

Пожалуй, каждый ML-инженер за время своей карьеры сталкивался с ситуацией, когда метрики модели на продакшне сильно отличаются от результатов на валидационных и тестовых выборках. Такие расхождения между ожиданиями и реальностью негативно влияют на репутацию ML-систем, особенно в доменных областях, где цена ошибки высока. Ещё они замедляют их внедрение в бизнес-процессы организаций и, конечно же, бьют по самооценке ML-инженеров.
Сегодня мы попробуем разобраться, в чём же основные причины таких расхождений и как можно их предотвратить (или по крайней мере быстрее обнаружить).
Начнём с самой банальной причины деградации метрик на продакшне – технические ошибки. Например, предсказания модели на офлайн-тестах и на продакшне могут отличаться из-за разницы в коде, который используется для предобработки изображений. Есть несколько простых способов защитить себя от подобного позора:
-
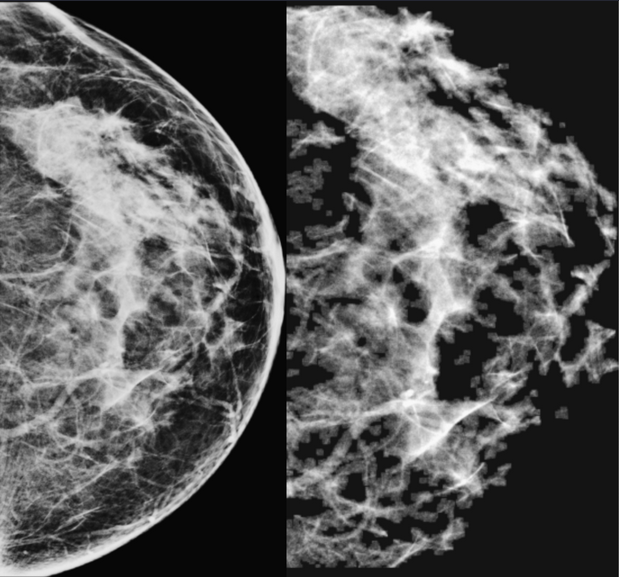
Устранение дублирования кода. Максимальное возможное количество кода (препроцессинг, обработка нейронной сетью, постпроцессинг) должно использоваться одновременно и при обучении, и на инференсе. Любая дубликация кода сразу же в разы увеличивает вероятность расхождений. То же самое относится и к конфигурационным файлам: на картинке можно увидеть пример того, как ошибка в прод-конфиге влияла на картинки, которые нейронка получала на вход (слева – при обучении, справа – на инференсе).
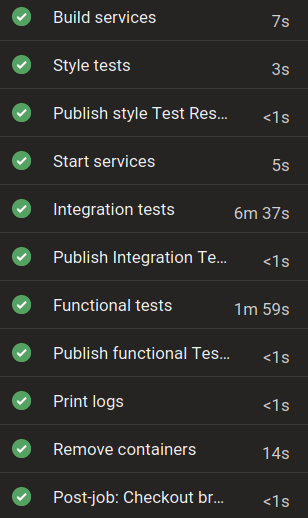
- Интеграционные метрик-тесты. Критически важно тестировать и замерять метрики системы в условиях, максимально приближённых к продакшн-условиям. В предрелизный пайплайн важно включить автоматический тест, который разворачивает систему целиком, засылает в неё тест-пак, получает предсказания, рассчитывает ML-метрики и сравнивает их с референсными значениями.
- Ручное тестирование важных релизов. Автоматические тесты способны обнаружить большую часть багов, но иногда числа не раскрывают всей картины, это особенно актуально для ML-систем, предсказания которых, видят сами пользователи (например, врачи). Например, одна из наших моделей продемонстрировала очень высокие метрики точности на всех тестах, но изредка находила признаки COVID-19 вне области лёгких. Врачи очень негативно относятся к таким грубым ошибкам, поэтому мы предпочитаем проводить визуальное контрольное тестирование предсказаний для важных релизов, затрагивающих предсказания модели. Причём крайне желательно задействовать в этом процессе доменных экспертов (опять же врачей).
Если вы ловите много багов на финальных этапах тестирования — это повод задуматься о том, почему вообще это происходит. Часто причиной таких проблем становятся неправильные процессы и недостаток коммуникации.
К примеру, однажды наша модель на калибровочном тестировании в медицинской организации продемонстрировала поистине ужасающие результаты (ROC-AUC = 0.53, предсказание на уровне подброса монетки), хотя на внутренних тестах та же метрика приближалась к идеальной. Оказалось, что причиной стало лёгкое недопонимание между командами ML-разработки и бэкенда по вопросу округления вероятности наличия патологии. Спешка и проблемы в коммуникации привели к тому, что ML-ядро и бэкэнд-часть были протестированы отдельно, а полноценное интеграционное тестирование всей системы проведено не было, что и привело к абсолютно неверным предсказаниям от отлично работающей модели.
Технические ошибки могут происходить не только на вашей стороне, но и на стороне клиента. Например, в систему, обученную для анализа флюорограмм могут начать попадать рентгеновские снимки других частей тела или вовсе калибровочные снимки с бутылками. Нахождение моделью на таких снимках различных патологий однозначно не вызовет восторга со стороны клиента, и, скорее всего, негативно повлияет на итоговые продакшн-метрики системы. Поэтому важно встраивать в ML-системы компоненты по детекции Out-of-Distribution примеров. Они могут быть основаны как на простых сравнениях статистик, описывающих входные данные, так и на использовании более продвинутых ML-способов. При обнаружении некорректного примера вместо предсказания можно информировать клиента о невозможности обработать данный случай.
Острая форма заболевания
Изменения в свойствах входных данных могут происходить и неслучайно. Например, к системе может подключиться новый клиент, или же у старого клиента может измениться протокол сбора данных (например, в медицинское учреждение поставили новый рентгеновский аппарат). Помимо этого, различные факторы (например, сам факт внедрения ML-системы или изменения в бизнес-процессах медицинского учреждения) могут приводить к изменениям входных данных или связи между входными данными и целевой переменной. Такие явления в мире ML называются covariate shift и concept drift.
Чтобы такие изменения не были для вас неожиданностью, важно поддерживать постоянную и доверительную коммуникацию с клиентами, а также объяснять им принципы работы ML-систем и потенциальные риски, связанные с их применением. Например, мы регулярно проводим вебинары для медицинского сообщества, в которых рассказываем о том, как мы обучаем, тестируем и деплоим наши системы.
Конечно, от всех изменений таким образом не защитишься, поэтому крайне важно внедрять системы автоматического мониторинга и алертинга. Вся релевантная информация (предсказания модели, статистики входных данных, количество запросов и прочее) должна логироваться, агрегироваться и выводиться на дашборды. Кроме того, при резких изменениях каких-либо из этих параметров желательно генерировать автоматические алерты в ваш любимый мессенджер. Здесь, однако, важно не переборщить с чувствительностью алертинга: слишком частые сигналы тревоги очень быстро начинают игнорировать.
Если вы чувствуете в себе смелость и азарт, можно поэкспериментировать с адаптивными системами и системами активного обучения. Адаптивные системы дообучаются прямо на продакшн-данных. Это может происходить с помощью сбора фидбека с пользователей или же путём автоматического создания задач врачам-разметчикам для сложных кейсов с продакшна. Такие ML-системы могут адаптироваться под изменения входных данных, но могут быть уязвимы к атакам, подвержены проблемам забывания старых данных и в целом сложны в эксплуатации.
Наконец, разница между метриками на внутреннем и внешнем тестировании может быть вызвана плохо подобранным тестовым сетом. Разнообразие медицинских данных огромно – как с точки зрения качества и типа изображений, так и в плане многообразия типов патологий.
Здесь можно посоветовать не скупиться в деньгах и времени при создании качественного тестового сета, не забывать о его обновлении (помним про проблему множественных проверок и переобучения под тестовый сет) и с самого начала работы ML-системы начать коллекционировать сет входных данных, с которыми система когда-либо имела проблемы. Даже простое визуальное тестирование ML-системы на таком разнообразном сете поможет уберечь её от деградации при очередном обновлении. Если у вас есть доступ к реальным продакшн-данным, пусть и неразмеченным, можно попробовать оценить степень расхождения между распределением обучающей и тестовой выборки и реальных данных.
Безусловно, запуск новой ML-системы в продакшн или обновление старой – это всегда волнительный момент для любого ML-инженера. Однако вероятность успеха этого мероприятия можно значительно увеличить, если следовать ряду несложных правил, о многих из которых я и рассказал в этом посте:- Устраняй дублирование кода между обучением и инференсом.
- Максимизируй автоматизированное тестирование (включая метрик-тесты, тесты на репродуцируемость, тесты на корректность предиктов).
- Смотри глазами на предикты системы перед релизом.
- Проблемы в коммуникации между командами могут привести к неприятным скрытым багам.
- По возможности встраивай в ML-системы компоненты по детекции Out-of-Distribution-примеров.
- Важно поддерживать постоянную коммуникацию с пользователями системы, но не забывать и про автоматический мониторинг.
- Разнообразный, корректный тестовый сет – наше всё.