
Эта история началась с того, что к нам (в компанию Amvera) пришел клиент, которому нужна была система распознавания речи. Да не простая, а качественно распознающая разговоры с микрофонов на АЗС, то есть речь в сильных шумах. Цель заказчика простая – контролировать, упоминают ли кассиры акции, предлагают ли установить мобильное приложение и выпить кофе. Вы наверняка все это сами слышали на заправках.
Но есть проблема. Хорошо распознать простую чистую речь могут почти все известные решения. Но речь, где на фоне играет радио, слышны звуки с других касс, громкость речи говорящих разная и присутствует много отраслевой лексики (бренды сигарет, марки топлива), качественно распознать не смогло ни одно «коробочное» решение.
Вызов принят! Мы решили за ограниченное время справиться с этим кейсом.
Шаг 1 – транскрибируем несколько файлов и замеряем качество распознавания на своем решении и решении конкурентов.
Для измерения качества распознавания используем метрику WER.
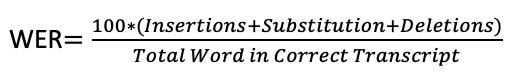
Пример расчета:
Исходные данные: Стационарный *** телефон зазвонил поздней ночью
Гипотеза: Стационарный синийi айфонs прозвонилsпоздней ночью
WER = 100*(1+2+0)/5 = 60% (т.е. ошибка равна 60%).
Итоги тестового замера
Качество по %WER (чем меньше, тем лучше)
1) 58.6 ЦРТ
2) 64.7 наше решение Amvera Speech- без дообучения
3) 69.1 Tinkoff
4) 69.5 Salutbot (Sber)
5) 79.1 Nanosemantica
«Серебряная медаль» — это конечно хорошо, но WER = 0,64 - это неприемлемый для бизнеса результат.
Без адаптации алгоритм «не видел» часть реплик и допускал большое количество ошибок распознавания.

ШАГ 2 – разметка данных
Чтобы решить задачу, мы стали транскрибировать данные. Это нужно для того, чтобы:
А) Познакомить акустическую модель с шумами, разностью амплитуд и т.д.
Б) Обогатить языковую модель специфическими терминами (марки сигарет, топлива) и учесть статистику употребления. Так, для задачи словосочетание «девяносто пятый» актуальнее, чем словосочетание «шестьдесят третий», так как это наименование топлива, а значит, ему нужно задать более высокую вероятность.
Количество дополнительных данных влияет на результат обучения нелинейно. Эффект заметен начиная от 10 часов аудио. При этом каждые следующие 10 часов дают все меньший прирост. Из опыта: прирост качества почти завершается после разметки и добавления в исходную обучающую выборку данных 50 часов. В связи с этим, транскрибировать больше 40-50 часов аудио почти нецелесообразно.
ШАГ 3 – замеряем прогресс

Качество по %WER (чем меньше, тем лучше)
1) 38.6 Amvera Speech дообучение, 28окт
2) 42.2 Amvera Speech дообучение,19окт
3) 58.6 ЦРТ
4) 64.7 Amvera Speech – без дообучения
5) 69.1 Tinkoff
6) 69.5 Salutbot (Sber)
7) 79.1 Nanosemantica
")
 и детектирует большинство произнесенных реплик вне зависимости от разности в громкости и других факторов.")
Результат
1. Ошибка за месяц снижена в 1,67 раза с 64.7% до 38,6% по WER .
2. Адаптированное решение лучше ближайшего конкурента (бот ЦРТ) в 1,51 раза по WER.
3. Адаптированное решение распознает отраслевые термины (бренды сигарет, марки топлива).
4. Оставшаяся ошибка приходится на сильно искаженную и слабо слышимую речь.
5. Нам повезло - речь на АЗС не очень разнообразна и дообучить алгоритм можно на небольшой выборке.
Конечно, 38,6% по WER - это немаленькая ошибка и нужно смотреть, какие из бизнес-кейсов при такой ошибке решаемы, но это явно лучше изначальных 64.7%.
Бонус для дочитавших: наш телеграм бот для распознавания голосовых сообщений @AmVeraSpeechBot. В боте вы можете проверить качество работы нашего решения (Amvera Speech) по распознаванию речи для общей лексики (это универсальная модель, а не модель для АЗС). Просто отправьте в бот короткую аудиодорожку или голосовое сообщение – и получите текстовую расшифровку.
Комментарии (13)

Robastik
21.12.2022 05:34+3это немаленькая ошибка и нужно смотреть, какие из бизнес-кейсов при такой ошибке решаемы
Надо понимать, что бизнес-кейс заказчика не решен→
контролировать, упоминают ли кассиры акции, предлагают ли установить мобильное приложение и выпить кофе.
Поэтому можно предложить заказчику зайти с другой стороны → освободить кассиров от несвойственной им функции.
Если заказчику кажется, что упоминание акций устами кассиров лучше, чем другие способы информирования, сделать "вклейку" необходимых фраз в речь кассиров. Например, на прикладывании карты к терминалу озвучивать приглашение на кофе, а на выползании чека напоминать о мобильном приложении. Акции упоминать при приветствии (которое и будет распознаваться ).
BigBeerman
21.12.2022 06:07+1кожаный мешок дешевле

MentalBlood
21.12.2022 09:45Это пока не понадобятся сложные методы контроля
BigBeerman
21.12.2022 09:51+1ну, это очень древняя тема, пока человек достаточно дешево обходится, его не заменят машиной. Плюс машину не получится обмануть

kirillkosolapov
21.12.2022 18:30Тут (с данным WER) закрываются кейсы с произнесением ключевых слов сотрудником, но полностью регламент тяжело оценить. Но для статистического анализа, какой сотрудник как часто и что предлагает, этого хватает.

mikelavr
21.12.2022 10:54+2Каждый раз на заправке говорю кассиру, что очень сочувствую ему по поводу требования этого голосового спама. Они замучено улыбаются.

dom1n1k
21.12.2022 11:06+2[оффтоп] То есть люди мало того, что портят UX своего сервиса, так еще и готовы тратить немалые деньги на контроль того, что точно испортили, не забыли, не профилонили.
Это ведь из жизни ситуация. Например, я много лет пользуюсь услугами одного интернет-магазина. Всегда шел к ним, даже если у конкурентов бывало чуть дешевле — потому что всё всегда проходило четко и удобно. Но с недавних пор они стали на каждом этапе назойливо впаривать допуслуги и мусорные страховки. На полном серьезе подумываю сменить контору. Дооптимизируются.

arheops
21.12.2022 12:32Тоесть на основании вот такого WER вы предлагаете делать дисциплинарные взыскания?
Я бы сказал, что это «задача не решается, но наш аналитик придумал обьяснение», а не «мы решили задачу».
И да, вклейка голосовых сообщений и блутус кнопка на касе «пора сообщение» была бы и дешевле, и проще. Ну и заодно позволяла бы человеку в то же время приготовить ходдог и КАЧЕСТВЕННО решить проблемы отчета по таким сообщениям. Да и просто можно было бы сделать — отходит человек от касы на два метра — играет сообщение(если с прошлого прошло больше минуты).
Это как раз случай, когда специалист бы обьяснял заказчику, почему у него постановка задачи неверна.kirillkosolapov
21.12.2022 17:25Мы тут как разработчик ASR выступаем, решения которого внедряет конечному клиенту наш клиент. И насколько мне известно, что разные гипотезы проверяли, но именно соблюдение регламента общения (со всеми апсейлами) сотрудников, позволяет поднять средний чек.
arheops
21.12.2022 17:49Ну тогда вы вообще сфейлили, поскольку не решили ничего.
Но подаете это как победу.
А ведь какой-то джун не разобравшись в вашей метрике решит, что и эта задача в России решена.
Лично я, понимая сложность задачи, зашел посмотреть, как же ее решили. И что? А никак, натренировали, результата как был никакой так и остался. Все улучшения от того, что вы сравнивате с более общей системой. Результаты при слабых шумах вы, естественно, не показали.kirillkosolapov
21.12.2022 18:26Это некорректно так говорить. Данного качества на самом деле хватает, чтобы оценивать факт произнесения ключевых слов (брендов) и предложений. Это же нужно не для поиска конкретных нарушений, а для сбора статистики по сотрудникам. А для статистики этого достаточно. И вы удивитесь, но для чистейшей телефонной речи WER у всех лучших вендоров (и у ЦРТ и у Яндекса и у нас) около 20% (это если честно считать) и ошибку почти не видно глазами. Ошибку 30-40% конечно уже видно, но она кроется в основном в речи посетителей АЗС, которые далеко от микрофона. И да - как инженеры мы довольны, что смогли сократить ошибку почти в 2 раза относительно простым способом. И если поработать еще с пол года в т.ч. с фильтрацией сигнала, можно еще сократить - но это соответствующие затраты на ФОТ и разметку данных.
OBIEESupport
Странно, но писать о распознавании без всей теории и тестов, а только на основании WER - это примерно как описывать Луну по фото с хорошего сотового телефона. Картинка есть, но заправки - это же интересная задача сама по себе. Скажем, если делать робозаправку, а не автоматизированную, как сейчас любят, на кого должен быть похож робот?
vkni
Для этого надо хотя бы перестать жить в мире киберпанка. Пока же делается рабозаправка, где автомат служит полицаем.
В нормальной ситуации это просто обычная заправка с оплатой по карте. Их делают уже десятилетия как. Вот так выглядит:
Чек выдаётся слева, карта засовывается справа.