
Обзор лучших функций, включенных в последнюю итерацию Python.

Пришло время, выход новой версии Python неизбежен. Сейчас она в бета-версии (3.9.0b3), но скоро мы увидим полную версию Python 3.9.
Некоторые из новейших функций невероятно интересные, и будет восхитительно видеть их использование после релиза. Мы рассмотрим следующее:
Давайте сначала рассмотрим новые функции и то, как мы их будем использовать.
Одна из новых и уже моих любимых фич с синтаксисом. Если у нас есть два словаря
У нас есть оператор слияния “
И оператор обновления “
Если наши словари имеют общий ключ, будет использована пара ключ-значение из второго словаря:
Еще одно интересное поведение оператора “
Если мы попробуем повторить то же самое со стандартным оператором объединения “
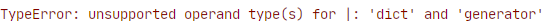
Python динамически типизирован, то есть нам не нужно указывать типы данных в нашем коде.
Это нормально, но иногда это может сбивать с толку, и внезапно гибкость Python становится более неприятной, чем что-либо еще.
Начиная с версии 3.5 мы могли указывать типы, но это было довольно громоздко. Текущее обновление действительно изменило подход, давайте посмотрим пример:

В нашей функции
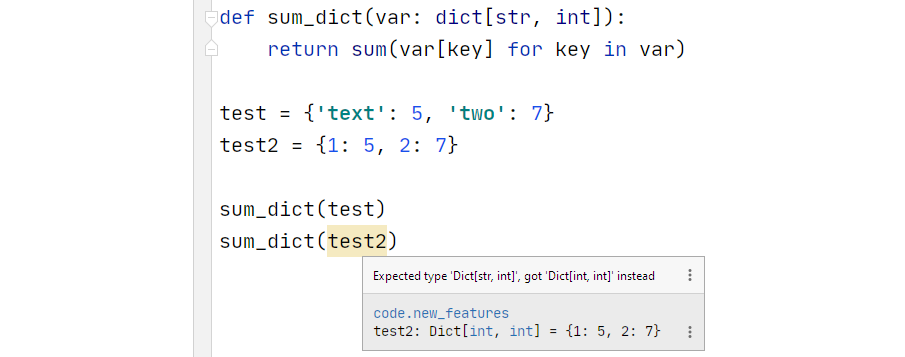
Теперь мы можем указать ожидаемый тип как
Мы также можем получить сведения об ожидаемых типах, например:
Тайп хинтинг может использоваться везде — и благодаря новому синтаксису он теперь выглядит намного чище:

Не так эффектны, как другие новые функции, но все же стоит их упомянуть, поскольку это может быть полезно. Добавлены два новых строковых метода для удаления префиксов и суффиксов:
Это скорее скрытое изменение, но оно может стать одним из наиболее значительных изменений для будущего развития Python.
В настоящее время Python использует грамматику, основанную преимущественно на LL(1), которая, в свою очередь, может быть проанализирована синтаксическим анализатором LL(1), который анализирует код сверху вниз, слева направо, с возможностью просмотра только одного токена.
Я почти не представляю, как это работает, но я могу рассказать вам про несколько актуальных проблем в Python из-за использования этого метода:
Все эти факторы (и многие другие, которые я просто не могу понять) оказывают одно большое влияние на Python; они ограничивают развитие языка.
Новый синтаксический анализатор, основанный на PEG, даст разработчикам Python значительно больше гибкости — и мы начнем это замечать начиная с Python 3.10.
Это то, что мы увидим в будущем Python 3.9. Если вы нетерпеливы, самая последняя бета-версия — 3.9.0b3 — доступна здесь.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
Пришло время, выход новой версии Python неизбежен. Сейчас она в бета-версии (3.9.0b3), но скоро мы увидим полную версию Python 3.9.
Некоторые из новейших функций невероятно интересные, и будет восхитительно видеть их использование после релиза. Мы рассмотрим следующее:
- Операторы объединения словарей
- Тайп хинтинг
- Два новых строковых метода
- Новый Python Parser — это очень круто
Давайте сначала рассмотрим новые функции и то, как мы их будем использовать.
Объединение словарей
Одна из новых и уже моих любимых фич с синтаксисом. Если у нас есть два словаря
a и b, которые нам нужно объединить, мы теперь используем операторы объединения.У нас есть оператор слияния “
|”:a = {1: 'a', 2: 'b', 3: 'c'}
b = {4: 'd', 5: 'e'}
c = a | b
print(c)[Out]: {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'}И оператор обновления “
|=”, который обновляет исходный словарь:a = {1: 'a', 2: 'b', 3: 'c'}
b = {4: 'd', 5: 'e'}
a |= b
print(a)[Out]: {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'}Если наши словари имеют общий ключ, будет использована пара ключ-значение из второго словаря:
a = {1: 'a', 2: 'b', 3: 'c', 6: 'in both'}
b = {4: 'd', 5: 'e', 6: 'but different'}
print(a | b)[Out]: {1: 'a', 2: 'b', 3: 'c', 6: 'but different', 4: 'd', 5: 'e'}Обновление словаря с помощью итераций
Еще одно интересное поведение оператора “
|=” — возможность обновлять словарь новыми парами ключ-значение, используя итеративный объект — например, список или генератор:a = {'a': 'one', 'b': 'two'}
b = ((i, i**2) for i in range(3))
a |= b
print(a)[Out]: {'a': 'one', 'b': 'two', 0: 0, 1: 1, 2: 4}Если мы попробуем повторить то же самое со стандартным оператором объединения “
|” мы получим TypeError, поскольку он будет разрешать только объединения между типами dict.Тайп хинтинг
Python динамически типизирован, то есть нам не нужно указывать типы данных в нашем коде.
Это нормально, но иногда это может сбивать с толку, и внезапно гибкость Python становится более неприятной, чем что-либо еще.
Начиная с версии 3.5 мы могли указывать типы, но это было довольно громоздко. Текущее обновление действительно изменило подход, давайте посмотрим пример:
В нашей функции
add_int мы явно хотим сложить два одинаковых числа(по какой-то загадочной неопределенной причине). Но наш редактор этого не знает, и совершенно нормально соединять две строки используя “+”, поэтому никакого предупреждения мы не увидим.Теперь мы можем указать ожидаемый тип как
int. Используя это, наш редактор сразу обнаруживает проблему.Мы также можем получить сведения об ожидаемых типах, например:
Тайп хинтинг может использоваться везде — и благодаря новому синтаксису он теперь выглядит намного чище:
Строковые методы
Не так эффектны, как другие новые функции, но все же стоит их упомянуть, поскольку это может быть полезно. Добавлены два новых строковых метода для удаления префиксов и суффиксов:
"Hello world".removeprefix("He")[Out]: "llo world""Hello world".removesuffix("ld")[Out]: "Hello wor"Новый парсер
Это скорее скрытое изменение, но оно может стать одним из наиболее значительных изменений для будущего развития Python.
В настоящее время Python использует грамматику, основанную преимущественно на LL(1), которая, в свою очередь, может быть проанализирована синтаксическим анализатором LL(1), который анализирует код сверху вниз, слева направо, с возможностью просмотра только одного токена.
Я почти не представляю, как это работает, но я могу рассказать вам про несколько актуальных проблем в Python из-за использования этого метода:
- Python содержит грамматику non-LL(1); из-за этого некоторые части текущей грамматики используют обходные пути, создавая ненужную сложность.
- LL(1) создает ограничения в синтаксисе Python (без возможных обходных путей). Эта проблема подчеркивает, что следующий код просто не может быть реализован с использованием текущего синтаксического анализатора (вызывает ошибку SyntaxError):
with (open("a_really_long_foo") as foo, open("a_really_long_bar") as bar): pass
- Из-за левой рекурсии (порядка выполнения слева направо) некоторые функции при парсинге могут сломать парсер и загнать его в бесконечную рекурсию. То есть конкретный рекурсивный синтаксис может вызвать бесконечный цикл в дереве синтаксического анализа, Гвидо ван Россум, создатель Python, объясняет это здесь.
Все эти факторы (и многие другие, которые я просто не могу понять) оказывают одно большое влияние на Python; они ограничивают развитие языка.
Новый синтаксический анализатор, основанный на PEG, даст разработчикам Python значительно больше гибкости — и мы начнем это замечать начиная с Python 3.10.
Это то, что мы увидим в будущем Python 3.9. Если вы нетерпеливы, самая последняя бета-версия — 3.9.0b3 — доступна здесь.
Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
- Курс по Machine Learning (12 недель)
- Курс «Профессия Data Scientist» (24 месяца)
- Курс «Профессия Data Analyst» (18 месяцев)
- Курс «Python для веб-разработки» (9 месяцев)











nikbond
Что-то такое ощущение, что Пайтон как язык уже давно законсервировался и особо не развивается, по сравнению с остальными.
alec_kalinin
Сейчас Python очень активно развивается, большей частью в сторону решения своих главных проблем с производительностью и GIL. Например, уже сейчас стало очень просто расставить типизацию в ключевых местах и получить компилированый код, свободный от GIL:
С учетом активно развивающейся концепции аннотации типов и усовершенствованием парсера синтаксиса, мы скором получим динамический язык, который путем расстановки типов в ключевых местах (и их автоматического вывода) можно ускорить практически до скорости языка C.
fougasse
А можно подробнее, как частичная типизация помогает убрать лок в интерпретаторе?
alec_kalinin
Допустим у нас в python интерпретаторе есть python функция, для которой мы знаем
Тогда для такой функции мы можем выйти из python интепретатора, освободить GIL, скомпилировать код в нэйтив для данной платформы, выполнить его и вернуться обратно в интепретатор. Самый удобный пакет сейчас для такого это numba, которая основана на LLVM.
Самое главное, что вся эта внутренняя работа абослютно незаметна для программиста. Все что нужно, это просто расставить типы. Уже как несколько лет такой подход идеально работает для математических вычислений в python, основанных на numpy array. Сам numpy array представляет собой python обертку над линейными областями памяти, поэтому для таких данных код генерируется очень хороший.
Для примера, рассмотрим следующую задачу.
Постановка задачи
Даны два набора из N точек в трехмерном пространстве. Необходимо посчитать матрицу попарных регуляризированных обратных расстояний. В нашем пример N = 5000.
Чистый код на Python
Время работы: 100.479 c.
Это очень долго. Теперь начинается магия!
Последовательная реализация с аннотацией типов
Время работы: 0.154 с, ускорее примерно в 700 раз. И все, что мы для этого сделали, по большому счету, только проставили типы.
Параллельная реализация с аннотацией типов
Ну ладно, а как на счет параллельности и GIL? Почти без изменений:
Мы добавили а) parallel=True в аннотацию и б) во внешнем цикле range заменили на prange.
Время работы: 0.47 с, ускорение по сравнения с последовательной версией примерно в 3.3 раза, что неплохо для моего четырехядерного лаптопа.
И что дальше?
Уже как несколько лет это работает идеально для математики и numpy array. Но разработчики numba пошли гораздо дальше. Очень важный момент, что такой же аннотацией типов код можно скомплировать и для GPU. Кроме того, стали поддерживаться почти все python типы, включая типизированные List, Dict, а также спецификации для классов, что я показывал выше. А в планах тесная интеграция с python type annotations.
Сейчас репозиторий на GitHub очень активный, около 170 контрибьюторов. И мне нравится, как развивается этот проект.
fougasse
Так, вроде, трюки с компилированием в нэйтив для числодрлбилок еще во 2м питоне были. Да, интересно, что всё больше сахара появляется, но сам интерпретатор как лочился, так и лочится. Конечно, приятно, что меньше возни руками для перехода в скомпилированый код.
Ну и в примере вы не просто и не столько типы проставили, а получили возможность в native скомпилировать, подключив numba, что, в принципе, типов могло и не требовать.
Естественно, что jit выиграет у интерпретатора на вычислительной задаче — это уже лет 15 не новость. С гораздо меньшим удобством замену range на prange и руками можно было бы сделать, тут, бесспорно, авторы молодцы.
Но, опять же, из самого питона GIL никуда не делся, вы просто «незаметно» вышли из него, но если вам понадобится что-то в интерпретируемом коде — вы снова залочитесь в одном потоке.
alec_kalinin
С одной стороны вы правы. Под капотом все тоже компилирование в нейтив. Но, с точки зрения программиста, ситуация меняется. Если раньше нужно было писать брутальный C модуль или использовать cython с его несколько извращенным синтаксисом, то теперь с numba достаточно подключения библиотеки и аннотации типов. И формально программист не выходит за пределы логики python.
И я вижу, как это дальше развивается. Numba тесно интегрируется с аннотацией типов python и поддерживает все больше и больше чистых python структур, а не только numpy array. Все те функции python, для которых возможно полное выведение типов, будут скомпилированы в native и свободны от GIL, при этом будут бесшовно сшиваться с python интерпретаторами.
Это похоже на концепцию языка julia, где авторы создали динамический язык, способный к автоматическому выведению типов. Правда в julia они начали с того, что обрезали все те возможности языка, для которых такое выведение типов невозможно.
Python идет примерно по той же дороге, выделяя то подмножество языка, для которого это возможно, и шаг за шагом расширяет это подмножество.
ser-mk
Получается вроде бы наооборот замедление в 3 раза. или там 0,047?
alec_kalinin
Да, там 0.047. Спасибо за правку!
Gorthauer87
А почему эти аннотации не могут тайпхинты юзать? Выглядят они жутко, если честно.
alec_kalinin
Пока не могут, так как эти аннотации пришли в python из необходимости существенно ускорить математические вычисления, основанные на numpy array. Не все типы python пока еще поддерживаются. Да и тайпхинты пока все еще в процессе развития.
Но в ближайших планах как раз и перейти на тайпхинты с поддержкой все большего количество чистых пайтоновских структур данных.
chersanya
Я за последними разработками в нумбе не следил давно, поэтому такой вопрос: уже можно, или планируется ли, чтобы такого рода код (ниже) тоже мог быстро работать? Пусть даже с аннотациями, но чтобы по возможности не сильно потерять в выразительности. И уж точно чтобы не хранить все данные как простые массивы чисел.
Бонусом: чтобы при этом можно было (почти) не меняя кода принимать не array-of-structs, а struct-of-arrays для производительности.
alec_kalinin
Я бы попробовал это реализовать двумя путями.
Если оставаться чисто в парадигме вложенных классов, я бы это сделал через @jitclass, как в jitclass.py и в binarytree.py.
Другой вариант вместо python классов использовать Numpy Strutured Array и их поддержку в Numba, structures.py.
Lsh
Т.е. аннотации в numba пока и нет? Поэтому вместо «self.data: int32» приходится писать перед классом дополнительные «подсказки»?