

Привет, Хабр!
Меня зовут Владислав Малеев, участник профессионального сообщества NTA.
Интеллектуальные системы призваны облегчать жизнь человека, выполняя за него рутинные задачи. Одной из таких задач является поиск информации в большом количестве текста. Возможно ли и эту задачу перенести на плечи интеллектуальных систем? Этим вопросом я решил задаться.
Содержание
С чего началось
Передо мной встала задача поиска в куче хозяйственных договоров ответа на интересующие нас вопросы. Если документов было бы несколько, то просмотреть их вручную не составило бы труда, но их количество доходило до сотни, в каждом из которых было по 50 или более страниц, при этом нужная информация могла быть только в одном.
И дело даже не в количестве затраченного времени — из‑за банальной усталости можно пропустить нужную информацию. Чтобы избежать подобных проблем решено было привлечь мощь машинного обучения, а именно вопросно‑ответных систем.
Такие системы позволяют по заданному пользователем вопросу на естественном языке дать на него ответ, основываясь на каком‑либо тексте. Частным примером такой системы является нашумевшая ChatGPT. Для текущей задачи настолько мощная система избыточна, поэтому я сделаю кое‑что попроще.
Более простые вопросно‑ответные системы не умеют обобщать ответ на вопрос, а, скорее, пытаются подобрать слова, наиболее подходящие по смыслу к вопросу. К примеру, такой текст:
Вчера выпало много снега, а сегодня из-за тёплой погоды он подтаял и заледенел. Придётся на выходных взять лом и немного разбить лёд. |
Если системе задать вопрос «Сколько в тексте запятых?», то она не сможет на него ответить, так как не «догадается» пересчитать их, а вот если спросить её: «Когда убирать лёд?», то она однозначно ответит: «на выходных», так как слово «лёд» встречается только в этом предложении и словосочетание «на выходных» относится ко времени.
Выбор модели
Модель для текущей задачи возьму уже обученную из библиотеки transformers. Данная библиотека даёт удобный интерфейс для загрузки, дообучения и использования более 20 000 предобученных моделей для обработки текста, изображений и аудио. Модели предоставляет сообщество по машинному обучению Hugging Face, а на их платформе организован удобный поиск подходящих моделей.
Также библиотека transformers поддерживает взаимодействие фреймворков PyTorch, TensorFlow и JAX, то есть можно на вход модели передать данные в одном фреймворке, а получить результаты в другом.
Чтобы выбрать подходящую для задачи модель выставляю на платформе Hugging Face соответствующие фильтры: тип модели — вопросно‑ответная, язык — русский. Под такие критерии попадают три модели, попробую их все:
Есть два способа, чтобы скачать и использовать модели. В первом все действия осуществляются через класс pipeline, что быстро и удобно. Небольшой пример использования данного класса ниже:
from transformers import pipeline
question = 'Когда будем убирать лёд?'
context = ('Вчера выпало много снега, а сегодня из-за'
' тёплой погоды он подтаял и заледенел.'
' Придётся на выходных взять лом и немного разбить лёд.')
model_pipeline = pipeline(
task='question-answering',
model='timpal0l/mdeberta-v3-base-squad2'
)
model_pipeline(question=question, context=context)Результат:
{'score': 0.6851194500923157,
'start': 88,
'end': 100,
'answer': ' на выходных'}Во втором способе отдельно скачивается модель с токенизатором, самостоятельно обрабатываются данные и подаются на вход модели. Это даёт большую гибкость по сравнению с первым способом. В текущей задаче я буду использовать только второй, так как объём текста слишком большой и его нужно обработать особым образом, об этом чуть ниже.
Программный код
Чтобы не усложнять код, приведу решение только на одной модели, остальные будут работать по аналогичному алгоритму.
Сначала я подключаю нужные библиотеки, а также скачиваю модель и токенизатор для них:
import torch
import numpy as np
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained("timpal0l/mdeberta-v3-base-squad2")
model = AutoModelForQuestionAnswering.from_pretrained("timpal0l/mdeberta-v3-base-squad2")Теперь следует с помощью токенизатора обработать вопрос вместе с текстом. Здесь я добавлю специальный флаг, чтобы токенизатор не вставлял в токены специальные символы, как, например, символ для разделения предложений. Для демонстрации работы системы в качестве текста буду использовать первый том произведения Льва Толстого «Война и мир»:
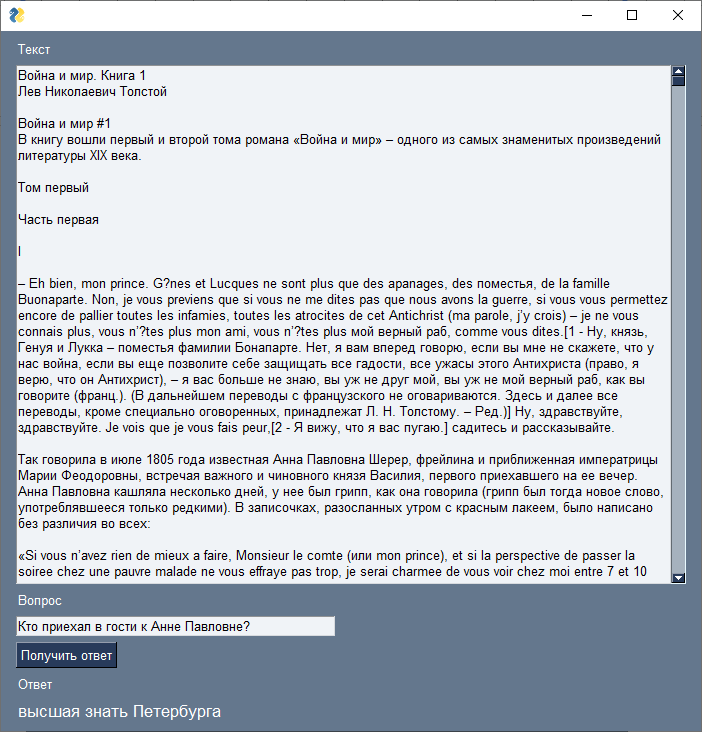
question = 'Кто приехал в гости к Анне Павловне?'
tokenized = tokenizer.encode_plus(
question, text,
add_special_tokens=False
)Чтобы в дальнейшем была возможность вывести ответ на естественном языке заранее извлекаю символьные токены:
tokens = tokenizer.convert_ids_to_tokens(tokenized['input_ids'])Далее нужно упаковать токены особым образом. Дело в том, что выбранные модели основаны на предобученной модели BERT, до недавнего времени являющейся одной из передовых в области обработки естественного языка, но ресурсы для её работы увеличиваются на порядок при увеличении количества обрабатываемых слов. Поэтому весь токенизированный текст я разбиваю на блоки одинаковой длины и подаю на вход модели. Каждый блок должен начинаться с вопроса и в дополнение, для увеличения эффективности, добавлю наложение последних токенов каждого блока на следующий.
Сначала задам длину каждого блока и длину наложения:
# Общая длина каждого блока
max_chunk_length = 512
# Длина наложения
overlapped_length = 30Элемент token_type_ids в токенизаторе нулями отмечает вопрос, а единицами основной текст, поэтому чтобы вычислить длину вопроса в токенах нужно подсчитать количество нулей в этом элементе:
# Длина вопроса в токенах
answer_tokens_length = tokenized.token_type_ids.count(0)
# Токены вопроса, закодированные числами
answer_input_ids = tokenized.input_ids[:answer_tokens_length]Первый блок будет без наложения, поэтому сначала соберу остальные блоки с наложением, а потом добавлю к ним первый. Вычислю длину блоков без вопроса и наложения:
# Длина основного текста первого блока без наложения
first_context_chunk_length = max_chunk_length - answer_tokens_length
# Длина основного текста остальных блоков с наложением
context_chunk_length =
max_chunk_length - answer_tokens_length - overlapped_lengthДалее отделю первый блок и обработаю оставшиеся (код под спойлером):
Код
# Токены основного текста
context_input_ids = tokenized.input_ids[answer_tokens_length:]
# Основной текст первого блока
first = context_input_ids[:first_context_chunk_length]
# Основной текст остальных блоков
others = context_input_ids[first_context_chunk_length:]
# Если есть блоки кроме первого
# тогда обрабатываются все блоки
if len(others) > 0:
# Кол-во нулевых токенов, для выравнивания последнего блока по длине
padding_length = context_chunk_length - (len(others) % context_chunk_length)
others += [0] * padding_length
# Кол-во блоков и их длина без добавления наложения
new_size = (
len(others) // context_chunk_length,
context_chunk_length
)
# Упаковка блоков
new_context_input_ids = np.reshape(others, new_size)
# Вычисление наложения
overlappeds = new_context_input_ids[:, -overlapped_length:]
# Добавление в наложения частей из первого блока
overlappeds = np.insert(overlappeds, 0, first[-overlapped_length:], axis=0)
# Удаление наложение из последнего блока, так как оно не нужно
overlappeds = overlappeds[:-1]
# Добавление наложения
new_context_input_ids = np.c_[overlappeds, new_context_input_ids]
# Добавление первого блока
new_context_input_ids = np.insert(new_context_input_ids, 0, first, axis=0)
# Добавление вопроса в каждый блок
new_input_ids = np.c_[
[answer_input_ids] * new_context_input_ids.shape[0],
new_context_input_ids
]
# иначе обрабатывается только первый
else:
# Кол-во нулевых токенов, для выравнивания блока по длине
padding_length = first_context_chunk_length - (len(first) % first_context_chunk_length)
# Добавление нулевых токенов
new_input_ids = np.array(
[answer_input_ids + first + [0] * padding_length]
)После того, как получены блоки токенов, формирую маски для отделения вопроса от текста и для «внимания» модели (код под спойлером):
Код
# Кол-во блоков
count_chunks = new_input_ids.shape[0]
# Маска, разделяющая вопрос и текст
new_token_type_ids = [
# вопрос блока
[0] * answer_tokens_length
# текст блока
+ [1] * (max_chunk_length - answer_tokens_length)
] * count_chunks
# Маска "внимания" модели на все токены, кроме нулевых в последнем блоке
new_attention_mask = (
# во всех блоках, кроме последнего, "внимание" на все слова
[[1] * max_chunk_length] * (count_chunks - 1)
# в последнем блоке "внимание" только на ненулевые токены
+ [([1] * (max_chunk_length - padding_length)) + ([0] * padding_length)]
)Теперь блоки и маски оборачиваю в tensor и подаю на вход модели:
# Токенизированный текст в виде блоков, упакованный в torch
new_tokenized = {
'input_ids': torch.tensor(new_input_ids),
'token_type_ids': torch.tensor(new_token_type_ids),
'attention_mask': torch.tensor(new_attention_mask)
}
outputs = model(**new_tokenized)Наконец, вычисляю наиболее вероятные позиции начала и конца ответа, извлекаю слова из ранее полученных токенов, удаляю из них вспомогательные символы и вывожу ответ (код и ответ под спойлером):
Код и ответ
# Позиции в 2D списке токенов начала и конца наиболее вероятного ответа
# позиции одним числом
start_index = torch.argmax(outputs.start_logits)
end_index = torch.argmax(outputs.end_logits)
# Пересчёт позиций начала и конца ответа для 1D списка токенов
# = длина первого блока + (
# позиция - длина первого блока
# - длина ответов и отступов во всех блоках, кроме первого
# )
start_index = max_chunk_length + (
start_index - max_chunk_length
- (answer_tokens_length + overlapped_length)
* (start_index // max_chunk_length)
)
end_index = max_chunk_length + (
end_index - max_chunk_length
- (answer_tokens_length + overlapped_length)
* (end_index // max_chunk_length)
)
# Составление ответа
# если есть символ начала слова '▁', то он заменяется на пробел
answer = ''.join(
[t.repace('▁', ' ') for t in tokens[start_index:end_index+1]]
)
print('Вопрос:', question)
print('Ответ:', answer)Результат:
Вопрос: Кто приехал в гости к Анне Павловне?
Ответ: высшая знать ПетербургаГрафический интерфейс
Чтобы было совсем уж хорошо, сделаю небольшой графический интерфейс. Для этого буду использовать библиотеку PySimpleGUI. Интерфейс будет состоять из текстового поля для ввода основного текста, вопроса по этому тексту, кнопки для запуска и поля для вывода ответа. Код для создания всего этого представлен ниже. Весь вышеизложенный код поиска ответа упакован в функцию question_answer, у которой первый аргумент текст, а второй — вопрос:
Код
import PySimpleGUI as sg
# Создание и укладка элементов окна
layout = [
[sg.Text('Текст', key='-Text-label-')],
[sg.Multiline('', key='-Text-', expand_x=True, expand_y=True)],
[sg.Text('Вопрос', key='-Question-label-')],
[sg.Input('', key='-Question-')],
[sg.Button('Получить ответ')],
[sg.Text('Ответ', key='-Answer-label-', visible=False)],
[sg.Text('', key='-Answer-', font=('Arial Bold', 13), visible=False)],
]
# Создание окна
window = sg.Window('', layout, resizable=True, size=(700, 700), finalize=True)
# Обработка событий окна, пока оно не будет закрыто
while True:
event, values = window.read()
# Событие закрытие окна
if event == sg.WINDOW_CLOSED:
break
# Событие при нажатии на кнопку для 'Получить ответ'
elif event == 'Получить ответ':
window['-Answer-label-'].update(visible=True)
window['-Answer-'].update(
question_answer(values['-Text-'], values['-Question-']),
visible=True
)
window.close()В результате интерфейс имеет следующий вид:
Сравнение результатов
Теперь проведу сравнения работы всех ранее выбранных моделей на нескольких вопросах:
№ п.п. |
Вопрос |
Отрывок из книги с правильным ответом |
Модель mdeberta-v3-base-squad2 |
Модель xlm-roberta-large-qa-multilingual-finedtuned-ru |
Модель model-QA-5-epoch-RU |
1 |
Кто в родстве с Монморанси? |
виконт Мортемар, он в родстве с Монморанси чрез Роганов |
виконт Мортемар |
Мортемар, он в |
Кстати, – виконт Мортемар |
2 |
Где был Пьер с десятилетнего возраста? |
Пьер с десятилетнего возраста был послан с гувернером-аббатом за границу, где он пробыл до двадцатилетнего возраста. |
с гувернером-аббатом за границу |
за границу, где он пробыл до двадцатилетнего возраста |
был послан с гувернером-аббатом |
3 |
О чём заключили пари Долохов с англичанином Стивенсом? |
Долохов держит пари с англичанином Стивенсом, моряком, бывшим тут, в том, что он, Долохов, выпьет бутылку рома, сидя на окне третьего этажа с опущенными наружу ногами. |
выпьет бутылку рома, сидя на окне |
Долохов, выпьет бутылку рома |
в том, что он, Долохов, выпьет бутылку |
4 |
Где располагается имение князя Николая Андреевича Болконского? |
В Лысых Горах, имении князя Николая Андреевича Болконского |
В Лысых Горах |
В Лысых Горах, имении князя |
Лысых Горах |
5 |
Кто приехал в гости к Анне Павловне? |
Абзац во второй части |
высшая знать Петербурга |
люди самые разнородные |
князь Ипполит |
6 |
Как звали сына графа Безухова? |
Абзац во второй части (ответ: Пьер) |
толстый молодой человек |
молодой человек |
незаконный |
Как видно на сравнении, модели лучше всего отвечают на вопросы с однозначным ответом, особенно если ответ расположен рядом с ключевыми словами из вопроса. Так, например, в 5-м вопросе все модели ответили, своего рода, правильно, а 6-й вопрос более обобщён, так как в тексте словосочетание «сын графа Безухова» и слово «Пьер» достаточно близко не встречаются, поэтому модели не смогли найти точный ответ.
Если сравнивать результативность моделей, то из всех трёх, на мой взгляд, лучше всего справилась первая модель, поэтому именно её и использовали на практике для решения своей задачи.
Вывод: применение и дальнейшее развитие
По итогу получен код для установки и использования предобученых вопросно‑ответных моделей с платформы Hugging Face для большого объёма текста. Главная цель его создания была автоматизация анализа произвольного текста путём составления вопросов на естественном языке, в противовес поиску нужной информации по ключевым словам.
Возможно и дальнейшее развитие инструмента, как, например, использование других моделей. Ввиду того, что задача заключается в обработке текста на русском языке, то подбор подходящей модели несколько усложняется, так как большинство моделей рассчитано на английский язык. Выходом может стать дообучение модели на собственных практических текстах. Так можно поймать сразу двух зайцев: и русифицировать модель, и лучше подогнать её на конкретные тексты, что должно повысить результаты в области её дальнейшего использования.
Ещё есть вариант использовать в качестве модели доступные аналоги GPT3, как, например, Alpaca или LLaMA. Данные модели уже на порядок более совершеннее, чем приведённые здесь и их результаты также должны быть лучше, но они в свою очередь требуют куда больших вычислительных мощностей даже для использования, не говоря уже о дообучении.
Даже несмотря на это, приведённую здесь вопросно‑ответную систему уже можно использовать на практике. В первую очередь она подойдёт тем, кому часто приходится работать с большими объёмами текста для поиска информации. Например, для поиска порядка действий в конкретных ситуациях по нормативным документам, получения коротких и быстрых ответов по протоколу совещания или же для поиска цены товара в документе расценок.
Комментарии (7)

NewTechAudit Автор
07.06.2023 06:06+1Добрый день!
Книгу Льва Николаевича взял для демонстрации работы, вопросно‑ответную систему можно использовать для любого текста на русском языке. Моей целью было создать инструмент для поиска ответов в объёмных документах, договорах и т.д.
Спасибо за интерес к посту!

Andrey_Epifantsev
07.06.2023 06:06А можно что-то подобное сделать для поиска информации по коду? Есть большая кодовая база. Периодически приходится в ней разбираться. Было бы здорово, если бы такая модель могла бы человеческим языком рассказать как устроен и работает этот код, примерно так как программист написавший его.
NewTechAudit Автор
07.06.2023 06:06Добрый день!
Cпециализированной модели для ответов по коду лично я не знаю. Знаю, что ChatGPT умеет хорошо отвечать на вопросы по переданному ему коду. Как вариант можно попробовать Alpaca и подобные, из минусов – им не получиться передать большой объём кода из-за ограничений размера сообщений. Ещё можно сгенерировать документацию с помощью существующих программ, как например Doxygen, а уже сгенерированный текст передать в вопросно-ответную систему.
Спасибо за вопрос!

Megavolv
07.06.2023 06:06Здравствуйте! Подскажите, пожалуйста, есть ли возможность каким-то образом получать не просто ответ, а ссылку на файл/абзац/предложение, по которому был построен ответ?
volchenkodmitriy
Довольно забавно выглядит программа, помогающая находить ответы на конкретные вопросы в художественном произведении. Это как помощник двоечнику на уроке литературы, чтобы он смог доказать что читал книгу. А человека должны взволновать образы, характеры, чувства, а не Кто? Где? Когда?))) Вот если бы для примера был взят учебник по Истории, тогда другое дело!
OlegZH
Можно автоматизировать написание энциклопедий (типа Википедии), когда реферативное описание сюжета автоматически извлекается из текста романа.
volchenkodmitriy
Да, это хорошая идея!