

- Часть 1: С чего стоит начать
- Часть 2: Расширенный экран-заставка
- Часть 3: Стиль сына маминой подруги
- Часть 4: Получение данных пользователя (добровольное)
- Часть 5: А где вы храните данные?
Передаю слово автору, Алексею Плотникову.
В предыдущей статье я поднял вопрос удобной синхронизации данных пользователя между устройствами и первым делом решил проблему с его идентификацией, однако это самая малая доля того, что предстоит сделать для реализации поставленных задач.
Куда более сложным вопросом является способ, а самое главное, место хранения пользовательских данных и, стараниями Microsoft, при постановке такого вопроса первое, что приходит в голову – это Microsoft Azure. Облачная платформа Azure включает в себя настолько широкий спектр сервисов, что кажется нет задач, которые нельзя решить с ее помощью. Так это или нет, я судить не берусь, но моя задача безусловно по силам данной платформе. Впрочем, обо всем по порядку.
Начнем мы с малого – что такое облако? Впервые я услышал об облаке в далеком 2012м и тогда чаще всего применялось словосочетание «облачные вычисления». Изначальная идея таких вычислений заключалась в распределении вычислительных работ между разными удаленными друг от друга устройствами. Особо впечатлительные рассказывали о будущем, в котором даже самые трудные задачи будут обрабатываться в пару мгновений за счет того, что вычисления будут распределены между всеми компьютерами мира.
На практике же, все свелось к датацентрам разбросанным по миру и предоставляющим свои вычислительные мощности потребителям, а от первоначальной концепции осталось лишь распределение между машинами внутри датацентра и между самими датацентрами (чаще всего в пределах одного региона).
Исходя из выше сказанного можно считать, что, когда вы слышите слово «облако», можете воспринимать его как более привычное «хостинг», с тем лишь отличием, что мощности облака можно расширить без дополнительных усилий с вашей стороны.
Второй вопрос, который может у вас возникнуть – почему Azure? «Раз это статья в блоге Microsoft, значит автор будет рассказывать только об их продуктах» – скажите вы и будете не правы. Мотивы использовать именно Azure гораздо банальнее – так как это продукт Microsoft, то он имеет максимально высокую степень интеграции с их прочими продуктами, с помощью которых и ведется разработка моего приложение.
Впрочем, замечу, что компания прикладывает максимум усилий для того, чтобы использование Azure было привлекательным и для разработчиков под Android или iOS. Ну и последним по упоминанию, но не по важности стоит вопрос стоимости использования облака. Так как я являюсь обладателем подписки BizSpark, мне предоставлен ежемесячный кредит на суму с лихвой, покрывающую мои потребности в облаке, хотя и те условия, что предоставляются на бесплатной основе также могут покрыть большинство потребностей частного разработчика.
Теперь перейдем к непосредственному выбору механизма синхронизации и хранения данных. Лукавить не стану, как самоучке мне часто приходится сталкиваться с технологиями, о которых я не имею не малейшего представления и до знакомства с UWP, подобные задачи я решал с помощью баз данных SQL.
Однако UWP не имеет средств по работе с классическими СУБД SQL, а в качестве альтернативы предлагается SQLite и, начав ее изучение, я выяснил что такая база данных является встроенной, что подходит для удобного хранения и использования локальных данных, но совершенно не подходит для размещения данных в удаленном хранилище. Уже в процессе написания данной статьи, когда нужная технология была выбрана, я натолкнулся на одно из решений Azure в области разработки мобильных приложений, которое позволяет синхронизировать данные из таблицы SQLite между устройствами, но все хорошенько обдумав, я так и остался на первоначальном выборе.
К слову, сделать первоначальный выбор было не сложно, так как Microsoft вежливо подсказали перечень технологий, с которыми разработчику UWP вероятно придется столкнуться. В последних версиях Visual Studio при создании нового UWP проекта вы увидите страницу с рекомендациями по началу работы, где одна из ссылок гласит «Добавление рекомендуемой службы». По нажатию на эту ссылку открывается вкладка «Подключение службы» и уже в ней мы видим вариант «Облачное хранилище со службой хранилища Azure».
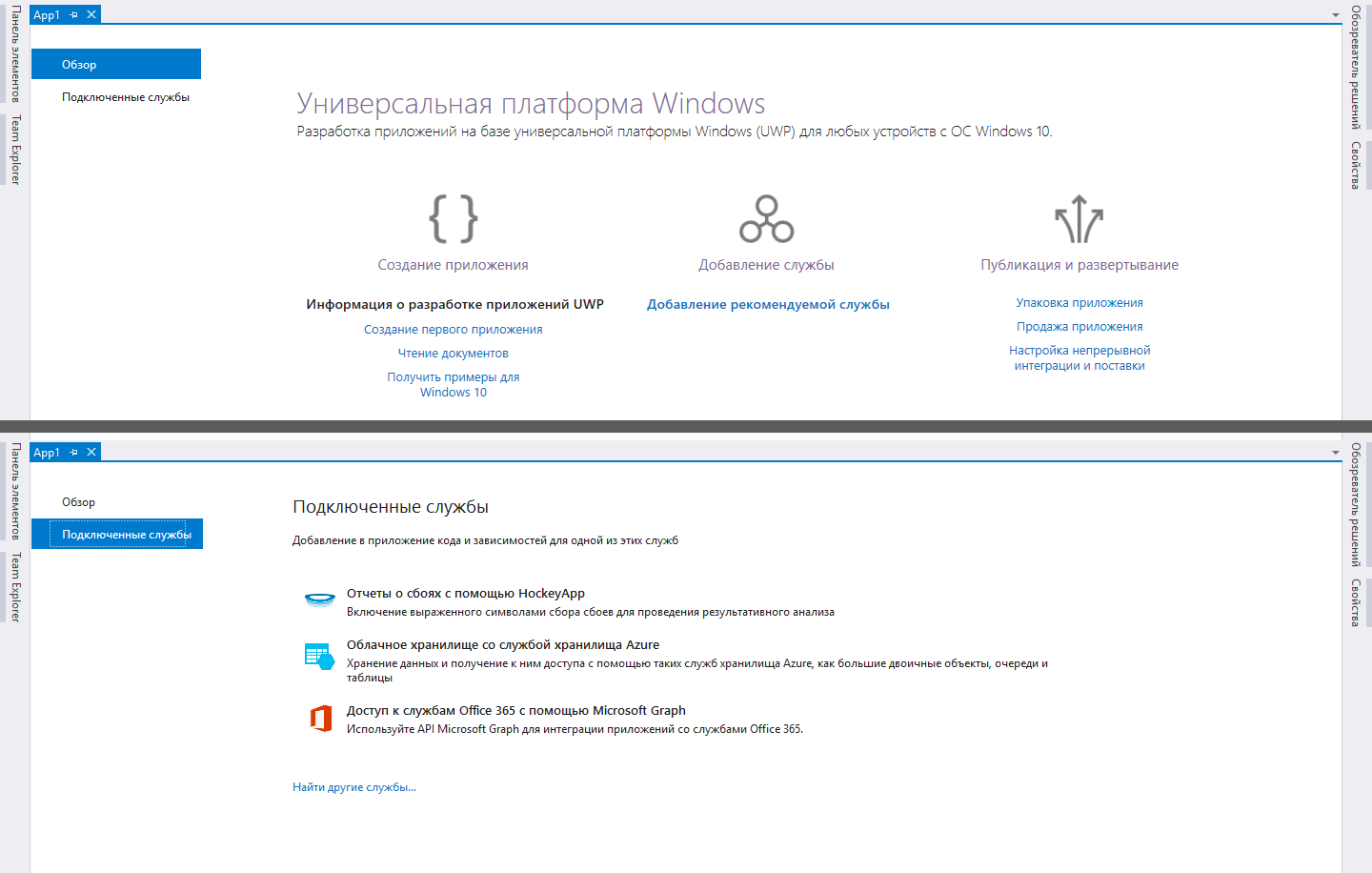
Интуиция подсказывает, что это именно то, что нужно, поэтому я решил остановится на углубленном изучении данного вопроса с целью дальнейшего использование в проекте.
Облачное хранилище представляет из себя набор из нескольких продуктов для разных задач подробнее о которых можно почитать здесь, но меня же в первую очередь заинтересовало хранилище таблиц, которое на поверку оказалось базой данных NoSQL.
NoSQL — это бессхемная база данных, то есть такая в которой таблицу не требуется структурировать заранее. По сути, таблица в данном случае это всего лишь часть пути к тому, что тут называют разделом, а значит в одной таблице могут содержаться строки, например, с тремя и пятью колонками одновременно. Для полного понимания особенностей хранилища таблиц советую внимательно почитать руководство, а я же буду рассматривать эту тему со своей приземленной точки зрения, ведь в конечном итоге материал ориентирован на новичков, коим в данной теме являюсь и я.
Для начала поэтапно разберемся как таблицу NoSQL создать:
1. Зарегистрируйте бесплатный аккаунт Azure. Если у вас есть подписка MSDN или BizSpark и она уже активирована в Azure, то можете пропустить этот шаг. Бесплатный аккаунт предоставляет вам кредит в размере 200$ на первый месяц и затем бесплатный доступ к определенному объему ресурсов большинства служб Azure. В переводе на понятный язык, все сделано так, что платить вам не придется до тех пор, пока ваш продукт не будет достаточно зарабатывать, чтобы покрыть расходы, не говоря уже об использования Azure в целях самообразования.
Но даже если вы преодолеете бесплатный порог, цены на хранилище таблиц намного лояльнее, чем на аналогичный объем баз данных SQL. Например, на момент написание статьи мною создано две таблицы, пока только с одной записью. За 18 дней отчетного периода я обращался к ней в среднем 20-30 раз за день и с кредитного счета за этот период списано 2 копейки. Масштабируя такие затраты на планируемый объем, я понял, что они с лихвой покрываются потенциальным доходом от приложения.
2. Теперь, когда у вас есть аккаунт в Azure, переходим к созданию учетной записи хранения.
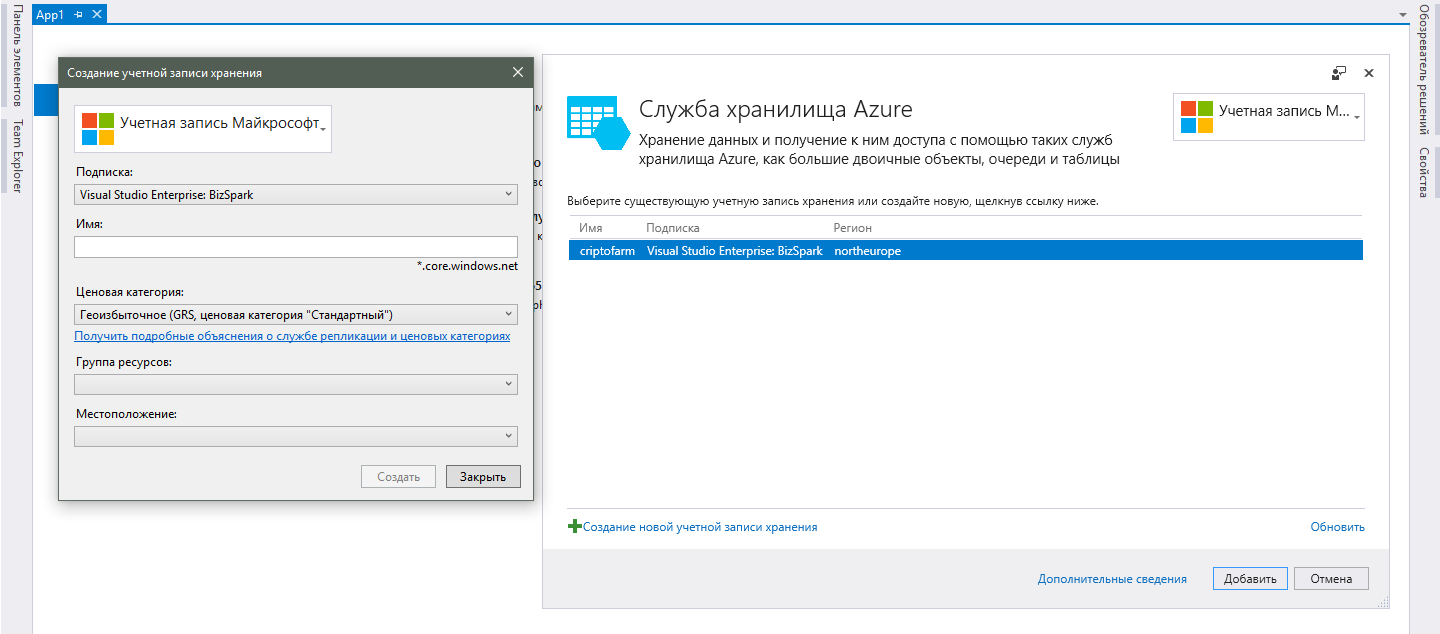
Сделать это можно все из той же страницы подключение сервисов Visual Studio, что я описал выше. Если вы вдруг закрыли эту страницу, то открыть ее можно при нажатии двойным щелчком на «Connected Services» в обозревателе решений. После выбора необходимой службы, откроется окошко с имеющимися учетными записями хранения и, для добавление новой, жмем соответствующую кнопку.
В новом окне понадобится выполнить следующие шаги:
- Для начала потребуется залогинится с вашей учетной записью Microsoft. Нужно использовать тот аккаунт, к которому привязаны ваши подписки или бесплатный аккаунт Azure.
- В поле «Подписка» после входа в аккаунт появятся ваши подписки(а). Тут с выбором все просто, поэтому комментарии излишни.
- В поле «Имя» нужно указать желаемое имя службы хранения. Так как это одновременно и доменное имя службы, оно должно быть уникальным в рамках всех имеющихся в Azure учетных записей, а не только в рамках вашей.
- Поле «Ценовая категория» потребует от вас понимания отличий облачной платформы от обычного хостинга, так как перейдя по ссылке под полем, вы сможете увидеть перечень цен, но не внятное объяснение, что дает вам каждый из вариантов. Конечно, в дебрях дополнительных ссылок можно найти исчерпывающую информацию обо всех эти сокращениях вроде GRS и LRS, но для рядового разработчика это лишнее. Достаточно понять, что чем дороже тариф, тем больше датацентров будет задействовано для обработки и хранения ваших данных и тем выше вероятности их сохранности. Для небольшого проекта вполне подойдет самый низкий тариф LRS.
- «Группа ресурсов» — это объединение нескольких служб Azure для единого управления ими. В нашем случае создаем новую, присваивая любое понятное имя и идем дальше.
- Последнее, что предстоит выбрать это «Местоположение» для вашей службы. Под местоположением подразумевается фактическое расположение датацентров, что будут отвечать за работу с нашими данными. Обратите внимание, что я говорю во множественном числе, так как в одном регионе может быть несколько датацентров и работа может быть распределена между ними (в случае, если вы выбрали советующую ценовую категорию). Выбирайте тот, что максимально близок к вашей основной пользовательской базе. Впрочем, если вы планируете вырасти до масштабов всего мира и вам важен максимальный отклик в любой точке планеты, никто не мешает вам для каждой региональной версии приложения создать отдельную учетную запись хранения и реализовать синхронизацию данных между ними. Именно высокий уровень расширяемости — это главное преимущество облака.
3. После создания учетной записи хранения, она будет добавлена в список и можно продолжать, нажав кнопку «Добавить». Результатом этого действия, станет добавление в проект пакета NuGet для работы с Azure и сохранение строки подключения в файле app.config проекта.
К сожалению, работать со значениями из данного файла в UWP невозможно (либо возможно с жуткими костылями), поэтому просто скопируйте оттуда строку подключения к службе хранилища в удобное место проекта и переходите к следующему пункту.
4. Теперь осталось создать таблицу и начать работу с ней. И вот здесь начинается индивидуальная работа, зависящая непосредственно от поставленных задач.
Дело в том, что прежде, чем приступать к созданию каких-либо таблиц стоит хорошо продумать архитектуру хранения ваших данных. Работать с хранилищем таблиц настолько удобно, что создать новую таблицу прямо из кода дело всего нескольких строк и при таком удобстве возникает естественное желание выделить отдельную таблицу для каждого пользователя, ведь в конечном итоге задача в синхронизации данных между его устройствами. Однако при работе с незнакомой технологией не стоит делать поспешных решений и нужно внимательно взвешивать все «за» и «против». В принятии правильного решения может помочь специальная статья руководства, но готовьтесь к тому, что ее придется несколько раз перечитать, так как сразу очень сложно усвоить все данные, особенно с учетом массы новых терминов.
Дальнейшее повествование я буду вести с учетом того, что вы все же прочитали руководство и поняли некоторые особенности работы с хранилищем таблиц. Например, я понял, что концептуально таблица не является какой-то обособленной единицей и является скорее местом логической группировки записей. Это легко понять, если представить таблицу как папку, в которой вы храните файлы с данными. Папка сама по себе не занимает места и не является неотъемлемой частью файлов, а всего лишь определяет часть пути к файлам, которые логично, но не обязательно, сохранять именно в эту папку.
Вывод из этого довольно простой – никто не мешает хранить настройки всех пользователей в одной таблице, главное, чтобы пара значений у колонок PartitionKey и RowKey были уникальными внутри таблицы. Это опять же реализуемо в моем проекте, так как в качестве PartitionKey выступит ID пользователя, а в качестве RowKey, например, строка «UserName», что позволит определить уникальную запись, в которой хранится имя пользователя. Но как я и сказал выше, нужно взвешивать все «за» и «против», так давайте же взвесим:
- «За» отдельную таблицу для данных каждого пользователя, выступает удобство в восприятии строения данных. Если воспринимать таблицу как папку с файлами, то логично, что все файлы одного пользователя лежат в одной папке и работать с такой архитектурой привычнее.
- «Против» отдельной таблицы выступают все остальные факторы. Данные пользователя внутри отдельной таблицы — это удобно ровно до тех пор, пока количество таких таблиц не будет исчисляется тысячами. Так как более высоким уровнем над таблицей является учетная запись хранения, другой группировки для них не предусмотрено.
С учетом потенциальной пользовательской базы мы рискуем утонуть в тысячах отдельных таблиц, потеряв те, что имеют какое-либо приоритетное значение. В тоже время хранение настроек всех пользователей в одной таблице, упрощает администрирование и работу с данными с целью сбора статистической информации или реализации социальных функций.
Мало того, низкая цена использования хранилища таблиц, позволяет продублировать какие-либо данные в отдельные таблицы, по требуемой логике. В частности, я планирую создать дополнительную таблицу с именем пользователя, ссылкой на аватар и указанием принадлежности к стране, которая будет использоваться для рейтинговых таблиц или других социальных функций, что, возможно, будут добавлены в приложение.
Итак, когда со структурой хранения данных разобрались, давайте наконец добавим новую таблицу. Так как создавать ее на уровне кода мы отказались, остается два варианта: через веб-портал Azure или с помощью специального инструмента «Microsoft Azure Storage Explorer», который можно загрузить с сайта storageexplorer.com. И в том, и в другом случае, необходимо выбрать нужную учетную запись хранения и в разделе «Служба таблиц/Tables» выбрать «+Таблица/Create Table». В появившемся диалоговом окне введите желаемое имя и зафиксируйте изменения.
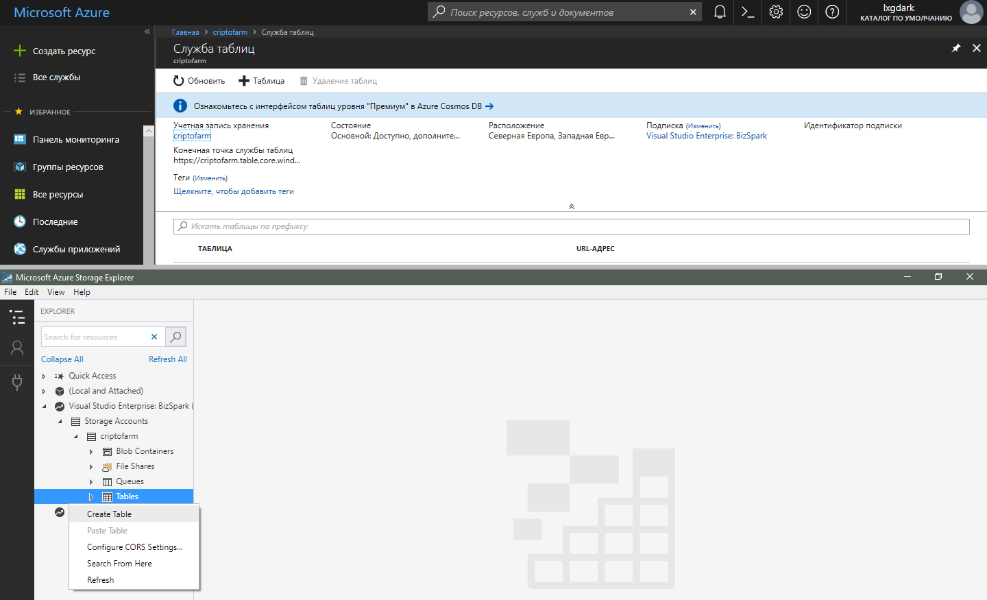
После этого с новой таблицей можно без проблем работать из кода.
Основные операции, которые я будут производить с таблицей – это вставка и извлечение строк, которые в терминологии хранилища таблиц называются «сущности». Такой термин проще воспринимать, когда понимаешь, что для вставки и извлечение сущности потребуется сопоставить ей класс унаследованный от TableEntity из Microsoft.WindowsAzure.Storage.Table. Класс наследник уже будет содержать некоторые обязательные поля, такие как, например, PartitionKey (имя раздела) и RowKey (имя строки), а те поля, что мы реализуем самостоятельно и будут колонками в строке (свойства сущности).
Рассмотрим пример таблицы в которой будет хранится перечень всех игроков с их именем, аватаром и принадлежностью к стране.
Первым делом добавим необходимые импорты:
Imports Microsoft.WindowsAzure.Storage
Imports Microsoft.WindowsAzure.Storage.TableМетоды для работы с таблицей я решил вынести в отдельный класс для удобства работы из разных точек приложения. Создадим его и сразу добавим заранее известные константы:
Public Class AzureWorker
Private Const AzureStorageConnectionString As String = "ваша строка подключения, что вы скопировали из app.config"
Private Const GamerListTableNameString As String = "GamerList"
'Код работы с таблицей
…
End ClassТеперь нужно создать класс, который мы будем сопоставлять с сущностью (строкой) внутри таблицы:
Private Class GamerListClodTableDataClass
Inherits TableEntity
Public Const RowKeyValue As String = "UserID"
Public Sub New ()
RowKey = RowKeyValue
End Sub
Public Property UserName As String = ""
Public Property UserСountryID As String = ""
Public Property UserAvatar As String = ""
End ClassСопоставляемый класс должен быть унаследован от TableEntity и иметь поля для данных, что мы планируем разместить в таблице. Обратите внимание, что задавать значения для RowKey или PartitionKey на уровне класса не обязательно, но в моем случае RowKey задан потому, что он является неизменным вне зависимости от прочих входных данных.
Но, так как на этом этапе вы, вероятно, не до конца прониклись сутью работы с хранилищем таблиц, разъясню заложенную в этот этап логику. Самым быстрым способом работы с таблицей, являются запросы к сущности по имени строки и имени раздела, поэтому нужно знать эти данные заранее. Кроме того, сочетание PartitionKey и RowKey должно быть уникальным в рамках таблицы, а значит в один из этих ключей логично записать уникальный ID пользователя, а второму ключу присвоить любое имя, которое мы всегда будем знать. Именно это и делается в классе GamerListClodTableDataClass.
Последний подготовительный этап перед непосредственными запросами к таблице, это создание ее объекта в отдельной функции:
Private Shared Function GetCloudTable(tableName As String) As CloudTable
Dim storageAccount As CloudStorageAccount = CloudStorageAccount.Parse(AzureStorageConnectionString)
Dim tableClient As CloudTableClient = storageAccount.CreateCloudTableClient()
Dim table As CloudTable = tableClient.GetTableReference(tableName)
Return table
End FunctionСделано это, чтобы не дублировать код каждый раз, когда мы захотим прочесть или записать данные в таблицу. Обратите внимание, что этот код не осуществляет непосредственных запросов к облаку и без проблем выполнится при отсутствующем подключении. Все что он делает это поэтапное создание объекта таблицы из имеющихся данных, таких как строка подключения к хранилищу и имя таблицы.
Наконец перейдем к непосредственной работе с таблицей и начнем с сохранения данных текущего пользователя:
Public Shared Async Function SavedOrUpdateUserData(u As UserManager) As Task(Of Boolean)
Dim table As CloudTable = GetCloudTable(GamerListTableNameString)
Try
If Await table.ExistsAsync Then
Dim UserDataClodTableData As New GamerListClodTableDataClass With {.PartitionKey = u.UserId, .UserName = u.UserName.Trim, .UserСountryID = u.UserСountryID, .UserAvatar = "https://apis.live.net/v5.0/" & u.UserId & "/picture"}
Dim insertOperation As TableOperation = TableOperation.InsertOrReplace(UserDataClodTableData)
Await table.ExecuteAsync(insertOperation)
Return True
End If
Catch ex As Exception
End Try
Return False
End FunctionЗапрос выполнен в виде асинхронной функции, чтобы вызывающий код мог получить результат выполнения (True при успехе и False в случае неудачи). Также в функцию передается параметр типа UserManager, который является ссылкой на класс с данными пользователя. Такой класс мы создали в прошлой статье, с тем лишь отличием, что в данной версии есть поле UserСountryID хранящее данные о стране пользователя.
Для запросов к таблице, сначала нужно создать ее объект, используя строку подключения к хранилищу и имя таблицы (этот процесс мы вынесли в отдельную функцию ранее). Далее следует проверить существование таблицы и, хотя мы точно уверены, что таблица с таким именем у нас есть, может возникнуть ошибка, например из-за отсутствия подключения к сети или из-за сбоя в облаке (именно поэтому данный код вынесен в блок Try/Catch). Затем, прежде чем произвести запись в таблицу, нужно создать экземпляр класса UserDataClodTableData и присвоить его полям требуемые значение и только потом создать операцию InsertOrReplace. Как можно догадаться из названия операции, она вставит новую строку в таблицу, если строки с такой же парой PartitionKey и RowKey в таблице не существует и заменит данные, если такая строка уже есть. Ну а финальная команда ExecuteAsync, собственно, и выполнит запланированное действие на стороне хранилища таблиц.
Считать данные из таблицы так же просто, как и записать их. Давайте, например, запросим имя пользователя:
Public Shared Async Function GetUserName(id As String) As Task(Of String)
Dim table As CloudTable = GetCloudTable(GamerListTableNameString)
Try
If Await table.ExistsAsync Then
Dim retrieveOperation As TableOperation = TableOperation.Retrieve(Of GamerListClodTableDataClass)(id, GamerListClodTableDataClass.RowKeyValue)
Dim retrievedResult As TableResult = Await table.ExecuteAsync(retrieveOperation)
If retrievedResult.Result IsNot Nothing Then
Return CType(retrievedResult.Result, GamerListClodTableDataClass).UserName
End If
End If
Catch ex As Exception
End Try
Return ""
End FunctionДанный код почти не отличается от предыдущего и так же начинается с создания объекта таблицы и проверки ее существования. Далее, как и при записи создаем операцию, но в этот раз операцию извлечения, которая требует указания PartitionKey и RowKey. После извлекаем результат с помощью ExecuteAsync и работаем с полученным объектом типа TableResult, что на деле сводится к приведению свойства Result к типу сопоставляемого класса и извлечению имени пользователя.
Работа с таблицей не ограничивается операциями чтения и записи и поддерживает массу различных сценариев. Например можно создать запрос, который извлечет все сущности с указанным PartitionKey или все сущности, что имеет указанное поле, но важно помнить о скорости выполнения таких операций, а также об объеме данных, которые будут переданы по сети.
Приведенный выше пример является самым оптимальным с точки зрения скорости запроса, так как система адресации быстрее всего найдет сущность по пути «имя хранилища\имя таблицы\ PartitionKey+RowKey», однако для получения одного только имени мы загружаем всю сущность целиком, что не благоприятно сказывается на объем передаваемых данных.
Ниже приведен модифицированный код функции с учетом максимальной оптимизации запроса:
Public Shared Async Function GetUserName(id As String) As Task(Of String)
Dim table As CloudTable = GetCloudTable(GamerListTableNameString)
Try
If Await table.ExistsAsync Then
Dim projectionQuery As TableQuery(Of DynamicTableEntity) = New TableQuery(Of DynamicTableEntity)().Where(TableQuery.CombineFilters(TableQuery.GenerateFilterCondition("PartitionKey", QueryComparisons.Equal, id), "and", TableQuery.GenerateFilterCondition("RowKey", QueryComparisons.Equal, GamerListClodTableDataClass.RowKeyValue))).Select({"UserName"})
Dim resolver As EntityResolver(Of String) = Function(pk, rk, ts, props, etag)
Return props("UserName").StringValue
End Function
Dim result As TableQuerySegment(Of String) = Await table.ExecuteQuerySegmentedAsync(projectionQuery, resolver, Nothing)
If result.Count > 0 Then
Return result(0)
End If
End If
Catch ex As Exception
End Try
Return ""
End FunctionВместо создания объекта операции, в данном коде мы создаем объект запроса, который содержит несколько методов для определения того, что нужно получить в результате. Метод Where создает фильтр, указывающий на необходимость вернуть только те строки, у которых PartitionKey и RowKey равны указанным значениям, а следующий за ним Select сообщает о необходимости выбрать только колонку UserName.
При таком запросе нет смысла сопоставлять результат с каким-либо классом, поэтому в качестве возвращаемого значения выступает словарь IDictionary, где ключ — это имя столбца, а значение его содержимое. Так как функция ExecuteQuerySegmentedAsync не знает какой результат ее выполнения будет получен в нее можно (а в данном случае нужно) передать делегат EntityResolver, который отсылает к функции, вынимающей из словаря нужное значение. Результатом всего этого становится перечислитесь TableQuerySegment в первом же индексе которого хранится имя запрошенного пользователя.
Вообще использование запросов вместо базовой операции извлечения позволяет существенно расширить возможности работы с таблицей, но будьте осторожны, потому что в отличии от классического SQL, здесь скорость обработки запроса напрямую зависит от его параметров. Вам никто не мешает выполнить запрос с целью извлечения всех записей пользователей, чьи имена равны заданному, но такой запрос будет более длительный, чем его аналог в SQL. Чтобы усвоить это, еще раз направляю вас в руководство по проектированию таблиц, на которое я ссылался выше, а так же рекомендую изучить статью, где приведены примеры по работе с хранилищем таблиц.
Важно! В статьях по ссылкам используется код для классических .NET приложений и отличается от реализации в UWP. Благо — это отличие не значительное и аналоги находятся интуитивно (чаще всего отличия в приставке «Async»).
В заключении поделюсь результатами использования хранилища Azure в моем проекте на текущий момент. При первом запуске, после получения ID пользователя и загрузки данных с Live ID, я предлагаю ему выбрать псевдоним (ник) на случай, если для игры ему не подходит сохраненное в профиле имя. Затем введенный ник сохраняется в классе UserManager вместо стандартного, и все эти данные сохраняются в таблицу GamerList. При следующем запуске происходит фоновое получение ID пользователя и запрос псевдонима из хранилища. В результате пользователь видит в игре свой ник, а не имя из стандартного профиля.
Также в будущем таблица со списком пользователей пригодится для ввода в игру социальных функций и, уже сейчас, я придумал минимум одно применение этим данным. В реализации этой задачи мне снова помогут инструменты Azure, такие как «Хранилище очередей» и «Функции Azure», но об этом я расскажу в одной из следующих статей.
Комментарии (7)

taliban
20.06.2018 17:08Сейчас полным ходом набирает популярность PWA, как по мне достойный мутант между оффлайном и онлайном. Так что не стоит кардинально брать сторону лишь одной из сторон.
(это предполагался ответ thauquoo)lxgdark
20.06.2018 17:56Да PWA как раз и подразумевался в фразе «решение Azure в области разработки мобильных приложений» о котором я узнал уже в процессе и от которого все равно отказался. В моем случае причиной стала прямая зависимость игрового процесса от скорости синхронизации (процесс завязан на таймерах).
Соглашусь, что для огромного пласта проектов PWA идеальное решение. Я вот, например, планирую его внедрить в свой проект «Шар напоминалка» в будущем.
Yankipl
20.06.2018 17:17Понравилась ваша статья, у вас хороший стиль повествования. Скажите, как я понял это ваш проект по самообразованию, а по каким критериям вы решили выбрать VB?
lxgdark
20.06.2018 17:51С VB началось мое знакомство с программированием и со временем я так к нему привык, что не хочу от него отказываться. C# я не плохо читаю, но не пишу на нем. Если бы разработка была моей работой, то скорее всего пришлось бы перейти на C#, но так как я делаю для себя, то зачем мучится?
К счастью VB не стоит на месте и идет в ногу со временем, поэтому я могу писать на нем современные приложения и не переживать, что отстал от трендов.unsafePtr
20.06.2018 22:30Благодаря Roslyn, можно конвертировать код из VB -> C#, и обратно. Это позволило мигрировать очень много написанного софта на C#.
thauquoo
После того, как я два месяца побывал в месте, где ужасная сотовая связь и никакого интернета вообще, то твёрдо решил, что у пользователя всегда должен быть способ работать в полном оффлайне, даже если программу принесли на флешке и установили, без единого байта по интернету.
Кто-то скажет, что это возврат в начало 2000-х, но только так можно быть наиболее честным перед пользователем, когда он уверен, что имеет полный контроль над своими данными и не привязан к облачным сервисам. Сервисы могут быть как дополнительный бонус, но бескомпромиссная привязка к ним — это зло.
lxgdark
Изначально я рассматривал два режима игры — онлайн с полным набором функций и офлайн с некоторыми ограничениями (в основном социально-ориентированными). Но после долгих раздумий пришел к выводу, что игровой механики слишком мало для офлайна, что в конечном итоге скажется на статистике отзывов. А вот с наличием рейтингов и прочих стимулов, игровая механика воспринимается совсем иначе. К слову в магазине Windows есть масса игр не работающих офлайн, поэтому эта практика стандартная.
На последок добавлю, что игра пишется с оглядкой на универсальность, а значит я рассчитываю, что игрок будет играть с нескольких устройств, а для этого не обойтись без облачной синхронизации.