
Привет, Хабр!
В сегодняшней статье будет рассмотрен анализ структуры деловых документов. Деловой документ предназначен для обмена данными между организациями и физическими лицами. Деловые документы характеризуются относительно простой структурой и ограниченным словарем статических текстов. Объемы потоков входящих и исходящих бумажных документов в крупных организациях могут достигать нескольких миллионов страниц в день, поэтому ручная обработка большого потока документов невозможна. Анализ текста и распознавание документа – известные задачи, однако анализ распознанного документа имеет свои особенности, о которых мы далее расскажем.
Известно подразделение деловых документов на жесткие и гибкие. Характеристикой жесткого документа является неизменность формы, то есть бланка документа без заполнения. Документ формируется после печати информации на бланке. Жесткие формы могут быть напечатаны полиграфическим способом. К таким жестким документам относятся идентификационные документы, свидетельства, дипломы. Другим способом является использование при печати документа одного единственного шаблона, который не может изменяться пользователем. В этом случае жесткой формой является распечатка шаблона без заполнения. Оцифровка (сканирование или съёмка мобильным устройством) возможна как документа, так и формы. Заметим, что в процессе оцифровки может быть получено несколько различных изображений (экземпляров), соответствующих одному и тому же документу. Различия объясняются случайными процессами в устройствах оцифровки и особенностями размещения документа перед сенсором, приводящими к различным искажениям.
Рассмотрим два экземпляра и
одного оцифрованного документа. Считаем, что процесс оцифровки позволяет получать образы документов без потерь, а также, что границы документа после оцифровки близки к границам изображения. Также будем считать, что после оцифровки подвергнем изображение документа нормализации по форме и размеру. Различия в двух экземплярах одного документа определяются дефектами оцифровки и точностью нормализации образа документа. Представим, что существует отображение
точек изображений
. Рассмотрим вектор, заданный парой точек
из изображения
,и вектор, заданный соответствующих им точек
из изображения
. Если угол между векторами
и
является малым и разница между расстояниями
и
является малой, то точку
можно найти, зная вектор
и точку
. В реальности это можно сделать только приближённо из-за искажений оцифровки, таких как проективные искажения, сферические аберрации, физические искажения листов документа. Отображение
является воображаемым, не существует возможности найти соответствие между всеми точками двух изображений. Но для жестких форм есть способ по некоторым точкам найти достаточно точный прогноз размещения других точек. Этот процесс назовём привязкой. Результатами распознавания деловых документов являются значения и текстовые данные полей, извлеченных из всего образа документа. Простым способом извлечения является прогноз границ полей и распознавание поля (OCR). То есть сначала проводится привязка границ поля, а распознавание учитывает свойства содержащейся в поле информации.
Жесткая форма создается так, что все создаваемые с помощью данной формы документов – после оцифровки и нормализации – становятся похожими с точностью до размера. Жесткими документами будем называть документы, созданные с помощью жестких форм.
Известно применение жестких документов для распознавания документов с целью извлечения данных. Из жестких документов извлекаемые данные описываются однострочными или многострочными полями в локализованном, нормализованном и ректифицированном изображении документа. Модель привязки основана на известном заранее описании, состоящем из опорных элементов. Расстояния от опорных элементов до границ извлекаемых полей определяются в процессе обучения. Опорными элементами являются локальные особенности (ключевые точки), сгруппированные в созвездия точек. Модель состоит из нескольких созвездий. Дескрипторами ключевых точек могут быть RFD, YOLO, YAPE. Для каждого типа дескриптора применяется свой детектор (алгоритм поиска ключевой точки и вычисления дескриптора). Сравнение множества точек модели и найденных точек в анализируемом документе проводится методом RANSAC, оценивающим близость модели и документа с помощью случайных выборок. Обратим внимание на то, что ключевых точек в образе документа содержится достаточно много (см. рис. 1), что и позволяется формировать случайные выборки.

Формы и документы, не являющиеся жесткими, назовём гибкими. Для гибкого документа не существует ограничения на расстояния между любой парой соответствующих геометрических объектов в двух экземплярах одного формы. Например, даже между двумя соседними словами расстояние может измениться из внесенных в форму модификаций, таких как:
изменение шрифта,
изменение межстрочного расстояния,
изменение границ фрагментов документа.
Мы предлагаем рассматривать распознанные слова как особые точки (на самом деле, области или пятна), сходные с перечисленными выше известными локальными особенностями. Дескриптором текстовой особой точки (ТОТ) является слово – последовательность распознанных знакомест, знакоместо может быть представлено символом и оценкой соответствия этому символу или вектором оценок соответствия всем возможным символам из алфавита распознавания. Детектором ТОТ является OCR. Некоторые распознанные слова могут быть уникальными в каком-либо контексте или окрестности. Под окрестностью мы понимаем:
страницу,
фрагмент страницы, отделённый линиями или промежутками от других фрагментов,
строку,
абзац.
Другие распознанные слова не являются уникальными в той же окрестности. В большинстве форм деловых документов уникальных слов содержится меньше, чем неуникальных. Мы покажем, как из нескольких неуникальных слов создать комбинированный дескриптор, который можно использовать для анализа структуры документа.
Мы рассмотрим две задачи анализа: привязку границ полей и классификацию какой-либо окрестности. Начнём с классификации страницы, то есть с проверки соответствия страницы какому-либо известному типу.
Рассмотрим простой метод классификации для двух типов документов и
, использующий известную структуру «мешок слов» (Bag-of-Words). Для каждого типа документа
зададим ещё 2 мешка слов:
и
в предположении, что слова из мешка D-(t1) не встречаются в документах с типом t2, а также слова D-(t2) не встречаются в документах с типом
. Рассмотрим документ неизвестного типа, представленный мешком слов
. Будем считать, что известна функция отождествления каждой пары слов. Если в мешке
нет ни одного слова из мешка
, но есть несколько слов из мешка
, то документ
соответствует типу
. Аналогично, если мешке
нет ни одного слова из мешка
, но есть несколько слов из мешка
, то документ
соответствует типу
. Если установлено соответствие только одному типу, то классификация считается успешной. В противном случае тип не установлен и нужно применить другие методы анализа документа или смириться с невозможностью определить тип. Число классов для «метода мешков» может быть существенно больше двух. Описанный метод пригоден не только для классификации документов, но и для различения фрагментов, строк, ячеек таблиц в одном документе. Неявно предполагается, что в документе или его части содержится достаточное число слов для построения мешков.
Классификация распознанных документов имеет свои особенности. Отождествление двух слов текста одной длины и
проводится проверкой совпадения кодов символов
и
. Если слова могут содержать ошибки, необходимо применять какую-нибудь метрику, например, классическое или модифицированное расстояние Левенштейна. Однако в распознанных документах может быть значительное число ошибок распознавания, например, из-за загрязнения бумажных документов или из-за искажений при оцифровке. В таких случаях в одном слове может быть много ошибок распознавания, более того, слово может объединиться с другими словами или разделиться на несколько слов. Ограниченность объема словаря формы делового документа также усложняет возможность применения неструктурных методов классификации. Далее мы расскажем о том, как построить алгоритм надежной классификации на основе структуры из нескольких ключевых слов, сопоставляемых со словами распознанного документа.
Распознанное слово выглядит как последовательность знакомест . Каждое знакоместо
представлено массивом альтернатив:
где – код символа,
– оценка соответствия символа
образу знакоместа
, а
– количество альтернатив. Оценки находятся в диапазоне
, самой лучшей оценкой считается
. Значения
могут различаться для различных
. Кроме этого известна рамка распознанного слова.
Теперь рассмотрим описание модели, состоящей из текстовых особых точек и отношений между ними. ТОТ представлена дескриптором в форме матрицы альтернатив:
В этом представлении – оценка соответствия распознанного образа знакоместа
символу
из алфавита распознавания, а
– объем алфавита распознавания. Оценки
находятся в диапазоне
, самой лучшей оценкой считается
. Для каждого знакоместа известна рамка
. В простейшем случае дескриптор ТОТ может состоять только из последовательности символов
, без альтернатив и оценок. Для каждой ТОТ должны быть известны параметры расстояния Левенштейна для сравнения дескриптора ТОТ
с распознанными словами
. В том числе должен быть задан порог для отождествления
. Если в распознанном документе найдено единственное слово, которое отождествлено с некоторой заданной заранее ТОТ, то эта отождествленная ТОТ считается привязанной. В общем случае в документе можно найти несколько распознанных слов, которые можно отождествить с ТОТ, для привязки ТОТ нужен способ выбора слова из нескольких кандидатов.
В отличие от отношений между геометрических ключевых точек в жестких документах, в гибких документах с некоторым зазором. Могут быть использованы отношения:
- слово
принадлежности окрестности
, слова в которой линейно упорядочены,
– слово
размещено"после" слова
для слов из одной окрестности (симметричное отношение -
, "до"),
–слово
размещено "выше" слова
для слов из одной окрестности (симметричное отношение -
, "ниже"),
или метрики:
– количество слов в промежутке между двумя словами
и
,
– псевдоевклидово расстояние двумя словами
и
(смысл "псевдо" ясен из рис. 2),
– евклидово расстояние двумя проекциями рамок слова
и
(смысл пояснен на рис. 3).


Рассмотрим созвездие , состоящее из упорядоченного набора ТОТ
, удовлетворяющих нескольким условиям:
Аналогично словам для метода "мешков" для каждой ТОТ известен признак, показывающий, является ТОТ обязательной, нейтральной или запрещающей.
Созвездия создаются для того, чтобы описать уникальную для некоторой окрестности последовательность ключевых слов (ТОТ), в которой каждый элемент не обязан быть уникальным для данной окрестности.
Опишем кратко метод привязки созвездия. Для каждого из ТОТ находятся одно или несколько отождествленных распознанных слов
, для которых справедливо:
Из всех кандидатов выбираются такие наборы ТОТ, в которых наихудшая оценка отождествления минимальна:
При этом для каждого из кандидатов на роль ТОТ проверяются условия на соответствие другим ТОТ в созвездии. Оптимизация проводится с учётом того, является ли каждая ТОТ обязательной, нейтральной или запрещенной. Точнее, в созвездии должны быть привязаны все обязательные ТОТ и не должно быть ни одной запрещенной ТОТ. Созвездие считается привязанным к распознанному документу, если привязано необходимое число обязательных и необязательных ТОТ созвездия, а все запрещенные ТОТ не привязаны.
Для нахождения оптимума в общем виде требуется сложный алгоритм перебора. Но для деловых документов число кандидатов для большинства ТОТ невелико, а часто имеется единственный кандидат. Условия на отношения между ТОТ существенно уменьшают число кандидатов. Поэтому допустим полный перебор вариантов. Результатом привязки созвездия является выделение упорядоченного множества распознанных слов, каждое из которых соответствует какой-либо ТОТ созвездия. Также известна оценка привязки созвездия .
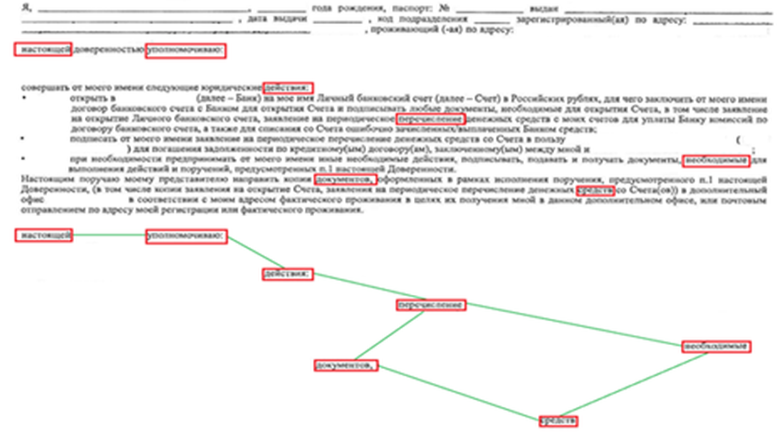
Структура созвездий задаётся фантазией дизайнера или возможностями обучения. Например, можно описать созвездие, напоминающее созвездие "Большой медведицы", см. рис . 4. Такое созвездие может быть применено для классификации фрагмента (абзаца) делового документа, приведённого на рисунке. В этом созвездии содержится 7 точек: ("настоящей"),
("уполномочиваю"),
("действия:"),
("перечисления"),
("необходимые"),
("документов"),
("средств"), связанные следующими:

При незначительном изменении шрифта и замене или добавлении слов, отличных от ТОТ "Большой медведицы", отношения между ТОТ не изменятся. При значительном изменении размера шрифта некоторые отношения выполняться не будут, однако будет выполнен следующий набор отношений:
Это созвездие представлено на рис. 5 и оно уже не похоже на "Большую медведицу".

Самое простое созвездие состоит из одного единственного слова. Другим примером является шингл (n-грамма) - последовательность слов, размещенных одно за другим):
Многие фрагменты документа могут быть описан с помощью цепи, состоящей из последовательность слов . Пары соседних слов
образует битерм, для которого может быть задано ограничение на расстояние между словами битерма:
Например, абзац, приведённый на рис. 6, описывается тремя цепями:
где цепь ограничивает зону абзаца сверху,
– снизу, а цепь
состоит из статических слов абзаца. Для некоторых битермов
из рис. 6. должно выполняться условие:

Текстовые строки также описываются аналогично абзацам. Если строка отличается от всех строк документа или фрагмента документа, то для ее привязки достаточно одной цепи. Описание строки и абзаца содержит последовательность термов, базирующихся на обязательных и запрещенных ключевых словах. Если строка не имеет уникальных слов в контексте документа или фрагмента документа, строка может быть привязана с помощью цепей и
.
Процесс обучения состоит из нескольких задач. Первая из них состоит в выборе базиса для созвездий. А именно, можно определить структуру созвездия как одно слово, шингл, цепь или более сложную (такую как Big Dipper). Для рассмотренных нами более 100 типов деловых документов для классификации фрагментов было достаточно цепей. Вторая задача – это построение модели, то есть выбор слов, образующих цепи, которые имеются в одном документе (фрагменте) и отсутствуют в других документах (фрагментах). Можно заметить сходство с выбором слов для метода "мешков", однако цепи как более сложный объект классифицируют распознанные тесты существенно более надёжно, чем отдельные слова. Обучение может быть проведено методами ML (например, CART), или вручную. Третья задача состоит в настройке параметров цепи, то есть в установление порогов между некоторыми ключевыми словами для некоторых метрик.
Привязка созвездий позволяет классифицировать фрагменты распознанного документа. После классификации распознанный деловой документ выглядит следующим образом:
где – либо привязанный, либо не привязанный фрагмент,
– область документа, не подлежащая классификации. С помощью описанного способа классификации мы получаем разбиение распознанного документа на фрагменты, в котором
являются окрестностями. Такое разбиение позволяет упрощать отождествление ТОТ. Очевидно, что отождествление слова со словами из строки
во всех отношениях существенно проще, чем отождествление слова со всеми распознанными словами документа
без анализа структуры.
Описанная технология анализа структуры деловых документов была нами опробована более чем на 100 типах деловых документов. Надежное разбиение распознанного документа на фрагменты проводится с помощью простой схемы автоматизированного обучения. Затраты времени на создание дескрипторов одного документа занимают от 1-го до 8 часов рабочего времени. Точность разбиения на фрагменты, определённая как доля правильно детектированных фрагментов по отношению к общему числу фрагментов, составляет 97-99%. Большей частью ошибки объясняются сильным зашумлением документов.
dyadyaSerezha
Правда? А 1 это O(10^6)? А 0.0001? Дальше читать не стал "математику".
SmartEngines Автор
Спасибо, поправили опечатку.