

Автор фото: Marques Kaspbrak, сайт Unsplash
Стриминг. Сегодня это слово у всех на устах. Большинство из нас ежедневно заходит на Netflix или YouTube. Можно сказать, что стриминг прочно вошёл в нашу жизнь, даже в некотором избытке.
Но редко кому-то приходит в голову: «интересно, а как устроена эта технология?» Мне как разработчику она кажется чистым безумием. Ведь приходится хранить и передавать по сети такие огромные объёмы данных, к которым должны иметь доступ пользователи во всём мире – а пользователь хочет получать контент без задержек и каких-либо проблем, причём, ресурс должен работать на всех его устройствах.
Не буду утверждать что хорошо понимаю, как стриминговые приложения устроены на внутрисистемном уровне. Вероятно, там используются концепции, о которых я даже не подозреваю, а сами приложения оптимизированы до последнего дюйма.
Но на этом статью оканчивать рано, коль скоро уж я решил её написать. В ней я хочу рассказать о моём непосредственном опыте, который приобрёл, работая тимлидом. Мы создавали одно стриминговое решение в компании Skeepers, и ниже я опишу, как создавать высококачественное видео, а затем в режиме потоковой передачи заливать это видео прямо на сайт вашего клиента – чтобы пользователь смотрел ваш контент, точно, как смотрит YouTube.
Здесь будут рассмотрены такие технологии, как Kubernetes, RabbitMQ и балансировщики нагрузки. Чтобы следить за ходом изложения, вам потребуется базовое понимание всех этих технологий.
Поясню, что здесь я понимаю под стримингом просмотр видео из Интернета, а не прямой эфир. В таком контексте любой видеоролик с YouTube считается видео-стримингом.
❯ Жизненный цикл видео: от загрузки до воспроизведения
Давайте проследим весь путь, в начале которого пользователь загружает видео на ваш сайт, а в завершении вы транслируете это видео другим пользователям, которые могут смотреть его с любых устройств. В частности, рассмотрим, какие проблемы должны быть при этом решены.

Автор фото Jakob Owens с сайта Unsplash
❯ Шаг первый: загрузка видео
Хорошо, для начала нужно закачать видео на сайт. Перед этим нам потребуется определить, в каком формате будет видео, какие кодеки для него понадобятся, или даже в каком разрешении будет ролик.
Первым делом видео нужно нормализовать. Это означает, что мы переведём все видеоролики в один и тот же формат (сначала mp4). Затем нужно стабилизировать видео и гармонизировать звук, чтобы картинка не дрожала, а некоторые звуки не казались слишком громкими.
Затем видео дробится на множество мелких фрагментов. В результате получается стриминговый формат для адаптивной трансляции потокового видео. Существуют различные стандарты для такого стриминга, например, HLS или MPEG-Dash. Стандарт HLS разработан компанией Apple и является нативным в операционной системе IOS. Стандарт MPEG-Dash создан компанией Moving Pictures Group в качестве альтернативы HLS.
Подробнее об адаптивной трансляции потокового видео рассказано здесь.
На эту задачу требуется много времени, поэтому пользователь не может просто синхронно ждать, пока ответит API. Эта операция должна происходить асинхронно.
Авторская схема, на которой в упрощённом виде изображена эта архитектура:
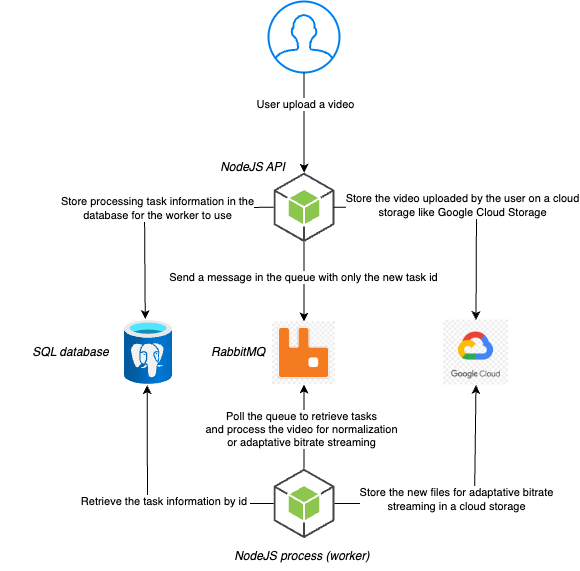
Store processing task information… // Сохранить в базе данных информацию о задаче на обработку, которой затем воспользуется рабочий поток
Store the video… // Сохранить загруженное пользователем видео в облаке, например, в Google Cloud Storage
Send a message in the queue // Отправить сообщение, содержащее только id новой задачи, поставить его в очередь
SQL database // База данных SQL
Poll the queue… // опросить очередь, чтобы извлечь из неё задачи и обработать видео для нормализации или адаптивной трансляции
Retrieve the task information… // Извлечь информацию о задаче по ее id
Store the new files… // Сохранить в облаке новые файлы для адаптивной трансляции видео
NodeJS process (worker) // (Рабочий) процесс NodeJS
На этой схеме показана асинхронная реализация с использованием RabbitMQ. Всякий раз, когда пользователь загружает новое видео, оно сначала попадает в облачное хранилище. В данном случае используется Google Cloud Storage, но, в принципе, подойдёт любое облако. Как только загрузка завершится, создаём в базе данных задачу и ставим её ID в очередь. Экран на пользовательском устройстве обновляется – выводится сообщение, что задача взята в работу, и требуется подождать несколько минут.
Рабочий поток NodeJS постоянно опрашивает очередь, дожидаясь новых задач как бравый солдат. Как только поступит новая задача, он получает из базы данных информацию о том, как её обрабатывать. Под капотом это задание решается при помощи FFmpeg (например, выполняется нормализация или видео подготавливается к адаптивной трансляции), результирующие файлы сохраняются в облаке, а статус задачи в базе данных обновляется.
Возможно, вы уже задумываетесь: «Постойте, у вас в заголовке статьи Kubernetes, а в схеме выше его нет» или «В таком виде она не масштабируется. Если будет наплыв видео, то всё сломается».
Сейчас до всего этого дойдём. Конечно же, представленная выше схема была вводной. Я постепенно знакомлю вас со всеми концепциями.
Действительно, здесь просматривается пара проблем. Если у нас всего один API и один рабочий поток, то в системе быстро наступит перегрузка. В первую очередь, потому, что FFmpeg требуется множество ресурсов. Давайте допилим!
Авторская схема, на которой в упрощённом виде изображена эта архитектура с участием Kubernetes:

Store processing task information… // Сохранить в базе данных информацию о задаче на обработку, которой затем воспользуется рабочий поток
Kubernetes cluster // Кластер Kubernetes
Load balancer // Балансировщик нагрузки
Store the video… // Сохранить загруженное пользователем видео в облаке, например, в Google Cloud Storage
Send a message in the queue // Отправить сообщение, содержащее только id новой задачи, поставить его в очередь
SQL database // База данных SQL
Poll the queue… // опросить очередь, чтобы извлечь из неё задачи и обработать видео для нормализации или адаптивной трансляции
Retrieve the task information… // Извлечь информацию о задаче по ее id
Pod // Под
Store the new files… // Сохранить в облаке новые файлы для адаптивной трансляции видео
NodeJS Worker (spawner) // Рабочий (порождающий) процесс NodeJS
Хорошо, в нашей схеме добавился Kubernetes. API NodeJS, обрабатывающий пользовательские вызовы, будет получать множество HTTP-вызовов, содержащих пользовательские файлы. Поэтому теперь у нас не API в одном экземпляре, а переменное количество подов Kubernetes. Нам придётся настроить автомасштабирование таким образом, что, если объём задействованных ОЗУ или ядер ЦП в подах достигает конкретного предела (70% мощности), то для того же API запустится новый под.
Для упрощения схемы в ней не указан «узел Kubernetes», но она может масштабироваться и в плоскости узлов. Если количество подов (а, в сущности, необходимая мощность подов) достигает предельной мощности, то в результате автоматического масштабирования выделяется новый узел, а внутри этого узла начинают запускаться новые поды.
Балансировщик нагрузки, расположенный перед API, будет случайным образом распределять все HTTP-вызовы среди всех имеющихся подов, размазывая нагрузку.
Рабочий поток, опрашивающий RabbitMQ, также автоматически масштабируется, но не на уровне ресурсов, а на уровне количества сообщений, ожидающих своей очереди. Чем больше таких ожидающих сообщений, тем быстрее их требуется обрабатывать. Эта задача решается только запуском новых рабочих потоков.
Уже гораздо лучше, но мы по возможности хотим сэкономить ресурсы. Давайте введём в схему вытесняемые узлы!
Вытесняемые виртуальные машины – это вычислительные VM -инстансы, которые обходятся дешевле, чем стандартные VM и не предоставляют гарантий доступности — из документации Google Cloud.
Авторская схема, на которой в упрощённом виде изображена эта архитектура с участием Kubernetes и вытесняемыми узлами:

Store processing task information… // Сохранить в базе данных информацию о задаче на обработку, которой затем воспользуется рабочий поток
Kubernetes cluster // Кластер Kubernetes
Load balancer // Балансировщик нагрузки
Store the video… // Сохранить загруженное пользователем видео в облаке, например, в Google Cloud Storage
Send a message in the queue // Отправить сообщение, содержащее только id новой задачи, поставить его в очередь
SQL database // База данных SQL
Poll the queue… // опросить очередь, чтобы извлечь из неё задачи и обработать видео для нормализации или адаптивной трансляции
Retrieve the task information… // Извлечь информацию о задаче по ее id
Pod // Под
Store the new files… // Сохранить в облаке новые файлы для адаптивной трансляции видео
NodeJS Worker (spawner) // Рабочий (порождающий) процесс NodeJS
Preemptible kubernetes node // Вытесняемые узлы Kubernetes
Pod worker // Рабочий процесс пода
Мы хотим, чтобы пользователю было максимально удобно работать, но вполне допустимо, если при этом доступное им видео не будет идеального качества при адаптивной трансляции сразу после загрузки контента. Может потребоваться несколько минут, пока найдётся доступный вытесняемый узел, однако вытесняемые узлы обходятся дешевле обычных.
В этой новой схеме наш рабочий поток NodeJS при помощи FFmpeg превращается в «порождающий» поток. Такой поток продолжает опрашивать очередь RabbitMQ, но обрабатывать само видео мы не собираемся, а запускаем новый под Kubernetes на вытесняемом узле, и вся обработка будет происходить в этом новом поде.
Так дешевле. Все ресурсоемкие задачи мы перенесли на вытесняемый узел, поэтому нам не требуется масштабировать наш порождающий поток так же, как и обычный узел.
Облако Google Cloud может убивать вытесняемые узлы в случае, если обычному узлу понадобятся ресурсы. Мы должны гарантировать, что сорвавшаяся задача вернётся в очередь и впоследствии её выполнение возобновится на другом узле.
Такая новая конфигурация с вытесняемыми узлами влечёт больше издержек при реализации, зато получается гораздо более качественной. Мы достигли той точки, начиная с которой обеспечивается бесконечное горизонтальное масштабирование.
❯ Второй шаг: воспроизведение видео
Хорошо, на данном этапе мы уже загрузили видео на сайт и преобразовали пользовательский файл так, чтобы его можно было транслировать в режиме потоковой передачи. Этот видеофайл может весить сотни мегабайт и быть разрезан на тысячи фрагментов.
HTML-тег video по умолчанию не поддерживает форматы адаптивной трансляции видео, в частности, HLS или MPEG-Dash, поэтому нам придётся воспользоваться собственным плеером. Наиболее востребованные плееры для воспроизведения потокового видео – это HLS.js и Skaka Player. Для обработки этого формата оба они используют расширение Media Source Extension. Далее я не буду вдаваться в подробное описание этих плееров и расширения MSE, поскольку эти темы выходят за рамки статьи. О них вы можете почитать по ссылкам, которые я привёл.
Чтобы видео повторно не скачивалось из облака всякий раз, когда кто-нибудь пытается его запустить (так как в противном случае нам придётся дорого заплатить облачному провайдеру), давайте пользоваться сетью доставки контента (CDN).
Собственная схема, в которой показано, как использовать CDN:
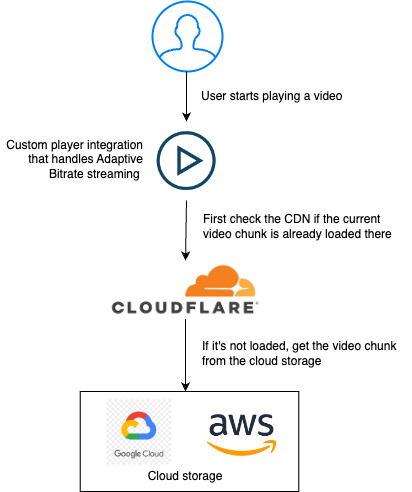
Custom player… // Интеграция собственного плеера, который будет обеспечивать адаптивную потоковую трансляцию данных
First check… // Сначала проверяем, загружен ли уже интрересующий нас фрагмент видео в сеть CDN
If it’s loaded… // Если он не загружен, то получаем видеофрагмент из облачного хранилища данных
Cloud Storage // Облачное хранилище
Пользователь приходит на сайт и собирается стримить видео. Все вызовы, направленные на получение видео, проходят через Cloudflare, провайдера, предоставляющего нам CDN. В CDN контент будет кэшироваться на периферийных устройствах. Таким образом, если нужный вам контент в их кэше отсутствует, то он будет запрошен по предоставленному вами URL.
«Периферийная» составляющая обеспечивает, что, в зависимости от вашего физического местонахождения, контент будет скачиваться с того (регионального) сервера, который расположен ближе всего к запрашивающему контент пользователю, поэтому и трансляция получится максимально быстрой.
Каждый фрагмент видео представляет собой отдельный файл, поэтому, если невезучему пользователю ещё придётся дожидаться, пока будет создан кэш, это ожидание всё равно будет недолгим. Не придётся скачивать гигабайты за один раз.
Здесь я опустил некоторые важные составляющие описанной архитектуры – в частности, микросервисы, веб-сокеты, публикацию/подписку в Redis и вебхуки, так как хотел сосредоточиться на возможностях автомасштабирования Kubernetes в сочетании с асинхронными очередями RabbitMQ.
Вероятно, на YouTube используется реализация, которая существенно отличается от нашей, но по этой статье уже можно составить неплохое впечатление о том, как может выглядеть такая сложная система как Kubernetes.
Хотел бы я превратиться в мышку и проскользнуть в недра Youtube, посмотреть на их архитектуру – чтобы проверить, далеко ли мы от них ушли. Думаю, надо подсказать такую идею автору мультфильма «Рататуй»; хороший сюжет, не правда ли?
Возможно, захочется почитать и это:
- ➤ Устранение неисправностей в приложении Java под Kubernetes
- ➤ Эфемерные контейнеры в Kubernetes
- ➤ Как объяснить суть Kubernetes таксисту
- ➤ Arcanum всё ещё актуальна? Ностальгический рассказ и идеальная сборка для игры в 2024
- ➤ Atomic Heart или как забилось сердце русского геймдева

Комментарии (15)

svok
09.01.2024 08:36НИКОГДА и ни при каких обстоятельствах не используйте rabbit и kafka при работе с мультимедиа! Не пройдете по производительности, а если и пройдете, то на ресурсах разоритесь и задержки будут чрезмерные, причем, нарастающие со временем.
Материалов, описывающих работу с потоковым видео полно, если знать ключевые слова. И ключевые слова здесь ffmpeg, gstreamer и opencv. Это три фреймворка, которые тесно между собой переплетены. Все написаны на C, все работают с протоколами и кодеками различных медиа-потоков, поддерживают все, что необходимо.

baldr
09.01.2024 08:36+2Вы абсолютно правы. Я тоже сначала зашел в статью, удивленный заголовком, и собирался написать то же самое.
Однако, по картинкам видно, что стриминг самого потока идет вообще через CDN, а RabbitMQ используется в задачах при загрузке и обработке видео. Заголовок не совсем отражает суть статьи.
svok
09.01.2024 08:36Любую обработку надо делать на указанных фреймворках. Rmq вообще для видео не подходит. Это как молотком в зубах ковыряться.


crewalink
09.01.2024 08:36Схемы достаточно наглядно разжовывают информацию, благодаря ним становится понятнее!

Chess
09.01.2024 08:36Спасибо, интересно.
Пару вопросов:
Почему Rabbit + отдельный layer "порождающих" подов, а не Pub/Sub + Cloud Functions (SQS + Lambdas)?
Вы уже используете Redis, почему тогда не Redis Streams вместо Rabbit?
Если только вытесняемые инстансы, не возникает ли проблем в часы пик? Не лучше ли микс из вытесняемых + гарантированные?
baldr
09.01.2024 08:36Я не автор, но разрешите мне прокомментировать с моей точки зрения.
Не все любят завязывать всё на облачные решения. Они не всегда оптимальны, в том числе, по цене. Вполне возможно, что уже была часть работы на выделенных серверах через RabbitMQ-воркеры и просто добавили это туда.
Ну, теоретически, доставка через Redis менее надёжна. Хотя, в целом, наверное, вполне подойдёт для таких задач. Опять же, киллер-фича RabbitMQ - это его роутинг через exchange/queue/routing_key. Плюс более удобный UI для менеджмента всего этого. Очень часто архитектурные решения принимаются просто, учитывая опыт команды - Redis Streams вышел в конце 2018г, а RabbitMQ используется на 10 лет дольше.
Хороший вопрос. Думаю, возникает. И да - наверное лучше. И, вполне возможно, что так и делается.
Lambda - удобная в чём-то штука, но может выжрать бюджет быстрее, чем пара спокойных серверов, неспешно прожёвывающих задачи из неприоритетной очереди. Особенно если там что-то обрабатывает ffmpeg или что-то, требующее GPU или несколько ядер.
baldr
В очередной раз встречаю эту ошибку при описании работы с RabbitMQ.
В протоколе AMQP потребители НЕ опрашивают очередь. Напротив, брокер поддерживает постоянный открытый канал со всеми потребителями и при поступлении нового сообщения выбирает нужного потребителя/ей и отправляет им пакет сам. Таким образом, мы не тратим время на открытие-закрытие соединения, на паузы при ожидании и на отправку запросов, не говоря уже о трафике.
А вот в случае с Apache Kafka, например - там, как раз, потребитель сам опрашивает очередь (скорее, список?) и забирает столько сообщений, сколько ему нужно и сам запоминает позицию.
McFkr
Ну смотря как реализован клиент.
Например, symfony messenger именно опрашивает очередь, поэтому в таком случае в UI самого кроля и не видно, сколько консьюмеров подключено к очереди
baldr
Нет, в AMQP нельзя "опрашивать очередь" и выбирать какие сообщения нравятся. Вы можете только получить первое же сообщение (или N сообщений), которое брокер решит назначить вашему консьюмеру. Я не знаю как именно реализован клиент в symfony messenger, но бегло посмотрел по докам и там, похоже, обычный AMQP-клиент. Не могу сказать почему он не показывается в списке, но должен, по идее.
McFkr
Ну речи и не идет о непоследовательном получении сообщений. Но из кроля можно принудительно вытаскивать сообщения без включения классического консьюмера. Мне лично такой подход не очень нравится.
baldr
А можете пример привести?
UPD: Согласен, похоже, что basic.get так работает. Я думал что там тоже через consuming оно идет.
McFkr
Вот только зашел чтоб про этот метод сказать) По сути можно в одном воркере реализовывать что-то типо приоритета очередей, когда 1 воркер работает сразу с несколькими очередями (к примеру для различного рода рассылок и нотификаций)
baldr
Ну можно, наверное, но тогда теряется куча фич - типа late ack, да и вообще медленнее это гораздо, чем подписка. basic.get может быть удобен именно при одноразовом подключении - типа периодического поллинга с веба или с мобильного, когда подключение держать неудобно.