

Введение
Прошло долгих четыре месяца с момента публикации статьи о моей попытке низкоуровневой реализации префиксного дерева. Несмотря на все мои старания потолок на который оказалась способна моя прошлая реализация префиксного дерева был ~80 тыс. слов в секунду. Я потратил тогда кучу сил и времени, но полученный результат сгодился бы только как лабораторная работа по информатике.
Многие тогда мне говорили: «Не изобретай велосипед, который уже изобрели! Используй готовое решение». Сложность в том, что мне не удавалось использовать что-то, что я не понимаю хотя бы в общих очертаниях.
Префиксное дерево я кажется понял, и вот чего удалось добиться.
Принцип работы
Я не очень хорошо знаю английский, поэтому из множества прочитанных на тему префиксных деревьев статей наверняка часть информации до меня не дошла. Поэтому придумывал я как все устроить, понимая лишь основной принцип работы префиксного дерева. Для тех кто не знает я постараюсь его описать понятнее, чем это написано в Википедии. Так я объяснял то, чем занимаюсь своей жене.
Префиксное дерево — логическая структура для хранения данных, которую можно представить как картотеку книг в библиотеке. У каждого ящичка есть номер. Каждому ящичку соответствует определенная букве алфавита. Внутри лежат номера следующих ящичков, открывая которые можно узнать следующие и так далее. Когда внутри ящичка ничего нет это значит, что буква этого ящичка является последней в слове. Проблема в том, что некоторые ящички остаются практически пустые, потому что в них лежат 1 или 2 номера, а оставшееся пространство пустует.
Для решения этой проблемы появилось множество разновидностей префиксных деревьев, в том числе: HAT-trie, double-array trie, tripple-array trie. Именно то, что я не смог досконально понять принцип их работы, толкнуло меня на дерево простое, как библиотечная картотека.
Еще в прошлый раз мне удалось воплотить довольно экономную по потреблению памяти реализацию простого префиксного дерева. Продолжая эту метафору с библиотечной картотекой, я сделал ящички в своей картотеке разного размера, для полного алфавита ящик самый большой, для 1 буквы — самый маленький.
Именно ту самую PHPшную схему мне удалось воплотить на Си.
1. Каждая буква слова по установленной таблице кодируется числом от 2 до 95. К примеру, слово «абв» кодируется тремя числами: 11, 12, 13. В целях максимального быстродействия используется двумерный массив чисел длиной 1 байт
uint8_t abc[256][256] = {}; Для преобразования программа читает строку по 1 байту, значение каждого байта она пытается брать в нашем массиве. Например, код цифры 1 = 49, значит смотрим abc[49][0];. Если там лежит значение отличное от '\0', значит это и есть код нашей буквы, запоминаем его и переходим к следующему байту. В нашем случае слово «абв» состоит из последовательности 6 байт по два байта на букву: 208, 176, 208, 177, 208, 178. Поскольку кодировка utf-8 устроена так, что первые байты однобайтовых символов никогда не совпадают с первыми байтами многобайтовых, в нашем массиве abc[208][0] = 0;.Однако для байтовых пар там вот какие совпадения:
/* а [11] */ abc[208][176] = 11;
/* б [12] */ abc[208][177] = 12;
/* в [13] */ abc[208][178] = 13;
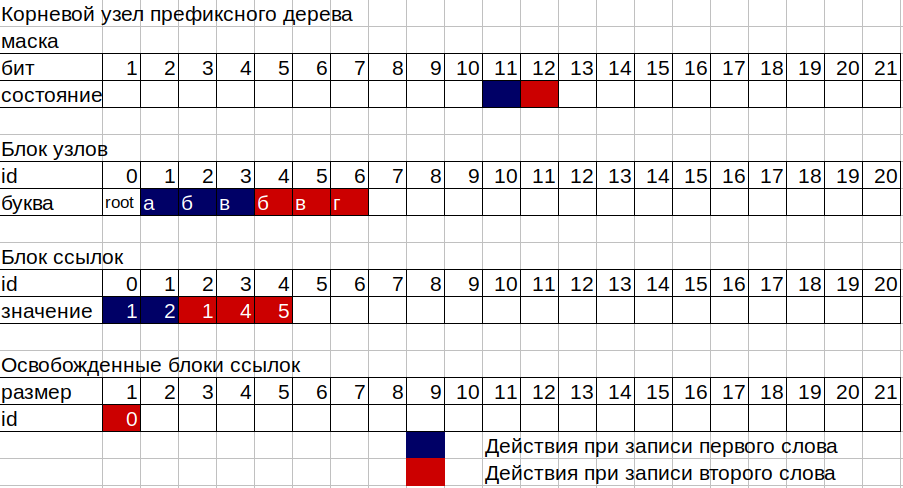
2. Теперь нам последовательно надо записать числа 11, 12 и 13 в ящички нашего дерева. Дерево состоит из 2-х отдельных неприрывных блоков памяти, первый — блок узлов, второй — блок ссылок, а также двух счетчиков занятых узлов и занятых ячеек блока ссылок. Каждый узел дерева состоит из 16 байт, 12 байт битовой маски и 4 байта на хранение id блока ссылок. Маска позволяет хранить числа со 2 по 96 бит. Первый бит маски используется для флага окончания слова на этом узле. Каждому узлу может соответствовать id из блока ссылок, если в этом узле записана хотя бы 1 буква, или не соответствовать, если узел является в терминах деревьев «листом», то есть на нем просто оканчивается какое-то слово. Выражаясь библиотечно, пустой ящичек.
3. Берем маску первого (корневого) узла. trie->nodes[0].mask; Считаем поднятые в этой маске биты, начиная со второго (первый для флага окончания слова). Если ни одного бита в маске не поднято, т.е. узел пуст, то нам потребуется блок ссылок размером 1 для хранения нашего числа 11, берем число из счетчика ссылок блока и увеличиваем старое значение на единицу (ведь нам нужен размер 1). Берем число из счетчика узлов и тоже увеличиваем старое значение на 1. Пишем в наш корневой узел id блока ссылок, который и есть число, полученное из счетчика блока ссылок. А в этот id блока ссылок пишем id нового узла, то есть числа, полученного из счетчика узлов. Теперь у нас помимо корневого узла (id 0) появился узел буквы «а» (id 1). Для записи числа 12, соответствующего букве «б» проделываем тоже самое, но уже с узлом буквы «а».
4. На последней букве «в» нам не понадобится место в блоке ссылок, поскольку у нас это будет последний узел на ветке или узел — лист. У такого узла поднят только 1 бит в маске.
5. Самая сложная часть работы дерева происходит, когда запись происходит в узел, в котором уже были записаны какие-то буквы. В этом случае схема работы следующая:
Предположим мы хотим дописать слово «бвг» (12, 13, 14) в наше дерево, в которое уже записано слово «абв» (11, 12, 13). Считаем биты в маске корневого узла до бита интересущей нас буквы. У нас буква «б» с кодом 12, значит бит этой буквы 12, в маске от 1 до 12 бита уже поднят бит 11 от буквы «а». Стало быть имеем текущий размер блока ссылок для корневого узла 1. Мы записываем вторую букву, значит нам теперь нужен блок ссылок размером 2. Тут вступает в дело реестр освобожденных блоков, в который записываются id и размеры участков в блоке ссылок, которые более не используются узлами дерева. Наш старый id блока ссылок для корневого узла размером 1 как раз и попадет в реестр свободных участков размером 1, поскольку нашему корневому узлу нужен размерчик покрупнее. Наш реестр не имеет подходящего участка размером 2 и мы опять берем в качестве нового id блока ссылок значение из счетчика блока ссылок, увеличивая счетчик на 2. По новому адресу блока ссылок в том же порядке, в котором расположены биты в маске узла мы записываем значение id узла из старого блока ссылок для буквы «а» первого слова и значение только что созданного узла буквы «б» второго слова.
Скорость работы
Звучит барабанная дробь… Помните прошлый результат? Около 80 тыс. слов в секунду. Дерево создавалось из словаря всех русских слов OpenCorpora 3 039 982 слов. А вот что получилось теперь:
yatrie creation time: 4.588216s (666k wps)
yatrie search time 1 mln. rounds: 0.565618s (1.76m wps)UPDATE 01.11.2018:
В версии 0.0.2 удалось еще почти в 2 раза поднять скорость за счет замены полноценных функций на макрофункции, а также изменение структуры маски узла на uint32_t mask[3], раньше было uint8_t mask[12].
Также добавил макросы LIKELY() UNLIKELY() для предсказания ожидаемых результатов в тех блоках if(), где это возможно.
Насколько это все компактно?
Указанный словарь OpenCorpora занимает ~84Мб, что не намного хуже libdatrie, который дает ~80Мб.
> Исходный код
Добро пожаловать!
Комментарии (10)

mat300
30.10.2018 05:59| yatrie creation time: 4.588216s (666k wps)
Батюшка, да не иначе сотона руковОдил вами во время сией разработки. Нехорошая какая цифирь нарисовалась
voidptr0
30.10.2018 12:11Я так понял, все пока рассчитано на работу в одном потоке (ну, разве, что читать можно параллельно). Если модифицировать для многопоточного использования, то скорость наверняка просядет.
gorodnev
30.10.2018 23:13Даже если писать из одного потока, а читать из других, то проблемы неизбежны :)
gorodnev
30.10.2018 23:12Пока посмотрел код работы с односвязными списками и есть пара моментов для улучшений:
1. Отказаться от рекурсии в пользу итерации для операций на списках;
2. Насколько часто происходит поиск предка в односвзянном списке? Если часто, может стоит рассмотреть использование двусвязного?
johovich Автор
31.10.2018 00:31Спасибо. Приятно, что кто-то полез под капот.
1. А если в процентах измерить, это сколько даст роста?
2. Там список я взял, который делал для ассоц. массива. Поэтому там так все. Предок там вообще не нужен ни разу, да и сам список нужен только при создании дерева. При чтении уже не используется.
Сейчас хочу попробовать самые потенциально сильные изменения, скорость повыше, а размер еще меньше.
Там сейчас битовая маска 96 бит 12 раз по 1 байту. Поэтому счет битов идет 12 раз. Хочу сделать не char, а int32 3 раза.
Id хранятся в полях int32, что сильно больше самого большого словаря. По моим замерам, весь русский язык умещается в 5 млн. узлов. А значит можно взять 3 байта на id, а не 4.
johovich Автор
31.10.2018 00:49Еще вот думаю как-то сделать, чтобы алфавит и размер маски можно было бы выбирать. Сейчас используется около 80 бит, но там англ. + русский + символы, обычно сразу оба алфавита не нужны.
В итоге можно сделать дерево более компактным, чем делает продвинутая, но более медленная либа libdatrie.a-tk
31.10.2018 08:12Дракона почитайте, там есть глава про подходящую структуру данных для этой задачи.
kloppspb
%zu же, в tests/tests.c :) Бенчмарки — завтра, sorry. Есть парочка реализаций, с которыми интересно сравнить.