
Проблема в том, что Яли слишком мал, чтобы разобраться в том, как играют в игру, и он изобрёл свою версию игры. Цель игры – разобрать карточки по категориям (покемон, энергия и тренировочная карта).
Он не спрашивал, откуда я знаю, какого типа карта. Он просто взял несколько карт и спросил, какого они типа. Получив несколько ответов, он сумел разделить несколько карт по типу (совершив при этом несколько ошибок). В этот момент я понял, что мой племянник – это, по сути, алгоритм машинного обучения, а моя задача в качестве дяди состоит в маркировке данных для него. Так как я дядя-гик, и энтузиаст машинного обучения, я начал писать программу, которая сможет посоревноваться с Яли.
Так выглядит типичная карта покемона:

Для умеющего читать взрослого человека легко понять, какого типа эта карта — на ней написано. Но Яли 4 года, и читать он не умеет. Простой OCR-модуль быстро решил бы мою задачу, но я не хотел делать лишних предположений. Я просто взял эту карту и предоставил её для изучения MLP-нейросети. Благодаря сайту pkmncards я мог скачивать картинки, уже рассортированные по категориям, поэтому с данными проблем не возникло.
Алгоритму машинного обучения нужны признаки, и моими признаками были пиксели изображений. Я преобразовывал 3 цвета RGB в одно целое число. Поскольку мне попадались картинки разных размеров, их нужно было нормализовывать. Найдя максимальные высоту и ширину картинок, я добавлял нули к картинкам меньшего размера.

Быстрый прогон QA перед работой самой программы. Я случайным образом брал две карты каждого типа и запускал предсказание. При использовании 100 карт из каждой категории подгонка шла очень быстро, а предсказания были ужасными. Затем я взял по 500 карт из каждой категории (исключая типы энергии, которых было всего 130), и запустил подгонку.
Память закончилась. Можно было запустить код подгонки в облаке, но я хотел придумать способ экономии памяти. Самая крупная картинка была размером 800x635, это было слишком много, и изменение размера картинок решило мою проблему.
Для настоящей проверки в дополнение к обычным картам я добавлял карты, на которых я немного калякал, карты, разрезанные пополам, с нарисованными поверх контурами, фотографировал их с телефоном (с плохой камерой) и т.п. Для тренировки эти карты не использовались.
Я использовал 1533 модели. Разные размеры картинок, несколько скрытых слоёв (до 3), длина слоя (до 100), цвета изображений, методы чтения изображений (всё целиком, верхняя часть, каждый второй пиксель, и т.п.). После многих часов подгонки лучшим результатом стало 2 ошибки из 25 карт (мало у каких моделей был такой результат, и каждая из них ошибалась на разных картах). 9 моделей из 1533 сработали с результатом в 2 ошибки.

Комбинация моделей давала мне результат с 1 ошибкой, если я поднимал порог выше 44%. Для теста я использовал порог в 50%. Я подождал месяц, пока Яли игрался с картами, и провёл тестирование.

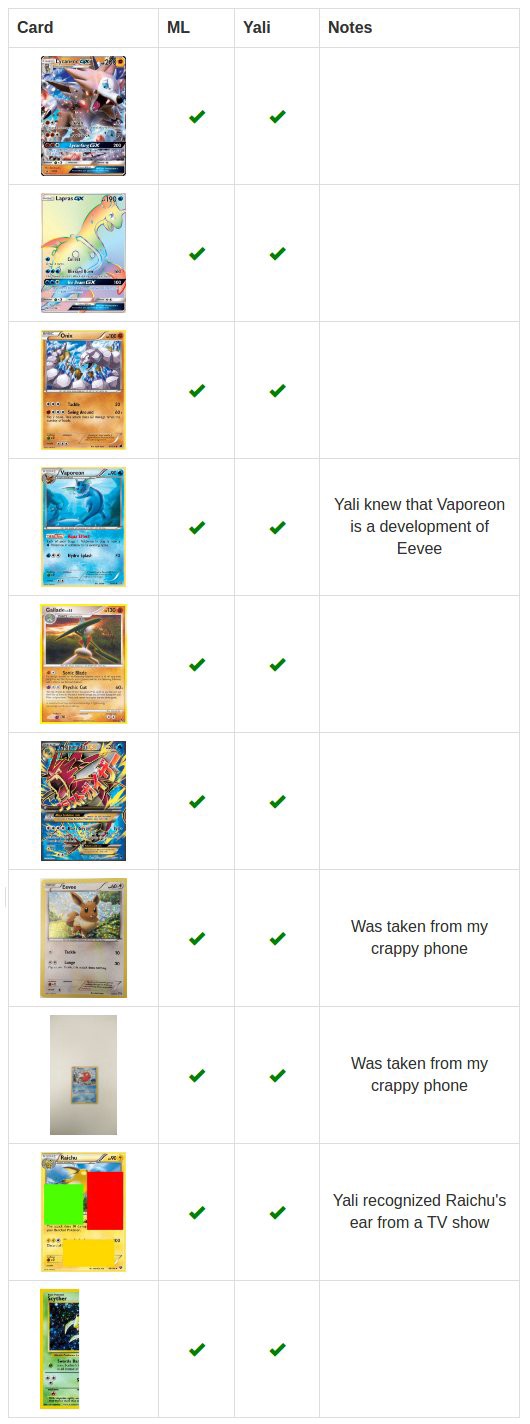
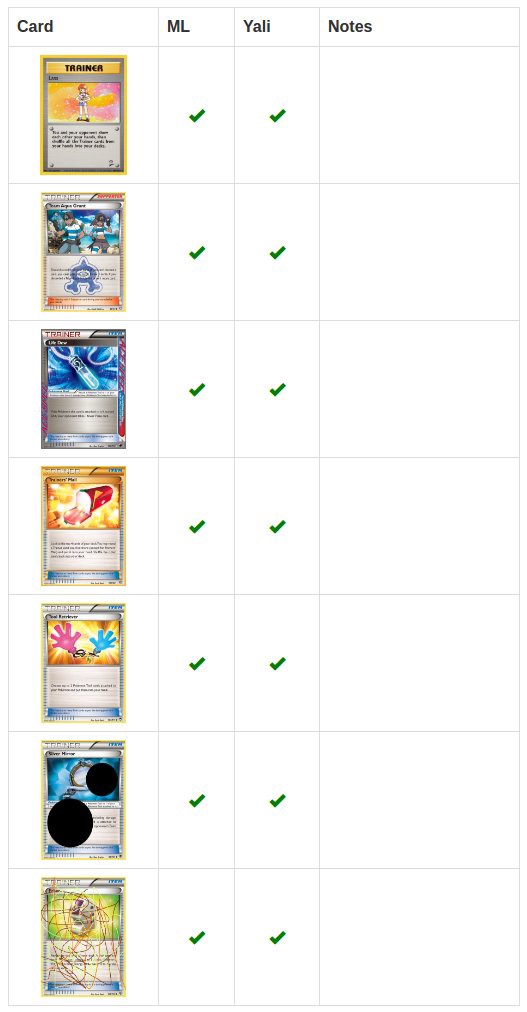
Ошибки происходят при распознавании энергетических карт. На pkmncards таких карт было всего 130, в отличие от тысяч карт других типов. Меньше примеров для обучения.
Я поспрашивал Яли по поводу того, как он распознавал карты, и он рассказал, что видел некоторых покемонов в телешоу или книгах. Именно так он распознал уши Райчу или узнал, что Вапореон – это водный Иви. У моей программы таких данных не было, только карты.
Победив Яли в игре с покемонами и получив награду, наш машинный интеллект отправляется навстречу новым приключениям.

Комментарии (7)

Alex_ME
08.04.2017 13:11Я использовал 1533 модели. Разные размеры картинок, несколько скрытых слоёв (до 3), длина слоя (до 100), цвета изображений, методы чтения изображений (всё целиком, верхняя часть, каждый второй пиксель, и т.п.)
Кто-нибудь, кто разбирается в ML, можете пояснить этот момент? Это значит разные конфигурации нейронных сетей и способов представления данных для них? Каждый вариант составляется вручную или как-то этот процесс может автоматизироваться? И каждый вариант надо отдельно обучить?
alex4321
08.04.2017 17:28Да, разные.
Можно перебираться возможные комбинации гиперпараметров (но, как минимум — нужно определиться с границами и тем, какие параметры перебираться).
И да — обучаются отдельно.
cepera_ang
10.04.2017 13:01Написано как-то сложно. В данном случае нужно было следовать заветам «Don't be a hero», а просто взять предобученную на ImageNet'e сеть, например, VGG-16 или Resnet-50 (обе есть встроенные во все основные фреймворки DL и даже с готовыми весами), добавить слой классификатора, отмасштабировать картинки в один (небольшой) размер и прогнать обучение пару эпох и готово.
Там ещё не понятно, обучал ли он на всём наборе карт и как проверял точность на новых (тех, которые модель не видела). Если обучал на всех, то по сути добился, чтобы модель выучила их все и давала правильные ответы, при этом непонятно может ли она новые распознать.Alex_ME
12.04.2017 01:53Спасибо за разъяснение.
А можете подсказать, где можно углубить знания по этим вопросам — до прочтения этой статьи и Вашего комментария даже не знал о существовании большого набора сетей
например, VGG-16 или Resnet-50
Большинство встреченных мною материалов по ML разжевывают основы ИНС, иногда немного базовой математики, вроде линейной регрессии, персептрон, обучение с обратным распространением ошибки (чаще всего на словах) и все. Иногда — сверточные сети в самых общих чертах.
cepera_ang
12.04.2017 13:18Просто на русском очень мало всего или вообще нет, сейчас на хабре идёт открытый курс по МЛ от ребят из opendatascience, в очереди посты как раз про сети и всё такое.
Если английский не проблема, то есть великолепные открытые источники:
— Видео-лекции введение от топовых чуваков в области про всё подряд (запись двухдневной школы в Стэнфорде): https://www.youtube.com/playlist?list=PLrAXtmErZgOfMuxkACrYnD2fTgbzk2THW
— онлайн книга начального/среднего уровня http://neuralnetworksanddeeplearning.com/
— более продвинутая (начинает с азов, но довольно резко усложняется, есть готовая пдф-версия где-то на гитхабе): http://www.deeplearningbook.org/
— великолепный курс по сетям в основном в приложении к картинкам (видео ищется на ютубе, скоро обещают версию 2017 официально выложить): https://cs231n.github.io
— подробный гайд как пользоваться вышеперечисленным для самостоятельного обучения: https://yerevann.com/a-guide-to-deep-learning/
Если останутся силы и станет скучно:
— топ-100 лучших статей по сетям за последние годы (все статьи огонь): https://github.com/terryum/awesome-deep-learning-papers
— другой похожий популярный список: https://github.com/songrotek/Deep-Learning-Papers-Reading-Roadmap

ivansmith
08.04.2017 20:13Мне показалось, что это просто сортировка по цвуту, но как-то очень сложно сделано…
sophist
> Алгоритму машинного обучения нужны особенности
Признаки. В контексте машинного обучения features – это признаки.