
Перечисления (или размеченные объединения), отличающиеся вариативностью и, следовательно, размером, провоцируют в Rust серьёзную фрагментацию памяти. Дело в том, что нам приходится выделять достаточно данных, чтобы их хватило на самый крупный вариант.
Рассмотрим следующее перечисление:
pub enum Foo {
A(u8),
B(u16),
C(u32),
D(u64),
}Поскольку приходится предусматривать пространство, чтобы разметить и выровнять данные, этот тип имеет длину 16 байт.
Это очень мешает, когда приходится собрать очень много таких структур в Vec или HashMap. Справиться с заполнением можно, применив в той или иной форме преобразование структур в массивы (SoA); при этом для хранения метки выделяется отдельный участок. Но сократить фрагментацию вариантов уже гораздо сложнее.
Можно вручную выкатывать специализированные структуры данных для конкретного перечисления, минимизируя таким образом фрагментацию. Но, если попытаетесь унифицировать такую операцию, чтобы она была применима к любому произвольному перечислению с сохранением максимальной эффективности памяти, то увидите, что в Rust это практически невозможно. Единственный вариант в данном случае — воспользоваться процедурными макросами, которые плохо компонуются (работая с ними, нельзя применять ни #[derive] со сторонним кодом, ни псевдонимы типов). Кроме того, они не обладают информацией о типах (если только не прибегать к обходным манёврам с использованием generic_const_expr , но в таком случае граф вызовов засоряется пространными конструкциями where, а ещё не удаётся работать с обобщёнными параметрами типов). Zig, в свою очередь, позволяет преобразовывать структуры данных самым невероятным образом, и всё это делается лаконично и универсально.
Ниже перейдем к деталям реализации, но сначала я хотел бы объяснить, каков вообще прок от подобного снижения фрагментации памяти.
Контекст
На мой взгляд, разработка эффективных массивов перечислений во многом продиктована опытом работы с компиляторами. Есть проблема, то и дело всплывающая при проектировании абстрактного синтаксического дерева (AST): как бы выделить под это дерево поменьше памяти. Но, когда мы компилируем такие деревья, именно в этот период производительность сильно падает. Дело в том, что пропускная способность памяти и, соответственно, задержки — традиционное узкое место во фронтендах компиляторов. На форумах по языку Rust давно обсуждается видео о компиляторе Carbon от Чендлера Кэррата. В этом материале описано, что распарсенное абстрактное синтаксическое дерево clang может потреблять в 50 раз больше памяти, чем оригинальный исходный код, и такое в порядке вещей!
Хорошо, так как же это всё связано с перечислением? Что ж, чаще всего для представления узлов синтаксического дерева подбирается какая-нибудь рекурсивная (или рекурсивно-подобная) структура данных. Давайте определим узел для выражений в Rust, причём косвенность обеспечим при помощи индексирования новых типов:
enum Expr {
Unit,
Number,
Binary(Operation, ExprId, ExprId),
Ident(Symbol),
Eval(ExprId, ExprSlice),
BlockExpression(ExprId, StatementSlice)
}Примечание: для сравнения рассмотрим, как можно написать узел AST на языке OCaml:
type expr =
| Unit
| Number
| Binary of op * expr * expr
| Ident of symbol
| Eval of expr * stmt listСерьёзное отличие от Rust состоит в том, что здесь мы без какой-либо явной косвенности можем выражать по-настоящему рекурсивные типы данных. Дело в том, что здесь нам не приходится вести учёт памяти — за нас это делают среда времени исполнения и сборщик мусора.
Теперь наша задача сводится к тому, что хочется повысить эффективность упаковки этих перечислений. Простой Vec(Expr) будет потреблять память в объёме sizeof(Enum) на каждый элемент, что соответствует размеру наибольшего варианта + метка + отступ. К счастью, есть способы с этим справиться.
Сокращение фрагментации
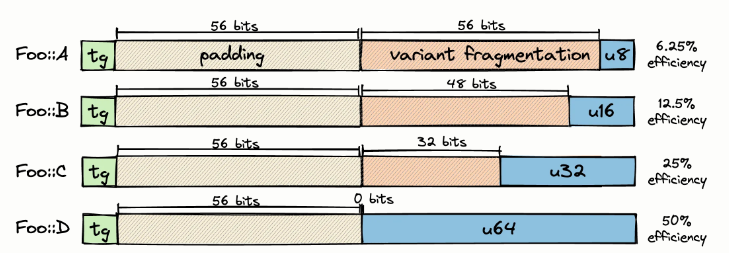
Рассмотрим простой пример с 3-вариантным перечислением, в которое входят элементы размером 8, 16 и 32 бита. Если хранить их в обычном Vec, то получится такая картина:
Рис. 2: Здесь под каждый элемент резервируется достаточно места, чтобы на каждом участке помещался 32-разрядный вариант, и при этом выполнялись требования к выравниванию.

Самый распространённый способ повысить эффективность упаковки — просто следить, чтобы варианты перечислений были как можно меньше; это делается при помощи размеченных индексов (*).
(*): Если вас интересуют подобные примеры из Rust, взгляните на крейт tagged_index, применяемый в компиляторе, а также ознакомьтесь с этим свежим постом об оптимизации строк. Такие оптимизации постоянно попадаются в высокопроизводительном коде, используемом, например, в языковых средах выполнения, сборщиках мусора, компиляторах, игровых движках или ядрах ОС.
К сожалению, всё это не решает проблему фрагментации окончательно. Зайдём с другой стороны — попробуем поработать напрямую с типом контейнера! Можно было бы воспользоваться подходом «структуры из массивов», чтобы хранить дискриминант и значение в двух разных регионах. На самом деле, именно так и делается в компиляторе Zig.

Рис. 3: Метки и значения объединений хранятся в двух разных регионах, поэтому отступы более можно не учитывать. Правда, здесь в коллекции объединений по-прежнему наблюдается фрагментация вариантов.
Поскольку в Zig применяется поэтапная компиляция, здесь у нас могут быть как раз такие контейнерные типы, которые в обобщённом виде обеспечивают такое SoA-преобразование для любого типа. В Rust приходится удовлетвориться процедурными макросами, например, soa_derive , а у них есть определённые недостатки. Например, нельзя ставить #[derive] на сторонние типы, не меняя при этом их источника).
Сокращаем фрагментацию вариантов
При таком SoA-преобразовании удаётся в значительной степени избавиться от лишних заполнений, возникающих при работе с метками перечислений, но этот вариант не оптимален. Чтобы как следует избавиться от фрагментации значений, можно создавать по одному вектору на каждый вариант.
Рис. 4: По сравнению с предложенной выше SoA-компоновкой, здесь мы получаем частичный, а не полный порядок. Поэтому, как только произойдёт вставка, мы возвращаемся к размеченному индексу, где содержится как метка перечисления, так и номер в конкретном массиве вариантов.

Не думаю, что эта коллекция как-то называется, поэтому назову её массив вариантных массивов (или AoVA). Такую структуру можно реализовать и в Rust, и в Zig. В первом для реализации нам понадобятся процедурные макросы, а во втором — выполнение кода во время компиляции (comptime).
Классы эквивалентности размера
На этом можно было бы остановиться, но давайте рассмотрим перечисления, в которых очень много, и эти варианты можно сгруппировать в небольшое множество кластеров, где все типы имеют одинаковый размер:
enum Foo {
A(u8, u8),
B(u16),
C(u16),
D([u8; 2]),
E(u32),
F(u16, u16),
G(u32),
H(u32),
I([u8; 4]),
J(u32, u32),
K(u32, (u16, u16)),
L(u64),
M(u64),
N(u32, u16, u16),
O([u8; 8])
}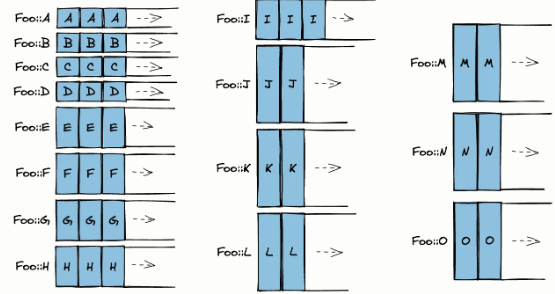
Как видите, при подходе «один вектор на вариант» получится в сумме 15 векторов. Вероятно, что количество (повторных) выделений и системных вызовов весьма возрастёт, и для его амортизации потребуется очень много памяти по сравнению с обычным Vec. Кроме того, векторы могут быть произвольным образом распределены в памяти, а из-за этого возрастает вероятность конфликтов в кэше. Коллекция AoVA как таковая также потребляет очень много памяти, и поэтому сильно раздувает любую структуру, в которую встраивается.
Теперь, если сгруппировать все варианты по размеру, то получится три кластера: по 2, 4 и 8 байт. Такие кластеры могут выделяться вместе в рамках одного и того же вектора — тем самым суммарное количество векторов, содержащихся у нас в контейнере, сокращается на 80%. Так, вполне реально сохранить варианты Foo в трёх кластерах:
struct FooVec {
c_2: Vec<[u8; 2]>, // A - D
c_4: Vec<[u8; 4]>, // E - I
c_8: Vec<[u8; 8]>, // J - O
}
Можно было бы сказать, что это плотная версия нашего паттерна AoVA. Но, если мы попытаемся компактно разместить различные варианты в одной и той же выделенной области памяти, то больше не сможем перебирать вектор типобезопасным образом. Добраться до элементов в таком контейнере можно было бы лишь при помощи меченого указателя, который был создан в момент вставки. Если при том паттерне доступа, которым вы пользуетесь, слепая итерация не требуется (так может обстоять дело с уплощёнными древовидными структурами, выстраиваемыми на основе индекса), то такой компромисс, возможно, оправдан.
Я реализовал прототип такой структуры данных на Zig. Здесь наиболее важны встроенные элементы компилятора, обеспечивающие рефлексию при работе с типами полей, байтовыми и битовыми размерами; также они позволяют проверять дискриминант.
Листинг: в сущности, этот код выполняет обычную рефлексию во время компиляции, что позволяет нам вычислять кластеры и отображения полей на кластер. Мы выполняем псевдодинамическое выделение памяти, пользуясь вектором, выделенным в стеке. На основе информации о кластере конструируется структура данных AoVA. Весь исходный код находится здесь.
// определить, что за тип перед нами (напр., структура, объединение, т.д.)
switch (@typeInfo(inner)) {
.Union => |u| {
// сохранить отображение с поля объединения на индекс кластера
var field_map = [_]u8{0} ** u.fields.len;
// перебрать поля объединений
for (u.fields, 0..) |field, idx| {
// вычислить размер
const space = @max(field.alignment, @sizeOf(field.type));
// вставить в хеш-таблицу
if (!svec.contains_slow(space)) {
svec.push(space) catch @compileError(ERR_01);
}
field_map[idx] = svec.len - 1;
}
// вернуть кластеры
return .{ .field_map = field_map, .sizes = svec };
},
else => @compileError("only unions allowed"),
}Если вы хотите организовать типобезопасный перебор, то можно добиться этого, раскошелившись на заполнение, и поставить метку обратно:
Рис. 5: В сущности, мы сегментировали перечисление на уровне данных, а интерпретацию на уровне типов оставляем нетронутой

Если отступы занимают слишком много места, то преобразование SoA можно проделать с каждым из вариантных массивов.
Рис. 6: Здесь показан похожий вариант сегментирования, но без отступов. Недостаток в данном случае в том, что мы удваиваем количество векторов.

Вот, как видите, здесь приходится соглашаться на много компромиссов — и все они зависят от того, как именно конкретное перечисление расположено в памяти.
Притом, что создавать такие структуры данных в Zig не составляет труда, в Rust, напротив, воспроизвести эти примеры при помощи процедурных макросов практически невозможно. Дело в том, что процедурные макросы не имеют доступа к информации о типах, например, каковы у них размер и выравнивание. Да, процедурный макрос можно заставить генерировать const fn, вычисляющий кластеры для конкретного перечисления, но при помощи этой функции нельзя указать длину массива для обобщённого типа.
Другое ограничение, присущее дженерикам Rust, таково: из того, как реализован типичный контейнер, не проистекает, является ли данный тип перечислением или структурой. В Zig же мы легко можем сделать нечто подобное:
// это псевдокод
struct EfficientContainer<T> {
if(T.isEnum()) {
x: EfficientEnumArray<T>,
} else {
x: EfficientStructArray<T>,
}
}Также можно конкретизировать, какова разновидность нашей реализации AoVA, основываясь на перечислении. Может быть, польза от совместного размещения различных вариантов начинает становиться целесообразной только на том этапе, когда количество векторов удаётся снизить более чем на 90%.
В конце концов, так удаётся в значительной степени и с большой детализацией контролировать подбор структур данных. А если у нас хорошо с эвристикой, то можем доверить эту работу механизму стейджинга, учитывающему типу — пусть выбирает наилучшую реализацию за нас. На мой взгляд, это огромное достижение в области компонуемости при работе с высокопроизводительным системным ПО.
Бонус: как определить битовую ширину индекса во время компиляции
Занимаясь реализацией прототипа, я подметил и другие способы сэкономить память. Например, если вы уже во время компиляции знаете максимальную мощность вашей структуры данных, то можете передать эту информацию той функции, что конструирует типы, и тогда она сможет определить битовую ширину возвращённого размеченного индекса.
Когда этот размеченный индекс включается в последующую структуру данных, например ещё в одно перечисление, информация, естественно, перетекает туда, а те разряды, которые нам не требуются, можно использовать для дискриминанта!
Итак, Zig позволяет добиться эффективности при компоновке памяти. Конкретно указывая, какие биты тебе нужны, можно пользоваться ими в различных частях кода. А при неявном расширении, вызванном приведением целых чисел, работа с API разной битовой ширины остаётся эргономичной. В каком-то отношении эта практика весьма напоминает мне уточнение типов и работу с диапазонами целых чисел (ranged integers), поэтому данная тема сильно перекликается с моим постом о самостоятельном подборе битовой ширины для целых чисел.
Заключение
В Rust не всегда удаётся писать высокоэффективные обобщённые структуры данных. В некоторых случаях из-за этого в код привносится огромная избыточная сложность, а бывает и так, что подобные структуры данных, в сущности, нереализуемы. Думаю, один из важнейших выводов, который я делаю из работы с поэтапной компиляцией — это широкие возможности влиять на компоновку памяти. Если вы разрабатываете язык для системного программирования, отличающийся эффективностью и содержащий бесплатные абстракции — то вам определённо следует присмотреться к поэтапному программированию и выполнению кода во время компиляции, принятым в Zig.
Комментарии (48)

nin-jin
12.10.2023 12:13+4Не понял, как вы так волшебным образом перешли от одного упорядоченного массива к нескольким плотным (не разреженным) массивам.

NN1
12.10.2023 12:13+3Это перевод.
Автор исходного текста открыл для себя что вектор структур менее выгоден по памяти чем набор отдельных векторов с полями структуры.
nin-jin
12.10.2023 12:13+2Если бы речь шла про структуры, то вопросов бы не было, но речь про объединения. А их вот так вот разделять совсем не выгодно - остаются огромные дырки.

domix32
12.10.2023 12:13Так суть та же - енам фактически это тег + структура. Речь в первую очередь идёт про вектора перечислений. И их выгоднее в определённых ситуациях перераскладывать на структуру массивов. Правда кейс получается несколько специфичный в любом случае.

orekh
12.10.2023 12:13Я в Zig не разбираюсь, но насколько понял по приведенному коду, там нет сквозной индексации: Метод append выплевывает индекс в виде кортежа (тег типа + индекс для конкретного типизированного массива), и только по этому тегированному индексу можно сделать get. Так что это не вектор, а куча enum-ов.
domix32
12.10.2023 12:13На самом деле вы пользуетесь им как обычным массивом и не думаете про все эти кортежи. Компилятор всё делает за вас.
NN1
12.10.2023 12:13Я полагаю и на Rust можно провернуть такое через.
По умолчанию текущее поведение вполне ожидаемо учитывая, что так работает во всех других языках.
domix32
12.10.2023 12:13У компилятора раста пока только автоматический packing структур есть в оптимизациях, когда поля структуры перемешиваются, чтобы занимать как можно меньше места. Механизмов AOS <> SOA в компилятор пока не завезли, хотя были некоторые обсуждения на форуме. Microsoft кстати по этому поводу презентовал свой язык.
По умолчанию текущее поведение вполне ожидаемо учитывая
Тут возникает вопрос что вы зовёте другими языками, ибо большинство языков с алгебраическими типами в виде enum это с десяток модных молодёжных языков, включая тот же Rust и несколько старичков вроде Haskell/OCaml с их GC, где про оптимизации подобного рода стали задумываться относительно недавно. Остальное большинство же имеет обычные целые числа в качестве enum, а всякие data-oriented layout крафтились через такую-то матерь и собственные препроцессоры кода.
NN1
12.10.2023 12:13Я имел ввиду скажем C/C++ где просто делаем variant , аналогично дела обстоят и в C#/Java когда мы эмулируем алгебраические типы.
orekh
12.10.2023 12:13+1Я не вижу в той реализации способа проитерироваться по элементам этого массива в том порядке, в котором они были добавлены.
Можно конечно самому сохранять тегированные индексы в отдельном массиве, но в этом упоощенном коде такого нет.
domix32
12.10.2023 12:13С точки зрения пользователя языка - ничего не поменялось. Делаешь также `for item in array` и трогаешь поля как тебе хочется. Компилятор сам все индирекции посчитает и подставит. Просто теперь память всё это дело будет занимать поменьше, чем при автоматическом выравнивании памяти.
NN1
12.10.2023 12:13+1Я полагаю вопрос был о том как мы в таком же порядке итерируемся как при массиве.
У нас получается либо общего порядка больше нет. Он есть относительный в каждом отдельном массиве, но не общий.
Либо мы как-то храним этот порядок, но тогда это увеличивает расход памяти обратно, а также такой перебор будет совсем не эффективным из-за постоянных прыжков между массивами.
domix32
12.10.2023 12:13Индирекции, особенно на больших данных, получаются дешевле чем промахи кэша из-за постоянной необходимости выравнивать куски памяти. Плюс SOA часто позволяет срабатывать автовекторизации, за счёт чего влияение скачков нивелируется ещё сильнее. Правда не знаю насколько у Zig этот механизм развит. LLVM такое умел, но с ним вроде развелись.
Но вообще да, в среднем ECS подход имеет некоторые накладные расходы, которые дают выигрыш на бОльших данных и головную боль на небольших.
Kelbon
Будем честны, в расте невозможно писать структуры данных, особенно эффективные. Там даже строку не смогли реализовать хорошо из-за языка
А на С++ описанное в статье пишется и довольно просто
https://github.com/kelbon/AnyAny/blob/main/include/anyany/variant_swarm.hpp
Причем расширяемее чем в zig
IgnisNoir
А можете пояснить что не так со строками в раст? Хотелось бы для себя узнать больше
Tesserust
Вообще строки в Rust появились вопреки, а не почему. Тип
Stringпод капотомVec<u8>, то есть вектор байт. Есть ещё&str- строковый слайс. Обычно, когда говорят про строки в Rust, имеют в виду эти 2 типа.Если
Stringможет быть мутабельным,то&strизменить напрямую никак нельзя.Есть ещё такая особенность: вы не можете индексировать строку.
fn main() {
Этот код не может быть скомпилирован, будет ошибкаlet my_string1 = "45456456";
let my_string2 = String::from("45456456");
println!("{}", my_string1[0]);
println!("{}", my_string2[0]);
}
error[E0277]: the type str cannot be indexed by {integer}Всё это следствие безопасности языка.
P.S.: поправьте меня, если я не прав.
IgnisNoir
Понял спасибо. Но в целом непонятна претензия к индексации строки. Ведь то что вы показали это валидный UTF-8 и к нему индексация символов неприменима так как это не константная операция по массиву. И это не следствие безопасности языка, а следствие того что это UTF-8 и один символ может кодироваться несколькими байтами. Взять определенный символ по индексу возможно, но для этого надо будет пройтись по массиву символов my_string.chars().nth(0)
Но и не понимаю претензию к тому что это вектор байт...ведь...строуки это и есть массив байт...разве нет?
Я не фанатик раста, я вообще его плоховато знаю. Так что не примите пожалуйста за попытку защиты языка. Я как раз наоборот пытаюсь для себя лучше его понять
Kelbon
они не "индексируются" потому что они юникодные, а там длина символа переменная
Arkasha
В QString как-то работает. Только там как бы QChar
IgnisNoir
там подозреваю просто перегрузка оператора идет и внутри такой же перебор идет
DrSmile
У QString индексирование легко может вернуть половину суррогата, так что именно что "как-то". QString — это тяжелое наследие времен UCS-2, которое с горем пополам расширили до UTF-16. Давно уже пора бы его закопать и переходить на UTF-8. Даже в WinAPI, спустя всего 20 лет, добавили поддержку!
NN1
Внутри всё равно UTF-16. Поэтому вызов UTF-8 будет не таким уж эффективным.
andreymal
Зато
my_string1[0..1]уже скомпилируется. Безопасность тут ни при чём, это всего лишь следствие использования кодировки UTF-8domix32
На самом деле строковых типов сильно больше и многим это даже не нравится. Это не проблема безопасности, но вполне себе показывает, что строки не настолько просты насколько хотелось бы - там utf, сям cp866, трям какой-нибудь legacy CJK-JIS. В этом смысле стандартная библиотека явным образом делает основной тип строк валидным utf-8 как один из хороших дефолтов.
Ну и если подумать, то выяснится, что буквально всё в структурах это вектор байт, просто в С/С++ отродясь не было честного байтового типа и был только
char*. Так что очень странная претензия.Kelbon
и чем же вас не устраивает char как байт? В С++17 есть даже std::byte, который в общем то только именем от char отличается
domix32
Например, наличием signed/unsigned char. std::byte относительно недавно появился, а в Си в честном виде его так и не завезли. std::byte не символьный и не арифметичесский тип, что как минимум на уровне шаблонов имеет значение. Но, да, кому нужны все эти модные штуки, когда есть
(unsigned char*)(void*)vabka
Это не следствие безопасности, а следствие того что UTF-8.
Очень хочешь получить бессмысленный кусок code point? Да пожалуйста - можешь бесплатно преобразовать String обратно в Vec или &str в &[u8]
Хочешь бесплатно индексироваться по символам - переходи на Ascii / UTF-32 не удивлюсь, если уже кто-то типы для таких строк создал (ну для ascii точно есть в std) - в общем в любую кодировку с фиксированным размером байтов.
art1z
Их там 7 видов - https://zerotomastery.io/blog/how-strings-work-in-rust/#The-7-different-Rust-string-types
Круче только VB с его Null, Empty и Nothing
IgnisNoir
Спасибо, вот это интересное чтиво было) Но наверное это следствие его низкоуровневости и попытки беопасно работать везде?)
NN1
Для удобной работы с Windows побольше надо будет :) windows-rs strings
domix32
Это не столько с Windows, сколько с winapi-rs. Но там и без этого уже всё в unsafe завёрнуто.
Kelbon
Ну, во первых они юникодные по умолчанию и других нет, что зачастую приводит к потере перфа на пустом месте, а во вторых для хорошей реализации обычно используют self -reference типы, а в расте такое невозможно, потому что все типы "муваются" только через memcpy
Ну и они нерасширяемые никак - только такая String и ничего больше. Для сравнения можно глянуть на С++ строку, где и аллокатор и трейты (поведение строки, типа кейс интенсив и тд) кастомизируются, как и тип символа
IgnisNoir
А почему это плохо что они по умолчанию юникод? По моему in general как раз в большинстве случаев и используется везде юникод, а там где нужен не юникод ситуаций сильно меньше. Так что тогда можно и сделать не юникод строку отдельно.
А можете пояснить на счет self reference типов пожалуйста?
Kelbon
потому что других нет. Возьмёт новичок и пойдет делать задачу на литкоде, строку перевернуть. А ему бах и все юникодные "прелести" в лицо, наверное на этом он язык и забросит
в С++ внутри строки есть указатель на массив символов, в зависимости от длины строки он либо указывает в динамическую память, либо внутрь самой строки, поэтому для маленьких строк(которых большинство) динамическую память выделять не нужно(и эффективность не теряется т.к. для доступа всегда достаточно перейти по указателю). А в расте
* непонятно как через лайфтаймы выразить что объект сам на себя ссылается
* если даже получится, то мувать объект будет нельзя, потому что в расте не предусмотрено ничего кроме копирования байт в новое место(а это сломает self-reference объект)
IgnisNoir
На счет литкода аргумента не понял. Тот же го тоже имеет юникод строки по умолчанию. И не вижу в этом проблемы и также легко юникод реверсил когда был джуном. Не понимаю что должно оттолкнуть и в чем проблемес.
А на счет self reference спасибо!
Kelbon
go является языком для бац-бац и в продакшн, а раст позиционирует себя как нечто системное и даже фундаментальное. При этом буквально в язык пихнуть формат строк, который далеко не идеален и через несколько лет может исчезнуть - ну это просто так не делают
andreymal
Ну, когда понадобится «исчезнуть» — выпустят новый edition, в котором изменят поведение строковых литералов и подсунут в prelude новую реализацию String, и в целом ничего страшного не произойдёт (хотя экосистеме понадобится какое-то время для переката, но нам не впервой — вон призрак UCS-2 нас уже лет тридцать преследует)
Cerberuser
https://lib.rs/crates/smol_str, https://lib.rs/crates/smartstring - навскидку.
То есть, всегда требуется переход по указателю? Тогда, по идее, это всё ещё не оптимальный вариант для маленьких строк, можно лучше.
Kelbon
интересно как вы без перехода по указателю сделаете доступ к строке. И там указатель который указывает буквально на следующий за собой байт, т.е. это мгновенное попадание
vabka
ну очень маленькие строки (например четыре буквы на английском в utf-8) можно передать как одно машинное слово вообще без indirection.
Четыре или три буквы - вполне реальные в мире строки. Например это могут быть тикеры для биржи.
Kelbon
мы говорим не про 4 байтика, а про строки. Для них лучше чем переход по указателю без ветвления придумать ничего нельзя(компилятор может оптимизировать этот переход по указателю, если на компиляции доказал, что строка < SSO size)
domix32
Та ну я вас умоляю.
s.chars().rev().collect::<String>не невесть какая магия.Kelbon
и это в тысячу раз неэффективнее чем переворот ASCI строки
domix32
Так вы за юникод говорили, причём тут ASCII? Разверни какой-нибудь "ふすむすぁしぺど" как ASCII по байтам и получишь грязи, а не "どぺしぁすむすふ", так что в плюсах точно кому-то прилетят юникодные прелести.
Если вас интересует только ASCII диапазон, то часто проще сразу в байты всё это дело перевести и работать с байтами.
AnthonyMikh
О да, способность решать задачи на Leetcode (с, кстати, крайне кривыми сигнатурами на большинстве языков) — это действительно очень репрезентативная метрика юзабельности языка.
C++ тут, кстати, не лучше — как на нём обратить строку
"Привет, мир", например?И, кстати, я всё ещё не видел случая, когда переворот строки является реальной задачей.
Kelbon
Придираться к примерам, игнорируя проблемы языка - как это по растовски
domix32
Self-Reference типы это для Cow-строк? Так и в плюсах и ЕМНИП в 11 стандарте ещё из дефолтного поведения убрали.
Kelbon
Казалось бы, причём тут cow