

Какие Go бенчмарки показывают лучшие результаты, будучи собранными gccgo и почему?
Ответы на эти вопросы под катом.
Введение
На данный момент существуют две наиболее зрелые реализации языка программирования Go:
- gc (5g/6g/8g/etc.) — первая, "стандартная" реализация.
- gccgo — frontend компилятора GCC для Go.
Постановка задачи: найти такие бенчмарки из стандартного дистрибутива Go, которые выполняются за меньшее количество времени при компиляции gccgo. Для каждого значительного отклонения найти причины наблюдаемого эффекта.
Предыдущее подобное сравнение выполнялось в 2013 году:
benchmarking Go 1.2rc5 vs gccgo.
Недостающие технические детали, которые могут быть важны для воспроизведения и валидации результатов можно найти в github репозитории.
Что и как измерялось
Поскольку gccgo отстаёт по релизам от gc, использовалась версия Go 1.8.1 (GCC 7.2).
Запуску и измерению подлежали многие Benchmark* функции из пакетов стандартной библиотеки, а также все тесты из $GOROOT/test/bench/go1.
Полный список перечислен в packages.txt.
Для GCC использовались флаги "-O3 -march=native".
Результаты доступны для Intel Core и Intel Xeon.
На обеих машинах были доступны AVX2 и FMA.
Более подробную информацию о тестовых машинах можно найти в секции /stats.
Для выявления статистически значимых отклонений использовался benchstat.
Дополнительной проверкой было сравнение с Go tip версией (1.10).
Часть расхождений в Go 1.10 исправлена, но некоторые преимущества gccgo могут сохраниться навсегда из-за особого подхода gc, в котором время компиляции является важным показателем.
Общая картина: все результаты в одной диаграмме
Перед построением общей диаграммы выполнены следующие действия:
- Удалены аномалии типа нулевого времени выполнения (объяснения ниже).
- Удалены бенчмарки с одинаковым временем выполнения (
gccgo.time=gc.time). - Разница времени выполнения сглажена с помощью логарифмирования.
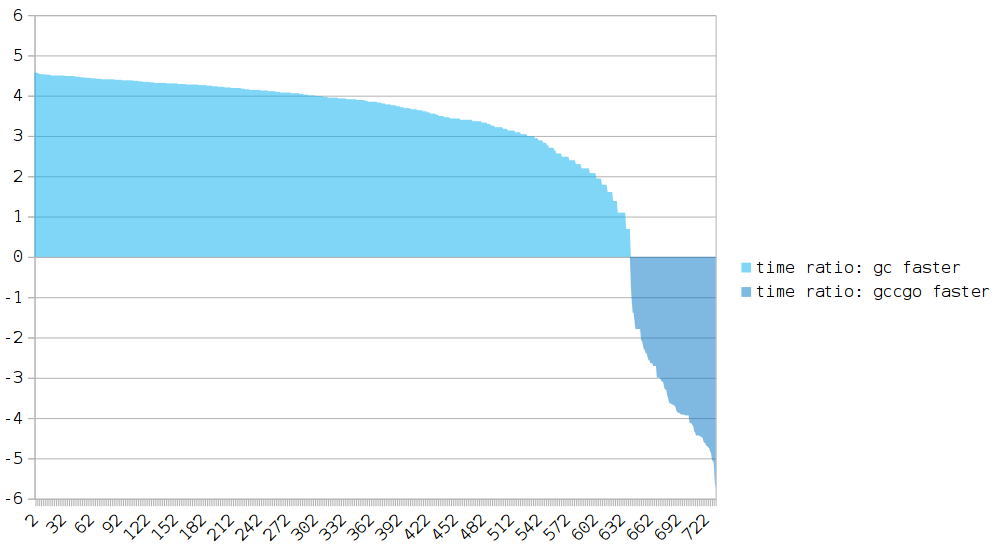
Ось X: бенчмарки.
Ось Y: отношение времени выполнения gccgo к gc.
Если значение Y выше 0 — программа, скомпилированная gccgo, выполняется медленнее.
Большинство тестов имеют значительно лучшие результаты на gc.
Основное преимущество перед gccgo — escape analysis.
Имеются также отклонения в пользу gccgo (118/808 тестов).
Сужение области поиска
Какое-то небольшое расхождение производительности в любом случае неизбежно, поэтому вместо исследования всех 118 случаев проведём фильтрацию:
- Сначала удалим все результаты, в которых дельта меньше ~10%.
- Для оставшихся тестов проведём сравнение с Go 1.10.
Убираем те, что в Go 1.10 догнали (или перегнали) gccgo. - Всё, что осталось, рассматриваем более подробно.
Первые два пункта привели к промежуточным таблицам, которые можно посмотреть
в секции /human-readable.
=> ~62 значимых тестов.
=> из них ~39 актуальных для 1.10.
=> из них ~26 выбраны для разбора.Были исследованы все 118 тестов.
Некоторые из них выглядели недостаточно стабильными.
Для части результатов я не нашёл однозначного объяснения.
Из-за этого для финального формата было решено произвести описанную выше фильтрацию.
В репозитории, на который многократно приводилась ссылка, можно найти "сырые" данные,
по которым любой может произвести анализ так, как он считает более правильным.
Самые интересные результаты
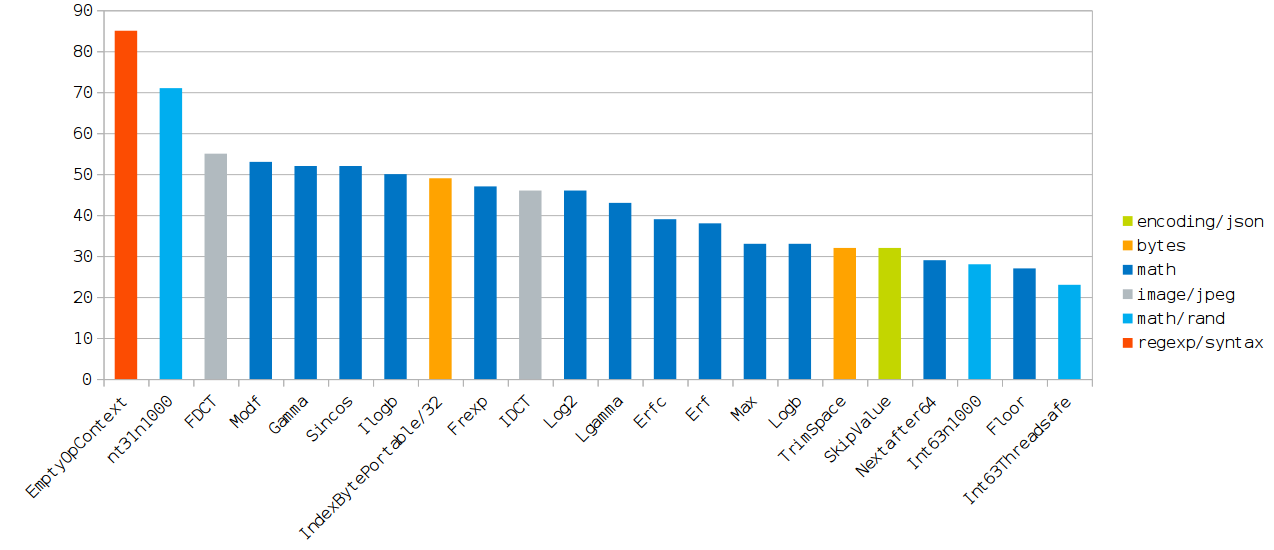
(Диаграмма кликабельна.)
В таблице ниже каждому из тестов присвоена одна или несколько наиболее значимых причин, которые приводят к наблюдаемому выше ускорению по сравнению с gc.
Если их устранить, то производительность становится практически идентичной.
Почти все причины оформлены в виде флагов оптимизации GCC.
Найдены эти флаги путём подбора (включение/отключение) минимального набора флагов оптимизации, которые приводили бы к уменьшению разрыва в производительности.
Описание флагов оптимизации GCC можно посмотреть здесь.
| Название | Наиболее значимые причины |
|---|---|
| EmptyOpContext | Неиспользуемый результат вызова [1] |
| Int31n1000 | Неиспользуемый результат вызова; -finline-functions |
| FDCT | -ftree-loop-vectorize |
| Modf | -mavx |
| Gamma | -mfma |
| Sincos | -mfma |
| Ilogb | -mfma |
| IndexBytePortable/32 | Замедление на коротких циклах [2] |
| Frexp | Неиспользуемый результат вызова; -finline-functions |
| IDCT | -ftree-loop-vectorize |
| Log2 | -mfma (зависит от Frexp) |
| Lgamma | -mfma |
| Erfc | -mfma |
| Erf | -mfma |
| Max | -mfma; -finline-functions |
| Logb | -mavx |
| TrimSpace | -finline-functions |
| SkipValue | -msse4.1 |
| Nextafter64 | -finline-functions; -ftree-loop-vectorize |
| Int63n1000 | -finline-functions |
| Floor | -mavx (vroundsd) |
| Int63Threadsafe | -finline-functions |
[1] Бенчмарк тестирует производительность функции, игнорируя
возвращаемый результат. Иногда это приводит к удалению вызова оптимизатором.
[2] Именно для теста с n=32 наблюдается подобное замедление.
Воспроизвести этот результат в свободном контексте не удалось.
Остальная часть статьи разбирает наиболее значительные оптимизации, которые привели к наблюдаемым результатам. Также затрагивается тема не совсем корректных бенчмарков, которые совсем не работают для gccgo, но пока работают для gc.
gccgo = better inlining
По умолчанию Go 1.10 умеет встраивать только "листовые" функции. Листовыми называют функции, которые не содержат вызовов других функций. Исключениями являются другие листовые функции, если "бюджет встраивания" содержащей функции не превышается встраиванием её тела.
Упрощённо, вот ограничения для встраиваемых функций:
- Суммарно (после всех встраиваний) не превышает некоторый порог сложности.
- Не содержит запрещённые элементы. golang#14768 — for-loops cannot be inlined.
- Является листовой. golang#19348 — enable mid-stack inlining.
Вычисление "цены функции" происходит до оптимизаций.
Это зачастую приводит к тому, что если для вас важно, встраивается функция или нет, придётся менять структуру кода на семантически эквивалентную, но имеющую более низкую цену без учёта оптимизаций.
Более того, у текущей модели есть недостаток: каскадные встраиваемые вызовы увеличивают суммарную цену функции. Это делает встраиваемые функции-обёртки не такими уж бесплатными с точки зрения inliner'а.
Вы можете проверить, встраивается функция или нет, используя специальные флаги компилятора. О влиянии gcflags="-l=4" читайте ближе к заключению.
gccgo = better constant folding
Как часто вы встречали подобные бенчмарки на Go?
func foo(i int) int { /* Реализация. Допустим, что эта функция "чистая". */ }
func BenchmarkFoo(b *testing.B) {
for i := 0; i < b.N; i++ {
foo(50) // Игнорируется возвращаемое значение вызова foo
}
}Обратите внимание на комментарий к строке с вызовом foo(50).
Оптимизатор может удалить как сам вызов, так и весь цикл внутри BenchmarkFoo.
Для gccgo это верный способ получить бенчмарки, которые выполняются 0 наносекунд:
// Названия вида YCbCrToRGB/(0|128|255) свёрнуты как YCbCrToRGB/*.
// gc.time gccgo.time delta
YCbCrToRGB/* 12.1ns ± 0% 0.0ns -100.00% (p=0.008 n=5+5)
RGBToYCbCr/* 12.8ns ± 0% 0.0ns -100.00% (p=0.008 n=5+5)
YCbCrToRGBA/* 13.8ns ± 0% 0.7ns ± 0% -94.78% (p=0.000 n=5+4)
NYCbCrAToRGBA/* 18.5ns ± 0% 1.0ns ± 6% -94.72% (p=0.008 n=5+5)Ниже показана довольно распространённая идиома:
var sink int
func BenchmarkBar(b *testing.B) {
for i := 0; i < b.N; i++ {
sink = bar(50)
}
}У неё две проблемы:
- Константный аргумент функции.
- Предположение о том, что присваивание глобальной (неэкспортируемой) переменной магически отменяет нежелательные оптимизации.
Обе эти проблемы встречаются в том числе и в бенчмарках стандартной библиотеки Go.
gccgo может встраивать значения глобальных переменных, которые по его мнению в программе не изменяются. В gc (по крайней мере на данный момент) этой оптимизации подлежат только константы и локальные данные.
Когда значение sink нигде не используется, будет не важно, изменяется ли эта переменная или нет. Подобно неиспользуемым неэкспортируемым функциям, gccgo удаляет переменные, которые никто не "читает".
Если вызов функции будет встроен (а в gccgo такое происходит чаще), то появляется риск полного вычисления тела цикла (потенциально вместе с самим циклом) на этапе компиляции.
В реальных приложениях не так часто можно "свернуть" целые циклы на этапе компиляции, однако некоторые бенчмарки Go попадают под эту оптимизацию.
В них и получаем магическое ускорение на 100%.
gccgo = better machine-dependent optimizations
Компилятор gc не генерирует инструкции из расширений после SSE2.
Это делает бинарники под x64 более переносимыми, но потенциально менее оптимальными.
Благодаря таким флагам, как -march=native, gccgo может генерировать
более эффективный код под конкретную машину, на которой планируется запускать приложение.
Мы также можем отнести векторизацию к машинно-зависимым оптимизациям, так как её эффективность довольно ограничена без доступа к AVX расширениям.
В текущей версии gc векторизации нет как таковой, если только не считать объединения нескольких перемещений в одно (до 16 байт, средствами SSE).
Из-за того, что в Go нет традиционных intrinsic функций, приходится писать ассемблерные реализации для достижения максимального ускорения.
Ассемблер Go 1.10 поддерживает большинство инструкций, доступных на современных x86_64.
Есть шанс, что в Go 1.11 можно будет использовать AVX512 (golang#22779 — AVX512 design).
| Ассемблерные функции не встраиваются, что иногда ставит крест на производительности, если только вы не реализуете весь алгоритм на языке ассемблера. |
gccgo = better calling convention
И для GOARCH=386, и для GOARCH=amd64 gc использует стек для передачи аргументов и возврата результатов функций. В 64-битном режиме доступно больше регистров, поэтому использовать стек для этих целей не оптимально.
Некоторое время ведётся обсуждение register-based calling convention.
Судить о потенциальном выигрыше производительности на данном этапе непросто, так как сейчас оптимизатор не выполняет некоторые преобразования, которые выгодны только для reg->reg перемещений. Сейчас же намного более характерны перемещения вида mem->reg->mem.
5-10%, о которых идёт речь в обсуждении выше, вполне могут превратиться в 15-30% для отдельных функций.
| Один из главных недостатков нового calling convention — инвалидация всего существующего ассемблерного кода, которого даже внутри Go предостаточно. |
Включаем mid-stack inlining
Оценим влияние -gcflags="-l=4" на те бенчмарки, где gccgo показал лучшие результаты за счёт использования больших возможностей для встраивания функций.
Ratio рассчитан как gccgo.time/gc.time.
| Название | Ratio до | Ratio после |
|---|---|---|
| math/rand/Int31n1000 | 0.77 | 1.00 (+0.23) |
| math/rand/Int63n1000 | 0.82 | 0.93 (+0.11) |
| math/rand/Int63Threadsafe | 0.80 | 1.00 (+0.20) |
| math/Frexp | 0.84 | 0.84 (=) |
| math/Max | 0.73 | 0.73 (=) |
| math/Nextafter64 | 0.61 | 0.81 (+0.20) |
| bytes/TrimSpace | 0.70 | 0.80 (+0.10) |
(Примечание: эти тесты запускались с иной конфигурацией, как отдельный эксперимент.)
Мнение Russ Cox по поводу использования -l=4 в Go 1.9/1.10:
-l=4 is explicitly untested and unsupported for production use.
If you do that and you get programs that break, you get to keep both pieces.
Ссылка на сообщение
Заключение
Производить правильные измерения производительности для gccgo сложнее, чем для gc.
По ощущениям, вы скорее реализуете бенчмарки для C++, нежели для Go (похожие "проблемы").
Для некоторых специфичных задач gccgo может дать некоторый прирост производительности.
Например, математические вычисления при включении правильных флагов оптимизации GCC получают измеримое ускорение, однако под удар попадут остальные части приложения.
Учитывая особенности наиболее типичных программ на Go, скорее всего замедлится более важная часть приложения (исключением могут быть простые утилиты командной строки).
Как и ко всем измерениям производительности, оценивать данное исследование нужно в контексте конкретных версий, которые были использованы при сравнении.
Значительным шагом вперёд для gccgo был бы качественный escape analysis.
Для gc из грядущих революций можно назвать упомянутую выше новую конвенцию вызовов и полноценное встраивание функций.
Комментарии (9)

Ne01eX
20.02.2018 19:22-1Я бы предпочёл, если бы больше людей на перешли с Go на Eiffel. В рамках проекта GNU это Liberty Eiffel, но я не уверен что это самый лучший из существующих свободных компиляторов. А достоинств у языка много, в том числе Си на выдаче в качестве промежуточного результата. Который в свою очередь можно оттранслировать в ассемблер и скормить gas. В итоге и программисты и майнтейнеры довольны. Ну и конечный юзер само собой.
Впрочем к статье это слабо относится, хотя читать было интересно, ага.blind_oracle
21.02.2018 10:47Если это поделие не стало популярным за 30 лет, то скорее всего уже никогда не станет. В языке главное даже не он сам, а комьюнити. Закопать.

quasilyte Автор
21.02.2018 11:13А зачем именно закапывать?
По мне так наоборот, пусть живёт и процветает.blind_oracle
21.02.2018 11:25Ну, закапывать это образно. В том плане, что юзать его незачем. Может и есть какие-то специфические применения для этого языка, но мне кажется их единицы и даже тогда стоит два раза подумать стоит ли в это вляпываться.

AterCattus
21.02.2018 11:05С похожиими доводами можно, к примеру, агитировать всех перейти с Java на Ada. Или с C++ на ObjC.
Так себе доводы.
Ne01eX
22.02.2018 12:52Довод был исключительно примера для и в контексте удобства для майнтейнера. И я не являюсь ни Eiffel-евангелистом, ни противником Go. По роду своей деятельности мне приходится сопровождать и поддерживать код, написанный на разных языках.
И раз уж была упомянута джава, то я считаю, что с неё можно и нужно перейти на любой другой язык. Но это, исключительно, — имхо.
Вы вольны писать на том языке, на котором вам удобнее.
Но замечу, что при прочих равных тот же «hello world» после компиляции на Си, Си++ и Го занимают: 10784, 11408 и 33720 байт.
Время выполненияbash-4.3# time ./hello
Hello world!
real 0m0.001s
user 0m0.001s
sys 0m0.000s
bash-4.3#
bash-4.3# time ./hello
Hello World!
real 0m0.003s
user 0m0.001s
sys 0m0.001s
bash-4.3#
bash-4.3# time ./hello
hello world
real 0m0.282s
user 0m0.030s
sys 0m0.007s
bash-4.3#
Ne01eX
Для GCC — Go субпроект новый и по большей части вторичный. Со временем конечно разработчики допилят шаблоны оптимизации, как допилили для других языков, ну а пока мы имеем то что имеем. :-)
crmMaster
Чем больше в gcc языков, тем короче наши скрипты для сборок :)