
Некоторое время назад к нам пришел клиент – крупный металлургический комбинат. Продукцию комбината перевозят поезда. А во время железнодорожных грузоперевозок машинисты и диспетчеры должны переговариваться согласно регламенту. За переговоры не по регламенту - штраф. Поэтому “боль” клиента была сильной: получить систему автоматического контроля регламента переговоров по рации во избежание финансовых потерь и снижения риска катастроф.
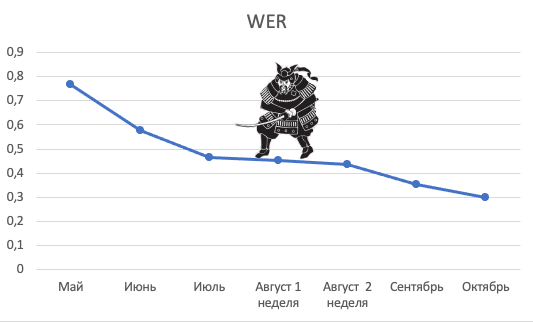
Мы опрометчиво согласились. А когда получили аудиозаписи, поняли, что поторопились подписывать договор. Дело в том, что записи с раций сопровождаются огромным количеством шумов. Качество аудио было такое, что порой мы сами не могли ничего разобрать. В одной записи мы поначалу слышали только «во во во», а когда напряглись, различили «два вагона вагон». Потренировав ухо, мы разметили некоторое количество записей и загрузили их в свою универсальную модель. Результат был плохой: ошибка распознавания - 76,9% (вернее WER – 0,769). Решили прогнать записи на других решениях. Итог был не лучше: ошибка Google составила 92% (WER – 0,92), другие вендоры дали похожий результат.
В принципе, еще можно было отказаться. Но мы решили «избрать путь самурая», а, как известно, путь самурая – это путь, ведущий к смерти. Шанс сделать из решения, которое почти ничего не распознает, решение, которое распознает почти все, стремится к нулю. А подписавшись на выполнение, мы рисковали попасть на большие штрафные санкции.
Первый месяц, работая на старой end2end архитектуре, мы не смогли заметно продвинуться в качестве. Уже почти отчаявшись, мы решили пойти ва-банк и перестроить все свое решение.
Что мы сделали:
Перешли от end2end архитектуры на гибрид. Для гибрида нужно меньше обучающих данных и он более робастный к изменениям аудио-среды. На гибриде мы стали ставить эксперименты, чтобы найти оптимальную конфигурацию.
Транскрибировали около 50 часов записей (потом, правда, потребовалось оттекстовать еще).
Собрали корпус текстов, характерных для железнодорожной сферы: инструкции машинистов, регламенты и т.д
Иногда казалось, что улучшить результат не получится, кейс провальный. Но за неудачами следовали эксперименты, улучшающие метрику. В итоге нам удалось снизить WER почти в 3 раза и распознавать речь с раций достаточно качественно.
Что действительно помогло:
Как ни удивительно, самый большой вклад внесли тексты для языковой модели. Только они обеспечили снижение WER на 0,3. Мы сами в это не сразу поверили, но объясняется данный факт довольно просто. При переговорах по рации на железнодорожном транспорте 200 самых употребимых выражений составляют порядка 90% от всех слов. Более того, если все слова распознавать как слово «вагон», вы получите около 15% качества :) Таким образом, сузив словарь до нескольких сотен слов (назовем его словарь Эллочки-людоедки) и правильно оценив вероятность их употребления, мы получаем максимальный прирост качества.
Вторым фактором было дообучение акустики и работа с шумами. Основной прирост мы начали получать, разметив (транскрибировав) 40 часов записей. Остальная разметка (еще несколько десятков часов) дала буквально 3% в приросте метрики.
Третий по значимости фактор – адаптация самой модели.
Вывод №1 – львиная доля прироста качества пришлась на создание обучающего датасета, при этом основной прирост дала семантика и первые 40 часов аудио.
Вывод №2 – иногда (правда не всегда), качество распознавания речи можно кардинально улучшить, имея нужный датасет и полгода на эксперименты;).
Вывод №3 – нам повезло. Если бы не узкая вариативность употребления слов в записях, не видать нам такого качества как своих ушей. И путь самурая - это интересно, но лучше не подписываться под обязательства, когда велик риск их не выполнить. В следующий раз может так не повезти.
Бонус для дочитавших: наш телеграм бот @AmVeraSpeechBot. В боте вы можете проверить качество работы нашего решения по распознаванию речи (Amvera Speech) (это универсальная модель, а не модель для ЖД) и просто безлимитно и бесплатно распознавать голосовые сообщения. Просто отправьте в бот короткую аудиодорожку или голосовое сообщение – и получите текстовую расшифровку.
Комментарии (11)

Markscheider
10.10.2022 21:01+1А шумы (радиопомехи) были ±одинаковые? Имею в виду частотную полосу "шипения", громкость относительно речи и пр.

Amvera_Speech Автор
10.10.2022 21:21+1Там было 2 типа записи - аналог и цифровой, на них было по разному. Плюс несколько станций - на них были отличия в акустике не стороне диспетчера. На аналоге как раз получилось лучше всего вычистить шумы (цифры как раз для него), на "цифре" было чуть хуже. А по распределению - там шумы как от самих раций, так и окружающий шум был, но от раций в похожем частотном диапазоне, который к сожалению, частично перекрывал диапазон в котором была сама речь.

sukhe
11.10.2022 19:51+1Каким образом шумы вычищали? Есть нормальные готовые библиотеки, или своё что-то изобретали?
Amvera_Speech Автор
11.10.2022 20:27+1Помимо стандартного, что стояло ранее - посмотрели по спектрограмме, на какие частоты приходятся шумы и применили простой самописный фильтр, чтобы "вычистить" эти частоты, там, где это было возможно.

Rive
10.10.2022 21:44+3Пожалуй, разметить датасет едва ли не сложнее, чем подобрать способ успешной работы с ним.
Amvera_Speech Автор
10.10.2022 21:50Соглашусь, нужна очень хорошая разметка, и если "чистые" записи размечать относительно просто (на час записи тратится 3-4 часа работы разметчика), то для этих пришлось тратить очень много времени, несколько раз их переслушивать и делать тройное перекрытие между разметчиками.

555www555
11.10.2022 00:55у вас свой движок по распознаванию речи? Мы производим аудиобейджи Свидетель и диктофоны Edic-mini - нам бы было бы интересно с вами посотрудничать.

YDR
11.10.2022 15:10+1Как только люди нейронки не мучают, только бы рации нормальные не покупать...(шутка, с долей шутки).
С Хорошей рацией и машинисту хорошо (вагон с прогоном и перегоном не перепутает).
А вообще интересно.
propell-ant
Я правильно понял термины:
у гугла был WER=0.92,
а если все слова распознать как "вагон", то был бы WER=0.85 ?
Спасибо, мир заиграл новыми красками!
Amvera_Speech Автор
Да, но Google такое выдавал на модели, которая из разряда совсем не приспособлена к акустики рации. У того же ЦРТ результат был лучше, но все равно общая модель не позволяла хорошо распознать настолько специфический домен. И 0,85 будет, если распознавать "вагон" без пропусков слов, а большая часть ошибки как раз заключалась в том, что в сильном шуме на всех решениях были огромные пропуски.
kirillkosolapov
К слову у ряда вендоров есть специальные отраслевые решения, которые дают приемлемые цифры в таких акустических условиях, правда их нет в открытом доступе.