
Прозвучала мысль, что мы кривые ламеры и не умеем всё правильно готовить. Альтернативой была гипотеза «все врут».
Прошло полгода. Мы научились всё это готовить, но заодно поняли, что гипотеза «все врут» куда более вероятная.

Тут видно, что RAM подключена к CPU1, а NVME-диски — к CPU2. Это будет критически важно дальше по сюжету.
В общем, сейчас расскажу, чего именно нам стоило ввести нормальные NVMe-тарифы и почему при всём этом очень важно разбираться в архитектуре сервера.
В чём была проблема
У нас не было NVMe-тарифа для наших клиентов VDS. Мы хотели сделать такой тариф, потому что рыночные запросы на это дело были. Чтобы сделать такой тариф, нужно выбрать конфигурацию сервера с NVMe-дисками внутри, протестировать её и внедрить по всем локациям. Мы используем только гомогенное корпоративное железо, то есть во всех наших ЦОДах по миру должны быть одни и те же конфигурации серверов. Так проще обслуживать, писать софт, обеспечивать единые цены и ремонтировать всё это. То есть введение нового сервера требует довольно больших тестов.
Мы купили несколько разных железок (самосбор, не корпоративных линеек, потому что корпоративные поставки сейчас очень долгие, чуть ли не с лагом в полгода в лучшем случае). И начали тестировать. История тестирования — в первом посте.
Краткие итоги:
— Сюрприз, но на NVMe нельзя собрать рейд. Точнее, можно, но он будет медленнее отдельных дисков, и никто так не делает. То есть смысла в рейде не то что нет, а он ещё и отрицательно сказывается на производительности. При этом все хостеры с NVMe пишут, что у них там рейды.
— Сюрприз, но NVMe-диски работают на считаные проценты лучше SSD-дисков. А мы ведь ждали совсем даже не этого.
Что было дальше
Первый сервер, до которого мы добрались в Москве летом, был Супермикро + набор дисков к нему. Тесты показали, что результаты не могут сравниться с тем, что вроде бы дают другие хостеры. То есть мы где-то что-то серьёзно недопонимали. Дальше я рассказал эту историю на Хабре, и Yoh, creker, vesper-bot, Savrik, trashwind, VanyaKokorev и borovinskiy высказали дельные мысли в комментариях. Спасибо, вы нам очень помогли в поисках дальше.
Поиски дальше заключались в том, что мы несколько месяцев искали узкое место.
Сначала пробовали разные варианты софтверного рейда включая VROC. Не помогло. Потом попробовали хардверный рейд. Как и ожидалось, ограничения шины всё равно не давали его использовать. Отвезли свой сервер в компанию, которая занимается нестандартной сборкой и делает очень кастомные решения. Они могут чуть ли не Делл из Супермикро собрать. В общем, у них лаборатория. Поставили разные софт-рейды и хард-рейды, стали менять кабели соединения, интерфейсы. Ничего особо не меняло ситуацию. Решили, что дело — в Hyper-V и его особенностях реализации, долго его ковыряли.
Что больше всего удивляло, мы общались и с поддержкой других хостингов, и с поставщиками железа, и с лабораториями, и никто не мог нормально объяснить, что происходит и почему NVMe такие медленные и тупые.
И тут внезапно прозвучала мысль про UPI-линии. И мы решили попробовать делить виртуальные машины по NUMA-нодам (нума-нода — это связка процессора, оперативки и диска в рамках одного сервера).
И тут у меня есть что вам показать!
Тесты
Тестировали платформу Supermicro X11DDW-NT:
| CPU |
Intel Xeon Gold 6250 |
| RAM |
DDR4-2933 32GB |
| SSD |
Intel P4610 1.6TB NVMe |
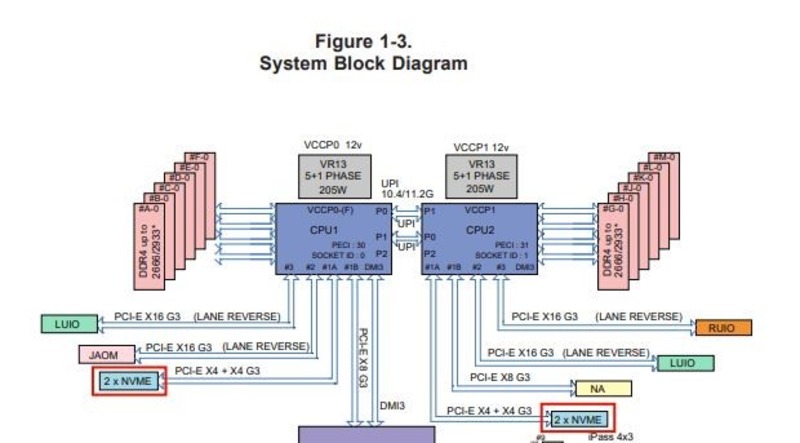
Разводка линий данной платформы. Видно, что каждый CPU обслуживает по два NVMe-диска. Каждый из дисков подключён с помощью PCI-E X4. CPU соединены между собой двумя UPI-линиями.
Теоретическая скорость линий:
- четыре линии PCI-E x4 — 16000 MB/s;
- две линии UPI — 20.8 GT/s.
Видно, что суммарная пропускная способность PCI-E-линий для четырёх дисков сравнима по величине с пропускной способностью двух линий UPI. Более того, транзакции UPI-линий используются для доступа к RAM и синхронизации работы CPU. Поэтому транзакций, которые используются непосредственно для передачи данных, остаётся меньше.
Чтобы полностью исключить шину UPI из обработки и передачи данных, мы поступим самым простым и надёжным способом: отключим CPU2, а также все модули RAM и диски NVME, к нему относящиеся:

На фотографии видно, что слоты CPU2 и относящихся к нему RAM- и NVME-дисков не заняты. Дальше для тестирования используем diskspd. Тесты проводим под Windows Server 2016 и Windows Server 2019.
Тест чтения: DiskSpd64.exe -b4K -t32 -o32 -w0 -d10 -r -S -c100G F:/testfile.dat G:/testfile.dat
Тест записи: DiskSpd64.exe -b4K -t32 -o32 -w100 -d10 -r -S -c100G F:/testfile.dat G:/testfile.dat
Результаты:
| Write (percent) |
Win2016 — IOPS |
Win2019 — IOPS |
| 0 (read) |
1132231.01 |
1026432.57 (- 9 %) |
| 100 (write) |
863745.10 |
953902.69 (+ 10 %) |
Во всех тестах нагрузка CPU была 95–98 %. Отсюда возникает вопрос, как изменится скорость, если поставить второй CPU. Поставим второй CPU и проведём соответствующий тест.
Windows Server 2016:
| Write (percent) |
один CPU — IOPS |
два CPU — IOPS |
| 0 (read) |
1132231.01 |
590263.08 ( — 48 %) |
| 100 (write) |
863745.10 |
594401.43 ( — 32 %) |
| Write (percent) |
один CPU — IOPS |
два CPU — IOPS |
| 0 (read) |
1026432.57 |
818586.28 ( — 21%) |
| 100 (write) |
953902.69 |
842953.92 ( — 12 %) |
▍ Вторая часть марлезонского балета:
А теперь установим оба CPU. Но вся RAM будет на CPU1, а NVME — на CPU2.
RAM подключена к CPU1, а NVME-диски — к CPU2.
Тесты на количество IOPS такие же, как в предыдущем разделе.
Тесты на пропускную способность:
Чтение: DiskSpd64.exe -b128K -t32 -o32 -w0 -d10 -si -S -c100G F:/testfile.dat G:/testfile.dat
Запись: DiskSpd64.exe -b128K -t32 -o32 -w100 -d10 -si -S -c100G F:/testfile.dat G:/testfile.dat
Количество IOPS:
| Write (Percent) |
Win2016 — IOPS — 4K |
Win2019 — IOPS — 4K block |
| 0 (read) |
530662.74 |
599021.15 (+ 13 %) |
| 100 (write) |
597662.21 |
783532.95 (+ 30 %) |
| Write (Percent) |
Win2016 — MiB/s — 128K block |
Win2019 — MiB/s — 128K block |
| 0 (read) |
5688.68 |
5035.62 ( — 11 %) |
| 100 (write) |
3843.31 |
3615.85 ( — 6 %) |
▍ Итоги:
Сравним количество IOPS при обмене без UPI и через UPI.
Windows Server 2016:
| Write (Percent) |
Без UPI — IOPS |
Через UPI — IOPS |
| 0 (read) |
1132231.01 |
530662.74 ( — 53 %) |
| 100 (write) |
863745.10 |
597662.21 ( — 31 %) |
| Write (Percent) |
Без UPI — IOPS |
Через UPI — IOPS |
| 0 (read) |
1026432.57 |
599021.15 ( — 41 %) |
| 100 (write) |
953902.69 |
783532.95 ( — 18 %) |
Что всё это значит?
Что все врут.
Как только мы начали распределять виртуалки по NUMA-нодам, внезапно всё заработало с нужной скоростью. Причём, кстати, под 2016-й винсервер иногда лучше, чем под 2019-й, так что если вы сейчас решаете, жить на уходящей с поддержки версии или сразу мигрировать на модное и современное, то это ещё один довод в обсуждение. Скорее всего, дело просто в том, что MS сдвинули баланс r/w где-то на уровне драйверов или рядом.
Так вот, по умолчанию виртуалки распределяются по NUMA-нодам в хаотичном порядке. Это значит, что UPI-линии используются для связи железа между нодами, в частности, с теми самыми NVMe-дисками. И могут стать узким местом.
Те хостеры, которые используют NVMe и не дописали свой софт так, чтобы создавать виртуалки в рамках одной NUMA-ноды, а не вперехлёст по железу, скорее всего, остановились на однопроцессорных серверах. На них всё «из коробки» будет работать с прогнозируемой скоростью. Там нет UPI вообще.
Относительно RAID-массивов — решения всё ещё нет. Удивительно, но рабочего рейда пока найти не удалось, хотя NVMe — всё же не вчерашняя технология. Те, кто пишет про RAID, либо банально врут, либо замедляют скорость чуть ли не ниже SSD, что исключает полезность NVMe-дисков. Мы решили делать полный технический бекап диска раз в сутки, и если что — автоматически восстанавливать из него при вылете NVMe-диска. Увы, но автоматических ребилдов, как на SSD, когда пользователь VDS этого даже не замечает, пока не будет (и в ближайшем будущем — тоже). Нам добавится работы при восстановлении при аварии. Точнее, нашим скриптам.
С новым распределением по NUMA-нодам результаты производительности NVMe у нас полностью в рынке. Тарифы — на бою, цены — хорошие. Посмотреть можно тут. Мы очень постарались, чтобы вы платили за реальную производительность, а не наклейку «NVMe» на тарифе.
Корпоративное железо приехало и выглядит вот так:



В этих серверах Lenovo SR650 V2 не две, а три UPI-линии. Возможно, наши танцы с бубном будут не нужны, так как мы надеемся, что дополнительная UPI-линия может убрать необходимость разделять виртуалки по NUMA-нодам.
Итого: если вы можете настраивать использование NUMA-нод в сервере с NVMe — лучше настроить. Если бы мы использовали KVM, то это всё завелось бы куда легче, дело отчасти — в реализации виртуализации (распределении ресурсов машин). Hyper-V изначально не имел возможности распределения виртуальных машин по NUMA-нодам, но в конечном счёте они выпустили специальную утилиту CpuGroups.exe. При её использовании можно получить измеримый эффект ускорения при использовании NVME-дисков.
Комментарии (64)

Alexsey
28.12.2021 14:47+13У админов-сетевиков есть фраза "проблема всегда в DNS". У админов виртуализации видимо аналог - "проблема всегда в NUMA" :)

creker
28.12.2021 15:44+5Они могут чуть ли не Делл из Супермикро собрать
Ирония в том, что делл и прочие супермикро и использует для некоторых моделей.
А про NUMA да, это штука известная. Я поэтому очень люблю супермикро за их документацию. К каждому серваку есть мануал с блоксхемой всех компонентов на материнке, что позволяет сразу оценить, где может быть ботлнек. Очень важно для любой pcie нагрузки, будь это диски или гпу. Терпеть не могу энтерпрайз этот, где толком не поймешь даже сколько у тебя райзеров pcie и каких будет. Куда уж там сколько pcie линий и откуда отведено под тот или иной порт.
Вот насчет рейда все равно не уверен. Какой-нить raid0 должен дать профит. Тут мне кажется сильно зависит от софта, т.к. pcie диски требует очень серьезной работы уже в софте, чтобы правильно раскидать потоки по ядрам, правильно шедулить запросы к дискам, минимизировать общение через интерконнект процессоров и т.д. и т.п.
amarao
28.12.2021 15:54+4По совести, у dell'а есть подробные блок-схемы именно в контексте nvme, потому что это (внезапно стало) важно. Там же написано в каких конфигурациях производительность будет ограничиваться (из-за сожительства nvme на одной линии).


t3chn0ph0b
28.12.2021 15:48+3мы надеемся, что дополнительная UPI-линия может убрать необходимость разделять виртуалки по NUMA-нодам
Очень хочется узнать результаты )

werter_l
28.12.2021 16:01Спасибо )
P.s. Перешел еще 7 лет назад на Proxmox VE (KVM). Там с numa все гораздо лучше.
Кому интересно forum.netgate.com/topic/163435/proxmox-ceph-zfs-pfsense-%D0%B8-%D0%B2%D1%81%D0%B5-%D0%B2%D1%81%D0%B5-%D0%B2%D1%81%D0%B5-%D1%87%D0%B0%D1%81%D1%82%D1%8C-2

DustCn
28.12.2021 16:03+1План такой. Сделать каждый нума узел одинаковым и при старте процесса пинить его на нумаузел и выдавать ближайший NVME, исключив "по умолчанию виртуалки распределяются по NUMA-нодам в хаотичном порядке". Попробовать поиграться с настройками SNC в биосе. SNC 2 будет в этом случае достаточно.

ntsaplin Автор
28.12.2021 17:19+1Настройки BIOS безусловно важны, но нам важно, чтобы виртуальная машина попала на ту NUMA-ноду, CPU которой обслуживает NVME диск, на котором расположен образ VM. В этом случае для обращения к диску виртуальной машине не потребуется задействовать UPI линии.

edo1h
30.12.2021 04:18+1но нам важно, чтобы виртуальная машина попала на ту NUMA-ноду, CPU которой обслуживает NVME диск, на котором расположен образ VM. В этом случае для обращения к диску виртуальной машине не потребуется задействовать UPI линии.
а зачем вам вообще двухядерные серверы?


porutchik
28.12.2021 17:12+1А не проще использовать 1 cpu на 64 ядра, например, без плясок с бубнами?
ntsaplin Автор
28.12.2021 17:48+1Не до конца понятно, какой процессор с 64 ядрами вы имеете ввиду, как правило они не подходят для нужд хостинга.
Intel Xeon Phi Processor 7210 — слишком низкая частота.
AMD Ryzen Threadripper 3990X Processor — слишком мало каналов памяти.
V1RuS
28.12.2021 18:09+1Так threadripper и не для серверов вроде. Вот Epyc 7742 например — 8 каналов памяти https://www.amd.com/ru/products/cpu/amd-epyc-7742

DarkNews
28.12.2021 21:03Вы как то упустили как раз то, что исходят из первой статьи вам было нужно.
Ryzen Threadripper Pro 3995WX.
64 ядра, 128 линий PCie 4 версии, 8 каналов оперативной памяти, и объем до 2ТБ.
При этом буст частота - до 4.2Ггц.
Это хоть и тредрипер, но по сути именно что серверный эпик, с апнутыми частотами. А если не нужен такой монстр - вполне вариант к примеру Ryzen Threadripper Pro 3955WX, как раз замеит два ваших 8 ядерника, базовая частота те же 3.9, буст 4.3, остальное так же что и у того что описывал выше.


Tangeman
28.12.2021 21:53+1Те, кто пишет про RAID, либо банально врут, либо замедляют скорость чуть ли не ниже SSD, что исключает полезность NVMe-дисков.
Получается Hetzner врёт? Они утверждают что у них RAID10 на хостах, диски NVMe, и судя по результатам тестирования внутри cloud-серверов, похоже таки на правду (fio на самом дешёвом cloud server, CX11, ему уже несколько лет):
# fio --filename=/fio.test --size=1G --direct=1 --rw=randrw --bs=1m --ioengine=libaio --iodepth=8 --iodepth_batch_submit=8 --runtime=10 --numjobs=6 --time_based --group_reporting --name=iops-test-job --eta-newline=1 ... Run status group 0 (all jobs): READ: bw=2894MiB/s (3034MB/s), 2894MiB/s-2894MiB/s (3034MB/s-3034MB/s), io=28.3GiB (30.4GB), run=10012-10012msec WRITE: bw=2919MiB/s (3061MB/s), 2919MiB/s-2919MiB/s (3061MB/s-3061MB/s), io=28.5GiB (30.6GB), run=10012-10012msec ## А также чистая запись # fio --filename=/fio.test --size=1G --direct=1 --rw=randwrite --bs=1m --ioengine=libaio --iodepth=8 --iodepth_batch_submit=8 --runtime=10 --numjobs=6 --time_based --group_reporting --name=iops-test-job --eta-newline=1 iops-test-job: (g=0): rw=randwrite, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=libaio, iodepth=8 ... Run status group 0 (all jobs): WRITE: bw=4560MiB/s (4781MB/s), 4560MiB/s-4560MiB/s (4781MB/s-4781MB/s), io=44.6GiB (47.8GB), run=10008-10008msecВ процессе тестирования использование процессора (vCPU, он там один) около 60%.
По любому быстрее чем обычный SSD — в разы. Результаты стабильные за все несколько лет, и не только на одном сервере, разумеется, и это с учётом того что на одном хосте крутится явно не один виртуальный.

AlexGluck
29.12.2021 03:34Причина скорее всего в том, что в качестве технологии виртуализации хетцнер использует KVM, а статья о hiper-v. Субьективно никогда не нравился hiper-v, как и многие другие проприетарные решения.

borovinskiy
29.12.2021 08:28+11 ГБ - очень мало. Лучше файл делать больше.
borovinskiy
29.12.2021 09:29+2Если там стоит аппаратный контроллер с writeback, есть вероятность, что все записанные данные уместились в его ОЗУ и это тест скорости ОЗУ контроллера.

thatsme
29.12.2021 21:13+1А чего вы там за 10 сек намеряете то? Уберите параметр --runtime=10, дайте тесту поработать на объём выше объёма кеша. На полный прогон теста на 100%. Результаты могут оказаться совсем не теми, что вы ожидаете.
Вот этот тест на 1МБ блок, это совсем не то кстати, что у вас в продуктиве происходит. Выглядит как маркетинг для консамерского рынка.
Блок на 4КВ лучше выставить наверное. Это будет типичный блок. А с 1М блоком тест закончится не успев запустить все потоки. С 1М блоком, тест внезапно становится более последовательный чем случайный.
На домашней системе RAID-10 на 6 SATA дисках (ZFS), против Samsung EVO 980 Pro 1TB. Смотрим разницу для размера блока:
ZFS-RAID10(compression lz4):
fio --randrepeat=1 --filename=./fio.test --size=10G --direct=1 --rw=randrw --bs=128k --ioengine=sync --iodepth=8 --iodepth_batch_submit=8 --numjobs=8 --group_reporting --name=iops-test-job --eta-newline=1 --rwmixread=75
iops-test-job: (g=0): rw=randrw, bs=(R) 128KiB-128KiB, (W) 128KiB-128KiB, (T) 128KiB-128KiB, ioengine=sync, iodepth=8
...
fio-3.27
Starting 8 processes
Jobs: 8 (f=8): [m(8)][26.7%][r=1538MiB/s,w=505MiB/s][r=12.3k,w=4040 IOPS][eta 00m:11s]
Jobs: 8 (f=8): [m(8)][27.3%][r=782MiB/s,w=269MiB/s][r=6254,w=2152 IOPS][eta 00m:16s]
Jobs: 8 (f=8): [m(8)][28.6%][r=800MiB/s,w=264MiB/s][r=6397,w=2111 IOPS][eta 00m:20s]
Jobs: 8 (f=8): [m(8)][30.3%][r=737MiB/s,w=261MiB/s][r=5892,w=2084 IOPS][eta 00m:23s]
Jobs: 8 (f=8): [m(8)][32.4%][r=791MiB/s,w=258MiB/s][r=6328,w=2061 IOPS][eta 00m:25s]
Jobs: 8 (f=8): [m(8)][35.0%][r=733MiB/s,w=243MiB/s][r=5863,w=1947 IOPS][eta 00m:26s]
Jobs: 8 (f=8): [m(8)][37.2%][r=896MiB/s,w=305MiB/s][r=7165,w=2443 IOPS][eta 00m:27s]
Jobs: 8 (f=8): [m(8)][40.0%][r=918MiB/s,w=307MiB/s][r=7341,w=2459 IOPS][eta 00m:27s]
Jobs: 8 (f=8): [m(8)][42.6%][r=602MiB/s,w=195MiB/s][r=4819,w=1560 IOPS][eta 00m:27s]
Jobs: 8 (f=8): [m(8)][44.9%][r=793MiB/s,w=269MiB/s][r=6343,w=2149 IOPS][eta 00m:27s]
Jobs: 8 (f=8): [m(8)][47.1%][r=821MiB/s,w=270MiB/s][r=6564,w=2163 IOPS][eta 00m:27s]
Jobs: 8 (f=8): [m(8)][50.0%][r=849MiB/s,w=292MiB/s][r=6791,w=2339 IOPS][eta 00m:26s]
Jobs: 8 (f=8): [m(8)][52.8%][r=926MiB/s,w=319MiB/s][r=7405,w=2552 IOPS][eta 00m:25s]
Jobs: 8 (f=8): [m(8)][55.6%][r=976MiB/s,w=325MiB/s][r=7808,w=2599 IOPS][eta 00m:24s]
Jobs: 8 (f=8): [m(8)][58.2%][r=899MiB/s,w=300MiB/s][r=7188,w=2403 IOPS][eta 00m:23s]
Jobs: 8 (f=8): [m(8)][60.7%][r=531MiB/s,w=174MiB/s][r=4250,w=1394 IOPS][eta 00m:22s]
Jobs: 8 (f=8): [m(8)][62.1%][r=594MiB/s,w=203MiB/s][r=4753,w=1622 IOPS][eta 00m:22s]
Jobs: 8 (f=8): [m(8)][64.4%][r=677MiB/s,w=224MiB/s][r=5419,w=1792 IOPS][eta 00m:21s]
Jobs: 8 (f=8): [m(8)][66.7%][r=729MiB/s,w=230MiB/s][r=5831,w=1841 IOPS][eta 00m:20s]
Jobs: 8 (f=8): [m(8)][68.9%][r=687MiB/s,w=243MiB/s][r=5493,w=1942 IOPS][eta 00m:19s]
Jobs: 8 (f=8): [m(8)][71.0%][r=801MiB/s,w=273MiB/s][r=6406,w=2183 IOPS][eta 00m:18s]
Jobs: 8 (f=8): [m(8)][74.2%][r=898MiB/s,w=297MiB/s][r=7185,w=2375 IOPS][eta 00m:16s]
Jobs: 8 (f=8): [m(8)][77.4%][r=818MiB/s,w=269MiB/s][r=6546,w=2153 IOPS][eta 00m:14s]
Jobs: 8 (f=8): [m(8)][79.4%][r=675MiB/s,w=222MiB/s][r=5401,w=1773 IOPS][eta 00m:13s]
Jobs: 8 (f=8): [m(8)][81.2%][r=702MiB/s,w=232MiB/s][r=5619,w=1854 IOPS][eta 00m:12s]
Jobs: 8 (f=8): [m(8)][83.1%][r=683MiB/s,w=235MiB/s][r=5463,w=1882 IOPS][eta 00m:11s]
Jobs: 8 (f=8): [m(8)][86.2%][r=808MiB/s,w=270MiB/s][r=6466,w=2162 IOPS][eta 00m:09s]
Jobs: 8 (f=8): [m(8)][89.2%][r=770MiB/s,w=252MiB/s][r=6160,w=2014 IOPS][eta 00m:07s]
Jobs: 8 (f=8): [m(8)][90.9%][r=805MiB/s,w=272MiB/s][r=6436,w=2174 IOPS][eta 00m:06s]
Jobs: 8 (f=8): [m(8)][93.9%][r=838MiB/s,w=284MiB/s][r=6701,w=2271 IOPS][eta 00m:04s]
Jobs: 8 (f=8): [m(8)][97.0%][r=1017MiB/s,w=335MiB/s][r=8137,w=2680 IOPS][eta 00m:02s]
Jobs: 1 (f=1): [(3),m(1),(4)][100.0%][r=817MiB/s,w=257MiB/s][r=6539,w=2053 IOPS][eta 00m:00s]
iops-test-job: (groupid=0, jobs=8): err= 0: pid=22448: Wed Dec 29 17:28:47 2021
read: IOPS=7681, BW=960MiB/s (1007MB/s)(60.0GiB/63986msec)
clat (usec): min=3, max=31324, avg=23.72, stdev=158.94
lat (usec): min=3, max=31324, avg=23.76, stdev=158.94
clat percentiles (usec):
| 1.00th=[ 7], 5.00th=[ 7], 10.00th=[ 8], 20.00th=[ 14],
| 30.00th=[ 15], 40.00th=[ 16], 50.00th=[ 16], 60.00th=[ 17],
| 70.00th=[ 17], 80.00th=[ 19], 90.00th=[ 38], 95.00th=[ 67],
| 99.00th=[ 105], 99.50th=[ 119], 99.90th=[ 635], 99.95th=[ 1745],
| 99.99th=[ 7373]
bw ( KiB/s): min=484096, max=10253199, per=100.00%, avg=984672.14, stdev=141259.34, samples=1010
iops : min= 3782, max=80100, avg=7692.66, stdev=1103.55, samples=1010
write: IOPS=2560, BW=320MiB/s (336MB/s)(20.0GiB/63986msec); 0 zone resets
clat (usec): min=12, max=38277, avg=3025.59, stdev=1507.55
lat (usec): min=12, max=38278, avg=3026.06, stdev=1507.34
clat percentiles (usec):
| 1.00th=[ 20], 5.00th=[ 36], 10.00th=[ 61], 20.00th=[ 1663],
| 30.00th=[ 3064], 40.00th=[ 3261], 50.00th=[ 3458], 60.00th=[ 3654],
| 70.00th=[ 3818], 80.00th=[ 4015], 90.00th=[ 4490], 95.00th=[ 4883],
| 99.00th=[ 5473], 99.50th=[ 5735], 99.90th=[ 6128], 99.95th=[ 6390],
| 99.99th=[ 6915]
bw ( KiB/s): min=174848, max=3511655, per=100.00%, avg=328313.31, stdev=47484.87, samples=1010
iops : min= 1366, max=27431, avg=2564.87, stdev=370.94, samples=1010
lat (usec) : 4=0.01%, 10=14.41%, 20=48.19%, 50=8.27%, 100=6.59%
lat (usec) : 250=1.13%, 500=0.19%, 750=0.23%, 1000=0.20%
lat (msec) : 2=1.13%, 4=14.33%, 10=5.33%, 20=0.01%, 50=0.01%
cpu : usr=0.14%, sys=2.60%, ctx=149825, majf=0, minf=137
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=491539,163821,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=8Run status group 0 (all jobs):
READ: bw=960MiB/s (1007MB/s), 960MiB/s-960MiB/s (1007MB/s-1007MB/s), io=60.0GiB (64.4GB), run=63986-63986msec
WRITE: bw=320MiB/s (336MB/s), 320MiB/s-320MiB/s (336MB/s-336MB/s), io=20.0GiB (21.5GB), run=63986-63986msecfio --randrepeat=1 --filename=./fio.test --size=10G --direct=1 --rw=randrw --bs=256k --ioengine=sync --iodepth=8 --iodepth_batch_submit=8 --numjobs=8 --group_reporting --name=iops-test-job --eta-newline=1 --rwmixread=75
iops-test-job: (g=0): rw=randrw, bs=(R) 256KiB-256KiB, (W) 256KiB-256KiB, (T) 256KiB-256KiB, ioengine=sync, iodepth=8...
fio-3.27
Starting 8 processes
Jobs: 8 (f=8): [m(8)][25.0%][r=1495MiB/s,w=514MiB/s][r=5981,w=2056 IOPS][eta 00m:12s]
Jobs: 8 (f=8): [m(8)][26.1%][r=769MiB/s,w=253MiB/s][r=3075,w=1013 IOPS][eta 00m:17s]
Jobs: 8 (f=8): [m(8)][28.6%][r=1011MiB/s,w=326MiB/s][r=4045,w=1302 IOPS][eta 00m:20s]
Jobs: 8 (f=8): [m(8)][32.3%][r=1133MiB/s,w=373MiB/s][r=4530,w=1491 IOPS][eta 00m:21s]
Jobs: 8 (f=8): [m(8)][35.3%][r=1115MiB/s,w=366MiB/s][r=4460,w=1464 IOPS][eta 00m:22s]
Jobs: 8 (f=8): [m(8)][38.9%][r=1304MiB/s,w=425MiB/s][r=5214,w=1700 IOPS][eta 00m:22s]
Jobs: 8 (f=8): [m(8)][42.1%][r=853MiB/s,w=286MiB/s][r=3410,w=1144 IOPS][eta 00m:22s]
Jobs: 8 (f=8): [m(8)][45.0%][r=781MiB/s,w=268MiB/s][r=3124,w=1070 IOPS][eta 00m:22s]
Jobs: 8 (f=8): [m(8)][47.6%][r=874MiB/s,w=290MiB/s][r=3494,w=1160 IOPS][eta 00m:22s]
Jobs: 8 (f=8): [m(8)][50.0%][r=960MiB/s,w=346MiB/s][r=3840,w=1383 IOPS][eta 00m:22s]
Jobs: 8 (f=8): [m(8)][53.3%][r=933MiB/s,w=313MiB/s][r=3733,w=1252 IOPS][eta 00m:21s]
Jobs: 8 (f=8): [m(8)][56.5%][r=1110MiB/s,w=358MiB/s][r=4441,w=1432 IOPS][eta 00m:20s]
Jobs: 8 (f=8): [m(8)][60.9%][r=1056MiB/s,w=364MiB/s][r=4224,w=1454 IOPS][eta 00m:18s]
Jobs: 8 (f=8): [m(8)][63.8%][r=943MiB/s,w=301MiB/s][r=3771,w=1204 IOPS][eta 00m:17s]
Jobs: 8 (f=8): [m(8)][66.7%][r=1074MiB/s,w=349MiB/s][r=4294,w=1395 IOPS][eta 00m:16s]
Jobs: 8 (f=8): [m(8)][69.4%][r=984MiB/s,w=331MiB/s][r=3937,w=1322 IOPS][eta 00m:15s]
Jobs: 8 (f=8): [m(8)][72.0%][r=851MiB/s,w=287MiB/s][r=3402,w=1149 IOPS][eta 00m:14s]
Jobs: 8 (f=8): [m(8)][76.0%][r=920MiB/s,w=321MiB/s][r=3679,w=1284 IOPS][eta 00m:12s]
Jobs: 8 (f=8): [m(8)][78.4%][r=1050MiB/s,w=328MiB/s][r=4198,w=1313 IOPS][eta 00m:11s]
Jobs: 8 (f=8): [m(8)][80.8%][r=570MiB/s,w=196MiB/s][r=2280,w=783 IOPS][eta 00m:10s]
Jobs: 8 (f=8): [m(8)][83.0%][r=784MiB/s,w=263MiB/s][r=3135,w=1052 IOPS][eta 00m:09s]
Jobs: 8 (f=8): [m(8)][86.8%][r=919MiB/s,w=318MiB/s][r=3676,w=1271 IOPS][eta 00m:07s]
Jobs: 8 (f=8): [m(8)][88.9%][r=884MiB/s,w=291MiB/s][r=3535,w=1165 IOPS][eta 00m:06s]
Jobs: 8 (f=8): [m(8)][92.6%][r=1031MiB/s,w=325MiB/s][r=4124,w=1300 IOPS][eta 00m:04s]
Jobs: 8 (f=8): [m(8)][94.5%][r=1090MiB/s,w=372MiB/s][r=4361,w=1489 IOPS][eta 00m:03s]
Jobs: 7 (f=7): [m(6),(1),m(1)][98.2%][r=803MiB/s,w=290MiB/s][r=3213,w=1159 IOPS][eta 00m:01s] Jobs: 2 (f=2): [m(1),(2),m(1),_(4)][100.0%][r=670MiB/s,w=224MiB/s][r=2680,w=894 IOPS][eta 00m:00s]
iops-test-job: (groupid=0, jobs=8): err= 0: pid=12791: Wed Dec 29 17:27:10 2021
read: IOPS=4544, BW=1136MiB/s (1191MB/s)(59.9GiB/54009msec)
clat (usec): min=6, max=37703, avg=46.85, stdev=211.13
lat (usec): min=6, max=37703, avg=46.91, stdev=211.13
clat percentiles (usec):
| 1.00th=[ 13], 5.00th=[ 14], 10.00th=[ 14], 20.00th=[ 27],
| 30.00th=[ 30], 40.00th=[ 31], 50.00th=[ 32], 60.00th=[ 33],
| 70.00th=[ 34], 80.00th=[ 38], 90.00th=[ 77], 95.00th=[ 137],
| 99.00th=[ 221], 99.50th=[ 255], 99.90th=[ 1582], 99.95th=[ 3163],
| 99.99th=[ 9241]
bw ( MiB/s): min= 494, max= 9652, per=100.00%, avg=1144.48, stdev=144.33, samples=852
iops : min= 1978, max=38607, avg=4577.88, stdev=577.29, samples=852
write: IOPS=1522, BW=381MiB/s (399MB/s)(20.1GiB/54009msec); 0 zone resets
clat (usec): min=20, max=27805, avg=5063.57, stdev=2444.92
lat (usec): min=21, max=27807, avg=5064.76, stdev=2444.10
clat percentiles (usec):
| 1.00th=[ 42], 5.00th=[ 85], 10.00th=[ 125], 20.00th=[ 3589],
| 30.00th=[ 5080], 40.00th=[ 5407], 50.00th=[ 5669], 60.00th=[ 5997],
| 70.00th=[ 6390], 80.00th=[ 6718], 90.00th=[ 7373], 95.00th=[ 7898],
| 99.00th=[ 9372], 99.50th=[10552], 99.90th=[11469], 99.95th=[11600],
| 99.99th=[12518]
bw ( KiB/s): min=184832, max=3352134, per=100.00%, avg=392700.39, stdev=50158.90, samples=852
iops : min= 722, max=13093, avg=1533.96, stdev=195.91, samples=852
lat (usec) : 10=0.01%, 20=13.73%, 50=51.47%, 100=5.20%, 250=7.47%
lat (usec) : 500=0.41%, 750=0.13%, 1000=0.11%
lat (msec) : 2=0.50%, 4=1.14%, 10=19.63%, 20=0.19%, 50=0.01%
cpu : usr=0.12%, sys=3.07%, ctx=151268, majf=0, minf=133
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=245434,82246,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=8Run status group 0 (all jobs):
READ: bw=1136MiB/s (1191MB/s), 1136MiB/s-1136MiB/s (1191MB/s-1191MB/s), io=59.9GiB (64.3GB), run=54009-54009msec
WRITE: bw=381MiB/s (399MB/s), 381MiB/s-381MiB/s (399MB/s-399MB/s), io=20.1GiB (21.6GB), run=54009-54009msecА теперь внимание 4к блок:
fio --randrepeat=1 --filename=./fio.test --size=10G --direct=1 --rw=randrw --bs=4k --ioengine=sync --iodepth=8 --iodepth_batch_submit=8 --numjobs=8 --group_reporting --name=iops-test-job --eta-newline=1 --rwmixread=75
iops-test-job: (g=0): rw=randrw, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=sync, iodepth=8
...
fio-3.27
Starting 8 processes
Jobs: 8 (f=8): [m(8)][0.9%][r=46.0MiB/s,w=15.5MiB/s][r=11.8k,w=3956 IOPS][eta 07m:41s]
Jobs: 8 (f=8): [m(8)][0.9%][r=26.9MiB/s,w=9784KiB/s][r=6877,w=2446 IOPS][eta 11m:09s]
Jobs: 8 (f=8): [m(8)][1.0%][r=31.5MiB/s,w=10.6MiB/s][r=8060,w=2703 IOPS][eta 13m:49s]
Jobs: 8 (f=8): [m(8)][1.0%][r=28.4MiB/s,w=9480KiB/s][r=7269,w=2370 IOPS][eta 15m:57s]
Jobs: 8 (f=8): [m(8)][1.1%][r=28.9MiB/s,w=9780KiB/s][r=7388,w=2445 IOPS][eta 17m:43s]
Jobs: 8 (f=8): [m(8)][1.2%][r=31.9MiB/s,w=10.9MiB/s][r=8166,w=2780 IOPS][eta 19m:01s]......
Jobs: 8 (f=8): [m(8)][98.8%][r=26.5MiB/s,w=9120KiB/s][r=6779,w=2280 IOPS][eta 00m:30s]
Jobs: 8 (f=8): [m(8)][98.9%][r=23.3MiB/s,w=7696KiB/s][r=5964,w=1924 IOPS][eta 00m:28s]
Jobs: 8 (f=8): [m(8)][99.0%][r=24.1MiB/s,w=8760KiB/s][r=6170,w=2190 IOPS][eta 00m:26s]
Jobs: 8 (f=8): [m(8)][99.1%][r=26.3MiB/s,w=8936KiB/s][r=6725,w=2234 IOPS][eta 00m:24s]
Jobs: 8 (f=8): [m(8)][99.1%][r=28.9MiB/s,w=9704KiB/s][r=7400,w=2426 IOPS][eta 00m:22s]
Jobs: 8 (f=8): [m(8)][99.3%][r=30.8MiB/s,w=10.3MiB/s][r=7895,w=2627 IOPS][eta 00m:19s]
Jobs: 8 (f=8): [m(8)][99.4%][r=34.2MiB/s,w=11.6MiB/s][r=8745,w=2979 IOPS][eta 00m:16s]
Jobs: 8 (f=8): [m(8)][99.5%][r=36.7MiB/s,w=12.2MiB/s][r=9396,w=3132 IOPS][eta 00m:13s]
Jobs: 8 (f=8): [m(8)][99.6%][r=23.4MiB/s,w=7704KiB/s][r=5986,w=1926 IOPS][eta 00m:11s]
Jobs: 8 (f=8): [m(8)][99.7%][r=29.0MiB/s,w=9.96MiB/s][r=7412,w=2550 IOPS][eta 00m:09s]
Jobs: 8 (f=8): [m(8)][99.8%][r=30.1MiB/s,w=9872KiB/s][r=7709,w=2468 IOPS][eta 00m:06s]
Jobs: 8 (f=8): [m(8)][99.8%][r=25.1MiB/s,w=8844KiB/s][r=6427,w=2211 IOPS][eta 00m:04s]
Jobs: 3 (f=3): [m(2),_(5),m(1)][100.0%][r=34.5MiB/s,w=10.9MiB/s][r=8827,w=2782 IOPS][eta 00m:00s]
iops-test-job: (groupid=0, jobs=8): err= 0: pid=24292: Wed Dec 29 18:21:34 2021
read: IOPS=6113, BW=23.9MiB/s (25.0MB/s)(60.0GiB/2572268msec)
clat (nsec): min=740, max=53590k, avg=10697.23, stdev=33246.32
lat (nsec): min=760, max=53590k, avg=10742.76, stdev=33246.96
clat percentiles (nsec):
| 1.00th=[ 1464], 5.00th=[ 1608], 10.00th=[ 1704], 20.00th=[ 1992],
| 30.00th=[ 11584], 40.00th=[ 12608], 50.00th=[ 12992], 60.00th=[ 13376],
| 70.00th=[ 13760], 80.00th=[ 14144], 90.00th=[ 15040], 95.00th=[ 15936],
| 99.00th=[ 20352], 99.50th=[ 24192], 99.90th=[ 79360], 99.95th=[ 95744],
| 99.99th=[123392]
bw ( KiB/s): min= 9304, max=314495, per=100.00%, avg=24455.63, stdev=938.24, samples=41127
iops : min= 2326, max=78621, avg=6113.84, stdev=234.56, samples=41127
write: IOPS=2038, BW=8156KiB/s (8352kB/s)(20.0GiB/2572268msec); 0 zone resets
clat (usec): min=3, max=36815, avg=3888.22, stdev=786.33
lat (usec): min=3, max=36815, avg=3888.30, stdev=786.33
clat percentiles (usec):
| 1.00th=[ 2409], 5.00th=[ 2835], 10.00th=[ 3032], 20.00th=[ 3261],
| 30.00th=[ 3458], 40.00th=[ 3654], 50.00th=[ 3851], 60.00th=[ 4015],
| 70.00th=[ 4228], 80.00th=[ 4424], 90.00th=[ 4817], 95.00th=[ 5211],
| 99.00th=[ 6063], 99.50th=[ 6325], 99.90th=[ 7373], 99.95th=[ 7701],
| 99.99th=[ 8455]
bw ( KiB/s): min= 3864, max=106361, per=99.99%, avg=8155.80, stdev=296.32, samples=41127
iops : min= 966, max=26589, avg=2038.88, stdev=74.08, samples=41127
lat (nsec) : 750=0.01%, 1000=0.04%
lat (usec) : 2=15.02%, 4=5.93%, 10=0.13%, 20=53.06%, 50=0.68%
lat (usec) : 100=0.19%, 250=0.05%, 500=0.01%, 750=0.01%, 1000=0.01%
lat (msec) : 2=0.04%, 4=14.49%, 10=10.35%, 20=0.01%, 50=0.01%
lat (msec) : 100=0.01%
cpu : usr=0.08%, sys=1.21%, ctx=5246713, majf=0, minf=146
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=15726772,5244748,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=8Run status group 0 (all jobs):
READ: bw=23.9MiB/s (25.0MB/s), 23.9MiB/s-23.9MiB/s (25.0MB/s-25.0MB/s), io=60.0GiB (64.4GB), run=2572268-2572268msec
WRITE: bw=8156KiB/s (8352kB/s), 8156KiB/s-8156KiB/s (8352kB/s-8352kB/s), io=20.0GiB (21.5GB), run=2572268-2572268msecУдручающая картина, не правда ли? А теперь внимание, то-же самое для NVME
NVME> fio --randrepeat=1 --filename=./fio.test --size=10G --direct=1 --rw=randrw --bs=4k --ioengine=sync --iodepth=8 --iodepth_batch_submit=8 --numjobs=8 --group_reporting --name=iops-test-job --eta-newline=1 --rwmixread=75
iops-test-job: (g=0): rw=randrw, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=sync, iodepth=8
...
fio-3.27
Starting 8 processes
iops-test-job: Laying out IO file (1 file / 10240MiB)
Jobs: 8 (f=8): [m(8)][4.1%][r=657MiB/s,w=217MiB/s][r=168k,w=55.7k IOPS][eta 01m:33s]
........Jobs: 8 (f=8): [m(8)][96.8%][r=657MiB/s,w=220MiB/s][r=168k,w=56.3k IOPS][eta 00m:03s]
Jobs: 8 (f=8): [m(8)][98.9%][r=657MiB/s,w=217MiB/s][r=168k,w=55.6k IOPS][eta 00m:01s]
Jobs: 8 (f=8): [m(8)][100.0%][r=653MiB/s,w=219MiB/s][r=167k,w=56.0k IOPS][eta 00m:00s]
iops-test-job: (groupid=0, jobs=8): err= 0: pid=22788: Wed Dec 29 19:02:39 2021
read: IOPS=167k, BW=654MiB/s (685MB/s)(60.0GiB/93995msec)
clat (usec): min=17, max=8563, avg=43.77, stdev=30.11
lat (usec): min=17, max=8564, avg=43.80, stdev=30.11
clat percentiles (usec):
| 1.00th=[ 38], 5.00th=[ 38], 10.00th=[ 38], 20.00th=[ 39],
| 30.00th=[ 40], 40.00th=[ 40], 50.00th=[ 40], 60.00th=[ 41],
| 70.00th=[ 41], 80.00th=[ 43], 90.00th=[ 49], 95.00th=[ 63],
| 99.00th=[ 135], 99.50th=[ 157], 99.90th=[ 176], 99.95th=[ 184],
| 99.99th=[ 297]
bw ( KiB/s): min=635320, max=681120, per=100.00%, avg=669528.73, stdev=1143.75, samples=1496
iops : min=158830, max=170280, avg=167382.17, stdev=285.94, samples=1496
write: IOPS=55.8k, BW=218MiB/s (229MB/s)(20.0GiB/93995msec); 0 zone resets
clat (usec): min=9, max=8514, avg=10.45, stdev= 5.40
lat (usec): min=9, max=8515, avg=10.50, stdev= 5.40
clat percentiles (nsec):
| 1.00th=[ 9664], 5.00th=[ 9792], 10.00th=[ 9792], 20.00th=[ 9920],
| 30.00th=[ 9920], 40.00th=[10048], 50.00th=[10176], 60.00th=[10304],
| 70.00th=[10560], 80.00th=[10944], 90.00th=[11456], 95.00th=[11968],
| 99.00th=[13504], 99.50th=[14272], 99.90th=[15808], 99.95th=[16768],
| 99.99th=[19584]
bw ( KiB/s): min=207440, max=235672, per=100.00%, avg=223287.40, stdev=627.87, samples=1496
iops : min=51860, max=58918, avg=55821.85, stdev=156.97, samples=1496
lat (usec) : 10=8.24%, 20=16.77%, 50=67.79%, 100=5.81%, 250=1.38%
lat (usec) : 500=0.01%, 750=0.01%, 1000=0.01%
lat (msec) : 2=0.01%, 4=0.01%, 10=0.01%
cpu : usr=1.70%, sys=4.07%, ctx=20977179, majf=0, minf=126
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=15726772,5244748,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=8Run status group 0 (all jobs):
READ: bw=654MiB/s (685MB/s), 654MiB/s-654MiB/s (685MB/s-685MB/s), io=60.0GiB (64.4GB), run=93995-93995msec
WRITE: bw=218MiB/s (229MB/s), 218MiB/s-218MiB/s (229MB/s-229MB/s), io=20.0GiB (21.5GB), run=93995-93995msecDisk stats (read/write):
nvme0n1: ios=15717227/5241742, merge=0/2, ticks=667570/47502, in_queue=715089, util=99.91%NVME выдаёт 220к 4к IOPS в сумме (r+w). При этом Samsung заявляет о 1М IOPS.Видимо не 4К IOPS.
В общем врут. Вернее "грамотно преподносят информацию".
Tangeman
30.12.2021 02:28Тесты ZFS могут не говорить о реальной призводительности если неизвестно сколько памяти получил ARC — ZFS очень агрессивен в кэшировании (direct i/o игнорирует), так что если памяти у вас достаточно (32GB или больше) вы меряете производительность самой файловой системы, а не накопителя. Поставьте ограничение на ARC чтобы файл в него точно не влезал, и добавьте
--fsync=1кfio(убедившись что в ZFS не стоитsync=disabled) — тогда тест будет более реалистичным.С блоками по 4k ситуация очень плохая за счёт организации самого ZFS (дерево, контрольные суммы и вот это всё) — сделайте ramdisk и померяйте, результаты тоже будут не впечатляющими, хотя конечно лучше чем с диском (любым).
NVME выдаёт 220к 4к IOPS в сумме (r+w). При этом Samsung заявляет о 1М IOPS.Видимо не 4К IOPS.
Потому что они указывают данные не для микса, а отдельно для чтения и записи — на только чтении или записи вы вероятно можете получить почти близко к 1M iops при QD > 32 а то и 128, правда, в
вакуумеидеальных условиях — т.е. тестируете его в монопольном режиме, причём заточенным под максимум производительности тулом. Вообще странно было бы ожидать от производителя гарантии iops не зная где и как будет использоваться накопитель, может его вообще по USB подключат, поэтому они указывают возможности железа (NVMe + PCIe), а вытянет ли их ваш конкретный сетап — это уже вопрос.Теперь вернёмся к NVMe на Hetzner. Я провел тот же тест с файлом в 20G, с блоками по 1M и 4k, всё длительностью 1 минута — думаю это уж точно в кэш не влезло (разве что в SLC на самом накопителе):
fio --filename=/fio.test --size=20G --direct=1 --rw=randrw --bs=1m --ioengine=libaio --iodepth=8 --iodepth_batch_submit=8 --runtime=60 --numjobs=6 --time_based --group_reporting --name=iops-test-job --eta-newline=10Jobs: 6 (f=6): [m(6)][20.0%][r=2672MiB/s,w=2636MiB/s][r=2672,w=2636 IOPS][eta 00m:48s] Jobs: 6 (f=6): [m(6)][38.3%][r=2862MiB/s,w=2910MiB/s][r=2862,w=2910 IOPS][eta 00m:37s] Jobs: 6 (f=6): [m(6)][56.7%][r=2854MiB/s,w=2893MiB/s][r=2854,w=2893 IOPS][eta 00m:26s] Jobs: 6 (f=6): [m(6)][75.0%][r=2758MiB/s,w=2820MiB/s][r=2757,w=2819 IOPS][eta 00m:15s] Jobs: 6 (f=6): [m(6)][93.3%][r=2850MiB/s,w=2865MiB/s][r=2850,w=2865 IOPS][eta 00m:04s] Jobs: 6 (f=6): [m(6)][100.0%][r=2745MiB/s,w=2703MiB/s][r=2744,w=2702 IOPS][eta 00m:00s] iops-test-job: (groupid=0, jobs=6): err= 0: pid=415743: Wed Dec 29 22:20:30 2021 read: IOPS=2791, BW=2792MiB/s (2927MB/s)(164GiB/60006msec)Разумеется, если я снижаюсь до 4k, то получаем сильное проседание по bandwidth, но если учесть что это виртуалка и на одном хосте их много, то оверхед и общая нагрузка сильно портят картину:
# fio --filename=/fio.test --size=20G --direct=1 --rw=randrw --bs=4k --ioengine=libaio --iodepth=8 --iodepth_batch_submit=8 --runtime=60 --numjobs=6 --time_based --group_reporting --name=iops-test-job --eta-newline=10Jobs: 6 (f=6): [m(6)][20.0%][r=96.8MiB/s,w=97.9MiB/s][r=24.8k,w=25.1k IOPS][eta 00m:48s] Jobs: 6 (f=6): [m(6)][38.3%][r=98.9MiB/s,w=99.9MiB/s][r=25.3k,w=25.6k IOPS][eta 00m:37s] Jobs: 6 (f=6): [m(6)][56.7%][r=99.7MiB/s,w=99.7MiB/s][r=25.5k,w=25.5k IOPS][eta 00m:26s] Jobs: 6 (f=6): [m(6)][75.0%][r=111MiB/s,w=111MiB/s][r=28.4k,w=28.3k IOPS][eta 00m:15s] Jobs: 6 (f=6): [m(6)][93.3%][r=107MiB/s,w=106MiB/s][r=27.3k,w=27.2k IOPS][eta 00m:04s] Jobs: 6 (f=6): [m(6)][100.0%][r=105MiB/s,w=105MiB/s][r=26.8k,w=26.8k IOPS][eta 00m:00s] iops-test-job: (groupid=0, jobs=6): err= 0: pid=415775: Wed Dec 29 22:29:51 2021 read: IOPS=26.2k, BW=102MiB/s (107MB/s)(6134MiB/60002msec)Очевидно что результаты, как вы выразились, "не впечатляющие", но если туда поставить обычные (не NVMe) SSD, они станут в несколько раз менее впечатляющими, а если учесть любовь некоторых хостеров строить хосты на ZFS, то всё совсем может оказаться печально (принудительный COW даже на блочных устройствах, компрессия и прочие радости — зато типа "супер надёжно").
Для сравнения — вот результат от OVH (VPS Comfort), где они тоже пишут про NVMe:
fio --filename=/fio.test --size=20G --direct=1 --rw=randrw --bs=4k --ioengine=libaio --iodepth=8 --iodepth_batch_submit=8 --runtime=60 --numjobs=6 --time_based --group_reporting --name=iops-test-job --eta-newline=10Jobs: 6 (f=6): [m(6)][18.3%][r=60.8MiB/s,w=61.6MiB/s][r=15.6k,w=15.8k IOPS][eta 00m:49s] Jobs: 6 (f=6): [m(6)][36.1%][r=63.4MiB/s,w=62.5MiB/s][r=16.2k,w=16.0k IOPS][eta 00m:39s] Jobs: 6 (f=6): [m(6)][52.5%][r=62.7MiB/s,w=62.5MiB/s][r=16.0k,w=16.0k IOPS][eta 00m:29s] Jobs: 6 (f=6): [m(6)][68.9%][r=61.9MiB/s,w=62.5MiB/s][r=15.8k,w=16.0k IOPS][eta 00m:19s] Jobs: 6 (f=6): [m(6)][85.2%][r=61.0MiB/s,w=62.5MiB/s][r=15.9k,w=16.0k IOPS][eta 00m:09s] Jobs: 6 (f=6): [m(6)][100.0%][r=63.0MiB/s,w=62.5MiB/s][r=16.1k,w=16.0k IOPS][eta 00m:00s] iops-test-job: (groupid=0, jobs=6): err= 0: pid=3963560: Wed Dec 29 22:11:02 2021 read: IOPS=15.0k, BW=62.4MiB/s (65.4MB/s)(3743MiB/60003msec)Очень похоже что что они ограничивают iops до 16k (слишком ровные результаты), соответственно при блоках в 4k сильно проседает и bandwidth. То же самое для 1M:
fio --filename=/fio.test --size=20G --direct=1 --rw=randrw --bs=1m --ioengine=libaio --iodepth=8 --iodepth_batch_submit=8 --runtime=60 --numjobs=6 --time_based --group_reporting --name=iops-test-job --eta-newline=10Jobs: 6 (f=6): [m(6)][19.7%][r=1048MiB/s,w=1055MiB/s][r=1047,w=1054 IOPS][eta 00m:49s] Jobs: 6 (f=6): [m(6)][36.1%][r=979MiB/s,w=940MiB/s][r=979,w=940 IOPS][eta 00m:39s] Jobs: 6 (f=6): [m(6)][52.5%][r=1052MiB/s,w=961MiB/s][r=1051,w=961 IOPS][eta 00m:29s] Jobs: 6 (f=6): [m(6)][68.9%][r=1057MiB/s,w=961MiB/s][r=1056,w=961 IOPS][eta 00m:19s] Jobs: 6 (f=6): [m(6)][85.2%][r=1059MiB/s,w=1006MiB/s][r=1058,w=1005 IOPS][eta 00m:09s] Jobs: 6 (f=2): [f(1),m(1),f(3),m(1)][96.8%][r=973MiB/s,w=1050MiB/s][r=973,w=1049 IOPS][eta 00m:02s] iops-test-job: (groupid=0, jobs=6): err= 0: pid=3963793: Wed Dec 29 22:13:57 2021 read: IOPS=1000, BW=1000MiB/s (1049MB/s)(58.7GiB/60036msec)Тут уже видно что идёт ограничение по bandwitdh (слишком уж "ровно" оно на протяжении всего теста) — и это в два-три раза менее впечатляюще чем у Hetzner.
Собственно, я и тесты-то сделал не чтобы показать что в виртуалке можно получить максимум от NVMe — за счёт виртуализации это практически невозможно (очень большой оверхед по дороге к накопителю, особенно если виртуалок много), но использование NVMe вполне оправданно — потому что без них всё будет намного хуже, как минимум в разы, а на загруженных по i/o хостах может даже на один-два порядка — по той простой причине что условные 500K iops на NVMe дадут по 50k iops на десяти виртуалках, в то время как не менее реалистичные 100k на "обычных" SSD дадут соответственно по 10k, да и скорость поделится соответственно.
В качестве иллюстрации оверхеда (домашний сервер, PNY CS3030 1T как накопитель, KVM в proxmox), на этот раз на чтении:
fio --filename=/dev/sda --size=20G --direct=1 --rw=randread --bs=4k --ioengine=libaio --iodepth=8 --iodepth_batch_submit=8 --runtime=60 --numjobs=6 --time_based --group_reporting --name=iops-test-job --eta-newline=10 --readonlyJobs: 6 (f=6): [r(6)][20.0%][r=592MiB/s,w=0KiB/s][r=152k,w=0 IOPS][eta 00m:48s] Jobs: 6 (f=6): [r(6)][38.3%][r=591MiB/s,w=0KiB/s][r=151k,w=0 IOPS][eta 00m:37s] Jobs: 6 (f=6): [r(6)][56.7%][r=588MiB/s,w=0KiB/s][r=150k,w=0 IOPS][eta 00m:26s] Jobs: 6 (f=6): [r(6)][75.0%][r=596MiB/s,w=0KiB/s][r=152k,w=0 IOPS][eta 00m:15s] Jobs: 6 (f=6): [r(6)][93.3%][r=595MiB/s,w=0KiB/s][r=152k,w=0 IOPS][eta 00m:04s] Jobs: 6 (f=6): [r(6)][100.0%][r=596MiB/s,w=0KiB/s][r=152k,w=0 IOPS][eta 00m:00s] iops-test-job: (groupid=0, jobs=6): err= 0: pid=15829: Wed Dec 29 22:44:38 2021 read: IOPS=150k, BW=586MiB/s (614MB/s)(34.3GiB/60001msec)Это гораздо более впечатляюще чем у Hetzner, но — это сервер на котором нет нагрузки, он фактически простаивает, да и процессор на нём в пару раз пошустрее (а он важен для пути накопитель=>lvm=>vm и обратно). Теперь тот же fio на хосте через LVM который подцеплен к виртуалке:
fio --filename=/dev/mapper/npve-vm--222--disk--0 --size=20G --direct=1 --rw=randread --bs=4k --ioengine=libaio --iodepth=8 --iodepth_batch_submit=8 --runtime=60 --numjobs=6 --time_based --group_reporting --name=iops-test-job --eta-newline=10 --readonlyJobs: 6 (f=6): [r(6)][19.7%][r=893MiB/s][r=229k IOPS][eta 00m:49s] Jobs: 6 (f=6): [r(6)][36.1%][r=886MiB/s][r=227k IOPS][eta 00m:39s] Jobs: 6 (f=6): [r(6)][54.1%][r=892MiB/s][r=228k IOPS][eta 00m:28s] Jobs: 6 (f=6): [r(6)][72.1%][r=889MiB/s][r=228k IOPS][eta 00m:17s] Jobs: 6 (f=6): [r(6)][90.2%][r=893MiB/s][r=229k IOPS][eta 00m:06s] Jobs: 6 (f=6): [r(6)][100.0%][r=900MiB/s][r=231k IOPS][eta 00m:00s] iops-test-job: (groupid=0, jobs=6): err= 0: pid=2993571: Wed Dec 29 22:46:47 2021 read: IOPS=229k, BW=895MiB/s (938MB/s)(52.4GiB/60001msec)Как видите, просто за счёт того что это виртуалка, мы уже теряем около 40%(!) — и это она одна, другой нагрузки в системе нет и даже отключены все митигации как на хосте так и на виртуалке (mitigations=off) — разумеется если виртуалок с десяток или два, они что-то делают, а поскольку это хостер то и митигации по полной программе — мы просядем ещё больше, но это проседание будет намного менее заметным чем в случае SATA/SAS.
Так что если кто-то говорит что "VPS получит скорость NVMe" — он скорее всего таки врёт, но если этот кто-то говорит "на наших хостах стоят NVMe и это сильно повышает производительность [чем если бы стояли SATA/SAS]" — то это всё же скорее всего правда — об этом говорит и опыт с хостерами, и собственный (правда, не на Hyper-V).
Про RAID для NVMe тоже смешанные чувства — конечно, "один раз не считается", но я для эксперимента делал softRAID1 (mdadm) на двух потребительских NVMe (PNY CS3030 1T, посаженных на один PCIe x16 слот в X470D4U + Ryzen 3600X), разницы в скорости практически не было (при записи), рандомное чтение было быстрее но не помню на сколько — и это совсем не серверное железо. Увы, это было относительно давно, сборки уже нет, а результаты я не сохранял — но успех этого эксперимента позволяет мне верить что заявленное Hetzner наличие RAID 10 на их cloud серверах очень реалистично, вопреки выводам в статье про невозможность (или нецелесообразность) RAID на NVMe.

nikweter
30.12.2021 04:15А почему вы считаете что softRAID1 (mdadm) на двух потребительских NVMe должен давать увеличение производительности? Это ведь зеркало, оно надежность увеличивает. А производительность — та же, даже падает немного.
AlexGluck
30.12.2021 04:35Человек хочет параллельного чтения с дисков при рейд 1. Кейсы где только чтение и в большом количестве существуют. Но для текущих вычислительных систем чтение 7гб/с (pcie4x4) для нвме практически нецелесообразно увеличивать. Гораздо лучше обеспечить горизонтальный рост, вместо вертикального.
borovinskiy
30.12.2021 15:30Выполнил пример для Hetzner NVMe на Intel DC S3500 SATA, подключенным как JBOD через контроллер. Proxmox, ZFS, LXC, CentOS8.
fio --filename=/fio.test --size=20G --direct=1 --rw=randrw --bs=4k --ioengine=libaio --iodepth=8 --iodepth_batch_submit=8 --runtime=60 --numjobs=6 --time_based --group_reporting --name=iops-test-job --eta-newline=10Результат в 3 раза ниже, чем у вас:
latency 31 мкс, IOPS 10k, bw 40 MB/s
Если бы вместо LXC был KVM, еще бы в 1.5-2 раза упало бы все.
Правда конечно бы на актуальных SSD сравнить c SATA и NVMe. Но похоже что да, есть смысл в NVMe.
З.Ы. При использовании Proxmox ZFS выбирают за бесплатные снапшоты с локальных дисков для контейнеров, а не за супернадежность.Tangeman
31.12.2021 05:14На актуальных всё точно также — собственно, это и меня и сподвигло перейти на NVMe в своё время, это было небо и земля даже для чисто экспериментальных проектов с кучей VM (хотя изначально я тоже был скептически настроен).
Окрылённый полученным опытом я посоветовал давнему клиенту тоже попробовать (он периодически жаловался на производительность, несмотря на то что в системе были только SSD) — в итоге он остался доволен как слон и сказал что субъективно ощущения как после пересадки с HDD на (первые) SSD — хотя конечно это зависит от задач (у него сильно нагруженный i/o кластер с k8s).
Proxmox ZFS выбирают за бесплатные снапшоты
В чём их бесплатность по сравнению с LVM thin? Да и при любом раскладе это "бесплатно" только для хостера, для клиентов это боль если (к примеру) у них там нагруженные базы или ещё что-то чему вредит COW.
ZFS и так не быстрая, и лучшее ей применение это NAS & co, где данные редко модифицируются "по месту" (бэкапы и прочее), если её ставить на хостинг и там хорошая активность — это просто смерть производительности даже на NVMe, и это при выключенных компрессии и дедупликации, а с ними это вообще ужас-ужас — в начале всё ок но со временем за счёт фрагментации всё начинает тормозить просто ужасно, особенно если памяти на ARC не десятки гигабайт и процессор не очень многоядерный.
Также при тестах из ВМ есть риск, что чтение будет из ОЗУ хоста.
Риск есть только если хост принудительно включает кэш и игнорирует direct i/o — я очень сомневаюсь что Hetzner это делает, не говоря уже о том что это приводит к сильному "загрязнению" памяти хоста всяким мусором и в целом плохо сказывается на всех (любая VM может загнать в swap хост и сильно помешать соседям — объём кэша на процесс/пользователя не тюнится, разве что ядро патченное).
Но я делал тесты и по чтению, разумеется — результаты почти идентичны (разница в пару процентов).
Для полноты картину, вот результаты тестирования с /dev/ram0 (на той же VM):
# fio --filename=/dev/ram0 --size=1G --direct=1 --rw=randrw --bs=4k --ioengine=libaio --iodepth=8 --iodepth_batch_submit=8 --runtime=10 --numjobs=6 --time_based --group_reporting --name=iops-test-job --eta-newline=1Jobs: 6 (f=6): [m(6)][30.0%][r=1307MiB/s,w=1315MiB/s][r=335k,w=337k IOPS][eta 00m:07s] Jobs: 6 (f=6): [m(6)][50.0%][r=1256MiB/s,w=1258MiB/s][r=321k,w=322k IOPS][eta 00m:05s] Jobs: 6 (f=6): [m(6)][70.0%][r=1244MiB/s,w=1243MiB/s][r=319k,w=318k IOPS][eta 00m:03s] Jobs: 6 (f=6): [m(6)][90.0%][r=1188MiB/s,w=1185MiB/s][r=304k,w=303k IOPS][eta 00m:01s] Jobs: 6 (f=6): [m(6)][100.0%][r=1326MiB/s,w=1329MiB/s][r=339k,w=340k IOPS][eta 00m:00s] iops-test-job: (groupid=0, jobs=6): err= 0: pid=420764: Fri Dec 31 02:51:52 2021 read: IOPS=323k, BW=1261MiB/s (1322MB/s)(12.3GiB/10001msec)Так что очень маловероятно что хост кэширует что-то — даже с учётом оверхеда виртуализации это было в пусть в два-три раза медленней, но явно не на порядок.
creker
31.12.2021 13:49В чём их бесплатность по сравнению с LVM thin? Да и при любом раскладе это "бесплатно" только для хостера, для клиентов это боль если (к примеру) у них там нагруженные базы или ещё что-то чему вредит COW.
В том, как ZFS внутри устроена. По сути, нужно лишь "форкнуть" дерево блоков. COW сделает все остальное.
Не сказал бы, что COW вредит базами. Наоборот. COW идеально сочетается с базами, т.к. они повсеместно пишут WAL. Что базы, что ZFS стараются не модифицировать то, что уже есть на диске. По крайней мере те базы, что были разработаны под HDD. По идее, если грамотно подобрать размер блока, то оверхед будет минимальный. Компрессия тут конечно немного жизнь подпортит. А уж про дедупликацию вообще надо забыть сразу. Никто ее не рекомендует использовать и поделом.
borovinskiy
30.12.2021 21:36Также при тестах из ВМ есть риск, что чтение будет из ОЗУ хоста.
Здесь совет такой, что отдельно измерить скорость чтения и записи и сравнить. Если скорости отличаются в 10 раз и скорость чтения близка к скорости чтения ОЗУ, очевидно чтение из ОЗУ и происходит.
thatsme
31.12.2021 12:14ZFS очень агрессивен в кэшировании (direct i/o игнорирует), так что если памяти у вас достаточно (32GB или больше) вы меряете производительность самой файловой системы, а не накопителя. Поставьте ограничение на ARC чтобы файл в него точно не влезал, и добавьте
--fsync=1кfio(убедившись что в ZFS не стоитsync=disabled) — тогда тест будет более реалистичным.Нет в ZFS не выключен sync. Отдельного ZIL на SSD или отдельных дисках нет. ARC к записи не имеет отношения, а ZIL пишется всегда sync. В дополнение engine в fio sync, а у вас libaio. Я специально во всех тестах sync eingine использовал. fsync на каждом блоке будет i/o scheduler ZFS просто ломать оптимизацию ZIL.Надёжности записи не добавит, а производительность снизит.
С другой стороны на SSD тоже нужно с теми-же параметрами проверять с fsync и sync engine, и также печально будет себя вести deadline IO scheduler ядра.
С другой стороны RAID-10 на SATA SSD или SAS SSD дисках даст значительный прирост к производительности относительно NVME (от кол-ва дисков конечно зависит, но прелесть SAS в том, что он серийный). Т.е. на 24Gbit SAS вы имеете шанс все это 24Gbit выжать из набора дисков. А RAID на NVME не даст никаких плюсов, т.к. всё упрётся в UPI и то как линии UPI разведены.
creker
31.12.2021 13:36также печально будет себя вести deadline IO scheduler ядра.
Поэтому для ssd нужно шедулер noop ставить и все будет хорошо. Для pcie дисков так вообще смерти подобно.
С другой стороны RAID-10 на SATA SSD или SAS SSD дисках даст значительный прирост к производительности относительно NVME (от кол-ва дисков конечно зависит, но прелесть SAS в том, что он серийный). Т.е. на 24Gbit SAS вы имеете шанс все это 24Gbit выжать из набора дисков. А RAID на NVME не даст никаких плюсов, т.к. всё упрётся в UPI и то как линии UPI разведены.
Оно в обоих случаях упрется в UPI линии для софтового рейда, а если SAS контроллер аппаратный, то еще в шину до него и в возможности самого контроллера, который в топовых вариантах выше 1млн IOPS не прыгнет. Я это уже проходил, когда собирал raid0 из sata ssd. Все упирается в контроллер, который еле вывозит десяток дисков. Скоро будем собирать на pcie дисках. Посмотрим на разницу.

PocketM
29.12.2021 01:47+3Я правильно понял, что у вас для виртуализации Hyper-V используется? Это только часть виртуалок крутиться в нем или весь хостинг на нем построен?
Если последнее, то можете рассказать по причинах/приемуществах его использования? В особеннности интересует окупаемость лицензий.

13werwolf13
29.12.2021 07:37+1не подумать о numa это прям проблема новичка, в любом хостере админы очень быстро натыкаются на это неочень но узкое горлышко, я на первых строках статьи уже подумал об этом.. как то вы долго доходили
мы когда ceph тюнили до 100гигвсек быстро нащупали numa, задолго до того как достигли желаемых результатов
и второй момент: виндовый жиперви, сириусли?!?!?!?

SexTools
29.12.2021 14:52Блин, даже энтепрайзные нвмешки время от времени вылетают. А поднимать данные с бэкапа, даже на нвме дикий даунтайм.
SexTools
29.12.2021 14:54+1Если вы упёрлись в линии чипсета, почему нельзя воткнуть nvme через переходник PCI-E x16 слот? Тем паче, что в переходниках часто и аппаратный рейд может быть на борту.

blaze79
29.12.2021 16:07-1вам было бы полезно почитать про современные линуксовые io-шедьюлеры. там подробно объясняется даже что важен сокет, в котором обратаывается прерывание.
ilmarin77
29.12.2021 16:31+1Я недавно сделал небольшой тест производительности нескольких конфигураций software raid nvm и Sata SSD, на похожем железе

Стандартный mdadm Сравнение с zfs Правда, есть подозрение что на той версии zfs что у меня была флаг O_DIRECT типа продолжается, но не честно.
ilmarin77
29.12.2021 16:52Второй график неправильный
borovinskiy
30.12.2021 23:58На графиках ZFS local чтение наверняка из ОЗУ идет.
ilmarin77
31.12.2021 01:06может быть, в той версии ZFS что у меня ( zfs-0.8.3-1ubuntu12.13 zfs-kmod-0.8.3-1ubuntu12.13 ) , поддержка флага O_DIRECT может быть кривая.

knutov
31.12.2021 01:58Её там вообще нет, он просто игнорируется. Поэтому всё ZFS на NVME медленновато из-за ARC (а с крутящимися дисками - наоборот, быстрее с ZFS).
В openzfs 3.0 обещают добавить полноценную поддержку O_DIRECT.
borovinskiy
30.12.2021 22:45А можете уточнить объем дисков (чтобы их ТТХ посмотреть) и что за модель контроллера была.
Пока из того, что я вижу:
1) у ZFS на 4k медленная запись.
2) при подключении по NFS разницы между NVMe и SATA не очень видно (сопутствующие расходы на сеть и реализацию NFS дороже).
3) разница между 10G и 100G при работе по NFS не слишком заметна.ilmarin77
31.12.2021 01:05железо:
1: Supermicro SYS-2029U-TN24R4T : Supermicro X11DPU ; Xeon Silver 4108 CPU x2; SSD INTEL SSDPE2KX080T8 x 6
2: Nvidia DGX-1: Xeon E5-2698 v4 x2 ; LSI MegaRAID SAS-3 3108 ; SSD SATA Samsung PM863 x4
При NFS - так и есть. Скорость удаётся поднять только если использовать RDMA, но в моём случае работало нестабильно ( периодически вешало систему).




foi
29.12.2021 19:53Не встречал подобного опыта что обнаружил я - как ведут себя различные фс на программном рейде 1, 10, 5, 6 из nvme дисков (про аппаратный даже и говорить не стоит, там никакая производительность), так вот - на ext4 производительность в любом рейде только падала по сравнению даже с 1 диском, в то же время на xfs почти что кратно количеству дисков в массиве возрастала. Тестил на серверах amd epyc rome 2 с кучами u.2 nvme дисков.
amarao
Используйте устройства не из низшего ценового сегмента. Интеловые DC-grade NVME накопители объективно выдают показатели, недостижимые для других шин (sas, sata). В любом из бенчмарков.
Софтрейд роняет производительность nvme, и это легко обнаружить, если собрать raid0 из 1920 ramd-disk'ов. Для двух дисков падение производительности не такое радикальное.
При тестировании nvme критически важным становится время выполнения системного вызова. Попробуйте использовать ПО с поддержкой io_uring, а ещё лучше, ОС, которая запускает ELF-файлы, а не 'е-хе'.
Перед тем, как измерять производительность nvme, проверьте, что ваши утилиты такое выдержат. null_blk - хорошее начало. Тот же fio начинает страдать на 3-4 миллионах iops'ов, а теоретический лимит имеет в 20 миллионов (на null устройстве без вызовов ядра).
creker
У них тут как раз все ок. Если все как в прошлой статье, то они используют Intel SSD DC P4610 Series 1.6TB, 2.5in PCIe 3.1 x4, 3D2, TLC Круче уж некуда.
amarao
Тогда я не понимаю, как они сумели "разогнать" SAS/SATA до PCI-E скоростей. Вот так вот взять и выдать 3ГБ/с на sas? Не верю. Так же как и в 500к IOPS на sata (потому что при 4к блоках это 2ГБ/с).
ntsaplin Автор
Мы подключали диски к PCI-E через U.2 интерфейс, в статье это указано. Более того приведена диаграмма разводки линий материнской платы.
amarao
А вы производительность виртуализации-то тестировали? Я вот с интересом наблюдал разницу в 10 раз в работе nullblk между бареметаллом и VM (при том, что nullblk вообще никаких внешних устройств не требует). latency переключения userspace/kernel у VM кратно выше, чем у BM, и чем лучше nvme, тем больше это начинает влиять.
ntsaplin Автор
Тестировали, но там тесты другого плана. Создается множество виртуальных машин, чтобы забить сервер «под завязку». На всех ВМ одновременно запускается тест диска. После этого собирается суммарный результат со всех виртуалок. Суммарный результат будет ниже чем при тестах с хостовой машины, но не принципиально. В рамках отдельной ВМ, производительность намного ниже, чем на «бареметалле».
amarao
Тогда я не понимаю с какой sas/sata SSD вы сумели 500000 IOPS получить, чтобы жаловаться, что "единицы процентов по сравнению с обычными SSD".
borovinskiy
NVMe вроде хвалят за низкую латентность. Если ядро часто переключает контекст и латентность переключения много больше NVMe, то подозреваю, что наоборот, разница между SATA SSD и NVMe будет труднее обнаружить.
Кстати, вот пример сравнения Baremetal https://elibsystem.ru/node/503 с Hyper-V, KVM на SATA SSD c древним контроллером, но и там довольно хорошо видна сильная зависимость производительности от гипервизора.
Вообще надо понять что тестировать-то хочется.
Абстрактную производительность NVMe? Производительность NVMe в Hyper-V в одиночной ВМ (не убивает ли оверхед Hyper-V низкую задержку NVMe)? Производительность NVMe при большом количестве ВМ, все из которых одновременно генерируют нагрузку по сравнению с SATA (качественное сравнение есть ли разница при большой нагрузке в условиях конкуренции кучи ВМ за CPU и NVMe)? Во всех трех случаях очевидно методика тестирования разная.
Более того, от того пишутся ли данные синхронно или последовательно тоже результаты бенчмарка зависят, а тут сюрприз, SSD часто нужны для баз данных, а РСУБД пишут часто последовательно (потому-что в журнал) малым количеством потоков с частыми fsync. Т.е. базы данных даже близко не выдают максимально возможные IOPS-ы на запись.
Дальше надо понимать, что NVMe хороши низкой задержкой. Но! Но когда 100500 ВМ генерируют параллельно нагрузку и утилизируют SSD в полку, общая пропускная способность конечно будет высокой (у SSD чем больше одновременных потоков - тем больше IOPS и мегабайт), но вот задержки начнут сильно нарастать, а в статье задержки вообще не представлены! Т.е. при миллионе IOPS задержки какие? Вот для примера про латентность от Intel:
Поэтому зная, что все зависит от всего (производительность от нагрузки случайная/последовательная, размера кластера, как часто fsync шлется, размера очереди, конкуренции за CPU множества ВМ, драйверов, ФС, гипервизора, writeback, способности ВМ читать из ОЗУ вместо диска из-за виртуализации и т.д.) надо, ну если хочется во всех этих аспектах посмотреть что происходит, делать не один тест, а на каждую из задач по тесту.
Естественно, синтетика с большим количеством очередей может совершенно не походить по профилю нагрузки на поведение баз данных. Так что логично поинтересоваться у клиентов какие базы гонять собираются и побенчмаркать базы на NVMe/SATA и посмотреть, есть ли разница. Естественно начинаются приколы, что SATA будет контроллер использовать и он тоже может и свои настройки иметь и задеркжи и т.д.
Итого: непростое это дело производительность дисковой подсистемы измерять!
edo1h
при времени доступа к nand >>50 мкс задержки шины уже особой роли не играют
borovinskiy
Все немного сложнее получается. Появляется дополнительный программный слой и дополнительный аппаратный (контроллер).
Только вчера читал тестирование PostgreSQL 2014 года и на SATA у них было что-то там 50 тыс. tps, а на NVMe 400 тыс. tps, а в RAM если диск держать 1500 тыс. tps.
Люди смотрят на такие бенчмарки и хотят, конечно, NVMe и почти x10 к работе базы.
edo1h
вы про sata?
так и nvme не обходится без программного слоя )
да, на один контроллер в цепочке cpu — nand в случае nvme меньше, но узким местом является не наличие контроллера само по себе, а достаточно узкая шина между ним и накопителем.
ну это очень специфичная нагрузка, почти наверняка синтетика.
ноги растут из hdd: в те времена запросы накопители обрабатывали долго, накапливалась очередь. так как время доступа определяется механикой, то единственным способом улучшить производительность было увеличение числа шпинделей, а большие очереди — с одной стороны нормой, с другой — единственным способом утилизировать потенциальную производительность дисковой системы.
с приходом ssd ситуация в корне поменялась, среднее время доступа из 5-10 мс стало 50-100 мкс, то есть на два порядка ниже (притом, как я писал выше, оно определяется nand, и особо не зависит от интерфейса); плюс оно практически не растёт до до некоторого порога нагрузки (на hdd оно растёт лавинообразно при qd>1 на шпиндель), в результате выигрыш в производительности в сравнении с hdd несколько порядков.
в итоге, до некоторой (и достаточно большой для реальной жизни) нагрузки все ssd независимо от интерфейса примерно одинаковы, потом сдаётся sata, потом sas, ну а у nvme самый высокий потенциал.
ну так вот, привычка тестировать дисковую подсистему с глубиной очереди 100500 никуда не делась со времён hdd, только к реальным нагрузкам это тестирование имеет мало отношения.
условная аналогия: мы сравниваем суперкары по скорости разгона с 200 км/ч до 300 км/ч, да, это сравнение покажет какой кар круче, но к скорости передвижения в городском потоке это будет иметь мало отношения (скорость разгона до 80 км/ч, более актуальная в городе, у них, скорее всего, окажется примерно одинаковой).
P. S. весь этот текст был про случайный доступ, на последовательном sata сдаётся достаточно рано, на каких-нибудь бэкапах разница между sata и sas/nvme может быть видна невооружённым глазом.
P. P. S. с другой стороны, сегодня nvme накопители обычно стоят примерно как sata, поэтому выбирать sata никакого смысла нет. sas ssd же вообще для меня какая-то экзотика )
borovinskiy
Postgres там наверняка тестировали "стандартным" pgbench.
С малой глубиной ни о каких 1+ млн. IOPS или 7 ГБ/c не может быть и речи. Так что это не привычка, а маркетинг -)
borovinskiy
Вот для примера латентность на корпоративном SSD Intel вот отсюда.
Вот еще пример того же источника, что разные SSD могут себя сильно по разному вести при записи.
А это пример пользовательского SSD, у которого латентность 5 мс (как у HDD) уже при 25 тыс. IOPS.
Латентность - важная величина. NVMe для баз данных именно за нее и выбирают (NAND-то одинаковая и в SATA и в NVMe). Поэтому её стоит приводить в бенчмарках.
edo1h
так это не sata виновата, это накопитель такой )
запустил на своём s3510 чтение в 4 потока, получил 30к iops и задержки 130 мкс. в 8 потоков 150 мкс. в 16 250 мкс (вот тут уже начал насыщаться контроллер на ssd; напоминаю, что это накопитель начального уровня).
заметьте, до насыщения шины ещё далеко, она не утилизирована ещё и наполовину, так что дело точно не в шине, а в самом накопителе.
на самом деле время доступа/иопсы/мегабайты в секунду элементарно пересчитываются друг в друга.
из теста в предыдущем абзаце 130 мкс задержки в 4 потока на блоках 4 КБ эквиваленты 4/130e-6 ≈ 30к iops или же 120 МБ/с.
напомню, что я изначально написал
при qd=1 время доступа чтения будет примерно 100 мкс что на sata, что на nvme накопителях.
и при qd=4, и при qd=8 тоже, я вам показал. и даже при qd=16 цифры сопоставимы.
да, при qd=1024 время доступа у nvme будет в разы меньше (а иопсы пропорционально выше), но если у вас на сервере qd=1024, то, скорее всего, что-то пошло не так.
на своих нагрузках разницу между sata и nvme накопителями в БД я вижу только в задачах вроде бэкапов; в типичной нагрузке на базу данных (если там нет seqscan'ов) разницы нет.
впрочем, повторюсь, сейчас sata ssd по сути уже не дешевле nvme, так что смысла выбирать sata нет.
borovinskiy
Зная IOPS можно узнать и пропускную способность, умножив IOPS на размер блока. 30 000 IOPS x 4K = 120 000 K/s. = 117 MB/s.
А вот как латентность вычислить из IOPS? Графики выше явно говорят, что зависимость не линейная, т.е. вычислить латентность из IOPS нельзя.
Вернее так, если у вас бенчмарк имеет глубину 1 и 1 очередь, то да, время за которое у вас выполнится одна операция и придет подтверждение ее выполнения и является латентностью по определению. Т.е. 1/(число IOPS) = время 1 операции.
По мере роста глубины и потоков у вас латентность становится больше среднего времени выполнения операций за некоторое время. Т.е. вычислять латентность при Q>1 и T>1 делением 1 на IOPS нельзя.
edo1h
IOPS=QD/latency
небольшая ошибка набегает из-за усреднений, но обычно это единицы процентов.
borovinskiy
Результаты
Очередь 10, IOPS 5000, Вычисляем по формуле latency = QD/IOPS = 2 мс. А измеренная по бенчмарку 5-8 мс с большим среднеквадратичным отклонением.
borovinskiy
Это можно и наглядно показать, что просто так задержку не стоит из IOPS вычислять.