
Предлагаем вам перевод поста «Unit Testing is Overrated» от Alex Golub, чтобы подискутировать на тему юнит-тестов. Действительно ли они переоценены, как считает автор, или же являются отличным подспорьем в работе? Опрос — в конце поста
Результаты использования юнит-тестов: отчаяние, мучения, гнев
Важность тестирования в современной разработке ПО сложно переоценить. Для создания успешного продукта недостаточно выпустить его и сразу забыть, это долгий итеративный процесс. После изменения каждой строки кода программа должна сохранять свою функциональность, что подразумевает необходимость тщательного тестирования.
В процессе развития отрасли разработки ПО совершенствовались и методики тестирования. Они постепенно сдвигались в сторону автоматизации и повлияли на саму структуру ПО, порождая такие «мантры», как «разработка через тестирование» (test-driven development), делая упор на такие паттерны, как инверсия зависимостей (dependency inversion), и популяризируя построенные на их основе высокоуровневые архитектуры.
Сегодня автоматизированное тестирование настолько глубоко связано в нашем сознании с разработкой ПО, что одно сложно представить без другого. И поскольку оно, в конечном итоге, позволяет нам быстро создавать ПО, не жертвуя при этом его качеством, то трудно спорить о полезности тестирования.
Однако, несмотря на существование различных подходов, современные «best practices» в основном подталкивают разработчиков к использованию конкретно юнит-тестирования. Тесты, область контроля которых находится в пирамиде Майка Кона выше, или пишутся как часть более масштабного проекта (часто совершенно другими людьми), или полностью игнорируются.
Преимущество такого подхода часть поддерживается следующим аргументом: юнит-тесты обеспечивают в процессе разработки наибольшую полезность, потому что способны быстро отслеживать ошибки и помогают применять упрощающие модульность паттерны разработки. Эта мысль стала настолько общепринятой, что сегодня термин «юнит-тестирование» в какой-то мере сливается с автоматизированным тестированием в целом, из-за оно чего теряет часть своего значения и вводит в замешательство.
Когда я был менее опытным разработчиком, я неукоснительно следовал этим «best practices», полагая, что они могут сделать мой код лучше. Мне не особо нравилось писать юнит-тесты из-за всех связанных с этим церемоний с абстракциями и созданием заглушек, но таким был рекомендованным подход, а кто я такой, чтобы с ним спорить?
И только позже, поэкспериментировав и создав новые проекты, я начал осознавать, что существуют гораздо более хорошие подходы к тестированию, и что в большинстве случаев упор на юнит-тесты является пустой тратой времени.
Агрессивно продвигаемые «best practices» часто имеют тенденцию к созданию вокруг себя карго-культов, соблазняющих разработчиков применять паттерны разработки или использовать определённые подходы, не позволяя им задуматься. В контексте автоматизированного тестирования такая ситуация возникла с нездоровой одержимостью отрасли юнит-тестированием.
В этой статье я поделюсь своими наблюдениями о данном способе тестирования и расскажу о том, почему считаю его неэффективным. Также я скажу о том, какие подходы использую для тестирования своего кода, как в open-source-проектах, так и в повседневной работе.
Примечание: код примеров этой статьи написан на C#, но при объяснении моей позиции сам язык не (особо) важен.
Примечание 2: я пришёл к выводу, что терминология программирования совершенно не передаёт свой смысл, потому что каждый, похоже, понимает её по-своему. В этой статье я буду использовать «стандартные» определения: юнит-тестирование направлено на проверку наименьших отдельных частей кода, сквозное тестирование (end-to-end testing) проверяет самые отдалённые друг от друга входные точки ПО, а интеграционное тестирование (integration testing) используется для всего промежуточного между ними.
Примечание 3: если вам не хочется читать статью целиком, то можете сразу перейти к выводам в конце.
Юнит-тесты, как понятно из их названия, связаны с понятием «юнита», обозначающим очень маленькую изолированную часть системы. Не существует формального определения того, что такое юнит, и насколько он должен быть мал, но чаще всего принимается, что он соответствует отдельной функции модуля (или методу объекта).
Обычно, если код пишется без учёта юнит-тестирования, тестирование некоторых функций в полной изоляции может оказаться невозможным, потому что они могут иметь внешние зависимости. Чтобы обойти эту проблему, мы можем применить принцип инверсии зависимостей и заменить конкретные зависимости абстракциями. Затем эти абстракции можно заменить на реальные или фальшивые реализации; это зависит от того, выполняется ли код обычным образом, или как часть теста.
Кроме того, ожидается, что юнит-тесты должны быть чистыми. Например, если функция содержит код, записывающий данные в файловую систему, то эту часть тоже нужно абстрагировать — в противном случае, тест, проверяющий такое поведение, будет считаться интеграционным тестом, потому что он покрывает ещё и интеграцию юнита с файловой системой.
Учитывая вышеупомянутые факторы, мы можем прийти к выводу, что юнит-тесты полезны только для проверки чистой бизнес-логики внутри конкретной функции. Их область применения не охватывает тестирование побочных эффектов или других интеграций, потому что это сфера уже интегрального тестирования.
Чтобы продемонстрировать, как эти нюансы влияют на проектирование, давайте возьмём пример простой системы, которую мы хотим протестировать. Представьте, что мы работаем над приложением, вычисляющим время восхода и заката; свою задачу оно выполняет при помощи следующих двух классов:
Хотя представленная выше структура совершенно верна с точки зрения ООП, ни для одного из этих классов невозможно провести юнит-тестирование. Поскольку
Давайте выполним итерацию кода и заменим конкретные реализации абстракциями:
Благодаря этому мы сможем отделить
Хотя некоторым подобные изменения могут показаться усовершенствованиями, важно указать на то, что определённые нами интерфейсы не имеют практической пользы, за исключением возможности проведения юнит-тестирования. В нашей структуре нет необходимости в полиморфизме, то есть в нашем конкретном случае такие абстракции являются самоцельными (т.е. абстракциями ради абстракций).
Давайте попробуем воспользоваться преимуществами проделанной работы и написать юнит-тест для
Мы получили простой тест, проверяющий, что
Чтобы симулировать нужное предусловие на этапе Arrange, нам нужно внедрить в зависимость юнита
Обратите внимание, что хотя
В конечном итоге, тест правильно проверяет, что бизнес-логика внутри
1. Юнит-тесты имеют ограниченную применимость
Важно понимать, что задача любого юнит-теста очень проста: проверять бизнес-логику в изолированной области действия. Применимость юнит-тестирования зависит от взаимодействий, которые нам нужно протестировать.
Например, логично ли подвергать юнит-тесту метод, вычисляющий время восхода и заката при помощи долгого и сложного математического алгоритма? Скорее всего да.
Имеет ли смысл выполнять юнит-тест метода, отправляющего запрос к REST API для получения географических координат? Скорее всего нет.
Если рассматривать юнит-тестирование как самоцель, то вы вскоре обнаружите, что несмотря на множество усилий, большинство тестов неспособно обеспечить нужный вам уровень уверенности просто потому, что они тестируют не то, что необходимо. В большинстве случаев гораздо выгоднее тестировать более обширные взаимодействия при помощи интегрального тестирования, чем фокусироваться конкретно на юнит-тестах.
Любопытно, что некоторые разработчики в подобных ситуациях в конечном итоге всё-таки пишут интегральные тесты, но по-прежнему называют их юнит-тестами. В основном это вызвано путаницей, которая окружает это понятие. Конечно, можно заявить, что размер юнита можно выбирать произвольно и что он может охватывать несколько компонентов, но из-за этого определение становится очень нечётким, а потому использование термина оказывается совершенно бесполезным.
2. Юнит-тесты приводят к усложнению структуры
Один из наиболее популярных аргументов в пользу юнит-тестирования заключается в том, что оно стимулирует вас проектировать ПО очень модульным образом. Аргумент основан на предположении, что проще воспринимать код, когда он разбит на множество мелких компонентов, а не на малое количество крупных.
Однако часто это приводит к противоположной проблеме — функциональность может оказаться чрезмерно фрагментированной. Из-за этого оценивать код становится намного сложнее, потому что разработчику приходится просматривать несколько компонентов того, что должно быть единым связанным элементом.
Кроме того, избыточное использование абстракций, необходимое для обеспечения изоляции компонентов, создаёт множество необязательных косвенных взаимодействий. Хоть сама по себе эта техника является невероятно мощной и полезной, абстракции неизбежно повышают когнитивную сложность, ещё сильнее затрудняя восприятие кода.
Из-за таких косвенных взаимодействий мы в конечном итоге теряем определённую степень инкапсуляции, которую могли бы сохранить. Например, ответственность за управление сроком жизни отдельных зависимостей переходит от содержащих их компонентов к какому-то другому не связанному с ними сервису (обычно к контейнеру зависимостей).
Часть инфраструктурной сложности тоже можно делегировать фреймворку внедрения зависимостей, что упрощает конфигурирование зависимостей, управление ими и активацию. Однако это снижает компактность, что в некоторых случаях, например, при написании библиотеки, нежелательно.
В конечном итоге, хоть и очевидно, что юнит-тестирование влияет на проектирование ПО, его полезность весьма спорна.
3. Юнит-тесты затратны
Можно логично предположить, что из-за своего малого размера и изолированности юнит-тесты очень легко и быстро писать. К сожалению, это ещё одно заблуждение; похоже, оно довольно популярно, особенно среди руководства.
Хоть упомянутая выше модульная архитектура заставляет нас думать, что индивидуальные компоненты можно рассматривать отдельно друг от друга, на самом деле юнит-тесты от этого не выигрывают. В действительности, сложность юнит-теста только растёт пропорционально количеству его внешних взаимодействий; это вызвано всей той работой, которую необходимо проделать для достижения изолированности при сохранении требуемого поведения.
Показанный выше пример довольно прост, однако в реальном проекте этап Arrange довольно часто может растягиваться на множество длинных строк, в которых просто задаются предусловия одного теста. В некоторых случаях имитируемое поведение может быть настолько сложным, что почти невозможно распутать его, чтобы разобраться, что оно должно было делать.
Кроме того, юнит-тесты по самой своей природе очень тесно связаны с тестируемым кодом, то есть все трудозатраты для внесения изменений по сути удваиваются, чтобы тест соответствовал обновлённому коду. Ухудшает ситуацию и то, что очень немногим разработчикам эта задача кажется увлекательной, поэтому они просто сбрасывают её на менее опытных членов команды.
4. Юнит-тесты зависят от подробностей реализации
Печальным следствием юнит-тестирования на основе заглушек (mocks) заключается в том, что любой тест, написанный по этой технике, обязательно учитывает реализацию. Имитируя конкретную зависимость, тест начинает полагаться на то, как тестируемый код потребляет эту зависимость, что не регулируется публичным интерфейсом.
Эта дополнительная связь часто приводит к неожиданным проблемам, при которых изменения, которые, казалось бы, ничего не могут сломать, начинают давать сбой при устаревании заглушек. Это может очень напрягать и в конечном итоге отталкивает разработчиков от рефакторинга кода, потому что никогда непонятно, возникла ли ошибка в тесте из-за действительной регрессии или из-за того, что он зависит от подробностей реализации.
Ещё более сложным может быть юнит-тестирование кода с хранением состояния, потому что наблюдение за мутациями через публичный интерфейс может оказаться невозможным. Чтобы обойти эту проблему, обычно можно внедрять шпионов, то есть своего рода имитируемое поведение, регистрирующее вызов функций и помогающее убедиться, что юнит использует свои зависимости правильно.
Разумеется, когда мы зависим не только от вызова конкретной функции, но и от количества вызовов и переданных аргументов, то тест становится ещё более тесно связанным с реализацией. Написанные таким образом тесты полезны только для внутренней специфики и обычно даже ожидается, что они не будут изменяться (крайне неразумное ожидание).
Слишком сильная зависимость от подробностей реализации также очень усложняет сами тесты, учитывая объём подготовки, необходимый для имитации определённого поведения; особенно справедливо это, когда взаимодействия нетривиальны или присутствует множество зависимостей. Когда тесты становятся настолько сложными, что трудно понимать само их поведение, то кто будет писать тесты для тестирования тестов?
5. Юнит-тесты не используют действия пользователей
Какое бы ПО вы не разрабатывали, его задача — обеспечение ценности для конечного пользователя. На самом деле, основная причина написания автоматизированных тестов — обеспечение гарантии отсутствия непреднамеренных дефектов, способных снизить эту ценность.
В большинстве случаев пользователь работает с ПО через какой-нибудь высокоуровневый интерфейс типа UI, CLI или API. Хотя в самом коде могут применяться множественные слои абстракции, для пользователя важен только тот уровень, который он видит и с которым взаимодействует.
Ему даже не важно, если ли в какой-то части системы баг несколькими слоями ниже, если пользователь с ним не сталкивается и он не вредит функциональности. И наоборот: пусть даже у нас есть полное покрытие всех низкоуровневых частей, но если есть изъян в интерфейсе пользователя, то это делает систему по сути бесполезной.
Разумеется, если вы хотите гарантировать правильность работы какого-то элемента, то нужно проверить именно его и посмотреть, действительно ли он работает правильно. В нашем случае, лучшим способом обеспечения уверенности в системе является симуляция взаимодействия реального пользователя с высокоуровневым интерфейсом и проверка того, что он работает в соответствии с ожиданиями.
Проблема юнит-тестов заключается в том, что они являются полной противоположностью такого подхода. Так как мы всегда имеем дело с небольшими изолированными частями кода, с которыми пользователь никогда напрямую не взаимодействует, мы никогда не тестируем истинное поведение пользователя.
Тестирование на основе заглушек ставит ценность таких тестов под ещё большее сомнение, потому что части системы, которые бы использовались, заменяются на имитации, ещё сильнее отдаляя симулируемое окружение от реальности. Невозможно обеспечить уверенность удобства работы пользователя, тестируя нечто непохожее на эту работу.

Юнит-тестирование — отличный способ проверки работы заглушек
Так почему же мы как отрасль решили, что юнит-тестирование должно быть основным способом тестирования ПО, несмотря на все его изъяны? В основном это вызвано тем, что тестирование на высоких уровнях всегда считалось слишком трудным, медленным и ненадёжным.
Если обратиться к традиционной пирамиде тестирования, то она предполагает, что наиболее значимая часть тестирования должна выполняться на уровне юнитов. Смысл в том, что поскольку крупные тесты считаются более медленными и сложными, для получения эффективного и поддерживаемого набора тестов нужно сосредоточить усилия на нижней части спектра интеграции:
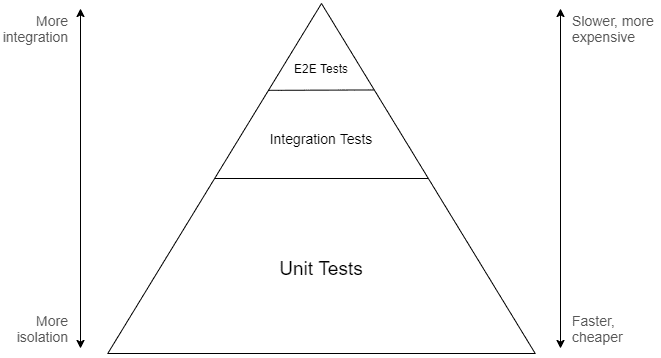
Сверху — сквозное тестирование, в центре — интегральное тестирование, внизу — юнит-тестирование
Метафорическая модель, предлагаемая пирамидой, должна передать нам мысль о том, что для качественного тестирования должны использоваться множество различных слоёв, ведь если сконцентрироваться на крайностях, то это может привести к проблемам: тесты будут или слишком медленными и неповоротливыми, или бесполезными и не обеспечивающими никакой уверенности. Тем не менее, упор делается на нижние уровни, потому что считается, что там возврат инвестиций в разработку тестов наиболее высок.
Высокоуровневые тесты, хоть и обеспечивают наибольшую уверенность, часто оказываются медленными, сложными в поддержке или слишком широкими для включения в обычно быстрый процесс разработки. Именно поэтому в большинстве случаев такие тесты поддерживаются специалистами QA, ведь обычно считается, что писать их должны не разработчики.
Интегральное тестирование, которое на абстрактной части спектра лежит где-то между юнит-тестированием и полным сквозным тестированием, часто совершенно игнорируется. Непонятно, какой конкретно уровень интеграции предпочтим, как структурировать и организовывать такие тесты. Кроме того, существуют опасения, что они выйдут из под контроля. Поэтому многие разработчики отказываются от них в пользу более чётко очерченной крайности, которой и является юнит-тестирование.
Из-за этих причин всё тестирование в процессе разработки обычно остаётся на самом дне пирамиды. На самом деле, это стало настолько стандартным, что тестирование разработки и юнит-тестирование сегодня стали практически синонимами, что приводит к путанице, усиливаемой докладами на конференциях, постами в блогах, книгами и даже некоторыми IDE (по мнению JetBrains Rider, все тесты являются юнит-тестами).
По мнению большинства разработчиков, пирамида тестирования выглядит примерно так:

Сверху — не моя проблема, внизу — юнит-тестирование
Хотя эта пирамида стала достойной уважения попыткой превратить тестирование ПО в решённую задачу, в этой модели очевидно есть множество проблем. В частности, используемые в ней допущения справедливы не во всех контекстах, особенно допущение о том, что высокоинтегральные наборы тестов являются медленными или трудными.
Мы как люди естественно склонны полагаться на информацию, переданную нам более опытными людьми, благодаря чему можем использовать знания предыдущих поколений и применять вторую систему мышления к чему-то более полезному. Это важная эволюционная черта, чрезвычайно повысившая нашу выживаемость как вида.
Однако когда мы экстраполируем свой опыт в инструкции, то обычно воспринимаем их как хорошие сами по себе, забывая об условиях, неотъемлемо связанных с их актуальностью. На самом деле эти условия меняются, и когда-то совершенно логичные выводы (или best practices) могут оказаться не столь хорошо применимыми.
Если взглянуть на прошлое, то очевидно, что в 2000-х высокоуровневое тестирование было сложным, вероятно, оно оставалось таким даже в 2009 году, но на дворе 2020 год и мы уже живём в будущем. Благодаря прогрессу технологий и проектирования ПО эти проблемы стали гораздо менее важными, чем ранее.
Сегодня большинство современных фреймворков предоставляет какой-нибудь отдельный слой API, используемый для тестирования: в нём можно запускать приложение в симулируемой среде внутри памяти, которое очень близко к реальной. Такие инструменты виртуализации, как Docker, также позволили нам проводить тесты, полагающиеся на действительные инфраструктурные зависимости, сохраняя при этом свою детерминированность и скорость.
У нас есть такие решения, как Mountebank, WireMock, GreenMail, Appium, Selenium, Cypress и бесконечное множество других, они упрощают различные аспекты высокоуровневого тестирования, которые когда-то считались недостижимыми. Если вы не разрабатываете десктопные приложения для Windows и не вынуждены использовать фреймворк UIAutomation, то у вас, скорее всего, есть множество возможных вариантов выбора.
В одном из моих предыдущих проектов у нас был веб-сервис, тестировавшийся на границе системы при помощи почти сотни поведенческих тестов, на параллельное выполнение которых тратилось менее 10 секунд. Разумеется, при использовании юнит-тестов можно добиться гораздо более быстрого выполнения, но учитывая обеспечиваемую уверенность, мы даже не рассматривали такую возможность.
Однако заблуждение о медленности тестов — не единственное ошибочное допущение, на котором основана пирамида. Принцип применения большинства тестов на уровне юнитов работает только тогда, когда эти тесты действительно обеспечивают ценность, что, разумеется, зависит от того, какой объём бизнес-логики находится в тестируемом коде.
В некоторых приложениях бизнес-логики может быть много (например, в системах подсчёта зарплаты), в некоторых она почти отсутствует (например, в CRUD-приложениях), а большинство ПО находится где-то посередине. Большинство проектов, над которыми работал лично я, не содержали такого объёма, чтобы была необходимость в обширном покрытии юнит-тестами; с другой стороны, в них было много инфраструктурной сложности, для которой было бы полезно интегральное тестирование.
Разумеется, в идеальном мире разработчик смог бы оценить контекст проекта и создать способ тестирования, наиболее подходящий для решения насущных задач. Однако в реальности большинство разработчиков даже не задумывается об этом, слепо наворачивая горы юнит-тестов в соответствии с рекомендациями best practices.
Наконец, по-моему, было бы справедливо сказать, что создаваемая пирамидой тестирования модель слишком проста в целом. Вертикальная ось представляет спектр тестирования как линейную шкалу, при которой любое повышение уверенности компенсируется эквивалентной величиной потери поддерживаемости и скорости. Это может быть истинным, если вы сравниваете крайние случаи, но не всегда правда для точек в промежутке между ними.
Пирамида также не учитывает того, что изоляция сама по себе имеет цену, она не возникает бесплатно просто благодаря «избеганию» внешних взаимодействий. Учитывая то, сколько труда требуется для написания и поддержки заглушек, вполне возможно, что менее изолированный тест может быть дешевле и в конечном итоге обеспечит бОльшую уверенность, хоть и при чуть более низкой скорости выполнения.
Если принять во внимание эти аспекты, то кажется вероятным, что шкала окажется нелинейной, и что точка максимального возврата инвестиций находится где-то ближе к середине, а не к уровню юнитов:

В конечном итоге, если вы пытаетесь определить эффективный набор тестов для своего проекта, пирамида тестирования — не лучший образец, которому можно следовать. Гораздо логичнее сосредоточиться на том, что относится конкретно к вашему контексту, а не полагаться на «best practices».
На самом базовом уровне тест обеспечивает ценность, если он гарантирует нам, что ПО работает правильно. Чем больше мы уверены, тем меньше нам нужно полагаться на себя в поиске потенциальных багов и регрессий при внесении изменений в код, потому что мы поручаем заниматься этим тестам.
Это доверие, в свою очередь, зависит от точности воспроизведения тестом настоящего поведения пользователя. Тестовый сценарий, работающий на границе системы без знаний её внутренней специфики должен обеспечивать нам бОльшую уверенность (а значит, и ценность), чем тест, работающий на нижнем уровне.
По сути, степень получаемой от тестов уверенности — это основная метрика, которой должна измеряться их ценность. А основная цель — это её максимальное увеличение.
Разумеется, как мы знаем, в деле задействованы и другие факторы: цена, скорость, возможность параллелизации и прочие, и все они тоже важны. Пирамида тестирования создаёт сильные допущения о том, как взаимосвязаны масштабирование этих элементов, но эти допущения не универсальны.
Более того, эти факторы являются вторичными относительно основной цели — достижения уверенности. Дорогой и долго выполняемый тест, обеспечивающий большую уверенность, бесконечно более полезен, чем чрезвычайно быстрый и простой тест, который не делает ничего.
Поэтому я считаю, что лучше писать тесты с максимально возможной степенью интеграции, поддерживая при этом их разумную скорость и сложность.
Значит ли это, что каждый создаваемый нами тест должен быть сквозным? Нет, но мы должны стремиться как можно дальше продвинуться в этом направлении, обеспечивая при этом допустимый уровень недостатков.
Приемлемость субъективна и зависит от контекста. В конечном итоге, важно то, что эти тесты пишутся разработчиками и используются в процессе разработки, то есть они не должны создавать обузу при поддержке и обеспечивать возможность запуска в локальных сборках и на конфигурационной единице.
В таком случае у нас скорее всего получатся тесты, разбросанные по нескольким уровням шкалы интеграции при кажущемся отсутствии ощущения структуры. Такой проблемы не возникает при юнит-тестировании, потому что в нём каждый тест связан с конкретным методом или функцией, поэтому структура обычно отзеркаливает сам код.
К счастью, это не важно, потому что упорядочивание тестов по отдельным классам или модулям не имеет значения само по себе; скорее, это побочный эффект юнит-тестирования. Вместо этого тесты должны разделятся по истинной пользовательской функциональности, которую они проверяют.
Такие тесты часто называют функциональными (functional), потому что они основаны на требованиях к функциональности ПО, описывающих его возможности и способ их работы. Функциональное тестирование — это не ещё один слой пирамиды, а совершенно перпендикулярная ей концепция.
Вопреки распространённому мнению, для написания функциональных тестов не требуется использовать Gherkin или фреймворк BDD, их можно реализовать при помощи тех же инструментов, которые применяются для юнит-тестирования. Например, давайте подумаем, как мы можем переписать пример из начала статьи так, чтобы тесты были структурированы на основе поддерживаемого поведения пользователей, а не юнитов кода:
Обратите внимание, что сама реализация тестов скрыта, потому что она не связана с тем, что они функциональны. Важно здесь то, что тесты и их структура задаются требованиями к ПО, а их масштаб теоретически может изменяться от сквозного тестирования и даже до уровня юнитов.
Называя тесты в соответствии со спецификациями, а не с классами, мы получаем дополнительное преимущество — устраняем эту необязательную связь. Теперь, если мы решим переименовать
Если придерживаться такой структуры, то наш набор тестов по сути принимает вид живой документации. Вот, например, как организован набор тестов в CliWrap (xUnit заменил нижние подчёркивания на пробелы):

Пока элемент ПО выполняет нечто хотя бы отдалённо полезное, то он всегда имеет функциональные требования. Они могут быть или формальными (документы спецификации, пользовательские истории, и т.д.) или неформальными (в устной форме, допускаемые, тикеты JIRA, записанные на туалетной бумаге, и т.д.)
Преобразование неформальных спецификаций в функциональные тесты часто может быть сложным процессом, потому что для этого требуется отступить от кода и заставить себя взглянуть на ПО с точки зрения пользователя. В моих open-source-проектах мне помогает составление файла readme, в котором я перечисляю список примеров использования, а затем кодирую их в тесты.
Подведём итог: можно заключить, что лучше разделять тесты по цепочкам поведений, а не по внутренней структуре кода.
Если объединить оба вышеупомянутых подхода, то образуется структура мышления, дающая нам чёткую цель написания тестов, а также понимание организации; при этом нам не нужно полагаться ни на какие допущения. Мы можем использовать эту структуру для создания набора тестов для проекта, сосредоточенный на ценности, а затем масштабировать его в соответствии с важными в текущем контексте приоритетами и ограничениями.
Принцип заключается в том, чтобы вместо упора на определённую область или набор областей, мы создаём набор тестов на основании пользовательской функциональности, стремясь как можно точнее покрыть эту функциональность.
Вероятно, вы не понимаете, из чего же состоит функциональное тестирование и как конкретно оно должно выглядеть, особенно если не занимались им раньше. Поэтому разумно будет привести простой, но законченный пример. Для этого мы превратим наш калькулятор восходов и закатов в веб-сервис и покроем его тестам в соответствии с правилами, изложенными в предыдущей части статьи. Это приложение будет основано на ASP.NET Core — веб-фреймворке, с которым я знаком больше всего, но такой же принцип должен быть применим к любой другой платформе.
Наш веб-сервис раскрывает свои конечные точки для вычисления времени восхода и заката на основании IP пользователя или указанного местоположения. Чтобы всё было чуть интереснее, для ускорения ответов мы добавим слой кэширования Redis, хранящий предыдущие вычисления.
Тесты будут выполняться запуском приложения в симулируемой среде, в которой оно может получать HTTP-запросы, обрабатывать маршрутизацию, выполнять валидацию и демонстрировать поведение. практически идентичное приложению, запущенному в продакшене. Также мы используем Docker, чтобы наши тесты использовали те же инфраструктурные зависимости, что и реальное приложение.
Чтобы разобраться, с чем мы имеем дело, давайте сначала рассмотрим реализацию веб-приложения. Обратите внимание, что некоторые части фрагментов кода ради краткости пропущены, а полный проект можно посмотреть на GitHub.
Для начала нам нужно найти способ определения местоположения пользователя по IP, выполняемое при помощи класса
Для преобразования местоположения во время восхода и заката мы воспользуемся алгоритмом вычисления восхода и заката, опубликованным Военно-морской обсерваторией США. Сам алгоритм слишком длинный, поэтому мы не будем его приводить здесь, а остальная часть реализации
Так как это веб-приложение MVC, нам также потребуется контроллер, предоставляющий конечные точки для раскрытия функциональности приложения:
Как показано выше, конечная точка
Все описанные выше части соединяются вместе в классе
Обратите внимание, что нам не пришлось реализовывать в классах каких-то самоцельных интерфейсов просто потому, что мы не планируем использовать заглушки. Возможно, нам понадобится заменить один из сервисов в тестах, но пока это непонятно, поэтому мы избежим ненужной работы (и ущерба структуре кода), пока точно не будем уверены, что это нужно.
Хоть проект и довольно прост, это приложение уже содержит в себе достаточное количество инфраструктурной сложности: оно полагается на сторонний веб-сервис (провайдера GeoIP), а также на слой хранения данных (Redis). Это вполне стандартная схема, используемая во многих реальных проектах.
В классическом подходе, сосредоточенном на юнит-тестировании, мы бы нацелились на слой сервисов и, возможно, на слой контроллера приложения, и писали бы изолированные тесты, гарантирующие правильное выполнение каждой ветви кода. Такой подход будет в какой-то мере полезен, но он никогда не обеспечит нам уверенности в том, что истинные конечные точки со всеми middleware и периферийными компонентами работают как положено.
Так что вместо этого мы напишем тесты, нацеленные непосредственно на конечные точки. Для этого нам понадобится создать отдельный тестовый проект и добавить несколько инфраструктурных компонентов, поддерживающих наши тесты. Один из них — это
Основная часть работы здесь уже выполнена
Мы можем использовать экземпляр этого объекта в тестах для запуска приложения и отправки запросов с предоставленным
Поскольку мы также используем Redis, нам нужен способ запуска нового сервера, который будет использоваться приложением. Существует множество способов реализации этого, но для простого примера я решил использовать в этих целях API оборудования (fixture) фреймворка xUnit:
Показанный выше код реализует интерфейс
Кроме того, класс
Настроив инфраструктуру, можно переходить к написанию первого теста:
Как видите, схема очень проста. Нам достаточно лишь создать экземпляр
Конкретно этот тест запрашивает маршрут
Хоть эти утверждения и способны отследить множество потенциальных багов, они не дают нам полной уверенности в совершенной правильности результата. Однако существует пара способов, которыми мы можем улучшить ситуацию.
Очевидный способ — можно заменить настоящего провайдера GeoIP фальшивым экземпляром, всегда возвращающим одинаковое местоположение, что позволит нам жёстко прописать в коде ожидаемое время восхода и заката. Недостаток такого подхода в том, что мы по сути уменьшаем масштаб интеграции, то есть мы не сможем убедиться, что приложение правильно общается со сторонним сервисом.
В качестве альтернативного подхода мы можем заменить IP-адрес, который тестовый сервер получает от клиента. Благодаря этому мы сделаем тест более строгим, сохраняя при этом тот же масштаб интеграции.
Для этого нам понадобится создать фильтр запуска, позволяющий нам при помощи middleware инъектировать выбранный IP-адрес в контекст запроса:
Затем мы можем соединить его с
Теперь мы можем дополнить тест, чтобы он использовал конкретные данные:
Некоторых разработчиков по-прежнему может тревожить использование в тестах стороннего веб-сервиса, потому что это может привести к недетерминированным результатам. В то же время, можно возразить, что нам действительно нужно встроить в наши тесты эту зависимость, потому что мы хотим знать, будет ли он ломаться или изменяться неожиданным образом, потому что это способно приводить к багам в нашем собственном ПО.
Разумеется, не всегда мы можем использовать реальные зависимости, например, если у сервиса есть ограничения на использование, он стоит денег, или просто медленный или ненадёжный. В таких случаях нам придётся заменить его на фальшивую (предпочтительно не на заглушку) реализацию для использования в тестах. Однако в нашем случае всё не так.
Аналогично тому, как мы сделали с первым тестом, можно написать тест, покрывающий вторую конечную точку. Этот тест проще, потому что все входящие параметры передаются напрямую как часть запроса URL:
Мы можем продолжать добавлять подобные тесты, чтобы убедиться, что приложение поддерживает все возможные местоположения и даты, а также обрабатывает потенциальные пограничные случаи, например, полярный день. Однако возможно, что такой подход будет плохо масштабироваться, потому что нам может и не стоит выполнять каждый раз весь конвейер только для проверки правильности бизнес-логики, вычисляющей время восхода и заката.
Важно также заметить, что хоть мы и пытались этого по возможности избегать, всё равно можно снизить масштаб интеграции, если на то будут реальные причины. В данном случае можно попробовать покрыть дополнительные случаи юнит-тестами.
Обычно это означало бы, что нам каким-то образом нужно изолировать
Мы можем изменить реализацию
Мы изменили код так, что вместо использования
Чтобы снова соединить всё вместе, нам достаточно изменить контроллер:
Так как имеющиеся тесты не знают о подробностях реализации, этот простой рефакторинг их не сломает. Сделав это, мы можем написать дополнительные короткие тесты для более подробного покрытия бизнес-логики без необходимости заглушек:
Хоть эти тесты больше и не используют полную область интеграции, они всё равно исходят из функциональных требований к приложению. Так как у нас уже есть другой высокоуровневый тест, покрывающий конечную точку целиком, мы можем сделать эти тесты более узкими, не жертвуя при этом общим уровнем уверенности.
Такой компромисс разумен, если мы стремимся повысить скорость выполнения, но я бы порекомендовал максимально придерживаться высокоуровневых тестов, по крайней мере, до тех по, пока это не станет проблемой.
Наконец, нам стоит сделать что-нибудь, чтобы гарантировать правильную работу слоя кэширования Redis. Даже несмотря на то, что мы используем его в своих тестах, на деле он никогда не возвращает кэшированный ответ, потому что между тестами база данных сбрасывается к исходному состоянию.
Проблема при тестировании таких аспектов, как кэширование, заключается в том, что их невозможно задать функциональными требованиями. Пользователь, не знающий о внутренней работе приложения, не может узнать, возвращён ли ответ из кэша.
Однако если наша задача заключается только в тестировании интеграции между приложением и Redis, нам не нужно писать тесты, знающие об особенностях реализации, и вместо этого можно сделать нечто подобное:
Тест несколько раз выполняет запрос к одной конечной точке и утверждает, что результат всегда остаётся одинаковым. Этого достаточно для проверки правильности кэширования ответов и возврата их таким же образом, как и обычных ответов.
В конечном итоге мы получили простой набор тестов, который выглядит вот так:

Обратите внимание, что скорость выполнения тестов довольно хороша — самый быстрый интегральный тест завершается за 55 мс, а самый медленный — меньше чем за секунду (из-за холодного запуска). Учитывая то, что эти тесты задействуют весь рабочий цикл, в том числе все зависимости и инфраструктуру, при этом не используя никаких заглушек, я могу сказать, что это более чем приемлемо.
Если вы хотите самостоятельно поэкспериментировать с проектом, то его можно найти на GitHub.
К сожалению, серебряной пули нет, и описанные в этой статье решения тоже страдают от потенциальных недостатков. В интересах справедливости будет разумно их упомянуть.
Одна из самых серьёзных проблем, с которыми я столкнулся при реализации высокоуровневого функционального тестирования — поиск удовлетворительного баланса между полезностью и применимостью. По сравнению с подходами, целиком сосредоточенными на юнит-тестировании, здесь приходится прикладывать больше усилий для проверки достаточной детерминированности таких тестов, их скорости выполнения, возможности выполнения независимо друг от друга и в целом их применимости в процессе разработки.
Широкомасштабность тестов также подразумевает необходимость более глубокого понимания зависимостей проекта и технологий, которые в нём применяются. Важно знать, как они используются, легко ли их контейнировать, наличие возможных вариантов и необходимые компромиссы.
В контексте интегрального тестирования аспект «тестируемости» определяется не тем, насколько хорошо можно изолировать код, а тем, насколько реальная инфраструктура приспособлена к тестированию и облегчает его. Это накладывает определённые требования с точки зрения технической компетенции и на ответственное лицо, и на команду в целом.
Кроме того, на подготовку и конфигурирование тестовой среды может потребоваться некоторое время, потому что для него требуется создание оборудования (fixtures), подключение фальшивых реализаций, добавление специализированного поведения инициализации и очистки, и так далее. Все эти аспекты придётся поддерживать в процессе увеличения масштабов и сложности проекта.
Само по себе написание функциональных тестов требует также чуть больше планирования, потому что теперь речь идёт не о покрытии каждого метода каждого класса, а об определении требований к ПО и превращению их в код. Иногда бывает сложно понять эти требования и то, какие из них являются функциональными, потому что для этого необходимо думать как пользователь.
Ещё одна распространённая проблема заключается в том, что высокоуровневые тесты часто страдают от нехватки локальности. Если тест не проходит из-за неудовлетворённых ожиданий или необработанного исключения, то обычно непонятно, что конкретно вызвало ошибку.
Хотя всегда существуют способы частичного устранения этой проблемы, это всегда становится компромиссом: изолированные тесты лучше указывают на причину ошибки, а интегральные тесты лучше показывают её воздействие. Оба вида равно полезны, поэтому всё сводится к тому, что вы посчитаете более важным.
В конечном итоге, я всё равно считаю, что функциональное тестирование стоит того, несмотря на все его недостатки, потому что, по моему мнению, оно приводит к повышению удобства и качества разработки. Я уже давно не занимался классическим юнит-тестированием и не собираюсь к нему возвращаться.
Юнит-тестирование — популярный подход к тестированию ПО, но в основном по ошибочным причинам. Часто его навязывают как эффективный способ для тестирования разработчиками своего кода, стимулирующий к использованию best practices проектирования, однако многие считают его затруднительным и поверхностным.
Важно понимать, что тестирование в процессе разработки не равно юнит-тестированию. Основная цель — не написание максимально изолированных тестов, а достижение уверенности в том, что код работает в соответствии с функциональными требованиями. И для этого есть способы получше.
Написание высокоуровневых тестов, руководствующихся поведением пользователя, обеспечит вам в дальней перспективе гораздо больший возврат инвестиций; при этом оно не так сложно, как кажется. Найдите подход, наиболее разумный для вашего проекта, и придерживайтесь его.
Вот основные уроки:
Существуют и другие замечательные статьи об альтернативных подходах к тестированию в современной разработке ПО. Вот те из них, которые показались интересными лично мне:
Результаты использования юнит-тестов: отчаяние, мучения, гнев
Важность тестирования в современной разработке ПО сложно переоценить. Для создания успешного продукта недостаточно выпустить его и сразу забыть, это долгий итеративный процесс. После изменения каждой строки кода программа должна сохранять свою функциональность, что подразумевает необходимость тщательного тестирования.
В процессе развития отрасли разработки ПО совершенствовались и методики тестирования. Они постепенно сдвигались в сторону автоматизации и повлияли на саму структуру ПО, порождая такие «мантры», как «разработка через тестирование» (test-driven development), делая упор на такие паттерны, как инверсия зависимостей (dependency inversion), и популяризируя построенные на их основе высокоуровневые архитектуры.
Сегодня автоматизированное тестирование настолько глубоко связано в нашем сознании с разработкой ПО, что одно сложно представить без другого. И поскольку оно, в конечном итоге, позволяет нам быстро создавать ПО, не жертвуя при этом его качеством, то трудно спорить о полезности тестирования.
Однако, несмотря на существование различных подходов, современные «best practices» в основном подталкивают разработчиков к использованию конкретно юнит-тестирования. Тесты, область контроля которых находится в пирамиде Майка Кона выше, или пишутся как часть более масштабного проекта (часто совершенно другими людьми), или полностью игнорируются.
Преимущество такого подхода часть поддерживается следующим аргументом: юнит-тесты обеспечивают в процессе разработки наибольшую полезность, потому что способны быстро отслеживать ошибки и помогают применять упрощающие модульность паттерны разработки. Эта мысль стала настолько общепринятой, что сегодня термин «юнит-тестирование» в какой-то мере сливается с автоматизированным тестированием в целом, из-за оно чего теряет часть своего значения и вводит в замешательство.
Когда я был менее опытным разработчиком, я неукоснительно следовал этим «best practices», полагая, что они могут сделать мой код лучше. Мне не особо нравилось писать юнит-тесты из-за всех связанных с этим церемоний с абстракциями и созданием заглушек, но таким был рекомендованным подход, а кто я такой, чтобы с ним спорить?
И только позже, поэкспериментировав и создав новые проекты, я начал осознавать, что существуют гораздо более хорошие подходы к тестированию, и что в большинстве случаев упор на юнит-тесты является пустой тратой времени.
Агрессивно продвигаемые «best practices» часто имеют тенденцию к созданию вокруг себя карго-культов, соблазняющих разработчиков применять паттерны разработки или использовать определённые подходы, не позволяя им задуматься. В контексте автоматизированного тестирования такая ситуация возникла с нездоровой одержимостью отрасли юнит-тестированием.
В этой статье я поделюсь своими наблюдениями о данном способе тестирования и расскажу о том, почему считаю его неэффективным. Также я скажу о том, какие подходы использую для тестирования своего кода, как в open-source-проектах, так и в повседневной работе.
Примечание: код примеров этой статьи написан на C#, но при объяснении моей позиции сам язык не (особо) важен.
Примечание 2: я пришёл к выводу, что терминология программирования совершенно не передаёт свой смысл, потому что каждый, похоже, понимает её по-своему. В этой статье я буду использовать «стандартные» определения: юнит-тестирование направлено на проверку наименьших отдельных частей кода, сквозное тестирование (end-to-end testing) проверяет самые отдалённые друг от друга входные точки ПО, а интеграционное тестирование (integration testing) используется для всего промежуточного между ними.
Примечание 3: если вам не хочется читать статью целиком, то можете сразу перейти к выводам в конце.
Заблуждения о юнит-тестировании
Юнит-тесты, как понятно из их названия, связаны с понятием «юнита», обозначающим очень маленькую изолированную часть системы. Не существует формального определения того, что такое юнит, и насколько он должен быть мал, но чаще всего принимается, что он соответствует отдельной функции модуля (или методу объекта).
Обычно, если код пишется без учёта юнит-тестирования, тестирование некоторых функций в полной изоляции может оказаться невозможным, потому что они могут иметь внешние зависимости. Чтобы обойти эту проблему, мы можем применить принцип инверсии зависимостей и заменить конкретные зависимости абстракциями. Затем эти абстракции можно заменить на реальные или фальшивые реализации; это зависит от того, выполняется ли код обычным образом, или как часть теста.
Кроме того, ожидается, что юнит-тесты должны быть чистыми. Например, если функция содержит код, записывающий данные в файловую систему, то эту часть тоже нужно абстрагировать — в противном случае, тест, проверяющий такое поведение, будет считаться интеграционным тестом, потому что он покрывает ещё и интеграцию юнита с файловой системой.
Учитывая вышеупомянутые факторы, мы можем прийти к выводу, что юнит-тесты полезны только для проверки чистой бизнес-логики внутри конкретной функции. Их область применения не охватывает тестирование побочных эффектов или других интеграций, потому что это сфера уже интегрального тестирования.
Чтобы продемонстрировать, как эти нюансы влияют на проектирование, давайте возьмём пример простой системы, которую мы хотим протестировать. Представьте, что мы работаем над приложением, вычисляющим время восхода и заката; свою задачу оно выполняет при помощи следующих двух классов:
public class LocationProvider : IDisposable
{
private readonly HttpClient _httpClient = new HttpClient();
// Gets location by query
public async Task<Location> GetLocationAsync(string locationQuery) { /* ... */ }
// Gets current location by IP
public async Task<Location> GetLocationAsync() { /* ... */ }
public void Dispose() => _httpClient.Dispose();
}
public class SolarCalculator : IDiposable
{
private readonly LocationProvider _locationProvider = new LocationProvider();
// Gets solar times for current location and specified date
public async Task<SolarTimes> GetSolarTimesAsync(DateTimeOffset date) { /* ... */ }
public void Dispose() => _locationProvider.Dispose();
}Хотя представленная выше структура совершенно верна с точки зрения ООП, ни для одного из этих классов невозможно провести юнит-тестирование. Поскольку
LocationProvider зависит от своего собственного экземпляра HttpClient, а SolarCalculator, в свою очередь, зависит от LocationProvider, невозможно изолировать бизнес-логику, которая может содержаться внутри методов этих классов.Давайте выполним итерацию кода и заменим конкретные реализации абстракциями:
public interface ILocationProvider
{
Task<Location> GetLocationAsync(string locationQuery);
Task<Location> GetLocationAsync();
}
public class LocationProvider : ILocationProvider
{
private readonly HttpClient _httpClient;
public LocationProvider(HttpClient httpClient) =>
_httpClient = httpClient;
public async Task<Location> GetLocationAsync(string locationQuery) { /* ... */ }
public async Task<Location> GetLocationAsync() { /* ... */ }
}
public interface ISolarCalculator
{
Task<SolarTimes> GetSolarTimesAsync(DateTimeOffset date);
}
public class SolarCalculator : ISolarCalculator
{
private readonly ILocationProvider _locationProvider;
public SolarCalculator(ILocationProvider locationProvider) =>
_locationProvider = locationProvider;
public async Task<SolarTimes> GetSolarTimesAsync(DateTimeOffset date) { /* ... */ }
}Благодаря этому мы сможем отделить
LocationProvider от SolarCalculator, но взамен размер кода увеличился почти в два раза. Обратите также внимание на то, что нам пришлось исключить из обоих классов IDisposable, потому что они больше не владеют своими зависимостями, а следовательно, не отвечают за их жизненный цикл.Хотя некоторым подобные изменения могут показаться усовершенствованиями, важно указать на то, что определённые нами интерфейсы не имеют практической пользы, за исключением возможности проведения юнит-тестирования. В нашей структуре нет необходимости в полиморфизме, то есть в нашем конкретном случае такие абстракции являются самоцельными (т.е. абстракциями ради абстракций).
Давайте попробуем воспользоваться преимуществами проделанной работы и написать юнит-тест для
SolarCalculator.GetSolarTimesAsync:public class SolarCalculatorTests
{
[Fact]
public async Task GetSolarTimesAsync_ForKyiv_ReturnsCorrectSolarTimes()
{
// Arrange
var location = new Location(50.45, 30.52);
var date = new DateTimeOffset(2019, 11, 04, 00, 00, 00, TimeSpan.FromHours(+2));
var expectedSolarTimes = new SolarTimes(
new TimeSpan(06, 55, 00),
new TimeSpan(16, 29, 00)
);
var locationProvider = Mock.Of<ILocationProvider>(lp =>
lp.GetLocationAsync() == Task.FromResult(location)
);
var solarCalculator = new SolarCalculator(locationProvider);
// Act
var solarTimes = await solarCalculator.GetSolarTimesAsync(date);
// Assert
solarTimes.Should().BeEquivalentTo(expectedSolarTimes);
}
}Мы получили простой тест, проверяющий, что
SolarCalculator правильно работает для известного нам местоположения. Так как юнит-тесты и их юниты тесно связаны, мы используем рекомендуемую систему наименований, а название метода теста соответствует паттерну Method_Precondition_Result («Метод_Предусловие_Результат»).Чтобы симулировать нужное предусловие на этапе Arrange, нам нужно внедрить в зависимость юнита
ILocationProvider соответствующее поведение. В данном случае мы реализуем это заменой возвращаемого значения GetLocationAsync() на местоположение, для которого заранее известно правильное время восхода и заката.Обратите внимание, что хотя
ILocationProvider раскрывает два разных метода, с точки зрения контракта мы не имеем возможности узнать, какой из них вызывается. Это означает, что при выборе имитации одного из этих методов мы делаем предположение о внутренней реализации тестируемого метода (которую в предыдущих фрагментах кода мы намеренно скрыли).В конечном итоге, тест правильно проверяет, что бизнес-логика внутри
GetSolarTimesAsync работает ожидаемым образом. Однако давайте перечислим наблюдения, сделанные нами в процессе работы.1. Юнит-тесты имеют ограниченную применимость
Важно понимать, что задача любого юнит-теста очень проста: проверять бизнес-логику в изолированной области действия. Применимость юнит-тестирования зависит от взаимодействий, которые нам нужно протестировать.
Например, логично ли подвергать юнит-тесту метод, вычисляющий время восхода и заката при помощи долгого и сложного математического алгоритма? Скорее всего да.
Имеет ли смысл выполнять юнит-тест метода, отправляющего запрос к REST API для получения географических координат? Скорее всего нет.
Если рассматривать юнит-тестирование как самоцель, то вы вскоре обнаружите, что несмотря на множество усилий, большинство тестов неспособно обеспечить нужный вам уровень уверенности просто потому, что они тестируют не то, что необходимо. В большинстве случаев гораздо выгоднее тестировать более обширные взаимодействия при помощи интегрального тестирования, чем фокусироваться конкретно на юнит-тестах.
Любопытно, что некоторые разработчики в подобных ситуациях в конечном итоге всё-таки пишут интегральные тесты, но по-прежнему называют их юнит-тестами. В основном это вызвано путаницей, которая окружает это понятие. Конечно, можно заявить, что размер юнита можно выбирать произвольно и что он может охватывать несколько компонентов, но из-за этого определение становится очень нечётким, а потому использование термина оказывается совершенно бесполезным.
2. Юнит-тесты приводят к усложнению структуры
Один из наиболее популярных аргументов в пользу юнит-тестирования заключается в том, что оно стимулирует вас проектировать ПО очень модульным образом. Аргумент основан на предположении, что проще воспринимать код, когда он разбит на множество мелких компонентов, а не на малое количество крупных.
Однако часто это приводит к противоположной проблеме — функциональность может оказаться чрезмерно фрагментированной. Из-за этого оценивать код становится намного сложнее, потому что разработчику приходится просматривать несколько компонентов того, что должно быть единым связанным элементом.
Кроме того, избыточное использование абстракций, необходимое для обеспечения изоляции компонентов, создаёт множество необязательных косвенных взаимодействий. Хоть сама по себе эта техника является невероятно мощной и полезной, абстракции неизбежно повышают когнитивную сложность, ещё сильнее затрудняя восприятие кода.
Из-за таких косвенных взаимодействий мы в конечном итоге теряем определённую степень инкапсуляции, которую могли бы сохранить. Например, ответственность за управление сроком жизни отдельных зависимостей переходит от содержащих их компонентов к какому-то другому не связанному с ними сервису (обычно к контейнеру зависимостей).
Часть инфраструктурной сложности тоже можно делегировать фреймворку внедрения зависимостей, что упрощает конфигурирование зависимостей, управление ими и активацию. Однако это снижает компактность, что в некоторых случаях, например, при написании библиотеки, нежелательно.
В конечном итоге, хоть и очевидно, что юнит-тестирование влияет на проектирование ПО, его полезность весьма спорна.
3. Юнит-тесты затратны
Можно логично предположить, что из-за своего малого размера и изолированности юнит-тесты очень легко и быстро писать. К сожалению, это ещё одно заблуждение; похоже, оно довольно популярно, особенно среди руководства.
Хоть упомянутая выше модульная архитектура заставляет нас думать, что индивидуальные компоненты можно рассматривать отдельно друг от друга, на самом деле юнит-тесты от этого не выигрывают. В действительности, сложность юнит-теста только растёт пропорционально количеству его внешних взаимодействий; это вызвано всей той работой, которую необходимо проделать для достижения изолированности при сохранении требуемого поведения.
Показанный выше пример довольно прост, однако в реальном проекте этап Arrange довольно часто может растягиваться на множество длинных строк, в которых просто задаются предусловия одного теста. В некоторых случаях имитируемое поведение может быть настолько сложным, что почти невозможно распутать его, чтобы разобраться, что оно должно было делать.
Кроме того, юнит-тесты по самой своей природе очень тесно связаны с тестируемым кодом, то есть все трудозатраты для внесения изменений по сути удваиваются, чтобы тест соответствовал обновлённому коду. Ухудшает ситуацию и то, что очень немногим разработчикам эта задача кажется увлекательной, поэтому они просто сбрасывают её на менее опытных членов команды.
4. Юнит-тесты зависят от подробностей реализации
Печальным следствием юнит-тестирования на основе заглушек (mocks) заключается в том, что любой тест, написанный по этой технике, обязательно учитывает реализацию. Имитируя конкретную зависимость, тест начинает полагаться на то, как тестируемый код потребляет эту зависимость, что не регулируется публичным интерфейсом.
Эта дополнительная связь часто приводит к неожиданным проблемам, при которых изменения, которые, казалось бы, ничего не могут сломать, начинают давать сбой при устаревании заглушек. Это может очень напрягать и в конечном итоге отталкивает разработчиков от рефакторинга кода, потому что никогда непонятно, возникла ли ошибка в тесте из-за действительной регрессии или из-за того, что он зависит от подробностей реализации.
Ещё более сложным может быть юнит-тестирование кода с хранением состояния, потому что наблюдение за мутациями через публичный интерфейс может оказаться невозможным. Чтобы обойти эту проблему, обычно можно внедрять шпионов, то есть своего рода имитируемое поведение, регистрирующее вызов функций и помогающее убедиться, что юнит использует свои зависимости правильно.
Разумеется, когда мы зависим не только от вызова конкретной функции, но и от количества вызовов и переданных аргументов, то тест становится ещё более тесно связанным с реализацией. Написанные таким образом тесты полезны только для внутренней специфики и обычно даже ожидается, что они не будут изменяться (крайне неразумное ожидание).
Слишком сильная зависимость от подробностей реализации также очень усложняет сами тесты, учитывая объём подготовки, необходимый для имитации определённого поведения; особенно справедливо это, когда взаимодействия нетривиальны или присутствует множество зависимостей. Когда тесты становятся настолько сложными, что трудно понимать само их поведение, то кто будет писать тесты для тестирования тестов?
5. Юнит-тесты не используют действия пользователей
Какое бы ПО вы не разрабатывали, его задача — обеспечение ценности для конечного пользователя. На самом деле, основная причина написания автоматизированных тестов — обеспечение гарантии отсутствия непреднамеренных дефектов, способных снизить эту ценность.
В большинстве случаев пользователь работает с ПО через какой-нибудь высокоуровневый интерфейс типа UI, CLI или API. Хотя в самом коде могут применяться множественные слои абстракции, для пользователя важен только тот уровень, который он видит и с которым взаимодействует.
Ему даже не важно, если ли в какой-то части системы баг несколькими слоями ниже, если пользователь с ним не сталкивается и он не вредит функциональности. И наоборот: пусть даже у нас есть полное покрытие всех низкоуровневых частей, но если есть изъян в интерфейсе пользователя, то это делает систему по сути бесполезной.
Разумеется, если вы хотите гарантировать правильность работы какого-то элемента, то нужно проверить именно его и посмотреть, действительно ли он работает правильно. В нашем случае, лучшим способом обеспечения уверенности в системе является симуляция взаимодействия реального пользователя с высокоуровневым интерфейсом и проверка того, что он работает в соответствии с ожиданиями.
Проблема юнит-тестов заключается в том, что они являются полной противоположностью такого подхода. Так как мы всегда имеем дело с небольшими изолированными частями кода, с которыми пользователь никогда напрямую не взаимодействует, мы никогда не тестируем истинное поведение пользователя.
Тестирование на основе заглушек ставит ценность таких тестов под ещё большее сомнение, потому что части системы, которые бы использовались, заменяются на имитации, ещё сильнее отдаляя симулируемое окружение от реальности. Невозможно обеспечить уверенность удобства работы пользователя, тестируя нечто непохожее на эту работу.
Юнит-тестирование — отличный способ проверки работы заглушек
Тестирование на основе пирамиды
Так почему же мы как отрасль решили, что юнит-тестирование должно быть основным способом тестирования ПО, несмотря на все его изъяны? В основном это вызвано тем, что тестирование на высоких уровнях всегда считалось слишком трудным, медленным и ненадёжным.
Если обратиться к традиционной пирамиде тестирования, то она предполагает, что наиболее значимая часть тестирования должна выполняться на уровне юнитов. Смысл в том, что поскольку крупные тесты считаются более медленными и сложными, для получения эффективного и поддерживаемого набора тестов нужно сосредоточить усилия на нижней части спектра интеграции:
Сверху — сквозное тестирование, в центре — интегральное тестирование, внизу — юнит-тестирование
Метафорическая модель, предлагаемая пирамидой, должна передать нам мысль о том, что для качественного тестирования должны использоваться множество различных слоёв, ведь если сконцентрироваться на крайностях, то это может привести к проблемам: тесты будут или слишком медленными и неповоротливыми, или бесполезными и не обеспечивающими никакой уверенности. Тем не менее, упор делается на нижние уровни, потому что считается, что там возврат инвестиций в разработку тестов наиболее высок.
Высокоуровневые тесты, хоть и обеспечивают наибольшую уверенность, часто оказываются медленными, сложными в поддержке или слишком широкими для включения в обычно быстрый процесс разработки. Именно поэтому в большинстве случаев такие тесты поддерживаются специалистами QA, ведь обычно считается, что писать их должны не разработчики.
Интегральное тестирование, которое на абстрактной части спектра лежит где-то между юнит-тестированием и полным сквозным тестированием, часто совершенно игнорируется. Непонятно, какой конкретно уровень интеграции предпочтим, как структурировать и организовывать такие тесты. Кроме того, существуют опасения, что они выйдут из под контроля. Поэтому многие разработчики отказываются от них в пользу более чётко очерченной крайности, которой и является юнит-тестирование.
Из-за этих причин всё тестирование в процессе разработки обычно остаётся на самом дне пирамиды. На самом деле, это стало настолько стандартным, что тестирование разработки и юнит-тестирование сегодня стали практически синонимами, что приводит к путанице, усиливаемой докладами на конференциях, постами в блогах, книгами и даже некоторыми IDE (по мнению JetBrains Rider, все тесты являются юнит-тестами).
По мнению большинства разработчиков, пирамида тестирования выглядит примерно так:
Сверху — не моя проблема, внизу — юнит-тестирование
Хотя эта пирамида стала достойной уважения попыткой превратить тестирование ПО в решённую задачу, в этой модели очевидно есть множество проблем. В частности, используемые в ней допущения справедливы не во всех контекстах, особенно допущение о том, что высокоинтегральные наборы тестов являются медленными или трудными.
Мы как люди естественно склонны полагаться на информацию, переданную нам более опытными людьми, благодаря чему можем использовать знания предыдущих поколений и применять вторую систему мышления к чему-то более полезному. Это важная эволюционная черта, чрезвычайно повысившая нашу выживаемость как вида.
Однако когда мы экстраполируем свой опыт в инструкции, то обычно воспринимаем их как хорошие сами по себе, забывая об условиях, неотъемлемо связанных с их актуальностью. На самом деле эти условия меняются, и когда-то совершенно логичные выводы (или best practices) могут оказаться не столь хорошо применимыми.
Если взглянуть на прошлое, то очевидно, что в 2000-х высокоуровневое тестирование было сложным, вероятно, оно оставалось таким даже в 2009 году, но на дворе 2020 год и мы уже живём в будущем. Благодаря прогрессу технологий и проектирования ПО эти проблемы стали гораздо менее важными, чем ранее.
Сегодня большинство современных фреймворков предоставляет какой-нибудь отдельный слой API, используемый для тестирования: в нём можно запускать приложение в симулируемой среде внутри памяти, которое очень близко к реальной. Такие инструменты виртуализации, как Docker, также позволили нам проводить тесты, полагающиеся на действительные инфраструктурные зависимости, сохраняя при этом свою детерминированность и скорость.
У нас есть такие решения, как Mountebank, WireMock, GreenMail, Appium, Selenium, Cypress и бесконечное множество других, они упрощают различные аспекты высокоуровневого тестирования, которые когда-то считались недостижимыми. Если вы не разрабатываете десктопные приложения для Windows и не вынуждены использовать фреймворк UIAutomation, то у вас, скорее всего, есть множество возможных вариантов выбора.
В одном из моих предыдущих проектов у нас был веб-сервис, тестировавшийся на границе системы при помощи почти сотни поведенческих тестов, на параллельное выполнение которых тратилось менее 10 секунд. Разумеется, при использовании юнит-тестов можно добиться гораздо более быстрого выполнения, но учитывая обеспечиваемую уверенность, мы даже не рассматривали такую возможность.
Однако заблуждение о медленности тестов — не единственное ошибочное допущение, на котором основана пирамида. Принцип применения большинства тестов на уровне юнитов работает только тогда, когда эти тесты действительно обеспечивают ценность, что, разумеется, зависит от того, какой объём бизнес-логики находится в тестируемом коде.
В некоторых приложениях бизнес-логики может быть много (например, в системах подсчёта зарплаты), в некоторых она почти отсутствует (например, в CRUD-приложениях), а большинство ПО находится где-то посередине. Большинство проектов, над которыми работал лично я, не содержали такого объёма, чтобы была необходимость в обширном покрытии юнит-тестами; с другой стороны, в них было много инфраструктурной сложности, для которой было бы полезно интегральное тестирование.
Разумеется, в идеальном мире разработчик смог бы оценить контекст проекта и создать способ тестирования, наиболее подходящий для решения насущных задач. Однако в реальности большинство разработчиков даже не задумывается об этом, слепо наворачивая горы юнит-тестов в соответствии с рекомендациями best practices.
Наконец, по-моему, было бы справедливо сказать, что создаваемая пирамидой тестирования модель слишком проста в целом. Вертикальная ось представляет спектр тестирования как линейную шкалу, при которой любое повышение уверенности компенсируется эквивалентной величиной потери поддерживаемости и скорости. Это может быть истинным, если вы сравниваете крайние случаи, но не всегда правда для точек в промежутке между ними.
Пирамида также не учитывает того, что изоляция сама по себе имеет цену, она не возникает бесплатно просто благодаря «избеганию» внешних взаимодействий. Учитывая то, сколько труда требуется для написания и поддержки заглушек, вполне возможно, что менее изолированный тест может быть дешевле и в конечном итоге обеспечит бОльшую уверенность, хоть и при чуть более низкой скорости выполнения.
Если принять во внимание эти аспекты, то кажется вероятным, что шкала окажется нелинейной, и что точка максимального возврата инвестиций находится где-то ближе к середине, а не к уровню юнитов:
В конечном итоге, если вы пытаетесь определить эффективный набор тестов для своего проекта, пирамида тестирования — не лучший образец, которому можно следовать. Гораздо логичнее сосредоточиться на том, что относится конкретно к вашему контексту, а не полагаться на «best practices».
Тестирование на основе реальности
На самом базовом уровне тест обеспечивает ценность, если он гарантирует нам, что ПО работает правильно. Чем больше мы уверены, тем меньше нам нужно полагаться на себя в поиске потенциальных багов и регрессий при внесении изменений в код, потому что мы поручаем заниматься этим тестам.
Это доверие, в свою очередь, зависит от точности воспроизведения тестом настоящего поведения пользователя. Тестовый сценарий, работающий на границе системы без знаний её внутренней специфики должен обеспечивать нам бОльшую уверенность (а значит, и ценность), чем тест, работающий на нижнем уровне.
По сути, степень получаемой от тестов уверенности — это основная метрика, которой должна измеряться их ценность. А основная цель — это её максимальное увеличение.
Разумеется, как мы знаем, в деле задействованы и другие факторы: цена, скорость, возможность параллелизации и прочие, и все они тоже важны. Пирамида тестирования создаёт сильные допущения о том, как взаимосвязаны масштабирование этих элементов, но эти допущения не универсальны.
Более того, эти факторы являются вторичными относительно основной цели — достижения уверенности. Дорогой и долго выполняемый тест, обеспечивающий большую уверенность, бесконечно более полезен, чем чрезвычайно быстрый и простой тест, который не делает ничего.
Поэтому я считаю, что лучше писать тесты с максимально возможной степенью интеграции, поддерживая при этом их разумную скорость и сложность.
Значит ли это, что каждый создаваемый нами тест должен быть сквозным? Нет, но мы должны стремиться как можно дальше продвинуться в этом направлении, обеспечивая при этом допустимый уровень недостатков.
Приемлемость субъективна и зависит от контекста. В конечном итоге, важно то, что эти тесты пишутся разработчиками и используются в процессе разработки, то есть они не должны создавать обузу при поддержке и обеспечивать возможность запуска в локальных сборках и на конфигурационной единице.
В таком случае у нас скорее всего получатся тесты, разбросанные по нескольким уровням шкалы интеграции при кажущемся отсутствии ощущения структуры. Такой проблемы не возникает при юнит-тестировании, потому что в нём каждый тест связан с конкретным методом или функцией, поэтому структура обычно отзеркаливает сам код.
К счастью, это не важно, потому что упорядочивание тестов по отдельным классам или модулям не имеет значения само по себе; скорее, это побочный эффект юнит-тестирования. Вместо этого тесты должны разделятся по истинной пользовательской функциональности, которую они проверяют.
Такие тесты часто называют функциональными (functional), потому что они основаны на требованиях к функциональности ПО, описывающих его возможности и способ их работы. Функциональное тестирование — это не ещё один слой пирамиды, а совершенно перпендикулярная ей концепция.
Вопреки распространённому мнению, для написания функциональных тестов не требуется использовать Gherkin или фреймворк BDD, их можно реализовать при помощи тех же инструментов, которые применяются для юнит-тестирования. Например, давайте подумаем, как мы можем переписать пример из начала статьи так, чтобы тесты были структурированы на основе поддерживаемого поведения пользователей, а не юнитов кода:
public class SolarTimesSpecs
{
[Fact]
public async Task User_can_get_solar_times_automatically_for_their_location() { /* ... */ }
[Fact]
public async Task User_can_get_solar_times_during_periods_of_midnight_sun() { /* ... */ }
[Fact]
public async Task User_can_get_solar_times_if_their_location_cannot_be_resolved() { /* ... */ }
}Обратите внимание, что сама реализация тестов скрыта, потому что она не связана с тем, что они функциональны. Важно здесь то, что тесты и их структура задаются требованиями к ПО, а их масштаб теоретически может изменяться от сквозного тестирования и даже до уровня юнитов.
Называя тесты в соответствии со спецификациями, а не с классами, мы получаем дополнительное преимущество — устраняем эту необязательную связь. Теперь, если мы решим переименовать
SolarCalculator во что-то ещё или переместим его в другой каталог, то названия тестов не нужно будет изменять.Если придерживаться такой структуры, то наш набор тестов по сути принимает вид живой документации. Вот, например, как организован набор тестов в CliWrap (xUnit заменил нижние подчёркивания на пробелы):
Пока элемент ПО выполняет нечто хотя бы отдалённо полезное, то он всегда имеет функциональные требования. Они могут быть или формальными (документы спецификации, пользовательские истории, и т.д.) или неформальными (в устной форме, допускаемые, тикеты JIRA, записанные на туалетной бумаге, и т.д.)
Преобразование неформальных спецификаций в функциональные тесты часто может быть сложным процессом, потому что для этого требуется отступить от кода и заставить себя взглянуть на ПО с точки зрения пользователя. В моих open-source-проектах мне помогает составление файла readme, в котором я перечисляю список примеров использования, а затем кодирую их в тесты.
Подведём итог: можно заключить, что лучше разделять тесты по цепочкам поведений, а не по внутренней структуре кода.
Если объединить оба вышеупомянутых подхода, то образуется структура мышления, дающая нам чёткую цель написания тестов, а также понимание организации; при этом нам не нужно полагаться ни на какие допущения. Мы можем использовать эту структуру для создания набора тестов для проекта, сосредоточенный на ценности, а затем масштабировать его в соответствии с важными в текущем контексте приоритетами и ограничениями.
Принцип заключается в том, чтобы вместо упора на определённую область или набор областей, мы создаём набор тестов на основании пользовательской функциональности, стремясь как можно точнее покрыть эту функциональность.
Функциональное тестирование для веб-сервисов (с помощью ASP.NET Core)
Вероятно, вы не понимаете, из чего же состоит функциональное тестирование и как конкретно оно должно выглядеть, особенно если не занимались им раньше. Поэтому разумно будет привести простой, но законченный пример. Для этого мы превратим наш калькулятор восходов и закатов в веб-сервис и покроем его тестам в соответствии с правилами, изложенными в предыдущей части статьи. Это приложение будет основано на ASP.NET Core — веб-фреймворке, с которым я знаком больше всего, но такой же принцип должен быть применим к любой другой платформе.
Наш веб-сервис раскрывает свои конечные точки для вычисления времени восхода и заката на основании IP пользователя или указанного местоположения. Чтобы всё было чуть интереснее, для ускорения ответов мы добавим слой кэширования Redis, хранящий предыдущие вычисления.
Тесты будут выполняться запуском приложения в симулируемой среде, в которой оно может получать HTTP-запросы, обрабатывать маршрутизацию, выполнять валидацию и демонстрировать поведение. практически идентичное приложению, запущенному в продакшене. Также мы используем Docker, чтобы наши тесты использовали те же инфраструктурные зависимости, что и реальное приложение.
Чтобы разобраться, с чем мы имеем дело, давайте сначала рассмотрим реализацию веб-приложения. Обратите внимание, что некоторые части фрагментов кода ради краткости пропущены, а полный проект можно посмотреть на GitHub.
Для начала нам нужно найти способ определения местоположения пользователя по IP, выполняемое при помощи класса
LocationProvider, который мы видели в предыдущих примерах. Он является простой обёрткой вокруг внешнего сервиса GeoIP-поиска под названием IP-API:public class LocationProvider
{
private readonly HttpClient _httpClient;
public LocationProvider(HttpClient httpClient) =>
_httpClient = httpClient;
public async Task<Location> GetLocationAsync(IPAddress ip)
{
// If IP is local, just don't pass anything (useful when running on localhost)
var ipFormatted = !ip.IsLocal() ? ip.MapToIPv4().ToString() : "";
var json = await _httpClient.GetJsonAsync($"http://ip-api.com/json/{ipFormatted}");
var latitude = json.GetProperty("lat").GetDouble();
var longitude = json.GetProperty("lon").GetDouble();
return new Location
{
Latitude = latitude,
Longitude = longitude
};
}
}Для преобразования местоположения во время восхода и заката мы воспользуемся алгоритмом вычисления восхода и заката, опубликованным Военно-морской обсерваторией США. Сам алгоритм слишком длинный, поэтому мы не будем его приводить здесь, а остальная часть реализации
SolarCalculator имеет следующий вид:public class SolarCalculator
{
private readonly LocationProvider _locationProvider;
public SolarCalculator(LocationProvider locationProvider) =>
_locationProvider = locationProvider;
private static TimeSpan CalculateSolarTimeOffset(Location location, DateTimeOffset instant,
double zenith, bool isSunrise)
{
/* ... */
// Algorithm omitted for brevity
/* ... */
}
public async Task<SolarTimes> GetSolarTimesAsync(Location location, DateTimeOffset date)
{
/* ... */
}
public async Task<SolarTimes> GetSolarTimesAsync(IPAddress ip, DateTimeOffset date)
{
var location = await _locationProvider.GetLocationAsync(ip);
var sunriseOffset = CalculateSolarTimeOffset(location, date, 90.83, true);
var sunsetOffset = CalculateSolarTimeOffset(location, date, 90.83, false);
var sunrise = date.ResetTimeOfDay().Add(sunriseOffset);
var sunset = date.ResetTimeOfDay().Add(sunsetOffset);
return new SolarTimes
{
Sunrise = sunrise,
Sunset = sunset
};
}
}Так как это веб-приложение MVC, нам также потребуется контроллер, предоставляющий конечные точки для раскрытия функциональности приложения:
[ApiController]
[Route("solartimes")]
public class SolarTimeController : ControllerBase
{
private readonly SolarCalculator _solarCalculator;
private readonly CachingLayer _cachingLayer;
public SolarTimeController(SolarCalculator solarCalculator, CachingLayer cachingLayer)
{
_solarCalculator = solarCalculator;
_cachingLayer = cachingLayer;
}
[HttpGet("by_ip")]
public async Task<IActionResult> GetByIp(DateTimeOffset? date)
{
var ip = HttpContext.Connection.RemoteIpAddress;
var cacheKey = $"{ip},{date}";
var cachedSolarTimes = await _cachingLayer.TryGetAsync<SolarTimes>(cacheKey);
if (cachedSolarTimes != null)
return Ok(cachedSolarTimes);
var solarTimes = await _solarCalculator.GetSolarTimesAsync(ip, date ?? DateTimeOffset.Now);
await _cachingLayer.SetAsync(cacheKey, solarTimes);
return Ok(solarTimes);
}
[HttpGet("by_location")]
public async Task<IActionResult> GetByLocation(double lat, double lon, DateTimeOffset? date)
{
/* ... */
}
}Как показано выше, конечная точка
/solartimes/by_ip в основном просто делегирует исполнение SolarCalculator, а кроме того, имеет очень простую логику кэширования для избавления от избыточных запросов к сторонним сервисам. Кэширование выполняется классом CachingLayer, инкапсулирующим клиент Redis, используемый для хранения и получения JSON-контента:public class CachingLayer
{
private readonly IConnectionMultiplexer _redis;
public CachingLayer(IConnectionMultiplexer connectionMultiplexer) =>
_redis = connectionMultiplexer;
public async Task<T> TryGetAsync<T>(string key) where T : class
{
var result = await _redis.GetDatabase().StringGetAsync(key);
if (result.HasValue)
return JsonSerializer.Deserialize<T>(result.ToString());
return null;
}
public async Task SetAsync<T>(string key, T obj) where T : class =>
await _redis.GetDatabase().StringSetAsync(key, JsonSerializer.Serialize(obj));
}Все описанные выше части соединяются вместе в классе
Startup, конфигурирующем конвейер запросов и регистрирующем требуемые сервисы:public class Startup
{
private readonly IConfiguration _configuration;
public Startup(IConfiguration configuration) =>
_configuration = configuration;
private string GetRedisConnectionString() =>
_configuration.GetConnectionString("Redis");
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc(o => o.EnableEndpointRouting = false);
services.AddSingleton<IConnectionMultiplexer>(
ConnectionMultiplexer.Connect(GetRedisConnectionString()));
services.AddSingleton<CachingLayer>();
services.AddHttpClient<LocationProvider>();
services.AddTransient<SolarCalculator>();
}
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
app.UseDeveloperExceptionPage();
app.UseMvcWithDefaultRoute();
}
}Обратите внимание, что нам не пришлось реализовывать в классах каких-то самоцельных интерфейсов просто потому, что мы не планируем использовать заглушки. Возможно, нам понадобится заменить один из сервисов в тестах, но пока это непонятно, поэтому мы избежим ненужной работы (и ущерба структуре кода), пока точно не будем уверены, что это нужно.
Хоть проект и довольно прост, это приложение уже содержит в себе достаточное количество инфраструктурной сложности: оно полагается на сторонний веб-сервис (провайдера GeoIP), а также на слой хранения данных (Redis). Это вполне стандартная схема, используемая во многих реальных проектах.
В классическом подходе, сосредоточенном на юнит-тестировании, мы бы нацелились на слой сервисов и, возможно, на слой контроллера приложения, и писали бы изолированные тесты, гарантирующие правильное выполнение каждой ветви кода. Такой подход будет в какой-то мере полезен, но он никогда не обеспечит нам уверенности в том, что истинные конечные точки со всеми middleware и периферийными компонентами работают как положено.
Так что вместо этого мы напишем тесты, нацеленные непосредственно на конечные точки. Для этого нам понадобится создать отдельный тестовый проект и добавить несколько инфраструктурных компонентов, поддерживающих наши тесты. Один из них — это
FakeApp, который будет использоваться для инкапсуляции виртуального экземпляра приложения:public class FakeApp : IDisposable
{
private readonly WebApplicationFactory<Startup> _appFactory;
public HttpClient Client { get; }
public FakeApp()
{
_appFactory = new WebApplicationFactory<Startup>();
Client = _appFactory.CreateClient();
}
public void Dispose()
{
Client.Dispose();
_appFactory.Dispose();
}
}Основная часть работы здесь уже выполнена
WebApplicationFactory — предоставляемой фреймворком утилитой, позволяющей нам загрузить программу в память в целях тестирования. Также она предоставляет нам API для переопределения конфигурации, регистрации сервисов и конвейера обработки запросов.Мы можем использовать экземпляр этого объекта в тестах для запуска приложения и отправки запросов с предоставленным
HttpClient, а затем проверять соответствует ли ответ нашим ожиданиям. Этот экземпляр может быть или общим для нескольких тестов, или создаваться отдельно для каждого теста.Поскольку мы также используем Redis, нам нужен способ запуска нового сервера, который будет использоваться приложением. Существует множество способов реализации этого, но для простого примера я решил использовать в этих целях API оборудования (fixture) фреймворка xUnit:
public class RedisFixture : IAsyncLifetime
{
private string _containerId;
public async Task InitializeAsync()
{
// Simplified, but ideally should bind to a random port
var result = await Cli.Wrap("docker")
.WithArguments("run -d -p 6379:6379 redis")
.ExecuteBufferedAsync();
_containerId = result.StandardOutput.Trim();
}
public async Task ResetAsync() =>
await Cli.Wrap("docker")
.WithArguments($"exec {_containerId} redis-cli FLUSHALL")
.ExecuteAsync();
public async Task DisposeAsync() =>
await Cli.Wrap("docker")
.WithArguments($"container kill {_containerId}")
.ExecuteAsync();
}Показанный выше код реализует интерфейс
IAsyncLifetime, позволяющий нам определять методы, которые будут выполняться до и после запусков тестов. Мы используем эти методы для запуска контейнера Redis в Docker с последующим его уничтожением после завершением тестирования.Кроме того, класс
RedisFixture также раскрывает метод ResetAsync, который можно использовать для выполнения команды FLUSHALL, удаляющей все ключи из базы данных. Мы будем вызывать этот метод перед каждым тестом для сброса Redis к чистому состоянию. В качестве альтернативы мы могли бы просто перезапускать контейнер, что занимает больше времени, но более надёжно.Настроив инфраструктуру, можно переходить к написанию первого теста:
public class SolarTimeSpecs : IClassFixture<RedisFixture>, IAsyncLifetime
{
private readonly RedisFixture _redisFixture;
public SolarTimeSpecs(RedisFixture redisFixture)
{
_redisFixture = redisFixture;
}
// Reset Redis before each test
public async Task InitializeAsync() => await _redisFixture.ResetAsync();
[Fact]
public async Task User_can_get_solar_times_for_their_location_by_ip()
{
// Arrange
using var app = new FakeApp();
// Act
var response = await app.Client.GetStringAsync("/solartimes/by_ip");
var solarTimes = JsonSerializer.Deserialize<SolarTimes>(response);
// Assert
solarTimes.Sunset.Should().BeWithin(TimeSpan.FromDays(1)).After(solarTimes.Sunrise);
solarTimes.Sunrise.Should().BeCloseTo(DateTimeOffset.Now, TimeSpan.FromDays(1));
solarTimes.Sunset.Should().BeCloseTo(DateTimeOffset.Now, TimeSpan.FromDays(1));
}
}Как видите, схема очень проста. Нам достаточно лишь создать экземпляр
FakeApp и использовать предоставленный HttpClient для отправки запросов к одной из конечных точек, как бы это происходило в реальном веб-приложении.Конкретно этот тест запрашивает маршрут
/solartimes/by_ip, определяющий время восхода и заката для текущей даты на основании IP пользователя. Так как мы полагаемся на настоящего провайдера GeoIP и не знаем, каким будет результат, то выполняем утверждения на основе свойств, чтобы гарантировать валидность времени восхода и заката.Хоть эти утверждения и способны отследить множество потенциальных багов, они не дают нам полной уверенности в совершенной правильности результата. Однако существует пара способов, которыми мы можем улучшить ситуацию.
Очевидный способ — можно заменить настоящего провайдера GeoIP фальшивым экземпляром, всегда возвращающим одинаковое местоположение, что позволит нам жёстко прописать в коде ожидаемое время восхода и заката. Недостаток такого подхода в том, что мы по сути уменьшаем масштаб интеграции, то есть мы не сможем убедиться, что приложение правильно общается со сторонним сервисом.
В качестве альтернативного подхода мы можем заменить IP-адрес, который тестовый сервер получает от клиента. Благодаря этому мы сделаем тест более строгим, сохраняя при этом тот же масштаб интеграции.
Для этого нам понадобится создать фильтр запуска, позволяющий нам при помощи middleware инъектировать выбранный IP-адрес в контекст запроса:
public class FakeIpStartupFilter : IStartupFilter
{
public IPAddress Ip { get; set; } = IPAddress.Parse("::1");
public Action<IApplicationBuilder> Configure(Action<IApplicationBuilder> nextFilter)
{
return app =>
{
app.Use(async (ctx, next) =>
{
ctx.Connection.RemoteIpAddress = Ip;
await next();
});
nextFilter(app);
};
}
}Затем мы можем соединить его с
FakeApp, зарегистрировав его в качестве сервиса:public class FakeApp : IDisposable
{
private readonly WebApplicationFactory<Startup> _appFactory;
private readonly FakeIpStartupFilter _fakeIpStartupFilter = new FakeIpStartupFilter();
public HttpClient Client { get; }
public IPAddress ClientIp
{
get => _fakeIpStartupFilter.Ip;
set => _fakeIpStartupFilter.Ip = value;
}
public FakeApp()
{
_appFactory = new WebApplicationFactory<Startup>().WithWebHostBuilder(o =>
{
o.ConfigureServices(s =>
{
s.AddSingleton<IStartupFilter>(_fakeIpStartupFilter);
});
});
Client = _appFactory.CreateClient();
}
/* ... */
}Теперь мы можем дополнить тест, чтобы он использовал конкретные данные:
[Fact]
public async Task User_can_get_solar_times_for_their_location_by_ip()
{
// Arrange
using var app = new FakeApp
{
ClientIp = IPAddress.Parse("20.112.101.1")
};
var date = new DateTimeOffset(2020, 07, 03, 0, 0, 0, TimeSpan.FromHours(-5));
var expectedSunrise = new DateTimeOffset(2020, 07, 03, 05, 20, 37, TimeSpan.FromHours(-5));
var expectedSunset = new DateTimeOffset(2020, 07, 03, 20, 28, 54, TimeSpan.FromHours(-5));
// Act
var query = new QueryBuilder
{
{"date", date.ToString("O", CultureInfo.InvariantCulture)}
};
var response = await app.Client.GetStringAsync($"/solartimes/by_ip{query}");
var solarTimes = JsonSerializer.Deserialize<SolarTimes>(response);
// Assert
solarTimes.Sunrise.Should().BeCloseTo(expectedSunrise, TimeSpan.FromSeconds(1));
solarTimes.Sunset.Should().BeCloseTo(expectedSunset, TimeSpan.FromSeconds(1));
}Некоторых разработчиков по-прежнему может тревожить использование в тестах стороннего веб-сервиса, потому что это может привести к недетерминированным результатам. В то же время, можно возразить, что нам действительно нужно встроить в наши тесты эту зависимость, потому что мы хотим знать, будет ли он ломаться или изменяться неожиданным образом, потому что это способно приводить к багам в нашем собственном ПО.
Разумеется, не всегда мы можем использовать реальные зависимости, например, если у сервиса есть ограничения на использование, он стоит денег, или просто медленный или ненадёжный. В таких случаях нам придётся заменить его на фальшивую (предпочтительно не на заглушку) реализацию для использования в тестах. Однако в нашем случае всё не так.
Аналогично тому, как мы сделали с первым тестом, можно написать тест, покрывающий вторую конечную точку. Этот тест проще, потому что все входящие параметры передаются напрямую как часть запроса URL:
[Fact]
public async Task User_can_get_solar_times_for_a_specific_location_and_date()
{
// Arrange
using var app = new FakeApp();
var date = new DateTimeOffset(2020, 07, 03, 0, 0, 0, TimeSpan.FromHours(+3));
var expectedSunrise = new DateTimeOffset(2020, 07, 03, 04, 52, 23, TimeSpan.FromHours(+3));
var expectedSunset = new DateTimeOffset(2020, 07, 03, 21, 11, 45, TimeSpan.FromHours(+3));
// Act
var query = new QueryBuilder
{
{"lat", "50.45"},
{"lon", "30.52"},
{"date", date.ToString("O", CultureInfo.InvariantCulture)}
};
var response = await app.Client.GetStringAsync($"/solartimes/by_location{query}");
var solarTimes = JsonSerializer.Deserialize<SolarTimes>(response);
// Assert
solarTimes.Sunrise.Should().BeCloseTo(expectedSunrise, TimeSpan.FromSeconds(1));
solarTimes.Sunset.Should().BeCloseTo(expectedSunset, TimeSpan.FromSeconds(1));
}Мы можем продолжать добавлять подобные тесты, чтобы убедиться, что приложение поддерживает все возможные местоположения и даты, а также обрабатывает потенциальные пограничные случаи, например, полярный день. Однако возможно, что такой подход будет плохо масштабироваться, потому что нам может и не стоит выполнять каждый раз весь конвейер только для проверки правильности бизнес-логики, вычисляющей время восхода и заката.
Важно также заметить, что хоть мы и пытались этого по возможности избегать, всё равно можно снизить масштаб интеграции, если на то будут реальные причины. В данном случае можно попробовать покрыть дополнительные случаи юнит-тестами.
Обычно это означало бы, что нам каким-то образом нужно изолировать
SolarCalculator от LocationProvider, что, в свою очередь, подразумевает заглушки. К счастью, есть хитрый способ этого избежать.Мы можем изменить реализацию
SolarCalculator разделив чистые и загрязнённые части кода:public class SolarCalculator
{
private static TimeSpan CalculateSolarTimeOffset(Location location, DateTimeOffset instant,
double zenith, bool isSunrise)
{
/* ... */
}
public SolarTimes GetSolarTimes(Location location, DateTimeOffset date)
{
var sunriseOffset = CalculateSolarTimeOffset(location, date, 90.83, true);
var sunsetOffset = CalculateSolarTimeOffset(location, date, 90.83, false);
var sunrise = date.ResetTimeOfDay().Add(sunriseOffset);
var sunset = date.ResetTimeOfDay().Add(sunsetOffset);
return new SolarTimes
{
Sunrise = sunrise,
Sunset = sunset
};
}
}Мы изменили код так, что вместо использования
LocationProvider для получения местоположения, метод GetSolarTimes получает его как явный параметр. Благодаря этому нам также больше не понадобится инверсия зависимостей, потому что зависимости для инвертирования отсутствуют.Чтобы снова соединить всё вместе, нам достаточно изменить контроллер:
[ApiController]
[Route("solartimes")]
public class SolarTimeController : ControllerBase
{
private readonly SolarCalculator _solarCalculator;
private readonly LocationProvider _locationProvider;
private readonly CachingLayer _cachingLayer;
public SolarTimeController(
SolarCalculator solarCalculator,
LocationProvider locationProvider,
CachingLayer cachingLayer)
{
_solarCalculator = solarCalculator;
_locationProvider = locationProvider;
_cachingLayer = cachingLayer;
}
[HttpGet("by_ip")]
public async Task<IActionResult> GetByIp(DateTimeOffset? date)
{
var ip = HttpContext.Connection.RemoteIpAddress;
var cacheKey = ip.ToString();
var cachedSolarTimes = await _cachingLayer.TryGetAsync<SolarTimes>(cacheKey);
if (cachedSolarTimes != null)
return Ok(cachedSolarTimes);
// Composition instead of dependency injection
var location = await _locationProvider.GetLocationAsync(ip);
var solarTimes = _solarCalculator.GetSolarTimes(location, date ?? DateTimeOffset.Now);
await _cachingLayer.SetAsync(cacheKey, solarTimes);
return Ok(solarTimes);
}
/* ... */
}Так как имеющиеся тесты не знают о подробностях реализации, этот простой рефакторинг их не сломает. Сделав это, мы можем написать дополнительные короткие тесты для более подробного покрытия бизнес-логики без необходимости заглушек:
[Fact]
public void User_can_get_solar_times_for_New_York_in_November()
{
// Arrange
var location = new Location
{
Latitude = 40.71,
Longitude = -74.00
};
var date = new DateTimeOffset(2019, 11, 04, 00, 00, 00, TimeSpan.FromHours(-5));
var expectedSunrise = new DateTimeOffset(2019, 11, 04, 06, 29, 34, TimeSpan.FromHours(-5));
var expectedSunset = new DateTimeOffset(2019, 11, 04, 16, 49, 04, TimeSpan.FromHours(-5));
// Act
var solarTimes = new SolarCalculator().GetSolarTimes(location, date);
// Assert
solarTimes.Sunrise.Should().BeCloseTo(expectedSunrise, TimeSpan.FromSeconds(1));
solarTimes.Sunset.Should().BeCloseTo(expectedSunset, TimeSpan.FromSeconds(1));
}
[Fact]
public void User_can_get_solar_times_for_Tromso_in_January()
{
// Arrange
var location = new Location
{
Latitude = 69.65,
Longitude = 18.96
};
var date = new DateTimeOffset(2020, 01, 03, 00, 00, 00, TimeSpan.FromHours(+1));
var expectedSunrise = new DateTimeOffset(2020, 01, 03, 11, 48, 31, TimeSpan.FromHours(+1));
var expectedSunset = new DateTimeOffset(2020, 01, 03, 11, 48, 45, TimeSpan.FromHours(+1));
// Act
var solarTimes = new SolarCalculator().GetSolarTimes(location, date);
// Assert
solarTimes.Sunrise.Should().BeCloseTo(expectedSunrise, TimeSpan.FromSeconds(1));
solarTimes.Sunset.Should().BeCloseTo(expectedSunset, TimeSpan.FromSeconds(1));
}Хоть эти тесты больше и не используют полную область интеграции, они всё равно исходят из функциональных требований к приложению. Так как у нас уже есть другой высокоуровневый тест, покрывающий конечную точку целиком, мы можем сделать эти тесты более узкими, не жертвуя при этом общим уровнем уверенности.
Такой компромисс разумен, если мы стремимся повысить скорость выполнения, но я бы порекомендовал максимально придерживаться высокоуровневых тестов, по крайней мере, до тех по, пока это не станет проблемой.
Наконец, нам стоит сделать что-нибудь, чтобы гарантировать правильную работу слоя кэширования Redis. Даже несмотря на то, что мы используем его в своих тестах, на деле он никогда не возвращает кэшированный ответ, потому что между тестами база данных сбрасывается к исходному состоянию.
Проблема при тестировании таких аспектов, как кэширование, заключается в том, что их невозможно задать функциональными требованиями. Пользователь, не знающий о внутренней работе приложения, не может узнать, возвращён ли ответ из кэша.
Однако если наша задача заключается только в тестировании интеграции между приложением и Redis, нам не нужно писать тесты, знающие об особенностях реализации, и вместо этого можно сделать нечто подобное:
[Fact]
public async Task User_can_get_solar_times_for_their_location_by_ip_multiple_times()
{
// Arrange
using var app = new FakeApp();
// Act
var collectedSolarTimes = new List<SolarTimes>();
for (var i = 0; i < 3; i++)
{
var response = await app.Client.GetStringAsync("/solartimes/by_ip");
var solarTimes = JsonSerializer.Deserialize<SolarTimes>(response);
collectedSolarTimes.Add(solarTimes);
}
// Assert
collectedSolarTimes.Select(t => t.Sunrise).Distinct().Should().ContainSingle();
collectedSolarTimes.Select(t => t.Sunset).Distinct().Should().ContainSingle();
}Тест несколько раз выполняет запрос к одной конечной точке и утверждает, что результат всегда остаётся одинаковым. Этого достаточно для проверки правильности кэширования ответов и возврата их таким же образом, как и обычных ответов.
В конечном итоге мы получили простой набор тестов, который выглядит вот так:
Обратите внимание, что скорость выполнения тестов довольно хороша — самый быстрый интегральный тест завершается за 55 мс, а самый медленный — меньше чем за секунду (из-за холодного запуска). Учитывая то, что эти тесты задействуют весь рабочий цикл, в том числе все зависимости и инфраструктуру, при этом не используя никаких заглушек, я могу сказать, что это более чем приемлемо.
Если вы хотите самостоятельно поэкспериментировать с проектом, то его можно найти на GitHub.
Недостатки и ограничения
К сожалению, серебряной пули нет, и описанные в этой статье решения тоже страдают от потенциальных недостатков. В интересах справедливости будет разумно их упомянуть.
Одна из самых серьёзных проблем, с которыми я столкнулся при реализации высокоуровневого функционального тестирования — поиск удовлетворительного баланса между полезностью и применимостью. По сравнению с подходами, целиком сосредоточенными на юнит-тестировании, здесь приходится прикладывать больше усилий для проверки достаточной детерминированности таких тестов, их скорости выполнения, возможности выполнения независимо друг от друга и в целом их применимости в процессе разработки.
Широкомасштабность тестов также подразумевает необходимость более глубокого понимания зависимостей проекта и технологий, которые в нём применяются. Важно знать, как они используются, легко ли их контейнировать, наличие возможных вариантов и необходимые компромиссы.
В контексте интегрального тестирования аспект «тестируемости» определяется не тем, насколько хорошо можно изолировать код, а тем, насколько реальная инфраструктура приспособлена к тестированию и облегчает его. Это накладывает определённые требования с точки зрения технической компетенции и на ответственное лицо, и на команду в целом.
Кроме того, на подготовку и конфигурирование тестовой среды может потребоваться некоторое время, потому что для него требуется создание оборудования (fixtures), подключение фальшивых реализаций, добавление специализированного поведения инициализации и очистки, и так далее. Все эти аспекты придётся поддерживать в процессе увеличения масштабов и сложности проекта.
Само по себе написание функциональных тестов требует также чуть больше планирования, потому что теперь речь идёт не о покрытии каждого метода каждого класса, а об определении требований к ПО и превращению их в код. Иногда бывает сложно понять эти требования и то, какие из них являются функциональными, потому что для этого необходимо думать как пользователь.
Ещё одна распространённая проблема заключается в том, что высокоуровневые тесты часто страдают от нехватки локальности. Если тест не проходит из-за неудовлетворённых ожиданий или необработанного исключения, то обычно непонятно, что конкретно вызвало ошибку.
Хотя всегда существуют способы частичного устранения этой проблемы, это всегда становится компромиссом: изолированные тесты лучше указывают на причину ошибки, а интегральные тесты лучше показывают её воздействие. Оба вида равно полезны, поэтому всё сводится к тому, что вы посчитаете более важным.
В конечном итоге, я всё равно считаю, что функциональное тестирование стоит того, несмотря на все его недостатки, потому что, по моему мнению, оно приводит к повышению удобства и качества разработки. Я уже давно не занимался классическим юнит-тестированием и не собираюсь к нему возвращаться.
Выводы
Юнит-тестирование — популярный подход к тестированию ПО, но в основном по ошибочным причинам. Часто его навязывают как эффективный способ для тестирования разработчиками своего кода, стимулирующий к использованию best practices проектирования, однако многие считают его затруднительным и поверхностным.
Важно понимать, что тестирование в процессе разработки не равно юнит-тестированию. Основная цель — не написание максимально изолированных тестов, а достижение уверенности в том, что код работает в соответствии с функциональными требованиями. И для этого есть способы получше.
Написание высокоуровневых тестов, руководствующихся поведением пользователя, обеспечит вам в дальней перспективе гораздо больший возврат инвестиций; при этом оно не так сложно, как кажется. Найдите подход, наиболее разумный для вашего проекта, и придерживайтесь его.
Вот основные уроки:
- Рассуждайте критически и подвергайте сомнению best practices
- Не полагайтесь на пирамиду тестирования
- Разделяйте тесты по функциональности, а не по классам, модулям или области действия
- Стремитесь к максимально высокому уровню интеграции, сохраняя при этом разумные скорость и затраты
- Избегайте жертвования структурой ПО в пользу тестируемости
- Используйте заглушки только в крайних случаях
Существуют и другие замечательные статьи об альтернативных подходах к тестированию в современной разработке ПО. Вот те из них, которые показались интересными лично мне:
- Write tests. Not too many. Mostly integration (Kent C. Dodds)
- Mocking is a Code Smell (Eric Elliott)
- Test-induced design damage (David Heinemeier Hansson)
- Slow database test fallacy (David Heinemeier Hansson)
- Fallacy of Unit Testing (Aaron W. Hsu)
- The No. 1 unit testing best practice: Stop doing it (Vitaliy Pisarev)
- Testing of Microservices at Spotify (Andre Schaffer)


















vdem
Не читал (многабукаф, только пролистал) но осуждаю :) Мне лично юнит-тесты очень помогают не поломать что-нибудь, особенно когда общее представление о проекте еще не оформилось и приходится часто вносить правки. Я уверен (вернее даже знаю), что они сэкономили мне кучу времени. Другое дело, что не надо это возводить в абсолют, конечно, и стремиться к 100% покрытию или менять архитектуру в угоду тестируемости, которая может зависеть от используемого фреймворка для тестов.
VIkrom
Что в ваших юнит-тестах есть юнит? Ведь на ранних этапах проекта постоянно меняются внутренние интерфейсы, значит меняются сигнатуры методов, значит ломаются тесты и их постоянно нужно поддерживать. Где в таком случае помощь от юнит-тестов?
vdem
Я отдельные модули по одному пишу. И в процессе покрываю тестами (это конечно не best practices, когда сначала пишут тесты, а потом код). Да, часть времени уходит на переписывание и тестов тоже, но дальше, когда модуль уже более-менее готов и уже может работать с другими (которые я начинаю писать, когда предыдущий почти оформился). И вот здесь тесты начинают очень помогать, так как теперь уже приходится вносить небольшие изменения в уже почти готовый код.
P.S. Это я рассказываю, как я над своим собственным проектом работаю. А заказчики как правило на тестах экономят. Но попадаются и такие, для которых тесты чуть ли не важнее кода.
Guzergus
Почему же? Есть целая методология под это — Test Driven Development.
Приведите, пожалуйста, парочку примеров.
Вот, скажем, стандартный пример из моей практики: приходит ХТТП реквест на регистрацию, надо сделать следующие действия (happy path):
1. Сходить в базу проверить, нет ли пользователя.
2. Создать пользователя в базе
3. Закинуть в message bus сообщение, что новый пользователь был создан
4. Ответить 200 клиенту
Предположим, мы вынесли эту логику на некий бизнес-слой, т.е. у нас есть функция SignUpUser, которая внутри вот это всё делает. Что и как мы будем тестить?
vdem
1. Сформировать HTTP-запрос
2. Отправить в SignUpUser
3. Проверить что у нас в базе появилась запись (для тестов можно и тестовую базу иметь (имхо лучше так, я лично для своего проекта использую sqlite), или замокать класс для доступа к БД)
4. Проверить что там в message bus (надеюсь Вы интерфейсы используете, или просто хардкодите какую-то реализацию?)
5. Проверить ответ
P.S. А дальше извините, у меня работа а я и так уже три часа тут торчу.
Guzergus
Разумеется. Если будет время и желание, я бы с удовольствием обсудил это подробнее, т.к. тема лёгких и полезных юнит тестов очень интересна, особенно в сравнении чистых функций и алгоритмов против типичного энтерпрайза.
onets
То, что вы описали — это не юнит-тест. О чем в статье и говорится:
VolCh
Какой-то
UserServiceс методомSignUpUser(UserRegistrationData userData)получает в зависимостиIUserRepositoryиIMessageBus, делает простые вещи типа:Два мока: MemoryUserRepo и MemoryMessageBus
Два основных теста:
Это покрывает именно бизнес-логику.
Guzergus
Спасибо. Именно такой вариант я наблюдал и практиковал у себя.
Что заметил из интересного:
Как итог, я предпочитаю такие тесты в принципе не писать. Оценить импакт с научной точки зрения сложно, но субъективно особой пользы я от них не видел.
Что меня очень интересует, это то, можно ли с минимальными усилиями описать спецификацию «мы делаем Б и В (publish, add) только если условие А истинно, в противном случае возвращаем ошибку». То есть, вместо того, чтобы императивно проверять, что и когда вызывается, выразить правила декларативно с гарантией того, что они не нарушатся разработчиком случайно.
Из того, что встречал — вместо непосредственно выполнения этих действий вернуть структуру, описывающую, что и как делать, наподобие AST:
blog.ploeh.dk/2017/07/31/combining-free-monads-in-f
Правда, и ASТ также придётся валидировать на корректность тестами.
Вопрос того, насколько с этим удобно работать конкретно в .NET на C# для меня пока открыт.
VolCh
Решается созданием InMemoryUserRepository — полноценной реализации IUserRepository в памяти. Проверяем не вызвался ли метод add, а появился ли пользователь в "базе" после вызова сервиса. Естественно InMemoryUserRepository покрываем тестами как какой-нибудь LinqUserRepository.
Вот это в целом я считаю излишним для юнит или функционального тестирования.
Такие случаи бывают когда сложные условия, циклы.
Очень похоже на формальную верификацию, так что вряд ли с минимальными усилиями получится. С другой стороны, на каком-нибудь gherkin в секции given можно написать что-то вроде "user with email test@example.com is(n't) registered", но нужно будет написать хэндлер для этого паттерна, приводящий систему в нужное состояние.
Guzergus
Да, такое делали, в случае .NET просто через EF InMemory. Хороший подход и, в целом, более правильный, на мой взгляд.
Были куски логики посложнее, но там по итогу всё переписывалось на легковесную state machine и уже она тестилась. Традиционное «закинем моки и проверим вызовы» показалось не оптимальным.
Как пример: в зависимости от того, обращался пользователь ранее к сервису или нет, надо было вести себя по-разному. Сам вызов метода на получение информации о предыдущих обращениях не тестили, а вот логику в виде условной функции (currentState, userRequest) -> newState покрыли на ура. Пока что коллегам нравится.
Вот, у меня такие же мысли. Звучит хорошо, но на практике не так легко.
К сожалению, не работал с gherkin и вообще BDD не щупал на реальных проектах. Не исключаю, что в итоге оно может оказаться ещё более затратным, чем «тупой» тест с моками.
0xd34df00d
Оо, стейтмашины вместе с условиями типа «сюда может залезать только аутентифицированный юзер» — это ж канонический пример для легковесной верификации в завтипизированных языках. А если вам, например, нужно гарантировать, что юзер что-то там сделает ровно один раз (привет линейные типы), то это вообще прям одно удовольствие.
0xd34df00d
Проще всего это выразить добавлением в publish и add аргумента, требующего доказательство, что A истинно (а это доказательство произвести легко — достаточно на самом деле проверить A).
А вот это интереснее. Тут уже есть варианты, в зависимости от вашего стиля и философской школы, так сказать. ИМХО один из стандартных вариантов — набросать параметризуемый GADT тип-результат, вроде
и использовать его как
HackerDelphi
Я недавно для себя открыл SpecFlow очень даже интересная вещь- как раз-таки тестирование по спецификациям.
Artem_7
Мы бы каждый слой покрывали тестами отдельно. У вас 4 слоя:
1. Контроллер
2. Бизнес-слой
3. Слой работы с БД
4. Слой работы с очередью сообщений.
Контроллер работает только с бизнес-слоем (вызывает метод SignUpUser). Мокаем бизнес-слой. Тесты на контроллер проверяют только логику контроллера: аутентификацию, валидацию входящего DTO и поведение (реакцию контроллера) на разные варианты ответа бизнес-слоя (happy path, exception и т.п.)
Бизнес-слой работает со слоем БД и слоем очереди. Мокаем и то и другое и проверяем реакцию бизнес-слоя на различные варианты отклика от тех. слоев.
Слой работы с БД уже можно проверить на in-memory db. У вас две функции (поиск и создание пользователя), на каждую пишем свои тесты со своими данными.
Слой работы с очередью — по вкусу. Там явно будут вызовы функций какого-то фреймворка. Мокаем их и проверяем реакцию на описанные в доке исключения + happy path/
anonymous
У Вас здесь только 1 тест — проверить наличие пользователя в БД.
Все остальное — действия, согласно описания, не содержащие логику. Они не требуют юнит тестов. Для них достаточно простых интеграционных тестов.
Мы же не хотим тестировать работу message queue? Нам достаточно на уровне интеграционных/automation/API тестов проверить happy path. Более детально проверит automation, который должен покрыть всю логику приложения, согласно ТЗ.
ImLoaD
Соглашусь, и добавлю что иногда написание теста перед написанием функции само по себе облегчает жизнь
vdem
Я комбинирую оба подхода. Когда я уже точно знаю, что должна делать какая-нибудь функция или метод, я скорее сначала напишу пару тестов прежде чем писать реализацию.
0xd34df00d
А вот мой опыт уже не согласится с вашим опытом.
Я юнит-тесты не пишу (по крайней мере, если считать юнитами отдельные функции, например), и полёт нормальный. Вместо этого пишу интеграционные тесты на то, что вся система целиком работает нормально. При этом очень помогают типы — почти всегда если я делаю относительно тупой рефакторинг, не меняющий «бизнес-логику», то сразу после того, как типы сошлись, интеграционные тесты зелёные.
Как пример — очередной транспилятор, который я сейчас ваяю, и тесты на него. Я начал с парсера типов входного языка (там не очень тривиальный язык), и просто начал писать тесты на парсинг входных выражений языка в порядке возрастания сложности этих самых выражений, при этом не тестируя отдельные функции парсера. Как только парсер написан, я начал писать транспиляцию типов и тесты на парсер + транспайлер, не тестируя сам транспайлер в отдельности. Как только это было написано, я начал писать парсер термов (и тесты на парсер типов + парсер термов), потом — тайпчекер (и тесты на парсер типов + парсер термов + тайпчекер), потом — транспайлер всего этого вместе (и тесты на всё вместе).
В идеале, конечно, когда я пойму, что мне надо от языка, я сформулирую всякие нужные утверждения (например) и докажу их формально в каком-нибудь коке или идрисе. Тогда все эти тесты вообще можно будет выкинуть, по большому счёту.
defuz
0xd34df00d
Ну я же там всё с нуля делал, вплоть до своих натуральных чисел и операций на них :]
nin-jin
Судя по описанию у вас как раз получается фрактальное тестирование: https://habr.com/ru/post/510824/
0xd34df00d
Да, с одной стороны, похоже. С другой стороны, там говорится об «уровне ниже», а я бы не сказал, что уровень парсера ниже уровня тайпчекера или кодогенератора, скажем. ИМХО это равноправные уровни, просто в общем пайплайне системы парсер идёт перед тайпчекером, и проще начинать с него (да и термы для тайпчекера проще писать естественным синтаксисом, а не выписывать их представление).
nin-jin
Банально, чтобы написать тесты для тайпчекера, нужно подготовить AST, а самый удобный способ это сделать — написать исходный код, который уже распарсить в AST. И хоть сам тайпчекер не зависит от парсера, его тесты очень даже могут зависеть.
0xd34df00d
Да! И именно поэтому я сначала пишу парсер, чтобы не писать AST руками.