

В данной статье мы рассмотрим базовую теорию и практику рендеринга с помощью кроссплатформенного графического API wgpu. Данный API основан на стандарте WebGPU и предоставляет удобные, унифицированные и безопасные абстракции для взаимодействия с GPU. Используя wgpu мы инициализируем графическое устройство, создадим графический конвейер и нарисуем треугольник.
Немного подробнее
Под капотом wgpu использует для взаимодействия с GPU нативные (компилируемые под конкретную платформу) графические API: Vulkan, OpenGLES, D3D11, D3D12, Metal. А также работает под WASM на базе WebGPU API. Общая архитектура представлена на картинке:
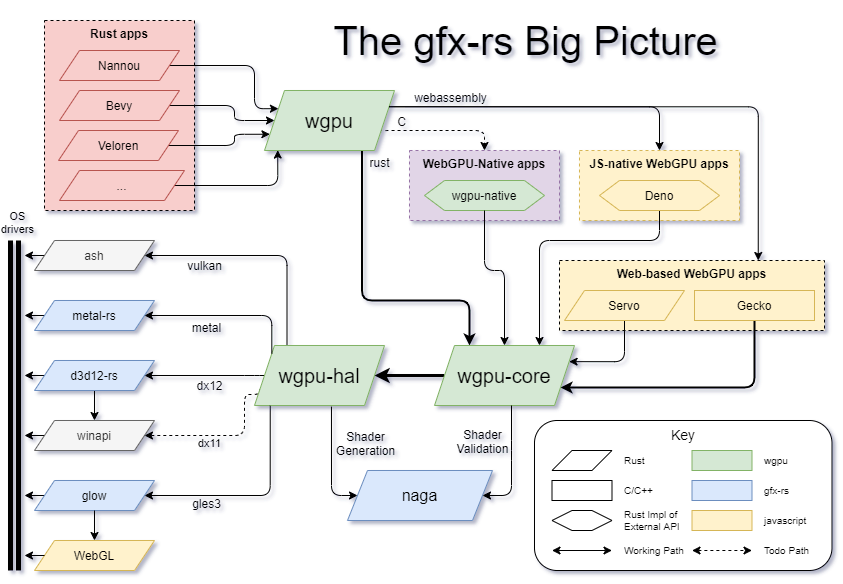
Основной интерес представляют следующие элементы схемы:
wgpu-core - внутренняя реализация стандарта WebGPU для нативных платформ.
wgpu-hal - абстракция над указанными на схеме графическими API.
naga - инструмент для работы с шейдерами.
Жёлтым цветом выделены инструменты для взаимодействия WASM кода с JavaScript.
Создание проекта
Для начала создадим приложение Rust с помощью команды:
cargo new --bin wgpu_first_stepsТеперь можно начинать писать код.
Создание окна
Прежде чем браться за рендер, необходимо создать поверхность, на которую будет выводиться наше изображение. Для этого будем использовать крейт winit, позволяющий писать кроссплатформенный код для создания окон и цикла обработки событий ОС.
Добавим winit в Cargo.toml файл и напишем код создания окна и простого цикла обработки событий:
use winit::dpi::PhysicalSize;
use winit::event::{Event, WindowEvent};
use winit::event_loop::{ControlFlow, EventLoop};
use winit::window::{Window, WindowBuilder};
fn main() {
// Создадим цикл обработки событий.
let event_loop = EventLoop::new();
let window_size: PhysicalSize<u32> = (800, 600).into();
// Создадим окно, задав его параметры.
let window = WindowBuilder::new()
.with_fullscreen(None)
.with_inner_size(window_size)
.with_title("wgpu first steps")
.build(&event_loop)
.unwrap();
// Запустим цикл обработки событий, передав в него замыкание,
// которое будет выполнятся на кождой итерации цикла.
event_loop.run(move |event, _, control_flow| {
// Будем попадать в тело цикла только при появлении события ОС.
*control_flow = ControlFlow::Wait;
match event {
// Если обработаны все накопившиеся события - перерисовываем содержимое окна.
Event::MainEventsCleared => {
// todo: код рендера
}
// Если было запрошено закрытие окна, завершаем цикл.
Event::WindowEvent {
event: WindowEvent::CloseRequested,
..
} => {
*control_flow = ControlFlow::Exit;
}
// Остальные события нам не интересны.
_ => {}
}
})
}Теперь, при запуске мы увидим пустое окно:

Инициализация устройства
Теперь нам нужно инициализировать экземпляр графического API и запросить у него графическое устройство.
Для инициализации экземпляра графического API, добавим wgpu в Cargo.toml и дополним код:
// Создание экземпляра графического API.
let instance = wgpu::Instance::new(wgpu::Backends::all());В функцию new() передаётся набор API (Vulkan, D3D11, WebGPU, ...), которые мы позволим wgpu использовать на нижнем уровне. В нашем случае, передадим все возможные бэкенды, а библиотека сама выберет наиболее подходящий для системы, на которой будет запущено приложение.
Далее, создадим поверхность для отображения, используя созданное ранее окно.
// Создаём поверхность для отображения.
let surface = unsafe { instance.create_surface(&window) };Создание окна - это единственная небезопасная операция в wgpu. Это связано с тем, что wgpu не может контролировать время жизни окна. Например, если окно будет закрыто, а мы попытаемся что-то в нём отобразить, то мы получим undefined behavior.
Теперь можно запросить графический адаптер, способный рисовать на созданной поверхности. Запрос адаптера - асинхронная операция, которая может занять некоторое время. В некоторых случаях может потребоваться выполнять её без блокировки основного потока. Для нашего примера в этом нет нужды, поэтому просто заблокируем поток до получения устройства. Для этого используем крейт pollster. Добавим следующий код:
// Задаём желаемые параметры графического устройства
let adapter_options = wgpu::RequestAdapterOptions {
compatible_surface: Some(&surface),
..Default::default()
};
// Запрос устройства - асинхронная операция.
let adapter_future = instance.request_adapter(&adapter_options);
// Дождёмся её завершения с помощью pollster.
let adapter = pollster::block_on(adapter_future).unwrap();
// Выведем в терминал название выбранного устройства.
println!("Selected adapter: {}", adapter.get_info().name);Скорее всего, в результате будет выбрано интегрированный графический адаптер (если такой имеется). Дополнительные критерии выбора устройства можно задать в виде полей структуры wgpu::RequestAdapterOptions. В нашем примере подойдёт любое устройство.
Теперь, выбрав адаптер, можем создать логическое устройство.
// Зададим параметры устройства по умолчанию.
let device_descriptor = wgpu::DeviceDescriptor::default();
// Запрос устройства - асинхронная операция.
let device_future = adapter.request_device(&device_descriptor, None);
// Получаем логическое устройство и очередь задач для него.
let (device, queue) = pollster::block_on(device_future).unwrap();Логическое устройство будет в дальнейшем использовано для создания объектов, позволяющих рисовать. Очередь задач, как понятно из названия, будет использована для отправки команд рендеринга на графическое устройство.
Графический конвейер
Для преобразования данных (например, 3D модели) в изображение, графические устройства пропускают их через графический конвейер. Графический конвейер состоит из нескольких этапов обработки данных: от точек в некотором виртуальном пространстве до пикселей на изображении. Некоторые из этапов можно конфигурировать, а некоторые - даже программировать. Пользовательская программа, выполняющаяся на одном из этапов конвейера графическим процессором, называется шейдер.

На изображении, в упрощенном виде, представлены этапы графического конвейера:
Vertex Shader - это программа, которая вызывается для каждой вершины геометрии, переданной для рендеринга. Данная программа, обычно, используется для позиционирования объектов на экране.
Shape Assembly преобразует отдельные вершины в фигуры, из которых состоит поверхность геометрии.
Geometry Shader позволяет производить манипуляции на уровне фигур. Например, порождать новые. Этот этап используется редко, хотя и позволяет реализовать некоторые интересные техники рендеринга.
Rasterization - преобразование фигур во фрагменты (пиксели) финального изображения.
Fragment Shader - это программа, которая вызывается для каждого фрагмента, полученного на предыдущем этапе. Обычно в ней задают цвет этим фрагментам с учётом текстур и освещения.
Tests and Blending - этап отвечающий за проверку глубины и смешение цветов фрагментов разных фигур, положение которых совпало. Проверка глубины, обычно, используется для того, чтобы модель на переднем плане не оказалось перекрыта другой моделью, которая должна находится на заднем плане.
Давайте создадим простейший графический конвейер, который позволит нам отрисовать треугольник. Для этого нам потребуется написать два шейдера: Vertex Shader и Fragment Shader. Geometry Shader не поддерживается wgpu из соображений кроссплатформенности. Хотя wgpu поддерживает несколько языков для написания шейдеров, основным для него является wgsl. Его мы и будем использовать.
Нам требуется вершинный шейдер, который, по команде отрисовки трёх вершин, вернёт три вершины треугольника. Вершины должны быть заданы в следующей системе координат:

Fragment shader, в свою очередь, должен окрасить каждый фрагмент треугольника в какой-нибудь цвет.
Создадим файл shader.wgsl и опишем в нём оба шейдера:
[[stage(vertex)]] // Атрибут указывает что функция относится к вершинному шейдеру.
// Функция принимает индекс (порядковый номер) вершины и возвращает её положение на экране.
fn vs_main([[builtin(vertex_index)]] in_vertex_index: u32) -> [[builtin(position)]] vec4<f32> {
// Здесь применим небольшой математический трюк.
// Чтобы не подгружать точки треугольника извне, рассчитаем их координаты
// исходя из порядкового номера.
let x = f32(i32(in_vertex_index) - 1); // f32() и i32() - преведение типов.
let y = f32(i32(in_vertex_index & 1u) * 2 - 1);
// Легко убедиться, что индексы [0, 1, 2]
// преобразуются в вершины с координатами [(-1,-1), (0,1), (1,-1)].
// Возвращаем позицию вершины
return vec4<f32>(x, y, 0.0, 1.0);
}
[[stage(fragment)]] // Атрибут указывает что функция относится к фрагментному шейдеру.
// Функция не принимает ничего, а возвращает цвет фрагмента.
fn fs_main() -> [[location(0)]] vec4<f32> {
// Возвращаем красный цвет для каждого фрагмента нашего треугольника.
return vec4<f32>(1.0, 0.0, 0.0, 1.0);
}Теперь можно загрузить этот код в наше приложение и загрузить шейдер на устройство, получив при этом объект, который идентифицирует этот шейдер:
// Включим код шейдера в исполняемый файл с помощью макроса include_str.
let shader_code = include_str!("../shader.wgsl");
// Создадим объект шейдера из его кода.
let descriptor = wgpu::ShaderModuleDescriptor {
label: None, // метку для отладки оставим не заданной
source: wgpu::ShaderSource::Wgsl(shader_code.into()),
};
let shader_module = device.create_shader_module(&descriptor);Наконец, создадим графический конвейер:
// Определим, какой формат изображения лучше всего подходит для выбранного адаптера.
let surface_format = surface.get_preferred_format(&adapter).unwrap();
// Зададим параметры целевого изображения. В нашем случае - поверхности в окне.
let color_targets = [wgpu::ColorTargetState { // Параметры цели для отрисовки.
format: surface_format, // Формат целевого изображения.
blend: None, // Смешение цветов не используем.
write_mask: Default::default(), // Пишем во все каналы RGBA.
}];
// Параметры графического конвейера оставим, в основном, по умолчанию.
let descriptor = wgpu::RenderPipelineDescriptor {
label: None, // Метку для отладки оставим не заданной.
primitive: Default::default(), // Создание фигур из вершин - по умолчанию.
vertex: wgpu::VertexState { // Параметры вершинного шейдера.
buffers: &[], // Буффер с данными о вершинах не используется.
module: &shader_module, // Идентификатор нашего шейдера.
entry_point: "vs_main" // Имя функции, которая будет вызываться для вершин.
},
fragment: Some(wgpu::FragmentState { // Параметры фрагментного шейдера.
targets: &color_targets, // Параметры целевого изображения.
module: &shader_module, // Идентификатор нашего шейдера.
entry_point: "fs_main", // Имя функции, которая будет вызываться для фрагментов.
}),
layout: None, // Разметку для передачи внешних данных в шейдер не используем.
depth_stencil: None, // Тест глубины нам не нужен.
multisample: Default::default(), // Multisample по умолчанию отключен.
multiview: None, // Отображение будет происходить только в одно изображение.
};
let pipeline = device.create_render_pipeline(&descriptor);Осталось настроить поверхность в соответствии с параметрами окна:
// Настроим поверхность в соотвитствии с параметрами окна:
let config = wgpu::SurfaceConfiguration {
usage: wgpu::TextureUsages::RENDER_ATTACHMENT, // Будем использовать surface для рендера.
format: surface_format, // Формат, который мы выбрали ранее.
width: window_size.width, // Ширина окна.
height: window_size.height, // Высота окна.
present_mode: wgpu::PresentMode::Mailbox, // Алгоритм вывода кадров на экран.
};
surface.configure(&device, &config);Полный код нашего приложения выглядит так:
use winit::dpi::PhysicalSize;
use winit::event::{Event, WindowEvent};
use winit::event_loop::{ControlFlow, EventLoop};
use winit::window::WindowBuilder;
fn main() {
// Создадим цикл обработки событий.
let event_loop = EventLoop::new();
let window_size: PhysicalSize<u32> = (800, 600).into();
// Создадим окно, задав его параметры.
let window = WindowBuilder::new()
.with_fullscreen(None)
.with_inner_size(window_size)
.with_title("wgpu first steps")
.build(&event_loop)
.unwrap();
// Создание экземпляра графического API.
let instance = wgpu::Instance::new(wgpu::Backends::all());
// Создаём поверхность для отображения.
let surface = unsafe { instance.create_surface(&window) };
// Задаём желаемые параметры графического устройства
let adapter_options = wgpu::RequestAdapterOptions {
compatible_surface: Some(&surface),
..Default::default()
};
// Запрос адаптера - асинхронная операция.
let adapter_future = instance.request_adapter(&adapter_options);
// Дождёмся её завершения с помощью pollster.
let adapter = pollster::block_on(adapter_future).unwrap();
// Выведем в терминал название выбранного адаптера.
println!("Selected adapter: {}", adapter.get_info().name);
// Зададим параметры устройства по умолчанию.
let device_descriptor = wgpu::DeviceDescriptor::default();
// Запрос устройства - асинхронная операция.
let device_future = adapter.request_device(&device_descriptor, None);
// Получаем логическое устройство и очередь задач для него.
let (device, queue) = pollster::block_on(device_future).unwrap();
// Включим код шейдера в исполняемый файл с помощью макроса include_str.
let shader_code = include_str!("../shader.wgsl");
// Создадим объект шейдера из его кода.
let descriptor = wgpu::ShaderModuleDescriptor {
label: None, // Метку для отладки оставим не заданной.
source: wgpu::ShaderSource::Wgsl(shader_code.into()),
};
let shader_module = device.create_shader_module(&descriptor);
// Определим, какой формат изображения лучше всего подходит для выбранного адаптера.
let surface_format = surface.get_preferred_format(&adapter).unwrap();
// Зададим параметры целевого изображения. В нашем случае - поверхности в окне.
let color_targets = [wgpu::ColorTargetState { // Параметры цели для отрисовки.
format: surface_format, // Формат целевого изображения.
blend: None, // Смешение цветов не используем.
write_mask: Default::default(), // Пишем во все каналы RGBA.
}];
// Параметры графического конвейера оставим, в основном, по умолчанию.
let descriptor = wgpu::RenderPipelineDescriptor {
label: None, // Метку для отладки оставим не заданной.
primitive: Default::default(), // Создание фигур из вершин - по умолчанию.
vertex: wgpu::VertexState { // Параметры вершинного шейдера.
buffers: &[], // Буффер с данными о вершинах не используется.
module: &shader_module, // Идентификатор нашего шейдера.
entry_point: "vs_main" // Имя функции, которая будет вызываться для вершин.
},
fragment: Some(wgpu::FragmentState { // Параметры фрагментного шейдера.
targets: &color_targets, // Параметры целевого изображения.
module: &shader_module, // Идентификатор нашего шейдера.
entry_point: "fs_main", // Имя функции, которая будет вызываться для фрагментов.
}),
layout: None, // Разметку для передачи внешних данных в шейдер не используем.
depth_stencil: None, // Тест глубины нам не нужен.
multisample: Default::default(), // Multisample по умолчанию отключен.
multiview: None, // Отображение будет происходить только в одно изображение.
};
let pipeline = device.create_render_pipeline(&descriptor);
// Настроим поверхность в соттвитствии с параметрами окна:
let config = wgpu::SurfaceConfiguration {
usage: wgpu::TextureUsages::RENDER_ATTACHMENT, // Будем использовать surface для рендера.
format: surface_format, // Формат, который мы выбрали ранее.
width: window_size.width, // Ширина окна.
height: window_size.height, // Высота окна.
present_mode: wgpu::PresentMode::Mailbox, // Алгоритм вывода кадров на экран.
};
surface.configure(&device, &config);
// Запустим цикл обработки событий, передав в него замыкание,
// которое будет выполнятся на кождой итерации цикла.
event_loop.run(move |event, _, control_flow| {
// Будем попадать в тело цикла только при появлении события ОС.
*control_flow = ControlFlow::Wait;
match event {
// Если обработаны все накопившиеся события - перерисовываем содержимое окна.
Event::MainEventsCleared => {
// todo: код рендера
}
// Если было запрошено закрытие окна, завершаем цикл.
Event::WindowEvent {
event: WindowEvent::CloseRequested,
..
} => {
*control_flow = ControlFlow::Exit;
}
// Остальные события нам не интересны.
_ => {}
}
})
}Теперь можно переходить к рендерингу.
Рендеринг
Для рендеринга нужно выполнить следующие шаги:
Получить следующий кадр для нашей поверхности.
Создать View для этого изображения этого кадра. View - это что-то вроде ссылки на изображение или его часть. Его можно использовать в качестве цели для отрисовки.
Создать объект для записи последовательности команд рендеринга в буфер, для последующей передачи его в устройство на исполнение. Такой объект называется CommandEncoder.
Создать в рамках CommandEncoder проход рендеринга задав ему View (созданный на этапе 2) в качестве цели для отрисовки. Внутри прохода рендеринга можно запускать графические конвейеры, которые будут рисовать пиксели в цель для отрисовки.
В проходе рендеринга задать созданный нами графический конвейер и выполнить для него команду отображения трёх точек.
Сохранить записанные команды в буфер.
Передать буфер с командами в очередь команд для устройства.
Отобразить кадр на экране.
Алгоритм может показаться запутанным, но на практике всё выглядит проще:
// Получаем следующий кадр.
let frame = surface.get_current_texture().unwrap();
// Создаём View для изображения этого кадра.
let view = frame
.texture
.create_view(&wgpu::TextureViewDescriptor::default());
// Создаём CommandEncoder.
let mut encoder =
device.create_command_encoder(&wgpu::CommandEncoderDescriptor { label: None });
// Новая область видимости нужна, чтобы компилятор видел,
// что RenderPass живёт не дольше, чем CommandEncoder.
{
let mut rpass = encoder.begin_render_pass(&wgpu::RenderPassDescriptor {
label: None, // Метку для отладки оставим не заданной.
color_attachments: &[wgpu::RenderPassColorAttachment {
view: &view, // Цель для отрисовки.
resolve_target: None, // Используется для мультисэмплинга.
ops: wgpu::Operations {
load: wgpu::LoadOp::Clear(wgpu::Color::BLUE), // Очищаем кадр синим цветом.
store: true, // Сохраняем содержимое после завершения данного RenderPass.
},
}],
depth_stencil_attachment: None, // Буфер глубины не используем.
});
// Задаём графический конвейер.
// Все последующие операции рендеринга будут исполняться на нём.
rpass.set_pipeline(&pipeline);
// Отрисоваваем один объект с тремя вершинами.
rpass.draw(0..3, 0..1);
}
// Сохраняем в буфер команды, записанные в CommandEncoder.
let command_buffer = encoder.finish();
// Передаём буфер в очередь команд устройства.
queue.submit(Some(command_buffer));
// Отображаем на экране отрендеренный кадр.
frame.present();Полный код теперь выглядит так:
use winit::dpi::PhysicalSize;
use winit::event::{Event, WindowEvent};
use winit::event_loop::{ControlFlow, EventLoop};
use winit::window::WindowBuilder;
fn main() {
// Создадим цикл обработки событий.
let event_loop = EventLoop::new();
let window_size: PhysicalSize<u32> = (800, 600).into();
// Создадим окно, задав его параметры.
let window = WindowBuilder::new()
.with_fullscreen(None)
.with_inner_size(window_size)
.with_title("wgpu first steps")
.build(&event_loop)
.unwrap();
// Создание экземпляра графического API.
let instance = wgpu::Instance::new(wgpu::Backends::all());
// Создаём поверхность для отображения.
let surface = unsafe { instance.create_surface(&window) };
// Задаём желаемые параметры графического устройства
let adapter_options = wgpu::RequestAdapterOptions {
compatible_surface: Some(&surface),
..Default::default()
};
// Запрос адаптера - асинхронная операция.
let adapter_future = instance.request_adapter(&adapter_options);
// Дождёмся её завершения с помощью pollster.
let adapter = pollster::block_on(adapter_future).unwrap();
// Выведем в терминал название выбранного адаптера.
println!("Selected adapter: {}", adapter.get_info().name);
// Зададим параметры устройства по умолчанию.
let device_descriptor = wgpu::DeviceDescriptor::default();
// Запрос устройства - асинхронная операция.
let device_future = adapter.request_device(&device_descriptor, None);
// Получаем логическое устройство и очередь задач для него.
let (device, queue) = pollster::block_on(device_future).unwrap();
// Включим код шейдера в исполняемый файл с помощью макроса include_str.
let shader_code = include_str!("../shader.wgsl");
// Создадим объект шейдера из его кода.
let descriptor = wgpu::ShaderModuleDescriptor {
label: None, // Метку для отладки оставим не заданной.
source: wgpu::ShaderSource::Wgsl(shader_code.into()),
};
let shader_module = device.create_shader_module(&descriptor);
// Определим, какой формат изображения лучше всего подходит для выбранного адаптера.
let surface_format = surface.get_preferred_format(&adapter).unwrap();
// Зададим параметры целевого изображения. В нашем случае - поверхности в окне.
let color_targets = [wgpu::ColorTargetState {
// Параметры цели для отрисовки.
format: surface_format, // Формат целевого изображения.
blend: None, // Смешение цветов не используем.
write_mask: Default::default(), // Пишем во все каналы RGBA.
}];
// Параметры графического конвейера оставим, в основном, по умолчанию.
let descriptor = wgpu::RenderPipelineDescriptor {
label: None, // Метку для отладки оставим не заданной.
primitive: Default::default(), // Создание фигур из вершин - по умолчанию.
vertex: wgpu::VertexState {
// Параметры вершинного шейдера.
buffers: &[], // Буффер с данными о вершинах не используется.
module: &shader_module, // Идентификатор нашего шейдера.
entry_point: "vs_main", // Имя функции, которая будет вызываться для вершин.
},
fragment: Some(wgpu::FragmentState {
// Параметры фрагментного шейдера.
targets: &color_targets, // Параметры целевого изображения.
module: &shader_module, // Идентификатор нашего шейдера.
entry_point: "fs_main", // Имя функции, которая будет вызываться для фрагментов.
}),
layout: None, // Разметку для передачи внешних данных в шейдер не используем.
depth_stencil: None, // Тест глубины нам не нужен.
multisample: Default::default(), // Multisample по умолчанию отключен.
multiview: None, // Отображение будет происходить только в одно изображение.
};
let pipeline = device.create_render_pipeline(&descriptor);
// Настроим поверхность в соттвитствии с параметрами окна:
let config = wgpu::SurfaceConfiguration {
usage: wgpu::TextureUsages::RENDER_ATTACHMENT, // Будем использовать surface для рендера.
format: surface_format, // Формат, который мы выбрали ранее.
width: window_size.width, // Ширина окна.
height: window_size.height, // Высота окна.
present_mode: wgpu::PresentMode::Mailbox, // Алгоритм вывода кадров на экран.
};
surface.configure(&device, &config);
// Запустим цикл обработки событий, передав в него замыкание,
// которое будет выполнятся на кождой итерации цикла.
event_loop.run(move |event, _, control_flow| {
// Будем попадать в тело цикла только при появлении события ОС.
*control_flow = ControlFlow::Wait;
match event {
// Если обработаны все накопившиеся события - перерисовываем содержимое окна.
Event::MainEventsCleared => {
// Получаем следующий кадр.
let frame = surface.get_current_texture().unwrap();
// Создаём View для изображения этого кадра.
let view = frame
.texture
.create_view(&wgpu::TextureViewDescriptor::default());
// Создаём CommandEncoder.
let mut encoder =
device.create_command_encoder(&wgpu::CommandEncoderDescriptor { label: None });
// Новая область видимости нужна, чтобы компилятор видел,
// что RenderPass живёт не дольше, чем CommandEncoder.
{
let mut rpass = encoder.begin_render_pass(&wgpu::RenderPassDescriptor {
label: None, // Метку для отладки оставим не заданной.
color_attachments: &[wgpu::RenderPassColorAttachment {
view: &view, // Цель для отрисовки.
resolve_target: None, // Используется для мультисэмплинга.
ops: wgpu::Operations {
load: wgpu::LoadOp::Clear(wgpu::Color::BLUE), // Очищаем кадр синим цветом.
store: true, // Сохраняем содержимое после завершения данного RenderPass.
},
}],
depth_stencil_attachment: None, // Буфер глубины не используем.
});
// Задаём графический конвейер.
// Все последующие операции рендеринга будут исполняться на нём.
rpass.set_pipeline(&pipeline);
// Отрисоваваем один объект с тремя вершинами.
rpass.draw(0..3, 0..1);
}
// Сохраняем в буфер команды, записанные в CommandEncoder.
let command_buffer = encoder.finish();
// Передаём буфер в очередь команд устройства.
queue.submit(Some(command_buffer));
// Отображаем на экране отрендеренный кадр.
frame.present();
}
// Если было запрошено закрытие окна, завершаем цикл.
Event::WindowEvent {
event: WindowEvent::CloseRequested,
..
} => {
*control_flow = ControlFlow::Exit;
}
// Остальные события нам не интересны.
_ => {}
}
})
}В результате при запуске приложение получаем такое окошко:

Итог
Итак, для отображения треугольника мы проделали следующие операции:
Организовали цикл обработки событий и создали окно.
Инициализировали экземпляр бэкенда wgpu.
Создали поверхность для окна.
Выбрали графический адаптер.
Создали виртуальное графическое устройство и очередь команд для него.
Написали вершинный и фрагментный шейдеры.
Создали графический конвейер.
Получили следующий кадр и View для его изображения.
Создали CommandEncoder.
Создали проход рендеринга.
Задали графический конвейер.
Добавили команду отображения вершин.
Сохранили команды из CommandEncoder в буфер команд.
Передали буфер команд в очередь на выполнение.
Отобразили кадр в окне.
Может показаться, что это очень большой объём работы для такой маленькой задачи. Прелесть в том, что пункты 1-5, обычно, выполняются единожды для любого графического приложения. Пункты 6-7, с небольшими дополнениями повторяются для каждого способа отрисовки, и каждое повторение не сильно отличается от предыдущего. Пункты 8-15 в реальном приложении ненамного сложнее, чем в данном примере. Иными словами, с ростом сложности приложения, сложность алгоритма рендеринга растёт слабо.
P.S.
Если статья вызовет интерес, то я, возможно, возьмусь за другие статьи, демонстрирующие другие возможности и примеры wgpu.
Статья подготовлена в преддверии старта курса Rust Developer, в связи с чем хочу пригласить всех желающих на бесплатный демоурок курса, в рамках которого будут разобраны подходы к реализации GUI фреймворков и рассмотрен Rust фреймворк iced, на котором будет создано небольшое приложение. Регистрация доступна по ссылке.
build_your_web
Интересно, как происходит дебаггинг шейдеров?
Можно каким-то образом увидеть состояние переменных в запущенном шейдере? На сколько я понимаю, в момент работы могут быть запущены тысячи шейдеров одновременно, так?
F3kilo Автор
Для отладки шейдеров существуют различные инструменты. Одни из них созданы под конкретного производителя GPU: NVIDIA Nsight, Radeon Developer Tool Suite. Другие универсальны: RenderDoc.
Про возможность просмотра значений локальных переменных шейдеров я не слышал. Возможно, такое доступно в каких-нибудь эмуляторах. Обычно, отладка производится на уровне просмотра входных и выходных данных шейдера.
Как верно отмечено, шейдер запускается одновременно на сотнях-тысячах процессоров GPU. Это работает по принципу SIMD.