
В обучении с подкреплением (Reinforcement Learning) часто используется любопытство в качестве мотивации для ИИ. Заставляющее его искать новые ощущения и исследовать окружающий мир. Но жизнь полна неприятных сюрпризов. Можно упасть с обрыва и с точки зрения любопытства это всегда будут очень новые и интересные ощущения. Но явно не то, к чему надо стремиться.
Разработчики из Berkeley перевернули задачу для виртуального агента с ног на голову: главной мотивирующей силой сделали не любопытство, а наоборот — стремление всеми силами избегать любой новизны. Но "ничего не делать" оказалось сложнее, чем кажется. Будучи помещенным в постоянно меняющийся окружающий мир, ИИ пришлось обучиться сложному поведению, чтобы избегать новых ощущений.
Обучение с подкреплением (Reinforcement Learning) делает робкие шаги в сторону создания сильного ИИ. И хотя пока все ограничивается очень низкими размерностями, буквально единицы, в которых приходится действовать виртуальному агенту (желательно разумно), время от времени появляются новые идеи как усовершенствовать обучение искусственного интеллекта.
Но усложняются не только алгоритмы обучения. Окружения тоже становятся сложнее. Большинство окружений для reinforcement learning очень простые и мотивируют агента исследовать окружающий мир. Это может быть лабиринт, который надо весь обойти, чтобы найти выход, или компьютерная игра, которую надо пройти до конца.
Но в долгосрочной перспективе живые существа (разумные и не очень) стремятся не только исследовать окружающий мир. Но и сохранить все хорошее, что есть в их короткой (или не очень) жизни.
Это называется гомеостаз — стремление организма сохранить постоянное состояние. В том или ином виде это свойственно всем живым существам. Разработчики из Berkeley приводят такой странный пример: все достижения человечества, по большому счету, созданы для защиты от неприятных сюрпризов. Для защиты от все возрастающей энтропии окружающей среды. Мы строим дома, где поддерживаем постоянную температуру, защищенную от перепадов погоды. Используем медицину, чтобы быть постоянно здоровыми и так далее.
С этим можно поспорить, но в этой аналогии действительно что-то есть.
Ребята задались вопросом — что будет, если главной мотивацией для ИИ сделать попытку избегать любой новизны? Минимизировать хаос в качестве целевой функции обучения, другими словами.
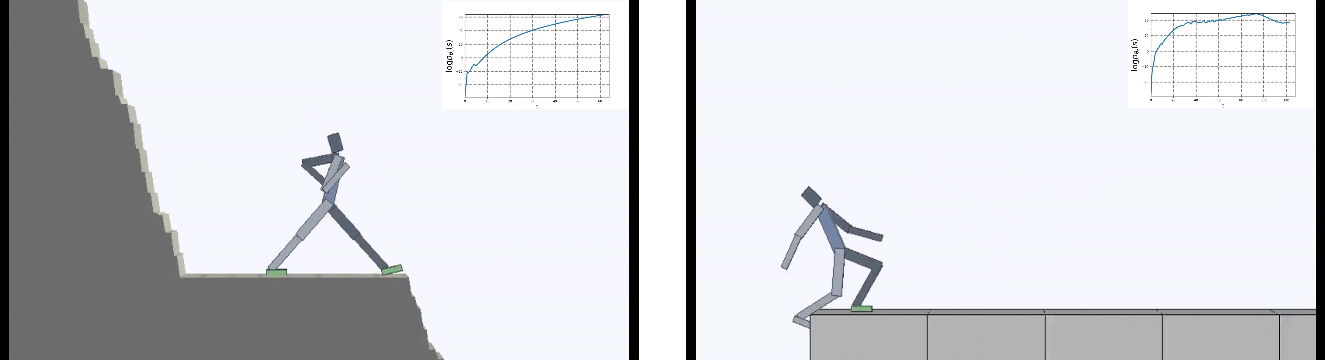
И поместили агента в постоянно меняющийся опасный мир.
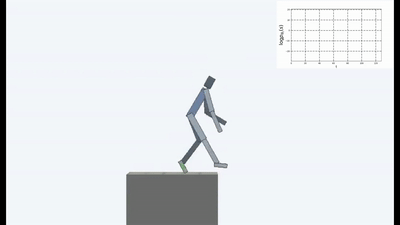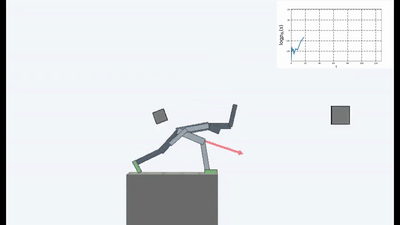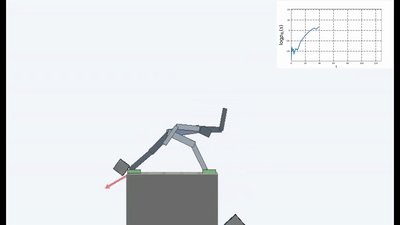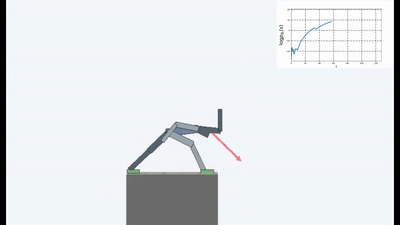
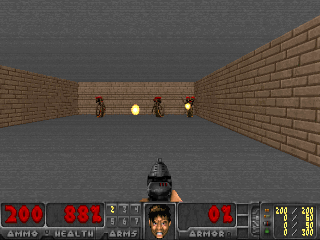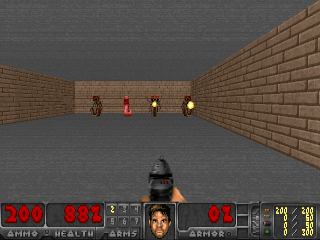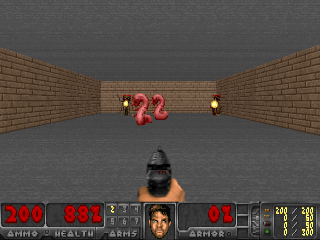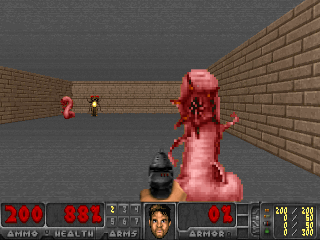
Результаты оказались интересными. Во многих случаях такое обучение превзошло обучение на основе любопытства, и чаще всего по качеству приближалось к обучению с учителем. То есть к специализированному обучению по достижению конретной цели — выиграть в игре, пройти лабиринт.
Это конечно логично, потому что если вы стоите на разрушающемся мосту, то чтобы продолжать на нем находиться (поддерживать постоянство и избегать новых ощущений от падения), вам необходимо постоянно отходить от края. Бежать изо всех сил, чтобы продолжать стоять на месте, как говорила Алиса.

И на самом деле в любом алгоритме обучения с подкреплением присутствует такой момент. Потому что смерти в игре и быстрое окончание эпизода штрафуются отрицательной наградой. Или, в зависимости от алгоритма, снижением максимальной награды, которую агент мог бы получить, если бы не падал постоянно со скалы.
Но именно в такой постановке, когда у ИИ нет никаких других целей, кроме как стремления избегать новизны, вроде как в обучении с подкреплением применено впервые.
Что интересно, с такой мотивацией виртуальный агент научился проходить многие игры, в которых есть цель для выигрыша. Например, тетрис.

Или окружение из Doom, где надо уворачиваться от летящих огненных шаров и стрелять в приближающихся противников. Потому что многие задачи можно сформулировать как задачи по сохранению постоянства. Для тетриса это стремление сохранить поле пустым. Экран постоянно заполняется? О боже, что же случится, когда он заполнится до конца? Не-не, такого счастья нам не надо. Слишком сильное потрясение.
С технической стороны это устроено довольно просто. Когда агент получает новый state, он оценивает насколько это состояние ему знакомо. То есть насколько новое состояние входит в распределение state, которые он посетил ранее. Чем в более знакомое state агент попадает, тем большую получает награду. И задача обучения policy (это все термины из Reinforcement Learning, если кто не знает) заключается в выборе таких действий actions, которые приводили бы к переходу в максимально знакомый state. При этом каждый полученный новый state служит для обновления статистики знакомых состояний, с которой сравниваются новые состояния.
Что интересно, в процессе ИИ самопроизвольно обучился пониманию тому, что новые state влияют на то, что считать новизной. И что достигнуть знакомых состояний можно двумя способами: либо перейти в уже известное состояние. Либо перейти в такое состояние, которое обновит само понятие постоянства/знакомости окружения, и агент окажется в новом, сформированном его действиями, знакомом state.
Это заставляет агента предпринимать сложные скоординированные действия, лишь бы ничего в жизни не делать.
Парадоксальным образом это приводит к аналогу любопытства из обычного обучения, и заставляет агента исследовать окружающий мир. Вдруг где-то есть место, еще более безопасное, чем здесь и сейчас? Там можно будет полностью предаться лени и абсолютно ничего не делать, избегая тем самым любых проблем и новых ощущений. Не будет преувеличением сказать, что подобные мысли наверно приходили в голову любому из нас. А для многих это является настоящей движущей силой в жизни. Хотя в реальной жизни никому из нас не приходилось сталкиваться с заполняющимся до верха тетрисом, конечно.
Если честно, это запутанная история. Но практика показывает, что это работает. Исследователи сравнили этот алгоритм с лучшими представителями на основе любопытства: ICM и RND. Первый представляет собой эффективный и ставший уже классическим в обучении с подкреплением механизм любопытства. Агент стремится не просто к новым незнакомым и поэтому интересным состояниям. Незнакомость ситуации в подобных алгоритмах оценивается по тому, может ли агент ее предсказать (в более ранних были буквально счетчики посещенных состояний, но сейчас все свелось к интегральной оценке, которую дает нейронная сеть). Но в таком случае шевелящаяся листва на деревьях или белый шум по телевизору обладали бы бесконечной новизной для такого агента, и вызывали бы бесконечно чувство любопытства. Потому что он никогда не сможет предсказать все возможные новые state в полностью случайной окружающей среде.
Поэтому в ICM агент стремится только к тем новым state, на которые он может повлиять своими действиями. ИИ может повлиять на белый шум на экране телевизора? Нет. Значит неинтересно. А может повлиять на мяч, если его сдвинуть? Да. Значит играть с мячом интересно. Для этого в ICM используется очень классная идея с Inverse Model, с которой сравнивается Forward Model. Подробнее в оригинальной работе.
RND представляет собой более новую разработку механизма любопытства. Которая на практике превзошла ICM. Если коротко, нейросеть пытается предсказать выходы другой нейросети, которая инициирована случайными весами и никогда не меняется. Предполагается, что чем более знакомая ситуация (подающаяся на вход обеим нейросетям, текущей и случайно инициированной), тем чаще текущая нейросеть сможет предсказывать выходы случайно инициированной. Я не знаю, кто все это придумывает. С одной стороны хочется пожать руку такому человеку, а с другой дать пинка за такие извращения.
Но так или иначе, а обучение на идее сохранения гомеостаза и попытке избегать любой новизны, во многих случаях на практике достигло лучшего итогового результата, чем обучение на основе любопытства на основе ICN или RND. Что отражено на графиках.
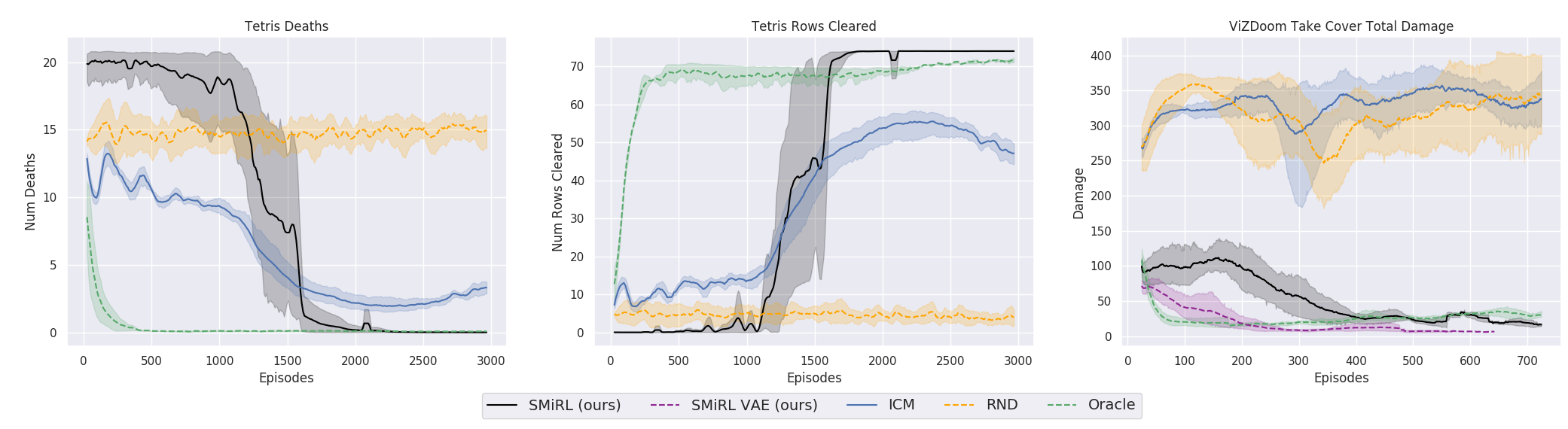
Но здесь нужно уточнить, что это только для окружений, которые исследователи использовали в своей работе. Они опасные, случайные, шумные и со все возрастающей энтропией. В них действительно может быть выгоднее ничего не делать. И лишь иногда активно шевелиться, когда в вас летит огненный шар или мост позади вас начинает разрушаться. Однако исследователи из Berkeley настаивают, видимо по своему нелегкому жизненному опыту, что такие окружения гораздо ближе к сложной реальной жизни, чем использовавшиеся ранее в обучении с подкреплением. Ну не знаю, не знаю. В моей жизни летящие в меня огненные шары из монстров и безлюдные лабириты с единственным выходом встречаются примерно с одинаковой частотой. Но нельзя отрицать, что предложенный подход, при всей его простоте, показал потрясающие результаты. Возможно, в будущем должны разумно сочетаться оба подхода — гомеостаз с сохранением положительного постоянства в отдаленной перспективе и любопытство для текущих исследований окружающей среды.
Комментарии (117)

Mad__Max
22.12.2019 01:07А я всегда говорил: лень — двигатель прогресса (развития)!
Заодно научился использовать как достаточно мощный фактор мотивации. Которые если сильно упростить можно свести к: активно делать что-то сейчас, чтобы меньше (желательно вообще НЕ) делать что-то потом. Во многом это самообман, но работает.
Интересно, что оказывается на искусственных нейтронных сетях это тоже хорошо работает.

iga2iga
22.12.2019 02:36Лень — двигатель прогресса!
Пардон, не прочитал комментарий выше…
… потому что — лень.

VDG
22.12.2019 06:07+1Либо перейти в такое состояние, которое обновит само понятие постоянства/знакомости окружения, и агент окажется в новом, сформированном его действиями, знакомом state.
Можете раскрыть эту часть?DesertFlow Автор
22.12.2019 16:32Агент получает награду за то, что переходит в знакомые state (награда пропорциональна узнаваемости места). Но когда у вас большой горизонт планирования и вы понимаете динамику среды, то вы можете сознательно перейти в малознакомое место и постоять там какое-то время, пока оно не станет для вас знакомым. Это примерно как построить дом — надо приложить усилия, получить много неприятной новизны (по правилам игры агент избегает новизны). Но зато в будущем вы получите намного больше награды, так как это сделанное вашими собственными руками место со временем станет для вас знакомым и вы будете получать награду просто за нахождение в нем. В качестве доказательства они приводят пример тетриса, где у агента изначально не было предпочтений, но в итоге он сформировал на несколько ходов вперёд тактику по "постройке дома" в углу в нижней строчке (см. яркость пикселей на гифка, это куда агент стремится). Так как помещая туда фигуры, в отдаленной перспективе он получит более стабильное состояние с пустым полем. Чем просто бороться по факту с текущими падающими фигурами.
Эта способность агента самостоятельно формировать для себя места, которые в будущем станут для него знакомыми с большой наградой (хотя сейчас они для него новые и болезненные) приводит к более сложному поведению, чем просто всегда переходить в ближайший state с максимальной узнаваемостью.
KonkovVladimir
22.12.2019 18:11Биологические системы обычно поддерживают свои сенсорные состояния в пределах физиологических границ, с интуитивным пониманием адаптивного поведения с точки зрения активного вывода причин этих состояний
— www.tandfonline.com/doi/abs/10.1080/00207727008920220.
То-есть биологическая система имеющая некоторую модель окружающей действительности, входящую (частично) в противоречие с ее сенсорными ощущениями, с одной стороны вынуждена усложнять эту модель, чтобы лучше предсказывать неожиданные ситуации, с другой стороны изменять окружающий мире, что-бы исключать неожиданные ситуации.
В целом разумной стратегией будет одновременно, изучая мир, менять его — минимизируя общие энергетические и временные затраты.
С технической стороны это устроено довольно просто. Когда агент получает новый state, он оценивает насколько это состояние ему знакомо. То есть насколько новое состояние входит в распределение state, которые он посетил ранее. Чем в более знакомое state агент попадает, тем большую получает награду. И задача обучения policy (это все термины из Reinforcement Learning, если кто не знает) заключается в выборе таких действий actions, которые приводили бы к переходу в максимально знакомый state. При этом каждый полученный новый state служит для обновления статистики знакомых состояний, с которой сравниваются новые состояния.
Утрируя можно сказать, что конечным результатом может быть либо изучить весь мир (все state знакомы), либо сделать его однообразным (мир состоит из одного state).
Оба этих состояния будут схожи с буддийской интуицией душевного споскойствия; конечная цель организма — быть в мире и гармонии с окружающей средой.
VDG
22.12.2019 20:46С аналогией-то из жизни понятно, меня интересует техническая сторона. В какой момент у агента щёлкает в голове переключатель, что нужно из тёплого места пойти «строить дом», и что это за тумблер? Иначе говоря, в какой момент и почему одна стратегия/поведение сменяется другой.
И почему агент просто не остаётся на месте «медитировать», ведь со временем это место тоже станет ему знакомым.Mad__Max
22.12.2019 21:57+1Так агрессивная внешняя среда не дает просто залипнуть на месте и «медитировать». А так да, агент именно к этому и стремится по возможности. Но среда все время чем-то гадит и ему приходится как-то реагировать и подстраиваться дабы вернуться к «блаженному ничегонеделанию».
DesertFlow Автор
23.12.2019 02:09Ничего там не щелкает, это так объясняют в BAIR полученные результаты. Технически, если у вас единственная целевая функция избегать новизны, то вы можете либо переходить в ближайший state с минимальной новизной, либо своими действиями сделать так, чтобы в каком-то state уменьшилась новизна. По алгоритму для этого достаточно постоять там долгое время, чтобы набралась статистика, в которой это место будет считаться хорошо знакомым.
Они просто запустили алгоритм и заметили, что в том же тетрисе и ещё паре игр агент не просто переходит в знакомые state, а целенаправленно делает так, чтобы конкретный state стал знакомым для него в будущем (начал приносить награду в будущем). Так как конкретно это место (state) будет выгодно в отдаленной перспективе. А определяет он это по нейросети, изучивший динамику среды на много шагов вперёд.
В тетрисе таким отдаленным выгодным state будет очищать самую нижнюю строчку (см.яркость пикселей на гифка в правой части). Хотя для текущего момента времени с точки зрения постоянства выгодно поддерживать одинаковой текущую линию. Но агент держит постоянной не ее, а стремится очистить все до самой нижней линии. Из этого они сделали такие выводы. О сложном скоординированном поведении.
Вообще, я заметил что в статьях BAIR часто делают такие далеко идущие выводы по каким-то незначительным и не полностью доказанным признакам. Но учитывая, что в Reinforcenent Learning двухмерная прыгающая нога из двух суставов считается сложной задачей с высокой размерностью, то тут особо не разбежишься. Приходится работать с тем что есть. С технической стороны эти выводы верны, но отсутствие масштабируемости конечно удручает. Будем надеяться, что это вопрос времени.
И как уже верно заметили, все время стоять на одном месте, делая это место все более и более знакомым, а значит приносящим больше награды, на практике не получается. Хотя агент стремится именно к этому. Но внешняя среда, вроде разрушающегося по пятам моста (или преследующие вас хищники, см. гифку в оригинальной статье) повышают энтропию в том месте, где вы стоите. И в какой-то момент соседний state становится более привлекательным с точки зрения знакомства (уменьшения новизны, увеличения постоянства). И агент переходит в него. Ну или делает более сложные скоординированные действия, как описано выше.
VDG
23.12.2019 20:50Спасибо, теперь прояснилось. Я бы интерпретировал так: агент постоянно стремится в точку «спокойствия», которую указывает/предсказывает нейросеть. В примере с мостом точка периодически перескакивает в соседнее безопасное положение, агент делает к ней шаг и снова встаёт на точку. В тетрисе точка (пустая нижняя строка) удалена не только в пространстве, но, так сказать, и во времени. Поэтому агент вынужден «продираться через фигуры», непрерывно двигаясь к ней.
DesertFlow Автор
24.12.2019 04:33Да, верно. Парадокс в том, что стремление избегать новизны (в этой статье) и стремление к новизне (механизм любопытства) в итоге приводят к примерно одинаковому поведению. Потому что любопытство заставляет искать новые state, но целевая функция обучения — оставаться в игре как можно дольше. А здесь избегание новизны заставляет убегать от изменений, которые по большей части представляют опасности. Что естественным образом тоже приводит к тому, что агент дольше остается живым. В итоге оба оказываются в том state, который наиболее выгоден с точки зрения продления жизни агента.
KonkovVladimir
24.12.2019 07:17Почему все неправильно переводят.
Принцип свободной энергии состоит в том, что системы — те, которые определены их вложением в одеяло Маркова — пытаются минимизировать разницу между их моделью мира и его сенсорным воприятием. Это различие можно охарактеризовать как «сюрприз» и минимизировать путем непрерывной коррекции модели мира системы. Таким образом, этот принцип основан на байесовской идее мозга как «двигателя вывода».
Фристон добавил второй способ минимизации: действие. Активно переводя мир в ожидаемое состояние, системы также могут минимизировать свободную энергию системы. Фристон предполагает, что это принцип всех биологических реакций.
«Сюрприз» это то что не укладывается в нашу модель мира.
Система стремиться избегать сюрпризов — звучит совершенно по другому и более правильно.
epishman
24.12.2019 12:27Возможно это один из принципов, но точно не единственный. Вот сижу я, тихо программирую, подстраиваясь под ЯП или пишу свой фреймворк. Достиг гомеостаза с мирозданием. Потом плюнул на все, и поехал на Эльбрус. Что меня толкнуло в неизведанное и опасное?
KonkovVladimir
24.12.2019 14:24+1Судя по тому как мало людей едет на Эльбрус — какое-то отклонение от нормы.

dim2r
23.12.2019 12:27С аналогией-то из жизни понятно, меня интересует техническая сторона. В какой момент у агента щёлкает в голове переключатель, что нужно из тёплого места пойти «строить дом», и что это за тумблер?
Человек похож на мультиагента и брокера. Мини-агенты имеют имеют разный приоритет. Например
— сижу программирую — активный агент программиста.
— и тут что-то зачесалось в ноге — брокер видит более приоритетный сигнал.
брокер включает другого мини-агента и временно передает ему управление руками, глазами и тд.
— более низкоуровневый, но более приоритетный агент-чесальщик чещет ногу.
— брокер получает сигнал удовлетворения и обратно переключается на программиста.
dim2r
23.12.2019 12:22а какова метрика знакомости места?
DesertFlow Автор
23.12.2019 17:34Вероятность, что этот state относится к распределению ранее посещённых state. Для простых дискретных игр (тетрис и, кажется, vizdoom) они хранят все посещенные state с начала эпизода и подгоняют на этом датасете простые генеративные вероятностные модели. Для тетриса на распределении Бернулли, а для vizdoom используют нормальное распределение. Для окружений с картинками они
используют вариационный автоэнкодер VAE. В общем, оценку знакомости места в сложных играх даёт нейросеть, натренированная на всех предыдущих эпизодах.dim2r
23.12.2019 21:05Не совсем понятно, каким образом считается, что эпизод1 похож эпизод2? В эпизоде может быть много кадров.
DesertFlow Автор
24.12.2019 04:37Не эпизод, а state — текущее состояние. Показания всех сенсоров агента в текущий момент. У него есть несколько вариантов действия action и для каждого варианта он оценивает, насколько знакомым окажется новый state, если он выберет это действие. И соответственно, в итоге выбирает то действие, которое по его мнению (по оценке нейросети) приведет к более знакомому состоянию. Состоянию, в котором он уже находился много раз.
Для дискретных actions (тетрис, VizDoom) они используют Q-learning, а для непрерывных (Humanoid) — TRPO.
dim2r
24.12.2019 16:44Состоянию, в котором он уже находился много раз.
так что, надо запоминать все состояния и вести счетчик для каждого?DesertFlow Автор
25.12.2019 01:52Они испытывали этот алгоритм на очень разных задачах с разными исходными данными. Там где простые условия, как в тетрисе, они действительно хранили все состояния от начала эпизода. И на этом датасете составляли генеративную вероятностную модель. Которая служила потом для обучения нейросети — мозгов агента. Показывая ему степень знакомости текущего места.
А где на входе сложные данные или картинки, для расчета вероятностей они использовали вариационный автоэнкодер — VAE. Это нейросеть, которая на выходе выдает вероятности. Математическое ожидание и отклонение. И вот она, хоть на своем выходе и предсказывает вероятность того, насколько текущий state знаком относительно начала текущего эпизода, на самом деле была обучена на большом количество предыдущих эпизодов.
То есть, там две нейросети — одна предсказывает вероятность что state знаком, начиная с начала эпизода (или на простых задачах, вместо нее посчитанное реальное распределение). А вторая — это уже мозги самого агента. Причем если брать мозги, которые они использовали для дискретных действий — Q-learning, то там внутри еще две нейросети, основная и догоняющая target. Да и нейросеть для непрерывных действий TRPO, тоже внутри состоит из двух нейросетей — actor и critic.
В общем, в этом Reinforcement Learning все сложно. А все потому, что обычные нейронные сети, такие как сверточные CNN для распознавания картинок, в Reinforcement Learning нифига не работают. И это прям хороший вопрос, почему. Толком на него до сих пор нет ответа.
Gryphon88
25.12.2019 11:53Спасибо за очень информативные комментарии, очень понятно, на пальцах и дают контекст «ну это тут все знают» для чтения статей по RL. Не думали о том, чтобы написать туториал «Что такое Reinforcement learning и чем он отличается от привычных нейросетей»?
DesertFlow Автор
25.12.2019 13:26Я уже пытался: https://habr.com/ru/post/437020/
Но это такая обширная тема, что если пытаться упрощать, то получается пустая болтовня, от которой нет пользы. А если чуть углубиться, то получаются одни формулы. Которые отталкивают любого нормального человека. Дело в том, что область обучения с подкреплением зародилась очень давно, десятилетия назад, ещё до нейросетей. И многие понятия и определения чисто исторически перекочевали в наше время. И они довольно сильно отличаются от привычных понятий в нейросетях. В Reinforcement Learning для обучения нейросетей используются совсем другие формулы и методы, чем для обычных, а сами нейросети там скорее используются как простенькие аппроксиматоры. С другой стороны, существующие методы обучения с подкреплением просто не могут обучать сложные нейросети (по разным причинам). Иначе их давно бы начали использовать. И единственное что привлекает исследователей в Reinforcenent Learning, то что это настоящий интеллект, пусть и работающий пока только на задачах очень низкой размерности. Со временем либо увеличится вычислительная мощность, либо будут найдены более эффективные методы обучения. И тогда для всех настанет коммунизм.
dim2r
25.12.2019 16:18Нейросеть может входить в состав RL.
Вот довольно толково разжевано, как её можно использовать.
habr.com/ru/post/439674
Автор даже уложил весь код в 150 строчек numpy. Я после прочтения сразу написал самообучающийся агент для крестиков-ноликов для Pytorch.KonkovVladimir
25.12.2019 16:39Да, а когда 300 спичечных коробков хватало — klink0v.livejournal.com/206278.html
DesertFlow Автор
26.12.2019 01:08В пинг-понге размерность 1. На 4 алгоритм уже захлёбывается. На 17 (примитивная модель гуманоида с минимальным числом суставов) обучить практически невозможно. Точнее удается, но ценой невероятных ухищрений с рядом ограничений на условия задачи, и ценой облачной вычислительной мощности. У человека 700 мышц и два глаза по 100 мегапикселей каждый. А число степеней свободы, приведенное к единице времени как в Reinforcement Learning, исчисляется миллионами или миллиардами. Продолжать?
К примеру, если за единицу времени вы можете сказать одно слово, то у вас 500 тысяч степеней свободы. Если фразами, то это сразу комбинаторный взрыв.
Понятно, что необходимо уменьшать единицу времени, тогда число степеней свободы для RL алгоритма уменьшается (но растет необходимый горизонт планирования). Число мышц можно уменьшить до каких-нибудь разумных 100 штук, например. А число слов до 2-30 тысяч. И картинку на входе подавать 640х480 (все равно пропускная способность глазного нерва на 30 кадрах в секунду примерно 2 мегапикселя, так что 100 мп разрешение глаза используется только для резкости и предобработки).
И получается, что когда RL алгоритмы смогут обрабатывать задачи с текущих размерностей 1-10 до хотя бы до нескольких сотен, а лучше тысяч. То тогда будет реальный шанс увидеть сильный ИИ, построенный на этом подходе. Вопрос ли это масштабирования, вот в чем вопрос. Сейчас RL алгоритмы не масштабируются. Но все может измениться, конечно.
DesertFlow Автор
26.12.2019 01:28Но это только если речь о голом RL. На практике используются гибриды. К примеру, размерность картинки с камеры с помощью обычной нейросети-автоэнкодера можно снизить до размерности 4. А уже в этой размерности обучать агента алгоритмами RL. Так уже существующими методами удается обучить ездить машинку по камере, например.
У человека тоже большая часть сенсорной информации предобрабатывается. Как пример глазной нерв, сжимающий видеопоток в 100 раз. Собственно, наше мышление это тоже пример невероятного снижения размерности. Из всего разнообразия показаний сенсоров и длительных по времени ситуаций (число комбинаций не поддается исчислению из-за комбинаторного взрыва), мы сжимаем их до типичных 20 тысяч слов, используемых человеком. И мыслим, то есть думаем, уже на уровне этих слов. В размерности всего 20 тысяч измерений.
Вот как только RL алгоритмы смогут работать с задачами размерностью 20 тысяч, то сразу естественным образом получим сильный разговорный ИИ, построенный на базе текстов. Возможно он будет не идеальный, так как всю информацию о внешнем мире мире ему придется получать из текста. Но болтать будет здорово.


RobertLis
22.12.2019 07:56нейросеть пытается предсказать выходы другой нейросети, которая инициирована случайными весами и никогда не меняется. Предполагается, что чем более знакомая ситуация (подающаяся на вход обеим нейросетям, текущей и случайно инициированной), тем чаще текущая нейросеть сможет предсказывать выходы случайно инициированной.
Это напоминает один трюк из эпохи, когда ещё не умели обучать многослойные модели. Брали сеть, инициализированную случайными весами, затем прикручивали к ней дополнительный слой — и обучали только его.
Итоговая конструкция обучалась легко: ведь это по сути был однослойный перцептрон — но могла при этом делать более сложные вещи. Одна из таких моделей — эхо-сети.
Эта идея давно уже витает в воздухе. Вот, например, древний анекдот про Дональда Кнута и его ученика:
Студент инициализировал нейросеть случайными весами. Когда его спросили, какой в этом смысл, он объяснил: так у сети не будет никаких предрассудков о том, как устроена реальность.
Преподаватель ненадолго задумался и ответил, что у этой нейросети уже есть предрассудки.
Отличие лишь в том, что студент их не понимает.epishman
22.12.2019 09:39у этой нейросети уже есть предрассудки
Естественно, ведь инициируем мы ее в определенный момент времени, находясь в определенном месте, значит для нее тоже будет работать натальная карта :)Cerberuser
22.12.2019 11:25- Твоя нейросеть втирает мне какую-то дичь! Это всё потому что она Близнец!
epishman
22.12.2019 11:41С сожалению, принудительное обучение
в лагеряхнивелирует врожденные задатки, и получаются стандартные болванки для стандартного бизнес-процесса.
RobertLis
22.12.2019 11:37Вы таки смеётесь, но если генератор случайных чисел был привязан к часам, то чисто теоретически некоторая связь с движением планет у неё будет.
epishman
22.12.2019 11:46Термин «случайное число» применимо только к статистически-значимой выборке, а в жизни любого человека такая выборка не достигается практически никогда, поэтому чисто с научной точки зрения — судьба конкретного человека абсолютно неслучайна. Ну вот стоите вы на краю обрыва, думате спрыгнуть или нет, и вытягиваете карту таро. Будет ли она случайной? В вашем случае — нет, но если поставить 10000 человек — тогда закон нормального распределения будет удовлетворен.

eksamind
22.12.2019 10:40+1учитывая все нарастающую проблему непонимания, почему нейросеть делать именно такой выбор, то появится "психологи ", которые запрос ответами будут пытатся понять, что там творится в нейросети)
Неожиданно эффективные решения нащовут интуицией, неожиданно неэффективные, тараканами...epishman
22.12.2019 11:50Ну, некоторые биологи-эволюционисты и некоторые психологи считают, что основная функция разума — это как раз объяснять выбор, который за секунду до того уже сделала нейросеть. С этой точки зрения человечество ничего не придумало и не изобрело — оно просто создает описание мира на новом дискретном языке.

ReDev1L
22.12.2019 12:28Нужно объединить эти два подхода. По умолчанию — исследовать, но как только есть опасность — переключать управление на лень и самосохранение. Опасность выявлять смертью агента и штрафами в исследовании.
shm-vadim
22.12.2019 13:10Кажется, что нейросети-параноики будут куда жизнеспособнее, потому что будут более полно соответствовать эволюционным принципам природы.

AllexIn
22.12.2019 16:12С каких пор эволюционные принципы признаны идеальными?
shm-vadim
22.12.2019 16:40Я не думаю, что они идеальны, у всего ведь есть свои недостатки и ограничения. Но то, что мы существуем и вполне серьезно думаем о создании искусственного интеллекта, само по себе многое говорит об их эффективности. И я, например, не могу вспомнить саморазвивающуюся и самоподдерживающуюся сложную систему функционирующую по другим принципам. Может вы подскажите?
AllexIn
22.12.2019 18:38Но то, что мы существуем и вполне серьезно думаем о создании искусственного интеллекта, само по себе многое говорит об их эффективности.
Не путайте работоспособность с эффективностью. О работоспособности говорит, об эффективности — нет.
И я, например, не могу вспомнить саморазвивающуюся и самоподдерживающуюся сложную систему функционирующую по другим принципам.
А рыба не может вспомнить ни одного сухопутного существа. Это тоже ни о чем не говорит.

EvgenZhaba
22.12.2019 15:56arxiv.org/abs/1912.05510 — ссылка на статью SMiRL: Surprise Minimizing RL inDynamic Environments
arxiv.org/pdf/1912.05510.pdf — на pdf в нейKonkovVladimir
22.12.2019 18:17Об этом уже давно пишут БРИТАНСКИЕ УЧЕНЫЕ — Принцип свободной энергии
epishman
22.12.2019 20:12Прочитал но мало что понял. Ну да, каждый субъект хочет подтвердить свое бытие, информационно уплотниться. Но ведь знания о мире — они нужны для действия, а не сами по себе, то есть субъект должен максимизировать свое действие в этом мире? Но об этом в статье ни слова.
KonkovVladimir
23.12.2019 07:01Ну почему же? Если вы лежите на диване и знаете, что лежите на диване зачем действовать?
Знания позволяют вам каждый вечер находить диван или создать диван если его негде найти!epishman
23.12.2019 12:49Но в жизни не так. Бывает человек вскакивает с дивана, и куда-то бежит, потому что у него внутри что-то переключилось. Кроме того, принцип свободной энергии (какой ужасный термин кстати) не объясняет самоубийство, а в природе это очень распостранено, даже на клеточном уровне (апоптоз). То есть, кроме гомеостаза существует некая целевая функция (или даже несколько), и когда она не выполняется — даже лежание на диване причиняет страдания.
KonkovVladimir
23.12.2019 13:18В жизни речь идет не о отдельном индивидууме, чья жизнь коротка, а о виде в целом. Каждый индивид создает потомство конкурирующее с потомством других индивидов и в итоге на отдельно взятом диване места может не хватить.
Лежание на диване причиняет огромные страдания если у соседа диван шире, мягче и дороже!
Целевая функция биологического организма — передача своего генетического материала большему количеству своих потомков, для бессметного ИИ это может быть не так.epishman
23.12.2019 13:35Целевая функция биологического организма — передача своего генетического материала
Вы не можете знать этого наверняка, пока сексуальная доминанта считается лишь одной из множества других. Клетка, находясь в пред-раковом состоянии совершает апоптоз, почему она это делает? А иногда не делает, и приходится мобилизовать иммунку.
DrugGarry
22.12.2019 15:56Консерваторы против революционеров. Еще очко в пользу консерваторов.
Кто в молодости не был радикалом — у того нет сердца, кто в зрелости не стал консерватором — у того нет ума. (Вроде Дизраэли)
Я всегда следовал правилу: не беги, если можешь стоять; не стой, если можешь сидеть; не сиди, если можешь лежать. (Черчилль)
DesertFlow Автор
22.12.2019 16:01Скорее ландшафт решений и состояний настолько многообразен, что к локальным экстремумам (про которые мы думаем, что они глобальные, хе-хе) можно прийти разными путями. Исследовать за счёт любопытства — хорошо. Находиться в безопасных местах и не высовываться — тоже хорошо. Оба варианта дают примерно одинаковый результат по выживанию. Забавно, что это проявилось даже на таких низких размерностях.
DrugGarry
22.12.2019 16:09Прийти можно разными путями
— согласен.Одинаковый результат по выживанию
— нет. Пессимистов доберется больше. Хотя нужны и те и другие. (Я про эволюцию)
igsend
23.12.2019 10:27Хороший подход, главное чтобы он не вылился в конечном итоге в формулу «Нет человеков = никто не изменяет условия» ;)
DesertFlow Автор
23.12.2019 10:48А к этому вполне может прийти ). Дело в том, что Reinforcement Learning — это попытка создать ИИ из первых принципов. Мотивация, любопытство, награда за успешные действия. Если такой ИИ решит, что для достижения цели ему выгоднее уничтожить всех человеков, то так он и сделает. Что ему может помешать-то? Мы конечно надеемся, что все действительно разумные существа достигают примерно одинакового уровня разумности и поэтому не будут вредить друг другу. Что разум это универсальная характеристика. Но гарантии этому нет.
Кроме того, пока будет создан действительно сильный разумный ИИ, ничто не мешает разработчикам выпускать не до конца разумные версии. У которых такие косяки могут цвести пышным цветом.
Существует и другой способ достичь сильного ИИ — имитационное обучение. Вы просто скармливаете нейросетям огромные датасеты с поведением живых людей. И цель обучения — копировать поведение людей. Примерно как в GAN. Тогда если будете обучать на датасете из "хороших" людей, то гарантированно получите добрый ИИ. Он в принципе не сможет уничтожить человечество, так как был обучен на хороших примерах. Такое его будет внутреннее устройство с точки зрения математики. Конечно, у него не должно быть противоречивых мотиваций и возможности себя изменять, чтобы в процессе размышлений прийти к вредным выводам). Это должна быть фиксированная система, с фиксированными весами нейросети. Просто обладающая памятью. Но с жестко прошитыми в нейронных связях "хорошими" инстинктами. Так что не все так плохо, страхи насчет злобных ИИ сильно преувеличены.
KonkovVladimir
23.12.2019 11:00Если такой ИИ решит, что для достижения цели ему выгоднее уничтожить всех человеков, то так он и сделает. Что ему может помешать-то?
Даже вирусу гриппа хватает ума не уничтожать человечество, ему достаточно «соплей из носа». ИИ всегда может вступить в симбиоз с человеками или паразитировать на них.
Не исключаю, что численность людей может сократиться до уровня американских индейцев, но полного уничтожения не будет.
Это должна быть фиксированная система, с фиксированными весами нейросети. Просто обладающая памятью. Но с жестко прошитыми в нейронных связях «хорошими» инстинктами.
Как только станет возможным копирование знаний из головы человека в нейросеть ИИ, машины станут нашими потомками в определенном смысле слова — продолжат эволюцию.DesertFlow Автор
23.12.2019 17:55Вирус это просто молекула, заключенная в белковую оболочку, да и то не всегда. Как ей может хватать на что-то ума? Просто так сложились химические реакции, что грипп легко побеждается иммунной системой. Но благодаря изменчивости, не искореняется окончательно. Другие вирусы есть смертельные. А есть и полностью исчезнувшие.
Вы наверно имеете ввиду, что эволюция справится и сохранит подобие гомеостаза. Тогда согласен, химические реакции на основе углерода и водорода (т.е. органическая химия) настолько разнообразны, что наверняка от любых болезней можно выработать механизмы защиты. В конце концов, жизнь существует уже три миллиарда лет, значит она устойчива ко всем основным угрозам со стороны химии.
Но ИИ это не молекулы и химические реакции, которые происходили эти миллиарды лет. Как и разум, это нечто новое. Мы потенциально можем создать в космосе мощный источник гамма излучения и прожарить всю планету, что не останется ни одной бактерии. А ещё проще разогнать булыжник до 20% световой, и при столкновении наша планета превратится каплю раскаленной жидкости. Ни одно живое существо не выживет. При таких размерах планеты при столкновениях, да и вообще, ведут себя как капли жидкости в невесомости (поэтому и круглые). Поэтому при достаточной энергии столкновения будет невозможно укрыться в каких-нибудь твердых кусках породы. Потому что их не будет, будет сплошная капля из магмы. Впрочем, при самом ударе на первоначально разлетающихся осколках что-то может и уцелеет. Но уверен, с этим тоже можно что-то придумать. Как раз задачка для сильного ИИ. Которого мы все сейчас дружными усилиями разрабатываем ).
epishman
23.12.2019 18:55Разум не является чем-то новым, и уж тем более не является специфичным для человека. Возможно, символьное мышление и глубина абстракций — это человеческое, но разум вообще довольно частое явление, достаточно изучить муравейник.
red75prim
23.12.2019 19:09И что такое разум? Способность решать хоть какие-то задачи? Сливной бачок унитаза подойдёт?
Вот способность решать любые задачи (или находить другой подход, если задача не решается) — это уже что-то.
epishman
23.12.2019 19:22Разум — это способность уменьшать энтропию. Сливной бачок ее увеличивает, а вот насос уже вполне разумен :))

Ermit
24.12.2019 16:33+2Мир устроен таким странным образом — чтобы навести порядок в одном месте, нужно намусорить в другом, но сильнее… )))
epishman
24.12.2019 17:30Говорят, именно так устроен капитализм, оказывается и все мироздание тоже!!!
Ermit
24.12.2019 17:38Вы все еще по пословицам живете ))))
epishman
24.12.2019 17:44+1Не, я стараюсь все проверять на собственном опыте. Вот например говорят что есть какой-то там рай, а в нем живут гурии. Дай, думаю, попробую… :)))
Ermit
24.12.2019 17:48+1Да, всё верно, как записал Матвей: по вере вашей да будет вам… (Мф 9:29)
epishman
24.12.2019 17:51+1Я вот немножно психологию изучал, и в веру не верю. Гурия — она либо есть, либо ее нет, а все остальное это фап :)))
Ermit
24.12.2019 17:59+1Простите за некоторое менторство, но за психологией Вам следует поизучать квантовую механику, там есть такой объект как Кот Шрёдингера, ничего общего с гуриями, в том числе и по состояниям. Главная особенность КШ в том, что неопределено жив он или мертв.
red75prim
24.12.2019 20:36Не "неопределенно жив он или мёртв", а "находится в суперпозиции состояний жив и мёртв". Как это понимать зависит от используемой интерпретации квантовой механики.
epishman
24.12.2019 21:32Да знаю я этого кота. Дело в том, что квантовая неопределенность она появляется только на микро-объектах, а чем больше частица — тем больше определенности в ее судьбе. Пока какое-то дело находится в стадии идеи — да, доля субъективного очень высока, но как только шестеренки закрутились — попадаешь в зависимость от собственного порождения. Гурия — это большой объект, и от моей веры не появится и не исчезнет. Как собственно и бог.
Mad__Max
24.12.2019 22:27+1Естественно, и насчет мироздания это давно известно. Глобально же энтропия убывать не может, поэтому единственный способ локально снизить энтропию в одном месте — за счет увеличения ее в другом месте, причем сильнее чем будет снижение в первом, так что суммарно в этом процессе она все-равно увеличится.
Только способность понижать свою энтропию это не свойство или определение разума. Это может быть одним из определений жизни и различения живого от неживого, а не разумного от неразумного.
А вот разум тут не причем, разве что как один из способов увеличения эффективности этого процесса развившийся у живых объектов.epishman
24.12.2019 22:33Совершенно верно. Поэтому и придумали сатану, низвергнутого в центр земли, потому что нужен энтропийный градиент. По поводу разума есть разные теории, я придерживаюсь той, которую изложил. Качественное отличие живого от неживого было опровергнуто в момент синтеза мочевины, так же будет и с разумом, и установится мнение что любой негэнтропийный процесс есть проявление разума. Другой метрики у нас нет.
red75prim
24.12.2019 22:58И ещё кто-нибудь наконец догадается померить объем, плотность, температуру и содержание хим. элементов в Мыслителе Родена и бронзовой болванке и установит, что никакой разницы нет.
Mad__Max
24.12.2019 23:28+1Причем тут вообще мочевина? Речь не о различии материи (химических веществ), где принципиальной разницы между живым и не живым нет кроме сложности строения. А о жизни как способе организации материи и процессов происходящих в ней.
Возможность самостоятельно снижать свою энтропию — одно из возможных определений является ли наблюдаемое явление жизнью или не является.
По этому определению например бактерии — это живые организмы. А вот например вирусы — уже нет, т.к. не способны это делать самостоятельно — только исключительно при помощи живого носителя/хозяина выполняющего за них большую часть критических процессов, а не просто обеспечивающих наличие подходящих условий среды в виде наличия пит. веществ, подходящей температуры и т.д. как для бактерий и других паразитов или симбиотов которые так же зачастую не могут жить в природе без хозяина, но от хозяина им нужна только подходящая среда.
Насос как выше упоминали естественно не является живым или тем более разумным — т.к. опять же неспособен понижать свою энтропию без помощи действительно живого. В данном случае в виде человека для начала создавшего его, а потом заправляющего топливом/энергией, ремонтирующего и т.д.
Т.е. можно сказать, что живой является система из человека + насоса. Но не сам насос отдельно.epishman
25.12.2019 03:36Смотрите, органические молекулы радикально отличаются от неорганических своей энергетической неустойчивостью, для объяснения этого ранше существовала целая теория витализма. Считалось что невозможно синтезировать органику из неорганики без духа святого. Синтез мочевины разбил эту теорию в прах, и сейчас даже синтез на РНК считается не чудом, а химическим процессом.
Однако мы ошибочно связываем разум с человеком, или там с жизнью, а на самом деле это просто одно из физических свойств мироздания — ВНТ энтропию увеличивает, а все что ее уменьшает можно назвать разумом. Это уходит корнями в теорию информации, и даже в квантовую механику. Пока это фрик-теория, но успехи машинного обучения все сильнее стирают грань между разумным и механистичным, и рано или поздно сотрут.
red75prim
24.12.2019 23:35+1Другой метрики у нас нет.
Если вернуться к теме статьи, то с таким подходом получается, что и ИИ не нужен — сделали тепловой насос помощнее и всё. Энтропию понижает? Да. Сильнее чем люди? При достаточной мощности — да. Супер-разум!
epishman
25.12.2019 03:44Эмм, подождите. Человек снижает энтропию сильнее, если считать на единицу потраченной энергии, одна из проблем например — очень низкое энергопотребление полета насекомых, механизмы пока так не могут. Человек может сделать механизм, который будет снижать энтропию более эффективно (насос), чем просто ведрами носить, то есть человек разумнее насоса!
red75prim
25.12.2019 07:18А физическое определение-то какое? Понижать энтропию будет насос, а не человек. Каким прибором определить, что вот этот человек стоящий в сторонке — конструктор насоса? Хотя произвёл он только листки бумаги с закорючками и до этого экземпляра насоса вообще не дотрагивался.
epishman
25.12.2019 10:31Да все просто жеж. Человек придумал насос. Насос обладает негэнтропийной мощностью X. Значит мощность человека не меньше X. Потом этот человек придумал холодильник с мощностью Y. Суммируем X + Y. И так далее. Разум надо считать по его материальным проявлениям, психологи давно это поняли, придумали бихевиоризм, и перестали в человеческих глюках и чувствах копаться. Хотя ради денег почему бы и нет )
red75prim
25.12.2019 11:02А кто и как будет определять кто что придумал? Почему это X+Y относится к человеку, а не к программе, просчитывавшей варианты конструкций?
epishman
25.12.2019 11:09К программе тоже относится. В моей теории разумен даже насос, программа разумнее насоса, потому что может его просчитать, человек разумнее программы потому что может ее написать. Нет другого способа померить эффективность разума, кроме как по его негэнтропийным проявлениям, такая точка зрения была популярна в 70-е, но потом все загнулось из за невозможности точно все посчитать. Трудовая теория стоимости и госплан загнулись ровно по той же причине — сложно, а компьютеров тогда не было. А сейчас все инструменты для подсчета результатов человеческой деятельности налицо.
ni-co
23.12.2019 19:11Добавлю: использование языка для создания и ХРАНЕНИЯ новых абстракций(библиотек) специфично для человека.
epishman
23.12.2019 19:18+1Строго говоря, не совсем. У врановых, обезьян и дельфинов экспериментально доказано существование абстракций второго уровня. Словарный запас обезьяны положим 500 слов, из них «банан груша слива» — это абстракции первого уровня. «Фрукты мясо» — абстракции второго уровня. Но обезьяна способна понять предложение «еда кроме фруктов», то есть по сути третий уровень. Просто у человека этих уровней несколько десятков, отличие чисто количественное.
DesertFlow Автор
24.12.2019 04:41Разум не является чем-то новым, и уж тем более не является специфичным для человека.
Так как нет четкого математического критерия, по которому можно отличить разумное существо от неразумного (если вам известен такой критерий, то приведите его формулу), то будем считать что разум — это что-то на уровне человека. Да, некоторые животные иногда проявляют зачатки разумности, и это хорошо — ведь мы отдаленные родственники с точки зрения эволюции.
Но за образец настоящего сильного разума и интеллекта надо брать идеализированного человека. Благородного, умного, красивого. Такого как я.
epishman
24.12.2019 12:42-1Так как нет четкого математического критерия, по которому можно отличить разумное существо от неразумного (если вам известен такой критерий, то приведите его формулу)
Конечно есть. Разум — это количество уменьшенной энтропии на единицу потраченной энергии, то есть R = -dS / dE. Паровой двигатель с насосом безусловно разумен, так как тратит энергию сжигания угля на подъем воды на высоту (что противоестественно), но поскольку вы придумали и двигатель и насос, потратив меньше каллорий, чем если бы носили воду ведрами — то вы разумнее насоса, а тот, кто придумал вас — еще разумнее, и так далее.DesertFlow Автор
25.12.2019 02:06но поскольку вы придумали и двигатель и насос, потратив меньше каллорий, чем если бы носили воду ведрами — то вы разумнее насоса
Я тоже сначала подумал, что можно так сравнивать степень разумности. Взять какой-то набор задач и посмотреть какой процент от этих задач может выполнить животное. Если кошка выполнила 1 из 10 задач, которые сделал человек, то значит ее разумность составляет 10% от человеческой.
Но так мы упираемся в выбор задач. Нет критерия, по которому их набирать. И в предельных случаях получим явно неправильные значения. Если взять задачу по перемещению из пункта А в пункт Б. Которую человек может выполнить. То и паровоз ее тоже может выполнить. Успех в 1 из 1. Формально, на этом наборе задач паровоз 100% разумен, так как выполнил 100% человеческих задач. Но это явно не то определение разума, которое нам хотелось бы. Оно формально верное, но не решает поставленную перед ним задачу.
epishman
25.12.2019 03:52Мертик нет, непонятно как изменение энтропии считать от деятельности человека или кошки. Но вот, например, демон Максвела должен быть совершенно разумным, именно поэтому классическая физика пытается доказать невозможность его существования!
red75prim
25.12.2019 07:31Не "пытается доказать", а "физический демон Максвелла невозможен". Чтобы он работал нужен не разум, а свободная энергия. То есть система должна быть незамкнутой. Вариант, когда демон управляется нематериальной душой, — это тоже незамкнутая система.
epishman
25.12.2019 10:35Так мы и не говорим про замкнутую систему, разум потребляет энергию это факт. но у Демона мы этот разум можем точно померить по моей формуле, кстати патентую единицу измерения разума — один демаксвел ©.
red75prim
25.12.2019 07:52Да не может быть физического определения разумности. Совершенно неважно сколько негэнтропии произведёт система на калорию съеденного бутерброда. Важно то, насколько эффективно система действует при достижении целевых состояний и насколько широк круг целевых состояний и условий окружающей среды, в которых система действует эффективно.
epishman
25.12.2019 10:26Если величину нельзя измерить численно, то и науки нет. Например я могу посчитать количество целевых состояний (привет Шенону), но что такое действовать? Что такое эффективно? Пока мы будем пользоваться неточными эмоционально-окрашенными словами, будем топтаться на месте, как древние с теорией теплорода.
KonkovVladimir
24.12.2019 07:30Мы потенциально можем создать в космосе мощный источник гамма излучения и прожарить всю планету, что не останется ни одной бактерии. А ещё проще разогнать булыжник до 20% световой, и при столкновении наша планета превратится каплю раскаленной жидкости. Ни одно живое существо не выживет.
Безжалостный космический завоеватель с альфа-центавры, перелогинтесь.
Результаты ваших сценариев полны неожиданности, «новизны» и «сюрпризов» в значении которое Карл Фристон вкладывает в эти понятия.
Если ИИ научится избегать сюрпризов он никогда не сделает так.
Не исключаю конечно появления фашиствующего ИИ с газовыми камерами и Lebensraum — ну вот и закон Годвина, подъехал.
epishman
23.12.2019 13:12В реальных организмах кроме собственно И очень много хардкода, то есть жестко прописанных правил, например запрет на спаривание с чужим видом — достигается химическим способом — чужая самка пахнет отвратительно, это кстати причина столь низкой распостраненности межрассовых браков. Родители вшивают кучу импринтов в доразумном периоде — «красть нехорошо», в результате чего человек разумен примерно процентов на 20, остальное — чистая механика. Так же и роботов будут делать — вошьют ему аппаратный запрет на атаку человека, и все. Или не вошьют, и все.
biakus
23.12.2019 10:34Прямо сразу вспомнил про книгу про гомеостатику www.ozon.ru/context/detail/id/33076387

mr_stepik
23.12.2019 14:47Подскажите, что за «oracle agent» на графиках скорости обучения?
DesertFlow Автор
23.12.2019 18:07Оракул — это алгоритм, знающий правильный ответ. Часто используется в машинном обучении, чтобы сравнивать эффективность обучаемых алгоритмов. Это как бы предельный случай, лучше которого уже ничего не может быть. Как оракул реализован здесь я не обратил внимания, но скорее всего на основе истинного распределения вероятностей узнаваемости мест. Так как оно должно набраться на статистике эпизода, то не сразу падает на графике, а постепенно. P.S. я когда-то потратил кучу времени, чтобы найти oracle алгоритм, который так же фигурировал в сравнениях в одной статье. Показывал намного лучшие результаты. Я думал, это метод конкурентов ). А оказалось вот так.

Frankenstine
25.12.2019 21:27ИИ, пытающийся избежать проблем, научился сложному поведению
А если сравнить его поведение с поведением ИИ, ведомому любопытством, то чьё поведение будет «сложнее»? Сдаётся мне, «ленивый» ИИ проиграет «любопытному».DesertFlow Автор
26.12.2019 01:11В данном случае, см. графики, где как раз сравнивается поведение с двумя лучшими моделями на основе любопытства, победил ленивый. Но скорее всего это из-за подобранных окружений. В них много опасностей, поэтому ленивый (считай — избегающий любой новизны) оказался в выигрыше.
epishman
Ну, конкуренция процессов возбуждения и торможения это основа работы нервной системы. С нетерпением жду появления у ИИ всех атрибутов классификации психики по Фрейду / Юнгу, ну там сознание, предсознание, подсознание, эго, супер-эго, ИД, а также внутренних запретов, комплексов, импринтов, проекций и трансферов. Если принять теорию, что разум есть свойство вселенной, и его законы глобальны, то ИИ обречен рано или поздно оказаться на кушетке психоаналитика!
adictive_max
Тут можно ещё вспомнить, что известный цикл Азимова «Я, Робот» был не пор инженеров, а про робо-психологов.
red75prim
Но кушетка психоаналитика будет до релиза, а не после.
epishman
Смотря что релизом считать. Человек-то обучается постоянно, и в основном без учителя, всякие алисы в общем тоже пытаются. И тоже будут попадать в тупики смыслов, переобучаться, импринтиться всякой дрянью, в общем работа для дата-сайентистов будет всегда :)
red75prim
В случае эволюции никаких релизов конечно нет. Но выпускать в серию автопилот, у которого после 100 тыс. км начинается экзистенциальный кризис, никто не даст. Поправят или встроят "кушетку с психоалитиком" в систему, если это действительно окажется законом.
В этом и отличие ИИ от остальных технологий. Любая человеческая деятельность потенциально может быть автоматизирована. Включая работу психоаналитика.
epishman
Забавную вещь читал, к сожалению ссылку не найду, но одним из методов борьбы с переобучением нейросетей является случайный сброс части весов, такое себе «прореживание связей» с последующим новым циклом обучения. И тут я вспомнил где это уже встречал — ишемический инсульт! И сразу стало понятна причина алкоголизма — люди инстинктивно борются с переобучением!!!
sgjurano
Это называется Dropout — веса не участвуют в forward-шаге с заданной вероятностью.
epishman
Большое спасибо, мне это как-раз было нужно, похоже, биологи еще не догадались, что деградация мозга порой необходима для выживания!
PS
Психологи знали давно, отсюда и гештальт-терапия.
staticlab
В одной статье из "Науке и жизни" 80-х аналогичная потребность была связана просто со сном. Только там, кажется, было про сети Кохонена, и что на какое-то время нужно прекратить поступление полезного сигнала, чтобы нейросеть «привела себя в порядок».
epishman
Насколько я понимаю, во сне идет преобразование кратковременной памяти в долговременную, потому что аксоны долго прорастают. Алкоголизм или курение это другое — там за счет местной ишемии идет убийство нейронов, в результате чего сеть становится проще. Кстати забавно, что мозг гениев содержит в среднем меньше связей чем мозг простолюдинов. То есть количество бывает мешает качеству, и если человек набрал за жизнь кучу вредных импринтов — проще dropout, чем мучаться.
JekaMas
Определиться бы ещё про каждое из упомянутых вами понятий: сознание...
epishman
Есть радикальный подход, что сознание (оно же разум) — это вторая движущая сила, противоположная энтропии. Везде, где мы наблюдаем процессы упорядочения — там проявляется разум. То есть разум это вообще не свойство мозга, это свойство пространства, если угодно. Пока непонятно, в каких единицах мерить разум, похоже, что-то вроде «скорость убывания энтропии на единицу чего-нибудь», то есть должна получиться размерность мощности (энтропия это аналог работы). Диалектика и гомеостатическое мироздание жеж :)
JekaMas
И есть еще несколько десятков определений, как сознания, так и разума(mind).
Ни единения, ни существенного прогресса в этом вопросе нет. И это приводит к невеселому выводу, что неизвестно, что наблюдать у ИИ или чему именно его учить, что мерить, как метрику успешности "сознания" или "разума".