

Уже более двух лет data build tool активно используется в компании Wheely для управления Хранилищем Данных. За это время накоплен немалый опыт, мы на тернистом пути проб и ошибок к совершенству в Analytics Engineering.
Несмотря на то, что в русскоязычном сегменте уже есть несколько публикаций, посвященных применению dbt, всё ещё нельзя говорить о широкой популярности и интересе, которые продукт стремительно обретает на Западе.
Поэтому сегодня я предлагаю вам экскурсию по Хранилищу Данных Wheely. В формат публикации я попытался уложить самые яркие моменты и впечатления от использования dbt, снабдив реальными примерами, практиками и опытом. Добро пожаловать под кат.
Структура превыше всего
Измерять сложность Хранилища Данных в количестве гигабайт сегодня - дурной тон
Налить кучу тяжело интерпретируемых данных без метаинформации (читай мусора) не составит большого труда. Гораздо сложнее из этих данных получить что-то осмысленное. То, на что с уверенностью могут опираться business stakeholders, принимая решения. То, что регулярно измеряется на предмет качества и актуальности. Наконец, то, что соответствует принципам Keep it simple (KISS) и Don’t repeat yourself (DRY).
Первостепенным элементом я считаю прозрачность структуры Хранилища Данных. Чаще всего DWH выстраивается согласно многослойной логике, где каждому этапу соответствует набор преобразований, детали реализации которого скрыты для последующих слоев (элемент абстракции).

Зеленым цветом – слой источников данных sources. Это реплики структур и таблиц из исходных систем, которые поддерживаются ELT-сервисом. Данные синхронизируются 1:1 с источником, без каких-либо преобразований. Опциональный слой flatten позволяет вложенные иерархические структуры (JSON) превратить в плоские таблицы.
Слой staging предназначен для простых преобразований: переименование полей, преобразование типов, расчет новых колонок с помощью конструкции case. На этом этапе мы готовим почву для дальнейших преобразований, приводим всё к единому виду и неймингу.
Intermediate или промежуточный слой отвечает за формирование предварительных таблиц и агрегатов, где происходит обогащение данных. Для ряда бизнес-областей мы не используем этот слой, для других логика может насчитывать до 5-10 взаимосвязанных моделей.
Кульминацией являются data marts или Витрины Данных, которые используются Data Scientists / Business Users / BI tools. Слой, в свою очередь, делится на:
dimensions: пользователи, компании, машины, водители, календарь
facts: поездки, транзакции, сеансы, продвижения, коммуникации
looker: материализованные представления и витрины, оптимизированные под чтение из BI-системы
Число 120 из заголовка публикации относится только к витринам данных:
Running with dbt=0.19.0
Found 273 models, 493 tests, 6 snapshots, 4 analyses, 532 macros, 7 operations, 8 seed files, 81 sources, 0 exposuresНа текущий момент в проекте:
273 модели во всех перечисленных слоях
493 теста на эти модели, включая not null, unique, foreign key, accepted values
6 снапшотов для ведения истории SCD (slowly changing dimensions)
532 макроса (большая часть из которых импортирована из сторонних модулей)
7 operations включая vacuum + analyze
81 источник данных
Помимо разбиения на логические слои, Хранилище можно нарезать по бизнес-областям. В случае необходимости есть возможность пересчитать или протестировать витрины, относящиеся к вертикалям Marketing / Supply / Growth / B2B. Например, в случае late arriving data или ручных корректировках маппингов/справочников.
Осуществляется это за счет присвоения моделям и витринам тегов, а также за счет богатых возможностей синтаксиса выбора моделей. Запустить расчет всех витрин вертикали Marketing и их вышестоящие зависимости:
dbt run -m +tag:marketingЭтот же принцип лежит в основе организации кодой базы. Все скрипты объединены в директории с общей логикой и понятными наименованиями. Сложно потеряться даже при огромном количестве моделей и витрин:
Иерархия проекта dbt
.
|____staging
| |____webhook
| |____receipt_prod
| |____core
| |____wheely_prod
| |____flights_prod
| |____online_hours_prod
| |____external
| |____financial_service
|____marts
| |____looker
| |____dim
| |____snapshots
| |____facts
|____flatten
| |____webhook
| |____receipt_prod
| |____wheely_prod
| |____communication_prod
|____audit
|____sources
|____aux
| |____dq
| | |____marts
| | |____external
|____intermediateОптимизация физической модели
Логическое разделение на слои и области - это замечательно. Но не менее важно и то, как эта логика ложится на конкретную СУБД. В случае Wheely это Amazon Redshift.
Подход с декомпозицией позволит разбить логику на понятные части, которые можно рефакторить по отдельности. Одновременно это помогает оптимизатору запросов подобрать лучший план выполнения. По такому принципу реализована одна из центральных витрин – journeys (поездки).
")
На этапе обогащения данных важна скорость склейки таблиц (join performance), поэтому данные сегментированы и отсортированы в одинаковом ключе, начиная с sources. Это позволит использовать самый быстрый вид соединения - sort merge join:
Конфигурация для оптимального соединения – sort merge join
{{
config(
materialized='table',
unique_key='request_id',
dist="request_id",
sort="request_id"
)
}}Витрина же хранится отсортированной по самым популярным колонкам доступа: city, country, completed timestamp, service group. В случае правильного подбора колонок Interleaved key позволяет значительно оптимизировать I/O и ускорить отрисовку графиков в BI-системах.
Конфигурация для быстрого чтения витрины – interleaved sortkey
{{
config(
materialized='table',
unique_key='request_id',
dist="request_id",
sort_type='interleaved',
sort=["completed_ts_loc"
, "city"
, "country"
, "service_group"
, "is_airport"
, "is_wheely_journey"]
)
}}При этом часть моделей есть смысл материализовать в виде views (виртуальных таблиц), не занимающих дисковое пространство в СУБД. Так, слой staging, не содержащий сложных преобразований, конфигурируется на создание в виде представлений на уровне проекта:
staging:
+materialized: view
+schema: staging
+tags: ["staging"]Другой интересный пример – результаты проверки качества данных. Выбранный тип материализации – ephemeral, т.е. на уровне СУБД не будет создано ни таблицы, ни представления. При каждом обращении к такой модели будет выполнен лишь запрос. Результат такого запроса является слагаемым в суммарной таблице, содержащей метрики всех проверяемых объектов.
В свою очередь большие таблицы фактов имеет смысл наполнять инкрементально. Особенно при условии того, что факт, случившийся однажды, больше не меняет своих характеристик. Таким образом мы процессим только изменения (delta) – новые факты, произошедшие после последнего обновления витрины. Обратите внимание на условие where:
Пример инкрементального наполнения витрины
{{
config(
materialized='incremental',
sort='metadata_timestamp',
dist='fine_id',
unique_key='id'
)
}}
with fines as (
select
fine_id
, city_id
, amount
, details
, metadata_timestamp
, created_ts_utc
, updated_ts_utc
, created_dt_utc
from {{ ref('stg_fines') }}
where true
-- filter fines arrived since last processed time
{% if is_incremental() -%}
and metadata_timestamp > (select max(metadata_timestamp) from {{ this }})
{%- endif %}
),
...Кстати, о принципах MPP и о том, как выжать максимум из аналитических СУБД я рассказываю на курсах Data Engineer и Data Warehouse Analyst (скоро первый запуск!).
SQL + Jinja = Flexibility
Высокоуровневый декларативный язык SQL прекрасен сам по себе, но вкупе с движком шаблонизации Jinja он способен творить чудеса.
Любой код, который вы используете с dbt проходит этапы compile & run. На этапе компиляции интерпретируются все шаблонизированные выражения и переменные. На этапе запуска код оборачивается в конструкцию CREATE в зависимости от выбранного типа материализации и фишек используемой СУБД: clustered by / distributed by / sorted by. Рассмотрим пример:
Model code:
{{
config(
materialized='table',
dist="fine_id",
sort="created_ts_utc"
)
}}
with details as (
select
{{
dbt_utils.star(from=ref('fine_details_flatten'),
except=["fine_amount", "metadata_timestamp", "generated_number"]
)
}}
from {{ ref('fine_details_flatten') }}
where fine_amount > 0
)
select * from detailsCompiled code:
with details as (
select
"id",
"fine_id",
"city_id",
"amount",
"description",
"created_ts_utc",
"updated_ts_utc",
"created_dt_utc"
from "master"."dbt_test_akozyr"."fine_details_flatten"
where fine_amount > 0
)
select * from detailsRun code:
create table
"master"."dbt_test_akozyr"."f_chauffeurs_fines"
diststyle key distkey (fine_id)
compound sortkey(created_ts_utc)
as (
with details as (
select
"id",
"fine_id",
"city_id",
"amount",
"description",
"created_ts_utc",
"updated_ts_utc",
"created_dt_utc"
from "master"."dbt_test_akozyr"."fine_details_flatten"
where fine_amount > 0
)
select * from details
);Ключевым моментом является тот факт, что пишете вы только лаконичный шаблонизированный код, а остальным занимается движок dbt. Написание boilerplate code сведено к минимуму. Фокус инженера или аналитика остается преимущественно на реализуемой логике.
Во-вторых, как происходит выстраивание цепочки связей и очередности создания витрин, продемонстрированные на картинках выше? Внимательный читатель уже заметил, что в рамках написания кода при ссылках на другие модели нет хардкода, но есть конструкция {{ ref('fine_details_flatten') }}– ссылка на наименование другой модели. Она и позволяет распарсить весь проект и построить граф связей и зависимостей. Так что это тоже делается абсолютно прозрачным и органичным способом.
С помощью шаблонизации Jinja в проекте Wheely мы гибко управляем схемами данных и разделением сред dev / test / prod. В зависимости от метаданных подключения к СУБД будет выбрана схема и период исторических данных. Продакшн модели создаются в целевых схемах под технической учетной записью. Аналитики же ведут разработку каждый в своей личной песочнице, ограниченной объемом данных в 3-е последних суток. Это реализуется с помощью макроса:
Макрос управления схемами для подключений:
{% macro generate_schema_name_for_env(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if target.name == 'prod' and custom_schema_name is not none -%}
{{ custom_schema_name | trim }}
{%- else -%}
{{ default_schema }}
{%- endif -%}
{%- endmacro %}Еще одним важным преимуществом является самодокументируемый код. Иными словами, из репозитория проекта автоматически можно собрать статический сайт с документацией: перечень слоев, моделей, атрибутный состав, метаинформацию о таблицах в СУБД и даже визуализировать граф зависимостей (да-да, картинки выше именно оттуда).

Не повторяйся – лучше подготовь макрос
Однотипный код, повторяющиеся обращения и действия, зачастую реализуемые по принципу copy-paste нередко являются причиной ошибок и багов. В Wheely мы придерживаемся принципа Do not repeat yourself и любой сколько-нибудь похожий код шаблонизируем в макрос с параметрами. Писать и поддерживать такой код становится сплошным удовольствием.
Простой пример с конвертацией валют:
-- currency conversion macro
{% macro convert_currency(convert_column, currency_code_column) -%}
( {{ convert_column }} * aed )::decimal(18,4) as {{ convert_column }}_aed
, ( {{ convert_column }} * eur )::decimal(18,4) as {{ convert_column }}_eur
, ( {{ convert_column }} * gbp )::decimal(18,4) as {{ convert_column }}_gbp
, ( {{ convert_column }} * rub )::decimal(18,4) as {{ convert_column }}_rub
, ( {{ convert_column }} * usd )::decimal(18,4) as {{ convert_column }}_usd
{%- endmacro %}Вызов макроса из модели:
select
...
-- price_details
, r.currency
, {{ convert_currency('price', 'currency') }}
, {{ convert_currency('transfer_min_price', 'currency') }}
, {{ convert_currency('discount', 'currency') }}
, {{ convert_currency('insurance', 'currency') }}
, {{ convert_currency('tips', 'currency') }}
, {{ convert_currency('parking', 'currency') }}
, {{ convert_currency('toll_road', 'currency') }}
, {{ convert_currency('pickup_charge', 'currency') }}
, {{ convert_currency('cancel_fee', 'currency') }}
, {{ convert_currency('net_bookings', 'currency') }}
, {{ convert_currency('gross_revenue', 'currency') }}
, {{ convert_currency('service_charge', 'currency') }}
...
from {{ ref('requests_joined') }} r По большому счету, макрос это просто вызов функции с передачей аргументов, на уже знакомом вам диалекте Jinja. Результатом работы макроса является готовый к исполнению SQL-скрипт. Макрос для кросс-сверки значений в колонках:
Сравнить значения двух колонок
-- compare two columns
{% macro dq_compare_columns(src_column, trg_column, is_numeric=false) -%}
{%- if is_numeric == true -%}
{%- set src_column = 'round(' + src_column + ', 2)' -%}
{%- set trg_column = 'round(' + trg_column + ', 2)' -%}
{%- endif -%}
CASE
WHEN {{ src_column }} = {{ trg_column }} THEN 'match'
WHEN {{ src_column }} IS NULL AND {{ trg_column }} IS NULL THEN 'both null'
WHEN {{ src_column }} IS NULL THEN 'missing in source'
WHEN {{ trg_column }} IS NULL THEN 'missing in target'
WHEN {{ src_column }} <> {{ trg_column }} THEN 'mismatch'
ELSE 'unknown'
END
{%- endmacro %}В макрос можно запросто записать даже создание UDF-функций:
Создать UDF
-- cast epoch as human-readable timestamp
{% macro create_udf() -%}
{% set sql %}
CREATE OR REPLACE FUNCTION {{ target.schema }}.f_bitwise_to_delimited(bitwise_column BIGINT, bits_in_column INT)
RETURNS VARCHAR(512)
STABLE
AS $$
# Convert column to binary, strip "0b" prefix, pad out with zeroes
if bitwise_column is not None:
b = bin(bitwise_column)[2:].zfill(bits_in_column)[:bits_in_column+1]
return b
else:
None
$$ LANGUAGE plpythonu
;
CREATE OR REPLACE FUNCTION {{ target.schema }}.f_decode_access_flags(access_flags INT, deleted_at TIMESTAMP)
RETURNS VARCHAR(128)
STABLE
AS $$
SELECT nvl(
DECODE($2, null, null, 'deleted')
, DECODE(LEN(analytics.f_bitwise_to_delimited($1, 7))::INT, 7, null, 'unknown')
, DECODE(analytics.f_bitwise_to_delimited($1, 7)::INT, 0, 'active', null)
, DECODE(SUBSTRING(analytics.f_bitwise_to_delimited($1, 7), 1, 1), 1, 'end_of_life', null)
, DECODE(SUBSTRING(analytics.f_bitwise_to_delimited($1, 7), 7, 1), 1, 'pending', null)
, DECODE(SUBSTRING(analytics.f_bitwise_to_delimited($1, 7), 6, 1), 1, 'rejected', null)
, DECODE(SUBSTRING(analytics.f_bitwise_to_delimited($1, 7), 5, 1), 1, 'blocked', null)
, DECODE(SUBSTRING(analytics.f_bitwise_to_delimited($1, 7), 4, 1), 1, 'expired_docs', null)
, DECODE(SUBSTRING(analytics.f_bitwise_to_delimited($1, 7), 3, 1), 1, 'partner_blocked', null)
, DECODE(SUBSTRING(analytics.f_bitwise_to_delimited($1, 7), 2, 1), 1, 'new_partner', null)
)
$$ LANGUAGE SQL
;
{% endset %}
{% set table = run_query(sql) %}
{%- endmacro %}Параметризовать можно и довольно сложные вещи, такие как работа с nested structures (иерархическими структурами) и выгрузка во внешние таблицы (external tables) в S3 в формате parquet. Эти примеры вполне достойны отдельных публикаций.
Не изобретай велосипед – импортируй модули
Модуль или package - это набор макросов, моделей, тестов, который можно импортировать в свой проект в виде готовой к использованию библиотеки. На портале dbt hub есть неплохая подборка модулей на любой вкус, и, что самое главное, их список постоянно пополняется.

С помощью модуля логирования и добавления 2 простых hooks на каждый запуск dbt у меня как на ладони появляется статистическая информация о времени, продолжительности, флагах и параметрах развертывания. Я наглядно вижу модели анти-лидеры по потребляемым ресурсам (первые кандидаты на рефакторинг):
models:
+pre-hook: "{{ logging.log_model_start_event() }}"
+post-hook: "{{ logging.log_model_end_event() }}"
Измерение календаря собирается в одну строку, при этом набор колонок поражает:
{{ dbt_date.get_date_dimension('2012-01-01', '2025-12-31') }}
С помощью модуля dbt_external_tables я уже выстраиваю полноценный Lakehouse, обращаясь из Хранилища к данным, расположенным в файловом хранилище S3. К примеру, самые свежие курсы валют, получаемые через API Open Exchange Rates в формате JSON:
External data stored in S3 accessed vith Redshift Spectrum
- name: external
schema: spectrum
tags: ["spectrum"]
description: "External data stored in S3 accessed vith Redshift Spectrum"
tables:
- name: currencies_oxr
description: "Currency Exchange Rates fetched from OXR API https://openexchangerates.org"
freshness:
error_after: {count: 15, period: hour}
loaded_at_field: timestamp 'epoch' + "timestamp" * interval '1 second'
external:
location: "s3://data-analytics.wheely.com/dwh/currencies/"
row_format: "serde 'org.openx.data.jsonserde.JsonSerDe'"
columns:
- name: timestamp
data_type: bigint
- name: base
data_type: varchar(3)
- name: rates
data_type: struct<aed:float8, eur:float8, gbp:float8, rub:float8, usd:float8>Ну и, конечно, ночью по расписанию работает VACUUM + ANALYZE, ведь Redshift это форк PostgreSQL. Дефрагментация, сортировка данных в таблицах, сбор статистик. Иначе говоря поддержание кластера в тонусе, пока dba спит.
dbt run-operation redshift_maintenance --args '{include_schemas: ["staging", "flatten", "intermediate", "analytics", "meta", "snapshots", "ad_hoc"]}'
Running in production: используем dbt Cloud в Wheely
dbt Cloud это платный сервис для управления проектами, основанными на движке dbt. За небольшие деньги команда получает возможность создавать окружения, конфигурировать джобы и таски, устанавливать расписание запусков, и даже полноценную IDE (среду разработки!) в браузере.
Прежде всего речь идет об удобстве использования: приятный и понятный визуальный интерфейс, простота поиска и ориентирования, акцентирование ключевой информации при разборе ошибок и чтении логов:

Во-вторых, это гибкие настройки условий запуска джобов. Начиная от простых условий с выбором дня недели и времени, продолжая кастомными cron-выражениями, и заканчивая триггером запуска через webhook. Например, именно через вебхук мы связываем в цепочку завершение выгрузок для кросс-сверки и начало расчета соответствующих витрин в Хранилище (kicked off from Airflow):
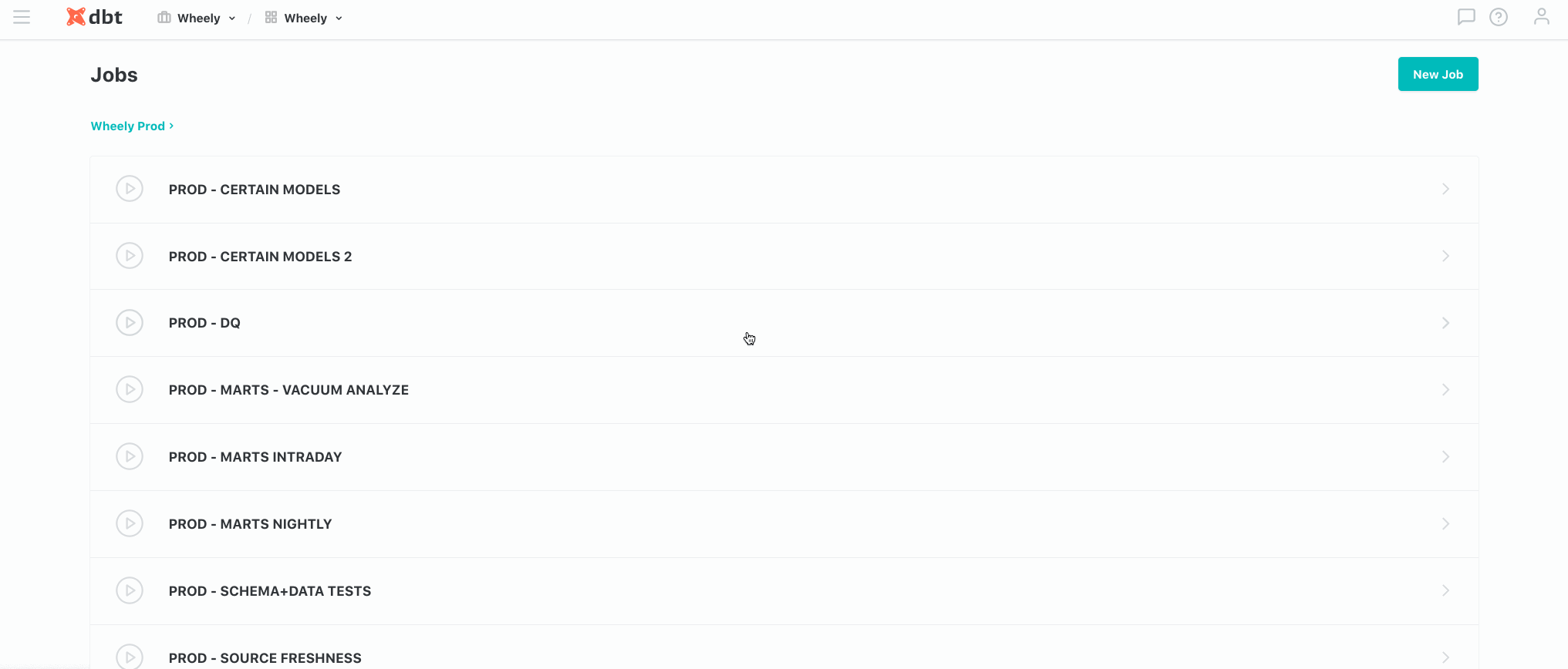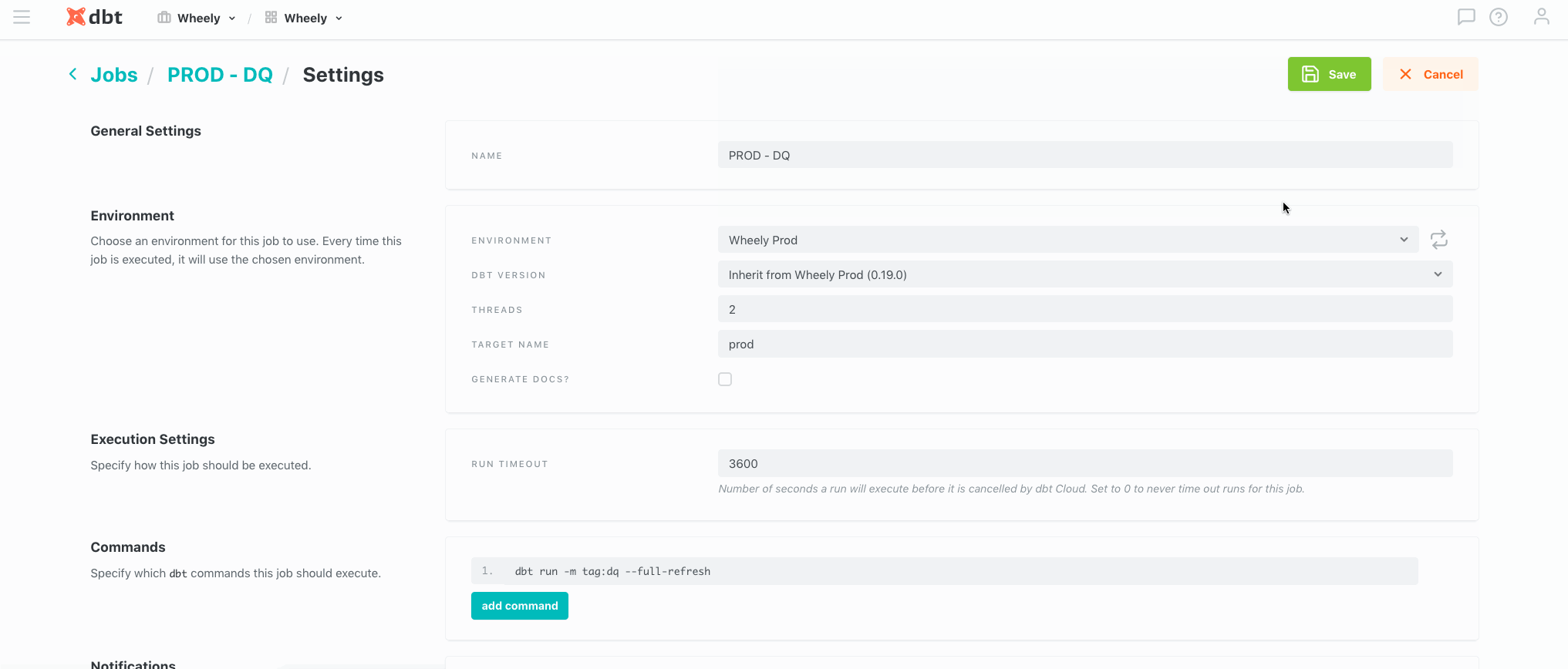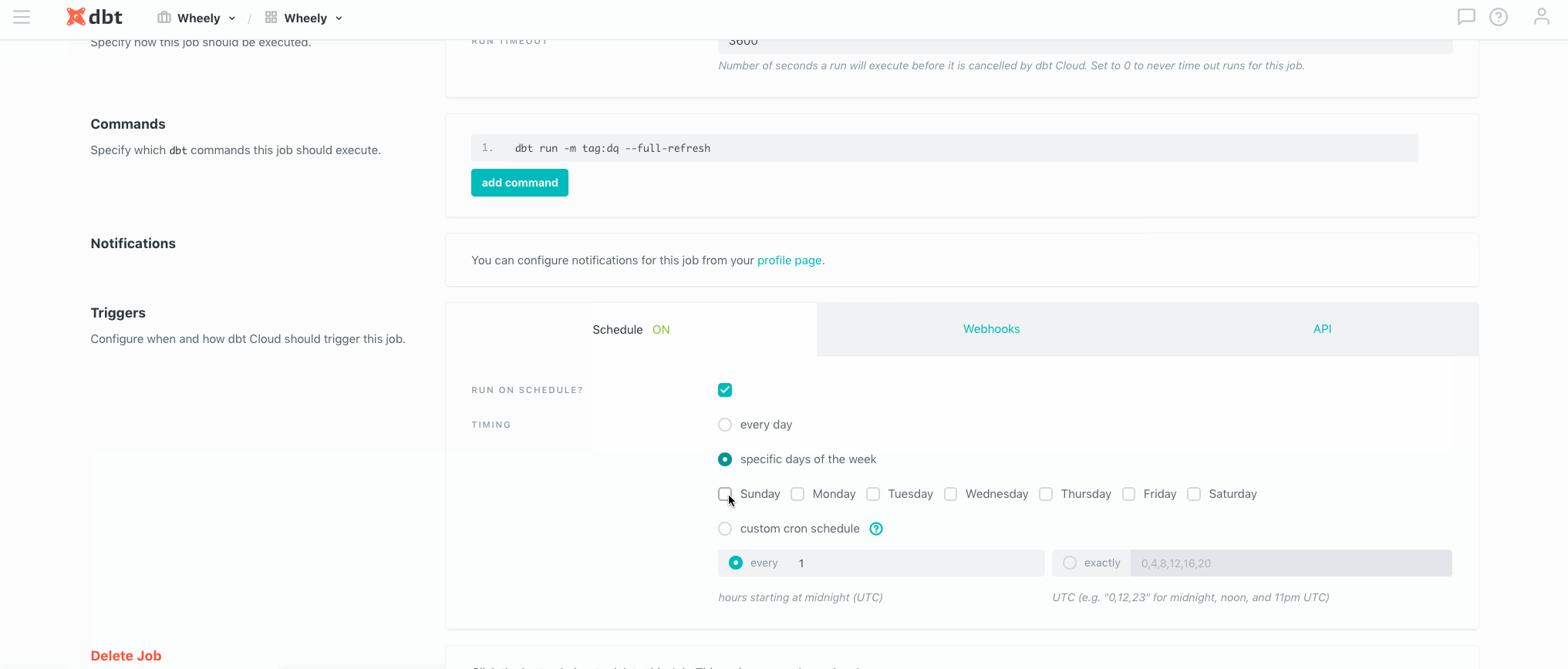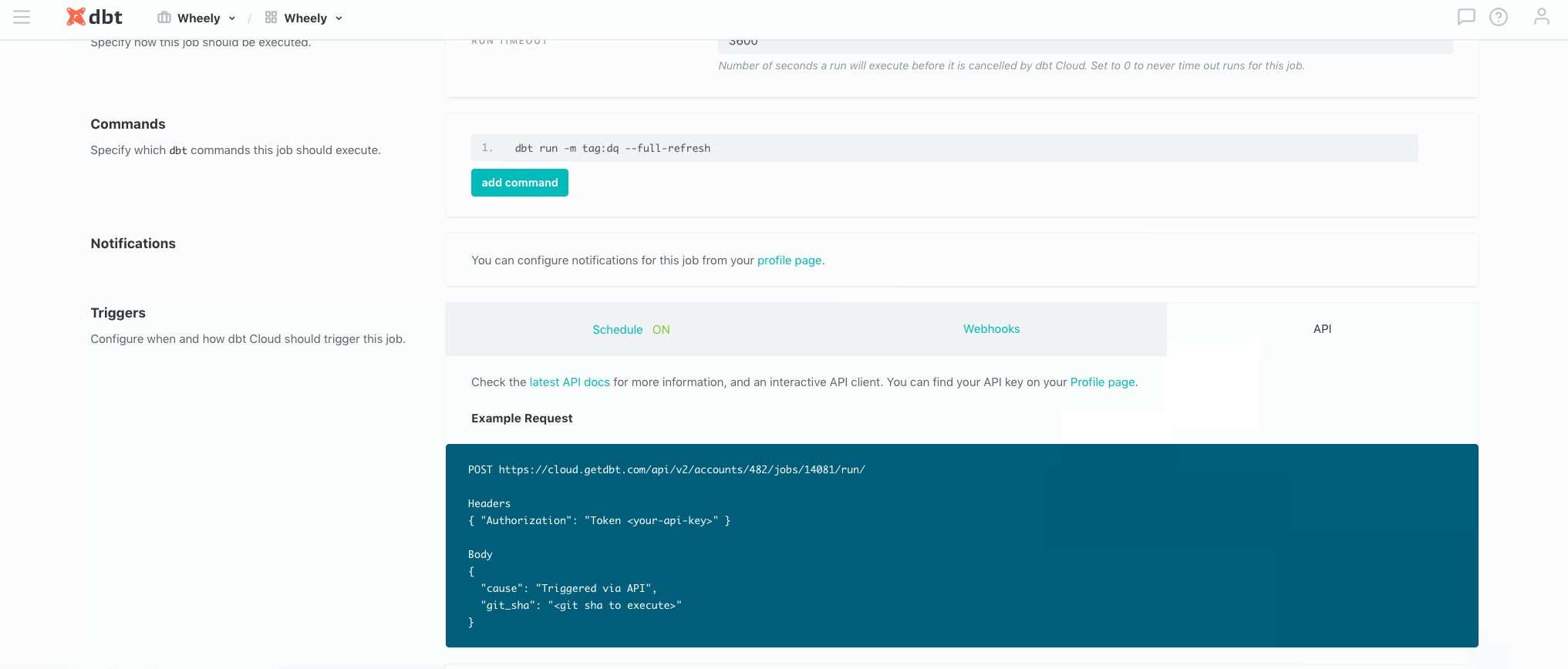
В третьих, это консолидация всех важных уведомлений одном месте. Для нашей команды это канал в Slack и любые проблемы связанные с Production-запусками. В режиме реального времени мы получаем все уведомления об инцидентах с деталями и ссылками на подробный лог.

Сам dbt является проектом с открытым исходным кодом, и использование продукта dbt Cloud представляется очень удобным, но не обязательным. В качестве альтернативных способов можно выбрать любой другой оркестратор: Airflow, Prefect, Dagster, и даже просто cron. В своем проекте Сквозная Аналитика я организую оркестрацию при помощи Github Actions. Выходит очень занятно.
Вместо заключения
В команде аналитики Wheely мы стремимся к тому, чтобы работа была наполнена смыслом и приносила удовлетворение и пользу, но не раздражение и негодование. Все перечисленные в публикации достоинства не могут не вызвать симпатию со стороны новых членов команды и значительно ускоряют процессы адаптации и onboarding.
Сегодня бизнес и команда активно растут. Доступен ряд интересных позиций: Head of Data Insights, Product Analyst. У тебя есть возможность узнать детали из первых уст и получить прямую рекомендацию.
Также время от времени я провожу вебинары и выступления, на которых подробнее рассказываю о своей работе и проектах. Следить за моими публикациями можно в телеграм-канале Technology Enthusiast – https://t.me/enthusiastech
Пишите, задавайте вопросы и, конечно, пробуйте dbt в своих проектах!
Apatic
Спасибо за статью.
У меня немного более верхнеуровневый вопрос, а как аналитики работают с хранилищем?
Я увидел, что у каждого своя песочница на три дня. А мне хочется вот прям сейчас посчитать данные на год назад, причем готовой продакшен витрины для этого нет, то как быть?
Или эта песочница только для каких-то регламентных моделей, которые будут крутиться на кроне, а запросы на SELECT можно делать к сырым данным за более долгий срок?
kzzzr Автор
Привет, спасибо за вопрос.
Всё верно подмечено.
3 дня это дефолтные настройки для ускорения разработки и экономии ресурсов. Каждое подключение конфигурируется «тегом». Сейчас их всего 3 для удобства: dev (для каждого члена команды), ci (он же тест), prod. У аналитиков по дефолту dev в настройках подключения под личной учеткой. Это реализовано в макросе:
Если есть цель построить витрины за бОльший период или оценить производительность – просто корректируется скомпилированный код вручную (убирается фильтр либо расширяется диапазон дат), запускается через dbeaver. Либо просто в локальной версии репо меняется значение переменной: