

Среди программистов не утихают споры о том, надо ли знать "алгосики" для реальной работы, или же это просто некий странный ритуал для прохождения воронки собеседований в компании а-ля FAANG (MANGA). У нас в Каруне в разных командах есть разные мнения на этот счёт. Я, например, как тимлид Go-команды считаю, что некую элементарную базу знать точно бы не помешало, но всё же главное, чтоб человек был хороший.
Мнения могут различаться, но одно я знаю точно: разгадывать загадки бывает очень интересно. Я как-то из любопытства прорешивал задачки на hackerrank, и, если для решения простых задач тупо достаточно догадаться отсортировать данные или построить map (даже не надо ничего особо знать), то для некоторых придумать решение довольно проблематично.
Одна из таких задач — нахождение самой длинной общей подпоследовательности (longest common subsequence). Подобный алгоритм используется в реальной жизни, в таких программах как diff. Скажу сразу: я не смог решить задачу самостоятельно за разумное время (т.е. пока не надоело решать) и посмотрел алгоритм в Википедии.
Но бог с ним с алгоритмом, мне стало жутко интересно, как же, блин, я должен был рассуждать, чтобы самому прийти к этому решению. В итоге эти рассуждения я решил выложить в виде статьи на Хабр.
Disclaimer: я точно не олимпиадник и не гуру алгоритмов, просто любопытствующий.
Задача
На hackerrank задача звучала как-то так:
Общий ребёнок.
Строка называется ребёнком другой строки, если она может быть сформирована путём удаления 0 или более символов из этой строки. Символы не могут быть перемешаны.
Даны две строки одинаковой длины. Найти длину наибольшей строки, которая может быть сконструирована так, что она является "ребёнком" обеих строк.
Например, для строк BCDEKF и CDEGKB наибольшим общим ребёнком будет CDEK, т.е. 4 общих символа без изменения их порядка.
Короче, надо написать тело для такой функции
// надо найти только длину
func commonChild(s1 string, s2 string) int {
}Если описывать менее формально, то это похоже на результат просмотра diff двух файлов. Файл — это последовательность элементов (например, строк кода), и diff ищет как можно больше одинаковых элементов (наибольшую общую подпоследовательность), а уже остальное показывает как различие.
Попытка в лоб
В книжках и статьях про подготовку к собеседованиям часто советуют задачу для начала попытаться решить в лоб. Чтобы выдавала правильный ответ хотя бы для небольших входных данных, а потом уже пытаться оптимизировать скорость. Вроде как это должно показать интервьюеру, что вы вообще понимаете задание и умеете хотя бы базово программировать.
Вот тупейшее решение в лоб: сначала найти начало общего ребёнка (точнее — перебрать все варианты, где может быть это начало), а потом, начиная с этой точки, свести задачу к предыдущей. Т.е. рекурсия. Тут надо отметить, что стек в Go динамический, поэтому слишком большой вложенности рекурсий обычно можно не бояться, на других языках это могло выглядеть сложнее.
func commonChild(s1 string, s2 string) int {
var maxLen int
for i := 0; i < len(s1); i++ {
for j := 0; j < len(s2); j++ {
if s1[i] == s2[j] {
next := commonChild(s1[i+1:], s2[j+1:])
l := 1 + next
if l > maxLen {
maxLen = l
}
}
}
}
return maxLen
}Решение простое, работает правильно на небольших примерах, но уже на жалких нескольких десятках символов наглухо зависает — алгоритм неоптимален (что неудивительно). Если я правильно понимаю, тут О(2^n).
Кстати, я спросил у ChatGPT, какая здесь алгоритмическая сложность, и он не моргнув глазом с умным видом сказал, что O(n^2), потому что здесь — цикл в цикле. В общем, робот не заметил рекурсию.
Пробуем оптимизировать
Если порешать какое-то количество задачек на Хакерранке, то понимаешь, что часто эта проблема решается, если где-то хранить промежуточные вычисления, т.е., грубо говоря, использовать некий кэш. Это не рокет сайенс: даже если вы всю жизнь пилите круды на PHP, вы точно хотя бы пару раз что-нибудь да кешировали для скорости. Это, кстати, главный принцип динамического программирования — решить подзадачу один раз, запомнить промежуточный результат, а потом много раз его использовать без лишних вычислений.
В итоге можно прийти к такому решению:
// здесь в качестве ключа кеша используется структура, в которой хранятся длины оставшихся строк, т.е. по сути позиция.
type Key struct {
len1 int
len2 int
}
var cache = map[Key]int{}
func commonChild(s1 string, s2 string) int {
key := Key{len1: len(s1), len2: len(s2)}
cached, exists := cache[key]
if exists {
return cached
}
var maxLen int
for i := 0; i < len(s1); i++ {
for j := 0; j < len(s2); j++ {
if s1[i] == s2[j] {
next := commonChild(s1[i+1:], s2[j+1:])
l := 1 + next
if l > maxLen {
maxLen = l
}
}
}
}
cache[key] = maxLen
return maxLen
}
Это решение работает побыстрее, но с какой-то длины всё равно зависает нафиг. Т.е. кешировать надо как-то поумнее. Но как?
Визуализация
В умных книжках говорят, что удачная визуализация — это половина решения. Но как это визуализируешь, сравнение каждого символа с каждым? Когда я сам искал решение, я пробовал рисовать две последовательности рядом и соединять их миллионом стрелочек, но это ни к чему не привело.
На самом деле мне особенно обидно, что правильный вариант не пришёл в голову в процессе решения, потому что несколько лет назад я сам писал на Хабр про визуализацию SQL-джойнов (часть 1, часть 2). И во второй части как раз рисовал объединение всех элементов со всеми в виде прямоугольника (матрицы).
В общем, если нужно сравнить все со всеми — рисуй матрицу. Например, для строк BCDEKF и CDEGKB рисуем правильный ответ, т.е. наибольшую последовательность. В этом простом случае она очевидна:
| B | C | D | E | K | F |
--|---|---|---|---|---|---|
C | | 1 | | | | |
--|---|---|---|---|---|---|
D | | | 2 | | | |
--|---|---|---|---|---|---|
E | | | | 3 | | |
--|---|---|---|---|---|---|
G | | | | | | |
--|---|---|---|---|---|---|
K | | | | | 4 | |
--|---|---|---|---|---|---|
B | | | | | | |
---------------------------Также полезно нарисовать какие-нибудь не такие прямолинейные случаи, например, строки EFABCD и ABCDEF. Тут две общие подпоследовательности: EF (пометил звёздочкой) и ABCD, вторая больше
| E | F | A | B | C | D |
--|---|---|---|---|---|---|
A | | | 1 | | | |
--|---|---|---|---|---|---|
B | | | | 2 | | |
--|---|---|---|---|---|---|
C | | | | | 3 | |
--|---|---|---|---|---|---|
D | | | | | | 4 |
--|---|---|---|---|---|---|
E | 1*| | | | | |
--|---|---|---|---|---|---|
F | | 2*| | | | |
---------------------------По этим двум картинкам уже в принципе видно, что последовательность увеличивается всегда смещением на одну (или более) клетку вправо и на одну (или более) вниз. Что, если подумать, и так понятно, но с картинкой намного нагляднее.
Ладно, это тоже простой пример, еще нужен случай с повторяющимися буквами.
BAABA и BABAB
Этот пример хорош тем, что для таких коротких строк есть прям очень много комбинаций, да и подпоследовательностей максимальной длины может быть несколько, не только BABA (ответ, который первым приходит в голову), но ещё и BAAB, например.
| B | A | A | B | A |
--|---|---|---|---|---|
B | * | | | * | |
--|---|---|---|---|---|
A | | * | * | | * |
--|---|---|---|---|---|
B | * | | | * | |
--|---|---|---|---|---|
A | | * | * | | * |
--|---|---|---|---|---|
B | * | | | * | |
-----------------------Я отметил звёздочками совпадения букв, и уже видно, в принципе, что, если учитывать, что последовательности строятся с обязательным смещением вправо и вниз, то наша BABA видна практически невооруженным глазом. Видны и другие, более мелкие: B, BA, BAB и тд., которые мы отбрасываем.
Вместо звёздочек можно писать некое число, которое увеличивается по диагонали, и по самому большому числу мы в итоге найдём и самую большую подпоследовательность.
Но есть нюанс: разумеется, не всегда последовательность идёт строго по диагонали (на одну клетку вправо и одну вниз). Бывает, смещается больше, проходит через пустоту (т.е. через несовпадающие символы). Сами эти несовпадающие символы не меняют длину общей подпоследовательности, но путь проходит через них. Поэтому для каждой пустой клетки можно тоже записать число и стрелочку, которая будет указывать на наиболее выгодный путь (на максимальное из чисел сверху или слева).
В итоге мы можем прийти к классической картинке (взято из Википедии)
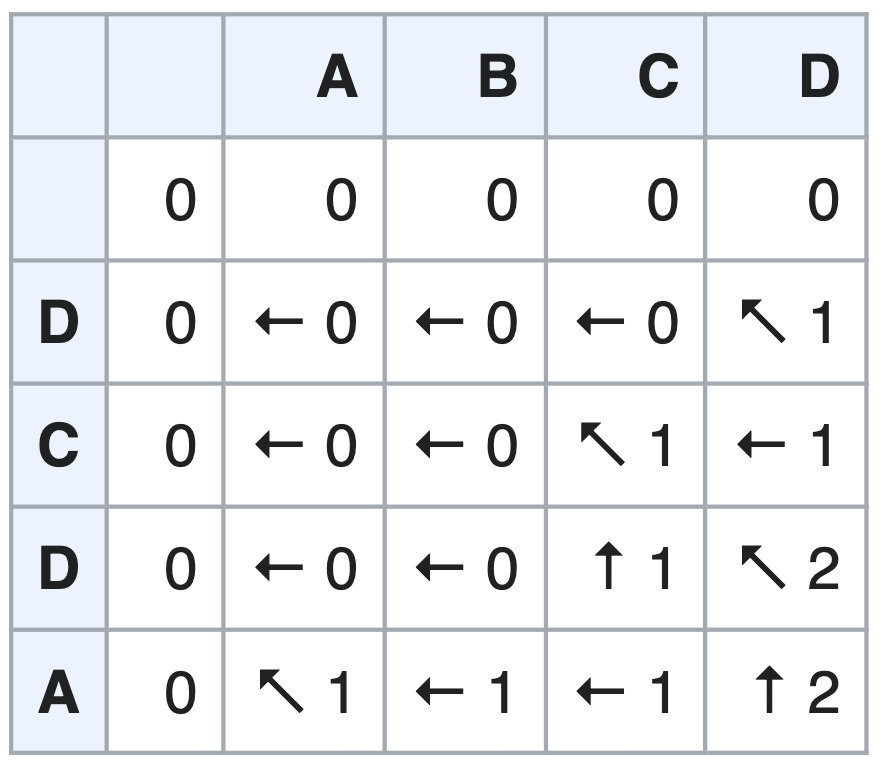
и алгоритму:
Таблица заполняется построчно, начиная с левого верхнего угла D-A. Заполняется так: если символы совпадают (например C-C, D-D, A-A), то берётся число из предыдущего элемента по диагонали (ближайшая клетка слева сверху), с прибавлением единицы. Если не совпадают, то просто копируется максимальное число из двух вариантов: соседней левой клетки или соседней верхней. Стрелочка на рисунке указывает на то поле, откуда именно бралось значение.
В результате в правом нижнем углу будет ответ: максимальная длина общего ребёнка. А по стрелочкам можно пойти до начала и восстановить и саму
подпоследовательность, не только длину (выписывая совпадающие символы).
func commonChild(s1 string, s2 string) int {
N := len(s1)
matrix := make([][]int, N+1)
for i := range matrix {
matrix[i] = make([]int, N+1)
}
for i := 0; i < N; i++ {
for j := 0; j < N; j++ {
if s1[i] == s2[j] {
matrix[i+1][j+1] = matrix[i][j] + 1
} else {
max := matrix[i][j+1]
if matrix[i+1][j] > max {
max = matrix[i+1][j]
}
matrix[i+1][j+1] = max
}
}
}
return matrix[N][N]
}В постановке задачи на hackerrank длины строк одинаковые, но разницы особой нет, можно легко переделать и на более общий случай.
Сложность такого алгоритма — очевидно O(N^2), потому что здесь нет ни рекурсии, ничего. Просто цикл в цикле.
Итог
Мне вполне было по силам решить эту задачу самостоятельно, ничего тут сложного нет, если бы я сразу нарисовал правильную картинку. Но как научиться догадываться до таких вещей, да ещё и с включенным таймером — для меня загадка.
Если посоветуете в комментах какую-нибудь хорошую статью или книжку, как нужно мыслить, чтобы легко придумывать решение для алгоритмических задач, буду очень признателен.
Комментарии (13)

Zara6502
05.04.2023 09:08-3алгосики - это язык ALGOL? И в чем потребность в статье использовать такой сленг? Вы книг много прочитали? В скольких из них авторы прибегали к уличному сленгу? Почему в написании статьи вы считаете что окружающим будет приятно читать неформальщину?

varanio Автор
05.04.2023 09:08+1Это прям очень токсично было.
Откуда ж такой снобизм? Почему я себя должен выдавать за наукообразного ... другого человека?
Я много книг читал, например, "Статистика и котики", "Гитара для чайников" и т.д. Есть серия книг "the complete idiots guide". Авторы этих книг умственно отсталые и не могут нормально что ли объяснить? Зачем все эти котики и idiots?
Так вот, дело в том, что когда автор использует много лишних терминов, чтобы казаться умнее, это очень сложно читать, читатель чувствует себя на изнурительной подготовке к скучному экзамену. Читатель чувствует себя глупым. Чем больше занудства, тем меньше хочется читать до конца. И наоборот - неформальное общение в условной курилке, с матом и приколами, может длиться очень долго, и всем норм. Потому что расслабленное общение продуктивно.
Лучше пусть читатель автора считает легкомысленным, чем себя глупым.
Есть, кстати, и книги на этот счет, где показано, что умничать на рабочих совещаниях - это самое плохое, что можно сделать.
Эта статья - это объяснение "на пальцах". Самый эффективный способ передачи информации.
Ну и последнее - есть люди, которым нравиться наукообразность, есть люди, которым нравится простое общение. Почему я должен подстраиваться именно под первую категорию? Мне это не интересно. Я, наоборот, в следующих статьях планирую вкладывать больше естественности речи.Zara6502
05.04.2023 09:08-1Это прям очень токсично было
Нет, скорее фактологично. Если вам не нравятся факты о себе, то вы не понимаете что делаете.
Откуда ж такой снобизм?
А причем тут манеры и высшее общество?
Почему я себя должен выдавать за наукообразного ... другого человека?
Статьи вы пишете не для себя, а для других. Это называется - целевая аудитория. И когда вы пишете, то мысли должны оформляться под ЦА. Ниже вы в полной мере обосновали вашу ЦА, это ни плохо ни хорошо, но имеет смысл в начале статьи писать - кому она посвящена, она исключит необходимость тарить время.
Я много книг читал, например, "Статистика и котики", "Гитара для чайников" и т.д. Есть серия книг "the complete idiots guide"
Я видел такие книги, но мыслей для их прочтения у меня не появлялось, объяснять почему?
Так вот, дело в том, что когда автор использует много лишних терминов, чтобы казаться умнее
Вы отталкиваетесь от ложной предпосылки. Использование терминов вообще и использование лишних терминов (что бы это не значило) это в любом случае разные вещи. Почему использование терминов - это "казаться умнее", мне неведомо.
это очень сложно читать
Почему? У меня только один ответ - вы не являетесь ЦА этой книги.
читатель чувствует себя на изнурительной подготовке к скучному экзамену
Ну это просто чушь. Вас кто-то заставляет читать? Мне кажется после окончания ВУЗа человек находится в свободном плавании и волен читать или НЕ читать. А использование слов и конструкций это не вопрос скуки или развлечения.
Читатель чувствует себя глупым
Если вы не понимаете предмета, то вы не понимаете предмета. Внезапно. Никакой другой информации из этого нельзя выделить. А кто там и что чувствует - это к психологам.
Чем больше занудства, тем меньше хочется читать до конца
Соглашусь, но вы эту предпосылку используете опять же заблуждаясь. Потому что я не призывал вас в статье занудствовать. У вас просто некорректно оформленная статья, которая не прошла бы редактуру, будь она тут.
И наоборот - неформальное общение в условной курилке, с матом и приколами, может длиться очень долго, и всем норм
Это вольное допущение не имеющее под собой доказательств. Мат и приколы должны быть к месту, если человек просто матерится, то он имбецил, если ржёт как конь - то тем более. Пардон, но ничего приятного в такой компании не нахожу. Поэтому про "всем" вы переборщили, тут опять же возвращаемся к ЦА.
Лучше пусть читатель автора считает легкомысленным, чем себя глупым
Если человек не видит причин для совершенствования то он перестает развиваться. Поэтому если я и читаю статью, то только ради того чтобы узнать новое, а не как пёрнуть в курилке или выматериться, я это умел в 5 лет.
Если я прочитал и понял только 10% то я принимаю решение или игнорировать эту тему, так как она для меня не важна или сложна или буду расширять поиск и закрывать пробелы. По-другому это работать не может.
Есть, кстати, и книги на этот счет, где показано, что умничать на рабочих совещаниях - это самое плохое, что можно сделать
У вас терминология школьника. Что значит "умничать на совещаниях"? Если я вместо алгосики говорю алгоритмы - я умничаю? А вам не кажется что на совещании присутствуют люди из разных отделов и это люди, ВНИМАНИЕ, разных профессий. И вы должны свой материал изложить (возвращаюсь к началу своего ответа) так, чтобы поняли они, а не чтобы вам было весело.
Я прекрасно осведомлен о разных способах управления коллективом, в том числе в неформальном ключе, но это всегда завязано на закрытый коллектив в узкой проблематике. Ну не будет ни один лид звонить по скайпу артисту и говорить на сленге, из которого он ничего не поймет. НЕ БУДЕТ. А все кто это делают (рукалицо и примеров таких достаточно), те просто глупые люди.
Эта статья - это объяснение "на пальцах". Самый эффективный способ передачи информации
Вот вы так не любите терминологию, а сами не понимаете, что моя претензия к вам именно о ней. Вы в статье использовали слова, которые трансформировать в русский сможет не каждый. И вы либо должны указать в начале статьи для кого она, либо вводить термины в обиход в рамках статьи. Вы ведь не знаете кто именно её будет читать.
И если уж вам нравится концепция "трёп в курилке", то моя претензия легко описывается в вашей же парадигме таким диалогом:
Вы: привет народ, толкну речь про алгосики...
Я: про что?
Вы: ну алгосики. Алгоритмы.
Я: Ааааа, алгосики.
Ну и последнее - есть люди, которым нравиться наукообразность, есть люди, которым нравится простое общение
Опять к терминам. Вы точно понимаете значение слова "наукообразный". Просто если судить по контексту, вы не правильно понимаете его значение.
Ну и я совсем не против простого общения, если автор делает это хорошо. Я смотрю много видео на английском и там в среде программистов вполне себе присутствует простое общение, но ребята не придумывают слова на ходу, что даже я, иностранец для них, понимаю их речь и она мало отличается от книжек на английском, включая книги 80-х (которые я читаю чаще).
Почему я должен подстраиваться именно под первую категорию?
Хм. У вас странный взгляд на вещи. Смотрите. Вы пишете статью, в вашей голове сидит идея - неформальный стиль для неформальной аудитории. Об этом вы никому не сообщаете (зачем? XD). Публикуете. А потом недовольны тем, что вам на это указывают? Как мы должны были догадаться, что вас устраивает только одна категория читателей? (какая именно кстати? я могу придумать 10 категорий) И мы опять возвращаемся к качеству вашей статьи, откуда вы семимильными шарами уводите наш разговор.
Я, наоборот, в следующих статьях планирую вкладывать больше естественности речи
Ну так вы об этом и скажите вашим потенциальным читателям. В чем проблема-то? Я прочитал бы эпиграф и закрыл вкладку - все довольны.
---
Касательно стиля речи - у человека он не зависит от желания казаться умнее. Верю что такая форма мимикрии существует, но это весьма крутой навык, так как всё что доводилось слышать мне (в том числе в научной среде) сразу заметно и выдает человека. А вот не понимать вещей и говорить умно и связно, это весьма круто. В целом всё завязано на словарный запас и зрительную память. Простые люди говорят короткими фразами и это не признак глупости, просто у них нет навыка построения длинных предложений.Но вы почему-то такой навык записали в какие-то уничижительные конструкции. Ну не нравится вам такое - да ради бога, никто не заставляет, вы статью правильно только оформите.
varanio Автор
05.04.2023 09:08Ну это просто чушь. Вас кто-то заставляет читать?
А вас кто-то заставляет читать эту статью? Ну поставьте минус, и читайте другие статьи, не пойму в чем проблема вообще. Я пишу так, как пишу, по-другому не буду.
Zara6502
05.04.2023 09:08+1Я так и сделал, не смог прочесть. Я вам, как автору, обозначил проблему, что с ней делать - вы решите сами, но вы решили меня ткнуть носом в придуманную вами же какую-то наукообразность (чтобы это не значило в вашем понимании).
А какой смысл в минусе без его описания? Тем более моему аккаунту расставлять минусы и плюсы недоступно.
Проблема в вас, вы не умеете общаться, не воспринимаете критику.
Пишите как хотите, вас вообще никто не отговаривает.

thevlad
05.04.2023 09:08+1Догадываться сложно, над многими нетривиальными проблемами годами работали не самые глупые люди из академической и коммерческой(R&D) науки с начала 60х. Тот же алгоритм из вашей статьи первая публикация(с эффективным алгоритмом). "James W. Hunt and Thomas G. Szymanski. A fast algorithm for computing longest subsequences. Commun. ACM, 20(5):350–353, 1977".
Но по моему опыту, практически все алгоритмы уже придуманы, надо только уметь правильно абстрагировать прикладную задачу в "математику" и иметь кругозор с некоторым базовым пониманием.
Zara6502
05.04.2023 09:08От себя дополню ваш последний абзац - знание алгоритма вторично, умный и образованный человек с хорошей математической базой сам "изобретёт" алгоритм. А вот выучивший все алгоритмы и не умеющий хорошей базы не сможет ими пользоваться. Поэтому я и противник упора тестирования умений базовыми алгоритмами.

domix32
опыт подсказывает, что примерно никто без матобразования не умеет догадываться до эффективных решений с такими префиксами. Всякие radix sort из той же оперы.
gohrytt
реальность подсказывает что либо алгоритмы не нужны либо должен быть способ научится их решать быстрее чем за 4-6 лет жизни
Zara6502
этот способ давно найден, называется - библиотека, я уже в 80-е пользовался.
самостоятельно могу написать только сортировку пузырьком, больше не знаю ничего (когда-то знал, но успешно забыл за ненадобностью)
Вы помните то что учили в вузе или только то чем занимаетесь каждый день? Я со школы и вуза помню только "квадрат гипотенузы равен сумме квадратов катетов" и "как использовать дискриминант". Из языков программирования что я изучал за всю жизнь помню только C# на уровне Hello world, просто потому что я на нем писал немного года три назад. Все остальные языки не помню совершенно, кроме базовых конструкций. Когда-то даже прочитал книжку по питону и сделал кучу уроков, написал пару программ для себя, а потом понял, что питон сам по себе пустой, нужно пользоваться безумным количеством библиотек, с которыми еще нужно повозиться чтобы они начали работать. Поэтому просто вернулся на C#. Из питона помню только его название.