаем свойство b. Завершив с этим, мы вызываем функцию JSAdd для сложения чисел, строк или того и другого.Проблема здесь в избыточном вызове
CheckMaps, поскольку, как мы знаем, map этого передаваемого объекта не может измениться между двумя операциями CheckMap. В этом случае она будет удалена.Мы можем увидеть это удаление избыточности в фазе упрощённого опускания графа.
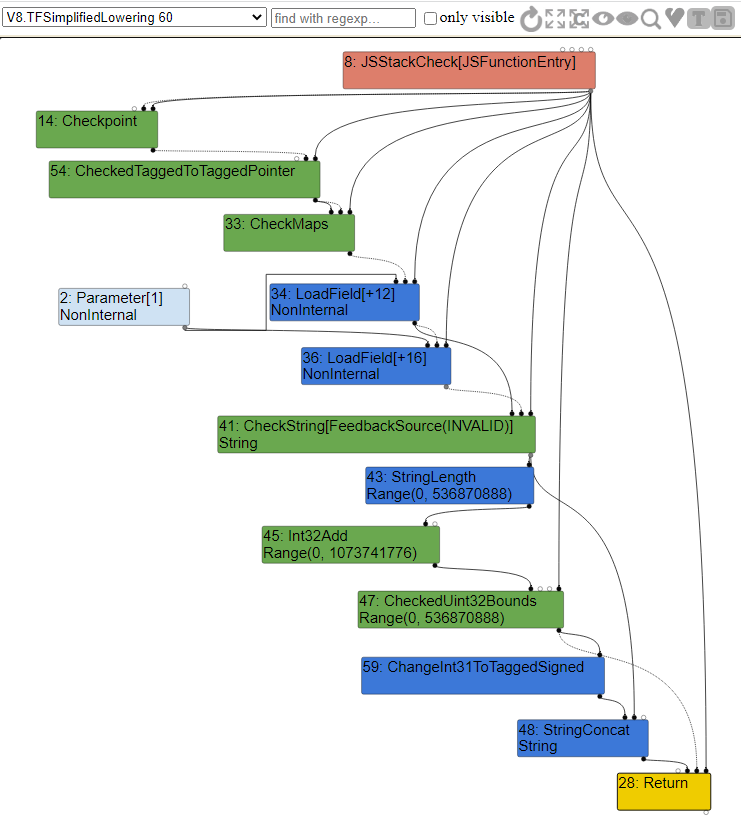
Как мы чётко видим, второй узел
CheckMaps был удалён и после первой проверки мы просто загружаем оба свойства одно за другим, что, по сути, ускоряет наш код. Кроме того, из-за упрощённого опускания вызов JSAdd был понижен до варианта в машинном коде для валидации выражений с integer и string согласно стандарту ECMAScript.Вернёмся к вопросу о том, является ли это уязвимостью безопасности. Как и говорилось, «когда как». Причина в том, что конкретная операция может вызвать побочные эффекты для наблюдаемого исполнения в нашем контексте, именно поэтому у нас есть цепочки побочных эффектов. Если TurboFan по какой-то причине забудет учесть побочный эффект и не запишет его в цепочку побочных эффектов, то появится возможность изменения Map объекта во время исполнения, например, другая пользовательская функция сможет изменить объект или добавить свойство.
Каждая операция промежуточного представления в V8 имеет соответствующие флаги. Пример некоторых из флагов для операторов JavaScript можно увидеть в
v8/src/compiler/js-operator.cc. С частью этих флагов связаны определённые допущения.Например,
V(ToString, Operator::kNoProperties, 1, 1) предполагает, что String не должен иметь свойств. Другой, например, V(LoadMessage, Operator::kNoThrow | Operator::kNoWrite, 0, 1), предполагает, что операция LoadMessage не будет иметь наблюдаемых побочных эффектов с флагом kNoWrite. Этот флаг kNoWrite не выполняет запись в цепочку эффектов.Как видите, если мы заставим компилятор удалить избыточную проверку для операции, которая считает, что побочные эффекты отсутствуют, то у нас возникнет потенциально подверженный эксплойтингу баг, если мы сможем модифицировать объект или свойство в процессе исполнения скомпилированного кода.
Эту тему устранения избыточности и побочных эффектов можно расширить и до обсуждения того, как баги, возникающие из-за этих проверок удаления, могут привести к уязвимостям с возможностью эксплойтинга. Но прежде чем это сделать, давайте вкратце рассмотрим ещё некоторые другие стандартные оптимизации.
Другие оптимизации
Как мы видели ранее из результатов выполнения с флагом,
--trace_turbo_reduction, в TurboFan происходит гораздо больше оптимизаций, чем мы рассмотрели. Я попытался раскрыть самые важные из них, связаные с багом, который мы будем эксплойтить в третьей части статьи, но всё равно хочу вкратце рассмотреть некоторые другие оптимизации, чтобы вы имели хотя бы общее представление об их наличии.Вот некоторые из прочих стандартных оптимизаций, которые можно встретить в TurboFan:
-
Оптимизация управления: как описано в
v8/src/compiler/control-flow-optimizer.cc, в общем случае эта оптимизация оптимизирует поток графа и превращает некоторые цепочки ветвления в switch. -
Анализ псевдонимов и глобальное перечисление значений: анализ псевдонимов (Alias analysis) выявляет зависимости между узлами
StoreиLoad. Если две операции загрузки зависят от одной, они не могут быть выполнены, пока не завершится первая операция, например,x = 2; y = x + 2; z = x + 2. GVN, или Global Value Numbering (глобальное перечисление значений) соответствует своему названию и удаляет избыточные операцииStoreиLoad, например,z = x + 2можно удалить, аzможно присвоить значениеy, поскольку операция избыточна. -
Dead Code Elimination (DCE): Dead Code Elimination (устранение мёртвого кода) выполняет именно то, что следует из названия. Оно просто обходит все узлы и удаляет код, который не будет исполняться. Например, если
xиyдля конструкции с True/False всегда будут являться true, то путь false будет считаться «мёртвым» и подлежит удалению.
Если вы хотите больше узнать о различных оптимизациях и море узлов, рекомендую прочитать TurboFan JIT Design и Introduction to TurboFan.
Распространённые уязвимости компилятора JIT
Разобравшись с полным конвейером V8 и оптимизациями компилятора, мы можем приступить к изучению классов уязвимостей, которые существуют в браузерах. Как мы знаем, движок JavaScript и все его компоненты наподобие компилятора реализованы на C++.
В этом случае конвейер в первую очередь уязвим к распространённым нарушениям безопасности памяти и типов, например, к целочисленным отрицательным и положительным переполнениям, ошибкам завышения или занижения на единицу, считыванию и записи за пределами допустимого пространства, переполнениям буфера, переполнениям кучи и, разумеется, к багам use-after-free.
В дополнение к обычным багам C++ также могут существовать баги логики и баги генерации машинного кода, которые могут возникать в фазе оптимизации из-за самой природы спекулятивных допущений. Такие баги логики могут возникать из-за неверного допущения потенциальных побочных эффектов, которые могут существовать у операции над объектом или свойством, или из-за неправильных проходов оптимизации, удаляющих критически важные предохранители типов.
Подобные типы проблем в целом называются уязвимостями «type confusion», при них компилятор не проверяет тип или shape переданного ему объекта, из-за чего компилятор слепо использует объект. Так было в случае уязвимости CVE-2018-17463, которую мы попробуем проанализировать и подвергнуть эксплойтингу в третьей части этой серии статей.
Дойдя до этого места, я подумывал провести анализ нескольких багов и продемонстрировать вам примеры уязвимого кода. В конечном итоге, я решил этого не делать. Почему? Мне кажется, у вас уже должно иметься достаточно хорошее понимание внутренностей браузера и V8, чтобы самостоятельно изучить код Chromium и понять отдельные баг-репорты.
Поэтому я выдам вам домашнее задание. Ниже представлен список видео и баг-репортов, связанных с эксплойтингом браузеров. Уделите время прочтению некоторых из этих отчётов, разберитесь, как возникли эти баги, и как появилась возможность их эксплойтинга.
Стоит заметить, что часть этих багов возникла в других движках JavaScript, однако они представляют собой модель возможных уязвимостей, которые могут возникнуть во всех движках JavaScript.
Рекомендую прочитать следующее:
- 35C3 — From Zero to Zero Day: ChakraCore Type Confusion due to Invalid Side-Effects
- Browser Security Beyond Sandboxing — CVE-2017-5121
- Chrome TurboFan Remote Code Execution via Type Confusion
- CVE-2015-0817 — Incorrect asm.js Bounds Checking Elimination
- CVE-2016-1669 — Use After Free in RegExp
- CVE-2016-1677 — Type Confusion Leads to Info Leak in decodeURI
- CVE-2016-5129 — V8 Out of Bound Read in GC with Array Object
- CVE-2017-2547 — WebKit: Invalid Bounds Check leads to OOB Access
- CVE-2017-5040 — Information Leak in Array indexOf
- CVE-2018-0758 — Chakra: JIT: Missing Integer Overflow Check
- CVE-2018-0769 — Chakra JIT: Incorrect Bounds Calculation
- CVE-2018-4192 — Race Condition in Garbage Collection for array.reverse()
- CVE-2018-6065 — V8 Integer Overflow in Object Allocation Size
- CVE-2018-6106 — V8 AwaitedPromise Incorrect State
- CVE-2018-6136 — Crash with JavaScript RegExp Subclassing
- CVE-2018-6142 — Information Leak in Map Constructor
- CVE-2019-5782 — Improper Side-Effect in Lowering Leads to OOB via Check Bounds Elimination
- CVE-2019-13764 — Invalid NaN Type Check via Typer Optimizer
- CVE-2021-21220 — Improper JIT OpCode Leads to RCE
- Exploiting Chrome V8: Krautflare (35C3 CTF 2018)
- Exploiting TurboFan Through Bound Check Elimination
- Issue: 762847 — Off By One in Range Optimization of String.indexOf
- Patch Gapping Chrome — Properties Backing Store Type Confusion
- JavaScript Vulnerability Database
- ZDI Advisories Page
В заключении
Надеюсь, основная часть материаладля вас понятна. Если это не так, то вернитесь к первой части, уделите время её прочтению и изучите все ссылки, которые позволят вам разобраться в непонятных концепциях.
Честно говоря, больше всего учиться мне помогли чтение и отладка кода V8. Это даёт гораздо большее понимание того, что происходит внутри движка, что и когда вызывается. Также это помогает лучше ознакомиться с кодом, если вы хотите проанализировать его на баги.
Из всей представленной в посте информации самой важной для следующего поста будет часть про оптимизацию. В третьей части этой серии статей мы воспользуемся всеми полученными знаниями для анализа и понимания CVE-2018-17463. Затем мы перейдём к пониманию основ примитивов эксплойтинга браузеров, а далее реализуем эксплойт бага, чтобы получить удалённое исполнение кода в системе.
Спасибо за чтение, увидимся в следующем посте!
Благодарности
Хочу от всего сердца поблагодарить maxpl0it за техническую проверку этого поста, предоставление критически важных отзывов и добавление нескольких важных подробностей.
Также хочу поблагодарить Коннора Макгарра и V3ded за вычитку этого поста на точность и удобность прочтения.
Наконец, хочу упомянуть Джереми Фестиво за его потрясающую работу в сфере эксплойтинга Chrome и за написание таких подробных постов для Diary of a Reverse Engineer. Эти посты были крайне полезными для понимания многих нюансов в Chrome и V8.
Ссылки
- An Introduction to Speculative Optimization in V8
- Circumventing Chrome’s Hardening of Typer Bugs
- Compiler Design: Static Single Assignment
- Deoptimization in V8
- Digging into the TurboFan JIT
- Exploiting TurboFan Through Bounds Check Elimination
- Firing up the Ignition interpreter
- Franziska Hinkelmann: JavaScript engines — how do they even?
- Getting Around the Chromium Source Code Directory Structure
- How To Start JIT-ting
- Ignition and TurboFan Compiler Pipeline
- Ignition Design Docs
- Ignition: Register Equivalence Optimization
- Intro to Chrome’s V8 from an Exploit Development Angle
- Introduction to TurboFan
- JavaScript engine fundamentals: optimizing prototypes
- JavaScript Engine Fundamentals: Shapes and Inline Caches
- Modern attacks on the Chrome browser: optimizations and deoptimizations
- Sea of Nodes
- Sigurd Scheider: Inside V8: The choreography of Ignition and TurboFan
- Sparkplug Design Documentation
- The Chromium Super (Inline Cache) Type Confusion
- TurboFan IR
- TurboFan JIT Design
- Understanding V8’s Bytecode
- V8 and How It Listens To You — Michael Stanton
- V8 release v6.8
- V8: Hooking up the Ignition to the TurboFan
- What’s up with Monomorphism?
Комментарии (2)

eugenk
00.00.0000 00:00+1Потрясающе интересно ! Очень надеюсь, что серия будет продолжена. Обожаю такие вещи.
emaxx
Великолепная статья!