

Хочу поделиться очередным вечерним долгостроем, который показывает, что можно делать игры даже на слабом железе.
О том, что пришлось делать, как это было решено и, как сделать нечто большее, чем очередной клон Pong — добро пожаловать под кат.
Осторожно: большая статья, трафик и множественные кодовые вставки!
Коротко об игре
Shoot`em up! — теперь на AVR.
По факту это очередной шмап, так что в очередной раз главный герой
Вся игра написана на С и С++ без использования библиотеки Wire от Arduino.
В игре есть 4 корабля на выбор (последний доступен после прохождения), каждый со своими характеристиками:
- маневренность;
- прочность;
- мощность орудий.
Так же реализовано:
- цветная 2D графика;
- power up для вооружения;
- боссы в конце уровней;
- уровни с астероидами (и их анимация вращения);
- смена цвета фона на уровнях (а не только черный космос);
- движение звезд на фоне с разной скоростью (для эффекта глубины);
- подсчет очков и их сохранение в EEPROM;
- одинаковые звуки (выстрелы, взрывы и.т.д.);
- море одинаковых противников.
Платформа
Возвращение призрака.
Заранее уточню, что эту платформу стоит воспринимать как старую игровую консольпервоготретьего поколения (80-е года, shiru8bit).
Также под запретом аппаратные модификации над оригинальным железом, что гарантирует обеспечение запуска на любой другой идентичной плате сразу из коробки.
Данная игра была написана под плату Arduino Esplora, но перенос под GBA или любую другую платформу, думаю, не составит большого труда.
Тем не менее, даже на этом ресурсе эта плата освещалась всего пару раз, а другие платы и вовсе не удостоились упоминания, несмотря на достаточно большое сообщество у каждой:
- GameBuino META:
- Pokitto;
- makerBuino;
- Arduboy;
- UzeBox/FuzeBox;
- и многие другие.
Начну с того, чего на Esplora нет:
- много памяти (ROM 28кб, RAM 2,5кб);
- мощности (8 бит CPU на 16 МГц);
- DMA;
- знакогенератора;
- выделенных областей памяти или регистров спец. назначения (палитра, тайлы, фон и.т.д.);
- управления яркостью экрана (эх, столько эффектов в помойку);
- расширителей адресного пространства (мапперы);
- отладчика (
да кому он нужен, когда есть целый экран!).
Продолжу тем, что тут есть:
- аппаратный SPI (может работать на скорости F_CPU/2);
- экран на базе ST7735 160x128 1,44“;
- щепотка таймеров (всего 4шт.);
- щепотка GPIO;
- горсть кнопок (5шт. + двухосевой джойстик);
- немного датчиков (освещение, акселерометр, термометр);
излучатель раздраженияpiezo buzzer.
Как видно тут почти ничего нет. Неудивительно, что никто не захотел ничего с ней сделать кроме клона Pong и пары тройки игр за все это время!
Возможно дело в том, что писать под контроллер ATmega32u4 (и ему подобным) аналогично программированию под Intel 8051 (которому на момент публикации почти 40 лет), где нужно соблюдать огромное количество условий и прибегать к различным трюкам и ухищрениям.
Обработка периферии
Один на все!
Посмотрев схему, было отчетливо видно, что вся периферия подключена через расширитель GPIO (мультиплексор 74HC4067D далее MUX) и переключается при помощи GPIO PF4,PF5,PF6,PF7 или старшего ниббла PORTF, а считывание выхода MUX происходит на GPIO — PF1.
Очень удобно переключать вход, просто присваивая значения порту PORTF по маске и ни в коем случае не забыв младший ниббл:
uint16_t getAnalogMux(uint8_t chMux)
{
MUX_PORTX = ((MUX_PORTX & 0x0F) | ((chMux<<4)&0xF0));
return readADC();
}
Опрос нажатия кнопки:
#define SW_BTN_MIN_LVL 800
bool readSwitchButton(uint8_t btn)
{
bool state = true;
if(getAnalogMux(btn) > SW_BTN_MIN_LVL) { // low state == pressed
state = false;
}
return state;
}
Далее значения для порта F:
#define SW_BTN_1_MUX 0
#define SW_BTN_2_MUX 8
#define SW_BTN_3_MUX 4
#define SW_BTN_4_MUX 12
Добавив еще чуть-чуть:
#define BUTTON_A SW_BTN_4_MUX
#define BUTTON_B SW_BTN_1_MUX
#define BUTTON_X SW_BTN_2_MUX
#define BUTTON_Y SW_BTN_3_MUX
#define buttonIsPressed(a) readSwitchButton(a)
Можно смело опросить правую крестовину:
void updateBtnStates(void)
{
if(buttonIsPressed(BUTTON_A))
btnStates.aBtn = true;
if(buttonIsPressed(BUTTON_B))
btnStates.bBtn = true;
if(buttonIsPressed(BUTTON_X))
btnStates.xBtn = true;
if(buttonIsPressed(BUTTON_Y))
btnStates.yBtn = true;
}
Прошу заметить, что предыдущее состояние не сбрасывается, иначе можно упустить факт нажатия на клавишу (еще это работает как дополнительная защита от дребезга).
SFX
Жужжание бит.
Что если нет DAC, нет чипа от Yamaha, а есть только прямоугольник PWM в 1 бит для звука?
Сперва, кажется не так много, но, несмотря на это, здесь используется хитрый PWM для воссоздания техники «PDM audio» и с ее помощью можно делать такое.
Нечто подобное обеспечивает библиотека от Gamebuino и все что нужно, так это перенести генератор хлопков на другой GPIO и таймер на Esplora (timer4 и вывод OCR4D). Еще для корректной работы так же используется timer1 для формирования прерываний и перезагрузки регистра OCR4D новыми данными.
Движок Gamebuino использует звуковые паттерны (как в трекерной музыке), что неплохо экономит место, но все сэмплы нужно делать самому, библиотеки с готовыми тут нет.
Стоит упомянуть, что этот движок привязан к периоду обновления равным около 1/50 сек или 20 кадрам/сек.
Для создания звуковых паттернов, после прочтения Wiki по аудиоформату, набросал простую GUI на Qt. Оно не выводит звук точно также, но дает примерное понятие, как будет звучать паттерн и позволяет загружать, сохранять и редактировать его.
Графика
Бессмертный Pixelart.
Дисплей кодирует цвета в двух байтах (RGB565), но так как изображения в таком формате много займут, то все они для экономии места сделаны индексированными по палитре, которую я уже описывал не раз в своих ранних статьях.
В отличие от Famicom/ NES здесь ограничений цветов на изображение нет и доступных цветов в палитре больше.
Каждое изображение в игре представляет собой массив байт, в котором хранятся следующие данные:
- ширина, высота;
- маркер начала данных;
- словарь (если есть, но об этом чуть позже);
- полезная нагрузка;
- маркер конца данных.
Например, такая картинка (увеличена в 10 раз):

в коде будет выглядеть так:
pic_t weaponLaserPic1[] PROGMEM = {
0x0f,0x07,
0x02,
0x8f,0x32,0xa2,0x05,0x8f,0x06,0x22,0x41,0xad,0x03,0x41,0x22,0x8f,0x06,0xa2,0x05,
0x8f,0x23,0xff,
};
Куда же без выбора корабля в этом жанре? После сотни тестовых эскизов с разницей в пиксель остались только эти корабли для игрока:

Примечательно, что корабли не имеют пламени в тайлах(здесь оно для наглядности), оно накладывается отдельно для создания анимации выхлопа от двигателя.
Совершенно не стоит забывать про пилотов каждого из кораблей:

Вариация кораблей противника не слишком большая, но напомню, места не слишком много, так что вот три корабля:

Без каноничных бонусов в виде улучшения оружия и восстановления здоровья игрок долго не протянет:

Само собой с ростом мощности орудий меняется вид излучемых снарядов:

Как писалось в начале, в игре есть уровень с астероидами, он наступает после каждого второго босса. Интересен он тем, что там много движущихся и вращаются объектов разного размера. Помимо этого, когда игрок попадает по ним, они частично разрушаются, становясь меньше в размере.
Hint: Крупные астероиды приносят больше очков.



Для создания этой простой анимации достаточно 12 небольших изображений:

Они делятся по три на каждый размер (большой, средний и малый) и на каждый угол вращения нужно еще 4 повернутых на 0, 90, 180 и 270 градусов. В игре достаточно заменять указатель на массив с изображением через равный интервал тем самым создавая иллюзию вращения.
void rotateAsteroid(asteroid_t &asteroid)
{
if(RN & 1) {
asteroid.sprite.pPic = getAsteroidPic(asteroid);
++asteroid.angle;
}
}
void moveAsteroids(void)
{
for(auto &asteroid : asteroids) {
if(asteroid.onUse) {
updateSprite(&asteroid.sprite);
rotateAsteroid(asteroid);
...
Сделано это так только из-за отсутствия аппаратной возможности, а программная реализация вроде Affine transformation займет больше чем сами изображения и будет весьма медленной.

Можно заметить часть прототипов и то, что появляется только в титрах после прохождения игры.
Помимо простой графики для экономии места и добавления ретро-эффекта из шрифта были выкинуты строчные глифы и все глифы что до 30 и после 127 байта ASCII.
Важно!
Не забывайте, что const и constexpr на AVR вовсе не означает, что данные будут в памяти программ, здесь для этого нужно дополнительно использовать PROGMEM.
Это связано с тем, что ядро AVR имеет в основе Гарвардскую архитектуру, поэтому для доступа к данным нужны специальные опкоды для CPU.
Сжимая галактику
Самый простой способ упаковать — RLE.
Изучив пакуемые данные можно заметить, что старший бит в байте полезной нагрузки в диапазоне от 0x00 до 0x50 не используется. Это позволяет сложить данные и бит-маркер начала повтора (0x80), а следующим байтом указывать количество повторений, что позволяет упаковать серию из 257(+2 от того, что RLE из двух байт — глупо) одинаковых байт всего в два.
Реализация распаковщика и вывод на экран:
void drawPico_RLE_P(uint8_t x, uint8_t y, pic_t *pPic)
{
uint16_t repeatColor;
uint8_t tmpInd, repeatTimes;
alphaReplaceColorId = getAlphaReplaceColorId();
auto tmpData = getPicSize(pPic, 0);
tftSetAddrWindow(x, y, x+tmpData.u8Data1, y+tmpData.u8Data2);
++pPic; // make offset to picture data
while((tmpInd = getPicByte(++pPic)) != PIC_DATA_END) { // get color index or repeat times
if(tmpInd & RLE_MARK) { // is it color index?
tmpInd &= DATA_MARK; // get color index to repeat
repeatTimes = getPicByte(++pPic)+1; // zero RLE does not exist!
}
++repeatTimes;
// get color from colorTable by color index
repeatColor = palette_RAM[(tmpInd == ALPHA_COLOR_ID) ? alphaReplaceColorId : tmpInd];
do {
pushColorFast(repeatColor);
} while(--repeatTimes);
}
}
Главное не выводить изображение за границу экрана иначе будет мусор, так как проверки границ тут нет.
Тестовое изображение распаковывается за ~39мс. при этом, занимая 3040 байт, в то время как без сжатия оно бы заняло 11200 байт или 22400 байт без индексации.
Тестовое изображение (увеличено в 2 раза):

На изображении выше можно заметить interlace, но на экране он сглаживается аппаратно, создавая эффект аналогичный CRT и при этом значительно увеличивая степень сжатия.
RLE не панацея
Лечимся от дежавю.
Как известно RLE отлично комбинируется с LZ-подобными упаковщиками. На помощь пришла WiKi со списком методов компрессии. Толчком же стало видео от «GameHut» про разбор невозможного интро в Sonic 3D Blast.
Изучив множество упаковщиков(LZ77,LZW,LZSS,LZO,RNC и.т.д.) пришел к выводам, что их распаковщики:
- требуют много RAM для распакованных данных (хоть 64кб. и больше);
- громоздки и медлительны (некоторым нужно строить деревья Хаффмана на каждый субблок);
- обладают низкой степенью сжатия при малом окне (очень жесткие требования к RAM);
- имеют неоднозначности с лицензированием.
После месяцев тщетных адаптаций было решено доработать уже имеющийся упаковщик.
По аналогии с LZ-подобными упаковщиками для достижения максимального сжатия, был использован словарный доступ, но на байтовом уровне — наиболее часто повторяемые пары байт заменяются на один байт-указатель в словаре.
Но тут есть подвох, как отличить байт «сколько повторений» от «маркера словаря»?
После продолжительного сидения с бумажкой и магической игры с битами появилось сие:
- «маркер словаря» есть маркер RLE(0x80) + байт данных (0x50) + номер позиции в словаре;
- ограничить байт «сколько повторений» до размера «маркер словаря» — 1 (0xCF);
- словарь не может использовать значение 0xff (оно для маркера конца изображения).
Применив все это, мы получаем фиксированный размер словаря: не более 46 пар байт и сокращение RLE до 209 байт. Очевидно, что не все изображения можно так упаковать, но и больше они не станут.
В обоих алгоритмах структура упакованного изображения будет следующей:
- по 1 байту на ширину и высоту;
- 1 байт на размер словаря, он же маркер-указатель начала упакованных данных;
- от 0 до 92 байт словаря;
- от 1 до N байт упакованных данных.
Полученную утилиту упаковщика на D (pickoPacker) достаточно положить в папку с индексированными *.png файлами и запустить из терминала (или cmd). Если нужна помощь, то запустите с ключом «-h» или «--help».
После работы утилиты на выходе получаем *.h файлы, содержимое которых удобно перенести в нужное место в проекте (поэтому include защиты нет).
Перед распаковкой идет подготовка экрана, словаря и чтение начальных данных:
void drawPico_DIC_P(uint8_t x, uint8_t y, pic_t *pPic)
{
auto tmpData = getPicSize(pPic, 0);
tftSetAddrWindow(x, y, x+tmpData.u8Data1, y+tmpData.u8Data2);
uint8_t tmpByte, unfoldPos, dictMarker;
alphaReplaceColorId = getAlphaReplaceColorId();
auto pDict = &pPic[3]; // save dictionary pointer
pPic += getPicByte(&pPic[2]); // make offset to picture data
do {
unfoldPos = dictMarker = 0;
do {
if((tmpByte = getPicByte(++pPic)) != PIC_DATA_END) {
if(tmpByte < DICT_MARK) {
buf_packed[unfoldPos] = tmpByte;
} else {
dictMarker = 1;
setPicWData(&buf_packed[unfoldPos]) = getPicWData(pDict, tmpByte);
++unfoldPos;
}
++unfoldPos;
} else {
break;
}
} while((unfoldPos < MAX_UNFOLD_SIZE) //&& (unfoldPos)
&& ((tmpByte > DATA_MARK) || (tmpByte > MAX_DATA_LENGTH)));
if(unfoldPos) {
buf_packed[unfoldPos] = PIC_DATA_END; // mark end of chunk
printBuf_RLE( dictMarker ? unpackBuf_DIC(pDict) : &buf_packed[0] ); // V2V3 decoder
}
} while(unfoldPos);
}
Прочитанный кусок данных может быть запакован по словарю, так что проверяем и распаковываем:
inline uint8_t findPackedMark(uint8_t *ptr)
{
do {
if(*ptr >= DICT_MARK) {
return 1;
}
} while(*(++ptr) != PIC_DATA_END);
return 0;
}
inline uint8_t *unpackBuf_DIC(const uint8_t *pDict)
{
bool swap = false;
bool dictMarker = true;
auto getBufferPtr = [&](uint8_t a[], uint8_t b[]) {
return swap ? &a[0] : &b[0];
};
auto ptrP = getBufferPtr(buf_unpacked, buf_packed);
auto ptrU = getBufferPtr(buf_packed, buf_unpacked);
while(dictMarker) {
if(*ptrP >= DICT_MARK) {
setPicWData(ptrU) = getPicWData(pDict, *ptrP);
++ptrU;
} else {
*ptrU = *ptrP;
}
++ptrU;
++ptrP;
if(*ptrP == PIC_DATA_END) {
*ptrU = *ptrP; // mark end of chunk
swap = !swap;
ptrP = getBufferPtr(buf_unpacked, buf_packed);
ptrU = getBufferPtr(buf_packed, buf_unpacked);
dictMarker = findPackedMark(ptrP);
}
}
return getBufferPtr(buf_unpacked, buf_packed);
}
Теперь из полученного буфера уже знакомым образом распаковываем RLE и выводим на экран:
inline void printBuf_RLE(uint8_t *pData)
{
uint16_t repeatColor;
uint8_t repeatTimes, tmpByte;
while((tmpByte = *pData) != PIC_DATA_END) { // get color index or repeat times
if(tmpByte & RLE_MARK) { // is it RLE byte?
tmpByte &= DATA_MARK; // get color index to repeat
repeatTimes = *(++pData)+1; // zero RLE does not exist!
}
++repeatTimes;
++pData;
// get color from colorTable by color index
repeatColor = palette_RAM[(tmpByte == ALPHA_COLOR_ID) ? alphaReplaceColorId : tmpByte];
do {
pushColorFast(repeatColor);
} while(--repeatTimes);
}
}
Замена алгоритма на удивление не сильно повлияла на время распаковки и составляет ~47мс. Это почти на 8мс. дольше, но тестовое изображение занимает всего 1650 байт!
До последнего такта
Почти все можно сделать быстрее!
Несмотря на наличие аппаратного SPI ядро AVR доставляет море головной боли при его использовании.
Достаточно давно известно, что SPI на AVR помимо того что работает на скорости F_CPU/2, так и регистр данных всего на 1 байт (нет возможности загружать 2 байта сразу).
Более того почти весь код SPI на AVR который я встречал, работает по такой схеме:
- загрузить данные SPDR;
- опрашивать в цикле бит SPIF в SPSR.
Как можно заметить, непрерывной подачи данных, как это сделано на STM32, тут и не пахнет. Но, даже тут можно ускорить вывод обоих распаковщиков на ~3мс!
Открыв даташит и заглянув в раздел «Instruction set clocks» можно подсчитать затраты CPU при передаче байта по SPI:
- 1 такт на загрузку регистра новыми данными;
- 2 такта на бит (или 16 тактов на байт);
- 1 такт на магию тактовой линии (чуть позже о «NOP»);
- 1 такт на проверку статусного бита в SPSR (или 2 такта на ветвлении);
Итого для передачи одного пикселя (двух байт) нужно затратить 38 тактов или ~425600 тактов для тестового изображения (11200 байт).
Зная, что F_CPU == 16МГц получаем
Вот пример вывода с прерываниями:
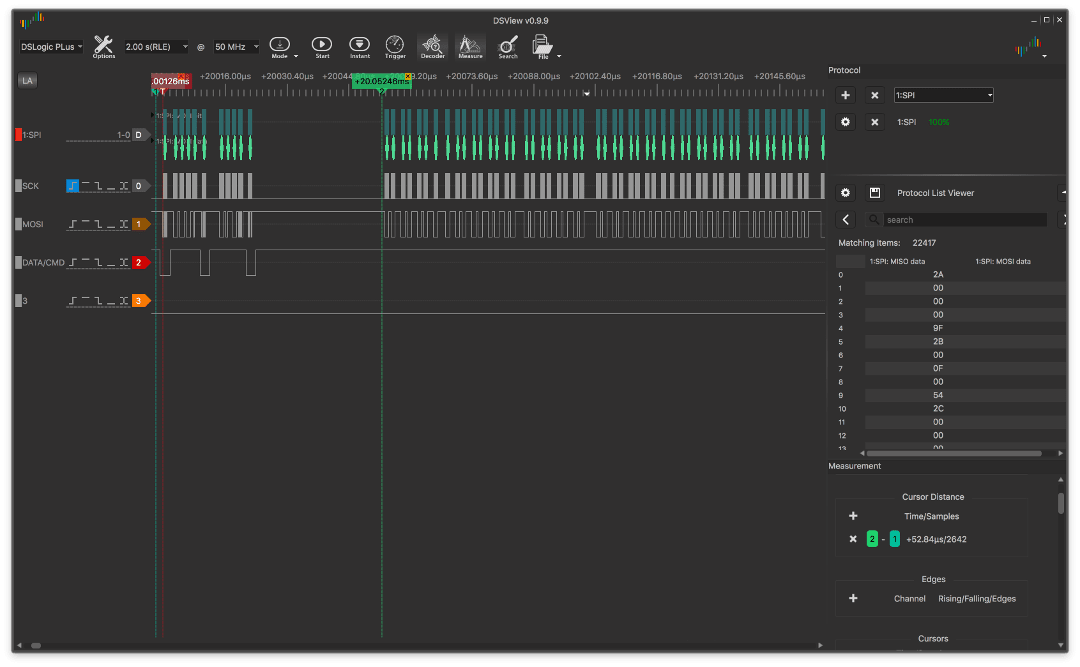
и без прерываний:

По графикам видно, что время между выставлением адресного окна в VRAM экрана и началом передачи данных в версии без прерываний меньше и разрывов между байтами во время передачи почти нет (график равномерный).
К сожалению, отключать прерывания при каждом выводе изображений нельзя, иначе сломаются звук и ядро всей игры (об этом позже).
Выше писалось про некий «магический NOP» для тактовой линии. Дело в том, что для стабилизации CLK и выставления флага SPIF нужен ровно 1 такт и к моменту чтения этого флага он уже выставлен, что позволяет избежать ветвления в 2 такта на инструкции «BREQ».
Вот пример без NOP:
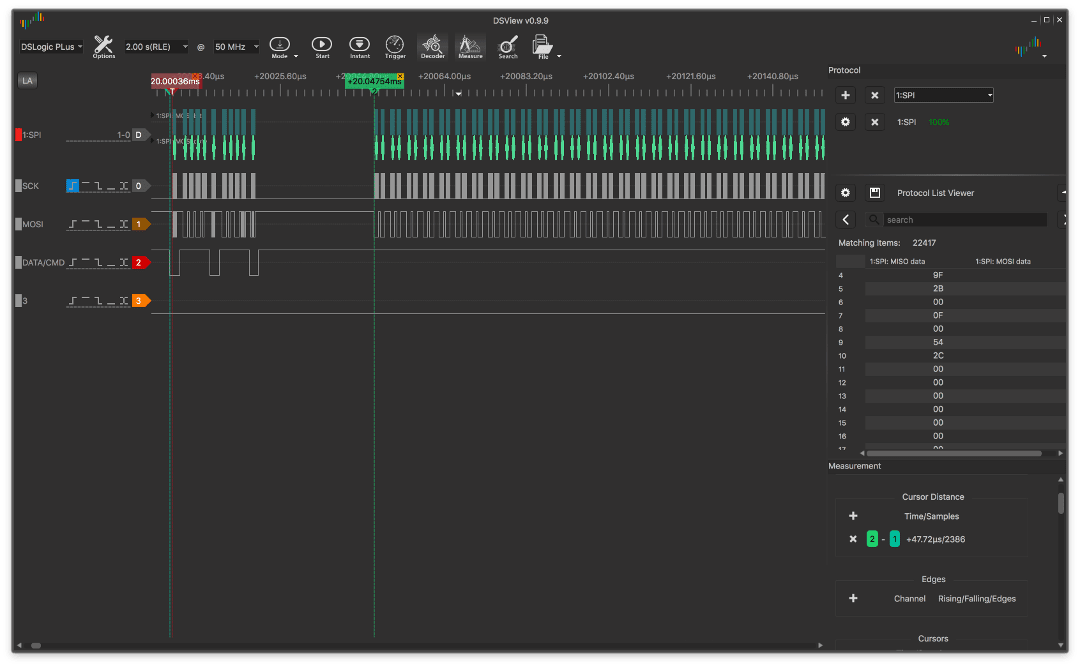
и с ним:

Разница кажется ничтожной, всего несколько микросекунд, но если взять другой масштаб:
Без NOP крупно:
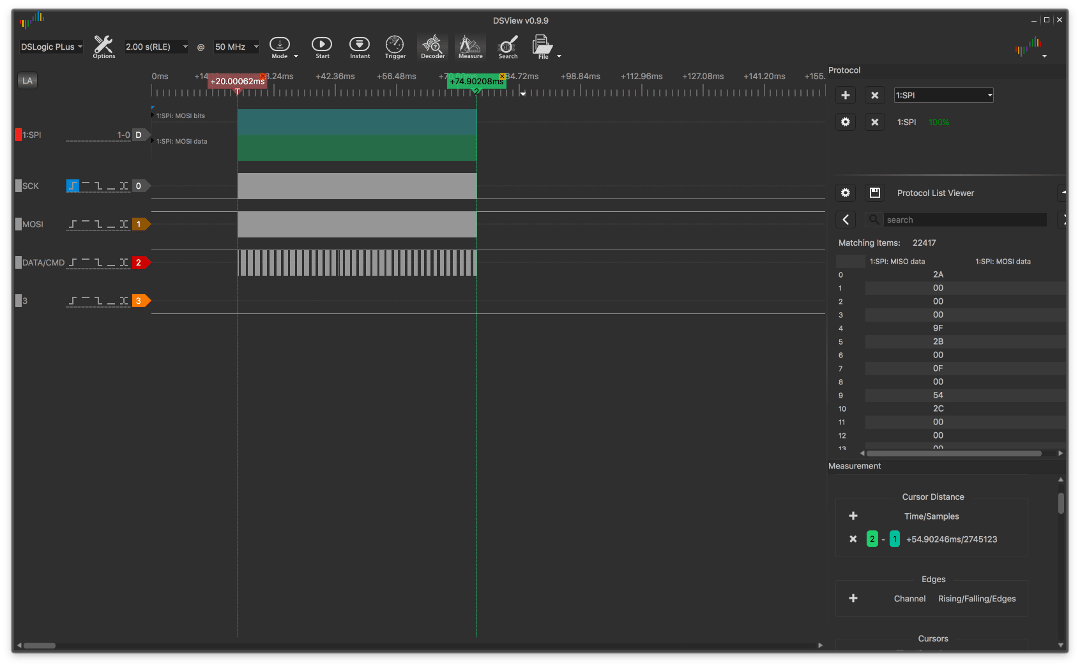
и с ним тоже крупно:

то разница становится куда заметнее, достигая ~4,3мс.
Теперь сделаем следующий грязный трюк:
Поменяем местами порядок загрузки и чтения регистров и можно не ждать на каждом втором байте флага SPIF, а проверять его только перед загрузкой первого байта следующего пикселя.
Применяем знания и разворачиваем функцию «pushColorFast(repeatColor);»:
#define SPDR_TX_WAIT(a) asm volatile(a); while((SPSR & (1<<SPIF)) == 0);
typedef union {
uint16_t val;
struct {
uint8_t lsb;
uint8_t msb;
};
} SPDR_t;
...
do {
#ifdef ESPLORA_OPTIMIZE
SPDR_t in = {.val = repeatColor};
SPDR_TX_WAIT("");
SPDR = in.msb;
SPDR_TX_WAIT("nop");
SPDR = in.lsb;
#else
pushColorFast(repeatColor);
#endif
} while(--repeatTimes);
}
#ifdef ESPLORA_OPTIMIZE
SPDR_TX_WAIT(""); // dummy wait to stable SPI
#endif
}
Несмотря на прерывание от таймера, использование трюка выше дает выигрыш почти на 6мс.:

Вот так простое знание железа позволяет выжать из него чуть больше и выводить нечто подобное:

Колизей коллизий
Битва коробок.
Для начала все множество объектов(корабли, снаряды, астероиды, бонусы) представляет собой структуры (спрайты) с параметрами:
- текущие координаты X,Y;
- новые координаты X,Y;
- указатель на изображение.
Поскольку изображение хранит ширину и высоту, то нет нужды дублировать эти параметры, более того, такая организация упрощает логику во многих аспектах.
Сам обсчет сделан до банального просто — на основе пересечения прямоугольников. Хоть оно недостаточно точное и не рассчитывает коллизии в будущем, но этого более чем достаточно.
Проверка происходит поочередно по осям X и Y. Благодаря этому отсутствие пересечения по оси X сокращает расчет коллизии.
Сперва проверяется правая сторона первого прямоугольника с левой стороной второго прямоугольника на предмет общей части оси X. В случае успеха идет аналогичная проверка для левой стороны первого и правой стороны второго прямоугольника.
После успешного обнаружения пересечений по оси X, идет проверка аналогичным образом для верхней и нижней сторон прямоугольников по оси Y.
Написанное выше выглядит куда проще чем кажется:
bool checkSpriteCollision(sprite_t *pSprOne, sprite_t *pSprTwo)
{
auto tmpDataOne = getPicSize(pSprOne->pPic, 0);
auto tmpDataTwo = getPicSize(pSprTwo->pPic, 0);
/* ----------- Check X position ----------- */
uint8_t objOnePosEndX = (pSprOne->pos.Old.x + tmpDataOne.u8Data1);
if(objOnePosEndX >= pSprTwo->pos.Old.x) {
uint8_t objTwoPosEndX = (pSprTwo->pos.Old.x + tmpDataTwo.u8Data1);
if(pSprOne->pos.Old.x >= objTwoPosEndX) {
return false; // nope, different X positions
}
// ok, objects on same X lines; Go next...
} else {
return false; // nope, absolutelly different X positions
}
/* ---------------------------------------- */
/* ----------- Check Y position ----------- */
uint8_t objOnePosEndY = (pSprOne->pos.Old.y + tmpDataOne.u8Data2);
if(objOnePosEndY >= pSprTwo->pos.Old.y) {
uint8_t objTwoPosEndY = (pSprTwo->pos.Old.y + tmpDataTwo.u8Data2);
if(pSprOne->pos.Old.y <= objTwoPosEndY) {
// ok, objects on same Y lines; Go next...
// yep, if we are here
// then, part of one object collide wthith another object
return true;
} else {
return false; // nope, different Y positions
}
} else {
return false; // nope, absolutelly different Y positions
}
}
Осталось добавить это в игру:
void checkInVadersCollision(void)
{
decltype(aliens[0].weapon.ray) gopher;
for(auto &alien : aliens) {
if(alien.alive) {
if(checkSpriteCollision(&ship.sprite, &alien.sprite)) {
gopher.sprite.pos.Old = alien.sprite.pos.Old;
rocketEpxlosion(&gopher); // now make gopher to explode \(^_^)/
removeSprite(&alien.sprite);
alien.alive = false;
score -= SCORE_PENALTY;
if(score < 0) score = 0;
}
}
}
}
Кривая Безье
Космические рельсы.
Как в любой другой игре с этим жанром корабли противника обязаны двигаться по кривым.
Было решено реализовать квадратичные кривые как самые простые для контроллера и этой задачи. Для них достаточно трех точек: начальной(P0), конечной(P2) и мнимой(P1). Первые две задают начало и конец линии, последняя точка описывает вид искривления.
Отличная статья по кривым.
Поскольку это параметрическая кривая Безье, то ей также необходим еще один параметр — количество промежуточных точек между начальной и конечной точками.
Итого получаем вот такую структуру:
typedef struct { // 7 bytes
position_t P0;
position_t P1;
position_t P2;
uint8_t totalSteps;
} bezier_t;
Нахождение точки для каждой координаты вычисляется вот такой формулой (thx Wiki):
B = ((1.0 — t)^2) P0 + 2t (1.0 — t) P1 + (t^2) P2,
t [>= 0 &&<= 1]
Долгое время ее реализация была решена в лоб без fixed point math:
...
float t = ((float)pItemLine->step)/((float)pLine->totalSteps);
pPos->x = (1.0 - t)*(1.0 - t)*pLine->P0.x + 2*t*(1.0 - t)*pLine->P1.x + t*t*pLine->P2.x;
pPos->y = (1.0 - t)*(1.0 - t)*pLine->P0.y + 2*t*(1.0 - t)*pLine->P1.y + t*t*pLine->P2.y;
...
Само собой так это оставлять нельзя. Ведь избавление от float могло бы не только дать улучшение по скорости, но и освободить ROM, так что были найдены следующие реализации:
- avrfix;
- stdfix;
- libfixmath;
- fixedptc.
Первая остается темной лошадкой, так как представляет собой скомпилированную библиотеку и возиться с дизассемблером не хотелось.
Второго кандидата из комплекта GCC изучить так же не вышло, так как используемый avr-gcc не пропатчен и тип «short _Accum» остался недоступен.
Третий вариант, несмотря на то, что обладает большим количеством мат. функций, имеет захардкоженные битовые операции на конкретных битах под формат Q16.16, что не дает возможности управлять значениями Q и I.
Последнюю можно считать упрощенной версией от «fixedmath», но главным достоинством является возможность управления не только размером переменной, которая по умолчанию 32бит с форматом Q24.8, но и значениями Q и I.
Результаты тестов при разных настройках:
| Тип | I.Q | Доп флаги | ROM байт | Tмс.* |
|---|---|---|---|---|
| float | - | - | 4236 | 35 |
| fixedmath | 16.16 | - | 4796 | 119 |
| fixedmath | 16.16 | FIXMATH_NO_OVERFLOW | 4664 | 89 |
| fixedmath | 16.16 | FIXMATH_OPTIMIZE_8BIT | 5036 | 92 |
| fixedmath | 16.16 | _NO_OVERFLOW + _8BIT | 4916 | 89 |
| fixedptc | 24.8 | FIXEDPT_BITS 32 | 4420 | 64 |
| fixedptc | 9.7 | FIXEDPT_BITS 16 | 3490 | 31 |
Из таблицы видно, что обе библиотеки заняли больше ROM и показали себя хуже чем скомпилированный код от GCC при использовании float.
Так же видно, что небольшая доработка под формат Q9.7 и уменьшение переменной до 16бит дало ускорение на 4мс. и освобождение ROM на ~50 байт.
Ожидаемым эффектом стало снижение точности и увеличением количества ошибок:

что в данном случае некритично.
Распределяя ресурсы
Работа во вторник и четверг всего на час.
В большинстве случаев все вычисления производятся каждый кадр, что не всегда оправдано, так как в кадре может не хватить времени на обсчет чего-либо и придется хитрить с чередованием, подсчетом кадров или их пропуском. Поэтому я пошел дальше — полностью отказался от кадровой привязки.
Разбив все на мелкие задачи, будь-то: обсчет коллизий, обработку звука, кнопок и вывод графики, достаточно выполнять их с определенным интервалом, а инертность глаза и возможность обновить только часть экрана сделают свое дело.
Управляем всем этим ни разу не ОС, а созданная мною пару лет назад стэйт машина или, проще говоря — не вытесняющий менеджер задач «tinySM».
Повторю причины использования его вместо любой из RTOS:
- ниже требования к ROM (~250 байт ядро);
- ниже требования к RAM (~9 байт на задачу);
- простой и понятный принцип работы;
- детерминированность поведения;
- тратится меньше процессорного времени;
- оставляет доступ к железу;
- не зависит от платформы;
- написан на С и легко обернуть в С++;
нужен был свой собственный велосипед.
Как я однажды уже описывал, задачи для него организуются в массив указателей на структуры, где хранится указатель на функцию и ее интервал вызова. Такая группировка упрощает описание игры отдельными этапами, что так же позволяет уменьшить количество ветвлений и динамически переключать набор задач.
Например, во время стартового экрана выполняется 7 задач, а во время игры их уже 20 (все задачи описаны в файле gameTasks.c).
Для начала нужно определить немного макросов для удобства:
#define T(a) a##Task
#define TASK_N(a) const taskParams_t T(a)
#define TASK(a,b) TASK_N(a) PROGMEM = {.pFunc=a, .timeOut=b}
#define TASK_P(a) (taskParams_t*)&T(a)
#define TASK_ARR_N(a) const tasksArr_t a##TasksArr[]
#define TASK_ARR(a) TASK_ARR_N(a) PROGMEM
#define TASK_END NULL
Объявление задачи на самом деле создание структуры, инициализация ее полей и помещение в ROM:
TASK(updateBtnStates, 25);
Каждая такая структура занимает 4 байта ROM (два на указатель и два на интервал).
Приятным бонусом макросов является то, что не выйдет создать более одной уникальной структуры для каждой функции.
Объявив нужные задачи, добавляем их в массив и так же помещаем в ROM:
TASK_ARR( game ) = {
TASK_P(updateBtnStates),
TASK_P(playMusic),
TASK_P(drawStars),
TASK_P(moveShip),
TASK_P(drawShip),
TASK_P(checkFireButton),
TASK_P(pauseMenu),
TASK_P(drawPlayerWeapon),
TASK_P(checkShipHealth),
TASK_P(drawSomeGUI),
TASK_P(checkInVaders),
TASK_P(drawInVaders),
TASK_P(moveInVaders),
TASK_P(checkInVadersRespawn),
TASK_P(checkInVadersRay),
TASK_P(checkInVadersCollision),
TASK_P(dropWeaponGift),
TASK_END
};
При выставлении флага USE_DYNAMIC_MEM в 0 для статической памяти главное не забыть инициализировать указатели на хранилище задач в RAM и задать максимальное их количество, которое будет исполняться:
...
tasksContainer_t tasksContainer;
taskFunc_t tasksArr[MAX_GAME_TASKS];
...
initTasksArr(&tasksContainer, &tasksArr[0], MAX_GAME_TASKS);
…
Постановка задач на выполнение:
...
addTasksArray_P(gameTasksArr);
…
Защита от переполнения хранилища управляется флагом USE_MEM_PANIC, если вы уверены в количестве задач, то для экономии ROM его можно отключить.
Осталось только запустить обработчик:
...
runTasks();
...
Внутри находится бесконечный цикл, который содержит основную логику. Попадая в него, также восстанавливается стэк благодаря «__attribute__ ((noreturn))».
В цикле поочередно перебираются элементы массива на необходимость вызова задачи по истечению интервала.
Отсчет интервалов сделан на основе timer0 в качестве системного с квантом в 1мс…
Несмотря на удачное распределение задач во времени, иногда происходило их наложение(jitter), что вызывало кратковременные замирания всего и вся в игре.
Определенно это нужно было решать, но как? О том, как все профилировалось в следующий раз, а пока попробуйте найти пасхалку в исходниках.
Конец
Вот так вот используя множество ухищрений (и еще много которых я не описал) и вышло все уместить в 24кб ROM и 1500 байт RAM. Если у Вас есть вопросы, буду рад на них ответить.
void invadersMagicRespawn(void)
{
for(auto &alien : aliens) {
if(!alien.alive) {
alien.respawnTime = 1;
}
}
}
Ничем не примечательно, правда?
void action()
{
tftSetTextSize(1);
for(;;) {
tftSetCP437(RN & 1);
tftSetTextColorBG((((RN % 192 + 64) & 0xFC) << 3), COLOR_BLACK);
tftDrawCharInt(((RN % 26) * 6), ((RN & 15) * 8), (RN % 255));
tftPrintAt_P(32, 58, (const char *)creditP0);
}
} a(void)
{
for(auto &alien : aliens) {
if(!alien.alive) {
alien.respawnTime = 1;
}
}
}
Получаем что «а(void)» не более чем пустышка, а «action()» вызывается только после входа в режим паузы больше чем 10 раз, счетчик скрыт в «disablePause();». Программа остается в бесконечном цикле и выводит случайные символы в случайном месте в стиле «Matrix Falling code» с текстом по центру. Вот такая простая обсурфикация занимающая всего 130 байт ROM.
Для сборки и запуска достаточно положить папку (или сделать линк) «esploraAPI» в «/arduino/libraries/».
Ссылки:
P.S. Увидеть и услышать как это все выглядит можно будет чуть позже когда сделаю приемлемое видео.
Комментарии (28)

smart_alex
05.10.2018 08:37Было бы неплохо, если бы вы выделили свою tinySM в отдельную библиотеку с простыми примерами использования на типовых задачах и написали статью с подробным разбором того что и как там работает внутри tinySM (именно внутри, с таймингами и прочим).
Понятно, что всю эту информацию можно получить проанализировав исходники игры, но так было бы проще и понятнее для большинства интересующихся вопросами многозадачности на микроконтроллерах.Bismuth208 Автор
05.10.2018 11:57Предложение отличное, но действительно ли это нужно? Да, это могло быть неплохим дополнением к статье про профилирование, но этих билиотек с десяток и более, даже Вы делали нечто идентичное и писали статью. Более того, у меня нет никакого желания вести монолог с сами знаете кем (хотя статьи у него отличные).

shiru8bit
05.10.2018 09:52Пара придирок. Консоли первого поколения — это как раз упомянутый Pong из начала 70-х, где не было даже процессора. А у AVR на 16 МГц вычислительной мощности на порядок больше, чем у консолей даже четвёртого поколения (SNES, Genesis), ближе к GBA. Памяти, конечно, очень мало, и с экраном на SPI тяжело. Но в целом на тех же ресурсах, как давно известно на примере UzeBox/FuzeBox, можно генерировать и RGB видеосигнал чисто в софте, и многоканальный звук, и ещё остаётся время для логики схожих по сложности игр.
Ну а так круто, дело хорошее. Нужно больше подобного творчества.Bismuth208 Автор
05.10.2018 11:59Благодарю, вполне обоснованные замечания, но осмелюсь заметить, что сравнение я приводил на аппаратном уровне, так как у первых консолей как раз ничего не было. Здесь же да, перегнул, будет ближе к 3 поколению, обязательно исправлю этот казус, но грубую вычислительную мощь без аппратных блоков трудно отнести к какому либо поколению.
Мне известно что можно выводить RGB сигнал, но зачастую там используют уже ассемблер, как например в этих играх:
Кто знает, может еще через года два будет будет от меня статья с очередной игрой, но уже с ассемблером. Уже сейчас я недалёко от этого. Например, когда игрался с SPI удавалось сделать много интересных эффектов изменяя время передачи данных и накладывая байты друг на друга.
Благодаря доступу к железу можно точно указывать паузу между байтами:
inline void sendData8Dirt_SPI1(uint8_t bData, uint8_t len) { // +2 mov cycles asm volatile( "out %[spdr], %[bData] \n" // 1 - transmit byte "dec %[len] \n" // 1 - decrease count "brne .-4 \n" // 1 -false 2-true; is it 0? : [bData] "=r" (bData), [len] "=r" (len) : "[bData]" (bData), "[len]" (len), [spdr] "I" (_SFR_IO_ADDR(SPDR)) // SPI data register : "cc" // indicates what flags may be clobbered ); }u-235
06.10.2018 15:08Когда подключал дисплей от Siemens s65 тоже пытался по всякому оптимизировать отправку данных по SPI. И тоже стал отправлять второй байт и не дожидаться завершения отправки. А сейчас пришла такая идея. Что если в pushColorFast разрешать прерывание от SPI отправлять только старший байт, а младший сохранять в переменной. В прерывании отсылать младший байт из переменной и запрещать это прерывание. По идеи, 16 тактов ожидания для отправки второго байта заменяются на 6 тактов прерывания.
Ну и вместо PROGMEM проще использовать __flash
8street
05.10.2018 10:59Интересно, сколько fps выдает игра?
Bismuth208 Автор
05.10.2018 12:00Нисколько — это просто нельзя подстчитать, читайте внимательнее пожалуйста:
Поэтому я пошел дальше — полностью отказался от кадровой привязки.
8street
05.10.2018 13:00Извиняюсь, конечно, за мой прокол, но дисплей, дисплей-то spi. А это накладывает некоторые ограничения на передачу большого фреймбуффера. Но поскольку отрисовывается только изменяемая область — я не в понятках. Хоть скажите, играется динамично, как на nes или медленнее?
Bismuth208 Автор
05.10.2018 14:14На Famicom/NES есть как динамичные игры так и медленные, так что сложно сказать. В целом по ощущениям и времени отклика можно сказать что игра работатет около 20-25 кадров/с.
О ценить частота кудров тут куда сложнее чем на Sega Saturn с ее двумя видеопроцессорами для 2D и 3D графики.
seri0shka
05.10.2018 11:20Вы просили критики, их есть у меня! )
На самом деле, я просто поражён. Во-первых, настолько детальная проработка мелочей (это как о проекте, так и о статье). Во-вторых, даже не представлял, что возможно столько вытянуть из ATmega32. Материала в статье хватило бы на десяток статей, многие вопросы можно рассматривать совершенно обособленно. Хотя видеть всё в составе одного проекта намного интереснее. Для меня это одна из лучших статей за всё время чтения Хабра и ГТ.
Жаль, не смогу попробовать, для меня дороговаты комплектующие.Мне б попроще ардуинку и дисплейчик от Нокиа. Или даже ТВ-выход (монохромный), что уже никому не интересно, как показывает практика.
Ещё на что обратил внимание, нет ни одной ошибки в тексте, очень часто этим страдают даже очень хорошие специалисты. Вроде и стараешься не обращать внимание (мы ведь не за это статьи оцениваем), но раздражает порой очень.
Ещё возник такой вопрос: сколько раз перезаливали прошивку? У меня на некоторые проекты (на несколько порядков проще вашего) уходит по несколько десятков перезаписей, ресурс некоторых подопытных уже должен подходить к концу.Bismuth208 Автор
05.10.2018 12:00Как заметили выше — это не максимум на что способен этот контроллер.
Ошибок много, позже подкорректирую, также заметил, что не все поместил из запланированого.
Буду добавлять еще, так что: «stay tuned».
Практика показывает, что когда разработчику не хватает ресурсов он берёт камень посильнее, а делать нечто большее чем вывод монохромного текста по RCA и умещать невмещаемое уже совершенно другой уровень.
Сложно сказать сколько раз переливал за год с лишним разработки, но около 30 раз в неделю точно.seri0shka
05.10.2018 13:18когда разработчику не хватает ресурсов он берёт камень посильнее
Вот этим мне и не нравится современная электроника. Я, наоборот, люблю использовать по-максимуму, это ведь намного интересней. Хотя экономически может быть и нецелесообразно, учитывая затраченное время.
30 раз в неделю за год- это уже 1500 раз, живучий, в интернете пишут про ресурс в 1000 записей.
Manwe_SandS
05.10.2018 16:43Вы меня извините (не хочу, чтобы меня заминусовали), но ошибки есть: «также» только один раз написано правильно, во всех остальных местах — неправильно. И деепричастный оборот употреблён с ошибкой. Давно заметил, что авторам технических текстов необходим корректор. Очень мало кто способен соблюсти все нормы русского литературного языка. А ведь такие статьи — литература, хочется получать эстетическое удовольствие от из чтения.
По содержанию статья отличная, автору большое уважение за подсчёт тактов и прочие демосценерские трюки. Сейчас тоже пишу игру на очень слабом железе, прекрасно понимаю героизм автора :)seri0shka
05.10.2018 16:57Да, если всматриваться, ошибки можно заметить, но они не «режут глаз». Многим действительно нужен хороший корректор. Вы про свою игру напишите. Маловато игр на Хабре.
Bismuth208 Автор
05.10.2018 22:33Благодарю за замечания, нашел машину с вордом (у меня стоит LibreOffice) и прогнал через него. Что нашел — исправил.
Process0169
05.10.2018 12:000,0000000625 наносекунд? Что-то очень быстро для 16Мгц
Bismuth208 Автор
05.10.2018 12:02Хм, вроде не ошибся в подсчете или Вас смутило, что выглядит как ничтожная доля наносекунды, а не секунды?
Process0169
05.10.2018 12:10+1Может я что-то не понимаю, но 0.0000000625 наносекунд это
0.0000000000000000625 секунд или 160 000 000 МГц
Имелось ввиду наверное все таки 6.25нс :)
Costic
05.10.2018 14:31У вас и с мс (миллисекундами), кажется, не корректно. Наверное мкс должно быть.
madf
05.10.2018 17:02Супер! Только:
SPI на AVR помимо того что работает на скорости F_CPU/2, так и регистр данных всего на 1 байт (нет возможности загружать 2 байта сразу).
XMega тоже AVR и подобное реализуемо. :)
Punk_Joker
Наконец-то реально интересная статья по МК, а не очередное элементарное поделие на Андуинке
iliasam
На самом деле, в хабе «Программирование микроконтроллеров» в последнее время не так уж и много статей про Ардуины.