
И все мы выполняем его неправильно (в том числе и я).
Я должен признаться. Несмотря на то, что меня много раз нанимали в том числе и благодаря моему опыту работы с платформами мониторинга, я начал его ненавидеть. Инструменты мониторинга и наблюдаемости (observability) совершают тяжкий грех: обманом заставляют людей думать, что это простая задача. Очень легко мониторить маленькое приложение или сервис. Но почти ни одно из таких решений не масштабируется.
Вместо этого мониторинг превращается в бесконечную последовательность маленьких неудач. Метрики на какое-то время исчезают, логи перестают записываться на несколько часов, веб-UI для трассировок больше не работает. Мы настраиваем эти инструменты, готовясь, что сможем о них после этого забыть, но на самом деле они требуют постоянно растущих усилий по обслуживанию. Некоторые инструменты ломаются, и их больше никто не чинит. Я слишком часто приходил в новую компанию и видел, что в ней развёрнут нелюбимый мной поломанный Jaeger.
Такое ощущение, что сейчас как никогда много инструментов мониторинга, но вперёд мы не движемся. Похоже, вместо развития упор делается на увеличение объёма выходных данных приложений для роста доходов компаний, занимающихся мониторингом. Кажется, практически никакого прогресса не происходит с принципом передачи меньшего количества логов и метрик от клиента. Я создаю всё более сложные стеки для записи огромных объёмов данных, чтобы использовать их всё меньше и меньше.
В статье я расскажу о том, что, по моему мнению, нужно делать, а также поделюсь своими надеждами и мечтами. Прошу вас убедить меня, что я не прав и что есть более качественные решения.
▍ Логи
Кажется, что это хорошая идея, так ведь? Небольшие заметки, которые ты оставляешь для себя; они позволяют понять, что же происходит в системе. По моему опыту, поначалу это просто «сохранение на диск операторов печати». Вскоре такой подход перестаёт масштабироваться, потому что пространство на диске начинает занимать хранение бесполезной информации, которая пригождалась во время тестирования, а теперь никому не нужна. «Давайте использовать уровни логов». Отлично, теперь нам придётся запутаться ещё больше.
- Уровни логов ничего не значат
Уровни Syslog

Уровни Python

Golang

2. Неразбериха с форматами логов
- Логирование в JSON — легко парсить, однако вложенный JSON может ломать парсеры, а разработчики могут легко менять формат.
- Журнал событий Windows — куча данных, из документации непонятно, насколько он «стандартен».
- Common Event Format — хорошая спецификация (прочитать её можно здесь), но я никогда не видел, чтобы кто-то использовал этот формат за пределами компаний-производителей сетевого оборудования.
- GELF — очень хороший формат, спроектированный для удобной работы с UDP для логирования (что в некоторых крупных компаниях является обязательным требованием), но до написания этой статьи я ничего о нём не слышал. Почитать о нём можно здесь.
- Common Log Format — по сути, логи Apache:
127.0.0.1 user-identifier frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326 - Nginx Log Format —
log_format combined '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent ' '"$http_referer" "$http_user_agent"';
Не существует консенсуса даже в том, для чего предназначены логи
Традиционный подход заключается в том, при использовании отладки локально или в среде разработки, информация обычно отбрасывается (наверно, вам не нужно подробно знать, что приложение выполняет всё правильно), а всё, что выше этой информации, записывается в лог. Проблема в том (особенно это справедливо для современных микросервисов с распределёнными запросами), что часто логи — это единственное место, в котором мы с определённой долей уверенности можем сказать, что «знаем всё о происходящем внутри системы».
Часто бывает так, что к запросу добавляется заголовок с ID, например, UUID. Этот UUID возвращается конечному потребителю; именно благодаря этому служба поддержки может изучать запросы и определять, что происходило с клиентом в это время. То есть платформа логирования внезапно становится чем-то гораздо большим, чем системой записи операторов печати при авариях — теперь это основной инструмент, который используется для отладки всех проблем внутри платформы.
Это влияет на службу поддержки (что и когда сделал этот клиент), это влияет на требования к аудиту — требуется фиксация записей всех взаимодействий. Поэтому вскоре простое требование «отправляй всё, что находится поверх информации» превращается в гораздо более масштабный проект, в котором поиск по логам и инфраструктура их записи становятся крайне важными для системы. Это единственный способ добраться до первопричин произошедшего с конкретным пользователем или взаимодействием. Вскоре этот проект становится источником данных для бизнес-аналитики: логи оказываются источником истины о количестве полученных вами запросов или о том, использует ли новый клиент платформу и так далее.
Внезапно вашей очень простой системы становится недостаточно для этого, потому что теперь нельзя просто передавать по SSH запросы в машину для службы поддержки. Вам уже нужен какой-то дружественный интерфейс. Возможно, вы начнёте со стека ELK, однако управление Elasticsearch — это, на самом деле, огромное мучение. Вы пробуете SigNoz, и он работает, но теперь это новый критически важный элемент инфраструктуры, который часто забрасывают.
Есть вероятность, что это не чья-то постоянная работа, просто получилось так, что кого-то попросили заняться логированием. Это и не должно быть постоянной работой, поэтому я полностью понимаю такую ситуацию. Такой человек устанавливает несколько Helm-чартов, засовывает их за OAuth-прокси и просто надеется на лучшее. Но вместо этого он получает непрерывный поток жалоб от потребителей системы логирования. «Логов нет, поиск не работает, мой парсер возвращает не то, что мне нужно».
Логи начинают использовать как источник истины для business intelligence, инструмент службы поддержки, основной инструмент отладки, как способ понять, что развёртывание сработало и так далее. Я наблюдал подобный паттерн во множестве компаний, и часто на заявления о его хрупкости отвечают, что «пока всё работало вполне неплохо».
Не буду париться, просто засуну всё в облако/SaaS/хранилище объектов
Отлично, но поскольку вам нужна каждая строка логов, затраты растут с каждым новым клиентом. Это само по себе неприятно по множеству причин, однако если ваши приложения болтливы или у вас просто бывает множество запросов в день, то это может стать серьёзной проблемой. По моему опыту, компании не предвидят, что затраты на мониторинг приложения запросто могут превзойти затраты на хостинг приложения, даже в случае простых приложений.
Логирование всегда заканчивается одинаково. Рано или поздно вы: или добавляете какую-нибудь систему без логирования для важных запросов пользователей, или продолжаете пользоваться SaaS и агрессивно отслеживаете нагрузки, надеясь на лучшее, или поддерживаете полную сквозную архитектуру логирования, записывающую всё на диск, с которым вы работаете.
Логи как концепция имеют смысл, но не работают как реальный инструмент, если только вы не решили вкладывать время разработчиков на каждом цикле, чтобы поддерживать функциональность логирования ИЛИ если вы не готовы тратить кучу денег на поставщиков услуг. Кроме того, скоро ваши разработчики будут писать парсеры логов, чтобы создавать алерты в определённых ситуациях, что кажется нормальным, но затем логи становятся ещё более критичными, и теперь вам нужно внедрять обязательное использование стандартов логирования или преобразовывать старые форматы логов в новые.
Ещё одна проблема заключается в том, что логи слишком бесполезны, чтобы их хранить. 99,9999% из них никогда не пригождаются, при этом ни выглядят точно так же, как остальные; в конечном итоге вы навечно запихиваете их в хранилище объектов, в котором ни одно живое существо никогда не будет взаимодействовать с ними. Я слишком часто писал скрипты, с разными вариациями повторяющие действие «берём из А терабайты логов, на которые никто никогда даже не взглянул, и перемещаем их в Б». Хуже того: из-за стоимости применения инструментов наподобие Athena для доступа к огромным объёмам данных вы не захотите, чтобы разработчики искали в них информацию.
Мои предложения
- Если сообщения логов — это основной для вас способ мониторинга всей системы на основе микросервисов, то вам нужно тщательно их продумать. Сколько это стоит, как часто у них возникают проблемы, можно ли масштабировать решения? Можете ли вы обойтись без хранения логов?
- Если у вас есть лог, который обязательно нужно хранить из соображений комплаенса или по юридическим причинам, то не используйте ту же систему, в которой сохраняете каждую строку 200 — OK. Записывайте этот лог в базу данных (в идеале) или в хранилище объектов за пределами конвейера логирования. Я использовал для этого DynamoDB, и он неплохо справляется в конвейере SQS -> Lambda -> Dynamo. Ваше внутреннее приложение может выполнять запросы к ней, и вам не придётся заботиться о сроке жизни логов с DynamoDB TTL.
- Если вы не будете отдавать логированию высокий приоритет (что я очень уважаю), то вам нужно создать и внедрить низкий SLA. SLA в 99% — это 7 часов и 14 минут офлайна в месяц. В первую очередь это проблема руководства, но это означает, что вам придётся заставить людей отвыкнуть от наличия бесконечно надёжного источника истины.
- Вашей организации нужен более высокий SLA? Оплатите SaaS и запишите это в затраты на выполнение приложения. Важно как можно точнее привязать биллинг внешнего SaaS к каждому из приложений, чтобы вы смогли сказать конкретной команде разработчиков: «наблюдаемость вашего приложения стоит нам слишком много», а не просто «бизнес в целом тратит много на наблюдаемость».
- Ваш друг — сэмплирование. OpenTelemetry поддерживает сэмплирование логов как фичу альфы. Она поддерживает сэмплирование на основании приоритета, что для меня очень важно. Вам нужен определённый процент логов с низким приоритетом, однако в идеале с развитием сервисов можно постепенно снижать их количество.
- Если вам нужно написать регулярные выражения для их парсинга, то начинайте молиться своим богам, чтобы логи имели стабильный формат
Надежды и мечты
- Валидация схемы как компонент сборщиков логов JSON. Может показаться странным, что этого пока нельзя сделать, но у нас должна быть возможность выставить требования к поступающим в систему логам, обеспечив их соответствие схеме организации. Было бы здорово, если бы это можно было сделать в среде разработки, чтобы сразу было видно, что логи не приходят.
- Распространение использования сэмплированных логов. Я мечтаю, чтобы их можно было привязать их к развёртываниям, чтобы перед развёртыванием и спустя какое-то время после него можно было сохранять 100% логов. Сборщик делает вызов API, чтобы узнать обычное количество отказов приложения (количество 2xx, 4xx, 5xx), а затем, если приложение сохраняет это соотношение, то усиливает сэмплирование.
Мне нравится то, что делает GCP для flow logs:
Несмотря на то, что Google Cloud не перехватывает каждый пакет, записи логов могут быть достаточно большими. Можно сбалансировать видимость трафика и затраты на хранение, отрегулировав следующие аспекты сбора логов:
Интервал агрегации: сэмплируемые за временной интервал пакеты агрегируются в одну запись лога. Этот интервал может быть следующим: 5 секунд (по умолчанию), 30 секунд, 1 минута, 5 минут, 10 минут или 15 минут.
Частота сэмплирования: перед записью в Logging несколько логов могут быть сэмплированы для уменьшения их количества. По умолчанию объём каждой записи лога масштабируется на 0,5 (50%), то есть хранится половина записей. Можно установить значение в интервале от1.0(100%, хранятся все записи логов) до0.0(0%, логи не хранятся).
Аннотации метаданных: по умолчанию записи flow log аннотируются информацией метаданных, например, названиями исходной и конечной VM или географическим регионом внешних источников и конечных точек. Для экономии места аннотации метаданных можно отключить или включить только часть аннотаций.
Фильтрация: по умолчанию логи генерируются для каждого потока в подсети. Можно создавать фильтры, чтобы генерировались логи, соответствующие определённым критериям.
Я хочу, чтобы эти возможности были всегда и у всего.
▍ Метрики
Ну ладно, логи — это отстой с ужасным соотношением сигнал-шум. Вместо них, мы используем метрики. Отлично! Поначалу работать с метриками очень просто. Добавить совместимые с Prometheus метрики в приложение легко можно с помощью одной из клиентских библиотек. Вы заставляете Prometheus получать эти метрики, обычно при помощи какого-то регулярного выражения k8s regex или внутренней зоны DNS. Затем перед Prometheus вы вставляете Grafana, добавляете Login with Google, и уже можно работать.
Но ведь всё будет не так. На самом деле Prometheus спроектирован так, чтобы работать на одном сервере. Можно выполнять вертикальное масштабирование, добавляя новые метрики и целевые системы, но у такого роста есть конечный предел. Плюс при возникновении проблемы с Prometheus вы разом теряете наблюдаемость всего стека. А потом вам приходится проектировать систему под федерацию. На этом этапе обычно начинается паника и поиск того, кому бы заплатить за то, чтобы это было сделано.
Три варианта масштабирования
1. Использование иерархической федерации, при которой один сервер Prometheus скрейпит высокоуровневые метрики с другого сервера. Это выглядит так:

Происходит огромный скачок сложности. Раньше вы просто хранили всё и надеялись на бога, а теперь вам нужно понять, какие метрики важны, а какие не очень, как выполнять агрегации внутри Prometheus; нужно добавлять сторонний мониторинг для всех этих новых сервисов. Я такое проделывал, это осуществимо, но помучиться придётся.
2. Кросс-сервисная федерация, которая проще в настройке, но имеет собственные странности. По сути, изнутри это обычный Prometheus, из которого выполняет чтение более низкоуровневый Prometheus, и вы направляете всё на «основной» узел.
Такая архитектура работает, но требует много места на диске, а те же проблемы с мониторингом остаются. Плюс снова происходит большой скачок сложности (однако на практике оказывается, что управление на этом уровне сложности вполне реализуемо силами одного человека).

Мне нужна реальная сквозная платформа метрик и алертов
Мои примеры хорошо работают только для кратковременных метрик. По сути, можно масштабироваться до «размера диска машины», что на практике в условиях облака, наверно, приемлемо. Однако всё описанное выше рассматривалось с точки зрения потребления метрик как инструментов для разработчиков. Как и в случае с логами, когда метрики становятся более полезными, они становятся интересны вне сферы отладки приложений.
С их помощью можно отслеживать всевозможные аспекты в стеке и сравнивать такие параметры, как успешность маркетинговой кампании. «Нам нужно знать, почему у этого крупного клиента внезапно начали возникать 5xx, чтобы сообщить причину его менеджеру». «Можешь определить, что клиент перестал пользоваться платформой, чтобы мы знали, когда предлагать ему скидочный код?» На разных работах я слышал подобные просьбы.
Мне нужно много метрик, и навсегда
С течением времени необходимая длительность хранения метрик неизбежно увеличивается. Пользователям нужна более конкретная информация не только о сервисах, но также о клиентах и конкретных путях. Они хотят, чтобы были алерты об этих путях, чтобы они хранились вечно, и им нужна возможность выполнять всевозможные действия с метриками.
И тут ситуация начинает очень сильно усложняться.
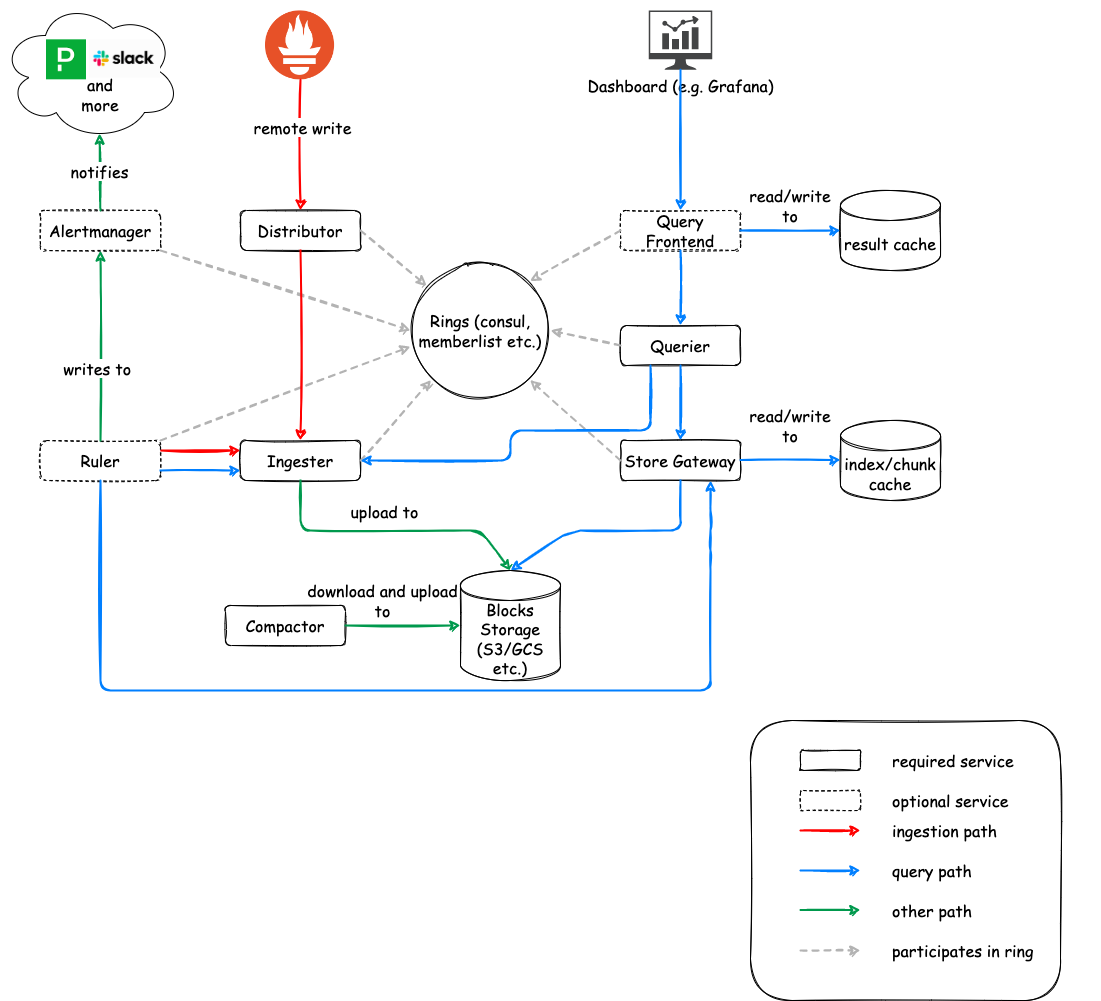
Cortex
Cortex — это пуш-сервис, позволяющий пушить в него метрики из стека Prometheus, а затем обрабатывать. У Cortex есть очень удобные возможности, например, устранение дублей входящих сэмплов с избыточных серверов Prometheus. Так что можно начать с набора избыточных Prometheus, настроить отправку в Cortex, а затем сохранять только одну метрику. Однако чтобы это заработало, необходимо добавить хранилище данных «ключ-значение». Вот все новые сервисы, которые мы добавляем:
- Distributor
- Ingester
- Querier
- Compactor
- Store gateway
- Alertmanager (необязательно)
- Configs API (необязательно)
- Overrides exporter (необязательно)
- Query frontend (необязательно)
- Query scheduler (необязательно)
- Ruler (необязательно)
Один раз я пользовался Cortex, он очень хорош, но для управления им требуется очень много работы. Если он взаимодействует с вашими серверами Prometheus, вам приходится управлять им, писать конфигурации и мониторить его, то всё это превращается в большой проект. Вероятно, стоит запускать его в выделенном кластере k8s или группе серверов.
Thanos

Цели схожи с целями Cortex, только архитектура другая. Это процесс-расширение, потребляющий метрики и перемещающий их при помощи более простой (на мой взгляд) модульной системы. Я только начал пользоваться Thanos, но мне показалось, что это довольно понятная система. Но всё равно поверх придётся добавлять довольно много для решения того, что изначально было довольно простой задачей. Однако из этих двух вариантов я бы порекомендовал Thanos, основываясь исключительно на простоте начала работы. Вот сервисы, которые вам придётся добавить:
- Sidecar: подключается к Prometheus, считывает его данные для запроса и/или загружает их в облачное хранилище.
- Store Gateway: обрабатывает метрики внутри блока облачного хранилища.
- Compactor: сжимает, даунсэмплирует и сохраняет данные в блоке облачного хранилища.
- Receiver: получает данные из журнала упреждающей записи Prometheus, передаёт их и/или загружает их в облачное хранилище.
- Ruler/Rule: применяет правила записи и алертов к данным в Thanos для их передачи и/или сохранения.
- Querier/Query: реализует Prometheus v1 API для агрегации данных из внутренних компонентов.
- Query Frontend: реализует Prometheus v1 API для его прокси-передачи в Querier, кэшируя ответ и опционально разделяя их по ежедневным запросам.
Это слишком сложно, я воспользуюсь SaaS
Отлично, но они дороги. И все правила логирования по-прежнему действуют. Нужно тщательно мониторить потребление и проверять, чтобы без причины не записывались метрики с большим количеством элементов. Часто при получении первого счёта пользователи испытывают шок, так что прежде чем использовать SaaS, выполните оценки и тесты.
Рекомендации
- С самого начала определите чёткий предел хранения метрик. Создаваемая вами система сильно будет зависеть от того, насколько долго вы будете их хранить. Лично я ограничиваю архитектуру из одного Prometheus тридцатью днями метрик. Я знаю людей, которые в федеративных архитектурах используют гораздо более длительные сроки, но я считаю, что полезно в качестве отправной точки использовать тридцать дней.
- Если метрики будут вашим основным инструментом наблюдаемости, то не останавливайтесь на полумерах. Будет намного сложнее апгрейдиться с системы с одним Prometheus, если от неё зависит весь бизнес, и даунтайм должен распространиться вверх и вниз по цепочке. Я бы с самого начала выбрал Thanos или Cortex, чтобы иметь гораздо большую гибкость, если вам потребуется хранить много метрик в течение долгого времени.
- Наметьте приемлемое конечное состояние. Если вы отслеживаете пугающее количество метрик, то для больших объёмов лучше подойдёт Cortex. Я знаю людей, хорошо управляющихся с Cortex при 1,6 миллиона метрик в секунду со всеми инструментами, которые у него есть для контроля и обработки такого количества данных. Однако если ваша цель — не объём, а долговременное хранение и доступность, то я бы выбрал Thanos.
- В отличие от многих, я считаю, что вам необходимо примириться с тем, что на работу с метриками у вас будет уходить много времени. Я никогда не видел полностью автономную систему, которая «просто работает» при больших объёмах без сумасшедшей стоимости. Системы нужно мониторить, изменять их потребление, настраивать конфигурацию, откатываться назад, и всё это занимает время.
▍ Трассировка
Логи дают понять, что в точности происходит, но имеют низкое соотношение сигнал-шум. Метрики отлично подходят для понимания происходящего, но не работают с бесконечным количеством параметров. На сцене появляется трассировка — популярная технология, которой уже пять лет. Трассировки решают множество описанных выше проблем, позволяя собирать огромные объёмы данных о запросах в стеке. Кроме того, они обеспечивают потрясающий мониторинг вне зависимости от типа платформы. Можно отслеживать запросы из приложения к балансировщику нагрузок, потом к бэкенду и микросервисам, и обратно.
Главное преимущество трассировки для меня заключается в том, что в ней изначально заложена концепция сэмплирования. Это инструмент для отладки и устранения неполадок, он не для комплаенса или бизнес-нужд. Поэтому он не испортился полностью со временем из-за того, что в него вставляют всевозможные странные требования. Трассировка позволяет выполнять сэмплирование очень безопасно, потому что она предназначена для устранения неполадок у разработчика.
Буду с вами откровенен, мой опыт настройки трассировки состоял в том, чтобы использовать SaaS и сконфигурировать трассировку. Чаще всего я работал с Cloud Trace. Она легко внедряется, контролировать затраты довольно легко, и мне нравится элемент для устранения неполадок.
Проблема с трассировками для меня в том, что их никто не использует. Когда я мониторю, как команды пользуются трассировками, то оказывается, что логинится для их использования всегда очень небольшая часть команды. Не знаю, почему этот инструмент не получил большей популярности среди разработчиков. Возможно, они больше привыкли к метрикам и логами, и не видят в нём ценности. Пока я не видел «правильных» реализаций трассировки.
Надеюсь, когда-нибудь ситуация изменится.
▍ Заключение
Возможно, я ошибаюсь насчёт мониторинга. Может быть, все остальные отлично справляются с ним и только я испытываю трудности. По моему опыту, мониторинг — это самый нелюбимый внутренний сервис. Он требует много работы, очень много стоит и никогда не приносит компании денег.
Выиграй телескоп и другие призы в космическом квизе от RUVDS. Поехали? ????

Комментарии (10)

cy-ernado
05.07.2023 16:08+2Можно еще посмотреть в сторону https://opentelemetry.io как попытку это все стандартизировать.

AnyKey80lvl
05.07.2023 16:08OpenTelemetry и т.п. закрывают малую часть задач мониторинга, в основном это всё крутится вокруг inject'а либ в приложение и сбора данных (транзакции, логи, метрики).
Но сбор/обработка трапов от сетевого оборудования или парсинг произвольных файлов для получения данных мониторинга никуда не денутся...

smarthomeblog
05.07.2023 16:08+1Попадалась статья про VictoriaMetrics. Как она в лучшую сторону отличается от того же Prometheus. Вот думаю попробовать хотя бы в качестве концепта.

citius
05.07.2023 16:08+3Виктория прекрасно и стабильно работает, при этом сильно экономит место засчет сжатия и дедупликации и умеет в отказоустойчивость, чего чистый Прометей не умеет.
Я прям удивился почему Cortex и Thanos в статье есть, а Виктории нет.
AnyKey80lvl
05.07.2023 16:08В статье много чего нет, например, Elastic Common Schema или Loki.
Victoria вообще в продакшне у многих уже давно.
Но в целом основные проблемы мониторинга подсвечены - сложно, нужно все продумывать. От себя добавлю, что между опенсорс тулами и платным софтом - пропасть. Нет опенсорс CMDB, нет коррелятора событий нормального, да даже простого поиска аномалий нет (opensearch не в счёт).

onyxmaster
05.07.2023 16:08+5никогда не приносит компании денег
Зато его отсутствие часто помогает деньги потерять :)


skyblade
05.07.2023 16:08А такие решения как zabbix, nagios, icinga уже совсем не модные что ли?
Как-то вообще не подсвечено, где им место в этих схемах.
А я сталкиваюсь с такими системами постоянно. Prometheus - это же больше для контейнеров всяких, но не всё же строится на них.AnyKey80lvl
05.07.2023 16:08+1Nagios и Icinga помирают медленно, но верно. В Европе распространён, правда, check_mk, который продолжает nagios-традиции.
А Zabbix - агентский/безагентский мониторинг, развивается и довольно широко применяется (хотя за пределами восточной европы не особо популярен кмк).
Не все задачи удобно/возможно закрыть Prometheu's ом.
Nikon_NLG
У Brian Brazil был хороший блог по поводу мониторинга (с уклоном на Prometheus конечно).
И в книге он неоднократно упоминал что собрать миллионы метрик - много ума не надо, а вот как с этим работать - отдельная головная боль, и просто "давайте на всё настроим alert" - плохая идея.
Да и сама по себе книга "Prometheus Up & Running" содержит немало идей для раздумья