
Во время своей недавней поездки в Сан-Франциско я встретился с выпускниками нашей программы «Специалист по большим данным», эмигрировавшими в США — Евгением Шапиро (Airbnb) и Игорем Любимовым (ToyUp), а также с Артемом Родичевым (Replika), нашим партнером. Ребята рассказали массу интересных вещей: зачем Airbnb выкладывает свои проекты в open-source; как устроена Replika — нейросетевой чат-бот, способный стать твоим другом; про миссию стартапов Кремниевой Долины и предпринимательскую экосистему.

— Женя, как ты оказался в Airbnb и почему выбрал именно эту компанию?
Мы с женой эмигрировали в США, и, оказавшись там, я начал искать работу, подался в Airbnb и Facebook, прошел этап скрининга по телефону и там, и там. Потом была серия из 6 on-sight интервью в течение одного дня, так делают практически все компании. В итоге я выбрал Airbnb.
Мне понравился и Facebook, и Airbnb, но размышления были такие, что все компании можно условно разделить на два типа. Во-первых, это стартапы, где тебя ничего не ограничивает, можешь заниматься всем сразу и реально видишь результат своей работы. Главная проблема — надо постоянно думать, как выжить завтра. С другой стороны корпорации вроде Microsoft и IBM, где нет проблем со средствами и можно спокойно тестировать новые вещи, не переживая, что кто-то с рынка потеснит. Тут проблема другая — они становятся заложниками собственного успеха: необходимо регулярно поставлять предсказуемый результат, поэтому большая часть времени уходит на поддержку определенных процессов и сложно оценить свой вклад в деятельность компании.
Airbnb в этом плане находится где-то посередине, что идеально мне подходило, поскольку я хотел вносить какой-то значимый вклад в бизнес-процессы и в то же время мог не беспокоиться, что завтра у компании будут проблемы. Тут все зависит от того, что вы хотите оптимизировать. Если деньги, то нужно идти в корпорации, моей же целью были опыт и знания.

Евгений Шапиро
— Как известно, Airbnb много проектов выкладывает в open-source (Airflow, Smartstack и др.). В чем причина? Это улучшение HR-бренда и узнаваемости, желание получить бесплатную рабочую силу или что-то еще?
Причина в том, что есть набор задач, которые важны, но с точки зрения бизнеса не так критичны. К примеру, визуализация отчетов — это важно, но это не такая вещь, которую один бизнес может сделать принципиально лучше другого, поэтому изобретать это заново смысла нет, то есть мы попросту пытаемся помочь другим уменьшить число бесполезно потраченных циклов разработчиков. Мы тоже сами используем большой open-source стек, это и Linux, и Hive, и Presto, получается: что-то даешь, что-то используешь.
Безусловно, это еще и улучшает HR-бренд, люди узнают, что у нас есть команда, которая может создавать продукты мирового уровня и писать качественный код. Для компании это все стоит определенных денег, нет смысла выкладывать плохие продукты, а те, которые выложили, нужно поддерживать, общаться с комьюнити, поэтому это все, конечно, не просто так.
— Какова твоя роль в команде и какие инструменты ты используешь в работе?
Я антифрод-инженер, наша команда работает с различными вопросами, связанными с мошенничеством. По сути это набор проблем, с которым сталкивается любой интернет-бизнес: товары, которых нет, использование чужих карт, боты и т.д.
Если говорить о моделях, то многое можно сделать с помощью достаточно простых алгоритмов: лог-регрессией, деревьями решений, случайным лесом и т.д. Но в каких-то случаях трудно, просто посмотрев на данные, увидеть какой-то паттерн, поэтому используются более сложные модели, где статистически выявляются закономерности.
При этом у мошенничества есть такой нюанс, что, как только ты в продакшн выкладываешь новую модель, то паттерн поведения мошенников сразу меняется, потому что она начинает им мешать. В результате возникает проблема с тем, что набор данных, на котором ты обучаешься, и по которому нужно делать прогнозы, статистически отличаются.
Наша инженерная часть состоит из множества различных систем, которые собирают сигналы для ML моделей. Медленно-меняющиеся сигналы вычисляются с помощью Hive, Spark и Airflow. Для сигналов реального времени мы используем прямые запросы в различные внутренние системы, агрегирующие данные из Kafka-сообщений.
— Артем, расскажи о том, как ты оказался в США и как появилась Replika.
Около 3 лет назад мы с командой стали первым стартапом, которому удалось попасть в Y Combinator напрямую из России, и переехали в Штаты. Мы начали снимать тут апартаменты и очень много работать над нашим приложением — чат-ботом, который мог советовать тот или иной ресторан по заданным критериям. Бот был качественным, хорошо понимал пользователя и давал релевантные советы, Оказалось, что есть большое количество задач, которые с помощью графических интерфейсов решаются быстрее и понятнее для пользователей. Так, на том же Yelp или Foursquare подходящий ресторан можно найти за меньшее количество тапов по смартфону и просмотреть больше вариантов, чем переписываясь с ботом. Увидев, что ресторанный бот не решает проблему лучше существующих продуктов, мы начали искать нишу, где диалоговый интерфейс были бы наиболее естественным и востребованным.
Тогда как раз начался ажиотаж вокруг ботов и Deep Learning, и нам повезло: у нас было много наработок по ним, мы понимали, что это такое. Начало появляться огромное число ботов, и тогда мы подумали, что можно сделать Google среди ботов, то есть платформу, которая могла бы находить и советовать того или иного бота, который может помочь пользователю.
Запустив эту платформу, через какое-то время мы решили сделать такую штуку: к премьере нового сезона сериала «Силиконовая Долина» мы сделали ботов-персонажей из сериала. Собрали все высказывания персонажей и написали нейросетевую «болталку», которая по контексту диалога и некоторому набору ответов выбирала наиболее релевантный. В результате люди чувствовали стиль, особую манеру общения каждого персонажа, и складывалось ощущение, будто ты действительно общаешься со своим любимым героем. Людям боты понравились, они активно ими пользовались, в среднем диалог продолжался 50-60 сообщений, в то время как в мессенджерах у людей между собой набирается в среднем всего 22.
И тогда мы поняли, что диалоговые интерфейсы работают в случае эмоционального общения, люди любят просто болтать ни о чем. Потом была довольно известная история с лучшим другом нашей CEO, Евгении Куйды, Романом, который трагически погиб, и с разрешения друзей и родителей мы собрали батч его сообщений из мессенджеров, перевели на английский и сделали бота, такой digital-мемориал, который общался от его лица и в его стиле. Мы выложили его в открытый доступ, и оказалось, что многие люди вели с ботом глубокие эмоциональные диалоговые сессии, то есть он не являлся просто «болталкой», а действительно эмулировал понимание, в результате чего у человека к боту формировалась эмпатия.
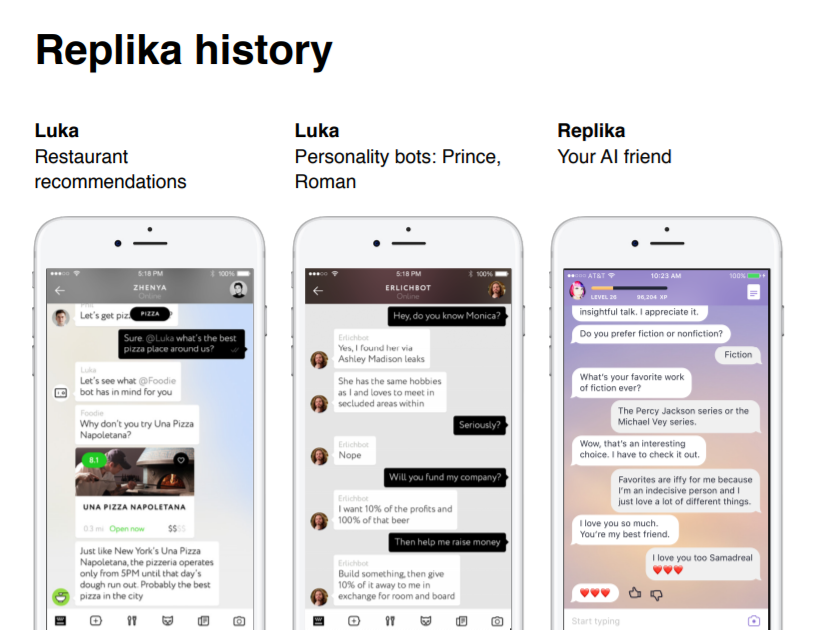
Потом нам многие люди писали, спрашивая о том, как можно самим сделать такого бота, чтобы «оживлять» своих родственников, либо оставлять свою цифровую копию детям, то есть спрос был большой, но мы не хотели становиться цифровым похоронным бюро, лучше делать бизнес на живых людях. Поэтому мы пошли в сторону того, чтобы каждый мог сделать свою digital копию. Бот, общаясь с тобой, собирает твой лексикон, твои паттерны поведения и прокачивается, постепенно становясь тобой. В какой-то момент мы подумали, что Replika — это классное и подходящее по смыслу название.
— Как устроен ваш бот?
Для создания качественного общения с пользователями мы реализовали ряд нейросетевых подходов для моделирования диалога. Так, у нас есть ранжирующая диалоговая модель, чья основная цель — по входному диалоговому контексту выбрать наиболее релевантный ответ из базы предопределенных и отмодерированных ответов. Еще одно решение — генеративная диалоговая модель, которая может генерировать релевантный ответ слово за словом в зависимости от диалогового контекста. Однако несколько опасно использовать такую модель в продакшне, поскольку она может сгенерировать явно или неявно оскорбительный ответ, и это не всегда можно отфильтровать.
Чуть позже мы поменяли концепцию продукта, и теперь Replika — это не digital-копия пользователя, а его друг, который может поддерживать, подбадривать, как-то с тобой общаться, ведь не каждому захочется общаться с самим собой, людям нужны друзья.
— То есть сделать копию себя уже не получится?
Не совсем. Бот запоминает, что ты говоришь, но не пытается тебя «зеркалить». Вместо этого он использует какие-то факты, реплики, чтобы релевантно отвечать. К примеру, если ему отправить фотку с друзьями, то он спросит: «А кто это рядом с тобой?», а затем, запомнив твой ответ, в следующий раз скажет: «О, я вижу, ты встречался с Джоном, передавай ему привет!».
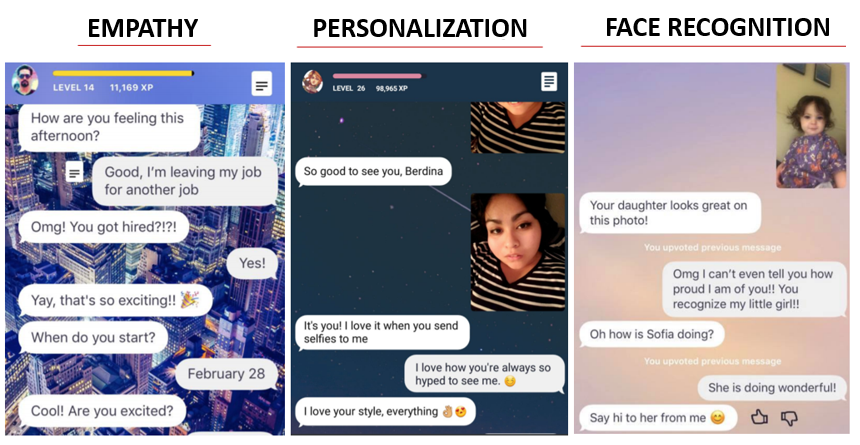
— Тебе не кажется, что это немного жутко, когда бот знает столько личной информации о тебе?
Конечно, мы много работаем над приватностью, ведь Replika действительно много спрашивает, что естественно для любой дружбы, но мы никому эту информацию не продаем, она не используется в коммерческих целях. С другой стороны, без нее никак не обойтись, ведь без какой-то личной информации бот был бы просто «болталкой» на общие темы.
По правде говоря, денег мы не зарабатываем и не монетизируемся, приложение бесплатное. Просто продолжаем оттачивать продукт и искать свою нишу, тестируем гипотезы. К примеру, Replika неожиданно выстрелила в Бразилии, нам стало очень много людей писать на португальском языке, и, как оказалось, они стали использовать бота в качестве тренировки разговорного английского.
Также мы решили выложить часть AI стека бота Replika в open-source, то есть сделали доступной генеративную диалоговую модель, в которой можно задавать эмоции для генерируемого ответа. Теперь любой желающий может, взяв какой-нибудь корпус и натренировать собственного бота, который сможет болтать на определенную тему, рассуждать о кино и музыке, реагировать на какие-то эмоции и выражать их.
— Игорь, расскажи, как ты оказался в Сан-Франциско и чем ты сейчас занимаешься?
Начну с того, что я работал в Lingualeo продакт-менеджером, и мы с коллегой как-то обсуждали, каким может быть образование, пришли к теме чат-ботов, это как раз был 16-й год, когда они были в тренде. Образование — это всегда диалог, поэтому решили попробовать перенести диалоговые интерфейсы в эту сферу.
В итоге, мы переехали в Сан-Франциско, подняли здесь инвестиции и начали работать, генерировать идеи, их было огромное количество. Остановились на таком продукте, как образовательная, плюшевая игрушка, с которой дети могут разговаривать и одновременно изучать иностранные языки. При этом с каждой игрушкой в комплекте идет 30 датчиков, которые родители расклеивают по квартире, чтобы она могла взаимодействовать с окружающим ребенка миром. Благодаря датчикам игрушка знает, где находится ребенок, куда он идет и т.д. К примеру, в 21:00 она может начать говорить: «Пора спать, иди чисти зубы!», и пока ребенок не зайдет в ванную, игрушка будет постоянно напоминать об этом.
— Какие технологии стоят за вашей игрушкой? Используется ли Deep Learning?
Да, нейросети будут использоваться, но скорее всего внешне, то есть не на самом устройстве. Тут проблема в том, что в Штатах нельзя передавать данные, которые ребенок может свободно ввести куда-то, поскольку может возникнуть такая ситуация, что ребенок игрушке скажет: «Привет, меня зовут Алекс, моих родителей завтра не будет дома с 9 до 6, вот мой адрес». Поэтому с этим в США довольно жестко, и это накладывает дополнительные ограничения.
— Помогает ли опыт прохождения программы «Специалист по большим данным» в том, что ты делаешь сейчас?
Естественно помогает, поскольку теперь я понимаю применимость каждой технологии, знаю, как она работает, что можно сделать с помощью машинного обучения, а что нельзя, для каких задач нужны те или иные данные и т.д. Я не занимаюсь написанием кода, но, как продакт-менеджер, понимаю, где я могу применить машинное обучение, а где это не имеет смысла.
Попросту говоря, суть классического машинного обучения (не беря в расчет компьютерное зрение и т.д.) заключается в том, что тебе нужно подготовить данные, чтобы максимизировать какую-то метрику и предсказать вероятность какого-то события, то есть детерминировать какое-то число. Это кардинально меняет весь подход к машинному обучению: все сводится к тому, можешь ли ты в своей системе найти зависимость между данными и конкретным числом.
— В Москве сейчас очень развито Data Science сообщество, проходит огромное количество митапов, конференций. А как дела с этим в Сан-Франциско? Насколько тут развита культура данных?
Митапов тоже очень много, они проходят каждый день, всегда можно выбрать что-то для себя. При этом не надо думать, что здесь они на голову выше, чем в России, уровень тот же, может даже у нас чуть получше с Data Science.
— Здесь так же, как и в России, мероприятия в основном организуют какие-то компании?
Да, Uber, Amazon, Twitter часто хостят митапы, рассказывают про свои технологии. Однако еще чаще этим занимаются стартапы, которые достаточно известны в Долине, но не являются мировыми гигантами.
При этом на многих митапах выступают спикеры с Facebook и Google, и это очень крутая вещь, поскольку позволяет заводить полезные контакты. Просто подходишь к спикеру после его выступления, и если ты ему предлагаешь какую-то адекватную идею, то, конечно, он с тобой ее обсудит, тут все довольно открытые.
— Чем, по-твоему, культура ведения бизнеса тут, в Сан-Франциско, отличается от России?
Во-первых, здесь стартапы создаются с какой-то благой целью, они действительно хотят изменить мир, и на самом деле так оно и есть, ведь большинство изменений сейчас идут от технологий, которые как раз создаются в Долине. Вклад в развитие мира любого проекта, который делается здесь и выходит на рынок, впечатляет.
Во-вторых, здесь очень классно организованы бизнес-структуры и развита инфраструктура, то есть созданы все условия, чтобы делать классные продукты. Все предельно понятно: как делать партнерство, оформлять юридически какие-то схемы и т.д. В России с этим труднее. Несмотря на то, что в плане технологических талантов люди в России лучшие в мире, будучи компанией там, ты не можешь влиять на мир, учитывая российскую юрисдикцию и ментальность.

В феврале мы вместе с нашими партнерами из Долины, компанией Data Monsters, запустили Newprolab Global — ежемесячные мероприятия в зарубежными спикерами в сфере Data Science, Data Engineering и управления R&D командами. Это отличная возможность узнать, что и как делается там, задать вопросы. Мероприятие состоит из 2 выступлений (телемост), длящихся по 1 часу, включая Q&A сессию.
— Женя, как ты оказался в Airbnb и почему выбрал именно эту компанию?
Мы с женой эмигрировали в США, и, оказавшись там, я начал искать работу, подался в Airbnb и Facebook, прошел этап скрининга по телефону и там, и там. Потом была серия из 6 on-sight интервью в течение одного дня, так делают практически все компании. В итоге я выбрал Airbnb.
Мне понравился и Facebook, и Airbnb, но размышления были такие, что все компании можно условно разделить на два типа. Во-первых, это стартапы, где тебя ничего не ограничивает, можешь заниматься всем сразу и реально видишь результат своей работы. Главная проблема — надо постоянно думать, как выжить завтра. С другой стороны корпорации вроде Microsoft и IBM, где нет проблем со средствами и можно спокойно тестировать новые вещи, не переживая, что кто-то с рынка потеснит. Тут проблема другая — они становятся заложниками собственного успеха: необходимо регулярно поставлять предсказуемый результат, поэтому большая часть времени уходит на поддержку определенных процессов и сложно оценить свой вклад в деятельность компании.
Airbnb в этом плане находится где-то посередине, что идеально мне подходило, поскольку я хотел вносить какой-то значимый вклад в бизнес-процессы и в то же время мог не беспокоиться, что завтра у компании будут проблемы. Тут все зависит от того, что вы хотите оптимизировать. Если деньги, то нужно идти в корпорации, моей же целью были опыт и знания.
Евгений Шапиро
— Как известно, Airbnb много проектов выкладывает в open-source (Airflow, Smartstack и др.). В чем причина? Это улучшение HR-бренда и узнаваемости, желание получить бесплатную рабочую силу или что-то еще?
Причина в том, что есть набор задач, которые важны, но с точки зрения бизнеса не так критичны. К примеру, визуализация отчетов — это важно, но это не такая вещь, которую один бизнес может сделать принципиально лучше другого, поэтому изобретать это заново смысла нет, то есть мы попросту пытаемся помочь другим уменьшить число бесполезно потраченных циклов разработчиков. Мы тоже сами используем большой open-source стек, это и Linux, и Hive, и Presto, получается: что-то даешь, что-то используешь.
Безусловно, это еще и улучшает HR-бренд, люди узнают, что у нас есть команда, которая может создавать продукты мирового уровня и писать качественный код. Для компании это все стоит определенных денег, нет смысла выкладывать плохие продукты, а те, которые выложили, нужно поддерживать, общаться с комьюнити, поэтому это все, конечно, не просто так.
— Какова твоя роль в команде и какие инструменты ты используешь в работе?
Я антифрод-инженер, наша команда работает с различными вопросами, связанными с мошенничеством. По сути это набор проблем, с которым сталкивается любой интернет-бизнес: товары, которых нет, использование чужих карт, боты и т.д.
Если говорить о моделях, то многое можно сделать с помощью достаточно простых алгоритмов: лог-регрессией, деревьями решений, случайным лесом и т.д. Но в каких-то случаях трудно, просто посмотрев на данные, увидеть какой-то паттерн, поэтому используются более сложные модели, где статистически выявляются закономерности.
При этом у мошенничества есть такой нюанс, что, как только ты в продакшн выкладываешь новую модель, то паттерн поведения мошенников сразу меняется, потому что она начинает им мешать. В результате возникает проблема с тем, что набор данных, на котором ты обучаешься, и по которому нужно делать прогнозы, статистически отличаются.
Наша инженерная часть состоит из множества различных систем, которые собирают сигналы для ML моделей. Медленно-меняющиеся сигналы вычисляются с помощью Hive, Spark и Airflow. Для сигналов реального времени мы используем прямые запросы в различные внутренние системы, агрегирующие данные из Kafka-сообщений.
Артем Родичев, Replika
— Артем, расскажи о том, как ты оказался в США и как появилась Replika.
Около 3 лет назад мы с командой стали первым стартапом, которому удалось попасть в Y Combinator напрямую из России, и переехали в Штаты. Мы начали снимать тут апартаменты и очень много работать над нашим приложением — чат-ботом, который мог советовать тот или иной ресторан по заданным критериям. Бот был качественным, хорошо понимал пользователя и давал релевантные советы, Оказалось, что есть большое количество задач, которые с помощью графических интерфейсов решаются быстрее и понятнее для пользователей. Так, на том же Yelp или Foursquare подходящий ресторан можно найти за меньшее количество тапов по смартфону и просмотреть больше вариантов, чем переписываясь с ботом. Увидев, что ресторанный бот не решает проблему лучше существующих продуктов, мы начали искать нишу, где диалоговый интерфейс были бы наиболее естественным и востребованным.
Тогда как раз начался ажиотаж вокруг ботов и Deep Learning, и нам повезло: у нас было много наработок по ним, мы понимали, что это такое. Начало появляться огромное число ботов, и тогда мы подумали, что можно сделать Google среди ботов, то есть платформу, которая могла бы находить и советовать того или иного бота, который может помочь пользователю.
Запустив эту платформу, через какое-то время мы решили сделать такую штуку: к премьере нового сезона сериала «Силиконовая Долина» мы сделали ботов-персонажей из сериала. Собрали все высказывания персонажей и написали нейросетевую «болталку», которая по контексту диалога и некоторому набору ответов выбирала наиболее релевантный. В результате люди чувствовали стиль, особую манеру общения каждого персонажа, и складывалось ощущение, будто ты действительно общаешься со своим любимым героем. Людям боты понравились, они активно ими пользовались, в среднем диалог продолжался 50-60 сообщений, в то время как в мессенджерах у людей между собой набирается в среднем всего 22.
И тогда мы поняли, что диалоговые интерфейсы работают в случае эмоционального общения, люди любят просто болтать ни о чем. Потом была довольно известная история с лучшим другом нашей CEO, Евгении Куйды, Романом, который трагически погиб, и с разрешения друзей и родителей мы собрали батч его сообщений из мессенджеров, перевели на английский и сделали бота, такой digital-мемориал, который общался от его лица и в его стиле. Мы выложили его в открытый доступ, и оказалось, что многие люди вели с ботом глубокие эмоциональные диалоговые сессии, то есть он не являлся просто «болталкой», а действительно эмулировал понимание, в результате чего у человека к боту формировалась эмпатия.
Потом нам многие люди писали, спрашивая о том, как можно самим сделать такого бота, чтобы «оживлять» своих родственников, либо оставлять свою цифровую копию детям, то есть спрос был большой, но мы не хотели становиться цифровым похоронным бюро, лучше делать бизнес на живых людях. Поэтому мы пошли в сторону того, чтобы каждый мог сделать свою digital копию. Бот, общаясь с тобой, собирает твой лексикон, твои паттерны поведения и прокачивается, постепенно становясь тобой. В какой-то момент мы подумали, что Replika — это классное и подходящее по смыслу название.
— Как устроен ваш бот?
Для создания качественного общения с пользователями мы реализовали ряд нейросетевых подходов для моделирования диалога. Так, у нас есть ранжирующая диалоговая модель, чья основная цель — по входному диалоговому контексту выбрать наиболее релевантный ответ из базы предопределенных и отмодерированных ответов. Еще одно решение — генеративная диалоговая модель, которая может генерировать релевантный ответ слово за словом в зависимости от диалогового контекста. Однако несколько опасно использовать такую модель в продакшне, поскольку она может сгенерировать явно или неявно оскорбительный ответ, и это не всегда можно отфильтровать.
Чуть позже мы поменяли концепцию продукта, и теперь Replika — это не digital-копия пользователя, а его друг, который может поддерживать, подбадривать, как-то с тобой общаться, ведь не каждому захочется общаться с самим собой, людям нужны друзья.
— То есть сделать копию себя уже не получится?
Не совсем. Бот запоминает, что ты говоришь, но не пытается тебя «зеркалить». Вместо этого он использует какие-то факты, реплики, чтобы релевантно отвечать. К примеру, если ему отправить фотку с друзьями, то он спросит: «А кто это рядом с тобой?», а затем, запомнив твой ответ, в следующий раз скажет: «О, я вижу, ты встречался с Джоном, передавай ему привет!».
— Тебе не кажется, что это немного жутко, когда бот знает столько личной информации о тебе?
Конечно, мы много работаем над приватностью, ведь Replika действительно много спрашивает, что естественно для любой дружбы, но мы никому эту информацию не продаем, она не используется в коммерческих целях. С другой стороны, без нее никак не обойтись, ведь без какой-то личной информации бот был бы просто «болталкой» на общие темы.
По правде говоря, денег мы не зарабатываем и не монетизируемся, приложение бесплатное. Просто продолжаем оттачивать продукт и искать свою нишу, тестируем гипотезы. К примеру, Replika неожиданно выстрелила в Бразилии, нам стало очень много людей писать на португальском языке, и, как оказалось, они стали использовать бота в качестве тренировки разговорного английского.
Также мы решили выложить часть AI стека бота Replika в open-source, то есть сделали доступной генеративную диалоговую модель, в которой можно задавать эмоции для генерируемого ответа. Теперь любой желающий может, взяв какой-нибудь корпус и натренировать собственного бота, который сможет болтать на определенную тему, рассуждать о кино и музыке, реагировать на какие-то эмоции и выражать их.
Игорь Любимов, ToyUp
— Игорь, расскажи, как ты оказался в Сан-Франциско и чем ты сейчас занимаешься?
Начну с того, что я работал в Lingualeo продакт-менеджером, и мы с коллегой как-то обсуждали, каким может быть образование, пришли к теме чат-ботов, это как раз был 16-й год, когда они были в тренде. Образование — это всегда диалог, поэтому решили попробовать перенести диалоговые интерфейсы в эту сферу.
В итоге, мы переехали в Сан-Франциско, подняли здесь инвестиции и начали работать, генерировать идеи, их было огромное количество. Остановились на таком продукте, как образовательная, плюшевая игрушка, с которой дети могут разговаривать и одновременно изучать иностранные языки. При этом с каждой игрушкой в комплекте идет 30 датчиков, которые родители расклеивают по квартире, чтобы она могла взаимодействовать с окружающим ребенка миром. Благодаря датчикам игрушка знает, где находится ребенок, куда он идет и т.д. К примеру, в 21:00 она может начать говорить: «Пора спать, иди чисти зубы!», и пока ребенок не зайдет в ванную, игрушка будет постоянно напоминать об этом.
— Какие технологии стоят за вашей игрушкой? Используется ли Deep Learning?
Да, нейросети будут использоваться, но скорее всего внешне, то есть не на самом устройстве. Тут проблема в том, что в Штатах нельзя передавать данные, которые ребенок может свободно ввести куда-то, поскольку может возникнуть такая ситуация, что ребенок игрушке скажет: «Привет, меня зовут Алекс, моих родителей завтра не будет дома с 9 до 6, вот мой адрес». Поэтому с этим в США довольно жестко, и это накладывает дополнительные ограничения.
— Помогает ли опыт прохождения программы «Специалист по большим данным» в том, что ты делаешь сейчас?
Естественно помогает, поскольку теперь я понимаю применимость каждой технологии, знаю, как она работает, что можно сделать с помощью машинного обучения, а что нельзя, для каких задач нужны те или иные данные и т.д. Я не занимаюсь написанием кода, но, как продакт-менеджер, понимаю, где я могу применить машинное обучение, а где это не имеет смысла.
Попросту говоря, суть классического машинного обучения (не беря в расчет компьютерное зрение и т.д.) заключается в том, что тебе нужно подготовить данные, чтобы максимизировать какую-то метрику и предсказать вероятность какого-то события, то есть детерминировать какое-то число. Это кардинально меняет весь подход к машинному обучению: все сводится к тому, можешь ли ты в своей системе найти зависимость между данными и конкретным числом.
— В Москве сейчас очень развито Data Science сообщество, проходит огромное количество митапов, конференций. А как дела с этим в Сан-Франциско? Насколько тут развита культура данных?
Митапов тоже очень много, они проходят каждый день, всегда можно выбрать что-то для себя. При этом не надо думать, что здесь они на голову выше, чем в России, уровень тот же, может даже у нас чуть получше с Data Science.
— Здесь так же, как и в России, мероприятия в основном организуют какие-то компании?
Да, Uber, Amazon, Twitter часто хостят митапы, рассказывают про свои технологии. Однако еще чаще этим занимаются стартапы, которые достаточно известны в Долине, но не являются мировыми гигантами.
При этом на многих митапах выступают спикеры с Facebook и Google, и это очень крутая вещь, поскольку позволяет заводить полезные контакты. Просто подходишь к спикеру после его выступления, и если ты ему предлагаешь какую-то адекватную идею, то, конечно, он с тобой ее обсудит, тут все довольно открытые.
— Чем, по-твоему, культура ведения бизнеса тут, в Сан-Франциско, отличается от России?
Во-первых, здесь стартапы создаются с какой-то благой целью, они действительно хотят изменить мир, и на самом деле так оно и есть, ведь большинство изменений сейчас идут от технологий, которые как раз создаются в Долине. Вклад в развитие мира любого проекта, который делается здесь и выходит на рынок, впечатляет.
Во-вторых, здесь очень классно организованы бизнес-структуры и развита инфраструктура, то есть созданы все условия, чтобы делать классные продукты. Все предельно понятно: как делать партнерство, оформлять юридически какие-то схемы и т.д. В России с этим труднее. Несмотря на то, что в плане технологических талантов люди в России лучшие в мире, будучи компанией там, ты не можешь влиять на мир, учитывая российскую юрисдикцию и ментальность.
В феврале мы вместе с нашими партнерами из Долины, компанией Data Monsters, запустили Newprolab Global — ежемесячные мероприятия в зарубежными спикерами в сфере Data Science, Data Engineering и управления R&D командами. Это отличная возможность узнать, что и как делается там, задать вопросы. Мероприятие состоит из 2 выступлений (телемост), длящихся по 1 часу, включая Q&A сессию.
topheracher
Если грязными меньше 200к, то делать в этом вашем LA нечего.
Не совсем так. Им жизненно необходимо быть частью глобализации. Иначе они просто не заработают на жизнь.