
Еще один доклад с Pixonic DevGAMM Talks — на этот раз от наших коллег из PanzerDog. Lead Software Engineer компании Павел Платто разобрал мета-сервер игры с сервисно-ориентированной архитектурой, рассказал, какие решения и технологии были выбраны, что и как у них масштабируется, и с какими трудностями пришлось столкнуться. Текст доклада, слайды и ссылки на другие выступления с митапа, как всегда, под катом.
Для начала хочу продемонстрировать небольшой трейлер нашей игры:
Доклад будет состоять из 3-х частей. В первой я расскажу о том, какие технологии мы выбрали и почему, во второй — о том, как устроен наш мета-сервер, а в третей расскажу о различной вспомогательной инфраструктуре, которую мы используем, и о том, как мы реализовали обновление без даунтайма.

Технологический стек
Мета-сервер хостится на Amazon и написан на языке Elixir. Это функциональный язык программирования с акторной моделью вычислений. Так как у нас нет Ops'ов, оперированием занимаются программисты, и большая часть инфраструктуры описана в виде кода с помощью Terraform от HashiCorp.
На данный момент Tacticool находится на стадии открытого бета-теста, мета-сервер находится в разработке чуть больше года и в эксплуатации почти год. Давайте посмотрим, с чего все начиналось.

Когда я пришел в компанию, мы уже имели базовую функциональность, реализованную в виде монолита на смеси С/С++ и хранимках PostageSQL. Данная реализация имела определенные проблемы.
Во-первых, из-за низкоуровневости С было довольно много трудноуловимых багов. Например, у некоторых игроков намертво зависал матчмейкинг из-за некорректного обнуления массива перед его повторном использовании. Разумеется, найти взаимосвязь этих двух событий было довольно сложно. И так как в коде повсеместно модифицировалось состояние из нескольких потоков, не обошлось без Race conditions.
О параллельной обработке большого количества задач тоже не могло быть и речи, потому что сервер запускал на старте около 10 процессов-воркеров, которые блокировались при запросах к Амазону или базе данных. И даже если забыть об этих блокирующих запросах, сервис начинал рассыпаться на паре сотен соединений, которые не выполняли никаких операций, кроме пинга. К тому же сервис невозможно было горизонтально масштабировать.
Через пару недель, потраченных на поиск и исправление наиболее критических багов, мы решили, что проще переписать все с нуля, чем пытаться исправить все недостатки текущего решения.
А когда начинаешь с нуля, есть смысл попробовать подобрать язык, который поможет избежать часть предыдущих проблем. У нас было три кандидата:

C# попал в список «по знакомству», т.к. клиент и игровой сервер у нас написаны на Unity и больше всего опыта в команде было именно с этим языком программирования. Go и Elixir рассматривали, потому что это современные и достаточно популярные языки, созданные для разработки серверных приложений.
Проблемы предыдущей итерации помогли нам определить критерии для оценки кандидатов.
Первым критерием было удобство работы с асинхронными операциями. В C# удобная работа с асинхронными операциями появилась не с первой попытки. Это привело к тому, что мы имеем «зоопарк» решений, которые, на мой взгляд, все равно стоят немного сбоку. В Go и Elixir данная проблема была учтена при проектировании этих языков, они оба используют легковесные потоки (в Go — это горутины, в Elixir — процессы). Эти потоки имеют намного меньший оверхед, чем системные, и так как мы можем создавать их десятками и сотнями тысяч, то нам не жалко их заблокировать.
Вторым критерием были возможности по работе с конкурентными процессами. C# из коробки не предлагает ничего другого, кроме тредпулов и общей памяти, доступ к которой нужно защищать с помощью различных примитивов синхронизаций. Go имеет менее подверженную к ошибкам модель в виде горутин и каналов. Elixir же предлагает акторную модель без разделяемой памяти с общением посредством обмена сообщениями. Отсутствие разделяемой памяти позволило реализовать в рантайме такие полезные для конкурентной среды исполнения технологии, как честная вымещающая многозадачность и сборка мусора без остановок мира.
Третьим критерием являлась доступность инструментов для работы с неизменяемыми типами данных. Весь мой опыт разработки показал, что довольно большая часть багов связаны с некорректным изменением данных. Решение для этого существует давным-давно — неизменяемые типы данных. В C# такие типы данных можно создавать, но ценой тонны бойлерплейта. В Go это вообще невозможно. А в Elixir все типы данных являются неизменяемыми.
И последним критерием было количество специалистов. Тут результаты очевидны. В конечном итоге мы остановили свой выбор на Elixir.
С выбором хостинга все было значительно проще. Игровые сервера у нас уже хостились в Amazon GameLift, кроме того Amazon предлагает большое количество сервисов, которые позволили бы нам сократить время на разработку.
Мы полностью «сдались» облаку и не разворачиваем сами никаких сторонних решений — базы данных, очереди сообщений — всем этим за нас управляет Amazon. На мой взгляд, это единственное решение для небольшой команды, которая хочет разрабатывать онлайн-игру, а не инфраструктуру для нее.
С выбором технологий разобрались, перейдем к тому, как работает мета-сервер.
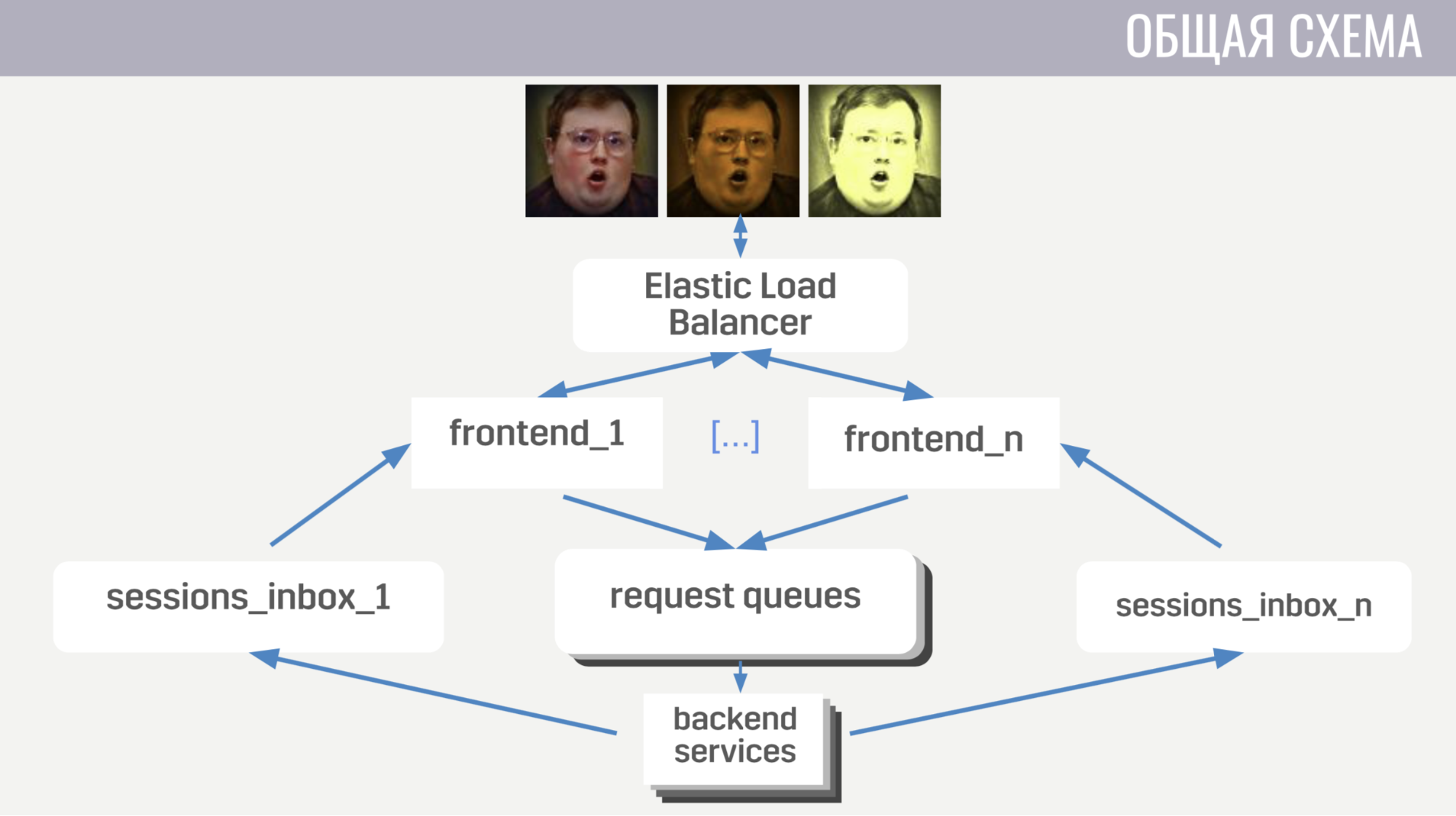
В общих чертах: клиенты подключаются к балансировщику нагрузки в Amazon посредством веб-сокетных соединений; эти соединения балансировщик раскидывает между несколькими инстансами фронтенда, фронтенд отдает запросы клиентов бэкендам. Но фронтенд и бэкенед общаются опосредованно, через очереди сообщений. Для каждого типа сообщений существует отдельная очередь и фронтенд по типу сообщений определяет, куда его записать, а бэкенды слушают эти очереди.
Чтобы бэкенд мог отправить на клиент ответ на запрос, либо какое-то событие, каждому фронтенду прикреплена отдельная очередь (специально для него выделенная). И в каждом запросе бэкенд получает идентификатор фронтенда, чтобы определить, в какую очередь нужно записать ответ. Если ему нужно послать событие, то он обращается к базе данных, чтобы узнать, к какому инстансу фронтенда подключен клиент.
С общей схемой всё, перейдем к деталям.

Во-первых, расскажу о некоторых особенностях клиент-серверного взаимодействия. Мы используем свой бинарный протокол, потому что он достаточно эффективный и позволяет экономить трафик. Во-вторых, при любых операциях с аккаунтом, которые его изменяют, сервер отсылает на клиент не эти изменения, а полную (обновленную) версию данного аккаунта. Это чуть менее эффективно, но все равно занимает не так много места и значительно упрощает нам жизнь как на клиенте, так и на сервере. Также фронтенд следит за тем, чтобы клиент выполнял не более одного запроса за раз. Это позволяет отлавливать баги на клиенте, например, когда он переходит на другой экран до того, как игрок увидит результат выполнения предыдущей операции.
Теперь немного о том, как устроен фронтенд.

Фронтенд это, по сути, веб-сервер, который слушает веб-сокетные соединения. Для каждой сессии создается по два процесса. Первый процесс обслуживает само веб-сокетное соединение, а второй является стейт-машиной, которая описывает текущее состояние клиента. На основе этого состояния он определяет допустимость запросов от клиента. Например, почти все запросы нельзя выполнять до тех пор, пока не завершится авторизация. Так как на фронтенде нет никакого состояния, кроме этих сессий, то очень легко добавлять новые инстансы фронтенда, но немного сложнее удалять старые. Перед удалением нужно дать всем клиентам завершить свои текущие запросы и попросить их переподключиться к другому инстансу.
Теперь о том, как выглядит бэкенд. На данный момент он состоит из пяти сервисов.
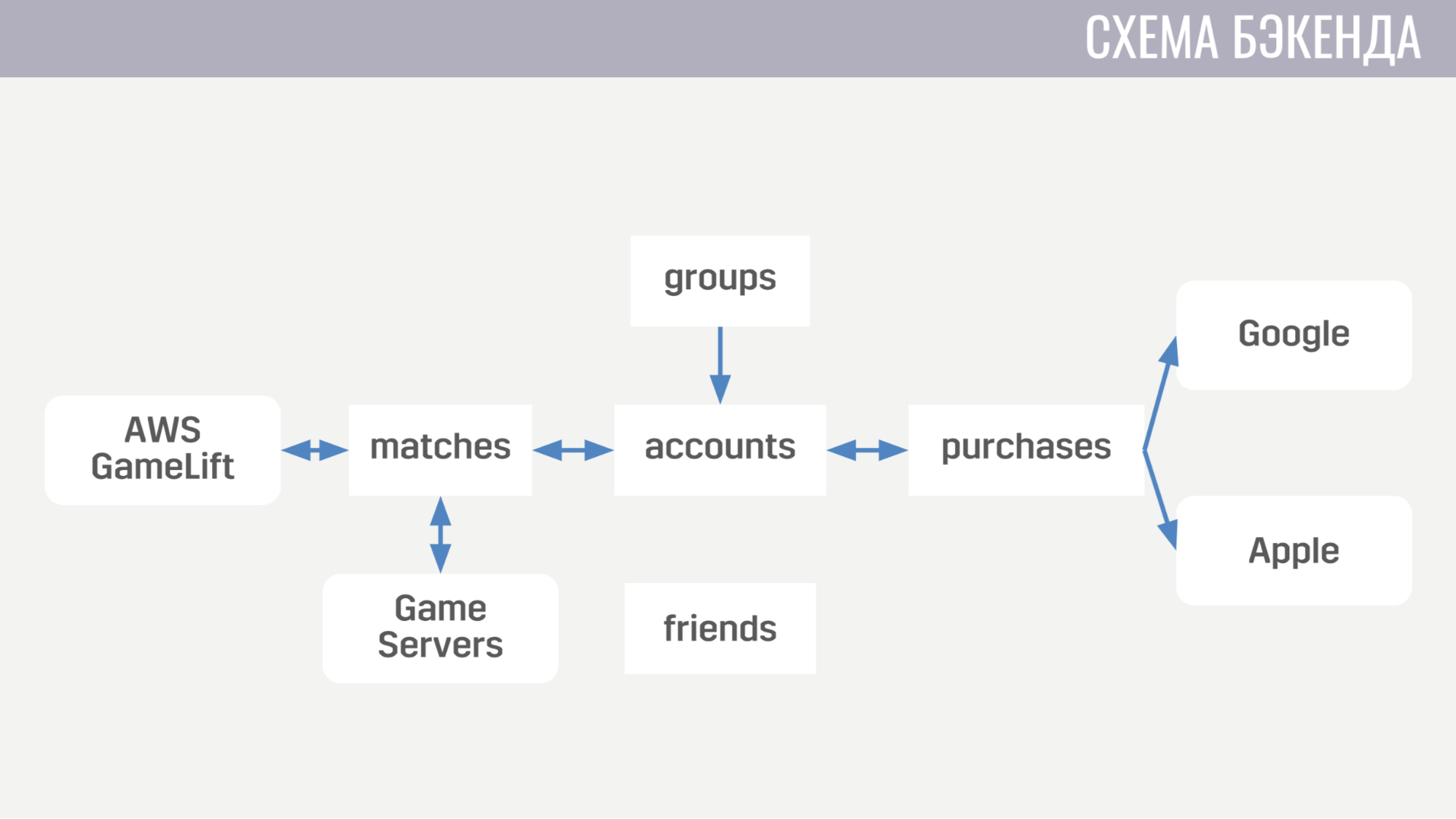
Первых занимается всем, что связано с аккаунтами — от покупок за внутриигровую валюту до выполнения квестов. Второй работает со всем, что связано с матчами — он напрямую взаимодействует с GameLift’ом и игровыми серверами. Третий сервис занимается покупками за реальные деньги. Четвертый и пятый отвечают за социальные взаимодействия — один за друзей, другой за игру в пати.
Каждый из бэкенд-сервисов с архитектурной точки зрения выглядит абсолютно идентично. Они представляют из себя набор пайплайнов, каждый из которых обрабатывает один тип сообщений. Пайплайн состоит из двух элементов: producer и consumer.

Единственная задача producer’а — вычитывать сообщения из очереди. Поэтому он реализован полностью в общем виде и для каждого пайплайна нам нужно только указать, сколько есть producer’ов, из какой очереди читать и сколько consumer’ов будет обслуживать каждый producer. Consumer же реализуется для каждого пайплайна отдельно и представляет из себя модуль с единственной обязательной функцией, которая принимает одно сообщение, выполняет всю необходимую работу и возвращает список сообщений, которые нужно отправить в другие сервисы клиенту, либо на игровой сервер. Также producer реализует back pressure, чтобы при резком возрастании количества сообщений не произошло перегрузки, и запрашивает сообщений не больше, чем у него есть свободных consumer’ов.
Бэкенд-сервисы не содержат никакого состояния, поэтому нам легко добавлять и удалять старые инстансы. Единственное, что нужно сделать перед удалением, это попросить producer’ов перестать вычитывать новые сообщения и дать consumer’ам немного времени закончить обработку активных сообщений.
Как происходит взаимодействие с GameLift’ом. GameLift состоит из нескольких составных частей. Из тех, что используем мы, это матчмейкер FlexMatch, очередь размещений, которая определяет, в каком конкретно регионе разместить игровую сессию с данными игроками, и сами флиты, состоящие из игровых серверов.
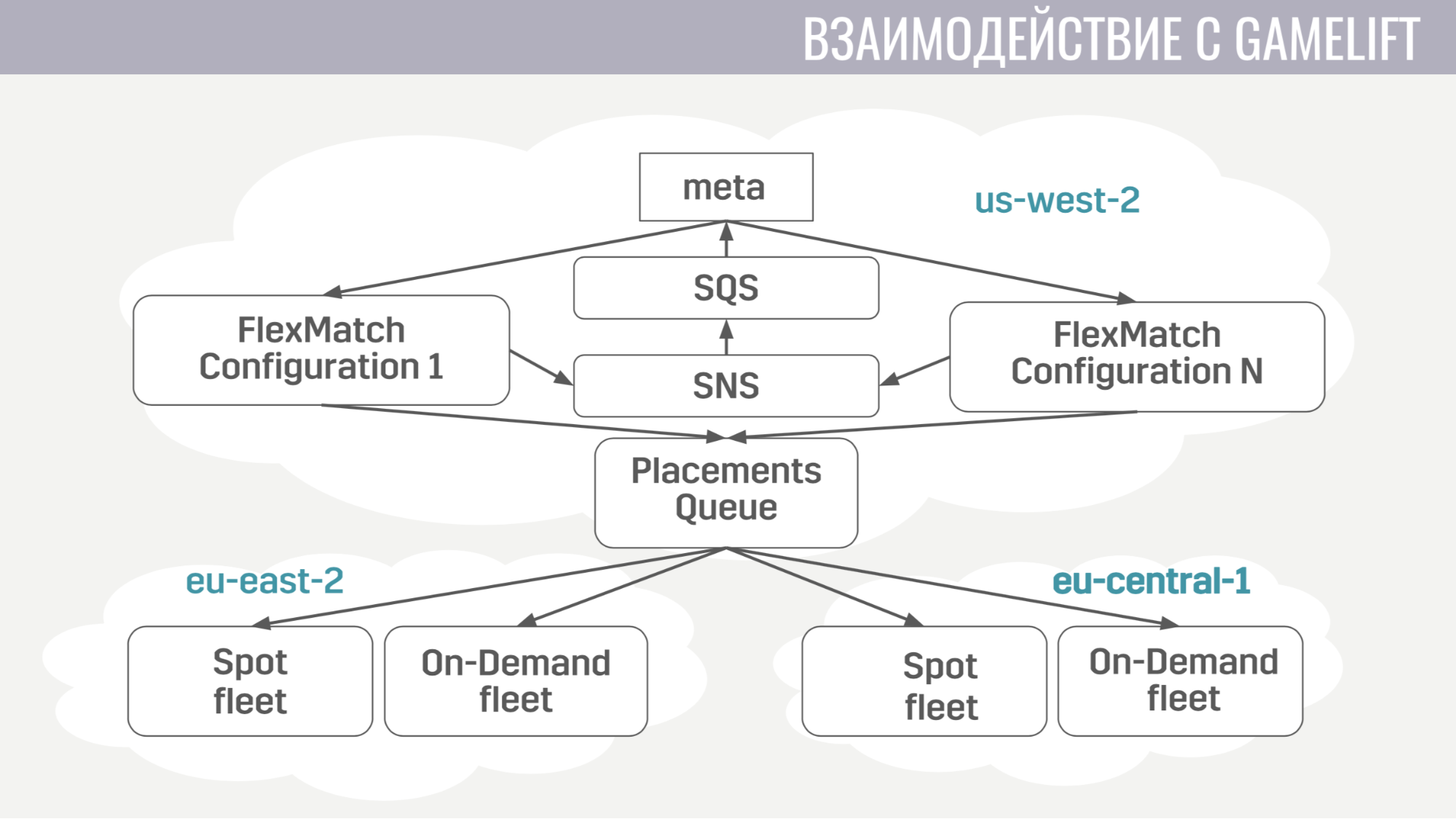
Как происходит это взаимодействие. Мета напрямую общается только с матчмейкером, отсылает ему запросы на поиск матча. А он уведомляет мету обо всех событиях в ходе матчмейкинга через те же самые очереди сообщений. И как только он находит подходящую группу игроков, чтобы начать матч, он отправляет заявку в очередь размещений, которая в свою очередь подбирает для них сервер.
Взаимодействие меты с игровым сервером предельно простое. Игровому серверу нужна информация об аккаунтах, ботах и карте, и всю эту информацию мета отсылает в очередь, созданную специально для этого матча в единственном сообщении.

А игровой сервер при активации начинает слушать эту очередь и получает все необходимые ему данные. В конце матча он отсылает его результаты в общую очередь, которую слушает мета.
Теперь перейдем к дополнительной инфраструктуре, которую мы используем.

Развертывание сервисов происходит достаточно просто. Все они работают в docker-контейнерах, а для оркестрации мы используем Amazon ECS. Он значительно проще, чем Kubernetes, разумеется, менее навороченный, но те задачи, которые нам от него нужны, он выполняет. А именно: масштабирование сервисов и rolling-релизы, когда нам нужно залить какой-нибудь багфикс.
И последний сервис, который мы также используем — это AWS Fargate. Он избавляет нас от необходимости самостоятельно управлять кластером машин, на которых запускаются наши docker-контейнеры.

В качестве основного хранилища мы используем DynamoDB. В первую очередь мы выбрали ее за то, что ее очень легко эксплуатировать и масштабировать. Также в качестве дополнительного хранилища мы используем Redis, посредством управляемого сервиса Amazon ElasiCache. Его мы используем для задачи глобального рейтинга игроков и для кэширования основных данных об аккаунте в тех ситуациях, когда нам нужно вернуть на клиент данные сразу о сотнях игровых аккаунтов (например, в той же таблице рейтингов, либо в списке друзей).
Для хранения конфигов, мета-геймплейных механик, описания оружия, героев и т.д. мы используем JSON-файл, который подкладываем в образы сервисов, которым он нужен. Потому что нам значительно проще выкатить новую версию сервиса с обновлёнными данными (если какой-то баг обнаружился), чем делать решение, которое будет динамически в рантайме обновлять эти данные из какого-то внешнего хранилища.
Для логирования и мониторинга мы используем довольно много сервисов.
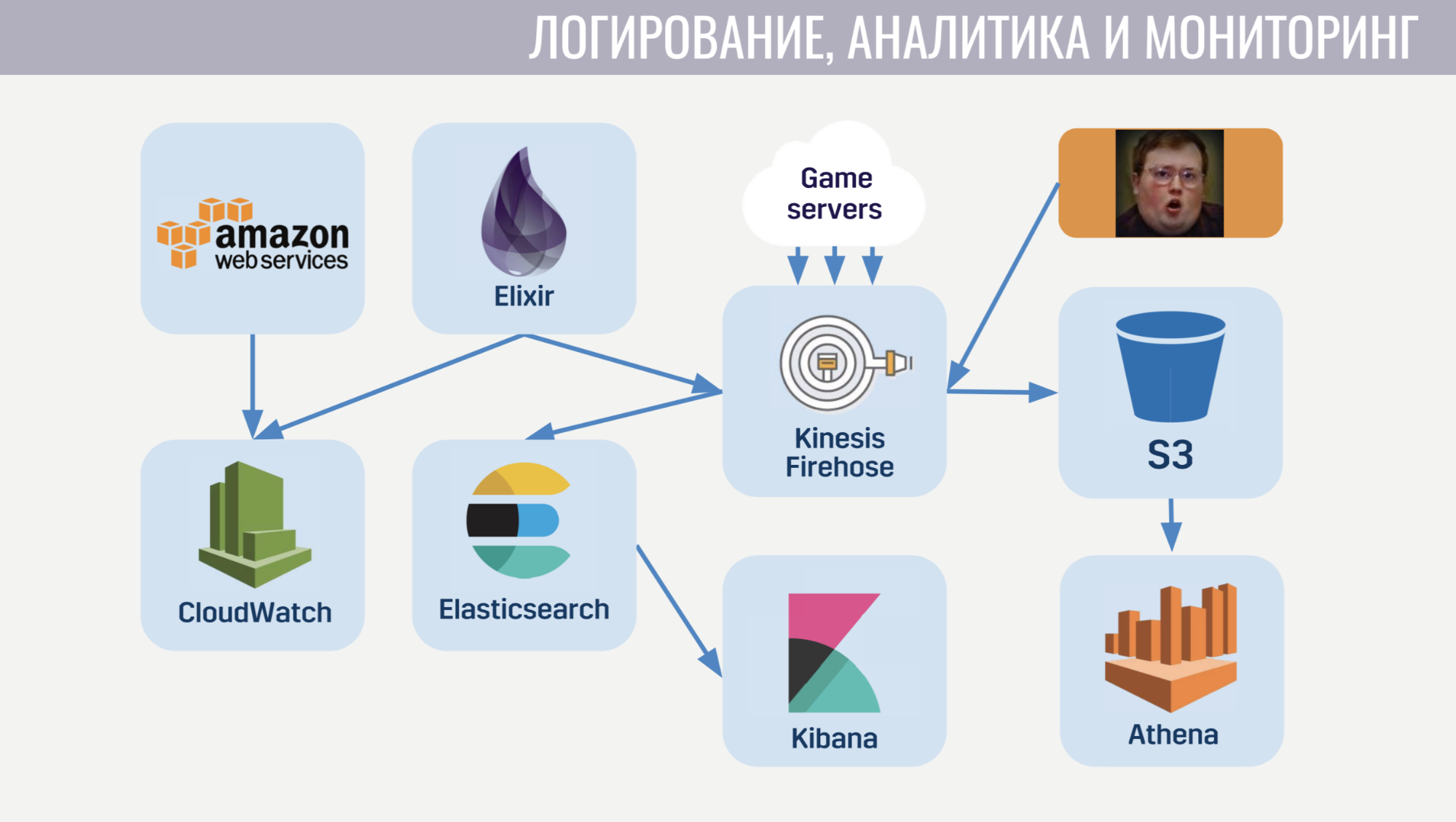
Начнем с CloudWatch. Это сервис мониторинга, в который стекаются метрики со всех амазоновских сервисов. Поэтому мы решили туда же слать метрики с нашего мета-сервера. А для логирования мы используем общий подход и на клиенте и на игровом сервере и на мета-сервере. Все логи мы шлем в амазоновский сервис Kinesis Firehose, который в свою очередь перекладывает их в Elasticseach и S3.
В Elasticseach мы храним только относительно свежие данные и с помощью Kibana ищем ошибки, решаем часть задач игровой аналитики и строим операционные дашборды, например, с графиком CCU и количество новых установок. В S3 лежат все исторические данные и используем мы их посредством сервиса Athena, который предоставляет SQL-интерфейс поверх данных в S3.
Теперь немного о том, как мы используем Terraform.

Terraform — это инструмент, который позволяет декларативно описать инфраструктуру и при каком-либо изменении описания, он автоматически определяет те действия, которые необходимо выполнить, чтобы привести вашу инфраструктуру к обновленному виду. Таким образом, имея единое описание, мы получаем практически идентичное окружение для staging и production. Также эти окружения полностью изолированы, потому что они разворачиваются под разными аккаунтами. Единственным существенным недостатком Terraform для нас является неполная поддержка GameLift.
Еще расскажу о том, как мы реализовали обновление без даунтайма.

Когда мы выпускаем обновления, мы поднимаем копию большинства ресурсов: сервисов, очередей сообщений, некоторых табличек в базе данных. И те игроки, которые скачают новую версию игры, будут подключаться к этому обновленному кластеру. Но те игроки, которые еще не обновились, могут продолжать некоторое время играть на старой версии игры, подключаясь к старому кластеру.
Как мы это реализовали. Во-первых, с помощью механизма модулей в Terraform. Мы выделили модуль, в котором описали все версионируемые ресурсы. И эти модули можно импортировать несколько раз, с разными параметрами. Соответственно, для каждой версии мы импортируем этот модуль, указав номер этой версии. Так же нам помогло отсутствие схемы в DynamoDB, что дает возможность выполнять миграции данных не во время апдейта, а откладывать их для каждого аккаунта до тех пор, пока его владелец не залогинится в новой версии игры. А в балансировщике мы просто указываем для каждой версии правила, чтобы он знал, куда роутить игроков с разными версиями.
Напоследок пара вещей, которым мы научились. Во-первых, конфигурация всей инфраструктуры должна быть автоматизирована. Т.е. некоторые вещи мы какое-то время настраивали руками, но рано или поздно ошибались в настройках, из-за чего случались факапы.

И последнее — нужно для каждого элемента вашей инфраструктуры иметь либо реплику, либо запасную копию. И если для чего-то это не сделать, то именно эта вещь нас когда-нибудь подведет.
— А вас не смущает, что автоскейлинг может заскейлиться слишком сильно вверх из-за какой-то ошибки и вы попадете на очень большие деньги?
— Для автоскейлинга все равно выставляются лимиты. Мы не будем ставить слишком большой лимит, чтобы не попасть на большие деньги. Это основное решение + мониторинг. Можно выставить алерты, если что-то заскейлилось слишком сильно.
— В данный момент у вас какие лимиты? Относительно текущей инфраструктуры в процентном соотношении.
— Сейчас у нас этап открытого бета-теста в 11 странах, поэтому не такой большой CCU, чтобы хоть как-то оценивать. Сейчас инфраструктура слишком overprovisioned для того количества людей, которые у нас есть.
— И лимитов пока нет?
— Есть, просто они в 10-100 раз больше, чем ССU у нас. Меньше не сделать.
— Вы рассказали, что у вас очереди между фронт- и бэкендом — это очень необычно. Почему не на прямую?
— Мы хотели stateless-сервисы, чтобы легко реализовать механизм бэкпреше, чтобы сервис не запрашивал больше сообщений, чем у него есть свободных обработчиков. Также, например, когда обработчик фейлится, очередь выдаст это же самое сообщение другому обработчику — возможно у него что-то получится.
— А очередь персистится как-то?
— Да. Это амазоновский сервис SQS.
— По поводу очередей: сколько у вас создается каналов во время игры? У вас на каждый матч какое-то количество каналов?
— Создается относительно немного. Большая часть очередей, например, очереди запросов — статические. Есть очередь запросов на авторизацию, есть очередь на старт матча. Из динамически создаваемых очередей у нас есть только очереди для каждого фронтенда (он при запуске создает для входящих сообщений для клиентов) и для каждого матча мы создаем по одной очереди. В этом сервисе это почти ничего не стоит, у них любой запрос биллится одинаково. Т.е. любой запрос к SQS (создать очередь, прочитать из нее что-то) стоит одинаково и при этом мы для экономии не удаляем эти очереди, они сами потом удалятся. А то, что они существуют, нам ничего не стоит.
— В данной архитектуре это для вас лимитом не будет являться?
— Нет.
Для начала хочу продемонстрировать небольшой трейлер нашей игры:
Доклад будет состоять из 3-х частей. В первой я расскажу о том, какие технологии мы выбрали и почему, во второй — о том, как устроен наш мета-сервер, а в третей расскажу о различной вспомогательной инфраструктуре, которую мы используем, и о том, как мы реализовали обновление без даунтайма.
Технологический стек
Мета-сервер хостится на Amazon и написан на языке Elixir. Это функциональный язык программирования с акторной моделью вычислений. Так как у нас нет Ops'ов, оперированием занимаются программисты, и большая часть инфраструктуры описана в виде кода с помощью Terraform от HashiCorp.
На данный момент Tacticool находится на стадии открытого бета-теста, мета-сервер находится в разработке чуть больше года и в эксплуатации почти год. Давайте посмотрим, с чего все начиналось.
Когда я пришел в компанию, мы уже имели базовую функциональность, реализованную в виде монолита на смеси С/С++ и хранимках PostageSQL. Данная реализация имела определенные проблемы.
Во-первых, из-за низкоуровневости С было довольно много трудноуловимых багов. Например, у некоторых игроков намертво зависал матчмейкинг из-за некорректного обнуления массива перед его повторном использовании. Разумеется, найти взаимосвязь этих двух событий было довольно сложно. И так как в коде повсеместно модифицировалось состояние из нескольких потоков, не обошлось без Race conditions.
О параллельной обработке большого количества задач тоже не могло быть и речи, потому что сервер запускал на старте около 10 процессов-воркеров, которые блокировались при запросах к Амазону или базе данных. И даже если забыть об этих блокирующих запросах, сервис начинал рассыпаться на паре сотен соединений, которые не выполняли никаких операций, кроме пинга. К тому же сервис невозможно было горизонтально масштабировать.
Через пару недель, потраченных на поиск и исправление наиболее критических багов, мы решили, что проще переписать все с нуля, чем пытаться исправить все недостатки текущего решения.
А когда начинаешь с нуля, есть смысл попробовать подобрать язык, который поможет избежать часть предыдущих проблем. У нас было три кандидата:
- C#;
- Go;
- Elixir.
C# попал в список «по знакомству», т.к. клиент и игровой сервер у нас написаны на Unity и больше всего опыта в команде было именно с этим языком программирования. Go и Elixir рассматривали, потому что это современные и достаточно популярные языки, созданные для разработки серверных приложений.
Проблемы предыдущей итерации помогли нам определить критерии для оценки кандидатов.
Первым критерием было удобство работы с асинхронными операциями. В C# удобная работа с асинхронными операциями появилась не с первой попытки. Это привело к тому, что мы имеем «зоопарк» решений, которые, на мой взгляд, все равно стоят немного сбоку. В Go и Elixir данная проблема была учтена при проектировании этих языков, они оба используют легковесные потоки (в Go — это горутины, в Elixir — процессы). Эти потоки имеют намного меньший оверхед, чем системные, и так как мы можем создавать их десятками и сотнями тысяч, то нам не жалко их заблокировать.
Вторым критерием были возможности по работе с конкурентными процессами. C# из коробки не предлагает ничего другого, кроме тредпулов и общей памяти, доступ к которой нужно защищать с помощью различных примитивов синхронизаций. Go имеет менее подверженную к ошибкам модель в виде горутин и каналов. Elixir же предлагает акторную модель без разделяемой памяти с общением посредством обмена сообщениями. Отсутствие разделяемой памяти позволило реализовать в рантайме такие полезные для конкурентной среды исполнения технологии, как честная вымещающая многозадачность и сборка мусора без остановок мира.
Третьим критерием являлась доступность инструментов для работы с неизменяемыми типами данных. Весь мой опыт разработки показал, что довольно большая часть багов связаны с некорректным изменением данных. Решение для этого существует давным-давно — неизменяемые типы данных. В C# такие типы данных можно создавать, но ценой тонны бойлерплейта. В Go это вообще невозможно. А в Elixir все типы данных являются неизменяемыми.
И последним критерием было количество специалистов. Тут результаты очевидны. В конечном итоге мы остановили свой выбор на Elixir.
С выбором хостинга все было значительно проще. Игровые сервера у нас уже хостились в Amazon GameLift, кроме того Amazon предлагает большое количество сервисов, которые позволили бы нам сократить время на разработку.
Мы полностью «сдались» облаку и не разворачиваем сами никаких сторонних решений — базы данных, очереди сообщений — всем этим за нас управляет Amazon. На мой взгляд, это единственное решение для небольшой команды, которая хочет разрабатывать онлайн-игру, а не инфраструктуру для нее.
С выбором технологий разобрались, перейдем к тому, как работает мета-сервер.
В общих чертах: клиенты подключаются к балансировщику нагрузки в Amazon посредством веб-сокетных соединений; эти соединения балансировщик раскидывает между несколькими инстансами фронтенда, фронтенд отдает запросы клиентов бэкендам. Но фронтенд и бэкенед общаются опосредованно, через очереди сообщений. Для каждого типа сообщений существует отдельная очередь и фронтенд по типу сообщений определяет, куда его записать, а бэкенды слушают эти очереди.
Чтобы бэкенд мог отправить на клиент ответ на запрос, либо какое-то событие, каждому фронтенду прикреплена отдельная очередь (специально для него выделенная). И в каждом запросе бэкенд получает идентификатор фронтенда, чтобы определить, в какую очередь нужно записать ответ. Если ему нужно послать событие, то он обращается к базе данных, чтобы узнать, к какому инстансу фронтенда подключен клиент.
С общей схемой всё, перейдем к деталям.
Во-первых, расскажу о некоторых особенностях клиент-серверного взаимодействия. Мы используем свой бинарный протокол, потому что он достаточно эффективный и позволяет экономить трафик. Во-вторых, при любых операциях с аккаунтом, которые его изменяют, сервер отсылает на клиент не эти изменения, а полную (обновленную) версию данного аккаунта. Это чуть менее эффективно, но все равно занимает не так много места и значительно упрощает нам жизнь как на клиенте, так и на сервере. Также фронтенд следит за тем, чтобы клиент выполнял не более одного запроса за раз. Это позволяет отлавливать баги на клиенте, например, когда он переходит на другой экран до того, как игрок увидит результат выполнения предыдущей операции.
Теперь немного о том, как устроен фронтенд.
Фронтенд это, по сути, веб-сервер, который слушает веб-сокетные соединения. Для каждой сессии создается по два процесса. Первый процесс обслуживает само веб-сокетное соединение, а второй является стейт-машиной, которая описывает текущее состояние клиента. На основе этого состояния он определяет допустимость запросов от клиента. Например, почти все запросы нельзя выполнять до тех пор, пока не завершится авторизация. Так как на фронтенде нет никакого состояния, кроме этих сессий, то очень легко добавлять новые инстансы фронтенда, но немного сложнее удалять старые. Перед удалением нужно дать всем клиентам завершить свои текущие запросы и попросить их переподключиться к другому инстансу.
Теперь о том, как выглядит бэкенд. На данный момент он состоит из пяти сервисов.
Первых занимается всем, что связано с аккаунтами — от покупок за внутриигровую валюту до выполнения квестов. Второй работает со всем, что связано с матчами — он напрямую взаимодействует с GameLift’ом и игровыми серверами. Третий сервис занимается покупками за реальные деньги. Четвертый и пятый отвечают за социальные взаимодействия — один за друзей, другой за игру в пати.
Каждый из бэкенд-сервисов с архитектурной точки зрения выглядит абсолютно идентично. Они представляют из себя набор пайплайнов, каждый из которых обрабатывает один тип сообщений. Пайплайн состоит из двух элементов: producer и consumer.
Единственная задача producer’а — вычитывать сообщения из очереди. Поэтому он реализован полностью в общем виде и для каждого пайплайна нам нужно только указать, сколько есть producer’ов, из какой очереди читать и сколько consumer’ов будет обслуживать каждый producer. Consumer же реализуется для каждого пайплайна отдельно и представляет из себя модуль с единственной обязательной функцией, которая принимает одно сообщение, выполняет всю необходимую работу и возвращает список сообщений, которые нужно отправить в другие сервисы клиенту, либо на игровой сервер. Также producer реализует back pressure, чтобы при резком возрастании количества сообщений не произошло перегрузки, и запрашивает сообщений не больше, чем у него есть свободных consumer’ов.
Бэкенд-сервисы не содержат никакого состояния, поэтому нам легко добавлять и удалять старые инстансы. Единственное, что нужно сделать перед удалением, это попросить producer’ов перестать вычитывать новые сообщения и дать consumer’ам немного времени закончить обработку активных сообщений.
Как происходит взаимодействие с GameLift’ом. GameLift состоит из нескольких составных частей. Из тех, что используем мы, это матчмейкер FlexMatch, очередь размещений, которая определяет, в каком конкретно регионе разместить игровую сессию с данными игроками, и сами флиты, состоящие из игровых серверов.
Как происходит это взаимодействие. Мета напрямую общается только с матчмейкером, отсылает ему запросы на поиск матча. А он уведомляет мету обо всех событиях в ходе матчмейкинга через те же самые очереди сообщений. И как только он находит подходящую группу игроков, чтобы начать матч, он отправляет заявку в очередь размещений, которая в свою очередь подбирает для них сервер.
Взаимодействие меты с игровым сервером предельно простое. Игровому серверу нужна информация об аккаунтах, ботах и карте, и всю эту информацию мета отсылает в очередь, созданную специально для этого матча в единственном сообщении.
А игровой сервер при активации начинает слушать эту очередь и получает все необходимые ему данные. В конце матча он отсылает его результаты в общую очередь, которую слушает мета.
Теперь перейдем к дополнительной инфраструктуре, которую мы используем.
Развертывание сервисов происходит достаточно просто. Все они работают в docker-контейнерах, а для оркестрации мы используем Amazon ECS. Он значительно проще, чем Kubernetes, разумеется, менее навороченный, но те задачи, которые нам от него нужны, он выполняет. А именно: масштабирование сервисов и rolling-релизы, когда нам нужно залить какой-нибудь багфикс.
И последний сервис, который мы также используем — это AWS Fargate. Он избавляет нас от необходимости самостоятельно управлять кластером машин, на которых запускаются наши docker-контейнеры.
В качестве основного хранилища мы используем DynamoDB. В первую очередь мы выбрали ее за то, что ее очень легко эксплуатировать и масштабировать. Также в качестве дополнительного хранилища мы используем Redis, посредством управляемого сервиса Amazon ElasiCache. Его мы используем для задачи глобального рейтинга игроков и для кэширования основных данных об аккаунте в тех ситуациях, когда нам нужно вернуть на клиент данные сразу о сотнях игровых аккаунтов (например, в той же таблице рейтингов, либо в списке друзей).
Для хранения конфигов, мета-геймплейных механик, описания оружия, героев и т.д. мы используем JSON-файл, который подкладываем в образы сервисов, которым он нужен. Потому что нам значительно проще выкатить новую версию сервиса с обновлёнными данными (если какой-то баг обнаружился), чем делать решение, которое будет динамически в рантайме обновлять эти данные из какого-то внешнего хранилища.
Для логирования и мониторинга мы используем довольно много сервисов.
Начнем с CloudWatch. Это сервис мониторинга, в который стекаются метрики со всех амазоновских сервисов. Поэтому мы решили туда же слать метрики с нашего мета-сервера. А для логирования мы используем общий подход и на клиенте и на игровом сервере и на мета-сервере. Все логи мы шлем в амазоновский сервис Kinesis Firehose, который в свою очередь перекладывает их в Elasticseach и S3.
В Elasticseach мы храним только относительно свежие данные и с помощью Kibana ищем ошибки, решаем часть задач игровой аналитики и строим операционные дашборды, например, с графиком CCU и количество новых установок. В S3 лежат все исторические данные и используем мы их посредством сервиса Athena, который предоставляет SQL-интерфейс поверх данных в S3.
Теперь немного о том, как мы используем Terraform.
Terraform — это инструмент, который позволяет декларативно описать инфраструктуру и при каком-либо изменении описания, он автоматически определяет те действия, которые необходимо выполнить, чтобы привести вашу инфраструктуру к обновленному виду. Таким образом, имея единое описание, мы получаем практически идентичное окружение для staging и production. Также эти окружения полностью изолированы, потому что они разворачиваются под разными аккаунтами. Единственным существенным недостатком Terraform для нас является неполная поддержка GameLift.
Еще расскажу о том, как мы реализовали обновление без даунтайма.
Когда мы выпускаем обновления, мы поднимаем копию большинства ресурсов: сервисов, очередей сообщений, некоторых табличек в базе данных. И те игроки, которые скачают новую версию игры, будут подключаться к этому обновленному кластеру. Но те игроки, которые еще не обновились, могут продолжать некоторое время играть на старой версии игры, подключаясь к старому кластеру.
Как мы это реализовали. Во-первых, с помощью механизма модулей в Terraform. Мы выделили модуль, в котором описали все версионируемые ресурсы. И эти модули можно импортировать несколько раз, с разными параметрами. Соответственно, для каждой версии мы импортируем этот модуль, указав номер этой версии. Так же нам помогло отсутствие схемы в DynamoDB, что дает возможность выполнять миграции данных не во время апдейта, а откладывать их для каждого аккаунта до тех пор, пока его владелец не залогинится в новой версии игры. А в балансировщике мы просто указываем для каждой версии правила, чтобы он знал, куда роутить игроков с разными версиями.
Напоследок пара вещей, которым мы научились. Во-первых, конфигурация всей инфраструктуры должна быть автоматизирована. Т.е. некоторые вещи мы какое-то время настраивали руками, но рано или поздно ошибались в настройках, из-за чего случались факапы.
И последнее — нужно для каждого элемента вашей инфраструктуры иметь либо реплику, либо запасную копию. И если для чего-то это не сделать, то именно эта вещь нас когда-нибудь подведет.
Вопросы из зала
— А вас не смущает, что автоскейлинг может заскейлиться слишком сильно вверх из-за какой-то ошибки и вы попадете на очень большие деньги?
— Для автоскейлинга все равно выставляются лимиты. Мы не будем ставить слишком большой лимит, чтобы не попасть на большие деньги. Это основное решение + мониторинг. Можно выставить алерты, если что-то заскейлилось слишком сильно.
— В данный момент у вас какие лимиты? Относительно текущей инфраструктуры в процентном соотношении.
— Сейчас у нас этап открытого бета-теста в 11 странах, поэтому не такой большой CCU, чтобы хоть как-то оценивать. Сейчас инфраструктура слишком overprovisioned для того количества людей, которые у нас есть.
— И лимитов пока нет?
— Есть, просто они в 10-100 раз больше, чем ССU у нас. Меньше не сделать.
— Вы рассказали, что у вас очереди между фронт- и бэкендом — это очень необычно. Почему не на прямую?
— Мы хотели stateless-сервисы, чтобы легко реализовать механизм бэкпреше, чтобы сервис не запрашивал больше сообщений, чем у него есть свободных обработчиков. Также, например, когда обработчик фейлится, очередь выдаст это же самое сообщение другому обработчику — возможно у него что-то получится.
— А очередь персистится как-то?
— Да. Это амазоновский сервис SQS.
— По поводу очередей: сколько у вас создается каналов во время игры? У вас на каждый матч какое-то количество каналов?
— Создается относительно немного. Большая часть очередей, например, очереди запросов — статические. Есть очередь запросов на авторизацию, есть очередь на старт матча. Из динамически создаваемых очередей у нас есть только очереди для каждого фронтенда (он при запуске создает для входящих сообщений для клиентов) и для каждого матча мы создаем по одной очереди. В этом сервисе это почти ничего не стоит, у них любой запрос биллится одинаково. Т.е. любой запрос к SQS (создать очередь, прочитать из нее что-то) стоит одинаково и при этом мы для экономии не удаляем эти очереди, они сами потом удалятся. А то, что они существуют, нам ничего не стоит.
— В данной архитектуре это для вас лимитом не будет являться?
— Нет.
Еще доклады с Pixonic DevGAMM Talks
- Использование Consul для масштабирования stateful-сервисов (Иван Бубнов, DevOps в компании BIT.GAMES);
- CICD: бесшовный деплой на распределенные кластерные системы без даунтаймов (Егор Панов, системный администратор Pixonic);
- Практика использования модели акторов в бэкэнд-платформе игры Quake Champions (Роман Рогозин, backend-разработчик Saber Interactive).
Hixon10
Спасибо за статью!
Ох, какой же вендор-лок, хоть и осознанный :)
Скажите, пожалуйста, а вы не рассматривали для ваших Пайплайнов связку технологий — gRPC + Kafka + Reactor Kafka + Spring Boot (вместе с удобным API для Kafka Streams)?
Или вам совсем не хотелось идти в Джаву и кафку?
Hinidu
Спасибо за вопрос :-)
Java практически не рассматривали, разница с C# не такая большая, разве что экосистема побогаче.
А какие преимущества для наших задач могла бы дать Kafka по сравнению с SQS я даже не знаю. Зато огромный минус в том, что её пришлось бы мне самому админить :-)