

Проверка знаний на собеседованиях — обычная практика. И мы сейчас не о глупых «Где вы видите себя через 5 лет?», а о нормальных вопросах по специальности. В этой статье мы собрали топ-20 вопросов, которые задают дата-сайентистам, чтобы проверить их уровень знаний. Все это реальные вопросы на реальных собеседованиях в российских компаниях. Но нас попросили не упоминать названия, чтобы не давать соискателям лишнего преимущества. Некоторые вопросы простые, другие — посложнее. Не будем затягивать, поехали.
1. В чём разница между контролируемым и неконтролируемым машинным обучением?
Контролируемое машинное обучение:
Использует известные и маркированные данные в качестве входных.
Имеет механизм обратной связи.
Наиболее часто используемые алгоритмы контролируемого обучения — деревья решений, логистическая регрессия и метод опорных векторов.
Неконтролируемое обучение:
Использует немаркированные данные в качестве входных.
Не имеет механизма обратной связи.
Наиболее часто используемые алгоритмы неконтролируемого обучения — кластеризация методом k-средних, иерархическая кластеризация и априорный алгоритм.
2. Перечислите этапы построения дерева решений
Взять весь набор входных данных.
Вычислить энтропию целевой переменной, а также прогнозные атрибуты.
Рассчитать прирост информации по всем атрибутам (информацию о том, как отсортировать разные объекты друг от друга).
Выбрать атрибут с наибольшим объёмом информации в качестве корневого узла.
Повторить ту же процедуру для каждой ветви, пока узел решения каждой ветви не будет завершён.
3. Что такое проблемы взрывающегося и затухающего градиента?
Градиент — это вектор частных производных функции потерь по весам нейросети. Он показывает вектор наибольшего роста функции для всех весов.
В процессе обучения при обратном распространении ошибки при прохождении через слои нейронной сети в элементах градиента могут накапливаться большие значения, что будет приводить к сильным изменениям весов. Это дестабилизирует алгоритм нейросети. Эта проблема называется взрывающимся градиентом.
Аналогичная обратная проблема, в которой при прохождении ошибки через слои градиент становится меньше, называется затухающим градиентом.
Чем больше количество слоев нейросети, тем выше риски данных ошибок. Для решения сложных задач с помощью нейронных сетей необходимо уметь определять и устранять её.

4. Как рассчитать точность прогноза, используя матрицу ошибок?
В матрице ошибок есть значения для общего количества данных, истинных значений и прогнозируемых значений.

Формула точности:
Точность = (истинно положительные + истинно отрицательные) / общее количество наблюдений.
Предположим, что истинно положительных значений у нас 2981, истинно отрицательных — 110, а всего — 3311. Используя формулу, находим, что точность прогноза составляет 93,36 %.
5. Как работает ROC-кривая?
ROC-кривая — это графическое изображение контраста между показателями истинно положительных и ложноположительных результатов при различных пороговых значениях.
Если считать TPR и FPR для фиксированного порога ? є [0,1], то их можно представить в виде функций от аргумента ?:
TPR = TPR(?), FPR = FPR(?). При этом обе функции монотонно возрастают от 0 до 1, а значит, определена функция:
ROC(x) = TPR(FPR-1(x)), x є [0,1]
ROC-кривая — это график функции.

Как правило, у хорошего классификатора кривая лежит по большей части либо целиком выше прямой y=x. Это связано с тем что при хорошей классификации надо получать максимальный TPR при минимальном FPR.
6. Объясните алгоритм машинного обучения SVM
SVM, или метод опорных векторов, — это набор алгоритмов обучения с учителем, который используется для классификации и регрессионного анализа.
Его основная идея — построение гиперплоскости, которая разделяет объекты выборки максимально эффективным способом. Сделать это можно с помощью алгоритма линейной классификации.

7. Что такое ансамбль методов?
Ансамбль методов — это использование нескольких алгоритмов с целью получения более высокой эффективности прогнозирования, чем можно было бы получить, используя эти алгоритмы отдельно.
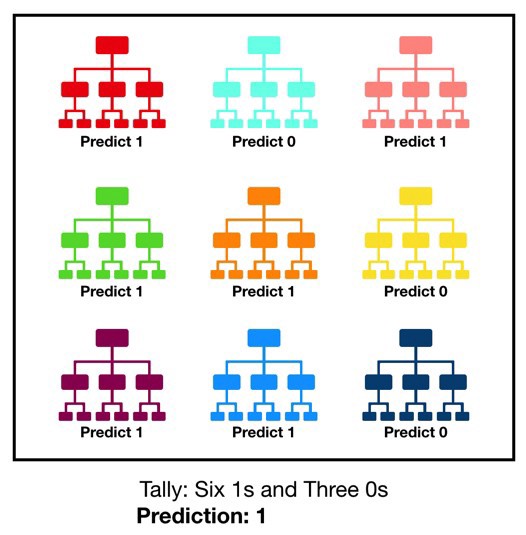
8. Что такое Random Forest?
Random Forest, или случайный лес, — это один из немногих универсальных алгоритмов обучения, который способен выполнять задачи классификации, регрессии и кластеризации.
Случайный лес состоит из большого количества отдельных деревьев решений, которые по сути являются ансамблем методов. Каждое дерево в случайном лесу возвращает прогноз класса, и класс с наибольшим количеством голосов становится прогнозом леса.
9. Какой метод перекрёстной проверки вы бы использовали для набора данных временных рядов?
Нормальная k-кратная процедура перекрёстной проверки может быть проблематичной для временных рядов.
Наиболее результативный подход для временных рядов — это прямая цепочка, где процедура выглядит примерно так:
сгиб 1: тренировка [1], тест [2];
сгиб 2: тренировка [1 2], тест [3];
сгиб 3: тренировка [1 2 3], тест [4];
сгиб 4: тренировка [1 2 3 4], тест [5];
сгиб 5: тренировка [1 2 3 4 5], тест [6].
Это более точно показывает ситуацию, где можно моделировать прошлые данные и прогнозировать прогнозные данные.
10. Что такое логистическая регрессия? Или приведите пример логистической регрессии.
Логистическая регрессия — это статистическая модель, которую используют для прогнозирования вероятности какого-либо события.
Например, нужно предсказать, победит конкретный политический лидер на выборах или нет.
В этом случае результат прогноза будет двоичным, то есть 0 или 1 (выигрыш/проигрыш). В качестве переменных-предикторов здесь будут: сумма денег, потраченных на предвыборную агитацию конкретного кандидата, количество времени, затраченного на агитацию, и так далее.
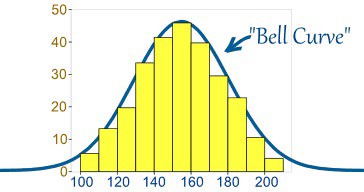
11. Что вы понимаете под термином «нормальное распределение»?
Нормальное распределение — одно из основных распределений вероятности.
Плотность нормального распределения выражается функцией Гаусса:

Где ? — математическое ожидание, ? — среднеквадратическое отклонение, ? ? — дисперсия, медиана и мода нормального распределения равны математическому ожиданию ?.
Примеры нормального распределения: погрешности измерений, отклонения при стрельбе, показатели живых популяций в природе.
12. Что такое глубокое обучение?
Глубокое обучение — совокупность большого количества методов машинного обучения, основанных на имитации работы человеческого мозга в процессе обработки данных и принятия решений.
По сути они основаны на обучении представлениям, а не специализированным алгоритмам под конкретные задачи. Из-за чего обучение нейронных сетей ведётся дольше, чем традиционное машинное обучение, но точность результатов получается выше.
13. В чём разница между машинным обучением и глубоким обучением?
Машинное обучение позволяет обучать компьютерную систему без её фактического программирования. А глубокое обучение — это подвид машинного обучения, который основан на аналогии нейронных сетей человеческого мозга. Это похоже на то, как наш мозг работает для решения проблем: чтобы найти ответ, он пропускает запросы через различные иерархии концепций и связанных вопросов.
14. Что такое рекуррентные нейронные сети (RNN)?
Рекуррентные нейронные сети — это вид нейросетей, в которых связи между элементами образуют направленную последовательность. Это позволяет обрабатывать серии событий во времени или последовательные пространственные цепочки.
Они используются преимущественно для задач, где нечто цельное состоит из ряда объектов, например при распознавании рукописного текста или речи.
15. Что такое обучение с подкреплением?
Обучение с подкреплением очень схоже по смыслу с обучением с учителем, но в роли учителя выступает среда, в которой система может выполнять какие-либо действия.
Обучение с подкреплением активно используется в задачах, где нужно выбрать лучший вариант среди многих или достичь сложной цели за множество ходов. К примеру, это могут быть шахматы или го, где нейросети дают только правила, а она совершенствует свои навыки с помощью игр с самой собой.
Машина пытается решить задачу, ошибается, учится на своих ошибках, совершенствуется, и так множество раз.

16. Объясните, что такое регуляризация и почему она полезна
Регуляризация в машинном обучении — метод добавления дополнительных ограничений к условию для того, чтобы предотвратить переобучение системы или решить некорректно поставленную задачу. Часто это ограничение представляет собой штраф за излишнюю сложность модели.
Прогнозы модели должны затем минимизировать функцию потерь, вычисленную на регуляризованном обучающем наборе.

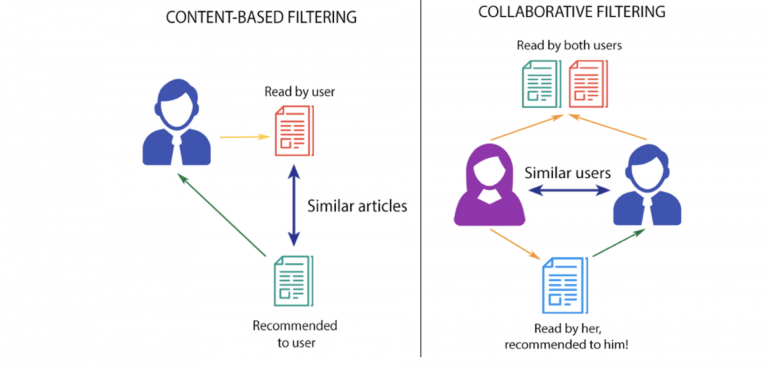
17. Что такое рекомендательные системы?
Подкласс систем фильтрации информации, что применяются для прогнозирования предпочтений или оценок, которые пользователь поставит продукту. Рекомендательные системы широко используются в фильмах, новостях, статьях, товарах, музыке и так далее.
18. Какова цель A/B-тестирования?
A/B-тестирование — это статистическая проверка гипотез для рандомизированных экспериментов с двумя переменными, A и B.
Его цель — обнаружение любых изменений на веб-странице, чтобы максимизировать или повысить результат стратегии.
19. Что такое закон больших чисел?
Это принцип теории вероятностей, который описывает результат выполнения одного и того же эксперимента множество раз.
При достаточно длительной серии экспериментов закон больших чисел гарантирует устойчивость средних значений от случайных событий. И среднее значение конечной выборки фиксированного распределения будет очень близко к математическому ожиданию выборки.
К примеру, при бросках шестигранного кубика. Чем больше бросков, тем больше среднее значение близится к математическому ожиданию 3,5.

20. Назовите несколько фреймворков для глубокого обучения
Pytorch.
TensorFlow.
Microsoft Cognitive Toolkit.
Keras.
Caffe.
Chainer.
Естественно, в этой выборке только теоретические вопросы, ведь практических задач (под реальные бизнес-кейсы компаний) просто бесконечное количество. Но всему этому мы учим на наших курсах по профессиям Data Scientist и Data Analyst, а карьерные консультанты помогают подготовиться к собеседованию. Про общую подготовку к собеседованию читайте здесь.

У нас еще много направлений для состоявшихся профи и новичков
ПРОФЕССИИ
КУРСЫ

deadmoroz14
Очень однобоко написано, вопросы про одно, ответы про другое. Да и такое ощущение, что статья является переводом medium-блогпоста, причём ещё не самого лучшего качества
Это называется «обучение с учителем» и «обучение без учителя». Нигде не встречал термина «неконтролируемое обучение». Это даже звучит как будто человек не понимает что он делает.Зависит от алгоритма. Дерево решений строится не обязательно по алгоритму ID3. Я могу взять CART и там не будет information gain. Могу вообще свой алгоритм придумать, и это тоже будет дерево решений.
Только нейросети? Почему опять сразу завал на конкретный алгоритм?
Что значит максимально эффективным? Как эффективность измеряется? «Сделать это можно с помощью алгоритма линейной классификации» не объясняет вообще ничего. А SVM что тогда? Нужен ещё один алгоритм?
Ни слова про margin, ничего про ядра. Красота просто.
Алгоритмов или моделей? Алгоритм построения моделей может быть один и тот же, а моделей, по нему построенных, несколько.
А описали бэггинг на деревьях)
Ответы немного противопоставлены друг другу. В одном говорится «совокупность большого количества методов машинного обучения» (как будто не только нейронные сети), в другом — «подвид машинного обучения, который основан на аналогии нейронных сетей человеческого мозга». При этом без каких-либо чётких критериев.
Больше 1-го скрытого слоя — deep learning. Всё.
Откуда тут взялись веб-страницы? Без веба нет A/B тестирования?
В общем, если бы я задумывался пойти на курсы, то Skillbox я бы не выбрал. Уж слишком реклама хорошая)
knagaev
Хороший комментарий, а вывод получился смешной :) Пишут из SkillFactory, а не пойдёте в Skillbox.
Видимо тот случай, когда популярность играет против.