

В этой статье я расскажу как за 30 минут настроить среду для машинного обучения, создать нейронную сеть для распознавания изображений a потом запустить ту же сеть на графическом процессоре (GPU).
Для начала определим что такое нейронная сеть.
В нашем случае это математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге, и при попытке смоделировать эти процессы.
Нейронные сети не программируются в привычном смысле этого слова, они обучаются. Возможность обучения — одно из главных преимуществ нейронных сетей перед традиционными алгоритмами. Технически обучение заключается в нахождении коэффициентов связей между нейронами. В процессе обучения нейронная сеть способна выявлять сложные зависимости между входными данными и выходными, а также выполнять обобщение.
С точки зрения машинного обучения, нейронная сеть представляет собой частный случай методов распознавания образов, дискриминантного анализа, методов кластеризации и прочих методов.
Оборудование
Сначала разберемся с оборудованием. Нам необходим сервер с установленной на нем операционной системой Linux. Оборудование для работы систем машинного обучения требуется достаточно мощное и как следствие дорогое. Тем, у кого нет под рукой хорошей машины, рекомендую обратить внимание на предложение облачных провайдеров. Необходимый сервер можно получить в аренду быстро и платить только за время использования.
В проектах, где необходимо создание нейронных сетей я использую сервера одного из российских облачных провайдеров. Компания предлагает в аренду облачные серверы специально для машинного обучения с мощными графическими процессорами (GPU) Tesla V100 от компании NVIDIA. Если коротко: использование сервера с GPU может быть в десятки раз быть более эффективным (быстрым) по сравнению с аналогичным по стоимости сервером где для вычислений используется CPU (всем хорошо знакомый центральный процессор). Это достигается за счет особенностей архитектуры GPU, которая быстрее справляется с расчетами.
Для выполнения примеров описанных далее, мы приобрели на несколько дней такой сервер:
- SSD диск 150 ГБ
- ОЗУ 32 ГБ
- Процессор Tesla V100 16 Gb с 4-мя ядрами
На машину нам установили Ubuntu 18.04.
Устанавливаем окружение
Теперь установим на сервер все необходимое для работы. Поскольку наша статья в первую очередь для начинающих, буду рассказывать в ней о некоторых моментах, которые пригодятся именно им.
Очень много работы при настройке среды выполняется через командную строку. Большинство из пользователей в качестве рабочей ОС используют Windows. Стандартная консоль в этой ОС оставляет желать лучшего. Поэтому мы будем использовать удобный инструмент Cmder/. Скачиваем mini версию и запускаем Cmder.exe. Далее необходимо подключится к серверу по протоколу SSH:
ssh root@server-ip-or-hostnameВместо server-ip-or-hostname указываете IP адрес или DNS имя вашего сервера. Далее вводим пароль и при успешном подключении мы должны получить примерно такое сообщение.
Welcome to Ubuntu 18.04.3 LTS (GNU/Linux 4.15.0-74-generic x86_64)Основным языком для разработки ML моделей является Python. А наиболее популярной платформой для его использование по Linux является Anaconda.
Установим ее на наш сервер.
Начинаем с обновления локального менеджера пакетов:
sudo apt-get updateУстанавливаем curl (служебная программа командной строки):
sudo apt-get install curlСкачиваем последнюю версию Anaconda Distribution:
cd /tmp
curl –O https://repo.anaconda.com/archive/Anaconda3-2019.10-Linux-x86_64.shЗапускаем установку:
bash Anaconda3-2019.10-Linux-x86_64.shВ процессе установки необходимо будет подтвердить лицензионное соглашение. При успешной установке вы должны будете увидеть это:
Thank you for installing Anaconda3!Для разработки ML моделей сейчас создано множество фреймворков, мы работаем с наиболее популярными: PyTorch и Tensorflow.
Использование фреймворка позволяет увеличить скорость разработки и использовать уже готовые инструменты для стандартных задач.
В этом примере будем работать с PyTorch. Установим его:
conda install pytorch torchvision cudatoolkit=10.1 -c pytorchТеперь нам необходимо запустить Jupyter Notebook — популярный у ML специалистов инструмент разработки. Он позволяет писать код и сразу видеть результаты его выполнения. Jupyter Notebook входит в состав Anaconda и уже установлен на нашем сервере. Необходимо подключится к нему из нашей настольной системе.
Для этого мы сначала запустим Jupyter на сервере указав порт 8080:
jupyter notebook --no-browser --port=8080 --allow-rootДалее открыв в нашей консоли Cmder еще одну вкладку (верхнее меню — New console dialog) подключимся по порту 8080 к серверу через SSH:
ssh -L 8080:localhost:8080 root@server-ip-or-hostnameПри вводе первой команды нам будет предложены ссылки для открытия Jupyter в нашем браузере:
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-18788-open.html
Or copy and paste one of these URLs:
http://localhost:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
or http://127.0.0.1:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
Воспользуемся ссылкой для localhost:8080. Скопируйте полный путь и вставьте в адресную строку локального браузера вашего ПК. Откроется Jupyter Notebook.
Создадим новый ноутбук: New — Notebook — Python 3.
Проверим корректную работу всех компонентов которые мы установили. Введем в Jupyter пример кода PyTorch и запустим выполнение (кнопка Run):
from __future__ import print_function
import torch
x = torch.rand(5, 3)
print(x)
Результат должен быть примерно таким:
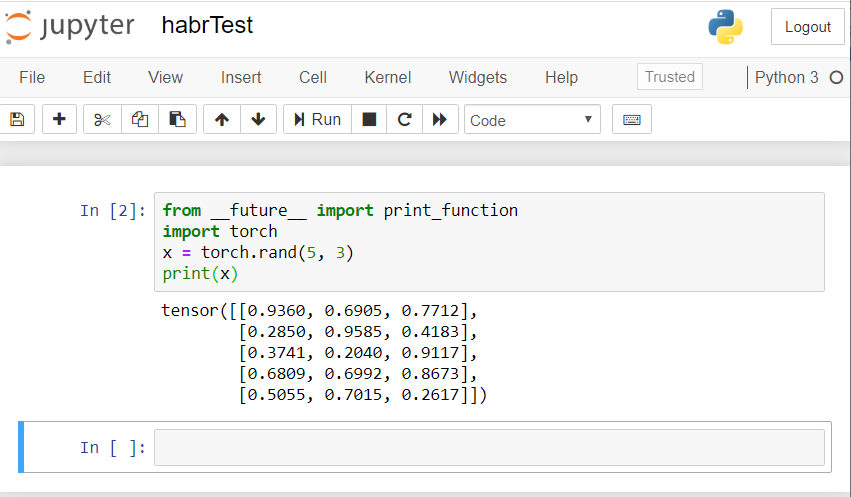
Если у вас аналогичный результат — значит мы все настроили правильно и можем приступать к разработке нейронной сети!
Создаем нейронную сеть
Будем создавать нейронную сеть для распознавания изображений. За основу возьмем данное руководство.
Для тренировки сети мы будем использовать общедоступный набор данных CIFAR10. У него есть классы: «самолет», «автомобиль», «птица», «кошка», «олень», «собака», «лягушка», «лошадь», «корабль», «грузовик». Изображения в CIFAR10 имеют размер 3x32x32, то есть 3-канальные цветные изображения размером 32x32 пикселей.
Для работы мы будем использовать созданный PyTorch пакет для работы с изображениями — torchvision.
Мы сделаем следующие шаги по порядку:
- Загрузка и нормализация наборов обучающих и тестовых данных
- Определение нейронной сети
- Тренировка сети на тренировочных данных
- Тестирование сети на тестовых данных
- Повторим тренировку и тестирование с использованием GPU
Весь приведенный ниже код мы будем выполнять в Jupyter Notebook.
Загрузка и нормализация CIFAR10
Скопируйте и выполните в Jupyter следующий код:
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')Ответ должен быть такой:
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verifiedВыведем несколько тренировочных образов для проверки:
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

Определение нейронной сети
Рассмотрим сначала как работает нейронная сеть по распознаванию изображений. Это простая сеть прямой связи. Он принимает входные данные, пропускает их через несколько слоев один за другим, а затем, наконец, выдает выходные данные.
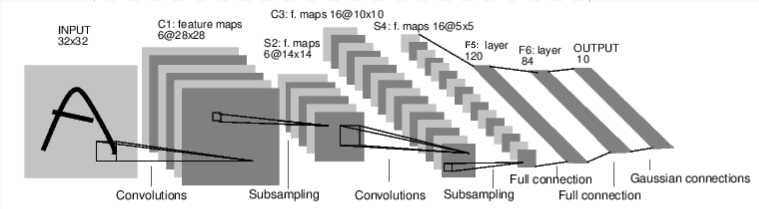
Создадим подобную сеть в нашей среде:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
Определим так же функцию потерь и оптимизатор
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)Тренировка сети на тренировочных данных
Начинаем тренировку нашей нейронной сети. Обращаю внимание что после этого как вы запустите на выполнение этот код, нужно будет подождать некоторое время до завершения работы. У меня это заняло 5 мин. Для обучение сети нужно время.
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
Получим такой результат:
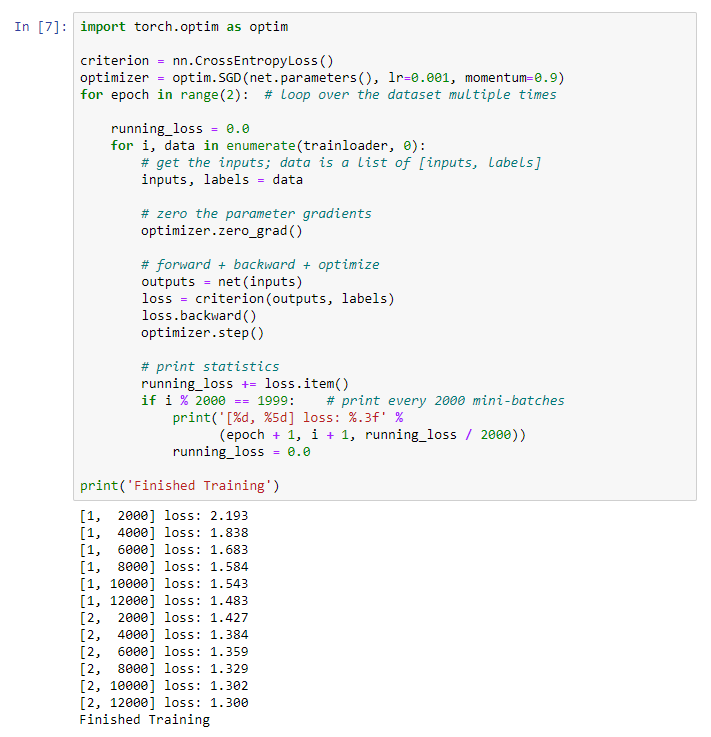
Сохраняем нашу обученную модель:
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)Тестирование сети на тестовых данных
Мы обучили сеть использую набор обучающих данных. Но нам нужно проверить, научилась ли сеть вообще чему-либо.
Мы проверим это, предсказав метку класса, которую выводит нейронная сеть, и проверив ее на предмет истинности. Если прогноз верен, мы добавляем образец в список правильных прогнозов.
Давайте покажем изображение из тестового набора:
dataiter = iter(testloader)
images, labels = dataiter.next()
# print images
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
Теперь попросим нейронную сеть сообщить нам что на этих картинках:
net = Net()
net.load_state_dict(torch.load(PATH))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))
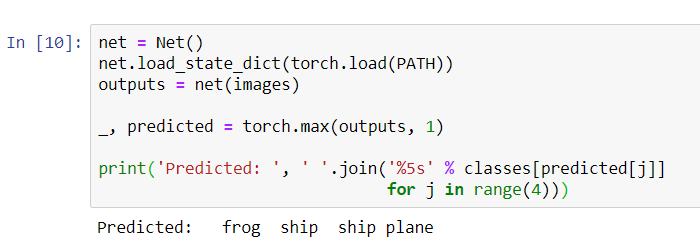
Результаты кажутся довольно хорошими: сеть определила правильно три картинки из четырех.
Давайте посмотрим, как сеть работает во всем наборе данных.
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))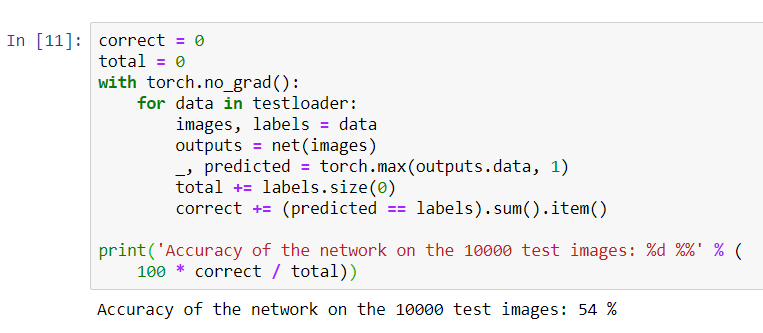
Похоже сеть что-то знает и работает. Если бы он определяла классы наугад, то точность бы была 10%.
Теперь посмотрим какие классы сеть определяет лучше:
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))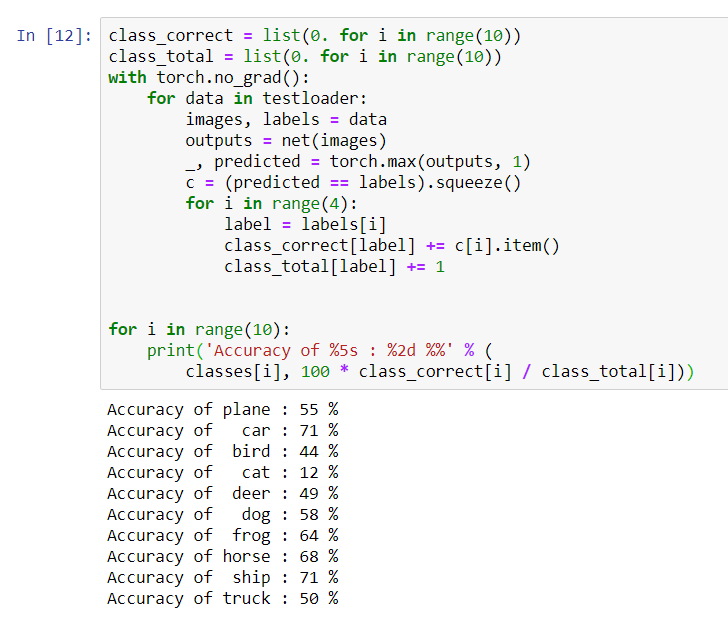
Похоже что лучше всего сеть определяет автомобили и корабли: 71% точности.
Итак сеть работает. Теперь попробуем перенести ее работу на графический процессор (GPU) и посмотри что поменяется.
Тренировка нейронной сети на GPU
Сначала объясню коротко что такое CUDA. CUDA (Compute Unified Device Architecture) — платформа параллельных вычислений, разработанная NVIDIA, для общих вычислений на графических процессорах (GPU). С помощью CUDA разработчики могут значительно ускорить вычислительные приложения, используя возможности графических процессоров. На нашем сервере, который мы приобрели, данная платформа уже установлена.
Давайте сначала определим наше GPU как первое видимое устройство cuda.
device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
# Assuming that we are on a CUDA machine, this should print a CUDA device:
print ( device )
Отправляем сеть на GPU:
net.to(device)Так же нам придется отправлять входы и цели на каждом шаге и в GPU:
inputs, labels = data[0].to(device), data[1].to(device)Запустим повторное обучение сети уже на GPU:
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data[0].to(device), data[1].to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')В этот раз обучение сети продолжалось по времени около 3 минут. Напомним что тот же этап на обычном процессоре длился 5 минут. Разница не существенная, это происходит потому что наша сеть не такая большая. При использовании больших массивов для обучения разница между скоростью работы GPU и традиционного процессора буде возрастать.
На этом кажется все. Что нам удалось сделать:
- Мы рассмотрели что такое GPU и выбрали сервер на котором он установлен;
- Мы настроили программное окружение для создания нейронной сети;
- Мы создали нейронную сеть для распознавание изображений и обучили ее;
- Мы повторили обучение сети с использованием GPU и получили прирост в скорости.
Буду рад ответить на вопросы в комментариях.





Ramzess_II
мда, начинающему будет очень тяжело разобраться в этом…
mongohtotech Автор
определенная подготовка нужна конечно ))
ktod
Очевидно же, под «начинающий» тут понимается «начинающий в ML», а не «в computer science».