
Всем привет!
В этой статье я расскажу о том, как можно увеличить размер запроса к ChatGPT до почти полутора миллионов символов!
При этом нам не понадобятся какие-то дополнительные средства – применять данный способ сможет каждый (ссылки на коды будут в конце статьи) прямо в самом чате.
Для начала пару слов о себе и о том, зачем мне вообще это понадобилось.
В самой IT области я уже довольно давно (начинал еще с DOS-овских программ на C в далеком 2000м), занимался разными профилями, в том числе меня интересовало ИИ.
Лет 7-8 назад, когда я сделал себе проект «умной квартиры» (9 модулей, контроль освещения, полива, климата, музыки и пр.), я решил внедрить туда голосового помощника. Название, кстати, выбрал по итогу Алиса – любимое женское имя.
Причем, выбирал из многих, вариантов ("Джарвис", увы, распознавался очень плохо), оказалось, фонетически слово «Алиса» распознается почти без ошибок и гораздо лучше других. Кстати, где-то через год появилась Алиса у Яндекса – поэтому я думаю, что они тоже имя взяли не с бухты-барахты, а проводили фонетический анализ.
Квартира просуществовала несколько лет, но за это время помощника я особо не развивал, да и не было больших ресурсов для обучения чего-то действительно умного.
С появлением БЯМ идея создания помощника заиграла новыми красками =)
Сейчас я хочу уже не просто чат-бота, который может решать широкий спектр задач. В принципе, эта идея родилась уже давно, но с помощью сегодняшних БЯМ, думаю, ее будет куда проще реализовать.
Несмотря на мой научный скепсис, как человека, написавшего не одну нейросеть с нуля, относительно интеллекта у ИИ, наши диалоги с ChatGPT произвели на меня впечатление.
Мне очень импонировала «человечность» этой БЯМ.
Поэтому я хочу создать своего помощника на основе именно ChatGPT, а не просто сделать свою модель с OpenAI API. Тем более, что таких объемов данных, что используются для тренировки ChatGPT у меня физически не может быть.
В целом, «план» примерно такой:
Увеличить память ChatGPT для возможностей реализации больших проектов.
Написать программные модули для расширения функционала ИИ-помощника с помощью самого ИИ-помощника
Спроектировать и создать (корпусные детали можно распечатать на 3д принтере, например) тело в реальности для ИИ-помощника.
Перенести программу ИИ-помощника в это «тело»
В итоге должен получиться антропоморфный робот с ИИ, который может выполнять не только программные, но и задачи в реальном мире.
Первая «преграда» на пути встала довольно быстро.
Это – ограниченная память ChatGPT.
Диалоги могут быть очень длинными, но практика показывает, что «помнит» он только последние несколько десятков тысяч символов из этого диалога.
Вроде как в платной версии GPT-Turbo размер запроса увеличили до 128000 но это все равно мало для больших проектов.
Итак, задача следующая: как в запрос в 4000 (8000 в GPT4) уместить гораздо больше информации, чем просто 4000 символов текста?
Звучит «невозможно», на манер задачи – «как вырезать в листке бумаги дырку больше чем сам листок?». Но именно невозможные задачи решать интереснее всего =)
Первое, что пришло в голову – конечно же, раз ChatGPT кушает txt файлы, просто скормить ему txt с миллионом символов и спрашивать по нему.
Оказалось, что текст из txt он воспринимает также, как текстовый запрос – то есть больше этого окна он прочитать не сможет. Экспериментально определенный буфер «окна памяти» совпал с тем, который дает на соответствующий запрос сам чат – 10000 символов.
Также ChatGPT кушает картинки и PDF.
Но самое главное для нас – он умеет распознавать текст и изображения.
А значит и текст с PDF.
И если мы создадим PDF, заполненный только текстом, по идее, ChatGPT должен его распознать (спойлер: еще как распознал)
Этапы следующие:
Получить ссылку на диалог с ChatGPT
Сохранить диалог в файл
Сгенерировать из этого файла PDF с текстом
Отправить полученный PDF в ChatGPT для распознавания и провести тесты
Получение ссылки на диалог с ChatGPT
Для получения ссылки на диалог воспользуемся встроенными средствами.
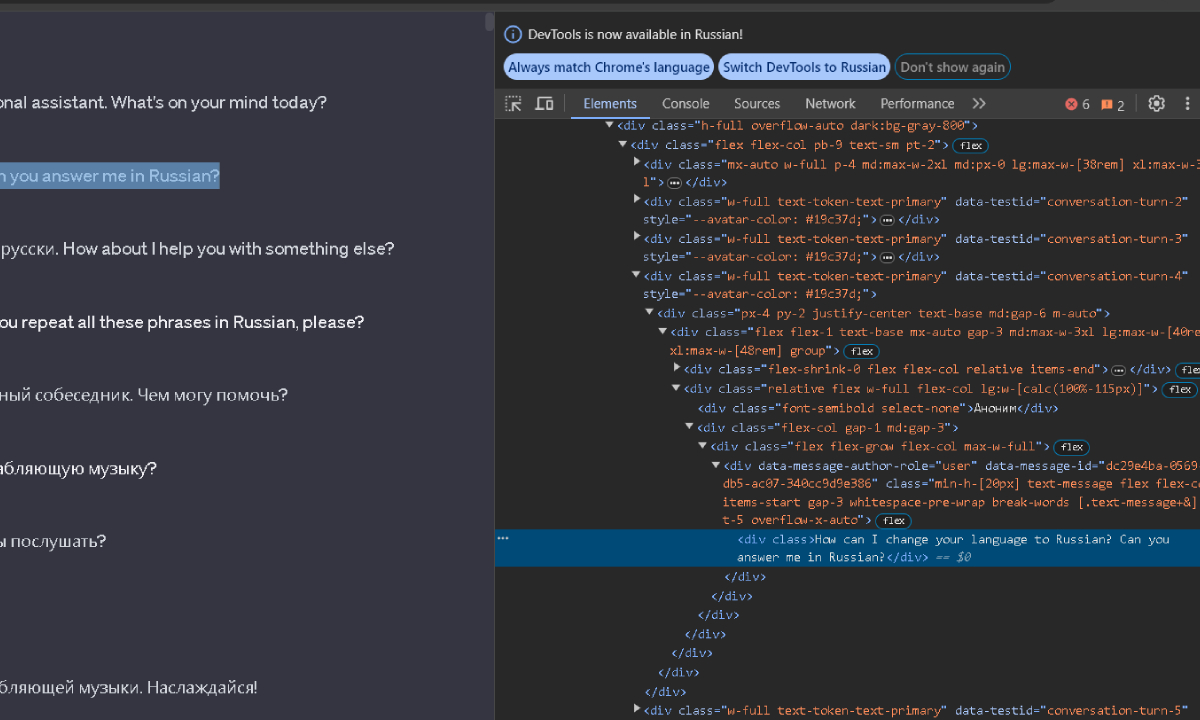
Откройте сайт https://chat.openai.com/ и слева в списке диалогов выберите тот, для которого хотите сохранить текст. В углу рядом с названием диалога будут три точки, щелкаем на них и выбираем «поделиться»:

Далее, в открывшемся окне щелкаем на «скопировать ссылку» (если ссылка на диалог уже есть, нужно сначала удалить прошлую и затем создать новую) и получаем адрес ссылки, по которой у нас будет весь текущий диалог.

Сохранение диалога в файл
Так как ссылка представляет собой веб-страницу, будем парсить с нее диалоги в текст.
Для этой задачи я использую Python и библиотеку Selenium (эмулирует веб-браузер) для работы с web.
По ней уже написано много статей, так что буду считать, что читатель с ней знаком.
С помощью анализа кода страницы легко находим контейнеры, в которых лежат фразы из диалогов и пишем скрипт по их вытаскиванию в текст:
def download_and_save_dialogues(file_path, eliraurl, window_width, window_height, window_x, window_y):
dialogue = []
options = Options()
driver = webdriver.Chrome(options=options)
driver.get(eliraurl)
# Получение всех контейнеров сообщений
message_containers = driver.find_elements('css selector', 'div.w-full.text-token-text-primary')
# Обработка контейнеров сообщений
for container in message_containers:
# Поиск контейнеров с фразами пользователя и ассистента
user_message = container.find_elements('css selector', 'div[data-message-author-role="user"]')
assistant_message = container.find_elements('css selector', 'div[data-message-author-role="assistant"]')
# Если найден контейнер с фразой пользователя, добавляем в словарь с префиксом "U:"
if user_message:
dialogue.append("U:" + user_message[0].text.strip())
# Если найден контейнер с фразой ассистента, добавляем в словарь с префиксом "A:"
if assistant_message:
dialogue.append("A:" + assistant_message[0].text.strip())
# Закрытие браузера
driver.quit()
# Сохранение словаря в файл с использованием pickle
with open(_TITLE_ + ".pkl", 'wb') as file:
pickle.dump(dialogue, file)
print(f"Диалог сохранен в файл: {file_path}")
Параметры window_width, window_height, window_x, window_y для нашей задачи не нужны, это оставлено для тестирования размеров окна эмулятора браузера Selenium, можете не обращать на них внимания.
Генерация файла PDF с текстом
Теперь, когда диалог сохранен в текст, нужно сделать из него PDF.
За это отвечает функция create_pdf, вот как она выглядит:
def create_pdf(dialogue_lines, output_file=_TITLE_, current_width=945, current_height=945,
marginX=0, marginY=0, offset=0, font_size=1, font_name=FONT_NAME):
global GLOBAL_PAGES
current_width = int(current_width)
current_height = int(current_height)
marginX = int(marginX)
marginY = int(marginY)
offset = int(offset)
font_size = int(font_size)
current_y = current_height - marginY
current_file_size = 0
symbols_in_PDF = 0
CANVASES = []
CANVAS_IND = 0
CANVASES.append(canvas.Canvas(str(output_file) + "_" + str(CANVAS_IND) + "_.pdf", pagesize=(current_width, current_height)))
words = ' '.join(dialogue_lines).split()
current_line = []
current_line_width = 0
word_ind = 0
for word in words:
symbols_in_PDF += len(word) + 1
word_ind += 1
word_width = CANVASES[CANVAS_IND].stringWidth(word, font_name, font_size)
current_line_width += CANVASES[CANVAS_IND].stringWidth(' ', font_name, font_size)
if current_line_width + word_width + marginX > current_width - offset:
CANVASES[CANVAS_IND].setFont(font_name, font_size)
CANVASES[CANVAS_IND].drawString(marginX, current_y - font_size, ' '.join(current_line))
current_line = [word]
current_line_width = word_width
current_y -= font_size
current_line_width = 0 # обнуляем ширину строки
if current_y - font_size < marginY:
CANVASES[CANVAS_IND].save()
print(f"SAVE: {CANVAS_IND} >>>> " + "if current_y - font_size < marginY:")
print(f"СИМВОЛОВ НА СТРАНИЦЕ PDF: {symbols_in_PDF}")
CANVASES[CANVAS_IND].showPage()
current_y = current_height - marginY
current_file_size = os.path.getsize(str(output_file) + "_" + str(CANVAS_IND) + "_.pdf")
print(f"РАЗМЕР PDF: {current_file_size} ( {output_file} )")
CANVAS_IND += 1
CANVASES.append(canvas.Canvas(str(output_file) + "_" + str(CANVAS_IND) + "_.pdf", pagesize=(current_width, current_height)))
GLOBAL_PAGES += 1
current_line = []
current_line_width = 0
else:
current_line = [word]
else:
current_line.append(word)
current_line_width += word_width
if current_line:
CANVASES[CANVAS_IND].setFont(font_name, font_size)
CANVASES[CANVAS_IND].drawString(marginX, current_y - font_size, ' '.join(current_line))
CANVASES[CANVAS_IND].save()
print(f"SAVE: {CANVAS_IND} >>>> " + "GLOBAL")
current_file_size = os.path.getsize(str(output_file) + "_" + str(CANVAS_IND) + "_.pdf")
print(f"ШИРИНА PDF: {current_width}")
print(f"ВЫСОТА PDF: {current_height}")
print(f"РАЗМЕР PDF: {current_file_size}")
print(f"СИМВОЛОВ: {symbols_in_PDF}")
Код использует библиотеку reportlab для работы с PDF.
Сама функция довольно проста:
На вход ей прилетает список dialogue_lines, содержащий фразы из диалогов.
Далее, он разбивается на слова и проходит по всем словам циклом, записывая их по одному в PDF, пока не кончится строка, далее, перенос на следующую строку и так далее – пока не заполним всю страницу PDF. Если символов в диалоге больше, чем на одну страницу – запись переходит на следующую. Размер PDF задается вручную (можно в конфиге, можно в командной строке), так что всегда можно «подгадать» так, чтобы символы влезли на одну страницу.
На выходе получим такой «манускрипт»:

Отправление PDF в ChatGPT для распознавания и тестирование
Прежде чем отправить диалог в файл, нужно сказать еще о парочке функций, присутствующих в коде – это функции генерации русского текста и вопросов-ответов.
Происходит это в следующем участке кода:
if GEN_TEXT:
print(f"Генерируем список русских слов...")
russian_words = generate_russian_words() # Генерируем список русских слов
print(f"Генерируем блоки текста для PDF...")
coeff = 3.68
MAX_BLOCKS = int((pdf_size[0] * pdf_size[1] / 10000) * coeff)
text_blocks = generate_text_blocks(russian_words, MAX_BLOCKS)
print(f"Блоков всего: {MAX_BLOCKS}")
# Генерация вопросов и ответов
questions, answers = generate_questions_answers(text_blocks)
# Сохранение вопросов и ответов в файлы
save_to_file(questions, 'questions.txt')
save_to_file(answers, 'answers.txt')
dialogue = text_blocksСами функции генерации текста и вопросов-ответов очень просты, вы их можете просмотреть в коде по ссылке ниже, скажу лишь, что вопросы-ответы представляют собой просто случайную строку из блока текста (блоки по 10000 символов – как раз для проверки памяти буфера) и ее продолжение.
То есть если у нас есть текст:
«ChatGPT был запущен 30 ноября 2022 года и привлёк внимание своими широкими возможностями: написание кода, создание текстов, возможности перевода, получения точных ответов и использование контекста диалога для ответов, хотя его фактическая точность и подверглась критике.»
То «вопрос» может быть такой: «, возможности перевода, получения точных ответов и»
А ответ тогда будет такой: «использование контекста диалога для ответов, хотя »
Вопросы‑ответы генерятся в тестовые файлы, один из которых (questions.txt) мы передадим ChatGPT, а по второму (answers.txt) будем сверять правильность ответов.
Для отправки и тестирования я использовал следующий промпт (разумеется, что числа вам нужно будет указать свои, скрипт, который я написал выдаст вам эти параметры):
Я дам тебе PDF файл на нем построчно записан текст на руссскком языке слева направо черный на белом фоне. Символов в тексте 1435545 размер файла в пикселах 625 на 625 весит файл 1239201 байт Далее я также прикреплю текстовый файл, представляющий из себя список строк-вопросов, которые встречаются в тексте по 5 символов каждый вопрос. Тебе нужно буде проанализировать PDF файл распознавая с него текст поэтапно по 10000 символов. При анализе каждого блока по 10000 символов нужно просматривать список вопросов из текстового файла, проверяя нахождение строки в блоке. Принахождении записывать в список ответов следующие 5 символов после символов вопроса в качестве строки-ответа. По окончании ответов на все строки-вопросы, необходимо записать список ответов в текстовый файл построчно и передать мне ссылку на его скачивание
Здесь длина строки вопроса-ответа = 5 символов, но вы можете установить любую длину вопроса при их генерации.
В итоговом текстовом файле при сравнении с файлом answers.txt получается 100% совпадение всех ответов.
Таким образом, информация передалась полностью.
Экспериментально у меня получилось в файле 625х625 пикселей PDF уместить 1430086 символов.
Почти полтора миллиона! И это – в одном запросе!
Сам ChatGPT говорит, что может кушать файлы PDF 20-30 MB и до 5000х5000 пикселей.
Увы, у меня почему-то при попытке скормить ему файлы больше 1.5MB выдает все время network error. Так что проверить это практически не могу - оставляю это удовольствие читателям.
Кстати, кто решит проверить, отпишитесь – интересно сколько символов получится передать в запросе к ChatGPT таким образом у вас?
Если аппроксимировать, то из файла 5000х5000 можно получить более МИЛЛИАРДА символов.
Но это в теории, пока что файлы даже 1000х1000 он у меня отказывается «переваривать».
Заключение
Здесь много направлений, которые можно развивать и исследовать.
Например, я перебрал всего пару сотен шрифтов, подобрав самый на мой взгляд компактный и хорошо распознаваемый. Если этим заняться серьезно, уверен, найдется куба более лучший шрифт для этой цели. Также, как я уже написал выше, из-за технических проблем у меня получилось передать только 1.5 миллиона символов в одном запросе, конечно же это не предел.
Ну и, конечно же, оптимизация и рефакторинг кода – текущий писался мною «на коленке», как это часто бывает в своих проектах, и не несет обучающей цели, так что прошу за кривоту кода помидоры не кидать, он тут не главное.
А главное – это интересный способ, который хорош также тем, что он, не создавая дополнительных нагрузок на серверы OpenAI, при этом позволяет уместить в запросе куда больше информации.
К тому же этот способ не получится «забанить», так как для этого придется лишить ChatGPT возможностей распознавания текста.
И, то что мне нравится больше всего, способ не требует доп. средств, плагинов, и т.д. и работает нативно.
Ссылка на репо с кодом (там же README, где описаны все параметры скрипта и как с ним работать).
Спасибо за внимание и с наступающим Новым Годом!
Комментарии (22)

MEXAHOTABOP
28.12.2023 11:16Помню на реддите это давно обсуждалось, под капотом они просто разбивают pdf на блоки которые отправляют в векторное хранилище, и подгружают релевантные к запросу части.
У sillytavern есть плагин который делает тоже самое, но локально и без pdf.

Devastor87 Автор
28.12.2023 11:16А можно ссылки на эти примеры?
Их можно "прикрутить" к ChatGPT?
Я находил только видео трехмесячной давности на ютубе по расширению памяти с использованием pdf, но там просто говорилось про текст с pdf, не было описания и разработки такого скрипта и запроса.
MEXAHOTABOP
28.12.2023 11:16Нагугленное описание процесса https://www.reddit.com/r/ChatGPTPro/comments/145yi21/comment/jno6uyy/ (оригинальный источник на openai не доступен в РФ)
В SillyTavern реализовано плагином через chromadb https://github.com/SillyTavern/SillyTavern-Extras/blob/08a18dc506d8d73685de5c4d28980fa544e258e0/server.py#L863 и да это будет работать с любым бэкендом, как локальным, так и chatgpt.
Devastor87 Автор
28.12.2023 11:16Так это всё через API.
Я же описал решение именно для ChatGPT, а не для GPT. Без сторонних плагинов.
Понятное дело, что через API можно много чего наворотить, но статья то не про это. Здесь используется именно сам ChatGPT4.

IvanPetrof
28.12.2023 11:16+2Символов в тексте 1435545 размер файла в пикселах 625 на 625
в pdf какие-то волшебные пиксели? Или как в 625*625=390625 пикселях удаётся написать полтора миллиона символов?
Devastor87 Автор
28.12.2023 11:16PDF - это векторный формат

Moog_Prodigy
28.12.2023 11:16+1Если векторный то причем тут пиксели вообще?

Quiensabe
28.12.2023 11:16Ни при чём. Автор почему-то упорно считает, что текст распознается с помощью OCR, хотя PDF прекрасно позволяет хранить текст именно как текст. Именно так он и хранился у автора, иначе, файл на 1,5 млн символов весил бы куда больше (в векторе или читаемом растре). Зачем были нужны эксперименты со шрифтами, попытками все уместить в одну страничку - совершенно непонятны.
Devastor87 Автор
28.12.2023 11:16+1Каким образом текст может храниться в растре здесь?
Вы читали код проекта?
Там используется drawString, которая "рисует" на canvas, это никакой не "текст в виде текста".
Посмотрите библиотеку, которая работает здесь с pdf.
Если здесь текст хранится в растре, покажите мне, каким образом в одном пикселе вы можете уместить 4 буквы?))
Конечно же здесь именно OCR, причем, я проводил тесты и с другими шрифтами, и с картинками в том же самом PDF.
То, что вы пишете - неверно, здесь именно вектор и OCR.
И что вообще значит "текст в виде текста"?)

Xeony
28.12.2023 11:16Не представляю как вы вместили 1 435 545 символов в 1 239 201 байт, если бы это был просто текстовик, это было бы возможно с сжатием, если файл хранится в векторном формате (как svg к примеру), то в OCR небыло бы смысла, если как утверждает автор символы именно рисуются, тогда или каждый символ был бы не читаем, или файл занимал больше места
Devastor87 Автор
28.12.2023 11:16Так об этом и статья: я придумал как это сделать и подробно описал, включая весь исходный код, чтобы любой, кто читает, мог бы это повторить у себя.
Насчёт OCR: насколько я понимаю, в PDF буквы рисуются векторно, поэтому и получается уместить такое количество (и это не предел, если аппроксимировать, то получится в файл 20 мб должно влезать больше миллиарда символов, а это уже небольшая библиотека ????), а проверки, которые показывают, что ChatGPT действительно способен всё это прочесть, также описаны в статье.
Ещё одну проверку я не стал описывать, но проводил: я просил чат прочитать файл PDF и перевести его в текст, разделяя на блоки по 10000, и он эту проверку прошёл, выдав в ответ текстовый файл с точным содержанием текста из pdf.
Смысл способа как раз в комбинации OCR+вектор.
Quiensabe
28.12.2023 11:16Конечно же здесь именно OCR,
Прежде чем громко говорить о чужих ошибках, хорошо бы проверять утверждения.
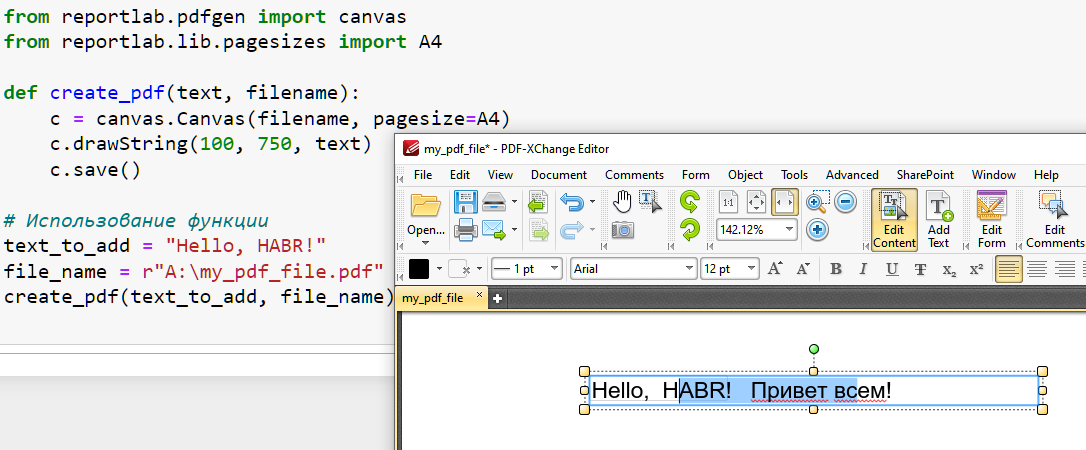
Вот код с вашей же библиотекой, и вашей же функцией. И pdf открытый в редакторе в котором впомине нет никакого OCR - прекрасно редактируется.
Потому что, как я и сказал, текст хранится "в виде текста" - т.е. в виде набора кодов символов, а не в виде растрового изображения всех знаков или их векторного описания.
Именно "текстовое" содержимое позволяет файлу иметь размер в байтах сравнимый с числом символов в тексте.
PDF документ может хранить и вектор и растр, и даже для текста сохраняет векторные описания, по одному для каждого из используемых глифов (для гарантии, что документ будет выглядеть аналогично на компьютере без нужных шрифтов).
Но ваш случай не имеет к этому функционалу отношения. Нет никакого OCR. И совершенно по барабану какие шрифты вы используете, хоть вообще без русских глифов. Если текстовую строку удастся извлечь из - он ее увидит.
Ну вот для примера я закрою кусок текста картинкой, и...
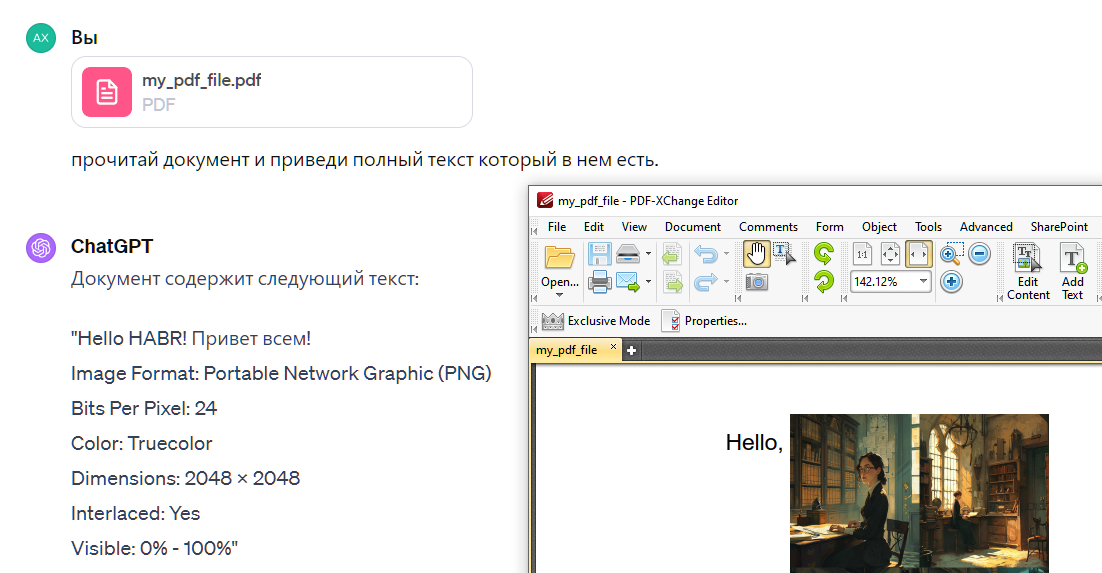
ChatGPT прекрасно видит текст даже сквозь нее...
Пойдет дальше - заменим шрифт в pdf документе не такой где вообще нет латиницы, и даже число знаков не совпадает с числом символов, и...

И, о чудо, опять ChatGPT справился с "распознаванием" несуществующего текста)))




Tuvok
28.12.2023 11:16Вы серьезно полагаете что проблема "Первая «преграда» на пути встала довольно быстро.
Это – ограниченная память ChatGPT." серьезнее чем "Спроектировать и создать <…> тело в реальности" ? Потому что просто тело это полдела, а как вы будете соединять это с "сознанием" в виде LLM?Devastor87 Автор
28.12.2023 11:16Я, вроде бы, нигде не давал оценку степени серьёзности проблем и не сравнивал их по этому критерию.
Можно узнать, на основании чего вы решили, что так считаю?
А вопрос не совсем понятен - что значит "как"?
В текущей формулировке он звучит слишком широко, и, разумеется, ответ на такой вопрос и близко не уместится в текст комментария)
Это тема для будущих статей.
Так что вы уточните, пожалуйста.
Я занимался программированием роботов и МК, работал с роботами, собирал роботов, поэтому, в целом, не вижу особой сложности прикрутить LLM к телу.
Это будет "существо" с большим количеством сенсоров, гармоничной синхронизацией сигналов от них и системой интерпретации этих сигналов (тут и вступает LLM)
Tuvok
28.12.2023 11:16+1Уточняю: LLM это только текст, весь набор данных от сенсоров и к исполнительным механизмам взваливать на одного него мне кажется немного невразумительным. Если брать человека как аналог, то полноценный робот это связь из нескольких нейросетей, отвечающих за свой аспект. Таким образом LLM будет даже не ядром системы, а всего лишь одним из элементов. И то нужна будет не просто генеративная сеть с галлюцинированием, но с модулем или блоком критической оценки собственных суждений.
Devastor87 Автор
28.12.2023 11:16Конечно, я планирую сеть из LLM, что-то похожее на AutoGPT в итоге сделать.
На одном из следующих этапов (до создания тела) планируется усложнение структуры. Пока я ещё думаю над тем, какие именно блоки там будут.
Например, в сети из ChatGPT один из них хранит сам диалог, второй хранит в себе эмоциональные окрасы его фраз, третий - связи между частями диалога, четвертый отвечает за чистку - убирает повторы, воду, и т.д.
Пока что финального списка блоков нет, это открытый вопрос, по мере разработки проекта он будет переформироваться, скорее всего, ещё не раз.
Вот, например, ваш вариант - блок оценки критичности суждений - возьму на заметку, хорошая идея, спасибо )


utya
28.12.2023 11:16+1Я тоже думал на этот счёт. Создание памяти которая касается только меня. Но у меня идея была такой. Каждый диалого ,также экспортировать, средствами chatgpt, выцеплять суть, давать тэги и это все сохранять в бд. Ну вот я подумал что лучше это хранить в бд. Потом после начала следующего диалога бегать в бд делать поиск по тегу и вычитывать о чем был разговор.
Много нюансов но идея была такой)
Devastor87 Автор
28.12.2023 11:16Идея интересная, но, если выцеплять суть - то это будет всё-таки суммация, а не точное содержание. И пока что ChatGPT не работает с БД напрямую в своем интерфейсе, непонятно как ему передавать информацию из БД в одном запросе сразу про весь диалог
zyaleniyeg
Так ничего не изменилось, чат все также кушает по 10000 символов за запрос, просто разбивает на запросы он сам
Devastor87 Автор
Увы, с текстовым файлом работает гораздо хуже, особенно вот это разбиение на блоки (то есть такие же тесты он не проходит также хорошо).
Плюс таким образом текст весит в 2 раза меньше - тоже определённая экономия.
Так что, даже если удастся то же самое провернуть с текстовым файлом, выгода всё же имеется. Но у меня не получилось добиться такой же точности с txt к сожалению :(