

Программирование текстовых редакторов может быть очень интересной и сложной задачей. Типы задач, которые должны решать текстовые редакторы, варьируются от тривиальных до невероятно трудных. Недавно я занимался переработкой внутренних структур данных редактора, над которым я работаю. В частности, самой фундаментальной для любого текстового редактора структуры данных: текста.
Ресурсы
Прежде чем мы приступим к разбору того, что я сделал, важно упомянуть очень полезные ресурсы для создания собственного текстового редактора:
- Build Your Own Text Editor — наверно, самый фундаментальный пост о создании текстового редактора с нуля, который я видел. Это превосходный туториал на случай, если вы хотите начать писать собственный текстовый редактор. Стоит заметить, что в редакторе из этого туториала в качестве внутренней структуры для текста используется, по сути, вектор строк.
- Text Editor: Data Structures — отличный обзор множества структур данных, которые можно использовать при реализации текстового редактора. (Спойлер: как минимум одна из них будет рассмотрена в моём посте)
- Плейлист Ded (Text Editor) на YouTube — это потрясающая серия, в которой @tscoding фиксирует процесс создания с нуля текстового редактора. Эти видео стали для меня источником вдохновения.
Зачем?
Если в сети есть так много хороших ресурсов о создании собственного текстового редактора (не говоря уже о том, что уже существует множество феноменальных текстовых редакторов), то зачем я это пишу? На то есть несколько причин:
- Я хотел заняться проектом, непохожим ни на один свой прошлый.
- Я хотел создать инструмент, которым смогу пользоваться.
- Мне всегда хотелось глубже разобраться с созданием собственных структур данных.
Я занялся реализацией собственной структуры данных потому, что увидел в своей программе проблему, а стандартные решения не полностью бы её устранили и не обеспечили бы достаточной гибкости. Более того, источником вдохновения для всего проекта во многом стало Handmade Community, поэтому всё создаётся с нуля. Если бы я использовал готовое решение, то ощущал бы, что оказал плохую услугу принципам, по которым создаётся этот редактор.
В начале…
Я убеждён, что нужно экспериментировать и как можно быстрее создавать что-то рабочее; по сути, это принцип fail fast. Я не хочу сказать, что при первой попытке следует забыть об оптимизации. Я всего лишь начал с самого простого описания текстового файла: с очень длинной строки.
При использовании в качестве буфера текста одной строки возникает множество отличных свойств:
- Это наиболее компактное описание.
- Алгоритмы вставки и удаления просты.
- Такой подход очень удобен для процесса рендеринга, потому что можно разделить строку на несколько view, которые можно рендерить по отдельности без дополнительного распределения.
- К тому же это очень просто.
Вот краткий пример вставки и удаления:
void insert_buffer(Editor::Data* data, std::string_view buf)
{
auto old_size = data->buf.size();
data->buf.resize(data->buf.size() + buf.size());
auto insert_at = next(begin(data->buf), rep(data->cursor));
auto end_range = next(begin(data->buf), old_size);
// First splat the buffer on the end, then rotate it to where
// it needs to be.
std::copy(begin(buf), end(buf), end_range);
std::rotate(insert_at, end_range, end(data->buf));
data->need_save = true;
}
void remove_range(Editor::Data* data, CharOffset first, CharOffset last)
{
auto remove_start = next(begin(data->buf), rep(first));
auto remove_last = next(begin(data->buf), rep(last));
auto removed_begin = std::rotate(remove_start, remove_last, end(data->buf));
data->buf.erase(removed_begin, end(data->buf));
data->need_save = true;
}Примечание: да, показанные выше алгоритмы можно упростить, всего лишь вызвав
buf.insert или buf.erase, но этот код просто разворачивает операции, которые были бы реализованы в этих функциях STL, никак не изменяя общую сложность.Но недостатки такого подхода ужасны. Удачи вам, если вы захотите работать с файлом больше 1 МБ. Вы не только начнёте ощущать эти выполняемые за линейное время операции: если внутреннему буферу понадобится перераспределить некоторые изменения в тексте, то весь процесс начинает очень тормозить, ведь нужно распределить буфер большего размера, скопировать каждый байт в новый буфер, а потом удалить старый. Это может случайным образом превращать операцию O(n) в O(n^2).
У использования огромного буфера текста есть и другой, гораздо менее заметный недостаток: как реализовать отмену/повтор (undo/redo)? Самое очевидное решение: создать отдельную структуру данных, отслеживающую все отдельные вставки и удаления. Вставки отслеживать гораздо проще, потому что их можно хранить как диапазон смещений и просто удалять их из исходного буфера при вызове операции отмены (undo). С удалениями всё чуть сложнее, потому что в системе с одной длинной строкой нужно хранить маленький буфер, содержащий удалённые символы, и смещение, из которого они были извлечены. Подойдёт нечто такое:
#include <cstddef>
#include <string>
enum class CharOffset : std::size_t { };
struct InsertionData
{
CharOffset first;
CharOffset last;
};
struct DeletionData
{
std::string deleted_buf;
CharOffset from;
};
struct UndoRedoData
{
enum class Kind { Insertion, Deletion };
Kind kind;
union
{
InsertionData ins;
DeletionData del;
};
UndoRedoData(InsertionData ins):
kind{ Kind::Insertion },
ins{ ins } { }
UndoRedoData(DeletionData del):
kind{ Kind::Deletion },
del{ del } { }
~UndoRedoData()
{
switch (kind)
{
case Kind::Insertion:
ins.~InsertionData();
break;
case Kind::Deletion:
del.~DeletionData();
break;
}
}
};Но такое решение слишком сложно и потенциально потребует большой траты ресурсов на распределения при удалении больших частей текста. Должно быть что-то получше…
Исследование
Я знал, что хочу решить все проблемы, свойственные единому огромному буферу текста, поэтому мои конкретные цели заключались в следующем:
- Эффективные вставка/удаление.
- Эффективные undo/redo.
- Достаточная гибкость для поддержки кодировки UTF-8.
- Эффективное многокурсорное редактирование.
▍ Буферное окно
Изначально я пошёл по пути буферного окна. Буферное окно (gap buffer) очень легко реализовать, и в качестве структуры данных его использует Emacs. Буферное окно помогает достичь цели из первого пункта списка. Не очень часто приходится редактировать весь файл, не так ли? Ну… Не совсем. Одна из моих любимых функций современных текстовых редакторов — это многокурсорное редактирование (multi-cursor editing) (иногда называемое block-style edits, хотя это немного иное), и после внимательного прочтения «Gap Buffers Are Not Optimized for Multiple Cursors» (поста с лучшими анимациями, объясняющими работу буферного окна) Криса Уэллонса я понял, что буферные окна — ошибочный выбор, потому что многокурсоное редактирование важно для меня.
Кроме того, буферные окна имеют примерно те же проблемы, что и длинные строки — сложно выполнять эффективные undo/redo без множества дополнительных структур хранения/данных.
- Эффективные вставка/удаление — есть.
- Эффективные undo/redo — нет.
- Достаточная гибкость для поддержки кодировки UTF-8 — есть.
- Эффективное многокурсорное редактирование — нет.
Буферное окно исключается.
▍ Строп
Очень привлекательной структурой данных для текстовых редакторов может быть строп. Строп (rope) имеет множество удобных свойств для редактирования, потому что он разделяет файл на множество мелких распределений, что позволяет выполнять очень быстрые амортизированные вставки или удаления из любой точки файла за O(lg n). Поначалу кажется, что строп решает все мои проблемы, потому что операции наподобие undo/redo можно проще реализовать благодаря снэпшоту дерева (или сохранению удалённых или изменённых узлов), а многокурсорное редактирование становится гораздо более легковесной операцией.
Так в чём же проблема? Давайте ненадолго вернёмся к undo/redo.
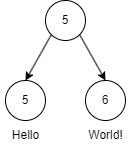
Это описание строки «HelloWorld». Если я хочу добавить пробел между «Hello» и «World», то новое дерево будет выглядеть так:

В конец узла «Hello» добавлен пробел. Самая привлекательная версия структуры данных «строп» заключается в том, чтобы сделать всё неизменяемым, то есть при расширении узла с «Hello» мы на самом деле создаём новый узел с новым буфером, содержащим новую строку, или создаём новый узел, содержащий только " ", что выглядит столь же многозатратным (однако строп должен определять какую-нибудь константу для ограничения размера каждого узла). Копирование узла при записи подразумевает, что хотя стек undo будет содержать более легковесную версию исходного дерева, новое созданное дерево может увеличить общее потребление памяти намного больше, чем вы могли изначально думать.
Для своего редактора я хотел что-то чуть более легковесное.
- Эффективные вставка/удаление — есть.
- Эффективные undo/redo — нет.
- Достаточная гибкость для поддержки кодировки UTF-8 — есть.
- Эффективное многокурсорное редактирование — есть.
▍ Piece Table
Теперь всё становится любопытнее. Piece table — это структура данных, имеющая долгую историю использования в текстовых редакторах. Когда-то piece table использовалась в Microsoft Word для реализации таких функций, как быстрые undo/redo, а также эффективное сохранение файлов. Похоже, piece table решает многие мои проблемы.
Однако у неё есть один, казалось бы, мелкий недостаток. Из-за того, что традиционная piece table реализуется как сплошной массив истории изменений, то подразумевается, что при долгих сессиях редактирования добавление множества мелких изменений в один файл вызовет часть артефактов, с которыми мы сталкивались в огромном буфере текста. Например, в произвольные моменты времени редактор может начать тормозить из-за перераспределения piece table в более крупный массив. Кроме того, стеки undo/redo должны будут хранить этот потенциально большой массив элементов.
- Эффективные вставка/удаление — есть (за исключением случаев долгих сессий).
- Эффективные undo/redo — есть (за исключением случаев долгих сессий).
- Достаточная гибкость для поддержки кодировки UTF-8 — есть.
- Эффективное многокурсорное редактирование — есть.
Эту проблему решила команда VSCode. Представляю вашему вниманию piece tree…
▍ Piece Tree
Не хочу повторять всё, что было описано в посте VSCode о его реализации буфера текста, но вкратце расскажу о том, чем интересна именно эта версия piece table, и что мне необходимо было изменить под себя.
Дополнение: мне указали на то, что piece tree изобрела не команда VSCode. Использование дерева для описания отдельных фрагментов предлагалось ещё в 1998 году в статье Data Structures for Text Sequences. Я просто считаю, что реализация предложенной в статье идеи в VSCode качественна и хорошо протестирована.
Реализованная VSCode piece table похожа на ребёнка традиционных структур данных piece table и «строп», во всём превзошедшего своих родителей. Мы получили красоту затрат амортизации вставок в стиле стропа и сжатие памяти piece table. Piece tree обеспечивает быстрые и сжатые вставки благодаря использованию красно-чёрного дерева для хранения отдельных фрагментов. Эта структура данных полезна тем, что гарантированно является сбалансированным деревом поиска, обеспечивая время поиска O(lg n), вне зависимости от того, сколько фрагментов со временем будет добавлено.
Однако в нём отсутствует одна крошечная особенность… В реализации VSCode не используются неизменяемые структуры данных, то есть для сохранения стеков undo/redo мне понадобится копировать piece tree целиком (разумеется, не внутренние данные). То есть оно обладает некоторыми из недостатков piece table, поэтому давайте их устраним! Это ведь будет несложно? (Спойлеры: это было сложно).
- Эффективные вставка/удаление — есть.
- Эффективные undo/redo — есть (почти; требуется копирование дерева).
- Достаточная гибкость для поддержки кодировки UTF-8 — есть.
- Эффективное многокурсорное редактирование — есть.
Моё собственное piece tree
Основная цель реализации моего собственного piece tree заключалась в превращении его в полностью функциональную структуру данных; то есть внутреннее состояние текста должно быть полностью неизменяемым, а для его изменения потребуется новое частичное дерево.
В реализованном VSCode piece tree используется традиционное красно-чёрное дерево. Перечитав книгу Introduction to Algorithms, я осознал, что попытка реализации красно-чёрного дерева, описанной в этой книге как чисто функциональный вариант, не будет простой по двум причинам:
- В книге активно используется сторожевой узел (sentinel node), описывающий узел NIL, но его можно изменять как обычный узел, хотя он только один.
- В алгоритмах книги в каждом узле активно используется указатель на родителя. Указатели на родителя — это чисто функциональные структуры данных, а это нас не устраивает, потому что изменение в любой части дерева, по сути, инвалидирует всё дерево.
Но ведь кто-нибудь уже реализовал неизменяемое красно-чёрное дерево? Ну… похоже на то. В своих поисках я обнаружил статью Бартоша Милевски Functional Data Structures in C++: Trees, в которой он рассказывает о простом способе реализации чисто функционального красно-чёрного дерева, но только для вставок. Вставки необходимы, но мне нужны и удаления, в противном случае piece tree просто не будет работать. В комментариях к посту говорится, что удаление реализовать крайне сложно, и что даже для работы с ним часто необходима новая концепция узлов. Мне очень понравилось решение Милевски для вставок, поэтому я начал своё красно-чёрное дерево с этой структуры данных, и реализовал остальную часть piece tree на её основе, за исключением удалений, но об этом позже.
▍ В чём были мои отличия
Теперь, когда я реализую буфер текста в виде дерева, чрезвычайно важно спроектировать мощные инструменты отладки для моего удобства и оценки того, какие части моей реализации нужно изменить для решения моих задач. Код исходного textbuffer VSCode в виде отдельного репозитория можно посмотреть здесь: https://github.com/microsoft/vscode-textbuffer. Реальную реализацию буфера текста (которая не сильно отличается от отдельного репозитория) можно посмотреть здесь: https://github.com/microsoft/vscode/tree/main/src/vs/editor/common/model/pieceTreeTextBuffer.
▍ CRLF
Моя новая реализация этой структуры данных не слишком далеко ушла от версии VSCode. Она отличается тем, что я принял решение не кодировать конец строки CRLF как формальную концепцию дерева. Мне не нравятся хитрости, на которые пришлось идти в их реализации, чтобы учесть, что CRLF содержится внутри одного piece, и, мне кажется, что это существенно усложняет структуру данных из-за аспекта, который в реальности необходимо учитывать в очень редких случаях. В моём текстовом редакторе (без новой реализации буфера текста) я учитываю CRLF в отдельной структуре данных, фиксирующей диапазоны строк. Если редактор находится в «режиме CRLF», то он будет восстанавливать диапазоны строк таким образом, чтобы обрезать возврат каретки, когда за ним следует символ новой строки. При новом буфере текста мне вообще не нужно фиксировать, где находятся CRLF, я просто учитываю их, когда происходит изменение буфера, при котором необходимо удалять и
\r, и \n, или при перемещении курсора для возврата его позиции до \r, если он предшествует \n.Вот пример того, что видит пользователь, когда включён «режим CRLF», а курсор движется до/после строки CRLF:

Вот, что делает система, или чтобы пропустить возврат каретки, или для перехода к символу до него (символ ¶ означает
\r):
Структура данных не обязана фиксировать CRLF, потому что редактору вообще очень редко приходится учитывать символ возврата каретки.
▍ Отладка
Возможность отладки сложной структуры данных необходима, если вы хотите чего-то достичь. Если изучить отдельный репозиторий реализации VSCode, то можно заметить, что основной способ валидации содержимого буфера — это
getLineContent, который является фундаментальным и важным API. Для реальной проверки всего буфера мне нужен был другой подход, поэтому я спроектировал алгоритм обхода дерева с интерфейсом в стиле итератора, чтобы можно было использовать цикл for-each:class TreeWalker
{
char current();
char next();
void seek(CharOffset offset);
bool exhausted() const;
Length remaining() const;
CharOffset offset() const;
// Для поведения в стиле итератора.
TreeWalker& operator++();
char operator*();
...
};
struct WalkSentinel { };
inline TreeWalker begin(const Tree& tree)
{
return TreeWalker{ &tree };
}
constexpr WalkSentinel end(const Tree&)
{
return WalkSentinel{ };
}
inline bool operator==(const TreeWalker& walker, WalkSentinel)
{
return walker.exhausted();
}Этот обходчик дерева оказался бесценной помощью в валидации редактирований и удалений, а также открыл новые возможности по проверке корректности поддержки UTF-8, потому что мне нужна была функция обхода конкретных элементов кодового пространства по заданному смещению. Естественно, были созданы и другие инструменты отладки как способ печати узлов дерева и связанных с ними piece:
void print_piece(const Piece& piece, const Tree* tree, int level);
void print_tree(const Tree& tree);▍ Undo/Redo
Реализация VSCode не реализует undo/redo непосредственно как операцию буфера текста, они выполняются через систему, в которой редактирование, применяемое к буферу текста, фиксирует последовательность «обратных» операций, необходимых для отмены (undo) предыдущего редактирования и передачи её вызывающей функции, которая затем выполняет хранение этой информации и отвечает за применение последовательного обратного редактирования. Эта система определённо является одним из решений, она позволяет избежать повторного копирования всего дерева, однако использует распределение буферов данных аналогично тому, как я объяснял возможность реализации undo/redo для однострочной реализации. Вот мои процедуры undo/redo:
UndoRedoResult Tree::try_undo(CharOffset op_offset)
{
if (undo_stack.empty())
return { .success = false, .op_offset = CharOffset{ } };
redo_stack.push_front({ .root = root, .op_offset = op_offset });
auto [node, undo_offset] = undo_stack.front();
root = node;
undo_stack.pop_front();
compute_buffer_meta();
return { .success = true, .op_offset = undo_offset };
}
UndoRedoResult Tree::try_redo(CharOffset op_offset)
{
if (redo_stack.empty())
return { .success = false, .op_offset = CharOffset{ } };
undo_stack.push_front({ .root = root, .op_offset = op_offset });
auto [node, redo_offset] = redo_stack.front();
root = node;
redo_stack.pop_front();
compute_buffer_meta();
return { .success = true, .op_offset = redo_offset };
}Да, и это всё, что нужно. Два связанных списка и вызов
compute_buffer_meta() (а это операция O(lg n)). Если вся структура данных неизменяема, то можно вернуться к любому корню, ссылку на который вы сохранили ранее, и состояние редактора будет полностью согласованным, что, нужно сказать, обеспечивает возможность создания UI для ветвящихся состояний редактора (своего рода мини-систему контроля версий), в котором пользователь будет перемещаться по графу состояний редактора в какое-то предыдущее состояние; больше никаких коммитов git commit -am'testing' как единственной возможности обратить изменения!▍ Возвращаемся к удалению
Я говорил, что мы вернёмся к операциям удаления, потому что в текстовых редакторах они столь же фундаментальны, как и операции вставки. Честно говоря, пойдя по пути реализации удаления неизменяемого красно-чёрного дерева, я много раз едва не сдался. Алгоритм из моей книги алгоритмов был простым, но нерабочим, потому что его нужно было преобразовать в рекурсивную версию, где нам также приходится избавиться от сторожевых узлов (которые используются в реализации красно-чёрного дерева VSCode, но это необязательно плохо). Превосходную визуализацию алгоритма красно-чёрного дерева создал факультет CS Университета Сан-Франциско, и я крайне рекомендую изучить её, если вам любопытно изучать алгоритмы в действии.
Чтобы понять, по каким же причинам удалять из красно-чёрных деревьев трудно, нужно рассмотреть случаи, которые необходимо учитывать при традиционном удалении из красно-чёрного дерева. В частности, случаи, когда возникает нарушение правил при создании двойных чёрных узлов удалением красного узла и возникает множество возможностей для ошибок. К счастью, нашлись разработчики, которые подумали, что реализация неизменяемого красно-чёрного дерева может быть полезной: мне удалось найти persistent-rbtree, адаптированное из Rust Persistent Data Structures. Этот код содержит надёжную логику удаления узлов, которую я смог адаптировать под своё красно-чёрное дерево и использовал как основу для своей процедуры удаления. Посмотреть, как это было сделано, можно в готовом репозитории по ссылке ниже.
После реализации удаления я, наконец, получил «идеальную» (для меня) структуру данных:
- Эффективные вставка/удаление — есть.
- Эффективные undo/redo — есть.
- Достаточная гибкость для поддержки кодировки UTF-8 — есть.
- Эффективное многокурсорное редактирование — есть.
fredbuf
Было бы безумием объяснять всё это и в результате не показать код. fred — это название моего текстового редактора, а поскольку я достаточно сильно изменил буфер текста VSCode и адаптировал его специально для fred, то назвал его fredbuf. Весь код и тесты можно посмотреть в репозитории fredbuf. Он не требует сторонних библиотек, так что сборка проходит очень просто. Редактор имеет лицензию MIT, так что можете экспериментировать! Улучшайте его так, как мне и не снилось! Для воспроизведения достаточно компилятора C++, поддерживающего C++20. Возможно, когда-нибудь я выпущу релиз fred.
Заключение
Чему я научился?
- Абсолютно необходимо заранее проводить исследования и определять ограничения. Не стоит тратить время на сложную структуру данных, чтобы после её мучительной реализации выяснить, что она не решает твоих проблем.
- Нужно создавать отладочные утилиты для структур данных на очень ранних этапах. Сомневаюсь, что завершил бы этот проект, если бы с самого начала не создал мощные отладочные утилиты.
- Удаление из неизменяемого красно-чёрного дерева — это сложно.

Комментарии (17)

semyong
26.06.2023 14:52+1Возможно кому-нибудь будет полезна старая статья про Gap Buffer - https://habr.com/ru/articles/197650/

Cheater
26.06.2023 14:52+1Копирование узла при записи подразумевает, что хотя стек undo будет содержать более легковесную версию исходного дерева, новое созданное дерево может увеличить общее потребление памяти намного больше, чем вы могли изначально думать.
ЯННП, может кто-нибудь объяснить, что имелось в виду под "записью" и "копированием узла при записи" и при чём тут потребление памяти, когда речь идёт о быстродействии?

domix32
26.06.2023 14:52Copy-on-write поведение. По-умолчанию копирования не происходит пока не начинается запись в некоторую позицию. Основная проблема что то самое copy может иногда оказываться не очень быстрым в зависимости от размера нижележащей структуры и соотвественно memory intensive, что может сказываться в том числе и на быстродействии.

DmitryKoterov
26.06.2023 14:52+2Если не ошибаюсь, современная память читается/пишется со скоростью около 20 ГБ/с. Это очень очень много. И возникает вопрос: а чего не брутфорсом-то просто делать, зачем структуру данных отдельную? Это точно не экономия на спичках при стрельбе из пушки по воробьям?

FreeNickname
26.06.2023 14:52Вам не доводилось редактировать многогигабайтные лог-файлы? Если у Вас лог-файл размером 1 Гб, скорость печати 420 символов в минуту, и Вы печатаете в середине файла, Вам, если совсем "в лоб", нужно будет выделять 7 Гб памяти в секунду (при общем занятом объёме в каждый момент времени 2 Гб: текущая версия и новая). Выглядит не очень практично :) А лог-файл ведь бывает и по 2 Гб. И по 3. А есть ещё всякие множественные курсоры. А это всё ещё нужно и отрендерить. И т.д.

event1
26.06.2023 14:52+2Простите за любопытство, но зачем кому-то может понадобится редактировать лог-файлы? Тем более, печатать в середине. Я просто всегда думал, что лог-файлы редактируются исключительно путём добавления записей в конец.
FreeNickname
26.06.2023 14:52+1Ну, я редактировал. Это может быть удобно, когда вам нужно отметить какой-нибудь фрагмент, или удалить нерелевантную часть, или что-нибудь в таком духе. Это не обязательно может быть файл с логами, просто я подумал о логах, т.к. сталкивался с этим.
Иными словами, чтобы облегчить себе чтение лога при разборе какой-то проблемы.
Естественно, если Вы этим занимаетесь на постоянной основе, у Вас, вероятно, будут какие-то специализированные инструменты (я даже для себя делал вспомогательные утилиты для работы с логами нашей компании), но зачастую гораздо проще и быстрее сделать это просто в текстовом редакторе. Но если текстовый редактор будет перевыделять память целиком на каждый символ, так, увы, не получится)

Zenitchik
26.06.2023 14:52+1Я обычно применял скриптовые средства, чтобы скопировать интересующую часть лога в отдельный файл, и редактировал её. Редактировать середину километрового лога, ИМХО, совмещение неприятного с бесполезным.
FreeNickname
26.06.2023 14:52Да, и так я тоже делал. И утилиты свои полноценные писал. И специализированным софтом для работы с логами пользовался. И регулярками лог преобразовывал. И редактировал лог-файл в том числе. Под каждую конкретную задачу – свой инструмент. Ну и под конкретного человека, на самом деле. Что быстрее / эффективнее – то и делаешь. У меня регулярно были случаи (да даже и всё ещё есть, хотя я уже давно не работаю с многогигабайтными логами), когда воспользоваться текстовым редактором для меня проще/быстрее. Отчасти, к слову, в силу того, что даже 10 лет назад на HDD работа с лог-файлом размером в 1-2 Гб не представляла проблем. Благодаря как раз оптимизации, вложенной в текстовые редакторы, включая грамотный выбор структур данных :)
DmitryKoterov
26.06.2023 14:52+1Многогигабайтный лог-файл только с диска займет прочитать минуту. Не говоря уж о записи. И в память не влезет, надо использовать memory-mapped files по любому. Какие уж там структуры данных…
FreeNickname
26.06.2023 14:52А, Вы про дисковую память? Я думал, Вы про оперативную) 20 Гб/с на consumer grade железе пока для постоянной памяти – много, если не брать всякие там flash RAID-массивы. В лучшем случае раза в 3 медленнее, и то с кучей оговорок. Или всё-таки про RAM?
Ну, тут ведь зависит от того, насколько "в лоб" делать. Я интерпретировал Ваше сообщение так: "Почему вместо каких-то заумных структур данных всё не хранить в одной строке, и перевыделять её при изменении?". По крайней мере, это самое brute force решение, которое пришло мне в голову. Если понял не правильно – мои извинения. Но, в любом случае, да, вот хотя бы в этом случае задачу "с нахрапа" не решить))

iuabtw
26.06.2023 14:52+2Многогигабайтный лог-файл только с диска займет прочитать минуту
На такое я люблю отвечать историей, как я однажды открыл 22Гб файл с XML данными (надо было на структуру глянуть, чтобы спарсить нормально) на двухъядерном компе с 4гб оперативы. ССД тогда в помине не было, но вим прожевал его секунд за 20, в нём легко работал поиск и прочие манипуляции с текстом.
Так что про минуту на чтение Вы явно загнули.

tenzink
26.06.2023 14:52+1CPU тоже очень-очень быстрый. Но зачем же пессимизировать программу заведомо неподходящим выбором структур данных. Хотя, интересно было бы посмотреть на бенчмарки.
iboltaev
Еще отлично должно подойти декартово дерево по неявному ключу. Immutable из коробки, полностью копировать дерево при вставке/удалении не нужно, а только O(logN) узлов, не будет проблем с undo/redo, легко пишется, все операции за O(logN)*
uszer
Подскажите редакторы, в которых можно ограничить используемый набор слов жёстко заданным словарём.
iboltaev
ну нету таких редакторов, и зачем ограничивать жестко заданным словарем?
uszer
Как вариант - стихи писать по методу турецко-подданного )