
Привет, Друзья!
Я написал библиотеку поисков путей на произвольных графах, и хотел бы поделиться ей с вами.
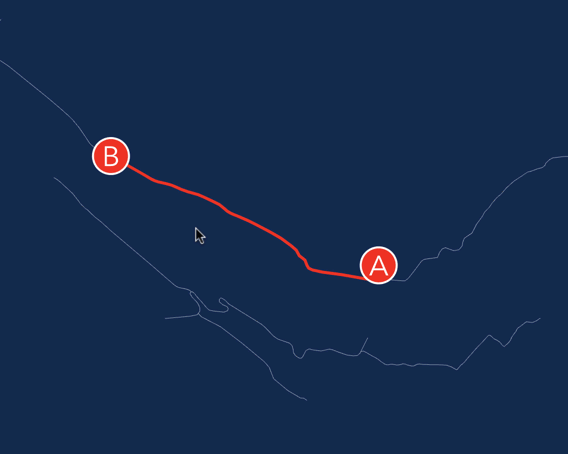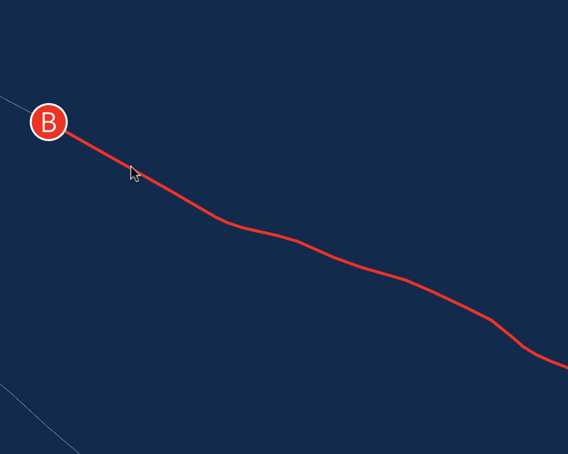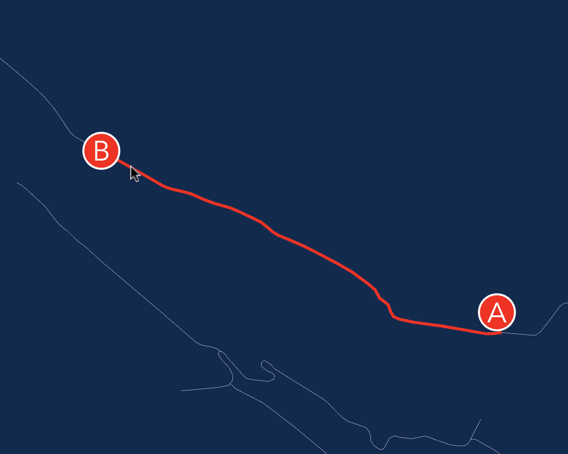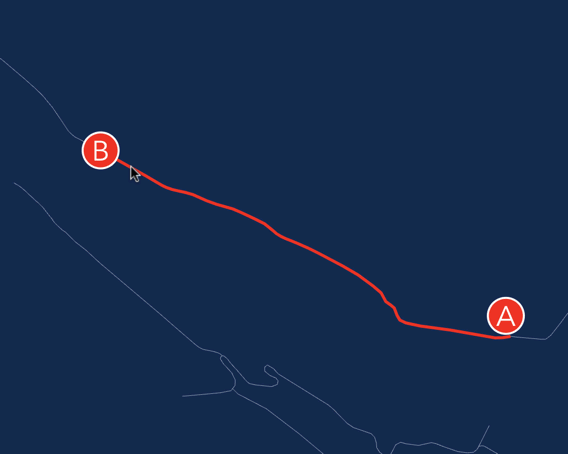
Пример использования на огромном графе:
Поиграться с демо можно здесь
В библиотеке используется мало-известный вариант A* поиска, который называется NBA*. Это двунаправленный поиск, с расслабленными требованиями к функции-эвристике, и очень агрессивным критерием завершения. Не смотря на свою малоизвестность у алгоритма отличная скорость сходимости к оптимальному решению.
Описание разных вариантов A* уже не раз встречалось на хабре. Мне очень понравилось вот это, потому повторяться в этой статье я не буду. Под катом расскажу подробнее почему библиотека работает быстро и о том, как было сделано демо.
Почему библиотека работает быстро?
"Как-то не верится что так быстро. Ты точно ниче не считаешь предварительно?"
Реакция друга, который первый раз увидел библиотеку.
Сразу должен признаться, я не верю что моя реализация — самая быстрая из возможных. Она работает достаточно быстро учитывая окружение в котором находится (браузер, javascript). Ее скорость сильно будет зависеть от размера графа. И, конечно же, то, что сейчас есть в репозитории можно ускорить и улучшить.
Статистика
Для замера производительности я взял граф дорог из Нью-Йорка ( ~730 000 ребер, 260 000 узлов). Таблица ниже показывает статистику времени, необходимого для решения одной задачи поиска пути из 250 случайно выбранных:
| Среднее | Медиана | Min | Max | p90 | p99 | |
|---|---|---|---|---|---|---|
| A* ленивый (локальный) | 32ms | 24ms | 0ms | 179ms | 73ms | 136ms |
| NBA* | 44ms | 34ms | 0ms | 222ms | 107ms | 172ms |
| A*, однонаправленный | 55ms | 38ms | 0ms | 356ms | 123ms | 287ms |
| Дейкстра | 264ms | 258ms | 0ms | 782ms | 483ms | 631ms |
Каждый алгоритм решал одну и ту же задачу. A* ленивый самый быстрый, но его решение не всегда оптимально. По-сути, это двунаправленный A* который сразу же выходит как только оба поиска встретились. NBA* двунаправленный, сходится к оптимальному решению. В 99% ему понадобилось меньше чем 172 миллисекунды, чтобы найти кратчайший путь (p99).
Оптимизации
Библиотека работает относительно быстро по нескольким причинам.
Во-первых, я изменил структуру данных в приоритетной очереди таким образом, что обновление приоритета любого элемента очереди занимает O(lg n) времени. Это достигается тем, что каждый элемент отслеживает свою позицию в куче во время перестройки очереди.
Во-вторых, во время нагрузочных тестов я заметил, что уборка мусора занимает значительное время. Это не удивительно, поскольку алгоритм создает много маленьких объектов когда он ходит по графу. Решается проблема со сборщиком мусора при помощи пула объектов. Это структура данных которая позволяет повторно использовать объекты, когда они уже не нужны.
Ну и наконец, алгоритм поиска NBA* имеет очень красивый и жесткий критерий посещения узлов.
Признаться, я думаю что это не предел совершенства. Вполне вероятно, если использовать иерархический подход, описанный Борисом удастся ускорить время для еще больших графов.
Как работает демо?
Создание библиотеки это, конечно, очень интересно. Но мне кажется демо-проект заслуживает отдельного описания. Я усвоил несколько уроков, и хотел бы поделиться с вами, в надежде, что это окажется полезным.
Прежде чем начнем. Кто-то меня спросил: "Но ведь это же граф? Как можно карту представить в виде графа?". Легче всего представить каждый перекресток узлом графа. У каждого перекрестка есть позиция (x, y). Каждый прямой участок дороги сделаем ребром графа. Изгибы дороги можно моделировать как частный случай перекрестков.
Готовим данные
Конечно, я слышал об https://www.openstreetmap.org, но их внешний вид меня не сильно привлекал. Когда же я обнаружил API и инструменты типа http://overpass-turbo.eu/ — это как новый мир открылся перед глазами :). Данные они отдают под лицензией ODbL, которая требует чтобы их упомянули (чем больше людей знают о сервисе — тем лучше становится сервис).
API позволяет делать очень сложные запросы, и дает потрясающие объемы информации.
Например, такой запрос даст все велодороги в Москве:
[out:json];
// Сохранить область в переменную `a`
(area["name"="Москва"])->.a;
// Скачать все дороги внутри a у которых аттрибут `highway == cycleway`
way["highway"="cycleway"](area.a);
// и объединить дороги с узлами графа (узлы содержат геопозицию)
node(w);
// Наконец, вернуть результаты
out meta;API очень хорошо описано здесь: http://wiki.openstreetmap.org/wiki/Overpass_API
Я написал три маленьких скрипта, чтобы автоматизировать получение дорог для городов, и сохранять их в мой формат графа.
Сохраняем граф
Данные OSM отдает в виде XML или JSON. К сожалению оба форматы слишком объемные — карта Москвы со всеми дорогами занимает около 47MB. Моя же задача была сделать загрузку сайта как можно быстрее (даже на мобильном соединении).
Можно было бы попробовать сжать gzip'ом — карта Москвы из 47МБ превращается в 7.1МБ. Но при таком подходе у меня не было бы контроля над скоростью распаковки данных — их бы пришлось парсить javascript'ом на клиенте, что тоже повлияло бы на скорость инициализации.
Я решил написать свой формат для графа. Граф разбивается на два бинарных файла. Один с координатами всех вершин, а второй с описанием всех ребер.
Файл с координатами — это просто последовательность из x, y пар (int32, 4 байта на координату). Смещение по которому находится пара координат я рассматриваю как иденификатор вершины (nodeId).

Ребра графа превращаются в обычную последовательность пар fromNodeId, toNodeId.

Последовательность на картинке означает, что первый узел ссылается на второй, а второй ссылается на третий, и так далее.
Общий размер для графа с V узлами и E ребрами можно подсчитать как:
storage_size = V * 4 * 2 + # 4 байта на пару координат на узел
E * 4 * 2 = # 4 байта на пару идентификаторов вершин
(V + E) * 8 # суммарно, в байтахЭто не самый эффективный способ сжатия, но его очень легко реализовать и можно очень быстро восстановить начальный граф на клиенте. Типизированные массивы в javascript'e работают быстрее, чем парсинг JSON'a.
Сначала я хотел добавить также вес ребер, но остановил себя, ибо загрузка на слабом мобильном соединении даже для маленьких графах станет еще медленнее.
В первую очередь мобильные телефоны
Когда я писал демо, я думал, что напишу о нем в Твиттер. Твиттер большинство людей читают с мобилок, а потому и демо должно быть в первую очередь рассчитано на мобильные телефоны. Если оно не будет загружаться быстро, или не будет поддерживать touch — пиши пропало.
Спустя пару дней после анонса, можно признать логику выше оправданной. Твит с анонсом демо стал самым популярным твитом в жизни моего твиттера.
Я тестировал демо в первую очередь на платформах iPhone и Андроид. Для тестов на Андроиде я нашел самый дешевый телефон и использовал его. Это очень сильно помогло с отладкой производительности и удобства использования на маленьком экране.
Асинхронность
Самая медленная часть в демо была начальная загрузка сайта. Код, который инициализировал граф выглядел как-то так:
for (let i = 0; i < points.length; i += 2) {
let nodeId = Math.floor(i / 2);
let x = points[i + 0];
let y = points[i + 1];
// graph это https://github.com/anvaka/ngraph.graph
graph.addNode(nodeId, { x, y })
}На первый взгляд — ничего плохого. Но если запустить это на слабеньком процессоре и на большом графе — страничка становится мертвой, пока основной поток занят итерацией.
Выход? Я знаю, некоторые используют Web Workers. Это прекрасное решение, учитывая что все сейчас многоядерное. Но в моем случае, использование web workers значительно бы продлило время, необходимое для создания демо. Нужно было бы продумать как передавать данные между потоками, как синхронизировать, как сохранить жизнь батарее, как быть когда web workers не доступны и т.д.
Поскольку мне не хотелось тратить больше времени, нужно было более ленивое решение. Я решил просто разбить цикл. Просто запускаем его на некоторое время, смотрим сколько времени прошло, и потом вызываем setTimeout() чтобы продолжить на следующей итерации цикла событий. Все это сделано в библиотеке rafor.
С таким решением у браузера появляется возможность постоянно информировать пользователя о том, что происходит внутри:

Отрисовка
Теперь, когда у нас загружен граф, нужно показать его на экране. Конечно, использовать SVG для отрисовки миллиона элементов не годится — скорость начнет проседать после первого десятка тысяч. Можно было бы нарезать граф на тайлы, и использовать Leaflet или OpenSeadragon чтоб нарисовать большую картинку.
Мне же хотелось иметь больше контроля на кодом (и подучить WebGL), поэтому я написал свой WebGL отрисовщик с нуля. Там я использую подход "scene graph". В таком подходе мы строим сцену из иерархии элементов, которые можно нарисовать. Во время отрисовки кадра, мы проходим по графу, и даем возможность каждому узлу накопить трансформации или вывести себя на экран. Если вы знакомы с three.js или даже обычным DOM'ом — подход будет не в новинку.
Отрисовщик доступен здесь, но я намеренно не документировал его сильно. Это проект для моего собственного обучения, и я не хочу создавать впечатление, что им можно пользоваться :)
Батарейка

Изначально, я перерисовывал сцену на каждом кадре. Очень быстро я понял, что это сильно греет телефон и батарея уходит в ноль с примечательной скоростью.
Писать код при таких условиях было так же неудобно. Для работы над проектом, я обычно заседал в кофейне в свободное время, где не всегда были розетки. Поэтому мне нужно было либо научиться думать быстрее, либо найти способ не сажать ноутбук так быстро.
Я до сих пор не нашел способ как думать быстрее, потому я выбрал второй вариант. Решение оказалось по-наивному простым:
Не рисуй сцену на каждом кадре. Рисуй только когда попросили, или когда знаешь, что она поменялась.
Может, это покажется слишком очевидным сейчас, но это было вовсе не так сначала. Ведь в основном все примеры использования WebGL описывают простой цикл:
function frame() {
requestAnimationFrame(frame); // Планируем следующий кадр
renderScene(); // рисуем текущий кадр.
// Ничего плохого в этом нет, но батарею мы можем так быстро посадить
}С "консервативным" подходом, мне нужно было вынести requestAnimationFrame() наружу из функции frame():
let frameToken = 0;
function renderFrame() {
if (!frameToken) frameToken = requestAnimationFrame(frame);
}
function frame() {
frameToken = 0;
renderScene();
}Такой подход позволяет кому угодно затребовать нарисовать следующий кадр. Например, когда пользователь перетащил карту и изменил матрицу преобразования, мы вызываем renderFrame().
Переменная frameToken помогает избежать повторного вызова requestAnimationFrame между кадрами.
Да, код становится немного сложнее писать, но жизнь батарее для меня была важнее.
Текст и линии
WebGL не самый простой в мире API. Особенно сложно в нем работать с текстом и толстыми линиями (у которых ширина больше одного пикселя).
Учитывая что я совсем новичок в этом деле, я быстро понял, что добавить поддержку текста/линий займет у меня очень много времени.
С другой стороны, из текста мне нужно было нарисовать только пару меток A и B. А из толстых линий — только путь который соединяет две вершины. Задача вполне по силам для DOM'a.
Как вы помните, наш отрисовщик использует граф сцены. Почему бы не добавить в сцену еще один элемент, задачей которого будет применять текущую трансформацию к… SVG элементу? Этот SVG элемент сделаем прозрачным, и положим его сверху на canvas. Чтобы убрать все события от мышки — ставим ему pointer-events: none;.

Получилось очень быстро и сердито.
Перемещаемся по карте
Мне хотелось сделать так, чтобы навигация была похожа на типичное поведение карты (как в Google Maps, например).
У меня уже была написана библиотека навигации для SVG: anvaka/panzoom. Она поддерживала touch и кинетическое затухание (когда карта продолжает двигаться по инерции). Для того чтобы поддерживать WebGL мне пришлось чуть-чуть подправить библиотеку.
panzoom слушает события от пользователя (mousedown, touchstart, и т.п.), применяет плавные трансформации к матрице преобразования, и потом, вместо того чтобы напрямую работать с SVG, она отдает матрицу "контроллеру". Задача контроллера — применить трансформацию. Контролер может быть для SVG, для DOM или даже мой собственный контроллер, который применяет трансформацию к WebGL сцене.
Как понять что кликнуто?
Мы обсудили как загрузить граф, как его нарисовать, и как двигаться по нему. Но как же понять что было нажато, когда пользователь касается графа? Откуда прокладывать путь и куда?
Когда пользователь кликнул на карту, мы могли бы самым простым способом обойти все точки в графе, посмотреть на их позиции и найти ближайшую. На самом деле, это отличный способ для пары тысяч точек. Если же число точек превышает десятки/сотни тысяч — производительность будет не приемлема.
Я использовал квад дерево чтобы проиндексировать точки. После того как дерево создано — скорость поиска ближайшего соседа становится логарифмической.
Кстати, если термин "квад дерево" звучит устрашающе — не стоит огорчаться! На самом деле квад-деревья, очень-очень похожи на обычные двоичные деревья. Их легко усвоить, легко реализовать и легко применять.
В частности, я использовал собственную реализацию, библиотека yaqt, потому что она неприхотлива по памяти для моего формата данных. Существуют лучшие альтернативы, с хорошей документацией и сообществом (например, d3-quadtree).
Ищем путь
Теперь все части на своих местах. У нас есть граф, мы знаем как его нарисовать, знаем что было на нем нажато. Осталось только найти кратчайший путь:
// pathfinder это объект https://github.com/anvaka/ngraph.path
let path = pathFinder.find(fromId, toId);Теперь у нас есть и массив вершин, которые лежат на найденном пути.
Заключение
Надеюсь, вам понравилось это маленькое путешествие в мир графов и коротких путей. Пожалуйста, дайте знать если библиотека пригодилась, или если есть советы как сделать ее лучше.
Искренне желаю вам добра!
Андрей.
Комментарии (51)

dem0n3d
25.09.2017 09:48+1Впечатляет. Я пару лет назад делал нечто подобное на pgrouting, и там используется двунаправленный Дейкстра, вероятно, неспроста. Неплохо было бы здесь его добавить в сравнение. Ещё можно было бы и BFS/DFS включить для наглядности...
Можно было бы попробовать сжать gzip'ом — карта Москвы из 47МБ превращается в 7.1МБ. Но при таком подходе у меня не было бы контроля над скоростью распаковки данных — их бы пришлось парсить javascript'ом на клиенте, что тоже повлияло бы на скорость инициализации.
gzip распаковывается браузером.
Это не самый эффективный способ сжатия, но его очень легко реализовать и можно очень быстро восстановить начальный граф на клиенте.
Ну а на сколько эффективнее (меньше) получилось чем JSON, XML/gzip?
anvaka Автор
25.09.2017 10:04> gzip распаковывается браузером.
Вы правы. Меня больше смущало отсутствие потокового парсинга JSON'a. Ну и потом, работа напрямую с типизрованными массивами потенциально дает возможность загнать данные сразу в видеобуфер. Не то, чтобы я это делал, но все же :)… Впрочем, глядя критично на вещи, не исключено что я тут чуть-чуть занялся велосипедостроительством и преждевременной оптимизацией.
> Ну а на сколько эффективнее (меньше) получилось чем JSON, XML/gzip?
Карта Москвы из 7.1МБ превратилась в 6.5МБ. Не сильно

RPG18
25.09.2017 10:01Интересно. Даст ли WebAssembly прирост производительности.
anvaka Автор
25.09.2017 10:16+1Хороший вопрос! Я когда-то считал
pagerankв javascript'e и ради интереса написал алгоритм на asm.js и на типизированных массивах. Только что проверил наnode 7.2.1, asm.js все еще медленнее чем типизированные массивы раза в пять (60 операций в секунду против 12). Мозиловский javascript движок, конечно, выигрывал на asm.js версии, когда проверял его несколько лет назадRPG18
25.09.2017 11:31Мы тестировали свой проект на iPad/iPhone с beta/TP Safari и получили 30 fps на wasm против 4 на asm.js. Правда в основном проект рисует графики, индикаторы нежели крутит комбинаторные задачки.
anvaka Автор
25.09.2017 17:37Интересно. Я думал wasm это просто asm.js завернутый в бинарный формат. Это не так?
DaylightIsBurning
25.09.2017 13:00Простая нативная реализация Дейкстры на таком графе ( ~730 000 ребер, 260 000 узлов) даст примерно 20-50 ms на одном ядре. Соответственно это число нужно делить примерно на 5 для A*. 20 ms — это 50 fps. Для пользовательских интерфейсов этого должно быть более чем достаточно — не нужно даже с приближёнными алгоритмами типа A* заморачиваться.
anvaka Автор
25.09.2017 17:39Очень интересно! Откуда данные? Можно ли посмотреть на код?

leschenko
25.09.2017 22:27Для поиска кратчайшего пути в связанном графе от одной вершины до другой есть Алгоритм Дейкстры. Код там же можно посмотреть.
В Вашем случае алгоритм строит не кратчайший путь, а быстро его строит. Собственно, Вы так и написали. Было бы интересно сравнить точность и время работы.anvaka Автор
25.09.2017 23:14Это не совсем верно. Все поисковики в моей библиотеке находят кратчайший путь, за исключением
A* greedy.
Алгоритм Дейкстры — это частный случай алгоритма
A*— просто функция эвристика всегда отдает 0.
Я так понял DaylightIsBurning сказал что 20-50ms будет скорость поиска кратчайшего пути, если использовать WebAssembly — потому мне хотелось узнать подробнее о методе/коде.
DaylightIsBurning
25.09.2017 23:5120-50ms будет скорость поиска кратчайшего пути, если использовать WebAssembly
По сути да, а точнее — полный просчёт SSSP задачи алгоритмом Дейкстры, и не WebAssembly, а нативный код. Я писал для себя маленькую функцию на C++ для этих целей (адаптированый копи-паст из гугла). В моём случае графы были с числом узлов ~110k и числом связей ~15*110k. На одном ядре i7-4930K получалось 20-30ms. В моём случае это были grid-графы на трёхмерной решётке. При этом глубина связывания была больше 1 (то есть не только 27 ближайших соседей рассматривалось но и часть второй коорд. сферы).
Код не идеальный, но если Вам интересно, то вот (главное в pathLength).anvaka Автор
25.09.2017 23:59Спасибо!
DaylightIsBurning
26.09.2017 01:02Если моя оценка производительность в ~6 тактов на операцию верна, то граф 730 000 ребер, 260 000 узлов должен обходиться за:
(|E| + |V|)*log|V|*6 тактов, что для моего CPU даст
(730000 + 260000)*log2(260000)*6 cycles /( 3.4*10^9 cycles/s) = 31.4 ms

wataru
25.09.2017 23:37У вас какие-то уж слишком оптимистичные оценки. Алгоритм дейкстры требует O(n log n + m log n) операций. Если подсчитать для этого графа, будет 17,820,000. Это надо умножить на константу — возьмем очень консервативно: 2. Т.е. у нас ~35 миллионов операций. Далеко не все из них тривиальные — там всякие скачки по указателям, сравнения. Если в среднем считать по 10 тактов на операцию, то при частоте в 3 Ghz это все займет 160 ms.
Для 20ms, как вы утверждаете, все операции должны занимать в среднем 1,25 такта, что просто невероятно. А это я еще константу маленькую взял. На практике, особенно в javascript'е оно будет в несколько раз больше.
DaylightIsBurning
26.09.2017 00:16Видимо, всё же константа ещё меньше. Только что проверил время выполнения:
Edges:13242707
Nodes:357911
Time Dijkstra: 78.862933 ms
Edges:13242707
Nodes:357911
Time Dijkstra: 87.523608 ms
Edges:13242707
Nodes:357911
Time Dijkstra: 63.876857 ms
Edges:8398297
Nodes:226981
Time Dijkstra: 37.649051 ms
Edges:8398297
Nodes:226981
Time Dijkstra: 37.884030 ms
Edges:8398297
Nodes:226981
Time Dijkstra: 38.607603 ms
Вот выдрал соответствующую часть кода. Скачков по указателям почти нет т.к. граф и куча реализованы поверх std::vector.DaylightIsBurning
26.09.2017 00:50Поправка, число узлов/рёбер получилось завышенным в 2 раза, т.к. реально поиск останавливался когда доходил до границы сферы, а не куба, т.е. реальное число узлов в Pi/6 раз меньше, число рёбер — аналогично.
Правильная производительность:
5.87181229 CPU cycles/operation=3.4*10^9 cycles/s*37.649051 ms/[(8398297/2+226981/2)operations*log(226981/2)]
То есть ещё можно оптимизировать. Пока что выходит не 20ms, но недалеко от моёй первой верхней оценки — 60-70ms.
DaylightIsBurning
26.09.2017 00:33Дейкстра, при правильной куче получается O(|E| + |V| log|V|), если верить википедии. У меня, наверное, O((|E| + |V|)*log|V|)
(8398297+226981)*log(226981)=153462774.844
3.4*10^9Hz*37.649051 ms/153462774.844=0.83 операций на такт. Учитывая что так кеш-миссов нет — вполне нормально. Наверное, можно как-то еще SIMD задействовать, но я не представляю, как.
zartarn
25.09.2017 12:45+1Я решил написать свой формат для графа. Граф разбивается на два бинарных файла. Один с координатами всех вершин, а второй с описанием всех ребер.
Файл с координатами — это просто последовательность из x, y пар (int32, 4 байта на координату). Смещение по которому находится пара координат я рассматриваю как иденификатор вершины (nodeId).
Вроде это CSR формат для хранения графов. Тут было встречал habrahabr.ru/post/214515

Iqorek
25.09.2017 14:25+1Вау, автор, вы молодец, аплодирую стоя. Такой проект нетривиален и далеко не каждый программист способен довести его до конца.
Два вопроса,
1. Есть где то место, где я бы смог по быстрому подменить ваш алгоритм на свой и проверить кто быстрей, ну так для спортивного интереса.
2. Планируется ли продолжение в виде продукта? Частенько от карт нужно быстро посмотреть маршрут между двумя точками и больше ничего, навигаторы и карты не то, что этого не позволяют, но слишком много действий, а нужно быстро.anvaka Автор
25.09.2017 17:45+1Спасибо! Развитие в виде продукта я не планировал. А вот чтобы быстро подменить алгоритм нужно добавить его ключ/имя сюда, чтобы показывался в выпадающем списке. Потом для этого ключа нужно создать поисковик здесь — у поисковика только один метод
find(fromNodeId, toNodeId), вернуть он должен массив узлов графа.
Можете также прислать ссылку на демо вашего алгоритма, если он публичный — я помогу потестировать.
Iqorek
26.09.2017 21:55Я пытался понять ваш, он идет навстречу, в первую очередь двигаясь в сторону точек, расстояние которых ближе всего к точке назначения?
У меня алгоритм вероятно чем то похож (но они все похожи) и так есть 2 стадии:
1. Максимально быстро найти первый путь до конечной точки
2. Проверить остальные варианты, до тех пор пока их расстояние меньше найденного.
В первой стадии, как быстро найти путь до конечной точки? (КО) Двигаться в ее направлении, то есть я сортировал все соседние точки по углу который между текущей точкой, конечной и соседней и первую очередь передвигался в сторону наименьшего угла между ними. Что бы не получилось вечного цикла, пройденные точки помечаются и повторном посещении, маршрут бракуется, алгоритм возвращается на шаг назад и проверяет остальные направления. Пока либо не переберет все точки до которых сможет добраться, либо не достигнет конечной точки.
Теперь если у нас есть первый маршрут, то маловероятно, что он самый оптимальный, поэтому алгоритм возвращается на шаг назад и проверяет нет ли более короткой дороги из предыдущей точки, в дополнение к проверкам из первой стадии, он проверяет что текущий маршрут не длинней уже найденного. Если длинней, дальше проверять нет смысла, дорог с отрицательной длинной нет. Если находится более короткий маршрут, то он заменяет тот первый. Все останавливается когда больше нет маршрута, который короче найденного.
код тут но он ужасен, в свое оправдание могу сказать только, что это было 15 лет назад, я его случайно нашел на старом сд с бекапом, когда перебирал кладовку :)anvaka Автор
27.09.2017 21:53Спастбо за детальный ответ!
Да, у меня тоже алгоритмы приоретизируют направление, которое наиболее вероятно приведет к целе (функция-эвристика дает примерную оценку от точки А1 к цели, точки с наименьшей оценкой будут рассмотрены в первую очередь)
hombre
25.09.2017 19:41Как-то перелапачивал граф с 300К+ вершин(50М ребер) и искал оптимальные пути от каждой вершины к каждой, дейкстра как раз хорошо подходил для этой цели, но скорость дейкстры сильно (на порядок, другой) оказалась зависит от реализации — типа модели поиска минимального значения, модели представления графа и т.п. и так по мелочи (от 10% до 50%) от всяких оптимизаций типа оптимального frontiera и т.п. Поэтому когда вижу разницу на порядок (а не на 3 порядка :), вопросы о том все ли до того как добраться до оценки было «выжато» из Дейкстры, которая даст глобальный оптимум.
anvaka Автор
25.09.2017 19:56все ли до того как добраться до оценки было «выжато» из Дейкстры?
Я использовал тот же код что и для
А*— просто эвристику в ноль поставил.
типа модели поиска минимального значения
Можете рассказать подробнее что это означает, пожалуйста?
hombre
25.09.2017 20:38типа модели поиска минимального значения
Можете рассказать подробнее что это означает, пожалуйста?
если в терминах псевдокода
1 function Dijkstra(Graph, source):
2
3 create vertex set Q
4
5 for each vertex v in Graph: // Initialization
6 dist[v] < INFINITY // Unknown distance from source to v
7 prev[v] < UNDEFINED // Previous node in optimal path from source
8 add v to Q // All nodes initially in Q (unvisited nodes)
9
10 dist[source] < 0 // Distance from source to source
11
12 while Q is not empty:
13 u < vertex in Q with min dist[u] // Node with the least distance will be selected first
14 remove u from Q
15
16 for each neighbor v of u: // where v is still in Q.
17 alt < dist[u] + length(u, v)
18 if alt < dist[v]: // A shorter path to v has been found
19 dist[v] < alt
20 prev[v] < u
21
22 return dist[], prev[]
то, например, реализация 13-я строчки
u < vertex in Q with min dist[u]
для больших графов может очень сильно влиять на производительность всего алгоритма. В моем случае, использование в этом месте структуры данных «минимальной кучи» (min-heap) с алгоритмичской сложностью операции поиска минимального значения на уровне O(1), дал значительный прирост (на порядок) — даже не смотря на доп. издержки поддержания этой «кучи» при добавлении элементов.anvaka Автор
25.09.2017 20:55Спасибо. Да, я тоже использую кучу для всех реализаций (включая Дейкстру)
justhabrauser
26.09.2017 00:36Откажитесь от работы с объектами (и ООП вообще) — будет Вам счастье.
Если речь идет о «турбо»
(ну… «как бы» турбо. Еще можно намутить свой распределитель памяти и вообще перейти на ассемблер — но это вопрос экономической целесообразности)DaylightIsBurning
26.09.2017 01:30А зачем отказываться от ООП? Оптимальному размещению в памяти ООП не препятствует, да и свой аллокатор запилить не мешает.

sshikov
25.09.2017 21:59Я правильно понимаю, что вы задачу все-таки слегка упростили? Ну т.е., из overpass достается граф дорог, но потом вы удаляете тэги, показывающие, что это вот — велодорога или хайвей? И маршрут строится без учета того, какой у нас транспорт, и какой транспорт может двигаться по каждому из участка дороги? Или я что-то пропустил?
anvaka Автор
25.09.2017 23:10Примерно так. Вот запрос который я выполняю для получения дорог.
Маршрут действительно строится без весов.
encyclopedist
26.09.2017 02:02А вы для какого ID его делаете для Нью-Йорка? Я попробовал для id 3600175905 ("New York City") и получил только 50000 ребер и 195000 вершин.
anvaka Автор
26.09.2017 02:04+1Граф Нью-Йорка не из OSM. Отсюда: www.dis.uniroma1.it/challenge9/download.shtml

slonopotamus
25.09.2017 23:46-4200мс — это чудовищно, отвратительно медленно. Я верю что это число можно уменьшить по меньшей мере раз в десять просто переписав код один в один на любом из более нормальных языков программирования. А немножко пооптимизировав и во все пятьдесят.
anvaka Автор
25.09.2017 23:49+2С удовольствием прочту о вашем методе, который дает 50-разовый прирост производительности в браузере!
igormwd
26.09.2017 20:21Мне кажется тут он не совсем правильный путь нашел

anvaka Автор
26.09.2017 20:22+1Мне кажется, я видел эту петлю на гуглокартах — есть подозрение что это единственный путь к точке B

proninyaroslav
26.09.2017 20:23Было бы интересно увидеть поиск кратчайшего пути с учётом динамически изменяющихся пробок. Возможно ли реализовать подобное в данном алгоритме?

tamtakoe
27.09.2017 14:49+1Библиотека замечательная! Демка, вообще, выше всяких похвал! Надеюсь, когда-нибудь найдет применение в жизни.
Если вы любите такие задачи, то могу подкинуть насущную проблему, которую в мире js никто ещё не решил. Это реализация бесконечного скрола. Не для конкретного случая, а универсальная. Т.е. динамически подгружаеммый с сервера массив данных, которые рендерятся в дом-элементы произвольной высоты, которая к тому же может динамически менятся. Это могут быть как строки, так и плитка и т.п. Состав элементов так же может меняться (какие-то удаляться, какие-то добавляться). Ну и методы для скролла к произвольному элементу, к началу, к концу. Разумеется, всё это должно шустро работать в современных браузерах и не прыгать по странице. Сделаете — будет вам вечный респект от js мираanvaka Автор
27.09.2017 21:55Спасибо :)
Проблема с бесконечным скролом интересная, конечно! Увы, у меня сейчас другие приоритеты.
Если вы на реакте пишете, то вот эта библиотека выглядит очень многообещающе: github.com/bvaughn/react-virtualized
vics001
27.09.2017 21:14+1Отличное демо!
Увидел у вас на github страничке, что вы пытались сделать двунаправленный A*, но он был не оптимальный. У меня была похожая проблема, главное правильно выбирать, когда встречаются дороги, т.е. важен порядок какую ветку сейчас надо рассматривать от начала или от конца. Так же очень важно не завершать работу алгоритма, когда найдена точка соприкосновения, а необходимо выполнения условия, что найденный маршрут короче суммы стоимости оставшихся дорог из очередей.
К сожалению, не могу поверить, что NBA* будет быстрее, чем двунаправленный A*, потому что «эвристика» (неправильно называть эвристика так как если она меньше 1, то она всегда находит оптимальный маршрут) направляет построение маршрута.
Еще маленькое замечание, оптимизации самого движка построения маршрута вещь необходимая для конечного продука, но сам алгоритм желательно проверять масштабированием. Грубо говоря, насколько становится медленным если перейти от 10К edge к 100К. Или сколько занимает времени построить 10 км маршрут, 100 км, 1000 км.
anvaka Автор
27.09.2017 22:04Спасибо за дельный совет!
NBA*и есть двунаправленныйА*, его особенность в том, что он делает после того как оба поиска встретились, и в том, как он учитывает эвристики с противоположной стороны поиска. Когда поиск вперед раздумывает зайти ли в узел или нет, он так же смотрит на эвристику обратного поиска — здесьf2инициализровано обратным поиском. Доказательство корректности можно найти здесь: https://repub.eur.nl/pub/16100/ei2009-10.pdfvics001
27.09.2017 23:26Хм… очень похоже на то, что я описал, но алгоритм все-таки другой, хотя результат может быть такой же. Крайне приблизительно алгоритм такой
R, S — priority queues forward & backward.
f — calculated route time function
h — heuristic function — h(x, y) = min_time(x, y) * h // обязательно, что h <= 1 и маршрут между x, y всегда меньше, чем min_time(x,y), на практике min_time = distance / max_possible_speed
R = priorityQueue | f(x) + h(x, end) Q = priorityQueue | h(start, x) + f(x) queue = R while(!queue.isEmpty()) { Edge start = queue.poll() for(Edge e : exploreAllOutgoingEdges(start)) { Edge s = visitedOppositeEdges.get(e) if(s != null){ queue.push(makeCompleteRoute(s, e)); } else { e.setParent(start); queue.push(e); } } if(peak( R ) < peak( S )) { queue = R } else { queue = S } }
mr-boyfox
27.09.2017 21:50Отличная статья, по поводу алгоритма «квад дерево» место этого можно использовать алгоритм: «R_tree», пример реализация на java github.com/davidmoten/rtree чтобы проиндексировать точки. Да стратегия вставки в R -tree с {\ displaystyle {\ mathcal {O}} (M \ log M)} {\ mathcal {O}} (M \ log M) более сложной, чем линейная стратегия разделения ( {\ displaystyle {\ mathcal {O}} (M)} {\ mathcal {O}} (M)) R-дерева, но менее сложной, чем квадратичная стратегия разделения ( {\ displaystyle {\ mathcal {O}} (M ^ {2})} {\ mathcal {O}} (M ^ {2})) для размера страницы {\ displaystyle M} Mобъектов и мало влияет на общую сложность.
dom1n1k
Когда я вижу красивое и ясное демо, для меня это уже процентов 80 гарантии, что продукт заслуживает внимания.
Alex_1985
Согласен полностью. Автор — ты молодец! Твою библиотеку прикрутить бы к поиску маршрута в навигаторах, которые работают с сенсорным экраном — и вот это было-бы реально — полезно! А то вечно там поиск маршрута — не ахти какой, в независимости от модели навигатора… (сугубо моё мнение).
Alex_1985
И ещё добавлю, что твою библиотеку бы — да в инструмент -Яндекс.Карт / «Линейка» — тогда цены бы не было :)