

В 2019 году мы стали свидетелями блистательного использования машинного обучения. Модель GPT-2 от OpenAI продемонстрировала впечатляющую способность писать связные и эмоциональные тексты, превосходящие наши представления о том, что могут генерировать современные языковые модели. GPT-2 не является какой-то особенно новой архитектурой – она очень напоминает Трансформер-Декодер (decoder-only Transformer). Отличие GPT-2 в том, что это поистине громадная языковая модель на основе Трансформера, обученная на внушительном наборе данных. В этой статье мы посмотрим на архитектуру модели, позволяющую добиться таких результатов: подробно рассмотрим слой внутреннего внимания (self-attention layer) и применение декодирующего Трансформера для задач, выходящих за рамки языкового моделирования.
Содержание
- Часть 1: GPT-2 и языковое моделирование
- Что такое языковая модель
- Трансформеры для языкового моделирования
- Одно отличие от BERT'а
- Эволюция блока Трансформера
- Экспресс-курс по нейрохирургии: заглядывая внутрь GPT-2
- Заглянем поглубже
- Конец первой части: GPT-2, дамы и господа
- Часть 2: визуализация внутреннего внимания
- Внутреннее внимание (без маскирования)
- 1 – Создание векторов Запроса, Ключа и Значения
- 2 – Подсчет коэффициентов
- 3 – Суммирование
- Визуализация маскированного внутреннего внимания
- Маскированное внутреннее внимание в GPT-2
- Вы сделали это!
- Часть 3: за пределами языкового моделирования
- Машинный перевод
- Суммаризация
- Трансферное обучение
- Генерация музыки
- Заключение
- Материалы
Часть 1: GPT-2 и языковое моделирование
Что же такое языковое моделирование?
Что такое языковая модель
В статье Word2vec в картинках было описано, что такое языковая модель – по сути, это модель машинного обучения, которая смотрит на несколько слов в предложении и предсказывает следующее слово. Наиболее известная языковая модель – это клавиатура смартфона, которая по мере набора текста подсказывает вам продолжение.
В этом смысле можно сказать, что GPT-2 представляет собой алгоритм предсказывания следующего слова клавиатурного приложения, но более тяжеловесный и умный, чем тот, что реализован в вашем телефоне. GPT-2 была обучена на большом наборе данных размером 40 Гб (WebText), который OpenAI собрали из интернета в рамках своего исследовательского проекта. С точки зрения объема хранения данных, клавиатурное приложение, например SwiftKey, занимает до 78 Мб, в то время как самый маленький вариант обученной GPT-2 использует уже 500 Мб для хранения всех ее параметров, а самая большая модель GPT-2 – в 13 раз больше (так что она может занимать до 6,5 Гб).

Отличный способ поэкспериментировать с GPT-2 предоставляет сервис AllenAI GPT-2 Explorer. Он использует GPT-2 для отображения предсказания десяти наиболее вероятных слов (наряду с их вероятностью), идущих после введенного вами слова.
Трансформеры для языкового моделирования
Как мы увидели в статье Трансформер в картинках, релизная модель Трансформера состояла из энкодера и декодера – каждый представляет собой стек т.н. блоков Трансформера. Эта архитектура подходила для машинного перевода – задачи, где архитектуры энкодер-декодер показывали хорошие результаты и в прошлом.
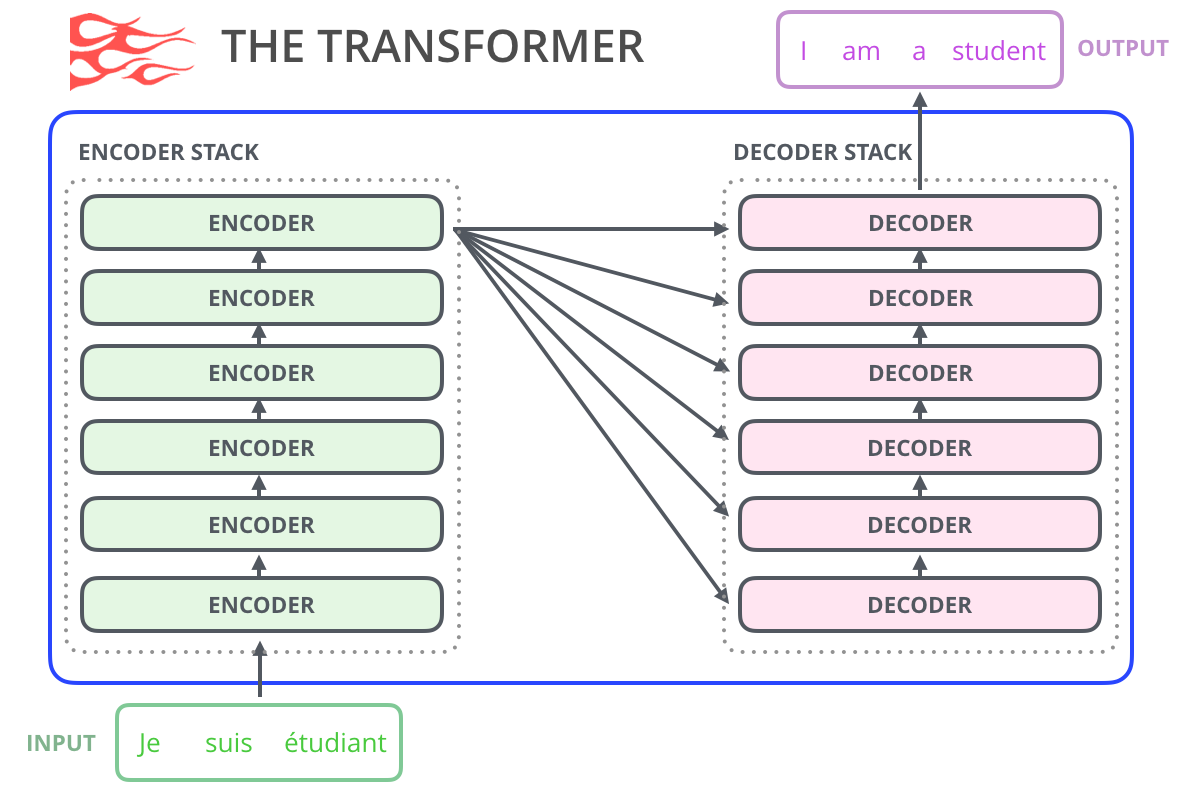
Последовавшие за релизом исследования показали, что мы можем отбросить декодер или энкодер и использовать всего один стек блоков Трансформера, надстраивая эти блоки столько, сколько вообще возможно, скармливая им огромные объемы текстовых данных для обучения и выполняя громадные объемы вычислений на них (некоторые из этих моделей требуют сотни тысяч долларов для обучения и даже миллионы в случае с AlphaStar).
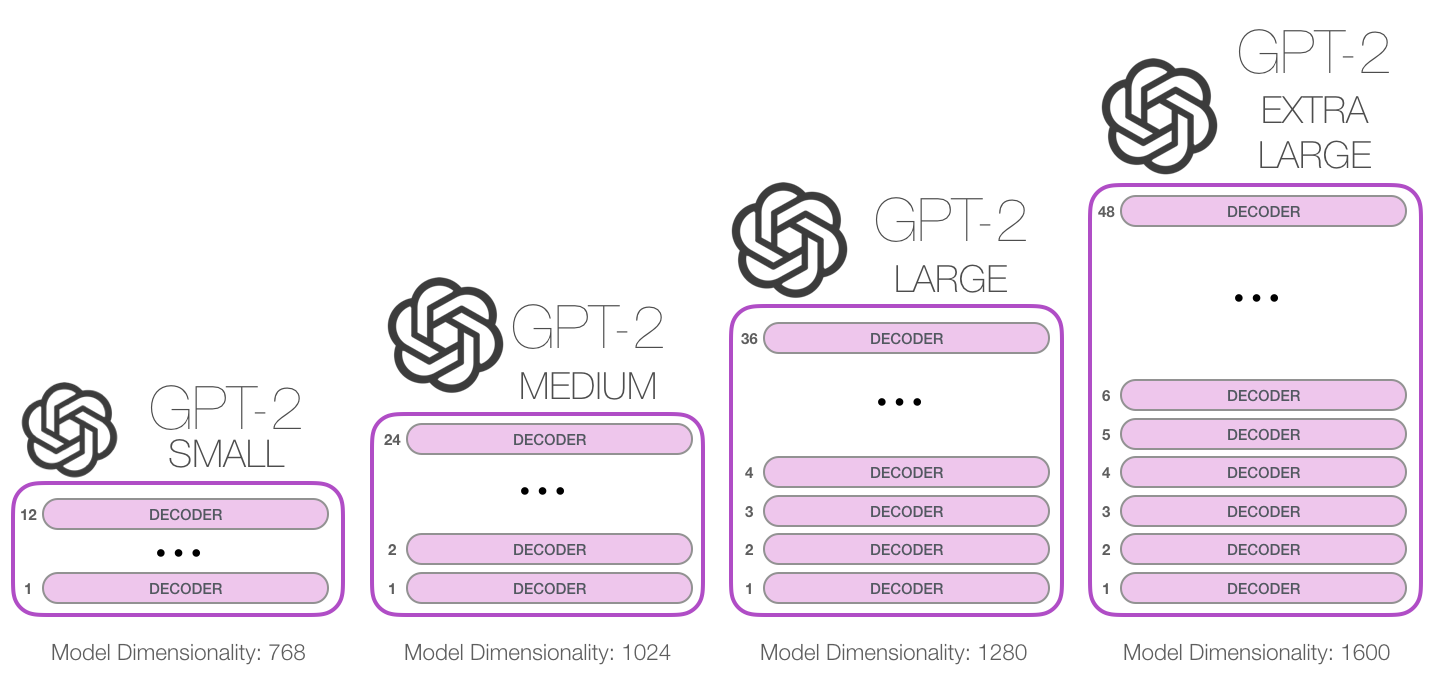
Как высоко мы можем надстраивать эти блоки? Выясняется, что это и есть одно из главных отличий между моделями GPT-2 разных размеров:
Одно отличие от BERT'а
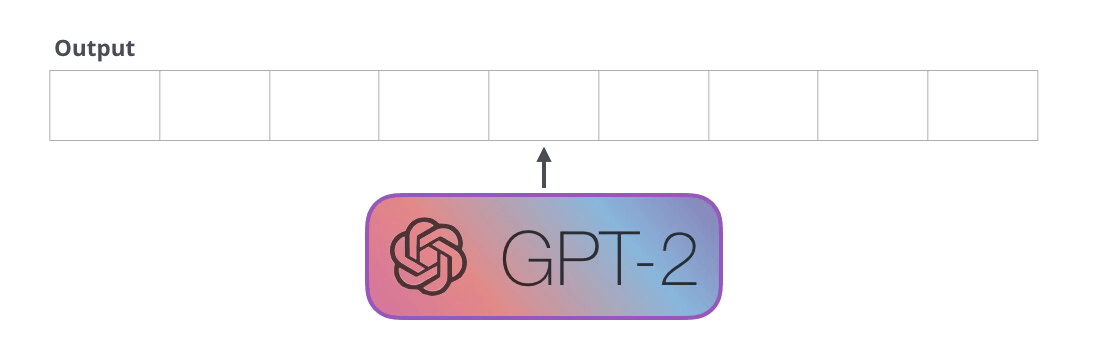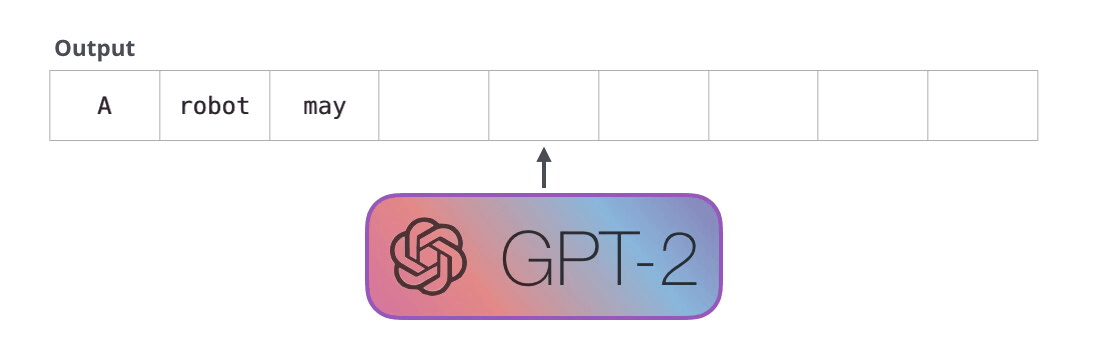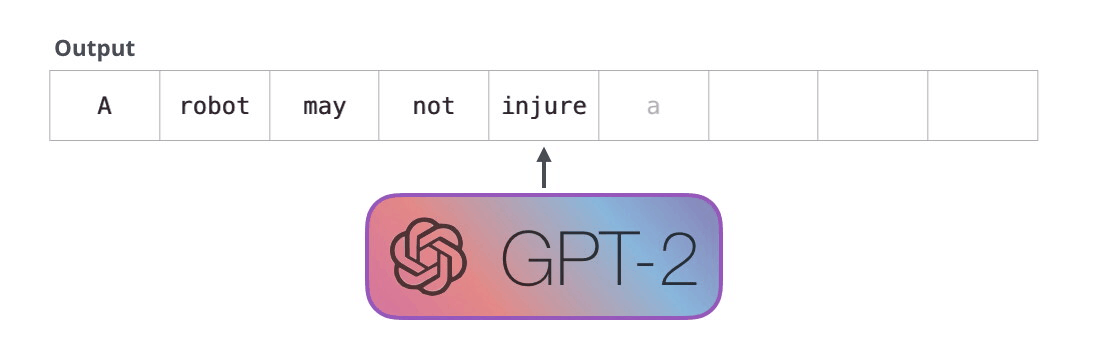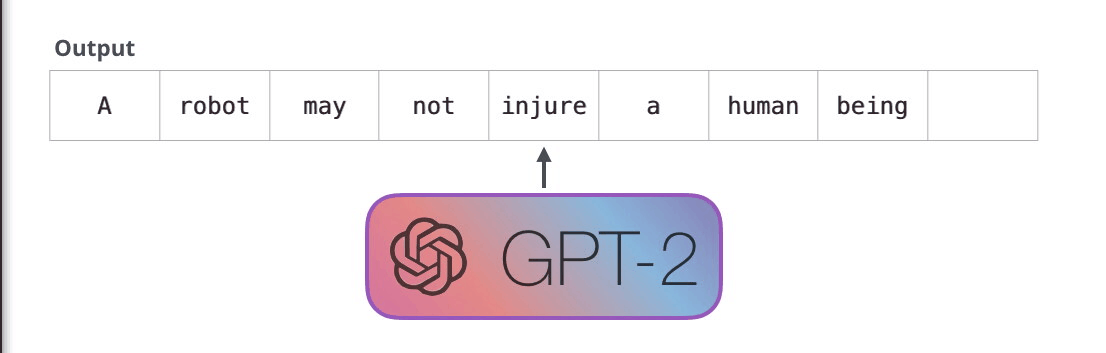
Первый закон робототехники:
Робот не может причинить вред человеку или своим бездействием допустить, чтобы человеку был причинён вред.
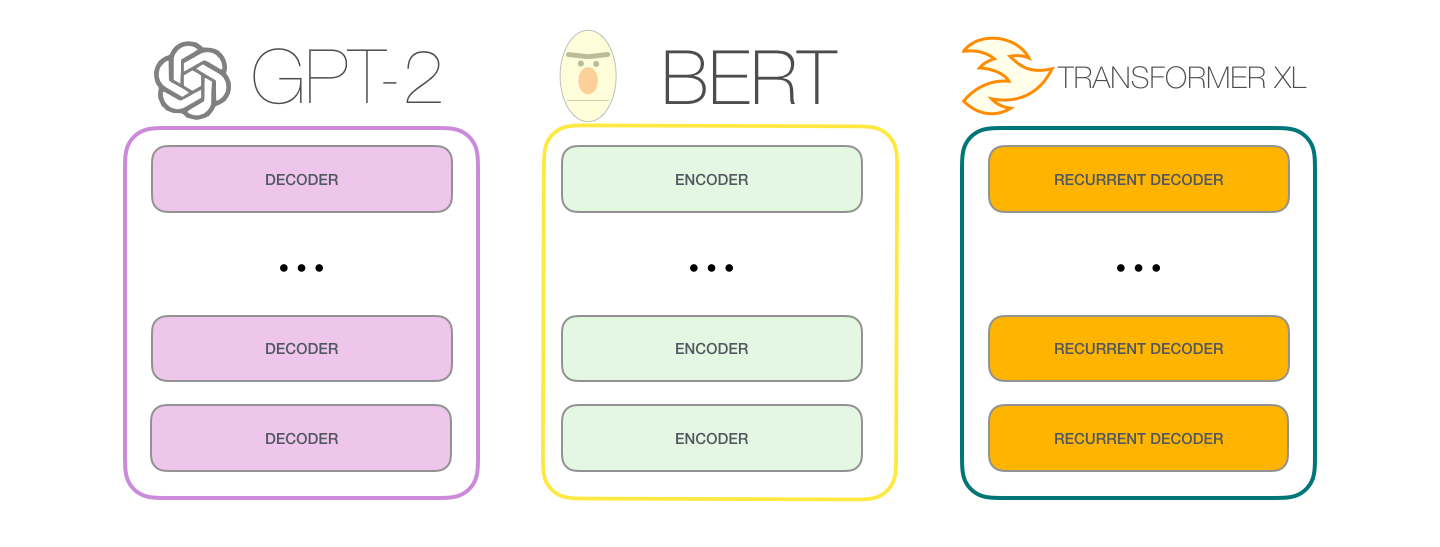
Модель GPT-2 построена с помощью блоков декодера Трансформера. BERT же, напротив, использует блоки энкодера. Мы посмотрим на разницу двух подходов в следующей части. Но одно ключевое различие состоит в том, что GPT-2, как и все традиционные языковые модели, генерирует на выходе один токен за раз. Посмотрим для примера, как хорошо обученная модель GPT-2 генерирует первый закон робототехники:
На деле происходит следующее: после того, как был вычислен каждый токен, он добавляется во входную последовательность. И эта новая последовательность подается на вход модели на следующем шаге. Эта идея называется «авторегрессией» (auto-regression) и именно она сделала RNN сети неоправданно эффективными.

GPT-2 и некоторые новые модели вроде TransformerXL и XLNet авторегрессивны по своей природе. BERT нет. И это своего рода компромисс. Потеряв авторегрессию, BERT приобрел способность включать контекст по обе стороны слова для получения лучших результатов. XLNet вернул себе авторегрессию, найдя при этом альтернативный способ инкорпорировать контекст по обе стороны.
Эволюция блока Трансформера
Релизная статья предложила два типа блоков Трансформера.
Блок энкодера
Первый – это блок энкодера:

Блок энкодера из релизной статьи Трансформера может принимать на вход последовательности ограниченной длины (например, 512 токенов). Если входная последовательность меньше этого ограничения, то мы можем просто заполнить остаток последовательности нулями.
Блок декодера
Второй – это блок декодера, который архитектурно мало отличается от энкодера. Он позволяет обращать внимание на особые сегменты энкодера:

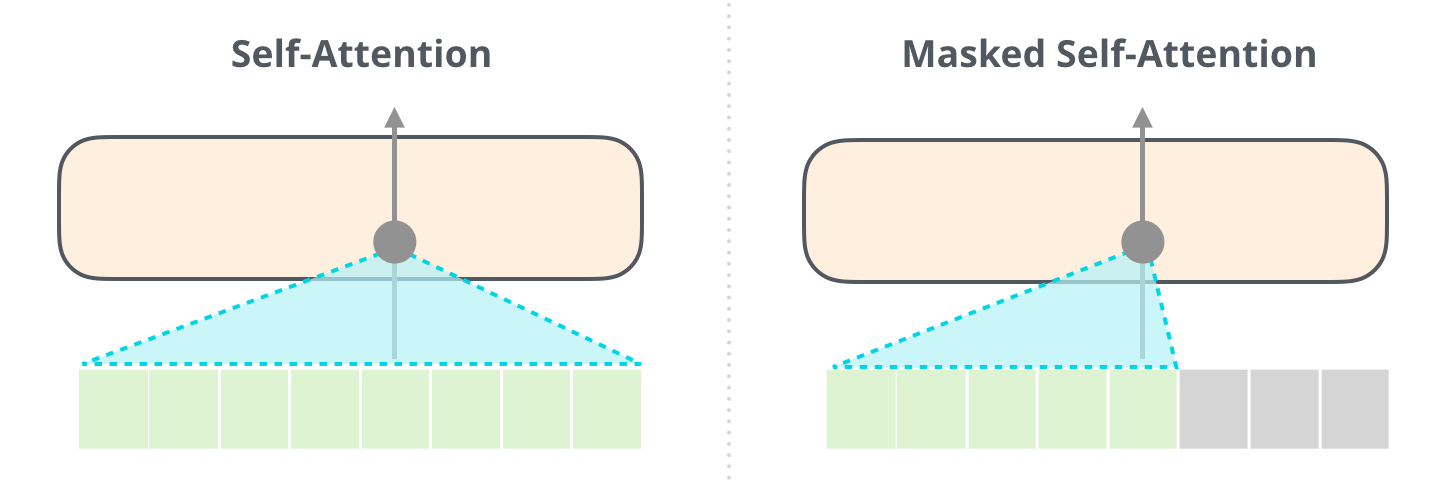
Ключевая разница заключается в механизме работы слоя внутреннего внимания и состоит в том, что здесь будущие токены маскируются не заменой слова на [mask] токен, как в BERT'е, а с помощью изменения процесса подсчета внутреннего внимания и блокирования информации от токенов, находящихся справа от той позиции, которая высчитывается в данный момент.
Если, например, мы хотим подсветить траекторию позиции #4, мы можем увидеть, что можно обратиться лишь к этому и предыдущему токену:
Важно провести различие между внутренним вниманием, которое использует BERT, и маскированным внутренним вниманием GPT-2. Обычный блок внутреннего внимания позволяет достать до токенов справа. Маскированное внутреннее внимание не позволяет этого сделать:
Блок декодирования
Следуя за релизной, статья «Generating Wikipedia by Summarizing Long Sequences» предложила другую организацию блоков трансформера, позволяющую создавать языковые модели: она отбросила энкодер Трансформера. Поэтому давайте назовем эту модель «Трансформер-Декодер». Эта ранняя языковая модель на основе Трансформера состояла из стека с 6 блоками декодера Трансформера:
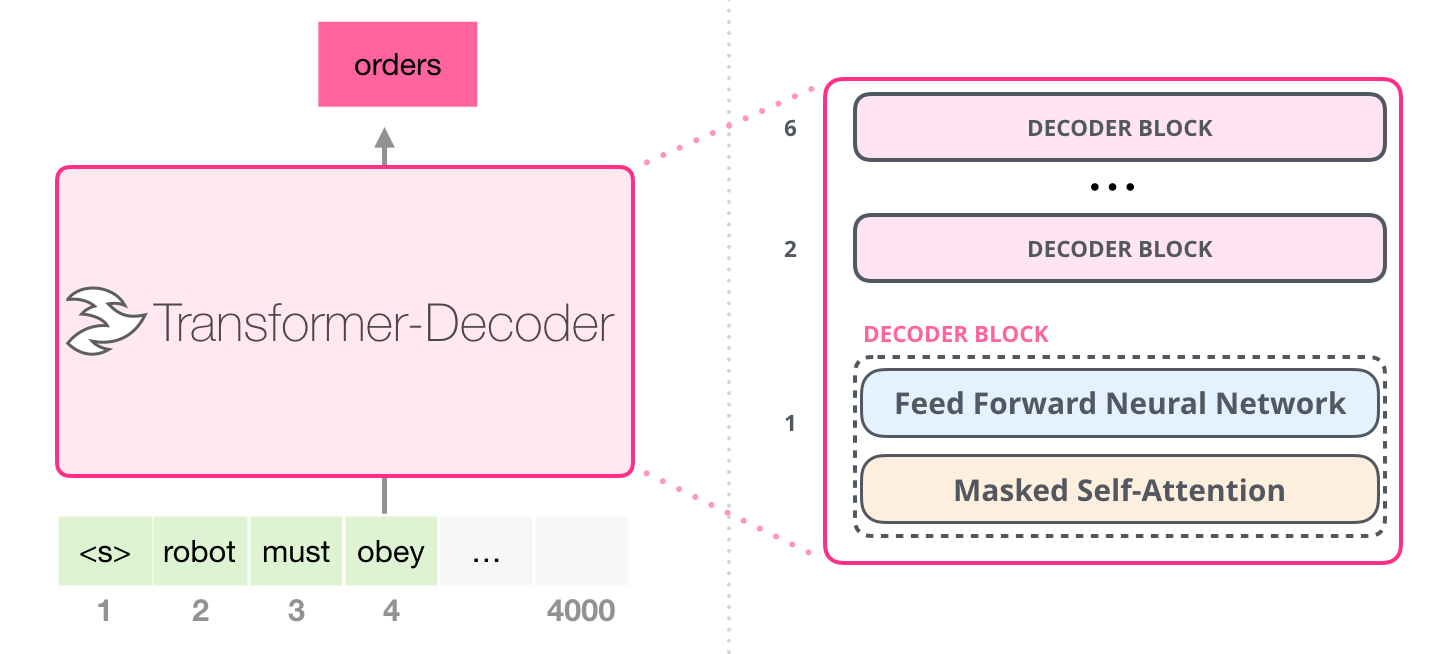
Блоки декодера идентичны. На развернутом изображении одного из них видно, что слой внутреннего внимания маскирован. Заметьте, что модель теперь может обращаться к 4000 токенов в отдельном сегменте – значительное улучшение по сравнению с 512 токенами оригинального трансформера.
Эти блоки весьма похожи на оригинальные блоки декодера, кроме того, что они отбросили второй слой внутреннего внимания. Схожая архитектура была исследована в статье «Языковое моделирование на уровне символов с более глубоким внутренним вниманием», где была создана языковая модель для предсказания одной буквы/символа за один период времени.
Модель GPT-2 от OpenAI использует именно такие блоки декодирования.
Экспресс-курс по нейрохирургии: заглядывая внутрь GPT-2
Загляни вглубь, и ты увидишь, как слова режут глубоко в моём мозге. Гроза обжигает, быстро обжигает, словесный нож вводит меня в безумие, безумие, да. (Budgie)
Давайте положим обученную GPT-2 модель на наш операционный стол и посмотрим, как она работает.

GPT-2 может обработать 1024 токена. Каждый токен проходит через все блоки декодера по своей собственной траектории.
Самый простой способ запустить обученную GPT-2 – пустить ее в свободное плавание (что технически называется генерацией безусловных выборок) или дать ей пример (подсказку), чтобы она могла говорить на определенную тему (т.е. генерация интерактивных условных выборок). В первом случае мы можем просто передать ей стартовый токен, и модель начнет генерировать слова (обученная модель использует в качестве стартового токена <|endoftext|>; обозначим его просто как <|s|>).
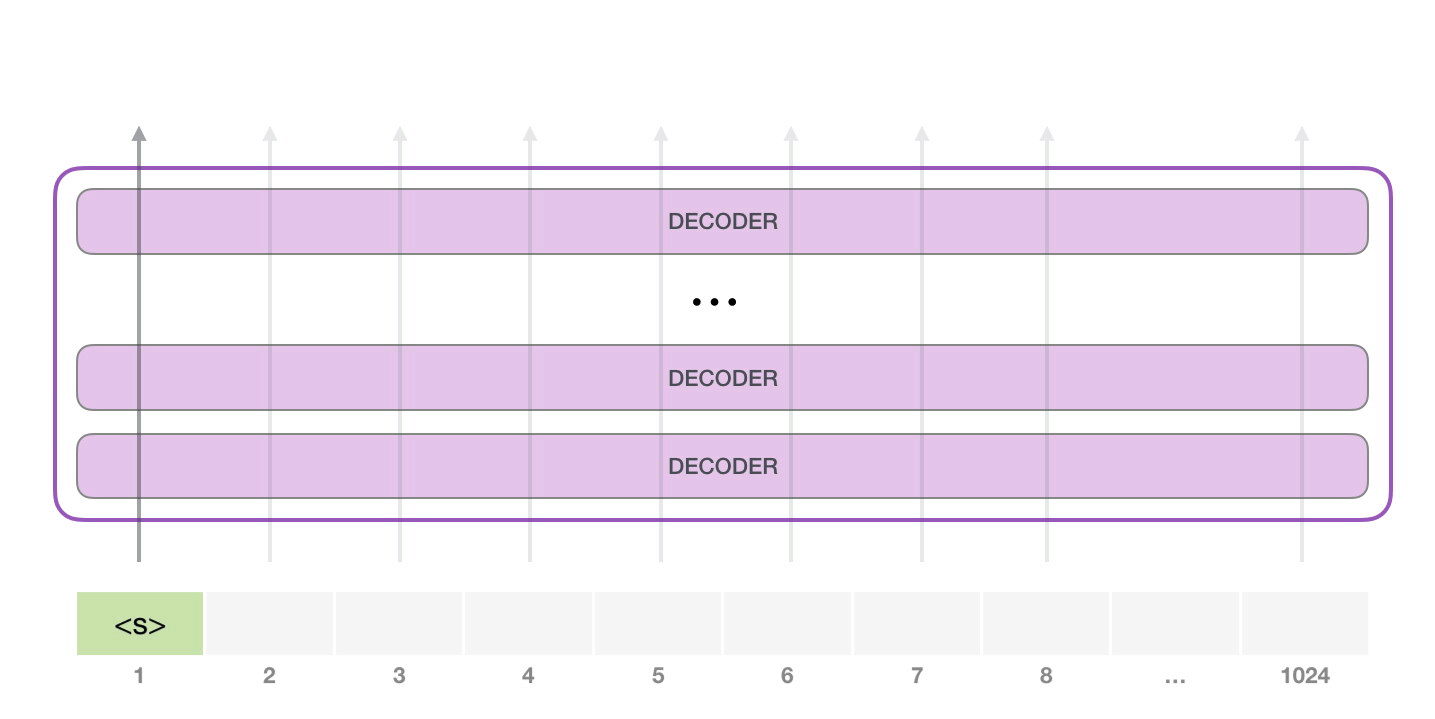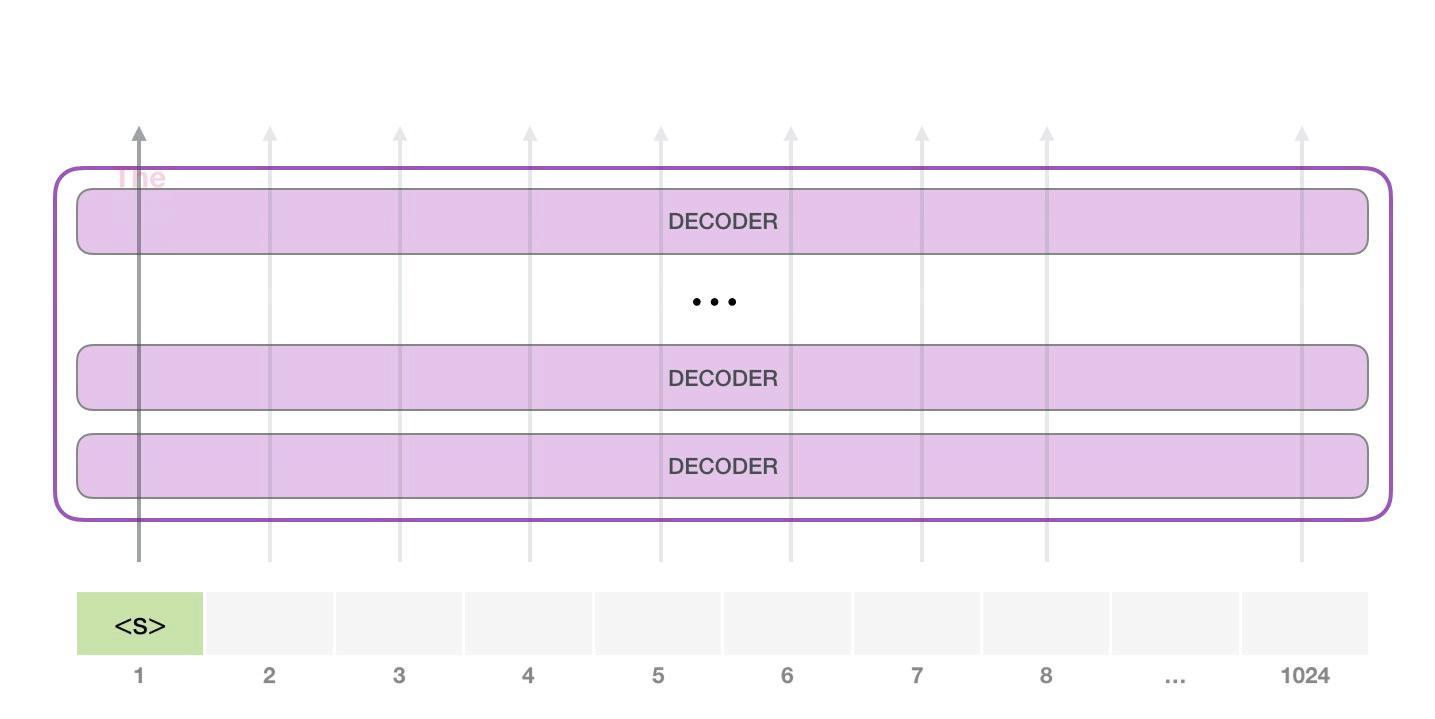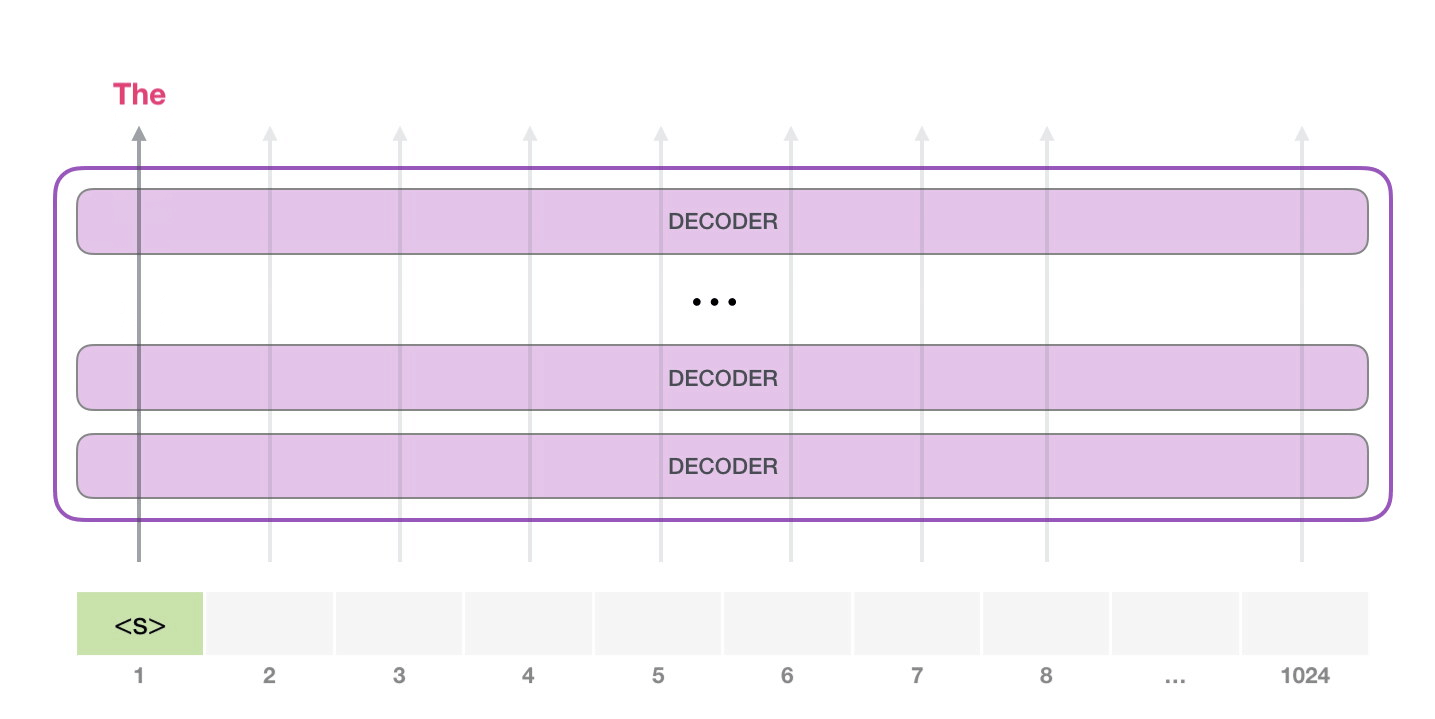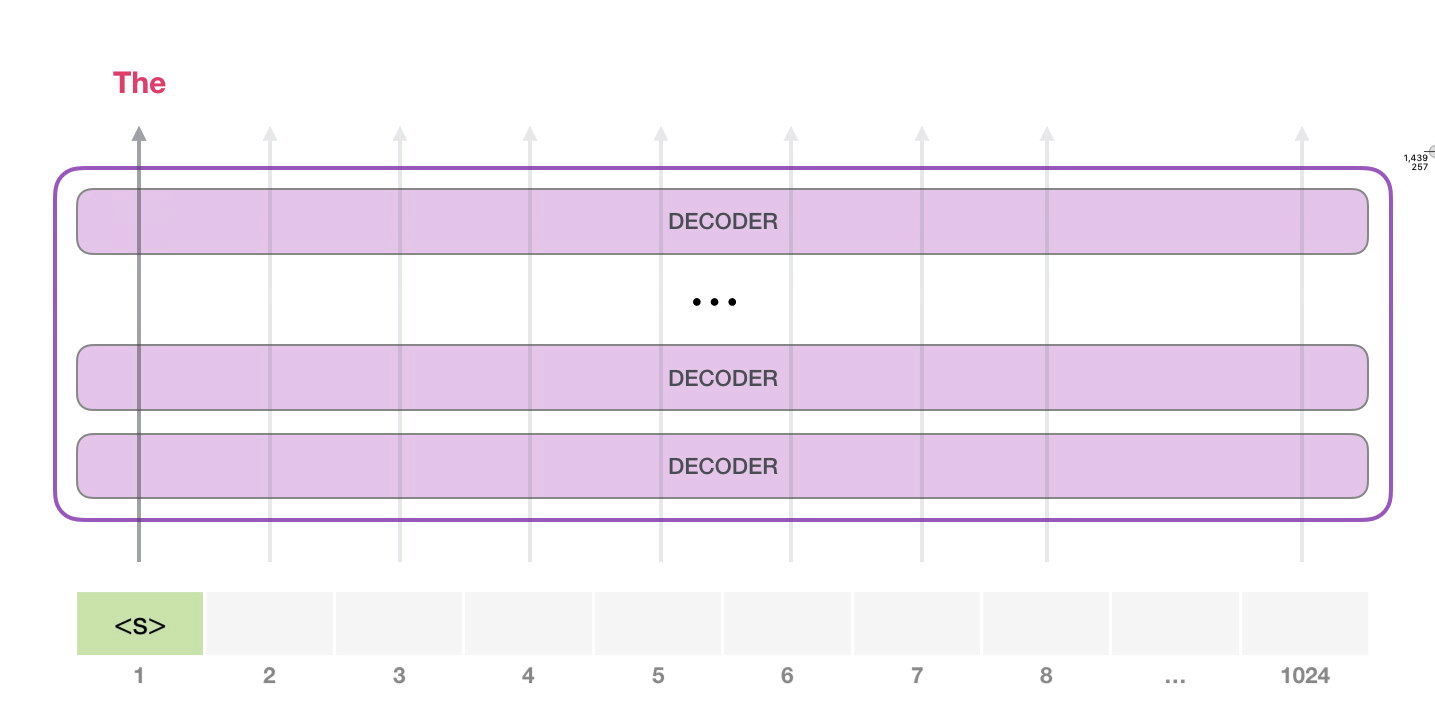
У модели есть только один входной токен, так что первая траектория окажется единственной активной. Токен успешно обрабатывается всеми слоями декодера и преобразуется в вектор, которому присваивается коэффициент (score) относительно словаря – всех слов, которые модель знает (50 тысяч слов у GPT-2). В нашем случае мы выбрали токен с наибольшей вероятностью – «the». Но есть шанс что-то перепутать – вы знаете, как бывает, когда вы пытаетесь нажать на предложенное слово на клавиатуре, и оно застревает в повторяющемся цикле, единственный выход из которого – нажать на второе или третье предложенное слово. То же может произойти и здесь. GPT-2 имеет параметр top-k, который мы можем использовать для того, чтобы модель рассматривала некоторую выборку слов, а не только топ слово (последнее, по сути, является случаем top-k = 1).
На следующем этапе мы добавляем наш выход во входную последовательность и модель предсказывает следующее слово:
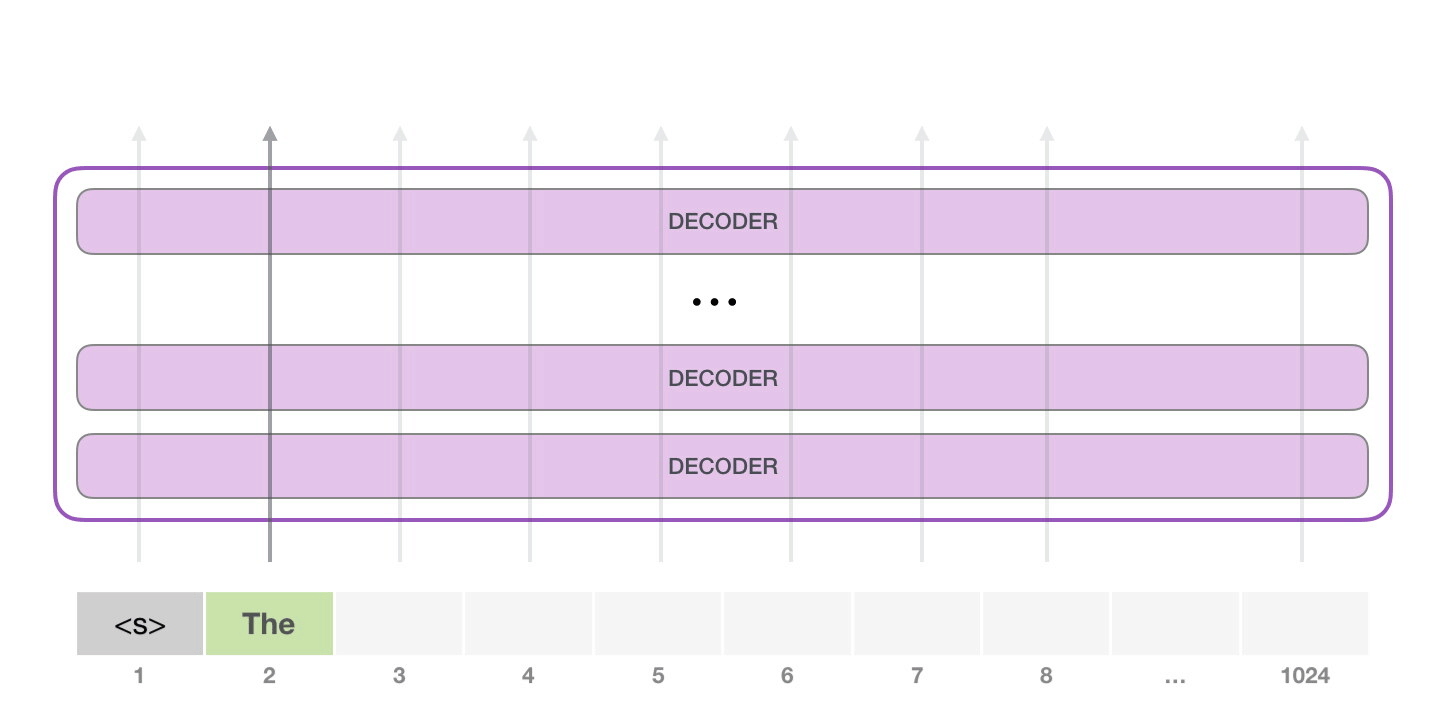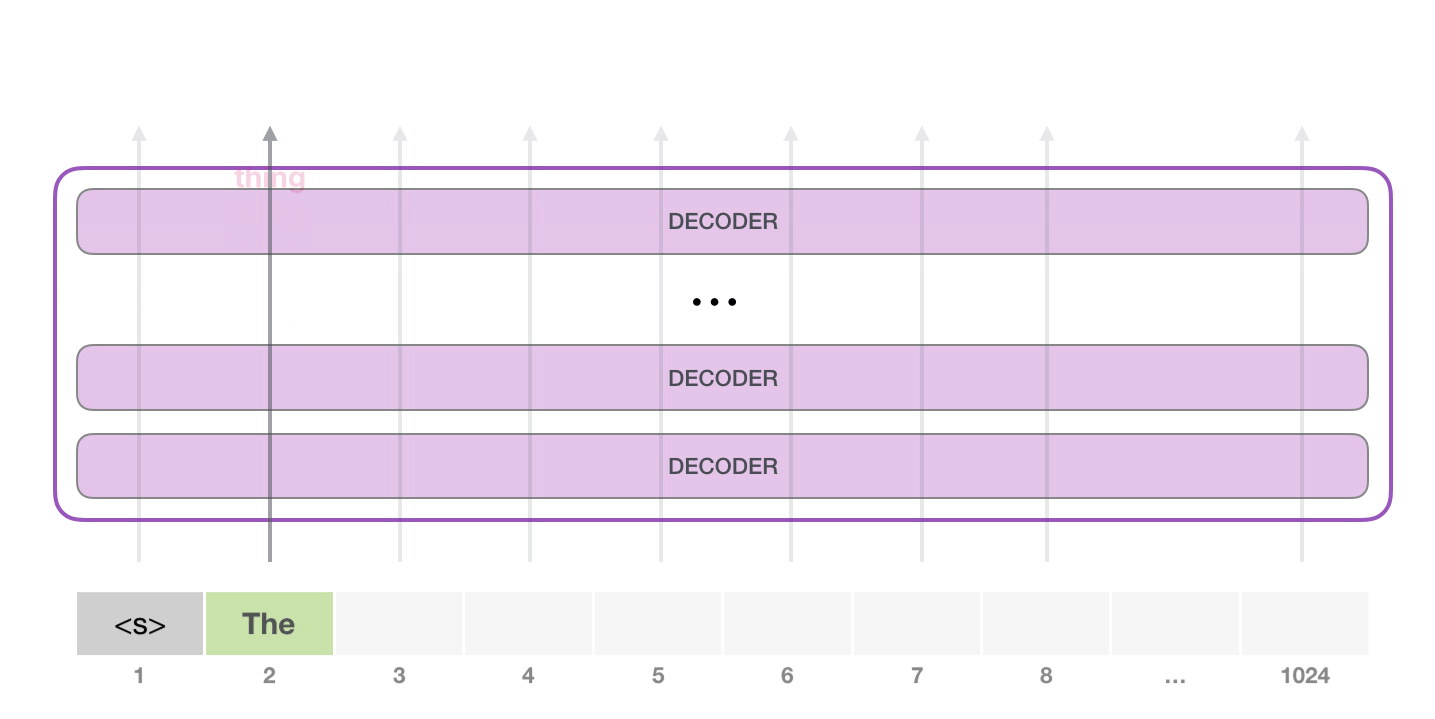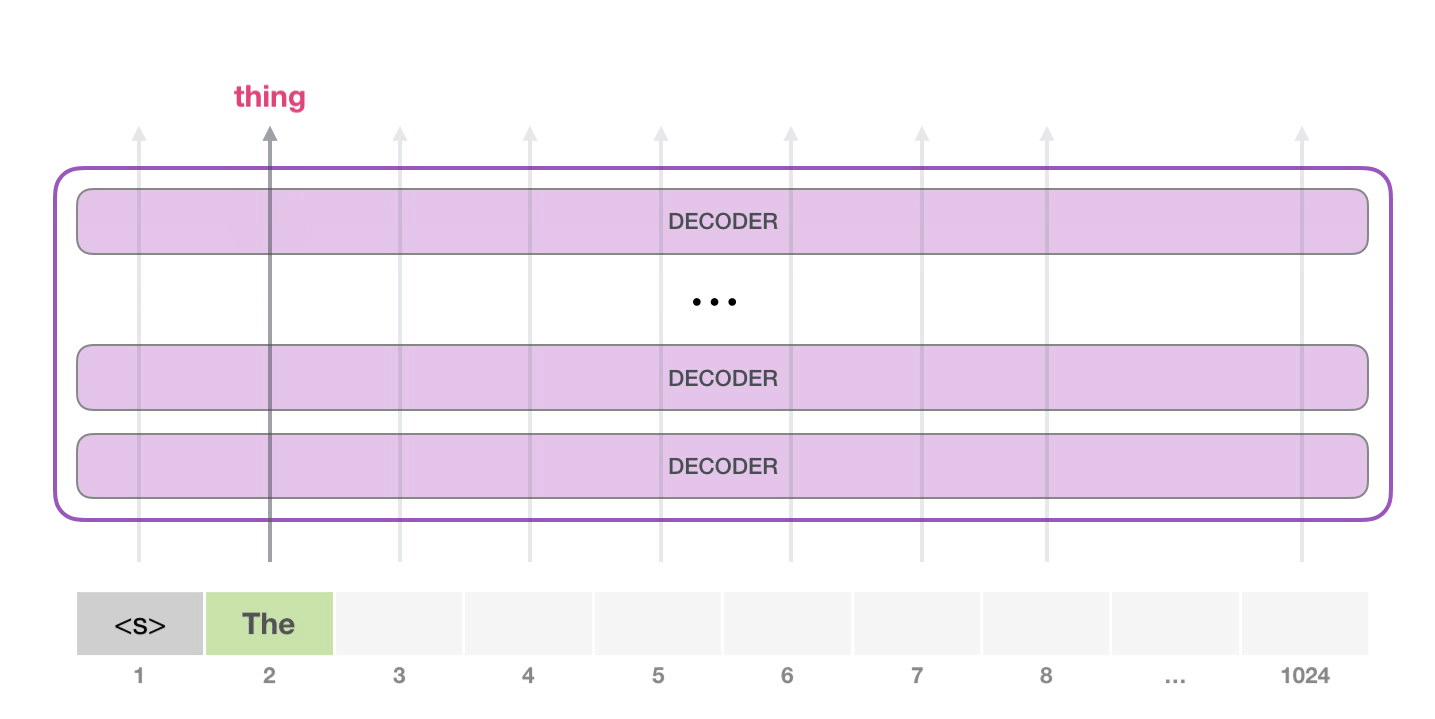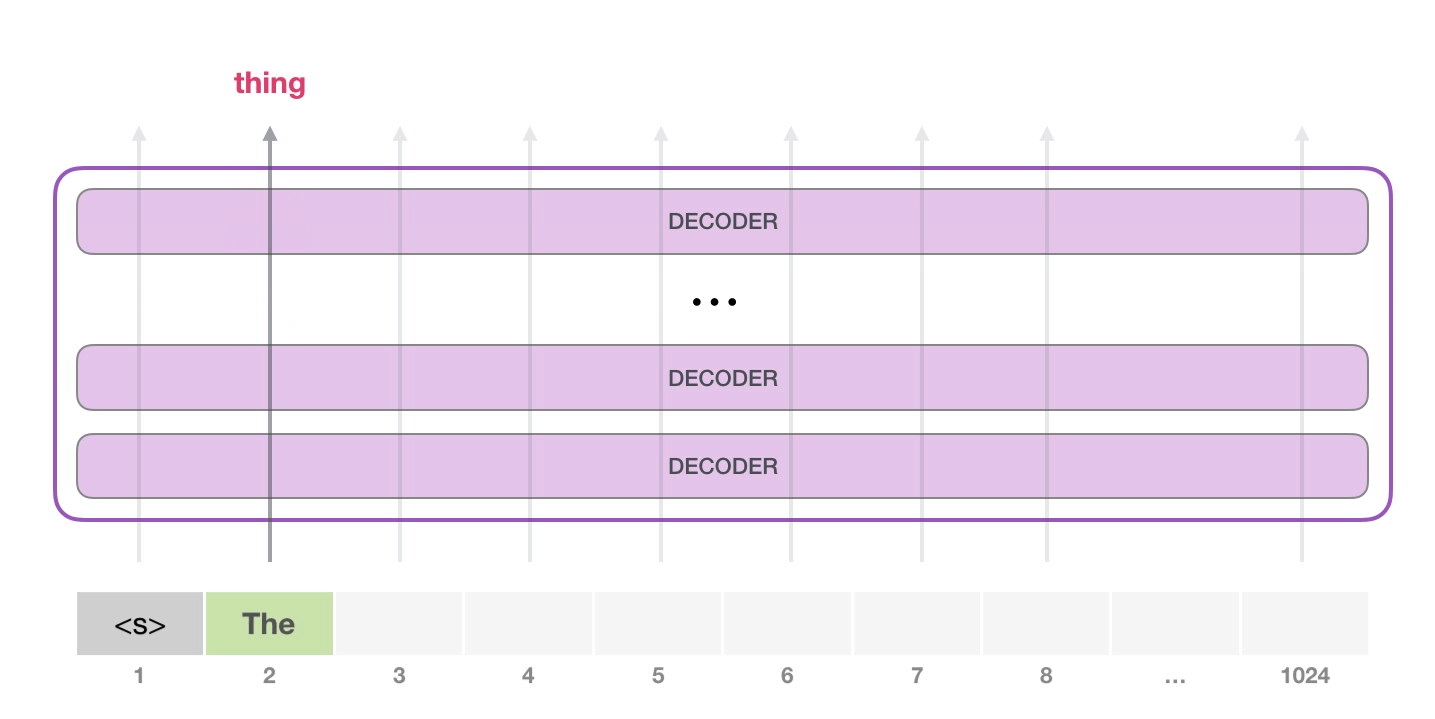
Обратите внимание, что в этой итерации активна лишь вторая траектория. Каждый слой GPT-2 сохраняет свою собственную интерпретацию первого токена и будет использовать ее в обработке второго (более подробно мы расскажем чуть ниже в разделе о внутреннем внимании). GPT-2 не переинтерпретирует первый токен после появления второго.
Заглянем поглубже
Кодирование входа
Рассмотрим модель более детально. Начнем со входа. Как и в других NLP-моделях, о которых мы говорили ранее, эта модель ищет эмбеддинг слова в своей матрице эмбеддингов – один из компонентов, входящих в обученную модель.
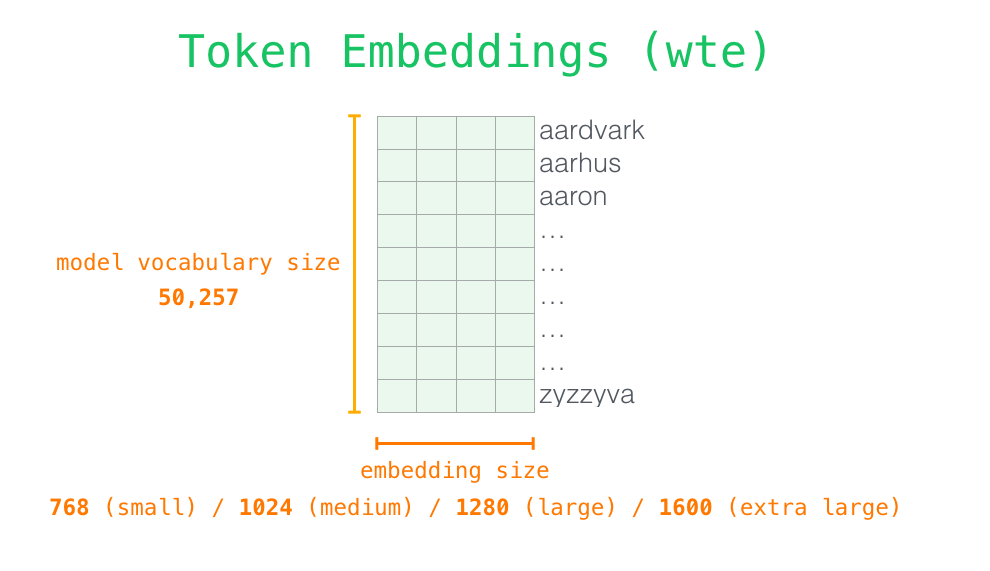
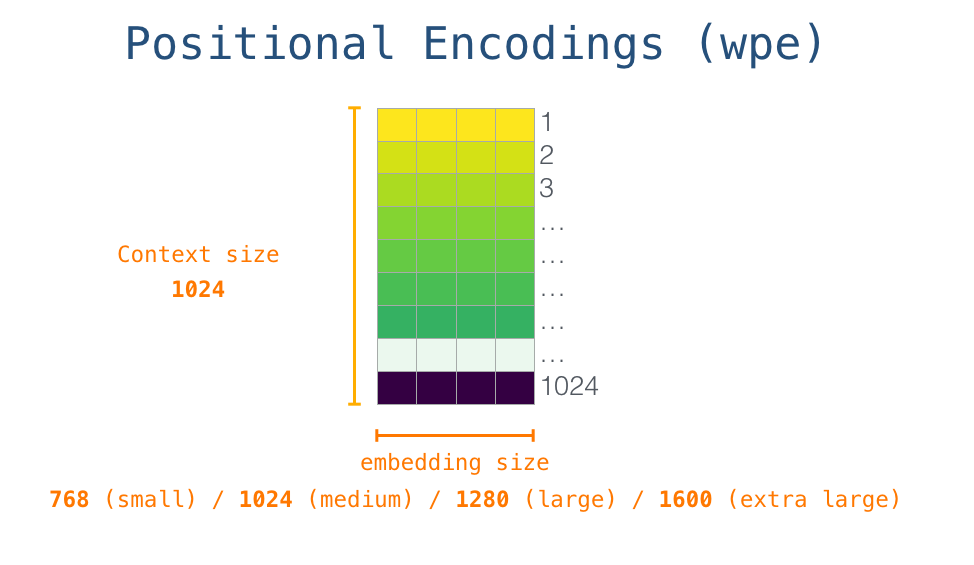
В строках расположены эмбеддинги – наборы чисел, представляющие слова и улавливающие какую-то часть их значения. Размеры этих наборов могут быть разным в зависимости от размера модели GPT-2. Самая маленькая модель использует эмбеддинги размерностью 768 на слово/токен.
Итак, сначала мы ищем эмбеддинг стартового слова <|s|> в матрице эмбеддингов. Прежде чем передать его в первый блок модели, нам нужно применить позиционное кодирование – сигнал, указывающий на порядок слов в последовательности в блоке Трансформера. Частью обученной модели является матрица, содержащая позиционные кодирующие векторы для каждой из 1024 позиций во входе.
Таким образом обрабатывается входное слово перед поступлением в первый блок Трансформера. Мы также знаем две матрицы весов, входящих в состав обученной GPT-2.

Передача слова в первый блок трансформера означает поиск его эмбеддинга и добавление вектора позиционного кодирования для позиции #1.
Путешествие вверх по стеку
Первый блок может теперь обработать токен, сначала проведя его через механизм внутреннего внимания, а затем через слой нейронной сети. Как только первый блок трансформера обработает токен, он высылает результирующий вектор вверх по стеку для последующей обработки вышестоящими блоками. Этот процесс идентичен в каждом блоке, но их веса как для внутреннего внимания, так и для нейронных подслоев отличаются.

Обзор внутреннего внимания
Язык в значительной мере опирается на контекст. Например, посмотрите на Второй закон робототехники:
Робот должен повиноваться всем приказам, которые даёт ему человек, кроме тех случаев, когда эти приказы противоречат Первому Закону.
Мы выделили несколько мест в предложении, где слова отсылают к другим словам. Невозможно понять или обработать эти слова без учета контекста, на который они ссылаются. Когда модель обрабатывает такое предложение, ей необходимо уметь понимать, что:
- ему относится к роботу;
- эти приказы относится к упоминавшимся ранее приказам («которые даёт ему человек»);
- Первому Закону относится к целому первому закону.
Именно это и делает внутреннее внимание: оно помогает модели понять релевантные и связанные слова для того, чтобы оценить контекст для каждого слова, прежде чем приступить к его обработке (прохождению через нейронную сеть). Для этого всем словам присваивают коэффициенты, обозначающие степень релевантности каждого из них в сегменте текста, и добавляют их в векторы представления этих слов.
Рассмотрим пример, где слой внутреннего внимания в верхнем блоке обращает внимание на «a robot» во время обработки слова «it». Вектор, который он передаст в свою нейронную сеть, будет суммой векторов для каждого из трех слов, умноженных на их коэффициенты.

Алгоритм внутреннего внимания
Внутреннее внимание работает параллельно для каждой траектории токена в сегменте. Важными компонентами являются три вектора:
- Запрос – это представление текущего слова, которое используется для вычисления коэффициентов для всех других слов (используя их ключи). Мы рассматриваем лишь запрос для токена, который обрабатываем в данный момент;
- Ключ – своего рода лейбл для слов в сегменте. Именно его мы сопоставляем при поиске релевантных слов;
- Значение – это фактическое представление самих слов; как только мы посчитаем коэффициент того, насколько слово релевантно, мы добавляем векторы Значения для представления текущего слова.

В качестве грубой аналогии можно сравнить это с поиском по картотеке. Запрос – это бумажка с названием того, что необходимо найти. Ключами будут подписи на папках внутри картотеки. Найдя подходящую папку, мы можем достать ее содержимое – вектор значения. Но в случае с внутренним вниманием мы ищем не одно значение, а сочетание значений из набора папок.
Умножение вектора запроса на каждый из векторов ключа даст нам коэффициенты для каждой папки (технически: скалярное произведение с последующей функцией софтмакс).
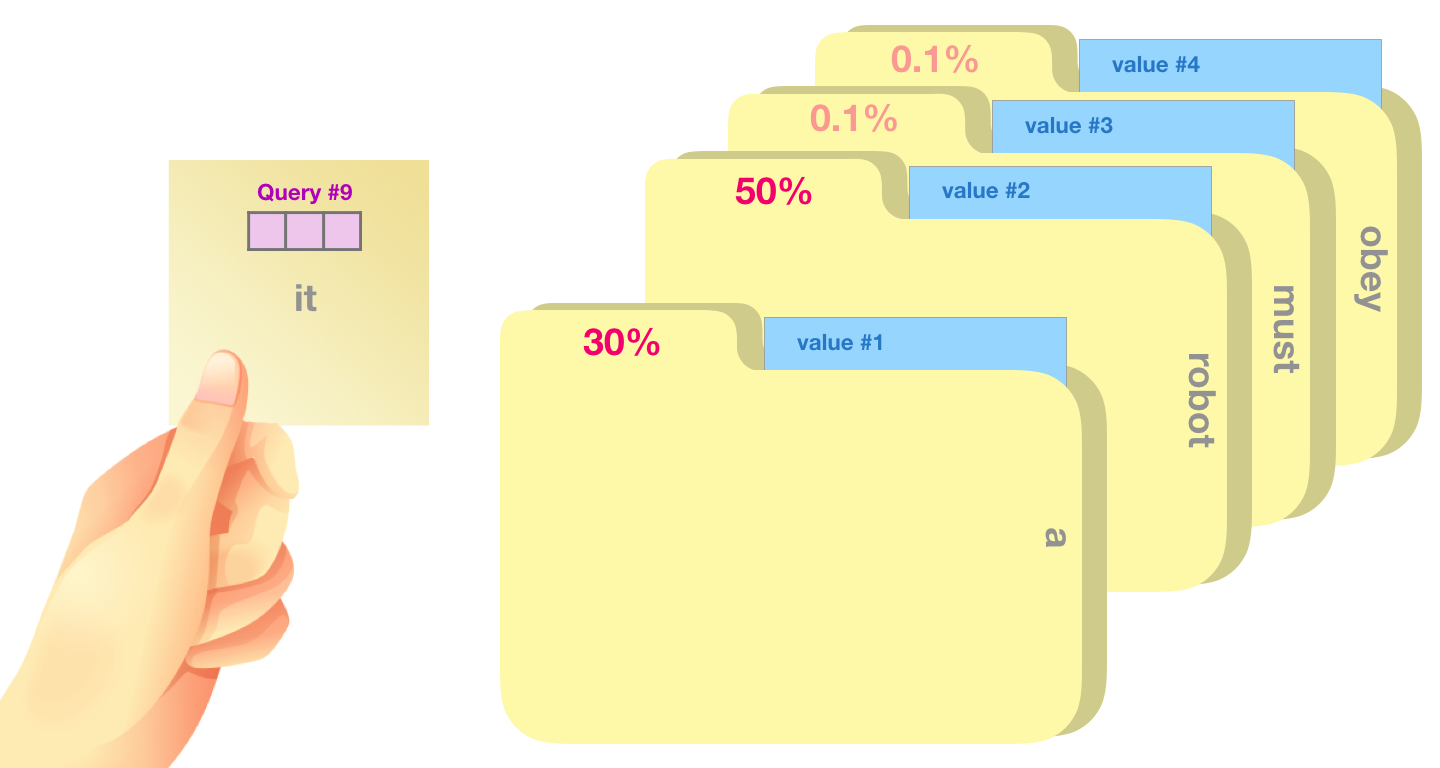
Сложив произведения каждого значения на его коэффициент, мы получим результат внутреннего внимания.
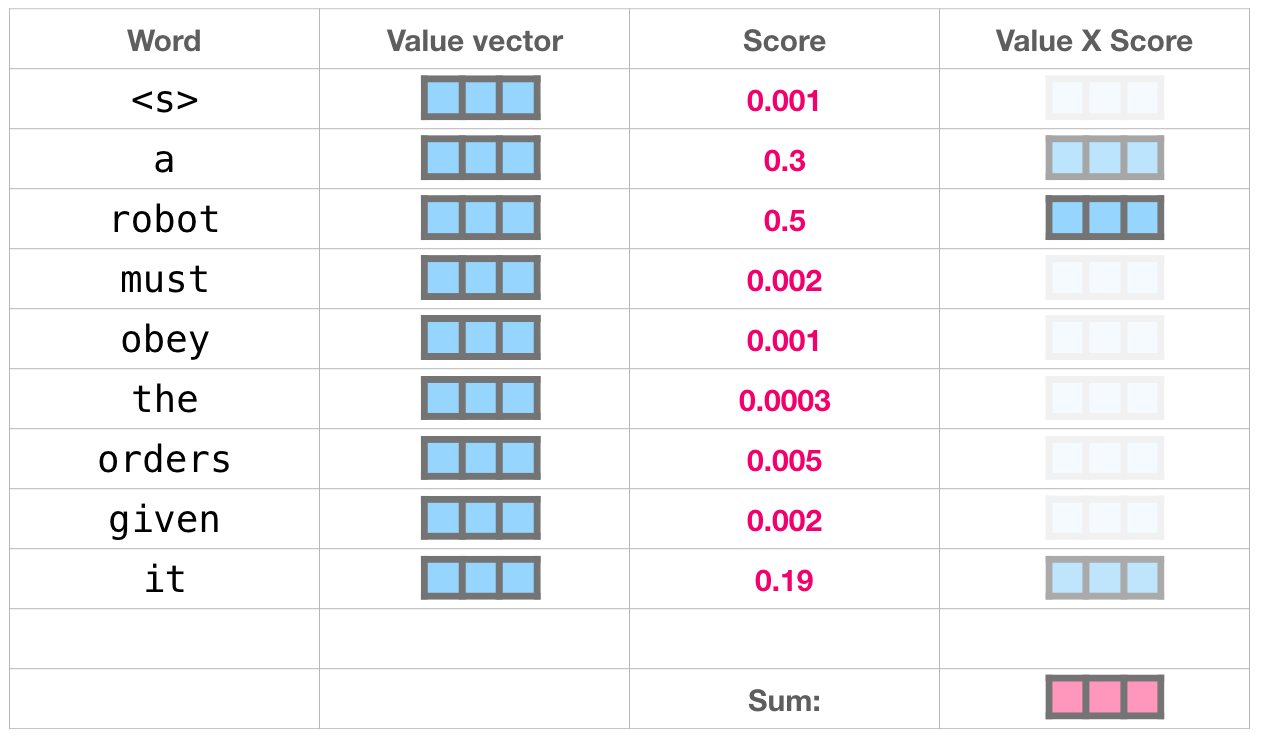
Этот набор взвешенных векторов значений представляет собой вектор, который 50% своего внимания обратил на слово «robot», 30% на слово «a» и 19% – на слово «it». Ниже в статье мы подробнее остановимся на внутреннем внимании. Но прежде продолжим наше путешествие вверх по стеку к выходу модели.
Выход модели
Когда верхний блок модели выдает выходной вектор (результат его собственного слоя внутреннего внимания и последующего слоя нейронной сети), модель умножает его на матрицу эмбеддингов.
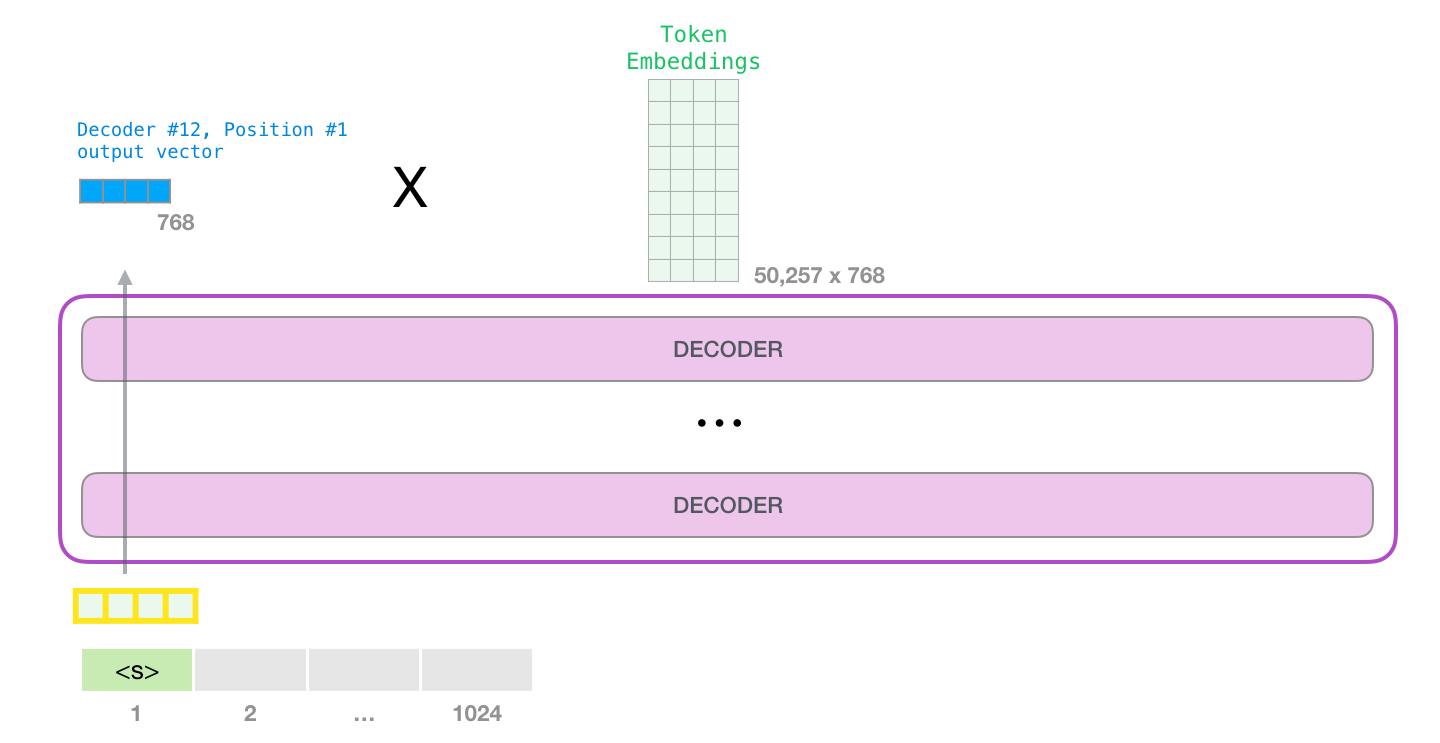
Как вы помните, каждая строка в матрице эмбеддингов соответствует эмбеддингу слова в словаре модели. Результатом этого произведения будет коэффициент для каждого слова из словаря.
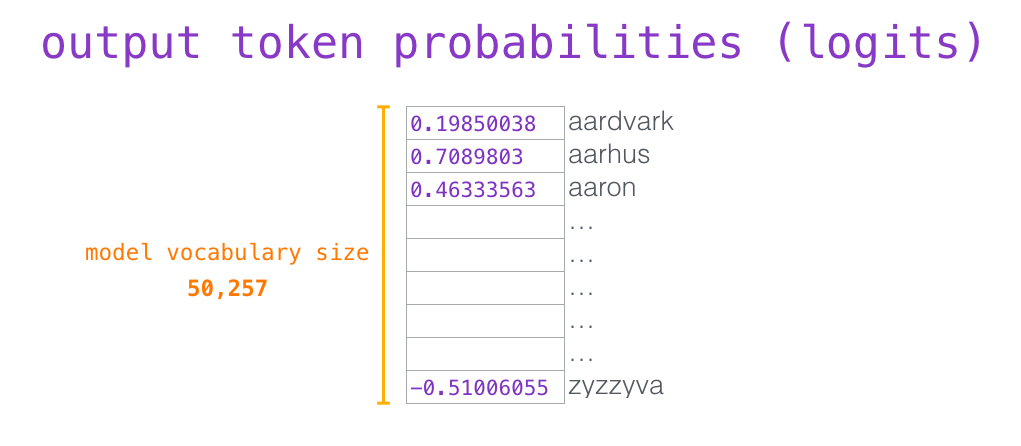
Мы можем просто выбрать токен с наибольшим коэффициентом (top_k = 1). Но результаты будут лучше, если модель будет учитывать также и другие слова. Поэтому хорошей стратегией будет выбрать слово из целого списка, используя коэффициент в качестве вероятности того, что это слово будет выбрано (так слова с наивысшим коэффициентом будут иметь больше шансов быть выбранными). Компромиссный вариант – установить top_k равный 40: так модель будет иметь в виду 40 слов с наибольшими коэффициентами.
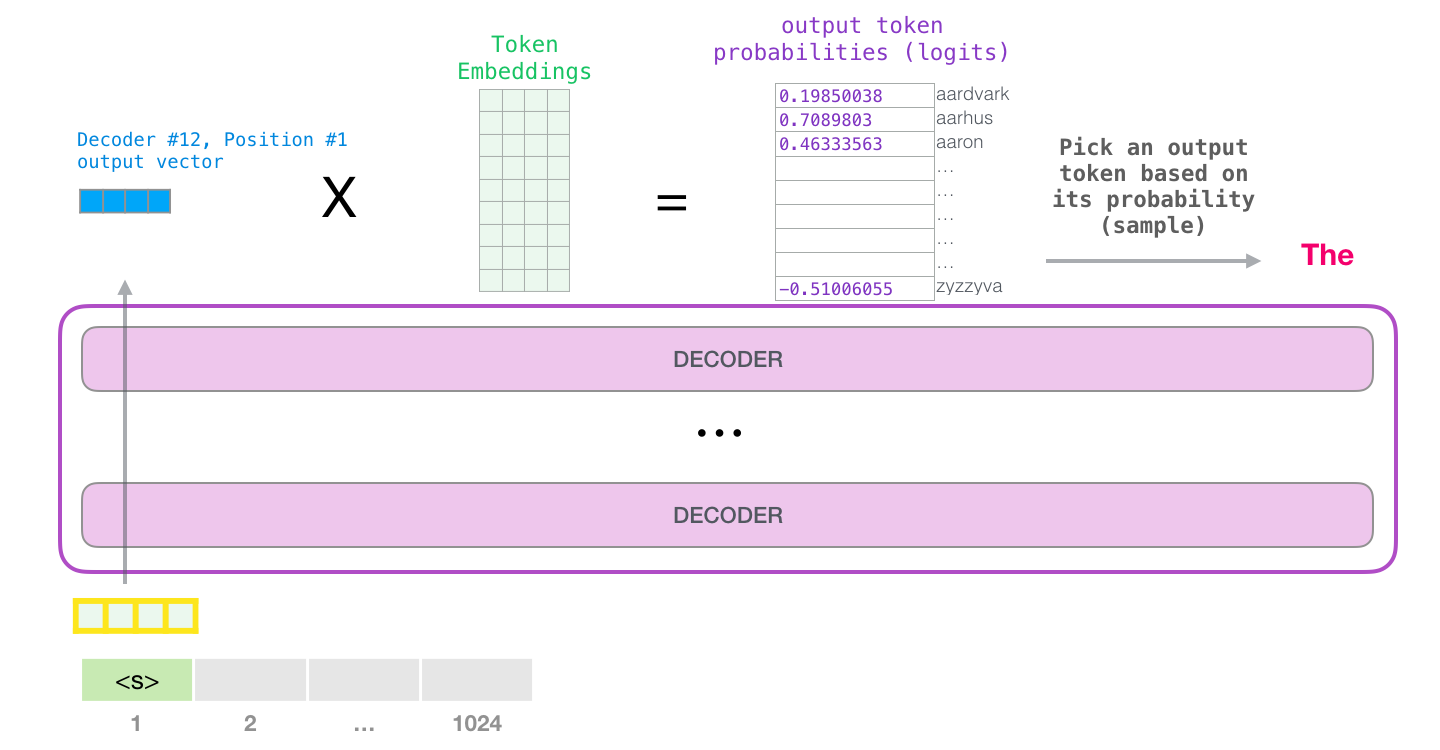
Таким образом, модель завершила одну итерацию и выдала одно слово. Далее этот процесс повторяется до тех пор, пока не будет сгенерирован весь контекст (1024 токена) или пока не появится токен конца предложения.
Конец первой части: GPT-2, дамы и господа
Итак, мы прошлись по тому, как работает GPT-2. Если вам любопытно узнать, что именно происходит внутри слоя внутреннего внимания, то следующая бонусная часть определенно для вас. Она была создана для того, чтобы предложить некоторые визуальные средства для описания механизма внутреннего внимания и облегчить дальнейший разбор моделей трансформера (таких как TransformerXL и XLNet).
Хотелось бы отметить некоторые упрощения, к которым пришлось прибегнуть в этой статье:
- «Слова» и «токены» использовались как синонимы и в этой статье взаимозаменяемы; однако на самом деле GPT-2 использует парную байтовую кодировку (Byte Pair Encoding) для создания токенов своего словаря. Это означает, что обычно токенами являются части слова.
- В нашем примере модель GPT-2 работает в режиме вывода/оценки (inference/evaluation mode). Вот почему она обрабатывает только одно слово за раз. Во время обучения модель будет обучаться на более длинных последовательностях текста и обрабатывать единовременно несколько токенов. Также на этапе обучения модель может обрабатывать батчи больших размеров (512), в отличие от батчей размером 1, которые используются в режиме оценки.
- Автор был несколько волен в ротации/транспозиции векторов для лучшей организации пространства и картинок. Во время применения модели необходимо быть более точным.
- В Трансформерах широко применяется техника нормализации слоев, и это достаточно важно. Мы отметили некоторые примеры ее использования в Transformer в картинках, а в этой статье в основном сосредоточимся на внутреннем внимании.
- В некоторых случаях было необходимо изобразить больше квадратиков для представления вектора. Эти случаи были описаны как «zoom in», например:
Часть 2: визуализация внутреннего внимания
Ранее в статье мы показывали эту картинку для иллюстрации применения внутреннего внимания в слое, обрабатывающем слово «it»:

В этой части мы рассмотрим более детально то, как это происходит. При этом мы будем пытаться понять, что происходит с каждым конкретным словом, поэтому далее будет много иллюстраций отдельных векторов. И хотя в реальности применение внутреннего внимания происходит с помощью перемножения гигантского размера матриц, мы остановимся здесь на интуиции того, что происходит на уровне одного слова.
Внутреннее внимание (без маскирования)
Давайте посмотрим на оригинальное внутреннее внимание, которое подсчитывается в блоке энкодера. Рассмотрим упрощенный блок Трансформера, обрабатывающий всего 4 токена за раз.
Применение внутреннего внимания требует выполнения трех основных шагов:
- Создание векторов Запроса, Ключа и Значения для каждой траектории;
- Использование вектора Запроса каждого входного токена для подсчета коэффициента относительно всех других векторов Ключа;
- Умножение векторов Значения на присвоенный им коэффициент и суммирование получившихся значений.
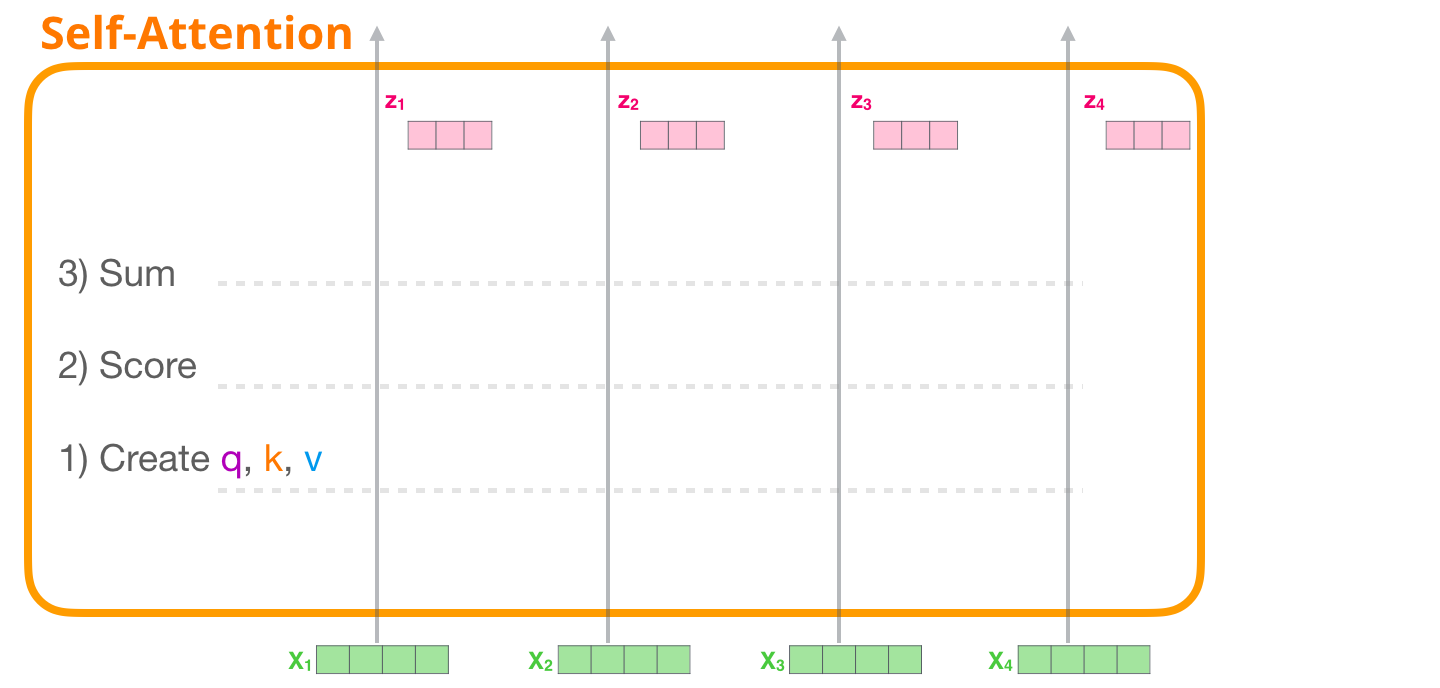
1 – Создание векторов Запроса, Ключа и Значения
Сфокусируемся на первой траектории. Мы возьмем ее вектор Запроса и сравним со всеми ключами. Это создаст коэффициент для каждого ключа. Первым шагом во внутреннем внимании является подсчет трех векторов для траектории каждого токена (опустим пока «головы» внимания):

Для каждого входного токена создается вектор Запроса, вектор Ключа и вектор Значения путем произведения на соответствующие матрицы весов WQ, WK, WV
2 – Подсчет коэффициентов
Теперь, когда у нас есть векторы, мы можем использовать векторы Запроса и Ключа для выполнения шага №2: перемножим вектор Запроса рассматриваемого нами первого токена на все векторы Ключа и получим коэффициент для каждого из четырех токенов.
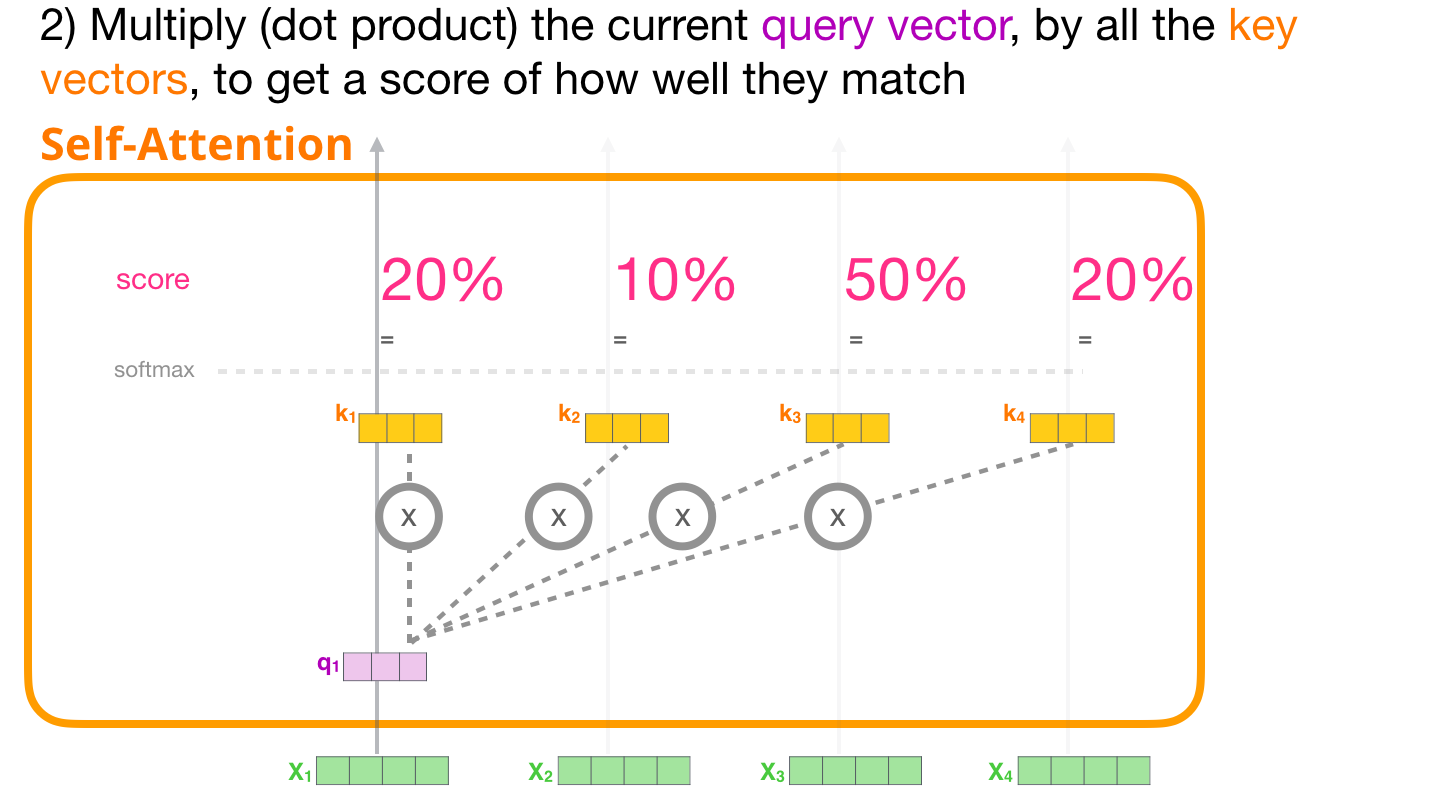
Перемножим (скалярное произведение) вектор Запроса рассматриваемого токена на все векторы Ключа и получим коэффициент того, насколько токены соответствуют друг другу
3 – Суммирование
Теперь мы можем перемножить коэффициенты и векторы Значений. Значение с наибольшим коэффициентом будет составлять большую часть результирующего вектора после того, как мы подсчитаем их сумму.
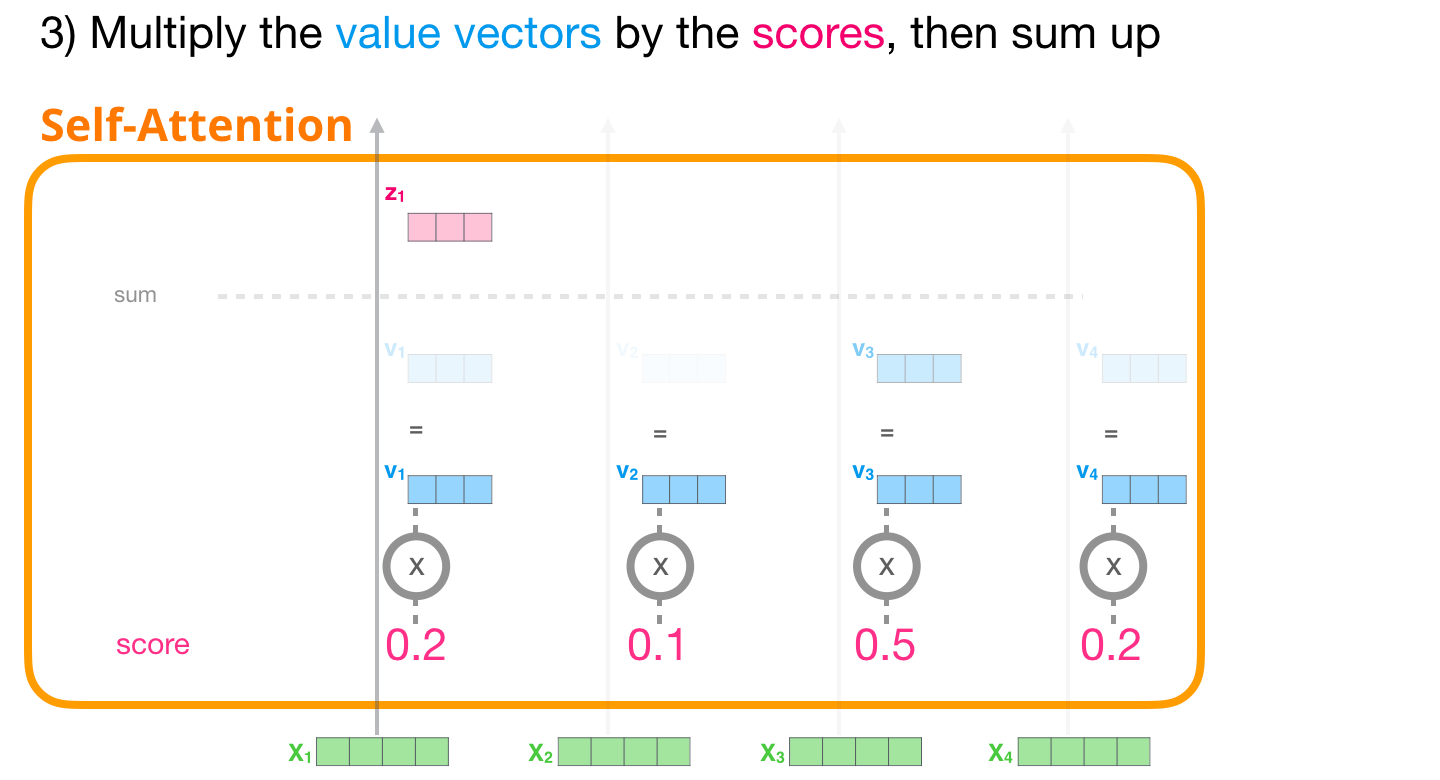
Перемножим векторы Значений на их коэффициенты и сложим получившиеся произведения
Чем меньше коэффициент, тем более прозрачным изображен вектор Значения – наглядная визуализация того, как умножение на небольшой коэффициент уменьшает долю этого вектора в результирующем векторе.
Если мы выполним данную операцию для каждой траектории, мы получим вектор, представляющий соответствующий токен и содержащий подходящий контекст этого токена. Эти векторы затем передаются в следующий подслой блока Трансформера (нейронную сеть прямого распространения).
Визуализация маскированного внутреннего внимания
Теперь, когда мы посмотрели на то, что происходит внутри этапа внутреннего внимания Трансформера, мы перейдем к маскированному внутреннему вниманию. Оно идентично внутреннему вниманию вплоть до шага №2. Предположим, модель имеет только два токена на входе и мы рассматриваем второй. В этом случае последние два токена маскируются. Таким образом модель вмешивается в процесс распределения коэффициентов, наделяя все будущие токены нулевыми весами:
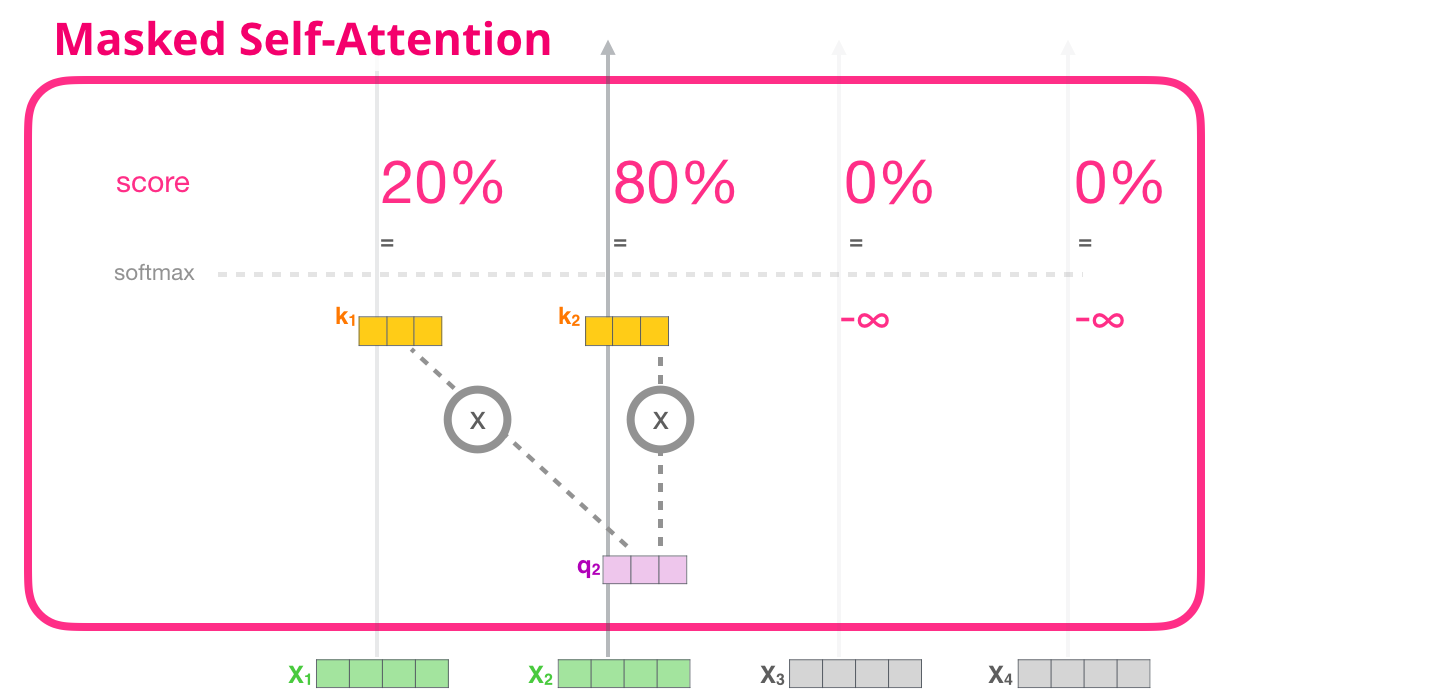
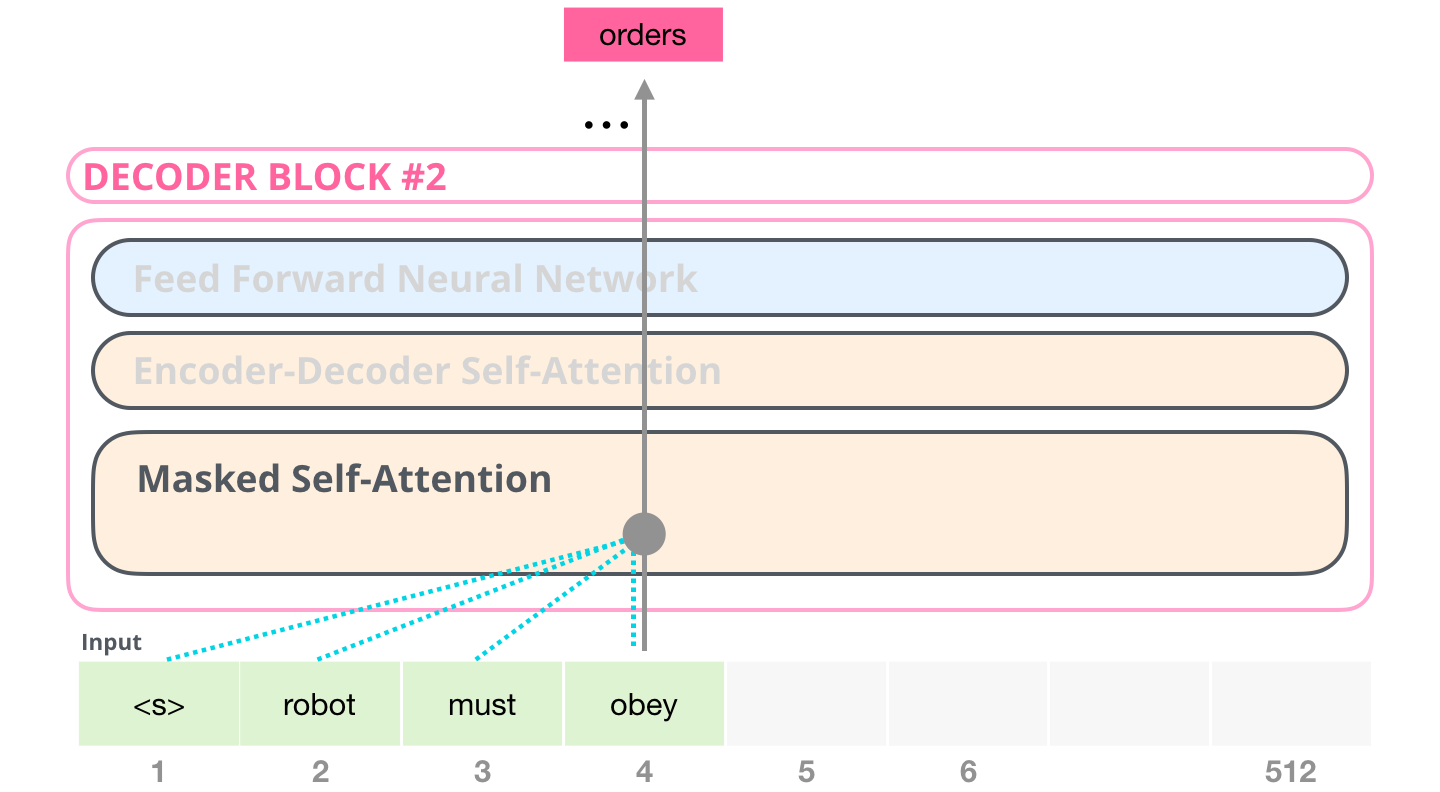
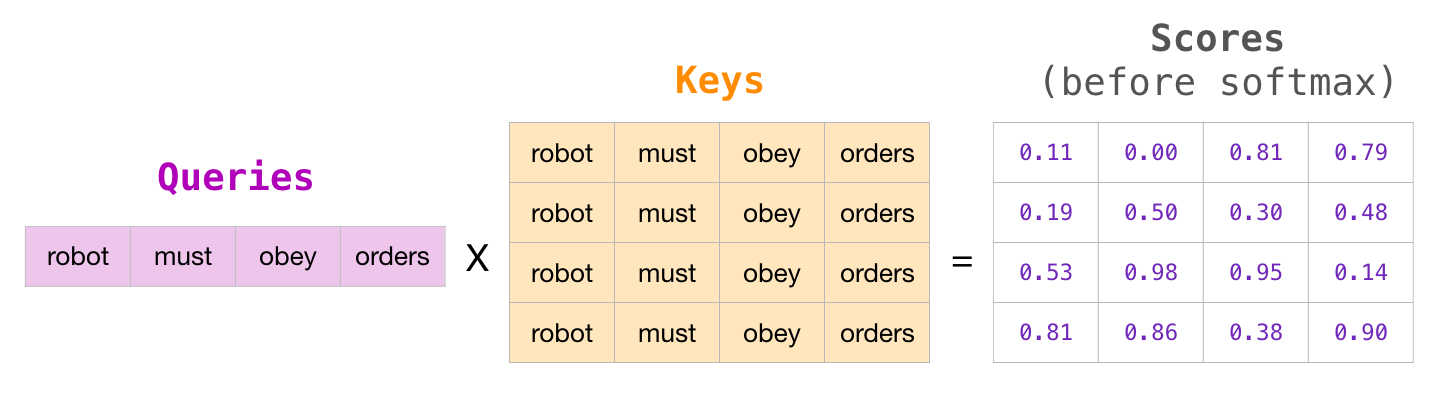
Это маскирование часто применяется в качестве матрицы, называемой маской внимания (attention mask). Возьмем, например, последовательность из четырех слов («robot must obey orders»). В случае языкового моделирования эта последовательность обрабатывается за 4 шага: один для каждого слова (с допущением, что каждое слово – это один токен). Т.к. эти модели работают батчами, мы можем установить размер батча 4 для нашей упрощенной модели, которая будет обрабатывать целую последовательность (с ее 4 шагами) как один батч.

Мы подсчитываем коэффициенты в матричной форме, перемножая матрицу Запроса на матрицу Ключа. Изобразим это следующим образом, имея в виду, что вместо слова будет стоять вектор Запроса (или Ключа), соответствующий слову в ячейке:
После перемножения мы «нахлобучиваем» нашу треугольную маску внимания. В те ячейки, которые мы хотим спрятать, она ставит или маску –бесконечность (-inf) или очень большое отрицательное число (например, -1 миллиард в GPT-2):

Затем, применяя функцию софтмакс для каждой строки, получим реальные коэффициенты, которые и будем использовать для внутреннего внимания:

Эта таблица коэффициентов означает следующее:
- Когда модель обрабатывает первый пример из набора данных (строка №1), который содержит только одно слово («robot»), 100% всего внимания будет на самом слове.
- Когда модель обрабатывает второй пример из набора данных (строка №2), который содержит слова («robot must»), во время обработки слова «must» 48% всего внимания будет на «robot» и 52% будет на слове «must».
- И т.д.
Маскированное внутреннее внимание в GPT-2
Рассмотрим более подробно маскированное внутреннее внимание в GPT-2.
Время оценки: обработка одного токена за раз
Мы можем сделать так, чтобы GPT-2 работала в точности так же, как маскированное внутреннее внимание. Но во время оценки, когда наша модель только добавляет одно новое слово после каждой итерации, будет неэффективно пересчитывать внутреннее внимание для более ранних траекторий токенов, которые уже были обработаны.
В этом случае мы обрабатываем первый токен (пока игнорируя <|s|>).
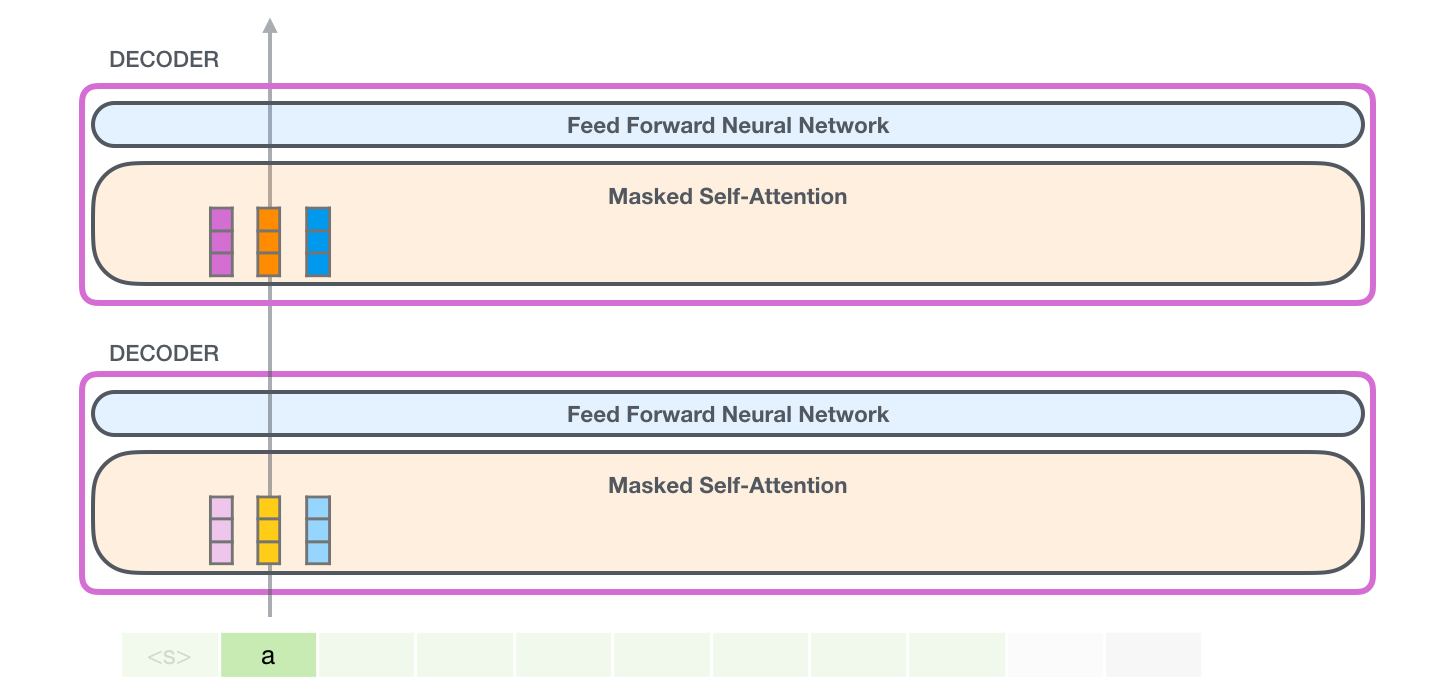
GPT-2 ждет векторы Ключа и Значения токена «a». Каждый слой внутреннего внимания ожидает соответствующие векторы Ключа и Значения для этого токена:

На следующей итерации, когда модель обрабатывает слово «robot», уже не нужно генерировать векторы Запроса, Ключа и Значения для токена «a» – модель просто использует векторы, сохраненные на первой итерации:

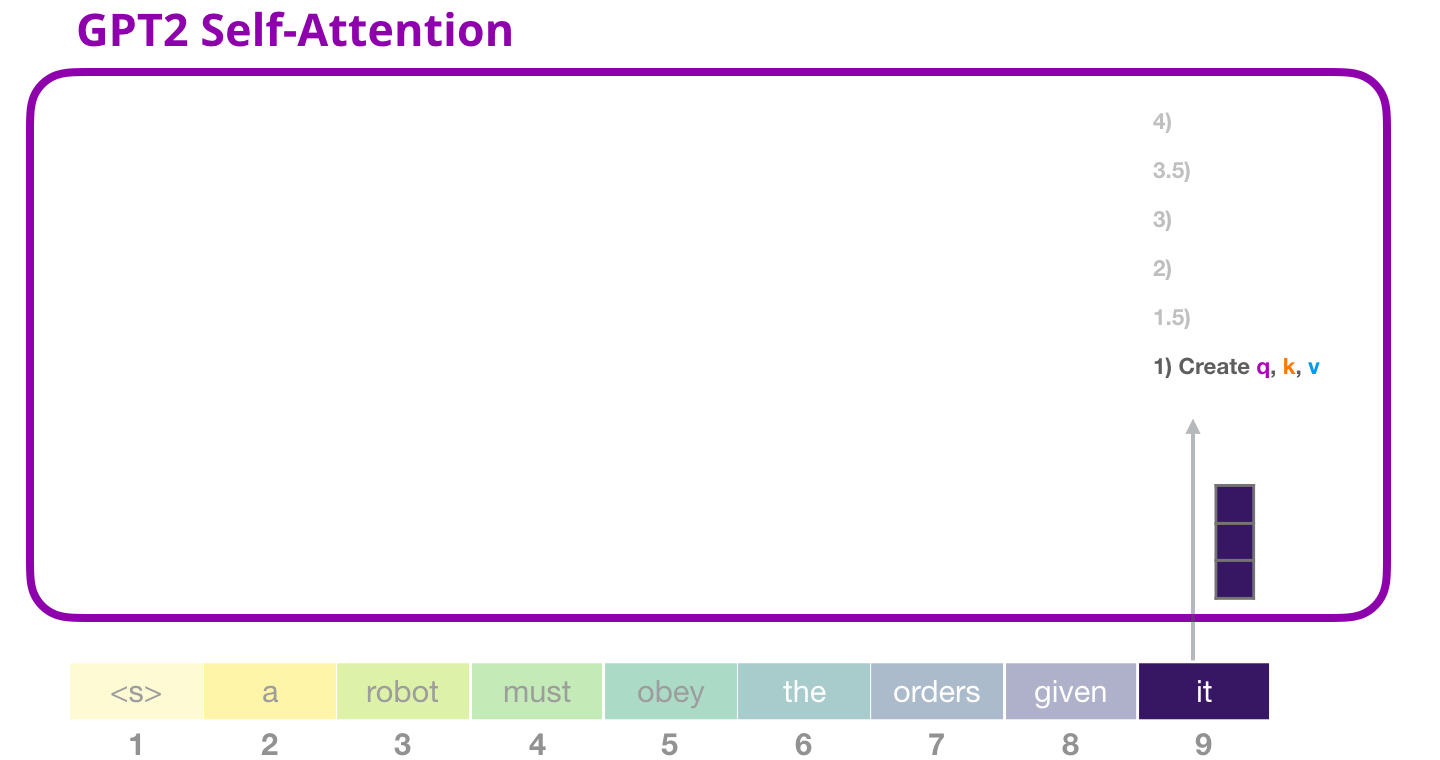
Внутреннее внимание GPT-2: 1 – Создание векторов Запроса, Ключа и Значения
Предположим, что модель обрабатывает слово «it». Что касается нижнего блока, то его вход для этого токена будет эмбеддингом «it» + вектор позиционного кодирования для слота #9:
Каждый блок в Трансформере имеет свои собственные матрицы весов (подробнее о них далее в статье), которые мы используем для создания векторов Запросов, Ключей и Значений.

Внутреннее внимание перемножает входные данные на матрицу весов и добавляет вектор смещения (bias vector), отсутствующий на картинке
Результатом этого произведения будет вектор, который является по сути конкатенацией векторов Запроса, Ключа и Значения для слова «it».
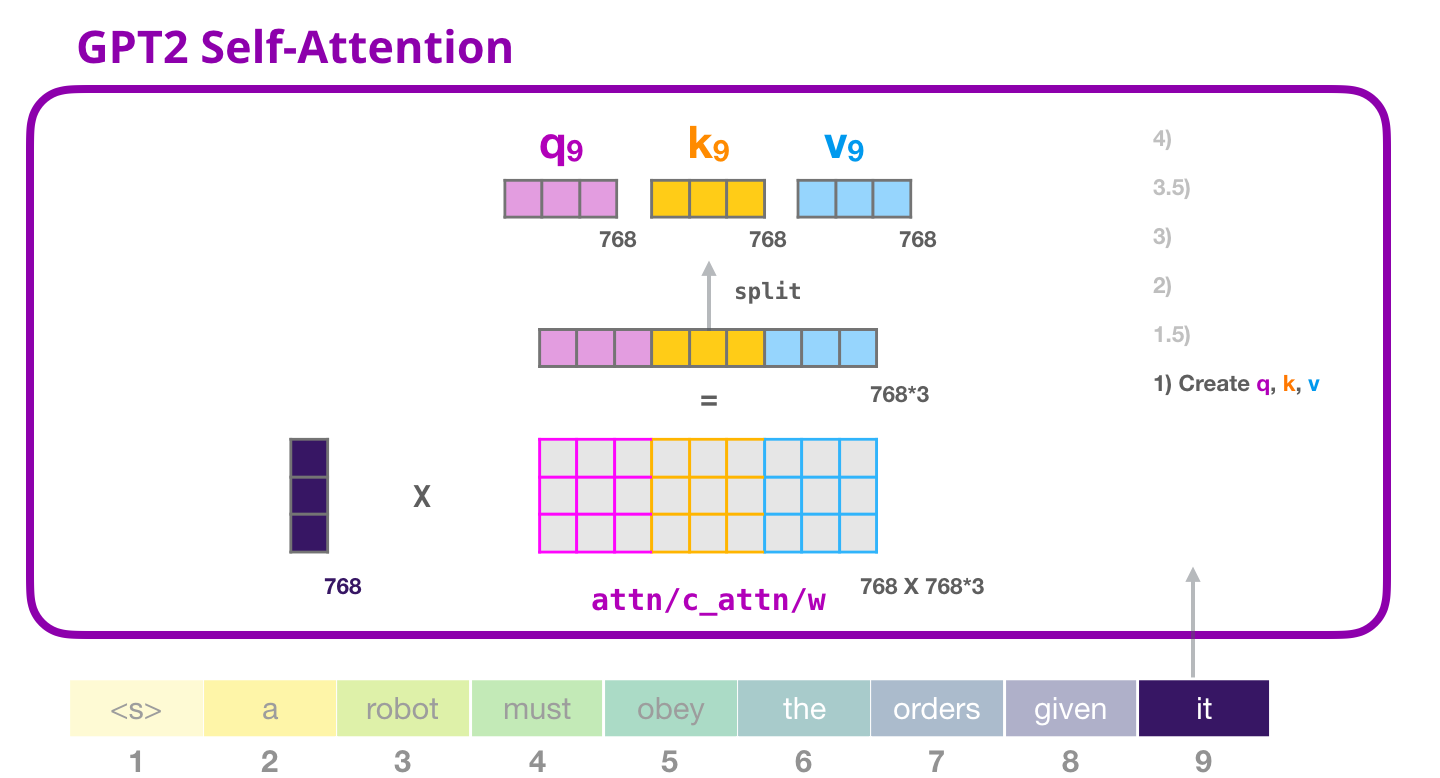
Перемножение входного вектора на вектора весов внимания (и последующее сложение с вектором смещения) образует векторы Ключа, Значения и Запроса для этого токена
Внутреннее внимание GPT-2: 1.5 – Разделение на «головы» внимания
В предыдущих примерах мы сразу окунулись во внутреннее внимание, игнорируя его «многоголовую» часть. Будет полезно кратко пролить свет на этот концепт. Внутреннее внимание осуществляется множество раз в разных частях векторов Запроса (Q), Ключа (K) и Значения (V). Разделение на «головы» внимания – это просто преобразование длинных векторов в матрицу. У маленьких GPT-2 есть по 12 «голов» внимания, что является первым измерением преобразованной матрицы:
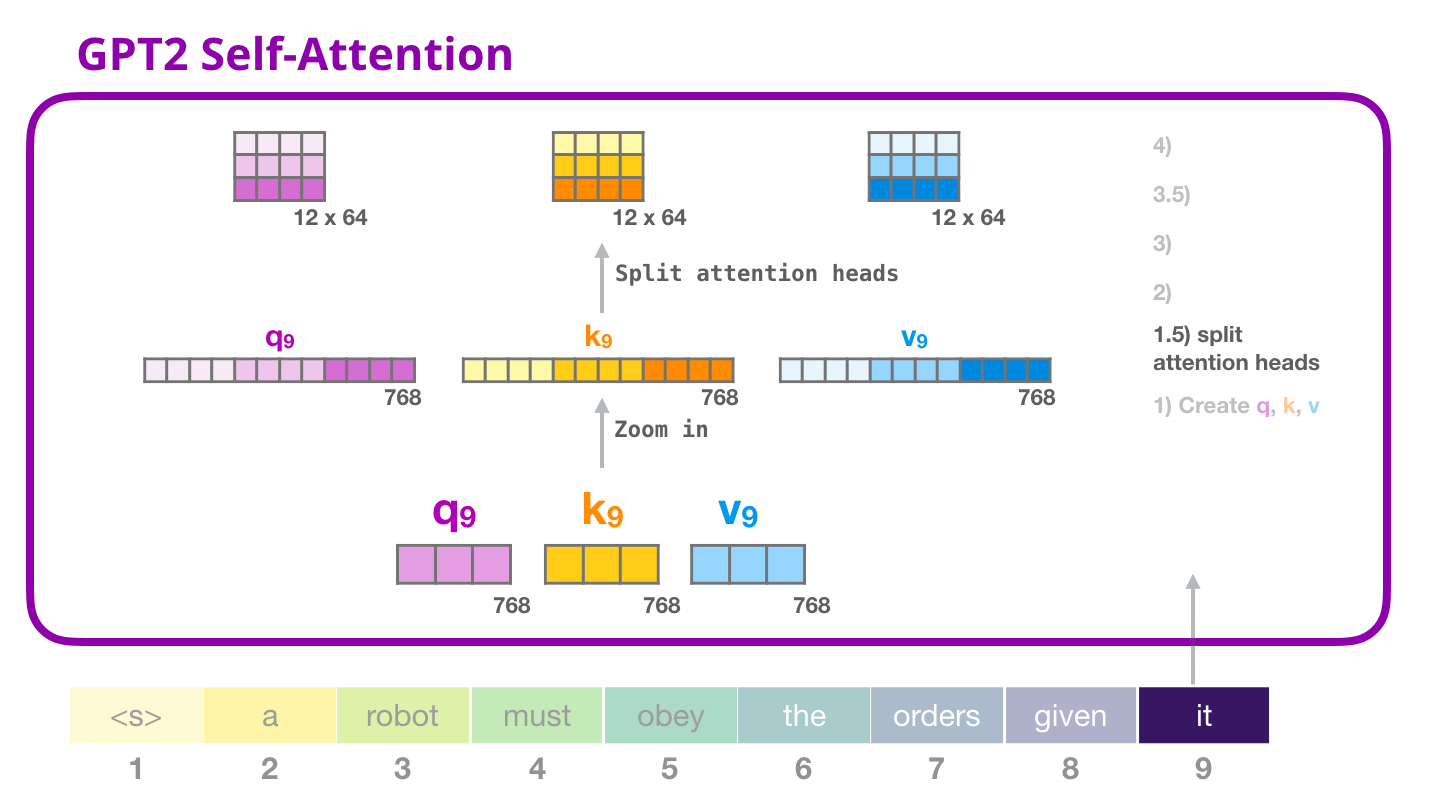
В предыдущих примерах мы рассматривали, что происходит внутри одной «головы» внимания. Что касается множественных «голов» внимания, то можно изобразить этот процесс следующим образом (для простоты изобразим только три из 12 «голов» внимания):
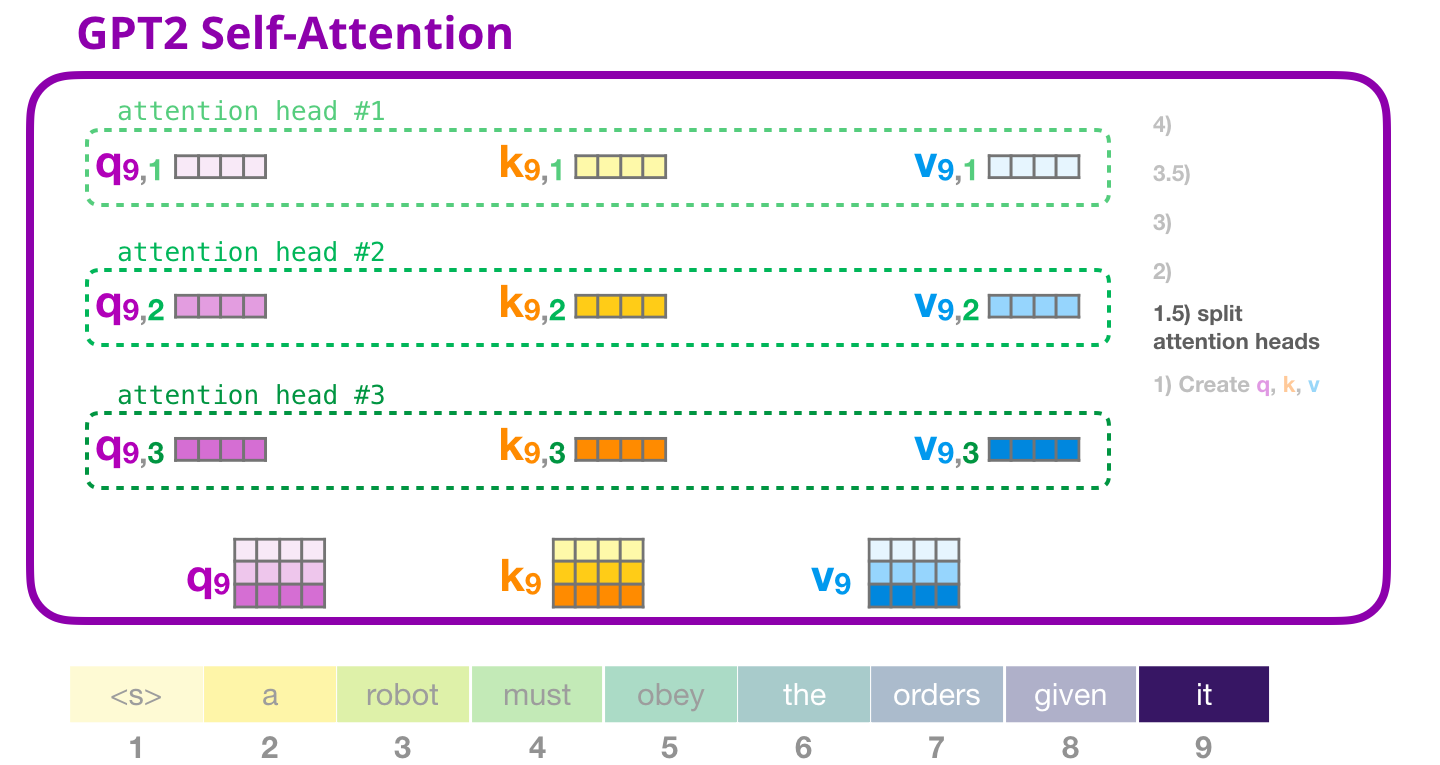
Внутреннее внимание GPT-2: 2 – Подсчет коэффициентов
Теперь мы можем перейти к вычислению коэффициентов (помня о том, что мы рассматриваем только одну «голову» внимания и что в других происходят схожие операции):
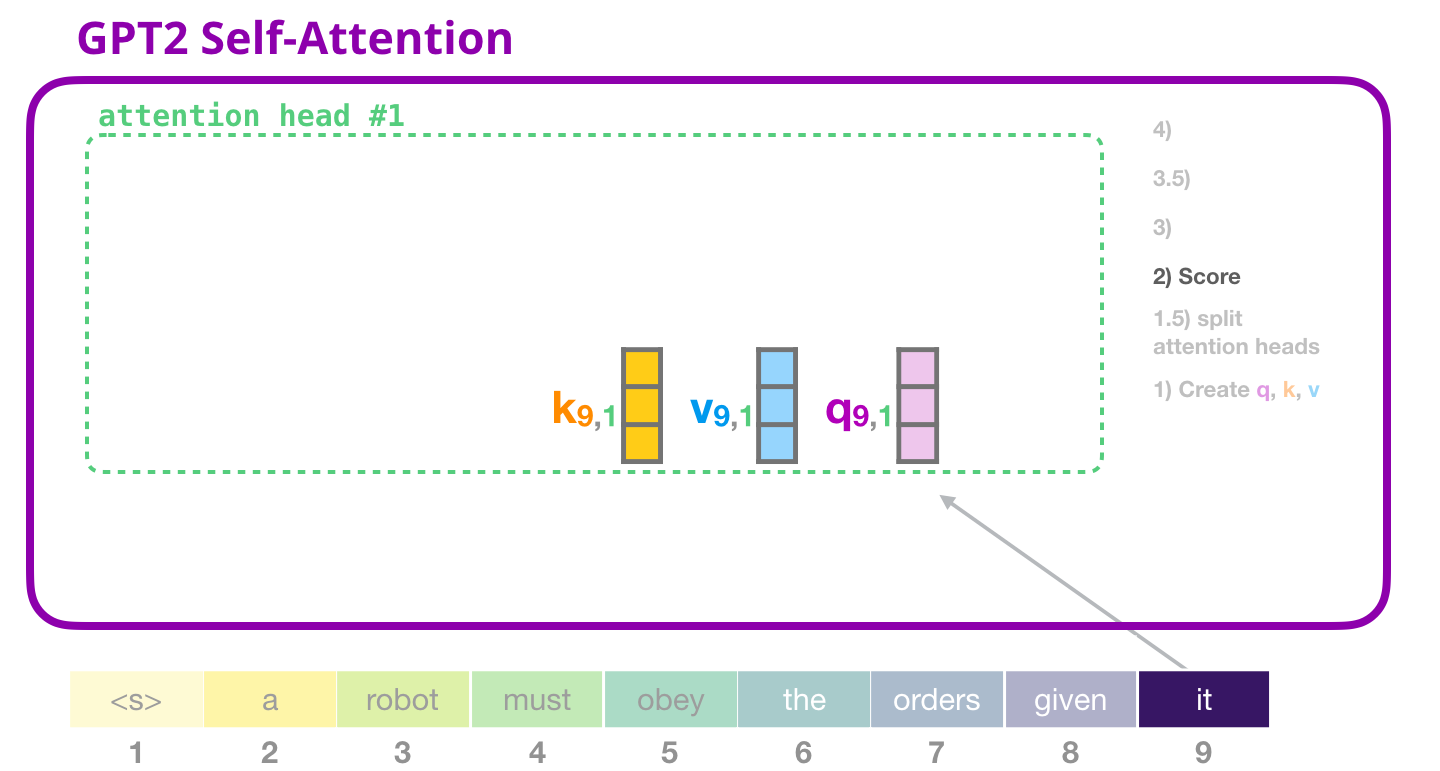
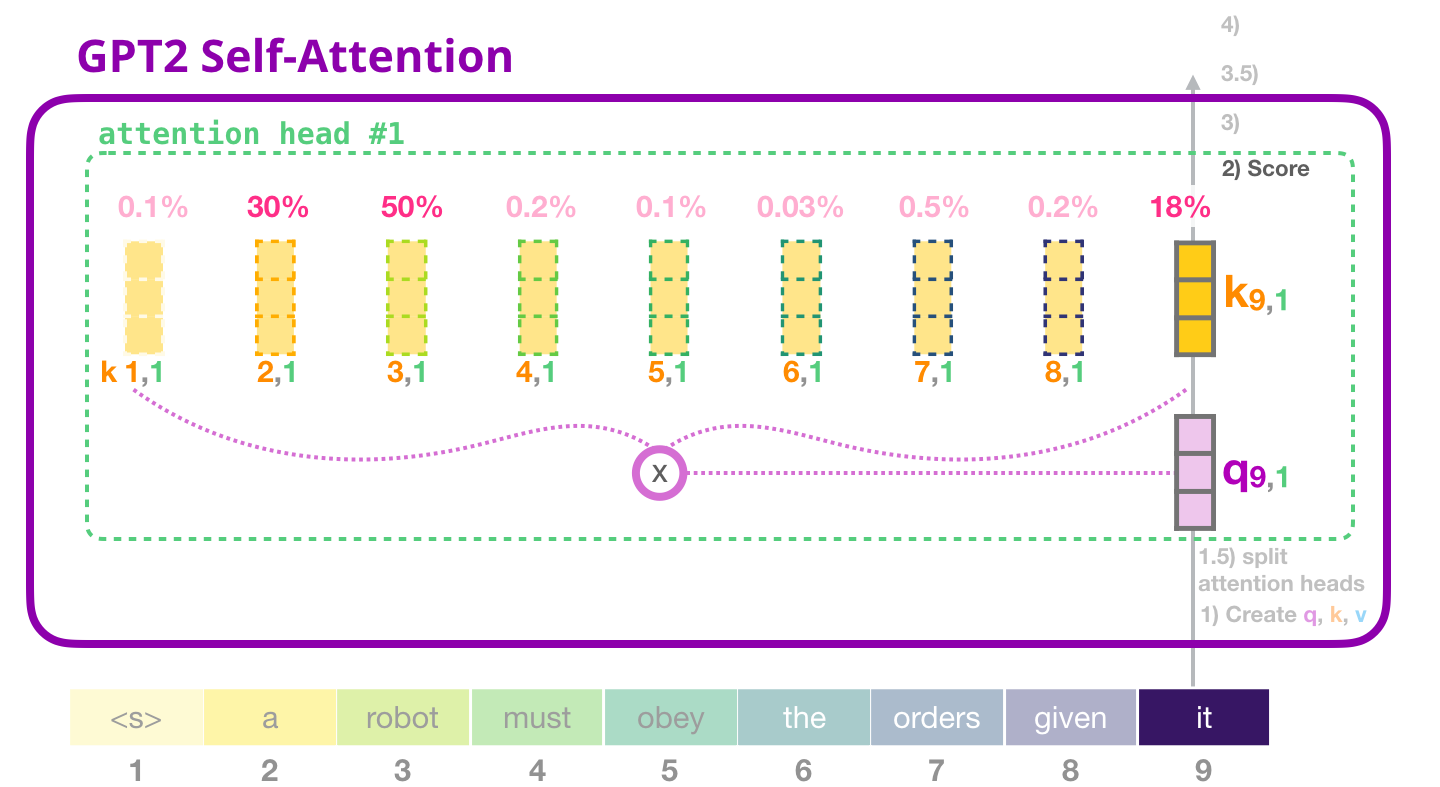
Токен получает коэффициент относительно всех Ключей других токенов (которые мы посчитали в «голове» внимания #1 в предыдущие итерации):
Внутреннее внимание GPT-2: 3 – Суммирование
Как мы видели ранее, теперь мы умножаем каждое Значение на его коэффициент и, суммируя, получаем результат внутреннего внимания для «головы» внимания #1:

Внутреннее внимание GPT-2: 3.5 – Объединение «голов» внимания
Обработка различных «голов» внимания заключается, прежде всего, в конкатенации их в один вектор:
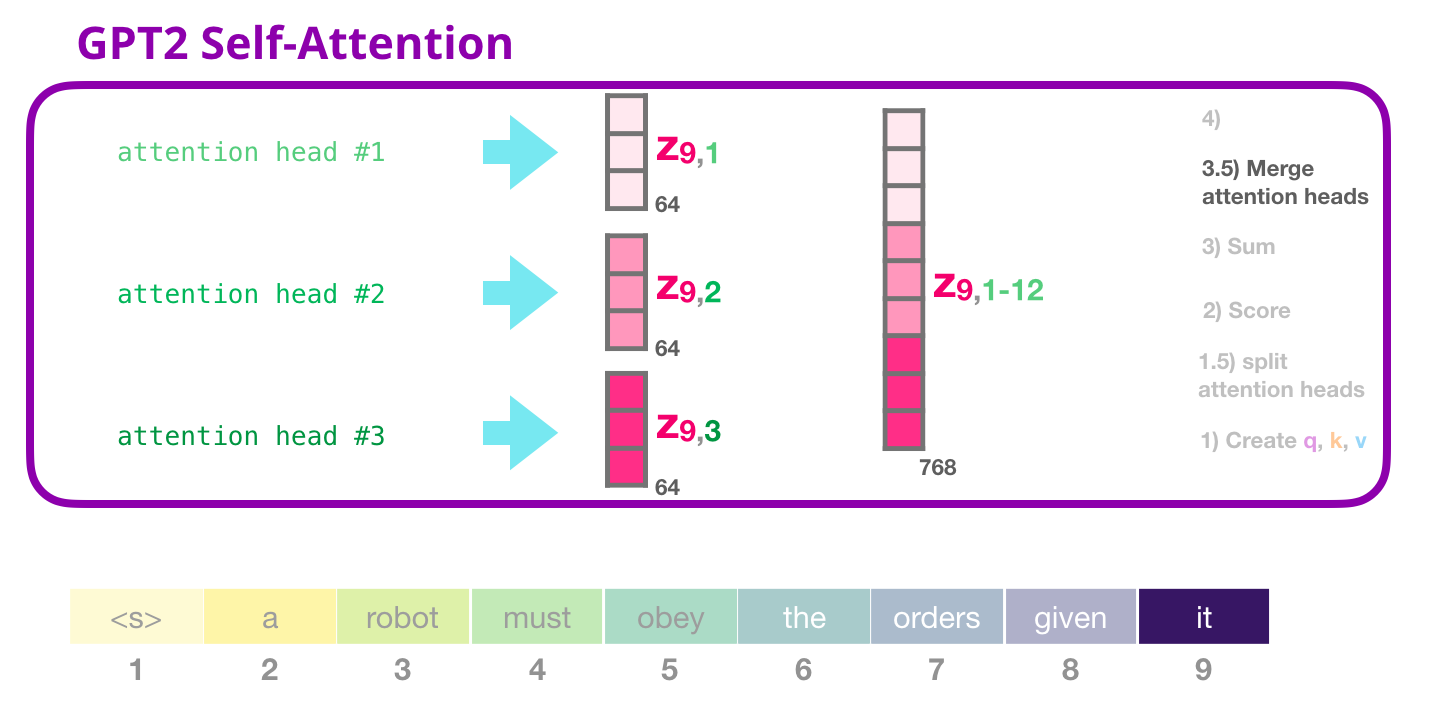
Но этот вектор еще нельзя отправлять на следующий подслой. Необходимо превратить этого франкенштейна скрытых состояний в однородное представление.
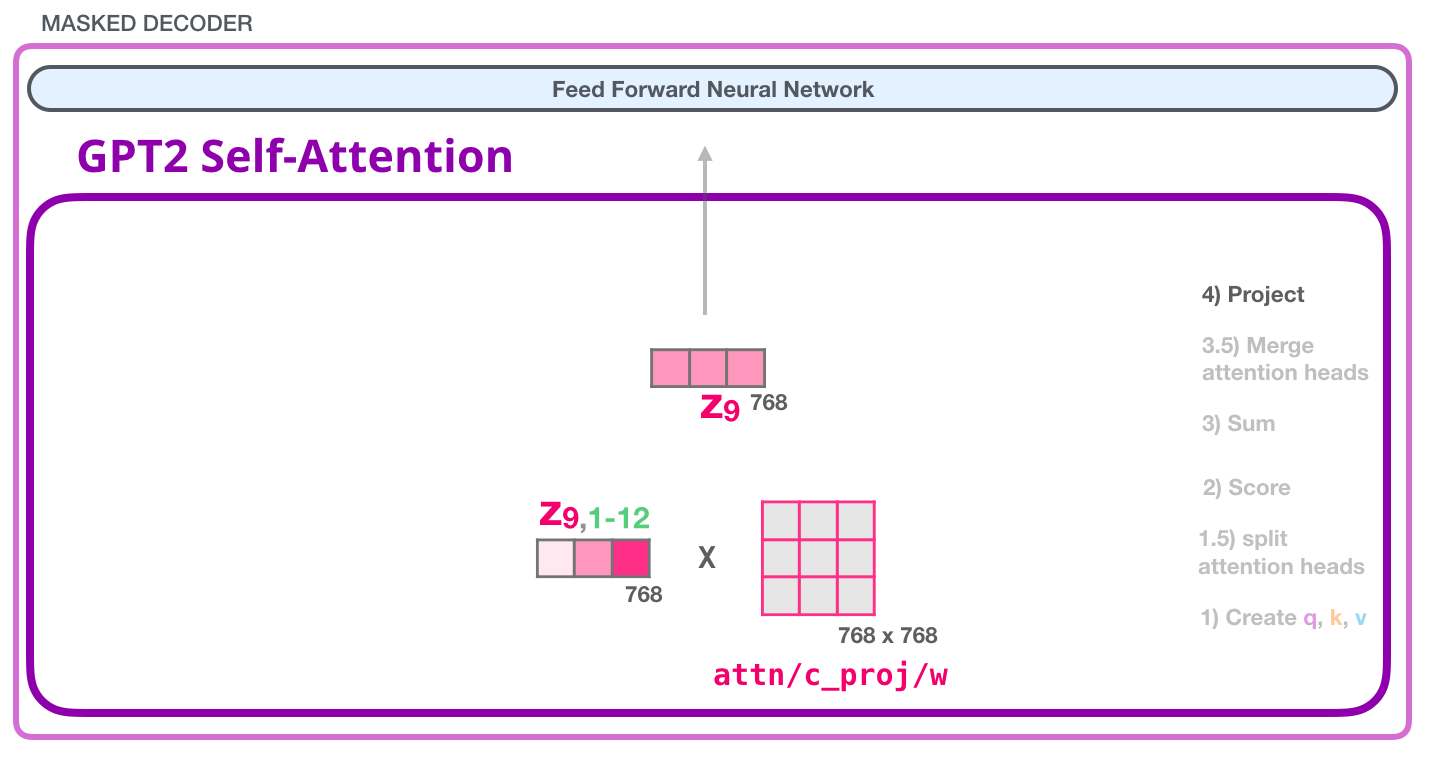
Внутреннее внимание GPT-2: 4 – Проецирование
Мы позволим модели учиться, как лучше сопоставить конкатенированный результат внутреннего внимания с вектором, с которым может работать нейронная сеть прямого распространения. Для этого понадобится вторая большая матрица весов, которая проецирует результаты «голов» внимания в выходной вектор подслоя внутреннего внимания:

Проделав это, мы создаем вектор, который можно передать в следующий слой:
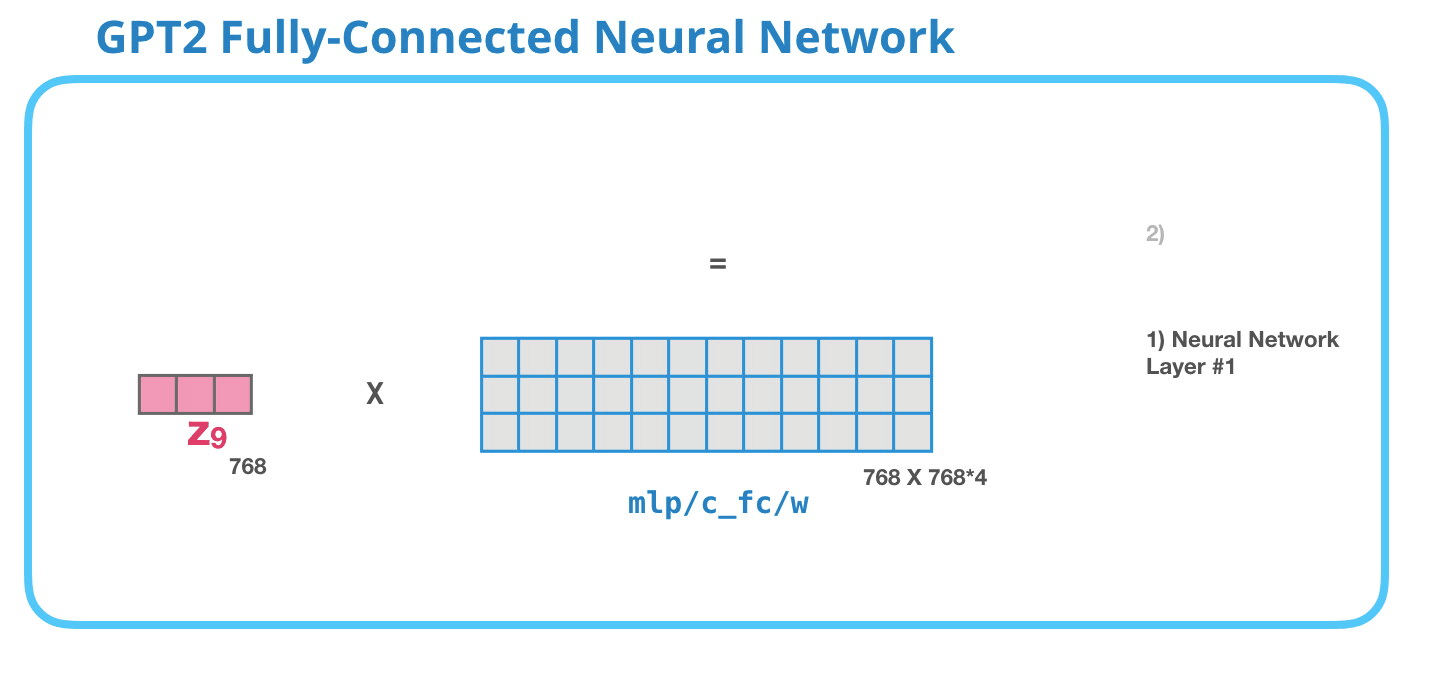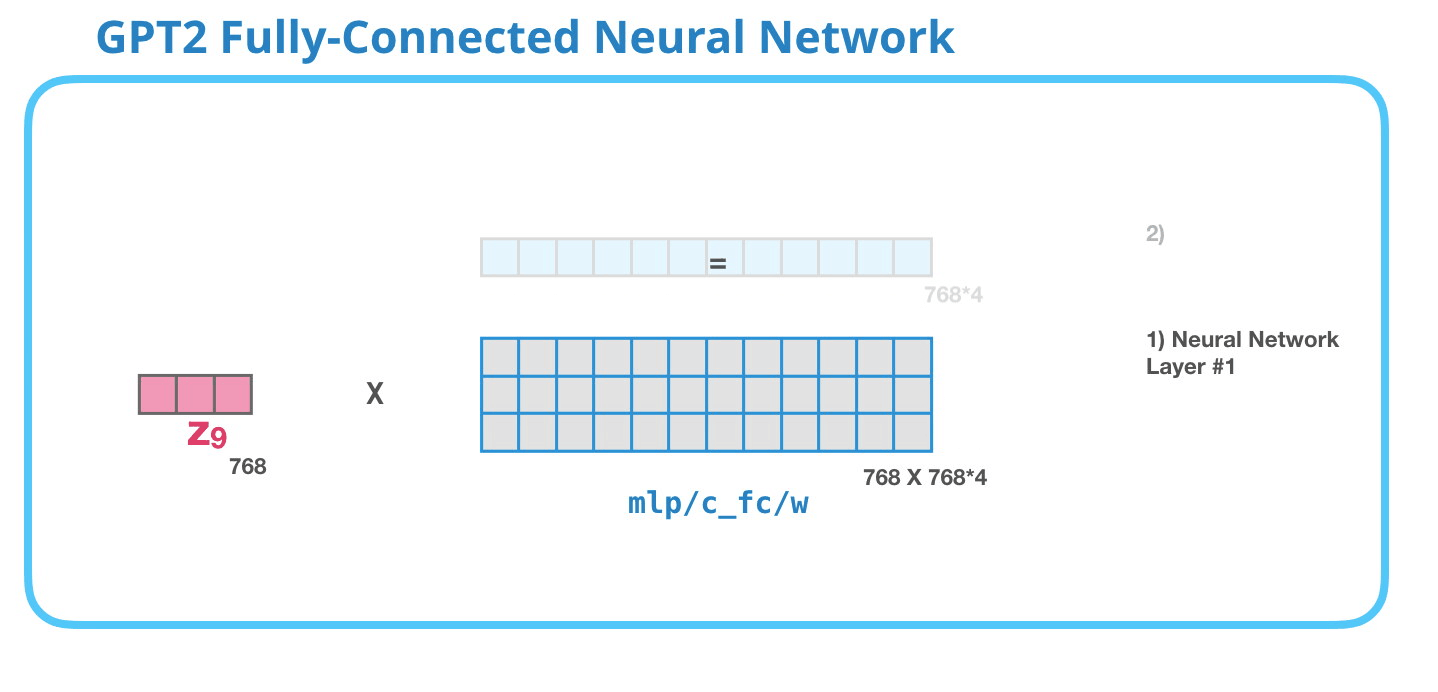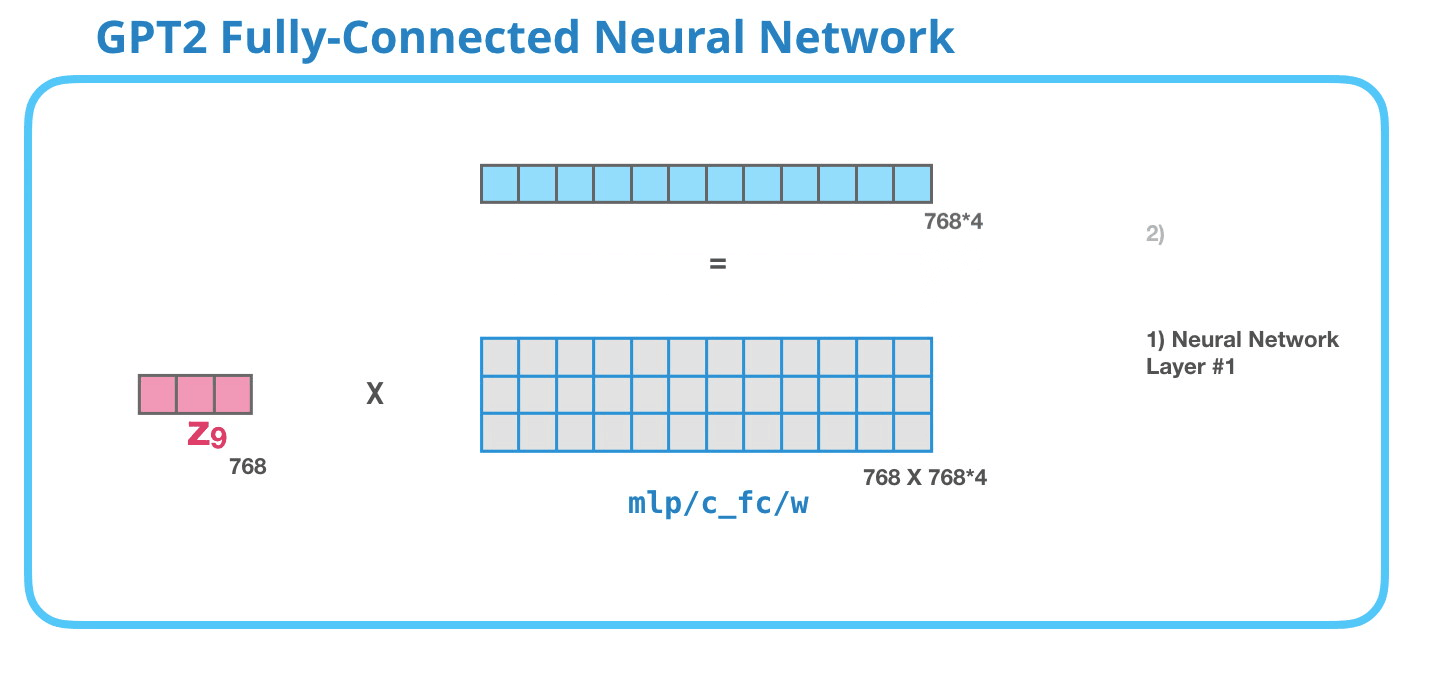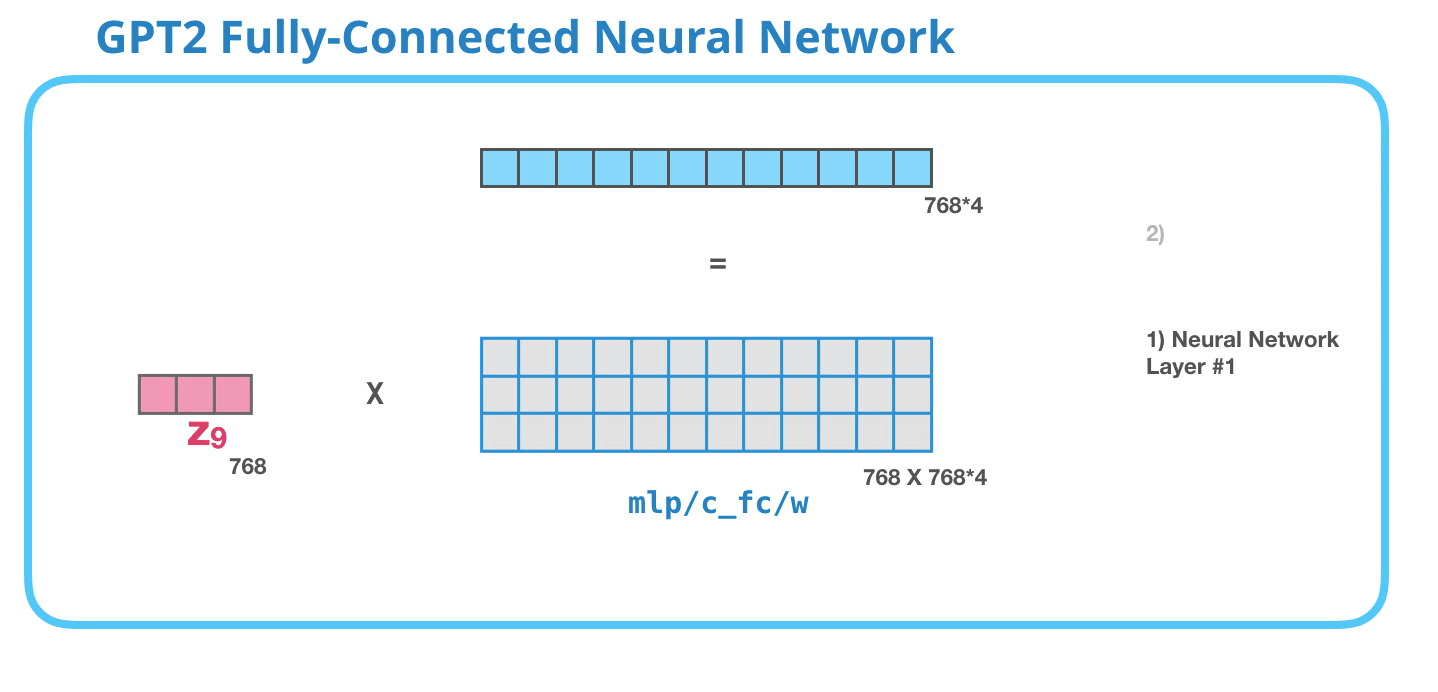
Полносвязная нейронная сеть GPT-2: Слой #1
Полносвязная нейронная сеть – это сеть, где блоки обрабатывают входной токен после того, как внутреннее внимание включило подходящий контекст в его представление. Она состоит из двух слоев. Первый слой в 4 раза больше размера модели (поскольку маленькая GPT-2 имеет размерность 768, эта нейронная сеть будет иметь 768*4 = 3072 нейронов). Почему именно в четыре? Просто это размер оригинального Трансформера (размерность модели была 512 и слоя #1 – 2048). Кажется, что это дает моделям Трансформера достаточную мощность представления для решения задач, которые ему до сих пор давались.
(Вектор смещения не отображен)
Полносвязная нейронная сеть GPT-2: Проецирование на размерность модели
Второй слой проецирует результат первого на размерность модели (768 у маленькой GPT-2). Результатом этого перемножения будет выход блока Трансформера для данного токена.

(Вектор смещения не отображен)
Вы сделали это!
Это наиболее детальное описание блока Трансформера, в которое мы когда-либо пускались. Вы теперь имеете достаточно обширную картину того, что происходит внутри языковой модели Трансформера. Подводя итоги, покажем, как наш храбрый входной вектор взаимодействует с матрицами весов:
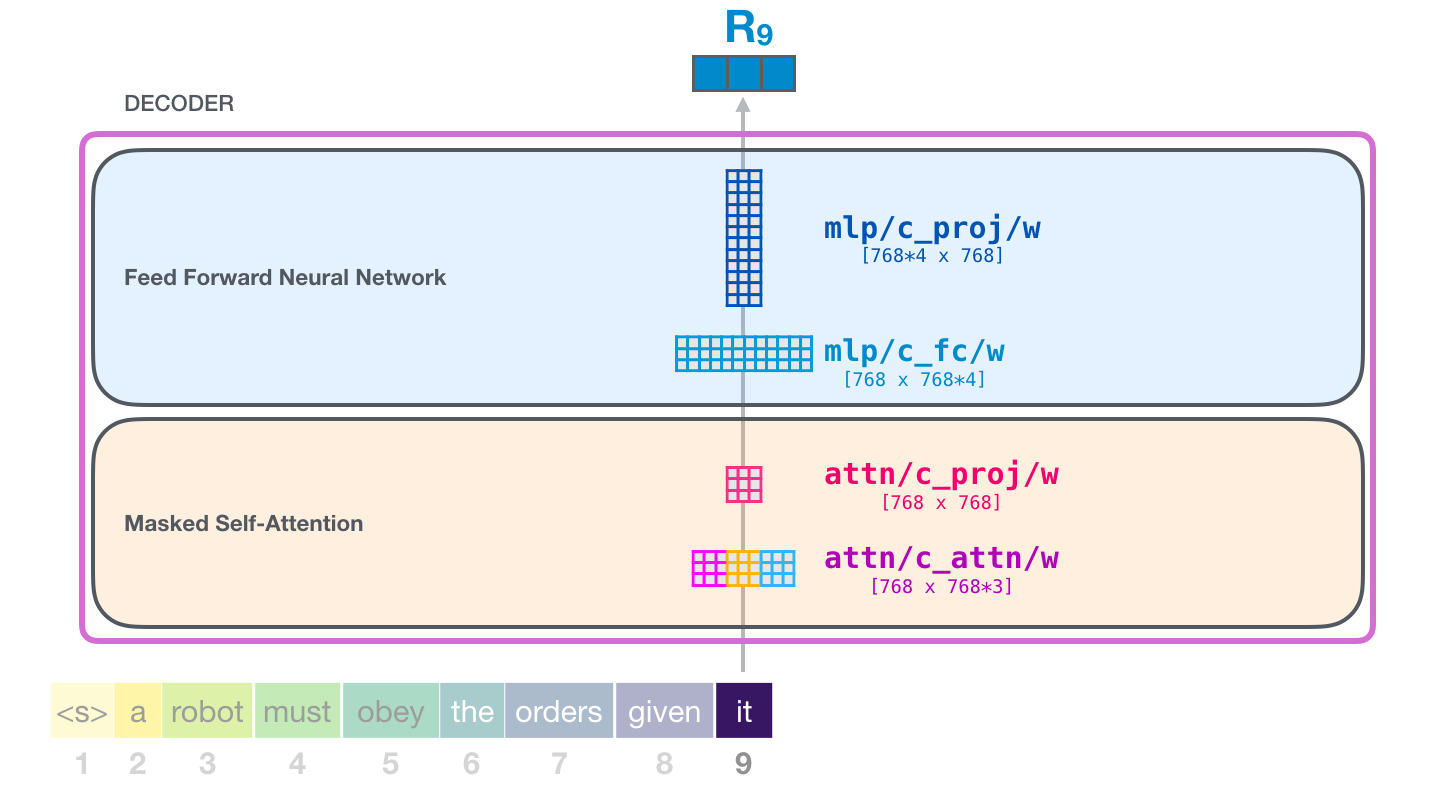
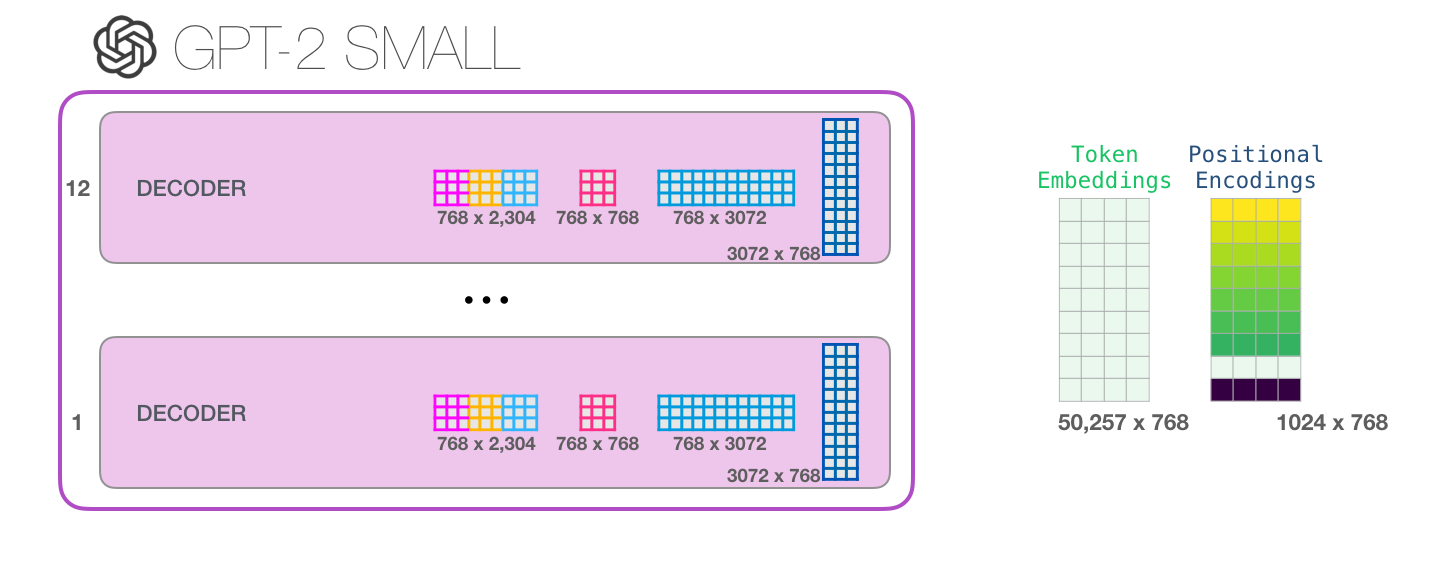
Каждый блок имеет свой собственный набор весов. С другой стороны, модель имеет только одну матрицу эмбеддинга токена и одну матрицу позиционного кодирования:
Если вы хотите увидеть все параметры этой модели, то они перечислены ниже:
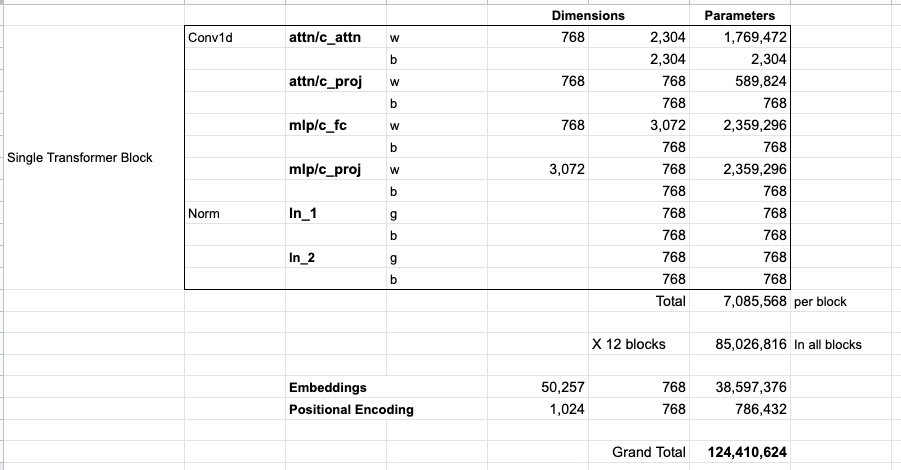
По какой-то причине здесь используется 124М параметров вместо 117М. Не вполне понятно почему, но кажется, что именно такое количество публикуется в открытом коде (поправьте, если это не так).
Часть 3: за пределами языкового моделирования
Декодирующие Трасформеры подают надежды и в задачах, отличных от языкового моделирования. Существует множество успешных применений этих моделей, которые можно визуализировать схожим образом. В завершение статьи посмотрим некоторые из этих применений.
Машинный перевод
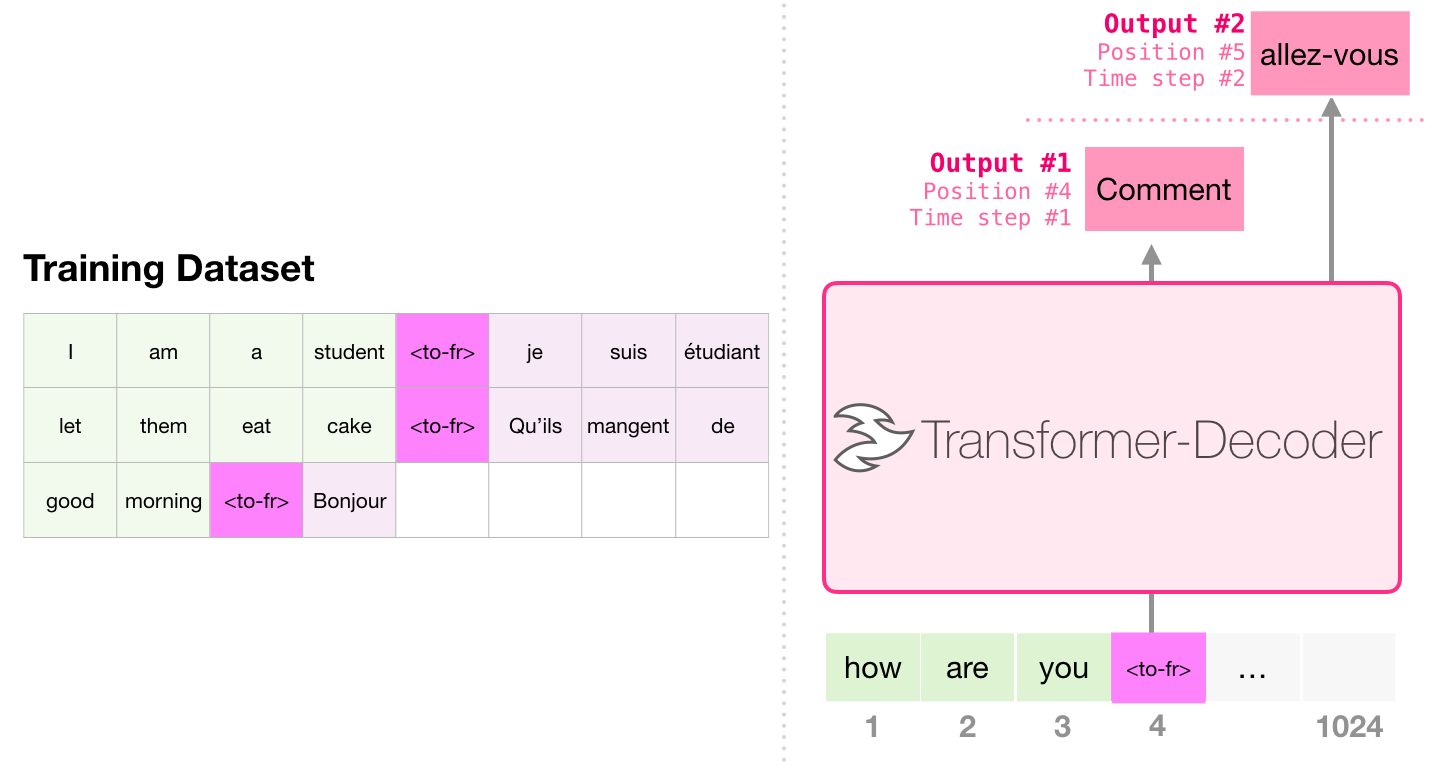
Энкодер не строго обязателен для осуществления перевода. Ту же задачу можно решить с помощью декодирующего Трансформера:
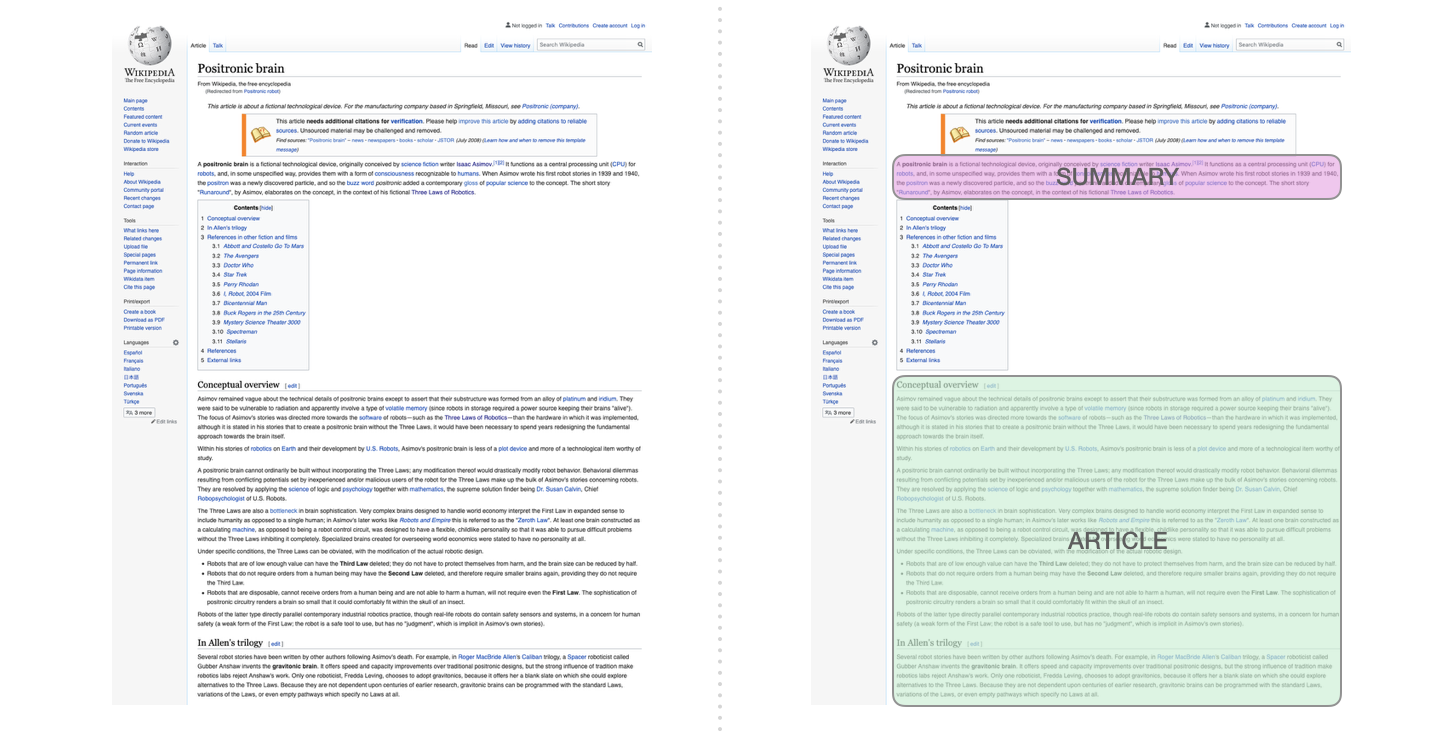
Суммаризация
Это та задача, для которой был обучен самый первый декодирующий Трасформер. А именно, он был обучен читать статьи Википедии (без вводной части, расположенной до содержания) и обобщать их. Реальные обобщающие части статей использовались в качестве тэгов в обучающем датасете:
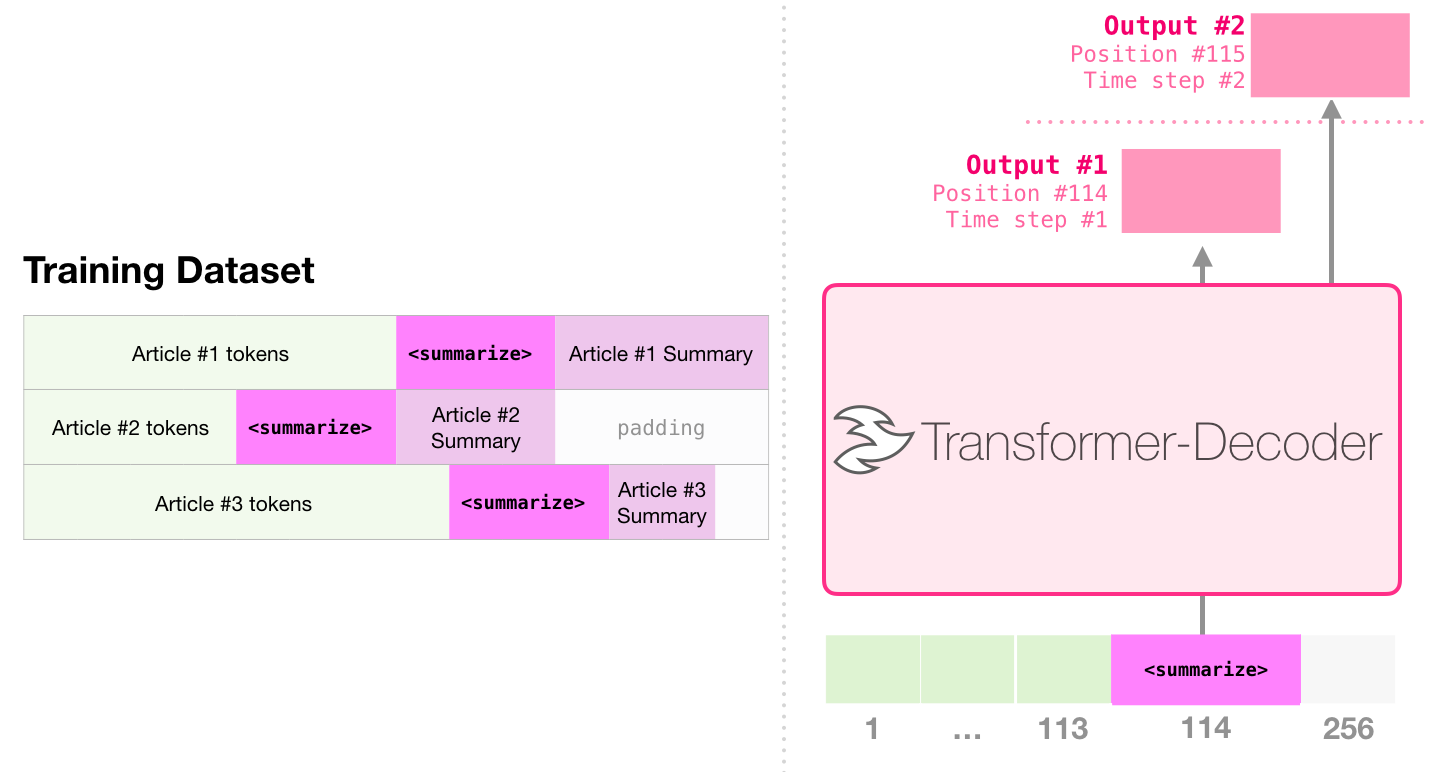
Обученная на статьях Википедии модель могла затем самостоятельно обобщать их.
Трансферное обучение
В статье Sample Efficient Text Summarization Using a Single Pre-Trained Transformer декодирующий Трасформер сначала был предобучен для языкового моделирования, а затем тонко настроен на суммаризацию. Оказалось, что благодаря такому подходу можно достичь лучших результатов, чем на предобученной модели энкодер-декодер на ограниченных объемах данных.
В релизной статье GPT-2 также приведены результаты суммаризации после предобучения модели на задаче языкового моделирования.
Генерация музыки
Музыкальный Трансформер использует архитектуру декодирующего Трасформера для генерации выразительной и динамичной музыки. «Музыкальное моделирование» очень похоже на языковое моделирование – просто позвольте модели обучаться музыке без учителя и свободно генерировать выходные последовательности (то, что мы называли выше «свободным плаванием»).
Вы можете задаться вопросом, как в таком случае представляется музыка. Помните, что языковое моделирование может осуществляться с помощью векторных представлений букв (символов), слов или токенов (частей слов). Для представления музыки (исполненной, например, на фортепиано) мы можем взять ноты и их «скорость» – меру того, как сильно была нажата клавиша.
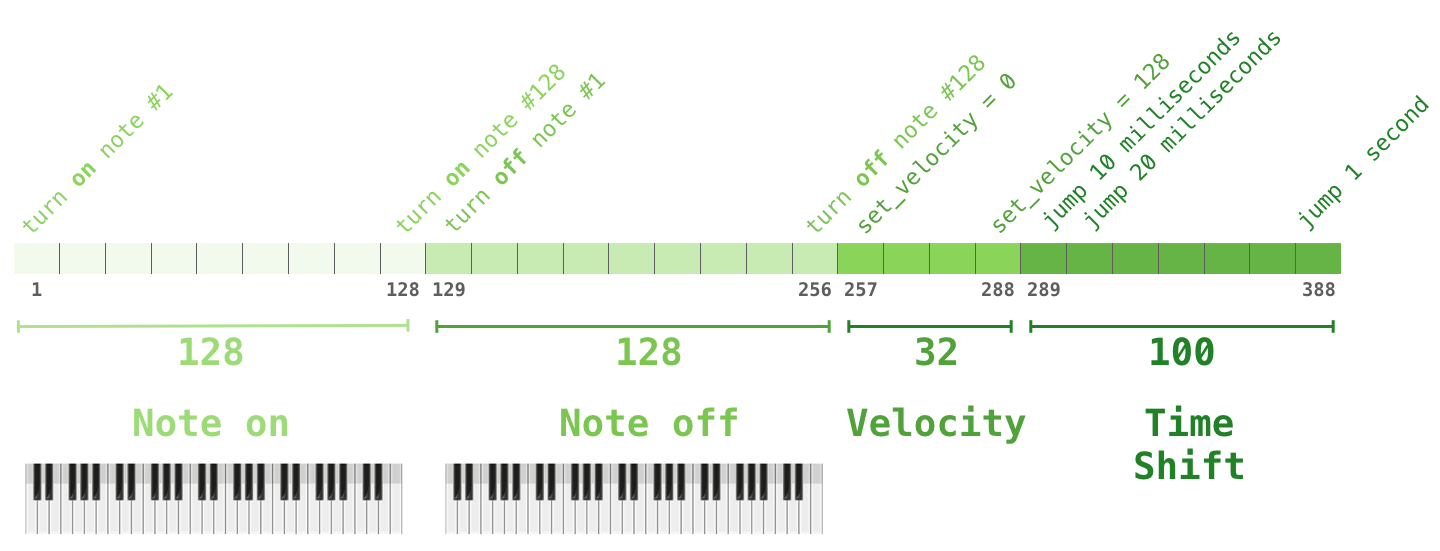
Произведение – это просто набор таких one-hot векторов. Файл формата midi может быть преобразован в такой формат. В статье есть следующий пример входной последовательности:

Представление one-hot вектора для этой входной последовательности будет выглядеть следующим образом:
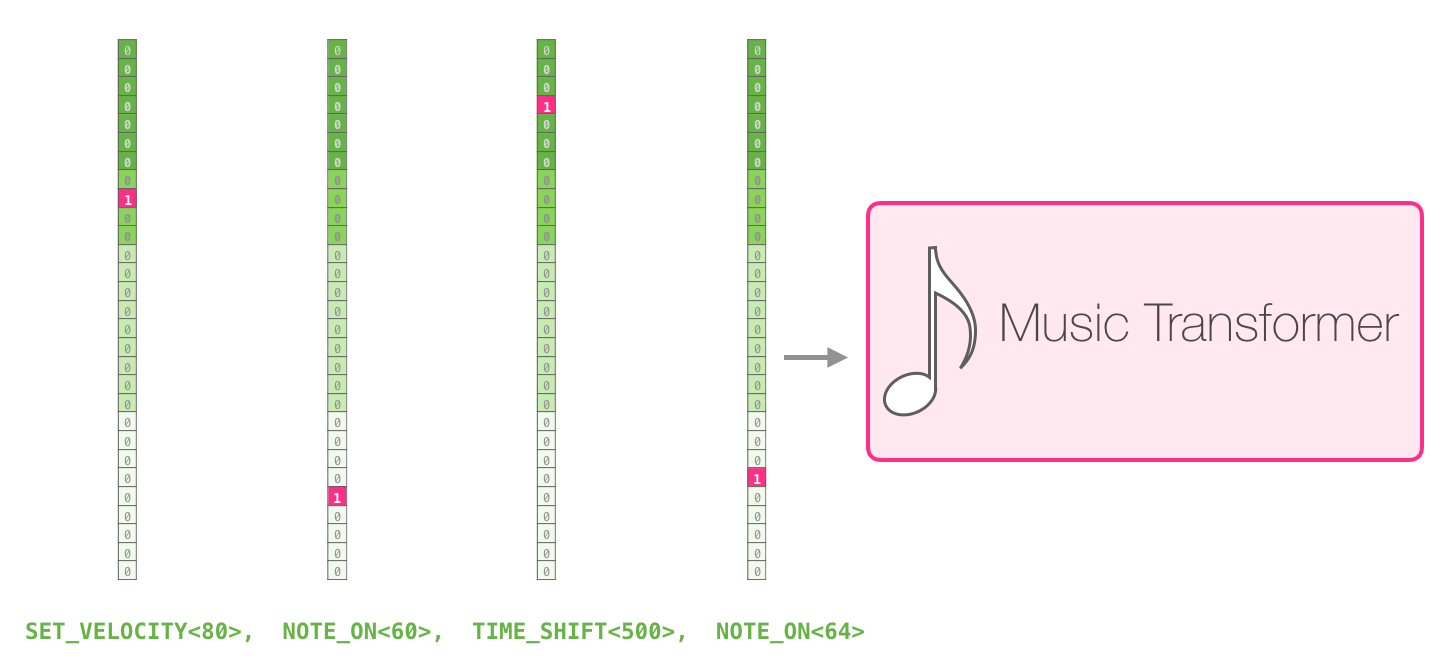
Также в статье есть прекрасная визуализация внутреннего внимания Музыкального Трансформера:
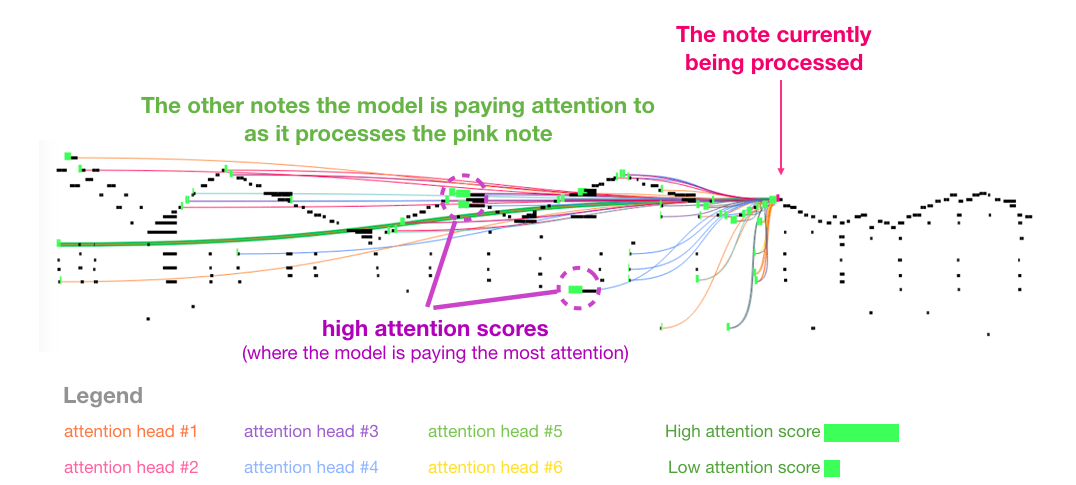
Если подобное представление музыкальных нот еще не совсем понятно, см. видео.
Заключение
Пора подытожить наше путешествие в GPT-2 и ее родительскую модель – декодирующий Трансформер. Надеемся, что после прочтения этой статьи вы стали лучше понимать механизм внутреннего внимания и теперь, когда вы знаете, что происходит внутри трансформера, вы можете более комфортно использовать модели на его основе.
Материалы
- Реализация GPT-2 от OpenAI
- См. библиотеку pytorch-transformers2 от Hugging Face, в которой помимо GPT-2, реализованы BERT, Transformer-XL, XLNet и другие передовые модели Трансформера.
Авторы
- Автор оригинала – Jay Alammar
- Перевод – Смирнова Екатерина
- Редактирование и вёрстка – Шкарин Сергей
rpisarev
Спасибо, статья очень захватывающая. Надо будет попробывать GPT-2 Small. Интересно с какими трудностями я столкнусь при использовании не английского?
Kouki_RUS Автор
Смотря какой язык. Думаю с основными европейскими (не русский) и китайским проблем не должно быть.