

Часто программистам приходится разбираться с чужим незнакомым кодом. Это может быть и изучение интересных проектов с открытым кодом, и необходимость по работе — в случае присоединения к новому проекту, при анализе большого объема legacy кода и т.д. Думаю, каждый из вас сталкивался с этим.
У меня в процессе такой работы всегда остро ощущалась необходимость некоего инструмента, специально заточенного для облегчения процесса быстрого погружения в большие объемы незнакомого кода. Со временем появлялись все новые интересные задумки в разных областях, и все они требовали изучения больших объемов чужого кода. Децентрализованные сети, криптовалюты, компиляторы, операционные системы — все это большие проекты, требующие изучения значительных объемов кода. В какой-то момент я решил: надо просто взять и сделать этот специальный инструмент. В этой статье я представляю вашему вниманию то, что получилось в результате.
Что вообще может помочь в изучении кода? Конечно, хорошо когда на код есть подробная документация — это как правило ее нет; хороший стиль кодирования и комментарии это тоже хорошо, но и этого как правило недостаточно. Также существуют различные генераторы документации к коду, такие как doxygen. Анализируя структуру кода и специальные документирующие комментарии, они генерируют документацию в виде гипертекста в формате html. Основной недостаток такой документации — ее неинтерактивность; в процессе изучения кода у программиста может возникнуть какое-то новое понимание, и для того чтобы отразить его в документации, нужно написать новые документирующие комментарии и перегенерировать всю документацию заново.
Кроме того, такая документация не имеет непосредственной связи с кодом в среде разработки, т.е. по щелчку на гиперссылке не произойдет открытия файла с данным кодом в IDE. Для таких инструментов есть хорошая аналогия, уходящая корнями в древние времена: первые дизассемблеры были инструментами командной строки, которые генерировали код без участия пользователя. Затем появился первый интерактивный дизассемблер («IDA pro»), который предполагал активное участие пользователя в процессе дизассемблирования — назначение имен переменных и функций, определение структур, написание комментариев к коду и т.д.
Анализ больших объемов чужого кода на высокоуровневом языке в чем-то очень похож на дизассемблирование. Таким образом у меня начало складываться представление о том, что именно я хочу. В большинстве IDE есть классические панели File View и Class View, отображающие структуру файлов и пространств имен/классов внутри них. Но эта структура как правило жестко связана с синтаксисом языка и не позволяет вносить пользовательскую смысловую нагрузку. Таким образом, первое что хотелось иметь — это интерактивная возможность построения произвольных деревьев, содержащих осмысленно названные ссылки на код — на те же классы и функции, или вовсе на произвольные места. И второе — это желание как-то пометить код непосредственно в редакторе. Пометки могут нести самый разный смысл: от простых «изучено», «разобраться», «переписать», до принадлежности кода к разным смысловым группам. Можно пометить комментарием, но хотелось чего-то более заметного. Например, изменения цвета фона у фрагмента кода. Так что цветовыделители на КДПВ это довольно точная аналогия из реального мира.
Проведя первые эксперименты, я довольно быстро понял, что это должен быть плагин к современной среде разработки, а не собственный редактор. Работать из двух редакторов одновременно — это глупо и неудобно; перспектива повторять все возможности среды разработки радости не внушала, да и зачем делать то что уже сделано? Поэтому плагин. Qt Creator был выбран в качестве первой IDE просто потому, что в нем наиболее востребованные операции навигации по коду (Go to definition, Find references и т.д.) выполняются максимально быстро. Следующей средой будет Visual Studio, а дальше — в случае успеха самой концепции — реализации для других IDE.
Теперь о том, как оно все устроено. Введено понятие «маркерных комментариев». Это обычный комментарий языка программирования (в данный момент это однострочный комментарий "//", используемый во множестве языков — C, C++, C#, Java,...), за которым следует последовательность спецсимволов, после которой — идентификатор и/или теги, за которыми может размещаться обычный человеческий комментарий. Я ввел три типа маркерных комментариев
- Комментарий для выделения произвольной области (area). Единственный тип, требующий «закрывающего» маркерного комментария. Начинается с "//<<" и заканчивается "//>>".
- Комментарий для обозначения произвольной строки в коде. Обозначается "//$$"
- Комментарий для выделения синтаксически корректного блока кода. Начинается с "//@@" и включает в себя расположенный ниже блок кода, ограниченный фигурными скобками "{" и "}", которые используются для блоков кода в большинстве си-подобных языков программирования. Реализован полноценный скобочный анализ — допускаются вложенные фигурные скобки, также парсер корректно пропускает фигурные скобки в строках и комментариях.
Далее, непосредственно за спецсимволами следует один или несколько идентификаторов, разделенных запятыми. Идентификаторы являются «тегами» и могут означать то, что захочет программист — признаки «изучено», «переписать», «разобраться», авторство кода, отношение кода к каким-то смысловым группам и т.д. Можно задать также один уникальный идентификатор — он ставится первым и отделяется от остальных двоеточием. При желании можно явно указать цвет фона фрагмента кода — в конце списка тегов ставится решетка, после которой указывается цвет в формате RGB (хотя этот способ не самый лучший — дальше будет рассказано о другом, более «правильном» способе). А в самом конце можно поставить пробел, после можно писать обычный человекочитаемый комментарий. Я старался выбирать синтаксис таким образом, чтобы он был максимально простым для быстрого ввода, не загромождал код и был удобным и для обычного комментирования.
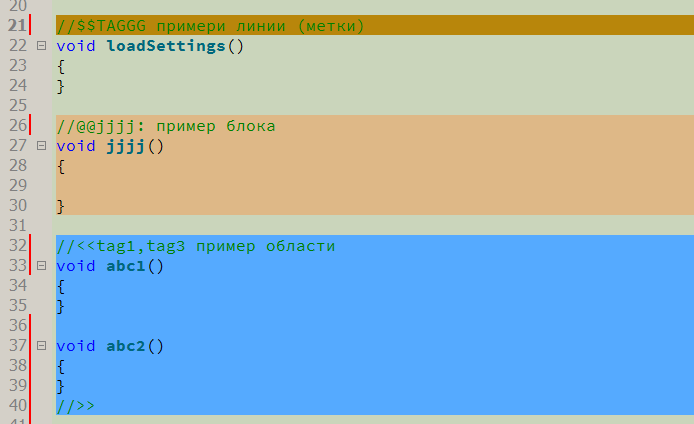
Хотя ручной ввод маркерных комментариев и возможен, предполагается использовать для этого специальные кнопки панели инструментов. Курсор устанавливается в нужную позицию кода и нажимается кнопка (или из меню выбирается один из последних вариантов).
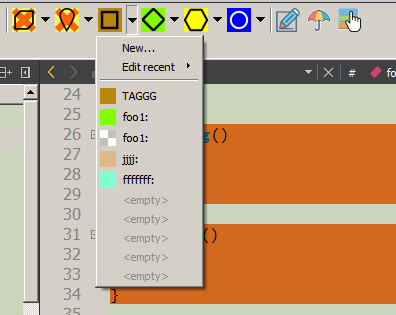
При необходимости будет открыт диалог ввода, куда можно ввести теги и идентификаторы маркерных комментариев, подробное описание, а также выбрать цвет фона. Эти данные будут занесены не только в код, но и в дерево «CRContentTree», отображаемое сбоку в панели деревьев (там где FileView, ClassView и т.д). Нужно отметить, что цвет фона может быть «прозрачным» — в этом случае используется цвет фона объемлющего блока (если таковой есть) или подсветка вообще не используется.
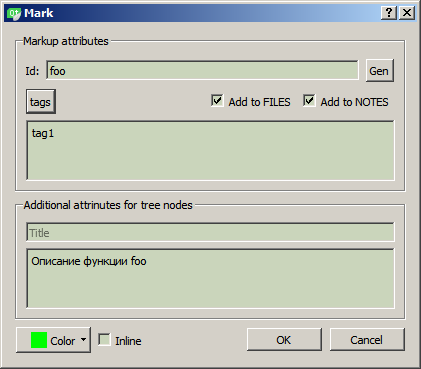
На данный момент дерево состоит из трех основных частей (узлов верхнего уровня): FILES, TAGS и NOTES (возможно, это не окончательное решение, т.к. концепция пока не вполне очевидна, равно как и удобство такой структуры).
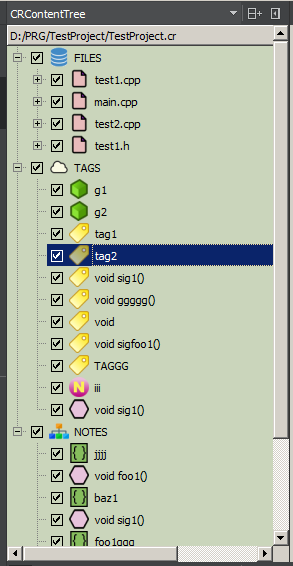
FILES — это файловая структура проекта, которая извлекается из файла проекта или из размещения исходников на диске. Файловые узлы создаются при начальной генерации дерева. Двойной щелчок на файловом узле привычно открывает файл в редакторе IDE. Можно указать добавление маркерного комментария в FILES — тогда дочерний узел появится у соответствующего файла. Именно сюда добавляются уникальные идентификаторы маркерных комментариев. Система проверяет уникальность идентификатора в пределах файлового узла дерева и дает возможность сгенерировать уникальное имя автоматически.
TAGS — это глобальное облако тегов проекта; теги не привязаны к файлу исходного кода и могут встречаться в любом файле проекта сколько угодно раз.
NOTES — это место для хранения узлов, сгруппированных произвольным образом и не привязанных к файловой структуре. Каждый узел содержит и путь к файлу, и идентификатор. Основное предназначение — создание пользовательских логических групп. Например, «все функции которые нужно переписать» или «все функции имеющие отношение к криптографии», или «последовательность функций сетевого обмена с сервером» (поскольку узлы в дереве упорядочены, то просто располагая узлы друг за другом, можно отображать любые последовательности).
У каждого узла дерева есть контекстное меню. Узел можно удалить (правда при этом не производится удаление маркерных комментариев из кода — пока я не уверен что это нужно), можно отредактировать. Предусмотрено добавление узлов, не связанных с маркерными комментариями: можно добавить например ссылку (Link). Двойной щелчок на таком узле откроет связанный ресурс в ассоциированной программе, например гиперссылку в браузере.
Каждый узел можно отключить, сняв соответствующую галочку в чекбоксе узла. Это приведет к тому что подсветка данного узла и всех дочерних узлов в коде будет снята. Таким образом, сняв например галочки с трех корневых узлов (FILES, TAGS и NOTES) можно отключить подсветку всех маркерных комментариев, кроме тех у которых цвет указан явно в коде (через решетку).
Двойной щелчок на узле открывает соответствующий файл в IDE и позиционирует курсор на соответствующую позицию кода. Для тегов, которые могут встречаться многократно, вместо открытия файла формируется список всех вхождений, который загружается в панель «CR Output», и уже двойным щелчком на соответствующей строке этого списка можно открыть файл и позицию в коде.
Каждый узел имеет поле для подробного описания (многострочный текст произвольной длины). Это описание загружается в область «CR Info» при простом выделении узла в дереве (одинарным щелчком мыши), а также установив курсор в любое место подсвеченной области в коде и нажав кнопку «Lookup» на панели инструментов. Всегда доступно редактирование, измененный текст сохраняется автоматически (по потере фокуса). Я подумываю о том, чтобы сделать в этой области поддержку формата Markdown, но пока руки до этого не дошли.
Не всегда хочется (или не всегда удобно) вставлять какие-либо комментарии в код. Поэтому вторая возможность — «сигнатуры», т.е. использование в качестве маркеров самого кода. Сигнатурой считается некоторая последовательрность токенов (без учета пробелов и переносов строк — то есть «foo(1,2,3)» и «foo ( 1, 2, 3 )» это одно и то же). Предусмотрено три типа сигнатур:
- блочные — подсвечивается блок, начинающийся с сигнатуры и включающий последовательность кода, заключенную в фигурные скобки.
- однострочные — подсвечивается вся строка с сигнатурой
- символьные — подсвечивается только последовательность сигнатуры. Такие сигнатуры удобно использовать для выделения отдельных имен — переменных, функций, классов.
Работа с сигнатурными блоками такая же, как и с маркерными. Точно также создаются узлы в дереве.
Если для маркерных узлов идентификатор и теги создавались отдельно, то для сигнатурных предлагается указать, как именно мы хотим рассматривать сигнатуру — как идентификатор (привязанный к файлу) или как глобальный тег. Например, для «имен» логично использовать именно режим тегов — тогда соответствующее имя будет подсвечено в коде по всему проекту.
Еще одна интересная возможность — построение покрытия кода. Специальная функция сканирует код и определяет места, не отмеченные вообще никак, и формирует список таких мест в «CR Output». При этом не учитываются пустые строки и комменитарии, т.е. в сканировании учитывается только значимый код. Двойным щелчком на строке списка можно перейти к этому месту в коде, и изучив его, отметить тем или иным способом.
Немного о формате хранения базы. Собственно в исходном коде хранятся только маркерные комментарии; содержимое дерева хранится в специальном xml-файле с расширением ".cr". Явной привязки файла базы к проектам нет, хотя при открытии проекта делается попытка открыть cr-файл с таким же именем, если ранее никакой cr-файл не был загружен.
Подведу итоги. В общем и целом я реализовал почти все то что хотел. Концепция новая и непривычная, и поэтому требуется некоторое время и обратная связь от пользователей, чтобы понять — что нужно развивать, а от чего возможно и отказаться. В попытке реализовать как можно больше возможностей что-то получилось слегка переусложненным, что неизбежно. Сам интерфейс возможно еще не устоявшийся и будет меняться. Но в целом, кажется, получилось неплохо.
Что в планах. Эта версия демонстрационная, во многом сырая и не предназначена для коммерческого использования. У меня есть мечта — сделать свой коммерческий продукт, приносящий пусть небольшой, но постоянный доход, достаточный чтобы заняться другими интересными проектами. Кроме того, некоторые вещи не адаптированы для коммерческого использования. Я представляю как подобную систему адаптировать для многопользовательского режима, с учетом того что код может правиться несколькими людьми одновременно, работающими через систему контроля версий. Также возможно посмотреть в сторону генерации привычной документации (html), возможно — инструментов для более глубокой интеграции с кодом (синтаксический анализ вместо лексического/скобочного, автоматическое получение списков классов и методов и преобразование их в узлы дерева). Разумеется требуется исправление багов (которые все еще есть) и улучшение фич. Ну и конечно я жду ваших комментариев с идеями и предложениями :)
На этом пока все (хотя остались еще некоторые мелкие фичи, о которых я не упомянул в статье — например я посчитал нужным добавить табы, так как без них совсем грустно — хотя для табов есть несколько плагинов; также на панель инструментов выведены некоторые основные команды Qt Creator, не имеющие отношения к плагину; и т.д.).
Ссылка для скачивания: https://www.dropbox.com/s/9iiw5x7elwy3tpe/CodeRainbow4.zip?dl=0
Системные требования: Windows, Qt Creator >= 4.5.1 собранный MSVC2015 32bit (это стандартная сборка, распространяемая на download.qt.io)
установка: распакуйте архив и скопируйте плагин в папку c:/Qt/Qt5.10.1/Tools/QtCreator/lib/qtcreator/plugins (это пример для стандартного размещения Qt, если у вас Qt установлен иначе или другая версия — путь будет другим) и (пере)запустите Qt Creator.
Комментарии (8)

phantom-code
01.10.2018 22:43Сам часто думаю о подобном инструменте. Я бы еще добавил возможность поиска по всем файлам, с предпросмотром и навигацией по результатам поиска (аналог Find in path в IDE от JetBrains или FileLocator Pro).
sentyaev
02.10.2018 01:59Инструмент пожет быть интересным. Вот только вчера проводил рефакторинг в достаточно большом проекте и нужно было найти все места использования определенной функциональности, причем из-за того, что это легаси, это не просто один класс или функция, а иногда и просто дублирующаяся логика. Т.е. задача была — найти все места, систематизировать как оно там работает, ну и после этого уже писать некий общий код.
Я использовал закладки, но вот выделение цветом думаю было бы намного интереснее.
Интересно, что в современных IDE кроме закладок можно использовать для такой задачи?
AlexZaharow
02.10.2018 09:03Честно говоря нахожу ваш подход сам по себе весьма спорным, разве что он подходит лично вам или для экспериментов. Поэтому интересно было бы где-то в статье указать были ли вами рассмотрены какие-то варианты проставления меток в исходном коде от других «производителей», чтобы отталкиваться от того, что искали по таким-то критериям, но не нашёл и вот теперь предлагаю мой вариант.
Я при недолгом копании в VS marketplace накопал следующие плагины:
https://marketplace.visualstudio.com/items?itemName=GilYoder.Remarker-18580
https://marketplace.visualstudio.com/items?itemName=OmarRwemi.BetterComments
Или вот плагин помощнее: https://marketplace.visualstudio.com/items?itemName=vs-publisher-1305558.VsTeXCommentsExtension

Можно использовать в комментариях LaTeX.
Вот плагин, воплощающий моё желание процентов на 90:
https://marketplace.visualstudio.com/items?itemName=MsBishop.ImageComments
Отображение картинок в комментариях! Его бы допилить, чтобы он из буфера обмена мог картинки вставлять и этот процент стал бы равен 95 (можно взять такой функционал из плагина markdown editor: marketplace.visualstudio.com/items?itemName=MadsKristensen.MarkdownEditor — он умеет вставлять картинки из буфера обмена).
Вот, например, сразу понятно откуда я беру строку сравнения:

Чуть немного по самим тегам. Поскольку в вас не очень сложные ключевые теги, то посоветую вам присмотреться к синтаксическим анализаторам, например, к такому компоненту как antlr. Выходной формат у него может быть написан на разных языках, а т.к. такие компоненты на содержат интерактива с экраном, то пихать их можно в самые разные языки и среды.
Надеюсь, вы поняли, что это комплимент ))) Поставить свою задачу и довести до логичного конца — круто!
werklop
Инструмент интересный, вы молодец.
Но позвольте внести субъективно-конструктивную критику:
1) Почему только Windows, а не Linux?
2) Исходя из п.1, расскажите, что будет, если я создам сигнатурный блок, а потом удалю метод, который был этим блоком?
3) Представьте, команда пользуется вашим инструментом и вдруг/постепенно что-то случается, вы перестаете поддерживать этот плагин или команда меняется и отказывается от его использования. По итогу, в коде будет куча комментариев с непонятной и ненужной информацией(раньше это были маркерные комментарии), эта куча будет пахнуть, причем неприятно. Вы задумывались над тем, чтобы хранить всю мета-информацию в отдельном файле/бд?
NeoCode Автор
Спасибо за отзыв!
1) если все будет хорошо, то будет и линукс, и другие среды разработки.
2) ничего не будет. Сигнатурная нода будет висеть в дереве. Я думал о том чтобы сделать функции поиска висячих узлов дерева и висячих маркерных комментариев в коде, с тем чтобы с ними можно было что-то сделать.
3) с ними можно обходиться как и с любыми комментариями в коде. Например какой нибудь тег TODO или FIXME — многие часто используют их без всяких маркерных комментариев, такие мешать не будут.
Вся метаинформация (дерево, подробные описания) и так хранится в отдельном xml-файле, а в перспективе наверное будет множество xml файлов — возможно по принципу «один файл исходника == один файл метаинформации» и еще дополнительные с общей метаинформацией). В исходниках только маркерные комментарии. Если ими не пользоваться, а ограничиться сигнатурами, то в исходниках вообще ничего не будет храниться. Добавил пару строк про это в статью.
werklop
эм… вы не путайте то, что де-факто является общеприменимым и то, что до селе никому не было известно(кастомные теги)
За ответы благодарю, удачи!
inkelyad
(3) На мой взгляд, проблемой не является. Инструмент предназначен для изучения и копания в коде, поэтому все маркерные комментарии либо вообще коммитится в основной код не будут, либо будут присутствовать только в отдельной ветке, посвященной какой-то задаче.