

Кирилл Дмитренко (Яндекс)
Всем привет! Меня зовут Кирилл Дмитренко, последние 4,5 года я работаю в Яндексе фронтенд-разработчиком. И все это время меня преследуют панорамы. Когда я пришел в компанию, я делал внутренние сервисы для панорам, после этого я решал задачи по панорамам на больших Яндекс.картах, а недавно сделал веб-плеер панорам на Canvas 2D, HTML и WebGL. Сегодня я хочу поговорить с вами о производительности WebGL-приложений.
Для начала мы посмотрим, что же такое WebGL, после этого мы обсудим, как можно измерять производительность WebGL-приложений, и закончим обсуждением некоторых оптимизаций WebGL-приложений и того, как мне удалось применить их в плеере панорам.
Итак, что же такое WebGL? WebGL – это API, который дает веб-платформе доступ к ресурсам графической карты, т.е. он позволяет рисовать аппаратно-ускоренную графику, в том числе трехмерную, прямо в браузере, прямо из вашего Javascript’а.
Структуру WebGL-приложения в некотором смысле можно сравнить с тем, как наши предки видели вселенную. Ну, по крайней мере, с одним из таких видений.

Т.е. это некий мир, который опирается на слонов, а те, в свою очередь, стоят на большой черепахе. И в этой картине миром, в котором вся логика, весь смысл, и все происходит, будет наше приложение. И наше WebGL-приложение будет опираться на три основных вида ресурсов:
- Буферы – такие большие блоки байт, куда мы укладываем нашу геометрию, которую мы хотим показывать пользователю, наши модели.
- Текстуры – картинки, которые мы хотим накладывать на наши модели, чтобы они выглядели красивее, естественнее, были похожи на объекты реального мира.
- Шейдеры – это небольшие программы, которые запускаются прямо на GPU и рассказывает GPU о том, как мы хотим показывать нашу геометрию, как мы хотим на нее накладывать наши текстуры и т.д.
И все эти ресурсы живут, рождаются и умирают в рамках WebGL-контекста. WebGL-контекст – такая большая черепаха на нашей картине, через него мы получаем доступ ко всем ресурсам, мы их создаем и, кроме того, в нем еще есть большое состояние, которое рассказывает о том, как мы связываем эти ресурсы между собой, как мы связываем вместе эти буферы, шейдеры, текстуры, и как мы используем результаты вычисления шейдеров. Т.е. большое состояние, которое влияет на рендеринг. Ну и, конечно, круто было бы, чтобы наше приложение работало побыстрее.
Но перед тем как говорить об оптимизациях, сначала нужно научиться измерять. Невозможно улучшить то, что мы не можем измерить. И самым простым инструментом, который позволяет нам это делать, является счетчик кадров в секунду.

Он доступен в Chrom’е, его несложно сделать самому, и с ним, в общем-то, все понятно, т.е. если у нас много кадров в секунду, то это хорошо, мало кадров – плохо. Но надо помнить одну тонкость, что FPS в приложении ограничен частотой обновления экрана пользователя. У большинства пользователей в дикой природе это 60 Гц, т.е. 60 кадров в секунду, и поэтому неважно, генерируем ли мы наш кадр за 5 мс, 10 мс… Всегда будет 60 кадров. К счетчику кадров в секунду нужно относиться с определенной толикой скепсиса. И все-таки, если у нас мало кадров в секунду, приложение тормозит, мы начинаем искать в нем узкие места. Мы начинаем пытаться его оптимизировать.
Я обычно в таких случаях думаю, как и вы – включаю профайлер, начинаю профилировать приложение, смотреть, в каких функциях мой JavaScript проводит больше всего времени, рассматривать эти функции под микроскопом и пытаться что-то с ними делать.
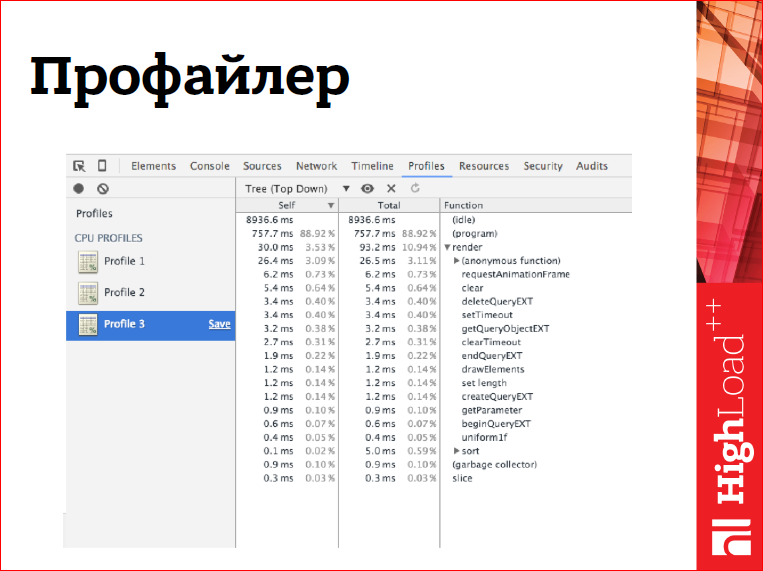
Однако в случае с OpenGL-приложениями профайлер сталкивается с проблемой.

Дело в том, что WebGL API частично асинхронное, т.е. все вызовы отрисовки асинхронны, некоторые другие вызовы тоже асинхронные. Что это значит, например, с вызовами отрисовки? Что когда, вызов вернул управление в наш JS, то отрисовка к этому моменту не закончилась, она закончится когда-то позже. Более того, она может начаться даже позже, чем нам вернулось управление. Т.е. все, что делает вызов отрисовки – он генерирует какую-то команду, складывает ее в буфер и возвращается к нам и говорит: «Вперед! Дальше!». Соответственно, в профайлере такие вызовы наверх не вылезут, да и, если у нас тормозит отрисовка, мы этого не увидим.
Но не все так плохо, некоторые вызовы все-таки синхронные, и некоторые вызовы, они не только синхронные, а они еще зловредным образом синхронизируют весь наш контекст. Т.е. они не только выполняют работу, которую мы на них возложили синхронно, они еще и, блокируя наше приложение при этом, дожидаются конца исполнения всех задач, которые мы возложили на контекст до этого, т.е. всех отрисовок, всех каких-то изменений состояний и т.д. Как раз такие проблемы профайлер поможет нам отловить.
А с отрисовкой нам может помочь другой инструмент, который называется EXT_disjoint_timer_query.

Это расширение для WebGL, оно еще жутко экспериментальное, т.е. это еще draft расширение. Оно позволяет измерять время выполнения наших команд на GPU. При этом, что очень круто, оно это делает асинхронно. Т.е. оно не синхронизирует наш контекст каким-то лишним образом, оно не добавляет много runtime overhead’ов, т.е. весь код, который мы напишем для измерения производительности приложения, можно будет ship’ить прямо в продакшн, прямо пользователям. И, например, собирать статистику. Или, что еще лучше, на основании этих данных, на основании этих измерений, подстраивать качество картинки под оборудование пользователя, т.е. на смартфонах показывать пользователям одну картинку, на планшетах – более качественную, потому что там обычно мощнее железо, а на десктопах, там, где бывает совсем мощное железо, показывать самую крутую картинку с самыми крутыми эффектами. Но при этом, надо написать какой-то код вокруг этого – это небольшой минус.

EXT_disjoint_timer_query позволяет измерить время исполнения первого или нескольких вызовов прямо на GPU. Еще оно позволяет ставить точные временные мерки в конвейере. Т.е. оно позволяет, например, измерить, сколько времени наши команды GL идут от нашего JS к GPU, т.е. какие у нас задержки в конвейере.
Еще EXT_disjoint_timer_query – это синхронный API, он позволяет создавать объекты query к драйверу, к реализации WebGL, через объекты query идет с ним работа. Вы создаете объект query и говорите: «Нет, я хочу поставить на этом объекте точную временную метку или начать с помощью него измерять время исполнения группы команд». После этого, вы заканчиваете построение кадра и обычно на следующий кадр, правда, возможно, позже, вам становятся доступны результаты измерения в наносекундах, довольно точные при этом. И эти измерения можно использовать.
Подведем краткие выводы про измерения.

У нас есть счетчик кадров в секунду как некая качественная характеристика приложения, которая позволяет сказать нам, тормозим мы или нет. И если мы тормозим, то профайлер JS нам поможет с поиском узких мест на CPU в нашем JS, в какой-то математике, в каком-то поддерживающим коде. EXT_disjoint_timer_query поможет нам с поиском узких мест на GPU.
Ок, мы научились измерять производительность, мы научились искать узкие места, теперь надо понять, что делать с ними дальше. Здесь мы обсудим лишь некоторые оптимизации. Графика компьютерная – это такая большая область хаков, обманов и оптимизаций странных. Мы обсудим лишь некоторые общие оптимизации, то, как я их применил в плеере панорам.

И первое правило, которое нужно взять на вооружение на пути к быстрому GL-приложению – это аккуратно работать с WebGL-состоянием. Как сказал в самом начале, в WebGL-контексте есть большой кусок состояния, который влияет на рендеринг и работать с ним нужно аккуратно. В частности, не нужно делать вызовов get* и read*, т.е. вызовов, которые запрашивают текущее состояние контекста или читают данные с видеокарты. Если это нам крайне необходимо. Почему? Потому что эти вызовы, мало того, что синхронны, они еще могут вызвать синхронизацию всего контекста, тем самым затормозив наши приложения. В частности, метод getError(), который проверяет, не возникла ли у нас ошибка в работе с WebGL-контекстом. Его стоит вызывать только в development’e, никогда в разработке. И нужно минимизировать переключения состояния, не делать это слишком часто, потому что каждое переключение нам чего-то стоит, в том числе тоже может вызывать синхронизации контекстов, а полезной какой-то работы, вообще говоря, не делает.
Как это может выглядеть в нашем коде?

В частности, это может выглядеть как-то вот так, т.е. вложенные друг в друга циклы, где во внешних циклах мы переключаем более дорогие состояния, мы переключаем их реже, а в более вложенных циклах мы переключаем состояния, которые переключать дешевле. В частности, подключение framebuffer’ов или переключение шейдерных программ – это довольно дорогие переключения, они практически гарантированно вызовут синхронизации и, вообще, проходят довольно долго. А переключение текстур и параметров шейдеров – они быстрее, их можно делать чаще.
Но и в этой замечательной конструкции можно оптимизироваться дальше.

Можно делать поменьше вызовов отрисовки и больше работы за каждый, т.е. каждый вызов отрисовки добавляет какой-то overhead на валидацию состояния, на отправку этих данных на видеокарту. И хорошо бы этот overhead размывать. А размывать его можно одним лишь способом – делая этих вызовов поменьше, добавляя поменьше overhead’ов, при этом делая больше работы за каждый вызов. В частности, можно уложить несколько объектов, несколько моделей, которые мы хотим нарисовать, в один буфер с данными. А если они используют текстуры, то все эти текстуры уложить в одну большую картинку, которую обычно называют текстурным атласом. И таким образом приведем несколько объектов к тому, что для них будет требоваться одинаковое состояние для отрисовки, и мы сможем нарисовать их за один вызов.
Есть такая хорошая техника, называется Instancing, которая позволяет рисовать несколько копий одного и того же объекта с разными параметрами за один вызов. Хорошим примером применения оптимизации Instancing является система частиц. Я хотел показать логотип нашей замечательной конференции, на которой мы находимся, нарисованный с помощью системы частиц, т.е. это небольшие объекты, небольшие модельки, которых очень много, там их было 50 тыс. И в первом случае я рисовал каждую из них отдельно, наивным подходом. А во втором случае я использовал специальное расширение.
Вообще, использовать расширения – это хорошая практика, в них часто заложены очень крутые фичи, без которых сложно или невозможно делать какие-то вещи. Наоборот, надо использовать их аккуратно, т.е. надо всегда оставлять запасной путь в коде, который будет работать без расширений.
Я использовал там ANGLE_instanced_arrays, который реализует Instancing для WebGL, т.е. я уложил все свои параметры для всех копий объектов в большой буфер, рассказал WebGL’у, что это буфер с параметрами копий, и – хоп! и он отрисовался. И дальше был красивый эффект, что там от 10 до 60 FPS все поднялось.
Что у нас было с этим делом в панорамах?

В панорамах минимизацию переключения контекста мы получили фактически бесплатно. Почему так получилось? Потому что у нас сама задача так стояла, т.е. мы рисуем в плеере сначала панораму, потом подписи объектов, а потом элементы управления, стрелочки переходов и шайбу быстрого перехода. И из этой формулировки вытекало, что одинаковые объекты мы рисуем рядом в коде. При этом мы применили Instancing для маркеров, т.е. все маркеры, все подписи объектов мы рисуем за один вызов отрисовки. И еще мы не генерируем вызовы отрисовки для секторов панорамы, которых не видно. Зачем генерировать вызов для того, чего мы все равно не увидим на экране? Т.е. техника, которая обычно называется viewport culling или frustrum culling.
И в этом месте, важно сказать, что у нас в Яндексе сферические панорамы, т.е. это какая-то картинка, наложенная на сферу. Когда вы открываете плеер, вы «стоите» в центре этой картинки и смотрите наружу. Так это выглядит, если посмотреть снаружи сферы, а не изнутри.

Так выглядит панорамная структура, панорамная картинка, приезжающая с сервера, т.е. она у нас в равнопрямоугольной проекции, мы ее так и храним:

Еще мы ее разрезаем на небольшие сектора для того, чтобы было удобно с ней работать в WebGL:

В WebGL нельзя создать сильно большие текстуры.
И для каждого такого сектора мы можем вычислить, попадает он у нас на экран или нет. Если он не попадает, мы не только его исключаем из списка на отрисовку, мы еще удаляем те ресурсы, которые он занимает, т.о. экономим память. Как только он снова становится виден, мы выделяем для него пустую текстуру, и данное изображение мы перезагружаем из кэша браузера.
Как-то так это выглядит в геометрии, т.е. каждому сектору текстуры соответствует сектор в геометрии сферы, и так это все и рисуется:

Другим большим и страшным грехом в WebGL-приложениях является Overdraw.

Что такое Overdraw? Это когда мы считаем пиксели по нескольку раз. Например, как на схеме, приведенной на слайде. Если мы сначала нарисуем прямоугольник, потом круг, а потом треугольник, то получится, что часть прямоугольника, а после этого и часть круга мы считали зря. Мы их все равно не видим, а ресурсы на них потрачены. Хорошо бы этого избегать. Существуют разные техники для этого.

Первая – это посчитать наподобие того, как мы делаем с секторами текстуры, невидимые объекты, т.е. объекты, которые закрываются другими объектами от нас, на CPU в нашем JS и не рисовать их, не генерировать для них вызовы отрисовки. Эта техника называется occlusion culling. Не всегда это просто сделать в JS, JS не очень быстрый с математикой.
Можно применить более простые техники, например, сортировать объекты по глубине, т.е. рисовать их от ближнего к дальнему, и тогда видеокарта сама сможет исключить из этого обсчета те пиксели, которые она будет точно знать, что они не попадут на экран, что они дальше, чем те, которые уже есть в кадре.
И если это сделать сложно, например, потому что объекты протяженные или хитро самопересекаются, можно сделать Depth pre-pass, т.е. с помощью очень простых шейдеров наполнить буфер глубины, тем самым рассказав видеокарте расстояние каждого пикселя от экрана и т.д., видеокарта сможет применить ровно ту же самую оптимизацию, что и в предыдущем случае.

В панорамах мы столкнулись с overdrow, решая другую проблему. Должно быть, что панорамная картинка напилена на сервере в нескольких размерах, в нескольких разрешениях, и мы хотим отображать пользователю размер картинки, наиболее подходящий для текущего зума плеера или текущего зума панорамы. Однако при этом мы хотим показывать ему наилучшее качество, которое у нас уже есть, что не всегда оптимально, могут быть меньшего качества. Как это выглядит?

Сначала мы рисуем самое плохое качество картинки, самое размытое, самое мыльное, потому что оно быстрее всего приезжает. После этого мы рисуем поверх него все, что у нас качества получше.

И тут видно, что не все участки картинки у нас есть, некоторые отсутствуют и они прозрачны и через них видно меньшее качество.

И после этого мы рисуем самое лучшее качество, которое у нас есть, которое тоже может быть частично прозрачное, потому что не приехали еще детали картинки.

И снова у нас есть просветы, через которые видно предыдущий слой:

Таким образом, за четыре прохода мы генерируем картинку панорамы на экране для пользователя. Почему так получилось? Потому что, во-первых, часть текстуры может быть прозрачной, и было не очень тривиально вычислять, какие, вообще говоря, прозрачные, а какие менее качественные части текстуры, закрыты частями более качественными. Поэтому приходилось так мучиться. На Retina-экранах это очень сильно тормозило, потому что там много пикселов, и не очень хорошо работало на мобильных.
Как мы это обошли? Если внимательно посмотреть на эту схему, которую я сейчас показывал, то можно предположить, что, вообще говоря, эту операцию можно сделать за один раз. Т.е. один раз схлопнув эти слои в один какой-то промежуточный буфер, его можно назвать кэш, и рисовать потом только его в кадре. Ровно это мы и сделали.

Допустим, у нас прилетели данные плохого качества, т.е. справа у нас данные, слева – текстура панорамная, ну, кусочек ее. У нас прилетели данные хорошего качества – мы отрисовали текстуру. Прилетели данные получше – мы отрисовали его текстуру поверх имеющихся плохих данных. Прилетели совсем хорошие данные – и мы их тоже нарисовали поверх. У нас все время одна картинка, которая оффлайново собирается из прилетающих данных.
Конечно, не всегда все так хорошо, сеть – штука непредсказуемая, и данные могут прийти не в том порядке. Но решаем проблему довольно просто.

Снова к нам прилетает плохая картинка, потом прилетает самая лучшая картинка, мы рисуем ее поверх. А потом прилетает картинка меньшего качества, мы ее, конечно, не выводим. Мы оставляем лучшее качество, которое у нас уже есть. Т.о. мы сводим несколько проходов рендеринга панорамы к одному, и это ускорило нас на разных девайсах, в том числе на Retina-девайсах.

Нередко наш код рендеринга, который написан на WebGL, работает очень быстро, он способен выдавать 60 fps на смартфонах, планшетах, десктопных компьютерах. А вот всякий код вокруг, который неизбежно присутствует в нашем веб-приложении, код, который обновляет DOM, код, который загружает ресурсы, код, который обрабатывает события пользователя, события UI, он начинает нас тормозить, т.е. он надолго забирает управление, вызывая задержки в анимациях, задержки в рендеринге и тормозит наше приложение.

С таким кодом, кажется, ничего нельзя сделать, кроме того, чтобы разбить его на небольшие части, т.е. если у нас грузится 100 картинок, то не надо грузить сразу 100, нужно грузить по 10, дюжинами, пятаками, как удобно. И написать планировщик, который будет исполнять этот код только тогда, когда на него реально есть время, когда он не затормозит анимацию.

Для нас в панорамах таким кодом стала загрузка тайлов и вытеснение невидимых частей панорамы, про которое я говорил в самом начале. С ним мы поступили очень просто – мы никогда не делаем этого, пока панорама движется, ведь если у нас картинка статичная, неважно, какой у нас fps, сколько кадров в секунду мы показываем, может быть, 1, может быть, 60 – пользователь не заметит разницы, картинка не движется, ничего не меняется на экране. Поэтому мы дожидаемся, пока закончится анимация и пересчитываем видимые тайлы, пересчитываем видимые сектора, текстуры. Создаем запросы и управляем ресурсами.
Кроме того, источниками проблем стали события программного интерфейса плеера. Плеер – это виджет, который встраивается в большие карты, и большие карты используют какие-то внешние события для того, чтобы показывать какие-то свои дополнительные элементы интерфейса.
С событиями API мы поступили довольно просто. Во-первых, мы их затроттлили, т.е. те события, которые должны генерироваться постоянно, например, пока меняется направление взора пользователя, направление взгляда в панораме, мы эти события затроттлили, т.е. значительно понизили частоту их генерации. Но и этого оказалось недостаточно, например, много проблем нам в этом месте создало history API браузера. Мы пытались по каждому событию изменения взгляда обновлять ссылку в адресной строке но это жутко тормозило все. И поэтому было сделано специальное событие, которое рассказывало уже внешнему коду о том, что панорама остановилась и можно делать тяжелую работу. Такая же схема, кстати, применена в API Яндекс карт. Там есть специальные события, по которым можно делать какую-то более тяжелую работу.
Давайте подведем выводы про оптимизацию.

Первое и самое важное – это нужно аккуратно работать с состоянием, потому что в самом неожиданном месте может возникнуть зловредная синхронизация, затормозить наше приложение. Не вызывать чтение состояния, не читать, если нет крайней необходимости читать данные с видеокарты и не вызывать get error в продакшне. Это самое важное.
Делать поменьше вызовов отрисовки и больше работы за каждый из них, т.о. мы размываем overhead, которые они добавляют.
Избегать overdraw самыми разными техниками, любыми, которые подойдут вашему приложению.
И планировщик для кода вокруг, т.е. планировщик для кода, который поддерживает рендеринг, и для того, чтобы он не забирал надолго управление и не тормозил.
Контакты
» dmikis@yandex-team.ru
» Профиль на Github
» Профиль на Facebook
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++.
Да, мы уже два года проводим секцию, которая называется «Производительность фронтенда».
Все видео HighLoad++ опубликованы в нашем аккаунте на YouTube, но вот работу по систематизации и выделению всей секции в отдельный плейлист мы ещё не сделали :(
В этом году на конференцию фронтенд-разработчиков Frontend Conf подано аж четыре доклада с тегом WebGL:
- Интерактивные 3D-карты своими руками / Александр Амосов (Avito);
- Портируем существующее Web-приложение в виртуальную реальность / Денис Радин (Liberty Global);
- Компоненты на GLSL шейдерах для контроля над каждым пикселом Web-приложения без потери производительности или самый технологичный спиннер в браузере, как и зачем он был создан? / Денис Радин (Liberty Global);
- Веб-погружение или виртуальная реальность с WebVR / Татьяна Кузнецова (DevExpress).
Интересно? Тогда ждём Вас на конференции! Но это за деньги.
Или бесплатно на трансляции, которую мы организуем совместно с Хабром :). Транслироваться будет не сама Frontend Conf, а лучшие доклады со всего фестиваля.
Поделиться с друзьями
GDXRepo
Да кто ж вас знает, может, работаете, а может, и нет… Шутка. Веселое начало, поправьте) А статья интересная, спасибо.
evocodes
Не один я такой внимательный юморист )) Статья действительно зачётная, только поправьте, пожалуйста, опечатки!
clamaw
Работаю:)