
Привет, Хабр!
Как знают наши постоянные читатели, мы давно и успешно издаем книги по Unity. В рамках проработки темы нас заинтересовал, в частности, инструментарий ML-Agents Toolkit. Сегодня мы предлагаем вашему вниманию перевод статьи из блога Unity о том, как эффективно обучать игровых агентов методом игры «с самим собой»; в частности, статья помогает понять, чем этот метод эффективнее традиционного обучения с подкреплением.

Приятного чтения!
В этом после дается обзор технологии self-play (игра с самим собой) и демонстрируется, как с ее помощью обеспечивается стабильное и эффективное обучение в демонстрационной среде Soccer из инструментария ML-Agents Toolkit.
В демонстрационных средах Tennis и Soccer из инструментария Unity ML-Agents Toolkit агенты стравливаются друг с другом как соперники. Обучение агентов в рамках такого состязательного сценария – порой весьма нетривиальная задача. На самом деле, в предыдущих релизах ML-Agents Toolkit для того, чтобы агент уверенно обучился, требовалась серьезная проработка награды. В версии 0.14 была добавлена возможность, позволяющая пользователю тренировать агентов методом обучения с подкреплением (RL) на основе self-play, механизма, имеющего принципиальное значение в достижении одних из наиболее высококлассных результатов обучения с подкреплением, например, OpenAI Five и DeepMind’s AlphaStar. Self-play при работе стравливает друг с другом актуальную и прошлую ипостаси агента. Таким образом, мы получаем противника для нашего агента, который может постепенно совершенствоваться с использованием традиционных алгоритмов обучения с подкреплением. Полноценно обученный агент может успешно соперничать с продвинутыми игроками-людьми.
Self-play предоставляет среду для обучения, которая построена по тем же принципам, что и соревнование с точки зрения человека. Например, человек, который учится играть в теннис, будет выбирать для спарринга соперников примерно того же уровня, что и сам, так как слишком сильный или слишком слабый соперник не так удобен для освоения игры. С точки зрения развития собственных навыков, для начинающего теннисиста может быть гораздо ценнее обыгрывать таких же начинающих, а не, скажем, ребенка-дошкольника или Новака Джоковича. Первый даже не сможет отбить мяч, а второй не подарит тебе такой подачи, которую ты сможешь отбить. Когда начинающий разовьет достаточную силу, он может переходить на следующий уровень или заявляться на более серьезный турнир, чтобы играть против более умелых соперников.
В этой статье мы рассмотрим некоторые технические тонкости, связанные с динамикой игры самим с собой, а также рассмотрим примеры работы в виртуальных окружениях Tennis и Soccer, отрефакторенных таким образом, чтобы проиллюстрировать игру с самим собой.
У феномена игры с самим собой – долгая история, отразившаяся в практике разработки искусственных игровых агентов, призванных соперничать с человеком в играх. Одним из первых эту систему использовал Артур Сэмюэл, разработавший в 1950-е симулятор для игры в шахматы и опубликовавший эту работу в 1959 году. Эта система стала предтечей эпохального результата в обучении с подкреплением, достигнутого Джеральдом Тезауро в игре TD-Gammon; итоги опубликованы в 1995 году. В TD-Gammon использовался алгоритм работы по методу временных различий TD(?) с функцией игры самим с собой, чтобы обучить агент игре в нарды настолько, что он мог бы посоперничать с человеком-профессионалом. В некоторых случаях наблюдалось, что TD-Gammon обладает более уверенным видением позиций, чем игроки международного класса.
Игра с самим собой нашла отражение во многих знаковых достижениях, связанных с RL. Важно отметить, что игра с самим собой помогла развитию агентов для игры в шахматы и го, обладающих сверхчеловеческими способностями, элитных агентов DOTA 2, а также сложных стратегий и контрстратегий в таких играх, как реслинг и прятки. В результатах, достигнутых при помощи игры с самим собой, часто отмечается, что игровые агенты избирают стратегии, удивляющие экспертов-людей.
Игра с самим собой наделяет агентов определенной креативностью, не зависящей от творчества программистов. Агент получает лишь правила игры, а затем – информацию о том, выиграл он или проиграл. Далее, опираясь на эти базовые принципы, агент должен сам выработать грамотное поведение. По словам создателя TD-Gammon, такой подход к обучению освобождает, «…в том смысле, что программа не стеснена человеческими склонностями и предрассудками, которые могут оказаться ошибочными и ненадежными». Благодаря такой свободе, агенты открывают блестящие игровые стратегии, совершенно изменившие представления специалистов-инженеров о некоторых играх.
В рамках традиционной задачи обучения с подкреплением агент пытается выработать такую линию поведения, которая доводит до максимума суммарную награду. Вознаграждающий сигнал кодирует задачу агента – такой задачей может быть, например, прокладка курса или сбор предметов. Поведение агента подчиняется ограничениям окружающей среды. Таковы, например, тяготение, преграды, а также относительное влияние действий, предпринимаемых самим агентом – например, приложение силы для собственного движения. Эти факторы ограничивают возможные варианты поведения агента и являются внешними силами, с которыми он должен научиться обращаться, чтобы получать высокую награду. Таким образом, агент тягается с динамикой окружающей среды, и должен переходить из состояния к состоянию именно так, чтобы достигалась максимальная награда.
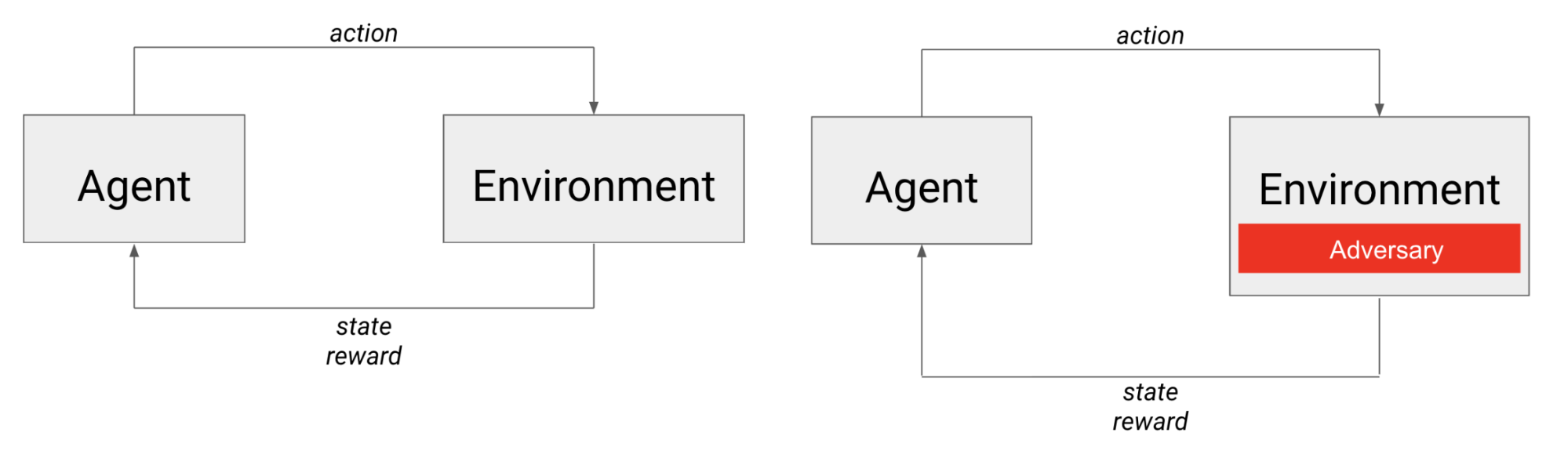
Слева показан типичный сценарий обучения с подкреплением: агент действует в окружающей среде, переходит в следующее состояние и получает награду. Справа показан сценарий обучения, где агент состязается с соперником, который, с точки зрения агента, фактически является элементом окружающей среды.
В случае с состязательными играми агент тягается не только с динамикой окружающей среды, но и с другим (возможно, интеллектуальным) агентом. Можно считать, что соперник встроен в окружающую среду, и его действия непосредственно влияют на следующее состояние, которое «увидит» агент, а также на награду, которую он получит.

Пример со средой «Теннис» из инструментария ML-Agents
Рассмотрим демо-пример ML-Agents Tennis. Голубая ракетка (слева) – это обучающийся агент, а фиолетовая (справа) – его соперник. Чтобы перекинуть мяч через сетку, агент должен учитывать траекторию мяча, летящего от соперника, и делать поправку угла и скорости летящего мяча с учетом условий среды (гравитации). Однако, в состязании с соперником перебросить мяч через сетку – это лишь полдела. Сильный соперник может ответить неотразимым ударом, и в результате агент проиграет. Слабый соперник может попасть мячом в сетку. Равный же соперник может вернуть подачу, и поэтому игра продолжится. В любом случае, как следующее состояние, так и соответствующая ему награда зависят как от условий окружающей среды, так и от соперника. Однако, во всех этих ситуациях агент делает одну и ту же подачу. Поэтому как обучение в состязательных играх, так и прокачка сопернических поведений у агента – это сложные проблемы.
Соображения, касающиеся подходящего оппонента, не тривиальны. Как понятно из изложенного выше, относительная сила оппонента значительно влияет на исход конкретной игры. Если оппонент слишком силен, то агенту, возможно, будет непросто научиться игре с нуля. С другой стороны, если оппонент слишком слаб, то агент может научиться побеждать, но эти навыки могут оказаться бесполезны в соревновании с более сильным или просто иным оппонентом. Следовательно, нам нужен оппонент, который будет примерно равен по силе агенту (неподатлив, но не непреодолим). Кроме того, поскольку навыки нашего агента улучшаются с каждой пройденной партией, мы должны в той же мере наращивать и силы его оппонента.
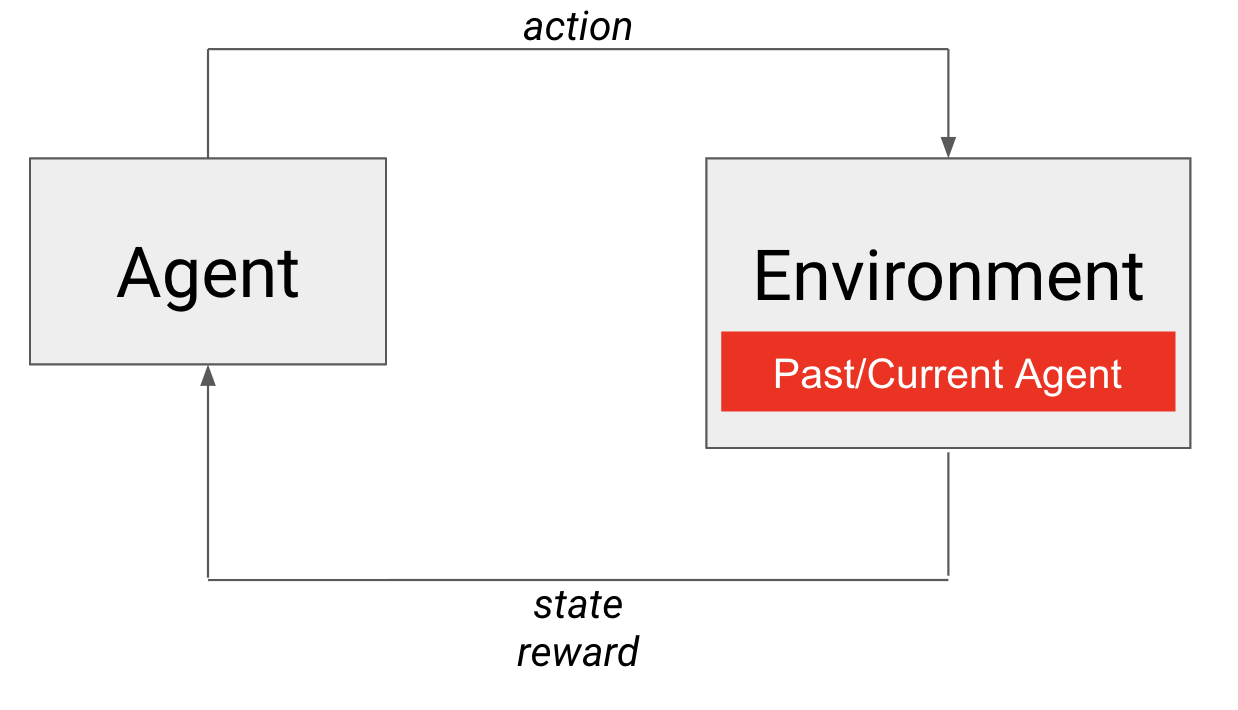
При игре с самим собой мгновенный снимок из прошлого или агент в его текущем состоянии – это и есть соперник, встроенный в окружающую среду.
Вот здесь нам и пригодится игра с самим собой! Сам агент удовлетворяет обоим требованиям к искомому оппоненту. Он определенно примерно равен по силе самому себе, и навыки его улучшаются со временем. В данном случае в окружающую среду встроена собственная политика агента (см. на рисунке). Тем, кто знаком с постепенно усложняющимся обучением (curriculum learning), подскажем, что эту систему можно считать естественным образом развивающимся учебным планом, следуя которому, агент научается сражаться против все более сильных оппонентов. Соответственно, игра с самим собой позволяет задействовать саму окружающую среду для обучения конкурентоспособных агентов для состязательных игр!
В двух следующих разделах будут рассмотрены более технические детали обучения конкурентоспособных агентов, касающиеся, в частности, реализации и использования игры с самим собой в инструментарии ML-Agents Toolkit.
Возникают некоторые проблемы практического характера, касающиеся самого фреймворка для игры с самим собой. В частности, возможно переобучение, при котором агент научается выигрывать только при определенном стиле игры, а также нестабильность, присущая процессу обучения, способная возникнуть из-за нестационарности функции перехода (то есть, из-за постоянно меняющихся оппонентов). Первая проблема возникает, поскольку мы хотим добиться от наших агентов общей подкованности и способности сражаться с оппонентами разных типов.
Вторую проблему можно проиллюстрировать в среде Tennis: разные оппоненты будут отбивать мяч с разной скоростью и под разными углами. С точки зрения обучающегося агента это означает, что, по мере обучения, одни и те же решения будут приводить к разным исходам и, соответственно, агент будет оказываться в разных последующих ситуациях. В традиционном обучении с подкреплением подразумеваются стационарные функции перехода. К сожалению, подготовив для агента подборку разнообразных оппонентов, чтобы решить первую проблему, мы, проявив неосторожность, можем усугубить вторую.
Чтобы справиться с этим, будем поддерживать буфер с прошлыми политиками агента, из которых и будем выбирать потенциальных соперников для нашего «ученика» на долгую перспективу. Выбирая из прошлых политик агента, мы получим для него подборку разнообразных оппонентов. Более того, позволяя агенту в течение долгого времени тренироваться с фиксированным оппонентом, мы стабилизируем функцию перехода и создаем более непротиворечивую учебную среду. Наконец, такими алгоритмическими аспектами можно управлять при помощи гиперпараметров, которые рассматриваются в следующем разделе.
Подбирая гиперпараметры для игры с самим собой, мы, прежде всего, держим в уме компромисс между уровнем оппонента, универсальностью окончательной политики и стабильностью обучения. Обучение в соперничестве с группой оппонентов, которые меняются медленно или вообще не меняются, а, значит, дают меньший разброс результатов – это более стабильный процесс, чем обучение в соперничестве с множеством разнообразных соперников, которые быстро меняются. Доступные гиперпараметры позволяют контролировать, как часто будет сохраняться текущая политика агента для последующего использования в качестве одного из соперников в выборке, как часто сохраняется новый соперник, впоследствии выбираемый для спарринга, как часто выбирается новый соперник, количество сохраненных оппонентов, а также вероятность того, что в данном случае обучаемому придется сыграть против собственного alter ego, а не против оппонента, выбранного из пула.
В состязательных играх «накопительная» награда, выдаваемая средой – пожалуй, не самая информативная метрика для отслеживания прогресса в обучении. Дело в том, что накопительная награда целиком и полностью зависит от уровня оппонента. Агент, обладающий определенным игровым мастерством, получит большую или меньшую награду, в зависимости от менее умелого или более умелого оппонента, соответственно. Мы предлагаем реализацию рейтинговой системы ELO, позволяющей рассчитывать относительное игровое мастерство у двух игроков из определенной популяции при игре с нулевой суммой. В течение отдельно взятого тренировочного прогона это значение должно стабильно увеличиваться. Отслеживать его, наряду с другими метриками обучения, например, общей наградой, можно при помощи TensorBoard.
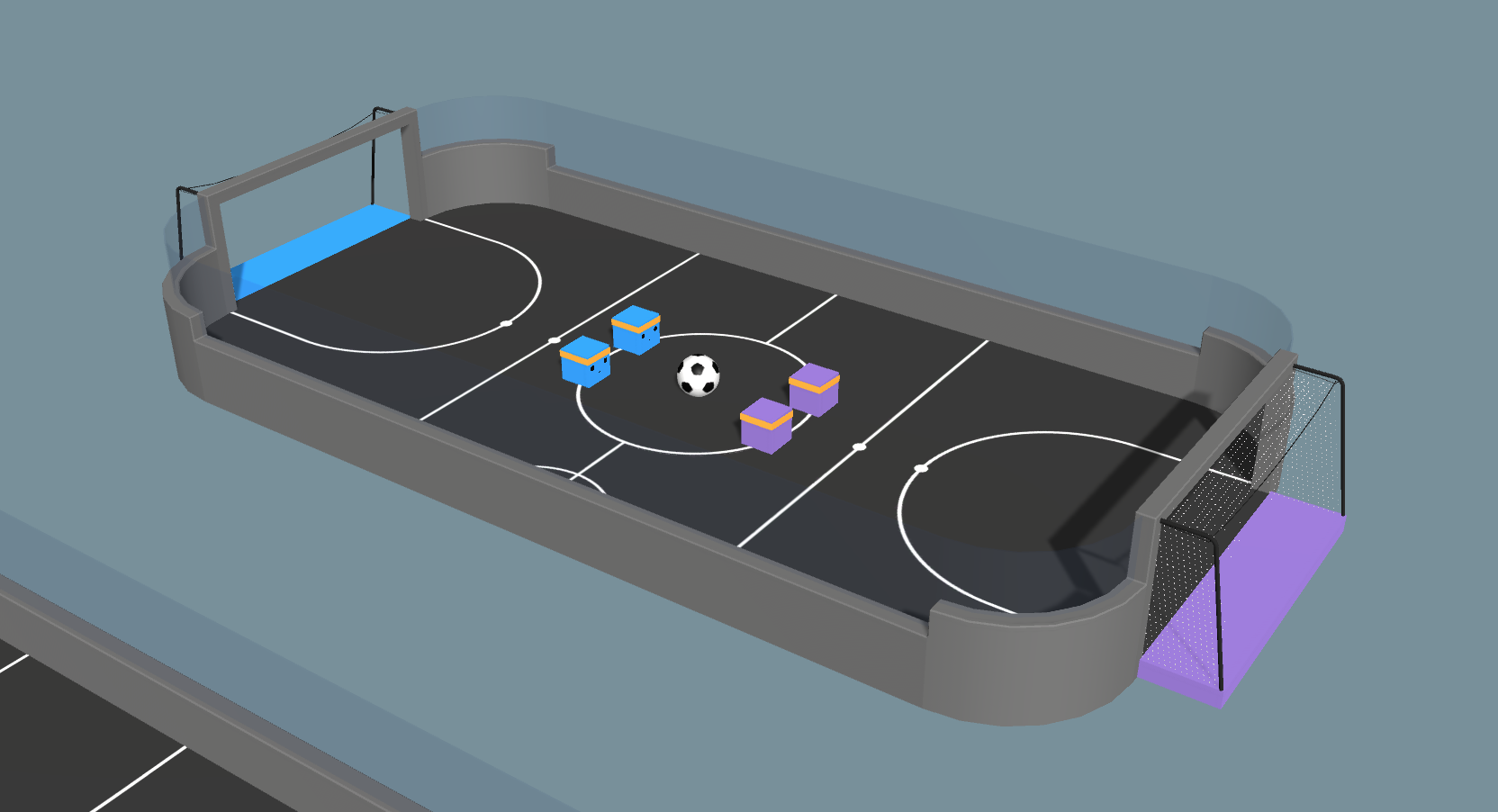
В последние релизы ML-Agent Toolkit не включается политика агентов для учебной среды Soccer, поскольку надежный учебный процесс в ней не выстраивался. Однако, задействовав игру с самим собой и проведя некоторый рефакторинг, мы сможем обучать агента нетривиальным вариантам поведения. Наиболее существенное изменение – это удаление «игровых позиций» из числа характеристик агента. Ранее в среде Soccer явно выделялись «вратарь» и «нападающий», поэтому весь геймплей выглядел более логично. В данном видео представлена новая среда, в которой видно, как спонтанно формируется ролевое поведение, при котором одни агенты начинают выступать в качестве нападающих, а другие – в качестве вратарей. Теперь агенты сами учатся играть на этих позициях! Функция награды для всех четырех агентов определяется как +1.0 за забитый гол и -1.0 за пропущенный гол, с дополнительным штрафом -0.0003 за шаг – этот штраф предусмотрен, чтобы стимулировать агентов на атаку.
Здесь еще раз подчеркнем, что агенты в учебной среде Soccer сами научаются кооперативному поведению, и для этого не используется никакого явного алгоритма, связанного с мультиагентным поведением или присваиванием ролей. Этот результат демонстрирует, что агента можно обучать сложным вариантам поведения, пользуясь сравнительно простыми алгоритмами – при условии, что задача будет качественно сформулирована. Важнейшее условие для этого заключается в том, что агенты могут наблюдать за своими сокомандниками, то есть, они получают информацию об относительной позиции сокомандника. Навязывая агрессивную борьбу за мяч, агент косвенно подсказывает сокоманднику, что тот должен отойти в защиту. Напротив, отходя в защиту, агент провоцирует сокомандника на нападение.
Если вам доводилось пользоваться какими-либо новыми возможностями из этого релиза – расскажите о них. Обращаем ваше внимание на страницу ML-Agents GitHub issues, где можно рассказать о найденных багах, а также на страницу форумов Unity ML-Agents, где обсуждаются вопросы и проблемы общего характера.
Как знают наши постоянные читатели, мы давно и успешно издаем книги по Unity. В рамках проработки темы нас заинтересовал, в частности, инструментарий ML-Agents Toolkit. Сегодня мы предлагаем вашему вниманию перевод статьи из блога Unity о том, как эффективно обучать игровых агентов методом игры «с самим собой»; в частности, статья помогает понять, чем этот метод эффективнее традиционного обучения с подкреплением.
Приятного чтения!
В этом после дается обзор технологии self-play (игра с самим собой) и демонстрируется, как с ее помощью обеспечивается стабильное и эффективное обучение в демонстрационной среде Soccer из инструментария ML-Agents Toolkit.
В демонстрационных средах Tennis и Soccer из инструментария Unity ML-Agents Toolkit агенты стравливаются друг с другом как соперники. Обучение агентов в рамках такого состязательного сценария – порой весьма нетривиальная задача. На самом деле, в предыдущих релизах ML-Agents Toolkit для того, чтобы агент уверенно обучился, требовалась серьезная проработка награды. В версии 0.14 была добавлена возможность, позволяющая пользователю тренировать агентов методом обучения с подкреплением (RL) на основе self-play, механизма, имеющего принципиальное значение в достижении одних из наиболее высококлассных результатов обучения с подкреплением, например, OpenAI Five и DeepMind’s AlphaStar. Self-play при работе стравливает друг с другом актуальную и прошлую ипостаси агента. Таким образом, мы получаем противника для нашего агента, который может постепенно совершенствоваться с использованием традиционных алгоритмов обучения с подкреплением. Полноценно обученный агент может успешно соперничать с продвинутыми игроками-людьми.
Self-play предоставляет среду для обучения, которая построена по тем же принципам, что и соревнование с точки зрения человека. Например, человек, который учится играть в теннис, будет выбирать для спарринга соперников примерно того же уровня, что и сам, так как слишком сильный или слишком слабый соперник не так удобен для освоения игры. С точки зрения развития собственных навыков, для начинающего теннисиста может быть гораздо ценнее обыгрывать таких же начинающих, а не, скажем, ребенка-дошкольника или Новака Джоковича. Первый даже не сможет отбить мяч, а второй не подарит тебе такой подачи, которую ты сможешь отбить. Когда начинающий разовьет достаточную силу, он может переходить на следующий уровень или заявляться на более серьезный турнир, чтобы играть против более умелых соперников.
В этой статье мы рассмотрим некоторые технические тонкости, связанные с динамикой игры самим с собой, а также рассмотрим примеры работы в виртуальных окружениях Tennis и Soccer, отрефакторенных таким образом, чтобы проиллюстрировать игру с самим собой.
История игры с самим собой в играх
У феномена игры с самим собой – долгая история, отразившаяся в практике разработки искусственных игровых агентов, призванных соперничать с человеком в играх. Одним из первых эту систему использовал Артур Сэмюэл, разработавший в 1950-е симулятор для игры в шахматы и опубликовавший эту работу в 1959 году. Эта система стала предтечей эпохального результата в обучении с подкреплением, достигнутого Джеральдом Тезауро в игре TD-Gammon; итоги опубликованы в 1995 году. В TD-Gammon использовался алгоритм работы по методу временных различий TD(?) с функцией игры самим с собой, чтобы обучить агент игре в нарды настолько, что он мог бы посоперничать с человеком-профессионалом. В некоторых случаях наблюдалось, что TD-Gammon обладает более уверенным видением позиций, чем игроки международного класса.
Игра с самим собой нашла отражение во многих знаковых достижениях, связанных с RL. Важно отметить, что игра с самим собой помогла развитию агентов для игры в шахматы и го, обладающих сверхчеловеческими способностями, элитных агентов DOTA 2, а также сложных стратегий и контрстратегий в таких играх, как реслинг и прятки. В результатах, достигнутых при помощи игры с самим собой, часто отмечается, что игровые агенты избирают стратегии, удивляющие экспертов-людей.
Игра с самим собой наделяет агентов определенной креативностью, не зависящей от творчества программистов. Агент получает лишь правила игры, а затем – информацию о том, выиграл он или проиграл. Далее, опираясь на эти базовые принципы, агент должен сам выработать грамотное поведение. По словам создателя TD-Gammon, такой подход к обучению освобождает, «…в том смысле, что программа не стеснена человеческими склонностями и предрассудками, которые могут оказаться ошибочными и ненадежными». Благодаря такой свободе, агенты открывают блестящие игровые стратегии, совершенно изменившие представления специалистов-инженеров о некоторых играх.
Обучение с подкреплением в состязательных играх
В рамках традиционной задачи обучения с подкреплением агент пытается выработать такую линию поведения, которая доводит до максимума суммарную награду. Вознаграждающий сигнал кодирует задачу агента – такой задачей может быть, например, прокладка курса или сбор предметов. Поведение агента подчиняется ограничениям окружающей среды. Таковы, например, тяготение, преграды, а также относительное влияние действий, предпринимаемых самим агентом – например, приложение силы для собственного движения. Эти факторы ограничивают возможные варианты поведения агента и являются внешними силами, с которыми он должен научиться обращаться, чтобы получать высокую награду. Таким образом, агент тягается с динамикой окружающей среды, и должен переходить из состояния к состоянию именно так, чтобы достигалась максимальная награда.
Слева показан типичный сценарий обучения с подкреплением: агент действует в окружающей среде, переходит в следующее состояние и получает награду. Справа показан сценарий обучения, где агент состязается с соперником, который, с точки зрения агента, фактически является элементом окружающей среды.
В случае с состязательными играми агент тягается не только с динамикой окружающей среды, но и с другим (возможно, интеллектуальным) агентом. Можно считать, что соперник встроен в окружающую среду, и его действия непосредственно влияют на следующее состояние, которое «увидит» агент, а также на награду, которую он получит.
Пример со средой «Теннис» из инструментария ML-Agents
Рассмотрим демо-пример ML-Agents Tennis. Голубая ракетка (слева) – это обучающийся агент, а фиолетовая (справа) – его соперник. Чтобы перекинуть мяч через сетку, агент должен учитывать траекторию мяча, летящего от соперника, и делать поправку угла и скорости летящего мяча с учетом условий среды (гравитации). Однако, в состязании с соперником перебросить мяч через сетку – это лишь полдела. Сильный соперник может ответить неотразимым ударом, и в результате агент проиграет. Слабый соперник может попасть мячом в сетку. Равный же соперник может вернуть подачу, и поэтому игра продолжится. В любом случае, как следующее состояние, так и соответствующая ему награда зависят как от условий окружающей среды, так и от соперника. Однако, во всех этих ситуациях агент делает одну и ту же подачу. Поэтому как обучение в состязательных играх, так и прокачка сопернических поведений у агента – это сложные проблемы.
Соображения, касающиеся подходящего оппонента, не тривиальны. Как понятно из изложенного выше, относительная сила оппонента значительно влияет на исход конкретной игры. Если оппонент слишком силен, то агенту, возможно, будет непросто научиться игре с нуля. С другой стороны, если оппонент слишком слаб, то агент может научиться побеждать, но эти навыки могут оказаться бесполезны в соревновании с более сильным или просто иным оппонентом. Следовательно, нам нужен оппонент, который будет примерно равен по силе агенту (неподатлив, но не непреодолим). Кроме того, поскольку навыки нашего агента улучшаются с каждой пройденной партией, мы должны в той же мере наращивать и силы его оппонента.
При игре с самим собой мгновенный снимок из прошлого или агент в его текущем состоянии – это и есть соперник, встроенный в окружающую среду.
Вот здесь нам и пригодится игра с самим собой! Сам агент удовлетворяет обоим требованиям к искомому оппоненту. Он определенно примерно равен по силе самому себе, и навыки его улучшаются со временем. В данном случае в окружающую среду встроена собственная политика агента (см. на рисунке). Тем, кто знаком с постепенно усложняющимся обучением (curriculum learning), подскажем, что эту систему можно считать естественным образом развивающимся учебным планом, следуя которому, агент научается сражаться против все более сильных оппонентов. Соответственно, игра с самим собой позволяет задействовать саму окружающую среду для обучения конкурентоспособных агентов для состязательных игр!
В двух следующих разделах будут рассмотрены более технические детали обучения конкурентоспособных агентов, касающиеся, в частности, реализации и использования игры с самим собой в инструментарии ML-Agents Toolkit.
Практические соображения
Возникают некоторые проблемы практического характера, касающиеся самого фреймворка для игры с самим собой. В частности, возможно переобучение, при котором агент научается выигрывать только при определенном стиле игры, а также нестабильность, присущая процессу обучения, способная возникнуть из-за нестационарности функции перехода (то есть, из-за постоянно меняющихся оппонентов). Первая проблема возникает, поскольку мы хотим добиться от наших агентов общей подкованности и способности сражаться с оппонентами разных типов.
Вторую проблему можно проиллюстрировать в среде Tennis: разные оппоненты будут отбивать мяч с разной скоростью и под разными углами. С точки зрения обучающегося агента это означает, что, по мере обучения, одни и те же решения будут приводить к разным исходам и, соответственно, агент будет оказываться в разных последующих ситуациях. В традиционном обучении с подкреплением подразумеваются стационарные функции перехода. К сожалению, подготовив для агента подборку разнообразных оппонентов, чтобы решить первую проблему, мы, проявив неосторожность, можем усугубить вторую.
Чтобы справиться с этим, будем поддерживать буфер с прошлыми политиками агента, из которых и будем выбирать потенциальных соперников для нашего «ученика» на долгую перспективу. Выбирая из прошлых политик агента, мы получим для него подборку разнообразных оппонентов. Более того, позволяя агенту в течение долгого времени тренироваться с фиксированным оппонентом, мы стабилизируем функцию перехода и создаем более непротиворечивую учебную среду. Наконец, такими алгоритмическими аспектами можно управлять при помощи гиперпараметров, которые рассматриваются в следующем разделе.
Реализация и детали использования
Подбирая гиперпараметры для игры с самим собой, мы, прежде всего, держим в уме компромисс между уровнем оппонента, универсальностью окончательной политики и стабильностью обучения. Обучение в соперничестве с группой оппонентов, которые меняются медленно или вообще не меняются, а, значит, дают меньший разброс результатов – это более стабильный процесс, чем обучение в соперничестве с множеством разнообразных соперников, которые быстро меняются. Доступные гиперпараметры позволяют контролировать, как часто будет сохраняться текущая политика агента для последующего использования в качестве одного из соперников в выборке, как часто сохраняется новый соперник, впоследствии выбираемый для спарринга, как часто выбирается новый соперник, количество сохраненных оппонентов, а также вероятность того, что в данном случае обучаемому придется сыграть против собственного alter ego, а не против оппонента, выбранного из пула.
В состязательных играх «накопительная» награда, выдаваемая средой – пожалуй, не самая информативная метрика для отслеживания прогресса в обучении. Дело в том, что накопительная награда целиком и полностью зависит от уровня оппонента. Агент, обладающий определенным игровым мастерством, получит большую или меньшую награду, в зависимости от менее умелого или более умелого оппонента, соответственно. Мы предлагаем реализацию рейтинговой системы ELO, позволяющей рассчитывать относительное игровое мастерство у двух игроков из определенной популяции при игре с нулевой суммой. В течение отдельно взятого тренировочного прогона это значение должно стабильно увеличиваться. Отслеживать его, наряду с другими метриками обучения, например, общей наградой, можно при помощи TensorBoard.
Игра с самим собой в среде Soccer
В последние релизы ML-Agent Toolkit не включается политика агентов для учебной среды Soccer, поскольку надежный учебный процесс в ней не выстраивался. Однако, задействовав игру с самим собой и проведя некоторый рефакторинг, мы сможем обучать агента нетривиальным вариантам поведения. Наиболее существенное изменение – это удаление «игровых позиций» из числа характеристик агента. Ранее в среде Soccer явно выделялись «вратарь» и «нападающий», поэтому весь геймплей выглядел более логично. В данном видео представлена новая среда, в которой видно, как спонтанно формируется ролевое поведение, при котором одни агенты начинают выступать в качестве нападающих, а другие – в качестве вратарей. Теперь агенты сами учатся играть на этих позициях! Функция награды для всех четырех агентов определяется как +1.0 за забитый гол и -1.0 за пропущенный гол, с дополнительным штрафом -0.0003 за шаг – этот штраф предусмотрен, чтобы стимулировать агентов на атаку.
Здесь еще раз подчеркнем, что агенты в учебной среде Soccer сами научаются кооперативному поведению, и для этого не используется никакого явного алгоритма, связанного с мультиагентным поведением или присваиванием ролей. Этот результат демонстрирует, что агента можно обучать сложным вариантам поведения, пользуясь сравнительно простыми алгоритмами – при условии, что задача будет качественно сформулирована. Важнейшее условие для этого заключается в том, что агенты могут наблюдать за своими сокомандниками, то есть, они получают информацию об относительной позиции сокомандника. Навязывая агрессивную борьбу за мяч, агент косвенно подсказывает сокоманднику, что тот должен отойти в защиту. Напротив, отходя в защиту, агент провоцирует сокомандника на нападение.
Что дальше
Если вам доводилось пользоваться какими-либо новыми возможностями из этого релиза – расскажите о них. Обращаем ваше внимание на страницу ML-Agents GitHub issues, где можно рассказать о найденных багах, а также на страницу форумов Unity ML-Agents, где обсуждаются вопросы и проблемы общего характера.

atri1
без негатива
в каждой статье про нейросети всегда общее то что — никакой конкретики
сколько времени занимает обучение до минимально рабочего состояния и до полноценного(с командным взаимодействием), сколько ресурсов требует воспроизведение обученных ботов для релиза
по статистике техже, упомянутых в статье, OpenAI где они опубликовали цифры по времени и деньгам, это годы на обучение с поддержкой команды самых лучших специалистов по нейросетям, с использованием невероятных мощностей арендуемых у Амазон (на несколько сотен тысяч долларов)
и результат требовал нескольких супер мощных ПК, и уже упирался в потолок по производительности из за сложной логики, и дальнейшее обучение требовало удаление кусков существующий логики или оптимизации очень сильной
тоесть эта статья просто обзор возможностей, без реального применения?
Sommerregen
реальное применение для генерации «умного» ИИ для игр или для тестирования уровней, нахождение багов и дизбаланса и тп
Kirsch
Всё сильно зависит от задачи. При правильно настроенных параметрах, простые задачки типа достижения заданных координат на поверхности агенты самостоятельно начинают выполнять через 150-200 тыс итераций обучения (шагов, steps в терминологии tensor flow), время тут измеряется минутами при большом числе одновременно обучающихся агентов. В комплексной среде и со сложными задачами (например, когда на входе не raycast сигналы, а видео), это миллионы итераций и часы/дни обучения. Извините, наверное тоже слишком поверхностно, но это не то что в рамках комментария, в рамках целой статьи сложно подробно изложить.
Sommerregen
гонку с рейкастом я натренировал за 45 минут на моем ПК, ИИ ездил лучше меня. Для реальных игр, есть блог юнити, где они решают уровни для мобильной игре по изображения. Как они пишут, за 4ч решают. Ровио, которые Angry Birds, тоже решают свои уровни с РЛ для нахождения баланса и тп