

Новый язык в Data Science. В России Julia довольно редкий язык, хотя за рубежом его используют уже 5 лет (тоже мне, удивили). Источников на русском нет, поэтому я решила сделать показательный пример работы Julia, взятый из одной замечательной книги. Лучший способ выучить язык — начни что-то писать на нем.
Привет Хаброжителям.
Некоторое время назад я начала изучать новый язык Julia. Ну как новый. Это что-то среднее между Matlab и Python, очень похож синтаксис, и сам язык написан на С/С++. В общем-то, история создания, что, зачем и почему есть на Википедии и в паре статей на Хабре.
Первое, с чего началось мое изучение языка — правильно, нагуглила на Coursera онлайн курс на английском. Там про базовый синтаксис + параллельно пишется мини-проект по предсказанию болезней в Африке. Основы и сразу практика. Если вам нужен сертификат, покупайте полную версию. Я проходила бесплатно. Отличие такой версии в том, что ваши тесты и ДЗ никто не проверит. Мне было важнее получить ознакомление нежели сертификат. (Читать зажала 50 баксов)
После я решила, что надо бы прочитать книгу по Julia. Гугл выдал список книг и дальше изучая отзывы и ревью, выбрала одну из них и заказала на Amazon. Книжные версии всегда приятнее читать и черкать в них карандашом.
Книга называется Julia for Data Science, автор Zacharias Voulgaris, PhD. Та выдержка, которую я хочу представить, содержит много опечаток в коде, которые я исправила и поэтому представлю рабочую версию + мои результаты.
kNN
Это пример применения алгоритма классификации метода ближайших соседей. Наверное, один из самых старых алгоритмов машинного обучения. Алгоритм не имеет фазы обучения и при этом довольно быстр. Смысл его довольно прост: чтобы классифицировать новый объект, нужно найти похожих «соседей» из набора данных (базы) и затем определить класс голосованием.
Оговорюсь сразу, что в Julia существуют готовые packages, и лучше пользоваться ими для сокращения времени и уменьшения ошибок. Но этот код, в некотором роде, показательный по синтаксису Julia. Для меня удобнее учить новый язык по примерам, нежели читая сухие выдержки общего вида той или иной функции.
Итак, что мы имеем на вход:
Training data X (обучающую выборку), training data labels x(соответствующие метки), testing data Y (тестовую выборку), number of neighbors k (число соседей).
Понадобятся 3 функции: distance calculation function, classification function и main.
Суть такова: берем один элемент тестового массива, вычисляем расстояния от него до элементов тренировочного массива. Затем выбираем индексы тех k элементов, которые оказались максимально близкими. Тестируемый элемент отнесем к тому классу, который является наиболее встречающийся среди k ближайших соседей.
function CalculateDistance{T<:Number}(x::Array{T,1}, y::Array{T,1})
dist = 0
for i in 1:length(x)
dist += (x[i] - y[i])^2
end
dist = sqrt(dist)
return dist
end
Основная функция алгоритма. На вход приходит матрица расстояний между объектами обучающей и тестовой выборки, метки обучающей выборки, число ближайших «соседей». На выходе предсказанные метки для новых объектов и вероятности каждой метки.
function Classify{T<:Any}(distances::Array{Float64,1}, labels::Array{T,1}, k::Int)
class = unique(labels)
nc = length(class) #number of classes
indexes = Array(Int,k) #initialize vector of indexes of the nearest neighbors
M = typemax(typeof(distances[1])) #the largest possible number that this vector can have
class_count = zeros(Int, nc)
for i in 1:k
indexes[i] = indmin(distances) #returns index of the minimum element in a collection
distances[indexes[i]] = M #make sure this element is not selected again
end
klabels = labels[indexes]
for i in 1:nc
for j in 1:k
if klabels[j] == class[i]
class_count[i] +=1
end
end
end
m, index = findmax(class_count)
conf = m/k #confidence of prediction
return class[index], conf
end
Ну и конечно же всея всех функций.
На вход будем иметь обучающую выборку Х, метки обучающей выборки х, тестовую выборку Y и кол-во “соседей” k.
На выходе мы будем получать предсказанные метки и соответствующие вероятности присуждения каждого класса.
function main{T1<:Number, T2<:Any}(X::Array{T1,2}, x::Array{T2,1}, Y::Array{T1,2}, k::Int)
N = size(X,1)
n = size(Y,1)
D = Array(Float64,N) #initialize distance matrix
z = Array(eltype(x),n) #initialize labels vector
c = Array(Float64, n) #confidence of prediction
for i in 1:n
for j in 1:N
D[j] = CalculateDistance(X[j,:], vec(Y[i,:]))
end
z[i], c[i] = Classify(D,x,k)
end
return z, c
end
Tестирование
Давайте протестируем то, что у нас получилось. Для удобства алгоритм сохраним в файл kNN.jl.
База позаимствована с Открытого курса по машинному обучению. Набор данных называется Samsung Human Activity Recognition. Данные поступают с акселерометров и гироскопов мобильных телефонов Samsung Galaxy S3, также известен вид активности человека с телефоном в кармане – ходил ли он, стоял, лежал, сидел или шел вверх/вниз по лестнице. Решим задачу определения вида физической активности именно как задачу классификации.
Метки будут соответствовать следующему:
1 – ходьба
2 – подъем вверх по лестнице
3 – спуск по лестнице
4 – сидение
5 – человек в это время стоял
6 – человек лежал
include("kNN.jl")
training = readdlm("samsung_train.txt");
training_label = readdlm("samsung_train_labels.txt");
testing = readdlm("samsung_test.txt");
testing_label = readdlm("samsung_test_labels.txt");
training_label = map(Int, training_label)
testing_label = map(Int, testing_label)
z = main(training, vec(training_label), testing, 7)
n = length(testing_label)
println(sum(testing_label .== z[1]) / n)
Result: 0.9053274516457415
Качество оценивается путем отношения правильно предсказанных объектов ко всей тестовой выборке. Вроде бы не так и плохо. Но моя цель скорее показать Julia, и что он имеет место быть в Data Science.
Визуализация
Дальше я хотела попробовать визуализировать результаты классификации. Для этого нужно построить двумерную картинку, имея 561 признак и не зная, какие из них самые показательные. Поэтому для снижения размерности и последующего проектирования данных на ортогональное подпространство признаков было решено использовать Principal Component Analysis (PCA). В Julia, как и в Python есть готовые packages, поэтому немного упростим себе жизнь.
using MultivariateStats #for PCA
A = testing[1:10,:]
#PCA for A
M_A = fit(PCA, A'; maxoutdim = 2)
Jtr_A = transform(M_A, A');
#PCA for training
M = fit(PCA, training'; maxoutdim = 2)
Jtr = transform(M, training');
using Gadfly
#shows training points and uncertain point
pl1 = plot(training, layer(x = Jtr[1,:], y = Jtr[2,:],color = training_label, Geom.point),
layer(x = Jtr_A[1,:], y = Jtr_A[2,:], Geom.point))
#predicted values for uncertain points from testing data
z1 = main(training, vec(training_label), A, 7)
pl2 = plot(training, layer(x = Jtr[1,:], y = Jtr[2,:],color = training_label, Geom.point),
layer(x = Jtr_A[1,:], y = Jtr_A[2,:],color = z[1], Geom.point))
vstack(pl1, pl2)
На первом рисунке размечена обучающая выборка и несколько объектов из тестовой выборки, которые нужно будет отнести к своему классу. Соответственно, на втором рисунке видно, что эти объекты были размечены.

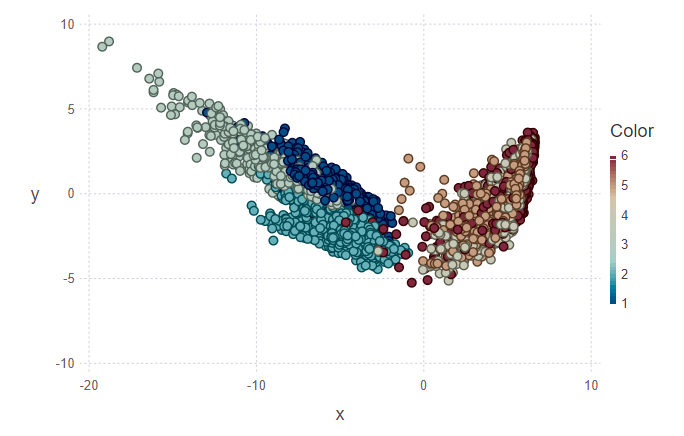
println(z[1][1:10], z[2][1:10])
> [5, 5, 5, 5, 5, 5, 5, 5, 5, 4][1.0, 0.888889, 0.888889, 0.888889, 1.0, 1.0, 1.0, 1.0, 0.777778, 0.555556]
Глядя на изображения, хочется задать вопрос «почему такие кластеры некрасивые?». Поясню. Отдельные кластеры не очень четко разграничены из-за особенностей данных и применения PCA. Для PCA простое хождение и хождение по лестнице, это как один класс – класс движения. Соответственно, второй класс – класс покоя (сидение, стояние, лежание, которые между собой не сильно отличимые). И поэтому четкое разделение прослеживается на два класса вместо шести.
Заключение
Для меня это только начальное погружение в Julia и использование этого языка в машинном обучении. Кстати говоря, в котором я тоже скорее любитель, чем профессионал. Но пока мне интересно, я продолжу глубже это дело изучать. Во многих иностранных источниках ставят ставки на Julia. Ну что ж, поживем, увидим.
P.S.: Если будет интересно, могу в следующих постах рассказать про особенности синтаксиса, про IDE, с установкой которого у меня были проблемы.
Комментарии (2)

topspin
24.07.2018 23:13Ждем хотя бы релиза 0.7. После него Julia наверное не будет очень сильно меняться.
ogurtsov
Материалы на русском есть. Как минимум, это переводная книга Шеррингтона "Осваиваем язык Julia" и мое недоруководство https://github.com/statist-bhfz/julia_stats Проблема в моментальном устаревании написанного прежде всего.