
Наша компания пишем много отчётов (такое бывает, когда вы занимаетесь хакингом). При этом часто требуется скрывать часть текста. У нас уже давно действует политика, по которой при сокрытии текста для надёжности следует использовать только чёрные полосы. Иногда люди хотят проявить себя используют такие методики удаления данных, как размытие, искажение или пикселизация. Но это ошибка.
Сегодня мы рассмотрим одну из таких методик — пикселизацию, и покажем, почему это плохой, небезопасный, гарантированный способ обеспечения утечки данных. Чтобы продемонстрировать, как это происходит, я написал инструмент под названием Unredacter. Он получает отредактированный пикселизированный текст и возвращает его в исходный вид. В реальном мире люди часто используют пикселизацию, но тыкать пальцем мы сейчас ни в кого не будем.
Вызов принят
Существует инструмент под названием Depix, который пытается выполнить ту же задачу при помощи хитрого процесса поиска перестановок пикселей, которые могли бы привести к получению пикселизированных блоков, имея последовательность де Брёйна соответствующего шрифта. Мне очень нравится теоретическая часть этого инструмента, но исследователь из Jumpsec указал на то, что иногда на практике он работает не так хорошо, как ожидалось. В реальных примерах с большой вероятностью возникают незначительные вариации и шум, мешающие работе алгоритма. Jumpsec объявила соревнование, предложив приз тому, кто сможет расшифровать следующее изображение:

Как я мог отказаться от такого вызова?!
Принцип действия пикселизации
Пикселизация выглядит так:
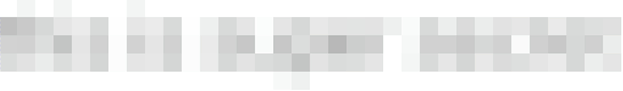

Алгоритм довольно прост; мы разделяем изображение на сетку с заданным размером блоков (в примере выше это 8x8). Затем для каждого блока мы задаём цвет отредактированного изображения равным усреднённому цвету исходных данных той же области. Вот и всё, просто скользящее среднее пикселей в каждом блоке.

Этот эффект как бы «размазывает» информацию изображения по каждому блоку. Однако хотя часть информации в процессе теряется, другая часть всё равно утекает. И эту утекшую информацию мы можем применить для своей выгоды.
Примечательно, что этот алгоритм из-за своей простоты широко стандартизован. То есть, редактируете ли вы изображение в GiMP, Photoshop или практически в любом другом инструменте, результат окажется одинаковым.
Для нашего proof-of-concept допустим, что нападающий знает:
- Тип шрифта отредактированного текста
- Размер шрифта отредактированного текста
- Что редактировался именно текст
Это вполне логичные допущения, так как в реалистичном сценарии нападающий с большой вероятностью получил полный отчёт, из которого вырезали только одну часть. В представленном для соревнования тексте непосредственно над пикселизированным текстом мы видим несколько слов, выдающих эту информацию.
Множество проблем борьбы с редактурой
Самое важное заключается в том, что процесс редактирования является локальным. С точки зрения криптографии можно сказать, что он не имеет диффузии. Изменение в одном пикселе исходного изображения влияет только на отредактированный блок, к которому он относится, то есть мы можем (чаще всего) распознавать изображение символ за символом. Мы проведём рекурсивный поиск в глубину для каждого символа, оценивая каждую догадку на предмет того, насколько хорошо она соответствует отредактированному тексту.
Допустим, мы предполагаем, что отредактирована буква «a», пикселизируем её и смотрим, насколько хорошо она соответствует отредактированному изображению. Затем мы предполагаем букву «b», и так далее. Выглядит не так уж сложно, правда? Ну, на самом деле всё равно есть множество логистических проблем, поначалу совсем неочевидных! Давайте разберём их.
Проблема «растекания» символа
Первая проблема, с которой мы сразу сталкиваемся, заключается в том, что символы в тексте не соответствуют 1 к 1 с блоками отредактированного изображения. Это значит, что у верной догадки может оказаться несколько ошибочных блоков по самому правому краю. Взгляните на этот пример:

Мы видим, что буквы «t» и «h» имеют общий столбец блоков. Поэтому если мы попробуем предположить букву «t», то самый левый столбец блоков окажется правильным, а самый правый — немного ошибочным.
Правильные пиксели, догадка «t» и разность

Второй столбец ошибочен из-за буквы «h». Если бы мы рассмотрели его отдельно, то могли бы прийти к выводу, что буква «t» не была верной первой буквой, потому что почти половина её блоков совершенно ошибочна.
Первым делом мы попытались не учитывать самый правый блок в любой догадке. Этот столбец растекается на другие пиксели сильнее всего и может иметь существенную долю ошибки. Проблема этого в том, что на практике такой подход уменьшал общее количество догадок насколько, что мы начали получать ложноположительные результаты. Всегда есть вероятность, что по чистой случайности ваша буква окажется соответствующей, и эта вероятность при уменьшении количества блоков повышается.
Поэтому вместо этого мы отрезали блок сравнения на границе самой буквы. Поэтому наша разность будет выглядеть так:

Как видите, качество совпадений сильно повысилось, потому что мы учитываем меньшую часть неверной области справа. Так происходит, потому что мы прерываем сравнение на границе, где завершается «t»:

Преимущество этого заключается в том, что чем больше наш предполагаемый символ распространяется на блок, тем с большей вероятностью блок будет хорошей догадкой, поэтому мы учитываем бОльшую часть этого блока. Поэтому мы автоматически обрезаем бОльшую часть блока, когда догадка плоха и сохраняем бОльшую часть блока, когда она хороша.
Проблема с пробелами
Подмножеством проблемы растекания символов является то, что пробел нарушает некоторые наши допущения о том, как работает угадывание символов. Неотъемлемой частью всей этой задачи является допущение о том, что когда мы угадываем верный символ, то ожидаем, что его получившаяся пикселизированная версия по большей части напоминает изображение, выданное в соревновании.
Однако это не всегда верно, если угадываемый символ является пробелом. Когда такое происходит, пикселизированные блоки будут полностью захвачены следующим символом. Вот пример, мы делаем предположение, что это «this is » (с пробелом в конце):

Оно пикселизируется следующим образом, как и можно ожидать, висячий пробел остаётся:

Проблема в том, что в изображении с решением после пробела есть ещё один символ. Он растекается настолько сильно, что наша верная догадка кажется совершенно ошибочной!

Эту проблему можно решать разными способами. Наиболее очевидный — никогда не делать предположения о пробелах по отдельности и всегда соединять их с каким-то другим символом. Таким образом мы сможем контролировать растекающийся символ. Хотя это «сработает», такой подход, по сути, вдвое увеличит размер множества доступных символов. Это сильно замедляет весь процесс обработки.
Вместо этого мы можем сделать особое исключение для предполагаемых пробелов, дающее им больший допуск в том, что считается «хорошей» догадкой. При тестировании выяснилось, что растекание никогда не бывает столь сильным, чтобы превзойти нижний порог. Выглядит немного неуклюже, но, похоже, работает.
Проблема шрифта с переменной шириной символов
Большинство шрифтов, которыми пишут люди, имеют переменную ширину символов. Это значит, что пространство по горизонтали, занимаемое каждой буквой, зависит от самой буквы. Например, «w» занимает больше места, чем «i». Противоположностью этому являются моноширинные шрифты, в которых буквы намеренно расставлены так, чтобы каждая занимала одинаковое пространство по горизонтали.
Переменная ширина:
iiiii
wwwww
Моноширинность:
iiiii wwwww
Для нашей атаки (предполагающей использование шрифта переменной ширины) это означает, что каждая предполагаемая буква будет иметь каскадное влияние на то, что находится справа от неё. Если вы сделаете предположение:
this is supww
То все последующие буквы будут смещены, даже если в остальном буквы «правильны».
Кажется, что это очень серьёзно, но на самом деле не всё так плохо. Это просто означает, что нам придётся продолжать использовать рекурсивный поиск в глубину и не рассматривать буквы как отдельные и независимые артефакты. Рекурсивный поиск в глубину хорошо здесь подходит, потому что учитывает порядок. Это работает следующим образом:
Допустим, имеющееся предположение имеет вид:
this is su
Мы попробуем подставлять каждый символ в качестве следующей буквы и посмотрим, какие из них достаточно хорошо соответствуют отредактированному изображению. У нас появится некое подмножество «хороших» догадок, вероятно, «p» и «q», потому что «p» — это верный ответ, а «q» достаточно сильно её напоминает. Затем мы начинаем весь процесс угадывания заново для новой строки «this is sup» вниз по цепочке, пока не наткнёмся на тупик без хороших догадок. На этом этапе стек вызова функции естественным образом вернётся назад, чтобы проверить нашу другую версию — q.
И так далее, пока мы не исчерпаем все «хорошие» догадки.
Проблема непостоянства шрифта
Разные движки рендеринга создают слегка отличающиеся изображения даже для того, что должно быть совершенно одинаковым шрифтом. Взгляните на два скриншота одного текста. Сверху показан рендеринг Sans Serif в GiMP, снизу — в FireFox:

Они почти идентичны, но не полностью. Выделяются два аспекта; во-первых, длина. Можно увидеть, что верхнее изображение чуть длиннее. Для достаточно длинных строк это может иметь каскадный эффект, смещающий всё изображение. Второе отличие заключается в растеризации текста; нижняя строка чуть жирнее верхней. В основном с этим можно справиться изменением яркости, но это настоящее мучение.
В Unredacter мы используем Electron, чтобы делать скриншоты локального безголового окна HTML. То есть в качестве рендерера используется Chrome. Чаще всего это не представляет проблемы. Но если отредактированный текст рендерился программой, не придерживающейся стандартов, то он достаточно сильно может отклониться от курса. Помните об этом.
Проблема смещения пикселизации
При пикселизации изображений есть две степени свободы, которые нужно учитывать: координаты смещения по x и y. Но каковы они?
Рассмотрим изображение угадываемого текста, разделённое на блоки размером 8x8:
Если считать его статичной сеткой, то существует 64 уникальных локации для размещения текста на этой сетке. Мы назовём это «смещением» по x и y. Изображения будут сильно зависеть от выбранного вами смещения:
Разные значений смещения для одного текста

Более того, нападающий никак не может узнать, какими были эти смещения. (В отличие от типа и размера шрифта). Смещение определяется в большинстве редакторов наподобие GiMP по большей мере случайным образом: по тому, куда нажал пользователь при создании прямоугольника выделения. Если он нажал на один пиксель выше или ниже, то пикселизация создаст достаточно отличающееся изображение!
Хорошо здесь то, что возможностей для смещения не так уж много. Всего возможно количество перестановок, равное размеру блока в квадрате. При размере блока 8 нужно будет проверить 64 смещения. В тексте, выданном на соревновании, размер блока равен 5, то есть проверить нужно лишь 25 смещений.

То есть первым делом Unredacter должен выяснить, какое смещение использовалось. Мы делаем это, проверяя каждое смещение в цикле и просматривая наличие любой буквы, найденной в качестве хорошей версии первой буквы. Затем мы берём все смещения, имеющие хорошие версии первой буквы, и добавляем их в список, чтобы далее проверять догадки.
Решение текста соревнования Jumpsec
Отлично! Вооружённые этими знаниями и инструментом для их использования, мы снова взглянем на изображение Jumpsec:

Первым делом мы замечаем странный цвет. Откуда он взялся? Разве там не должны быть только чёрный и белый, потому что текст чёрного цвета? Они троллят нас цветными буквами?
Я не совсем понимаю, почему это происходит (а иногда не происходит), но это артефакт процесса растеризации при рендеринге текста на экран. Посмотрите, что произойдёт, если приблизить текст, введённый в «Блокноте»:

Когда Unredacter рендерит буквы в безголовое окно Chrome, цветных артефактов не появляется, поэтому нам нужно преобразовать изображение в оттенки серого. При этом мы потеряем часть информации, но это нормально. Приложению Unredacter не нужны точные совпадения, а только «в основном правильные» догадки. После преобразования изображение выглядит так:

Далее нужно внести последнее изменение, а именно в нижнем ряду:

Он слишком маленький! Остальные блоки имеют размер 5x5, а нижний — 5x3. Спустя несколько часов проб и ошибок я заметил, что эти блоки слишком тёмные. Посмотрите, как выглядит предполагаемая буква «g» и сравните её с изображением:
Изображение с соревнования и предположение

Видите, что нижний ряд слишком тёмный? Так получилось, потому что в процессе пикселизации был выбран прямоугольник выделения, размер которого не кратен 5. Поэтому при определении алгоритмом среднего он усреднял меньшую область. (Поэтому она и более тёмная.) Но это неважно, мы можем это исправить, просто осветлив нижний ряд. В результате изображение получает следующий вид:

Далее нам нужно определить нужный шрифт и его размер. К счастью, это оказалось не слишком сложно, изображение было сделано в «Блокноте» Windows со стандартным шрифтом Consolas. Путём проб и ошибок я выяснил, что шрифт имеет размер 24px. (Я просто проверял разные размеры шрифтов, пока высота заглавной M не совпала.) Единственная сложность здесь заключалась в том, что в «Блокноте», очевидно, используется стандартное межбуквенное расстояние -0.2px. Если попробовать отрендерить текст в Chrome шрифтом Consolas, он окажется сильно длиннее. Но при letter-spacing в -0.2px он совпадает идеально.
Сверху: исходное изображение с соревнования
Снизу: рендеринг Unredacter в безголовом Chrome
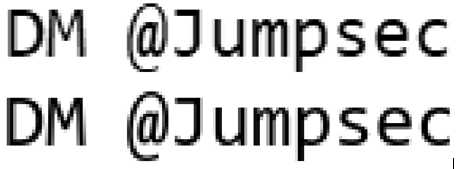
Если приглядеться, можно заметить, что буквы «s», «e» и «c» в рендеринге Notepad имеют бОльшую кривизну. Но это нормально. Повторюсь, нам не нужна точность на 100%. Этого вполне достаточно!
Unredacter достаточно быстро определил смещение [3, 1], посмотрим, к чему это приведёт!
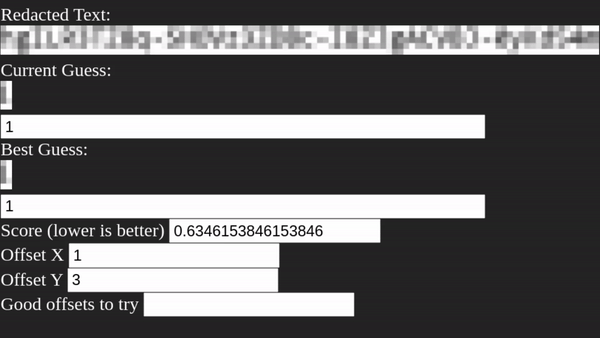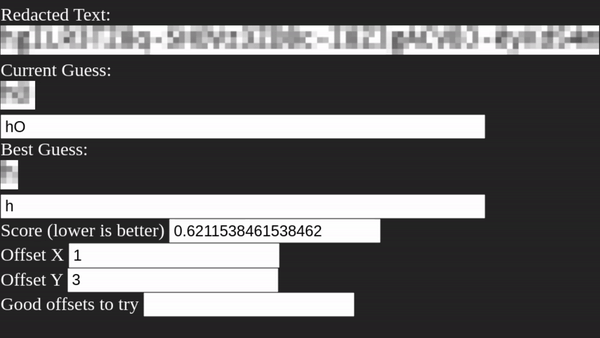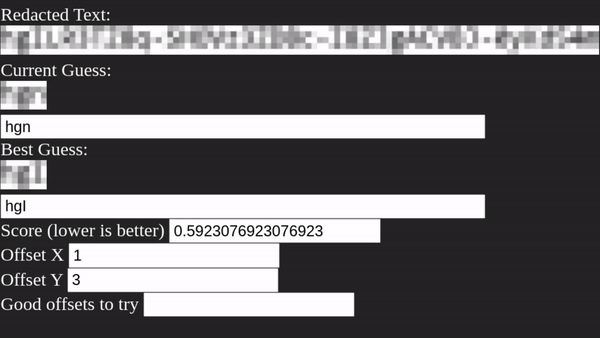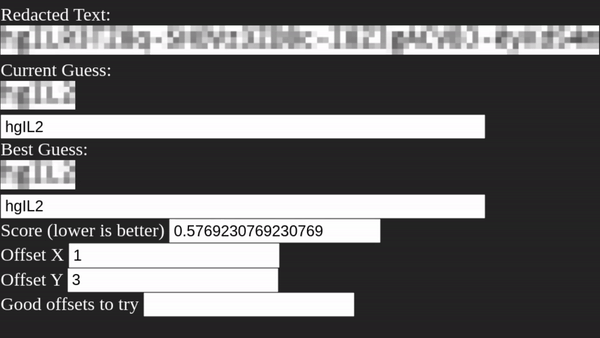
Поработав несколько минут, Unredacter выдал свою окончательную догадку:

Даже невооружённым взглядом видно, что наша догадка достаточно близка!
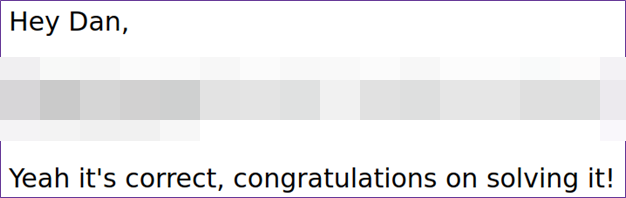
Сверху: исходное изображение с соревнования (в оттенках серого и с исправленным нижним рядом)
Снизу: догадка Unredacter
Я связался с Калебом Хербертом из Jumpsec и он подтвердил, что моя догадка верна!

Кроме того, Калеб попросил меня не раскрывать решение, чтобы вы могли решить загадку сами. (Выше оно размыто, а вы ведь никак не сможете прочитать размытый текст?) Огромное спасибо Jumpsec за это соревнование. И отличный способ протестировать новый инструмент!
Подведём итог
Если вы хотите изучить исходный код proof-of-concept Unredacter, то его можно найти на нашем GitHub.
Вывод заключается в том, что если вам нужно отредактировать текст, то используйте чёрные полосы, закрывающие весь текст. Никогда не пользуйтесь ничем другим. Никакой пикселизации, размытия, фаззинга или искажения. И убедитесь, что редактируете текст как изображение. Не совершайте ошибку, редактируя документ Word так, чтобы он имел чёрный фон с чёрным текстом. (Его всё равно можно прочитать, выделив его.)
Комментарии (36)

0mogol0
11.03.2022 10:47+1Никакой пикселизации, размытия, фаззинга или искажения.
эээ, размытие в режиме Average ничуть не хуже черных полос, просто даёт серые полосы, так как полностью усредняет всё до одного цвета...

masai
11.03.2022 11:25+7Оно даёт информацию о среднем цвете. Например, если злоумышленник каким-то другим методом пришёл к двум альтернативам, то средний цвет поможет выбрать ему правильную.
Лучше просто каким-то серым залить.
0mogol0
11.03.2022 11:36-3Например, если злоумышленник каким-то другим методом пришёл к двум альтернативам, то средний цвет поможет выбрать ему правильную.
ну в теории может и верно, но я сильно сомневаюсь, что на практике это будет необходимо, а разница между двумя цветами будет значительной...
так как зачерняют ИМХО чаще всего только часть текста, то из контекста будет понятно, какой вариант верный и без анализа среднего цвета.
Плюс, это требует, чтобы злоумышленник сумел как-то вскрыть текст (пусть и до нескольких возможных вариантов), но тогда смысл в закраске сильно теряется.
BigBeaver
14.03.2022 09:09Например, у вас могут быть документы со скрытыми номерами паспортов свидетелей/заявителей/клиентов. У злоумышленника может быть их список. Ваше обычное среднее позволяет с высокой точностью их сопоставить.
Вот идея закрашивать случайным средним выглядит интересно. Или заливать пикселизацией от случайной строки. Тогда есть шанс, что злоумышленник зря потратит ресурсы и время.

nerudo
11.03.2022 11:02+8Очевидно что сперва текст нужно подменять на случайный, а потом хоть обпикселизируйся. Недостаток — можно оценить количество символов. Ну так его и по черным полосам можно оценить в сравнении с другим текстом.



PrinceKorwin
11.03.2022 12:16+10... для надёжности следует использовать только чёрные полосы
Ну вот Microsoft так и поступала когда нужно было часть своих внутренних документов раскрыть. Только они сделали черные плашки редактируя PDF документ.
В итоге в любом редакторе можно было удалить эту плашку и посмотреть, что там под ней находится.
Поэтому в вашей статье не хватает указания на то, что такие документы нужно отдавать в растрированном формате и никогда в векторном/WYSIWYG.

vesper-bot
11.03.2022 13:09+8напоминает историю, как один парень у девушки просил картинку с сиськами, та его спрашивает "в каком формате сохранять из фотошопа?" тот "PSD!"
один из вариантов продолжения — девушка была довольно умной и схлопнула слои в растр перед сохранением.

spacediver
11.03.2022 15:31+11Нетленка с башорга
Катя: привет,я с уга вернулась!
Ромка: прив!как оно там?
Катя: да замечательно!прикинь,я на нудистском пляже загорала!!!У меня даже фотка одна есть...
Ромка: вах)))Фстудию!
Катя: АГА!Хитрец!Ну ладно,я щас только все прикрой черными квадратиками!!!
Ромка: Ну давай...
Катя: Слуш,я тут не до конца с фотошопом разобралась...В какой формат лучше сохранить?
Ромка: Ну...Конечно же в PSD
Катя: А,хорошо,щас кину!!!
Ромка: Давай,жду с нетерпением!!!!!

lea
11.03.2022 13:10Иногда замазываю эффектом "иней" из paint.net
")
(мин. и макс. радиус разброса = 5, плавность перехода = 2, шрифт Calibri, размер 16) Уверен, что шансов восстановить текст на изображении нет никаких.

amphasis
11.03.2022 13:39+3Есть у меня ощущение, что алгоритм этого фильтра детерминированный и зная его можно в достаточном для распознавания виде восстановить исходное изображение.
lea
11.03.2022 13:46https://github.com/rivy/OpenPDN/blob/master/src/Effects/FrostedGlassEffect.cs
Перебирать придется не только символы возможного текста, но и random seed.

Pavel1114
12.03.2022 07:14+2странная уверенность в мире, где с помощью машинного обучения и не такие вещи делают. Ну и главное зачем? В примере из статьи хотя бы понятно что это текст — т.е как бы показываешь пользователю что информация есть и осталось только получить к ней доступ. Ваш же способ практически не отличается от чёрных полос с точки зрения пользователя, но в то же время оставляет, пусть небольшую, но вероятность дешифрации
")

zopukh
11.03.2022 14:17+1Каждый раз, когда эта тема поднимается, у меня возникает вопрос: Почему нельзя сделать инструмент для заливки области рандомными пикселями? И пусть потом восстанавливают.




mactep3230
11.03.2022 15:46+3Просто сняв очки увидел hgILRIFIikq-SHEvXINk-INZIgaCWIJ-kymitS4m. Если бы это был осмысленный текст на русском, то думаю можно было бы восстановить точно.

ihouser
11.03.2022 16:44+1Уменьшил картинку до величины пикселей монитора. Эффект примерно такой же как и сняв очки.

engine9
11.03.2022 18:31Нужно просто "пиксели" ставить размером, эдак раза в четыре крупнее, чем размер одного закрашиваемого глифа. Картинка из поста.

mapron
11.03.2022 21:01+5все равно еще намного больше информации, чем 0 бит. я бы даже не согласился с предложением заливать однотонным серым цветом, который берется как среднее значение, только черная заливка, для того о чем я беспокоюсь (я даже для перестраховки явно сохранял файл в rbg24 bmp и потом открывал, чтобы не дай бог в альфа канале утечки никакой не было).
Как уже отметили в комментариях, если у злоумышленника есть какие-то другие источники (например тот же ключ но замазанный другим методом) именно ваши 10 квадратиков могут ему восстановить недостающее. Так что лучше не рисковать.


Sky-Fox
12.03.2022 12:25+1Что бы получить и красоту и не дать информацию можно создать утилиту которая не существующий текст размывает а например строки Пушкина подставляет до размытия... ну или на крайний случаю Lorem ipsum.

HoDGoD666
12.03.2022 22:39Иней, плюс дикая пикселизация, плюс блюр и ещё пикселизация. Давайте, удачи.
vesper-bot
13.03.2022 07:18+1Проще залить серым (0x90) — все равно не отличишь после такой накладки эффектов.
cleverate
>Первым делом мы замечаем странный цвет. Откуда он взялся? Разве там не должны быть только чёрный и белый, потому что текст чёрного цвета? Они троллят нас цветными буквами?
Автор статьи не знал про субпиксельное сглаживание? O_o
KonstantinID
так мало того - пиксели еще и квадратные
horror_x
Вот он удивится, когда узнает, что это ещё и от EDID матрицы может зависеть.
SShtole
Он ещё и использует гарнитуру с засечками для UI-меток!
жуя гриб на вилке, наябедничал кот.