

В этой статье продолжим тему решения криптографических задач с ресурса MysteryTwister. И сегодня на очереди любопытный шифр, далёким предком которого является квадрат Полибия. Мы познакомимся с трёхраздельным шифром Феликса Деластеля. Что интересно информации об этом энтузиасте криптографии очень мало в английском и французском сегментах сети (Деластель — француз), а в русскоязычном о нём почти нет совсем, хотя наверняка человеком он был очень неординарным. Почему я так решил? Да потому, что Феликс Деластель по роду профессиональной деятельности не имел к криптографии совершенно никакого отношения, поскольку всю жизнь проработал в порту Сен-Мало и криптографией занимался факультативно. Тогда как ранее и позже криптография была уделом учёных, профессиональных военных и дипломатов. Биографических данных о нём очень мало, но одно известно точно: на рубеже XIX и XX веков Деластель написал книгу "Traite Elementaire de Cryptographie" (Базовый трактат по криптографии), в которой он описывал системы шифрования, которые создал.
Одним из шифров, разработанных Деластелем, является трёхраздельный шифр (Trifid cipher), использующий таблицы для разделения каждой буквы открытого текста на триграмму. Что интересно, в этом шифре используется транспозиция совместно с дроблением для скрытия статистической взаимосвязи между зашифрованным и открытым текстом. Его предшественник — двунаправленный шифр, также придуманный Деластелем, был первым шифром для реализации принципов путаницы и распространения. Как отмечал сам Деластель, он наиболее практичен для шифрования латинского алфавита, лежащего в основе большинства европейских языков, поскольку в латинском алфавите 26 букв, а трёхраздельный шифр использует 27 позиций для шифрования.
Итак, перейдём к задаче.
Пример шифрования
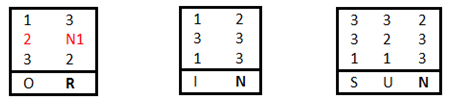
Даны три ключевых таблицы:
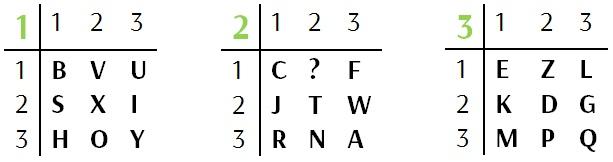
Зашифруем слово TOPSECRET.
Находим букву Т в таблице 2, столбце 2, строке 2. Записываем три цифры вертикально друг под другом. Теперь ищем букву О в таблицах. Получаем следующие координаты {1 2 3} и записываем их. Так же продолжаем для всех оставшихся букв, а результаты записываем столбиком слева направо.

Шифрование работает следующим образом. Первая горизонтальная группа из трёх букв — {2 1 3}. Выписываем букву из третьей строки первого столбца второй таблицы — R. Следующая триграмма — {1 3 2}, по этим координатам находится буква I. Таким образом используем все триграммы и получаем зашифрованный текст RIWTBSACK.
Для удобства расшифровки запишем шифрованное сообщение вертикально и выпишем по порядку координаты каждой буквы (номер таблицы, номер столбца, ном
Полученные числовые тройки выпишем горизонтально слева направо таким образом, чтобы в каждой строке было одинаковое количество цифр.
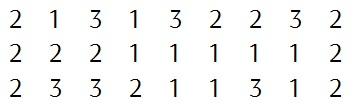
Далее уже по столбцам слева направо берём координаты, выписываем буквы из ключевых таблиц и получаем исходное сообщение.
Обратите внимание, что необязательно заканчивать ряд сразу после триграммы, она вполне может разбиваться и переноситься на следующую строку. Главный принцип заключается в одинаковом количестве символов в строках.
Задача
Два английских профессора на пенсии Многочей и Малобол посылают друг другу сообщения, зашифрованные с помощью трёхраздельного шифра. Ранее они обменялись ключом, состоящим из трёх таблиц. Профессор Малобол получает зашифрованный текст от своего коллеги Многочея, но по исключительной рассеянности профессор Малобол потерял вторую таблицу ключа. Сможет ли профессор восстановить открытый текст, несмотря на недостаточность ключевой информации?
Профессору необходима помощь с дешифрованием сообщения.
Для решения задачи необходимо:
1. Найти девять пропущенных букв латинского алфавита второй таблицы и расставить их в правильном порядке.
2. Сформировать числовые триграммы и записать правильные буквы открытого текста.
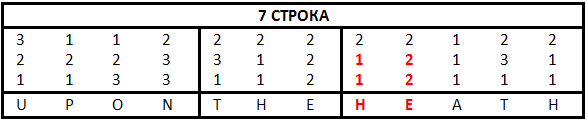
Зашифрованный текст
EMKE MEWAM OF YTDDC GFTY LYEWIG
KM ZHEPITO ?OVGG?NS? IJ EB JGUUG
EEVU NBQ WNPTYFDUOYY VKLR
EEWE MXO LLSHSTN XVYF TYL FXG
WWEV EMBR FZ AVT MUZ AAV EH LIJ
EDWBM OTW YFEYPZ
FEEK ESL IJFLA
EDKEK BE TMZV NIYF KBEAYGH
Зашифрованный текст соответствует английским словам, то есть пробел в зашифрованном тексте находится в той же позиции, что и пробел в открытом тексте. Открытый текст был зашифрован построчно, при этом сначала все пробелы были удалены до процесса шифрования и вставлены на те же самые места в уже зашифрованный текст.
Решение
Так как буквы в таблицах используются один раз, найдём буквы, из которых состоит вторая таблица простым исключением из алфавита:

Получим следующие буквы: BEHLMNTVW.
Далее разобьём шифрованное сообщение на трёхбуквенные группы и распишем координаты букв в таблице, при этом координаты букв второй таблицы обозначим через литеру и цифру (например, Е = {2 Е1 Е2}).
Красным отмечены буквы из второй таблицы. В этой таблице использованы только буквы для координат, чтобы её не загромождать. Далее будут использоваться и цифры.
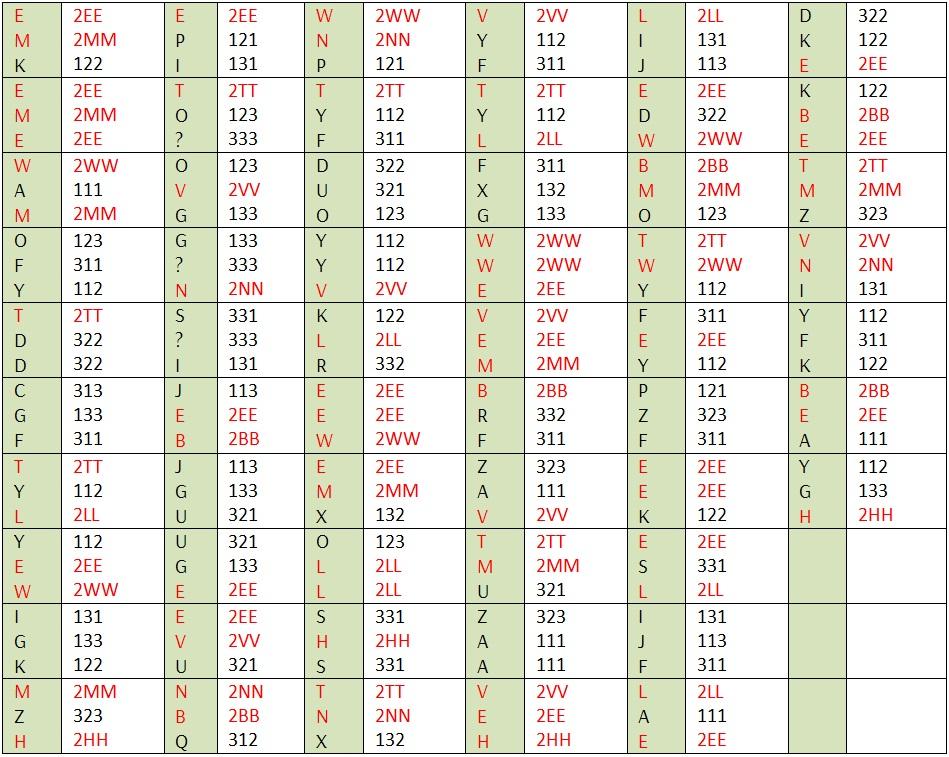
Полученные цифры запишем в табличной форме построчно слева направо для каждой строки отдельно и внесём в полученные таблицы известные по координатам буквы. Получилось не так уж и много.






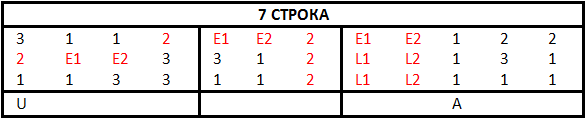

Перейдём к анализу. Начнём с самых коротких слов. Обратите внимание на вторую строку. Здесь у нас два двухбуквенных слова. {1 2 3} — это буква O, а {3 N1 2}, скорее всего, — буква R, и, соответственно, слово — это союз OR. Значит, координата N1 = 3. Учитывая первое слово в этой же строке, предположим, что это предлог IN и вторая координата N2 = 3. Расставим полученные координаты N = {2 3 3} по остальным строкам для подтверждения этой гипотезы. Действительно, получаем два предлога IN во второй строке, союз AND в четвёртой, популярное окончание -ING в третьем слове второй строки и восьмое слово в пятой строке SUN. Расставим N в соответствующие координатам {2 3 3} места.
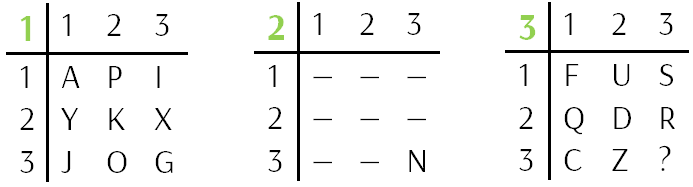
В данной системе шифрования имеется одна интересная особенность, которая играет нам на руку. Для шифрования используются три таблицы по девять членов в каждой, однако в английском алфавите всего 26 букв, поэтому 27 символом стал знак вопроса с координатами {3 3 3}. Учитывая эту особенность, проанализируем получившиеся таблицы.






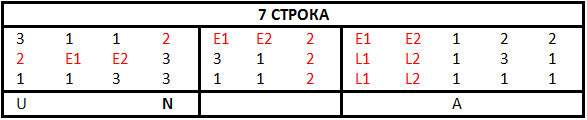

Так как знак вопроса не может находиться внутри слова, получается, что M2 ≠ 3 (2 слово 2 строка), E1 ≠ 3 (1 слово 6 строка), E2 ≠ 3 (3 слово 3 строка). Также, скорее всего, T1 ≠ T2 (2 слово 6 строка), поскольку вероятность наличия в тексте трёхбуквенного слова с двумя первыми одинаковыми буквами очень мала (да и не знаю я такого слова).
Пока более всего в текущем зашифрованном тексте привлекают внимание четыре слова: 6 в первой строке, 6 во второй, 4 в третьей и 1 в седьмой. Рассмотрим возможные сочетания букв в этих словах.
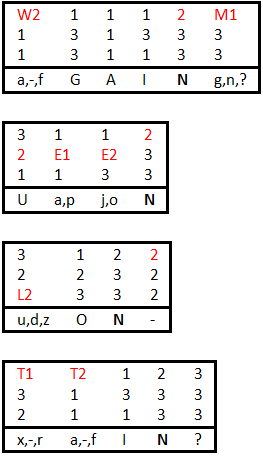
Итак, простым перебором вычисляем, что 6 слово первой строки, скорее всего, AGAIN? Первая буква — точно не F из третьей таблицы. Оставшиеся буквы второй таблицы не подходят, поэтому выбираем букву A. В окончании слова не может быть G и N, значит это знак вопроса из третьей таблицы. Таким образом, M1 = 3, W2 = 1.
Также перебором вычисляем первое слово седьмой строки: UPON. Значит E1 = 2, E2 = 2.
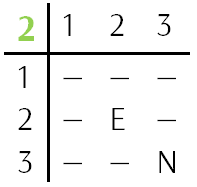
Для проверки гипотез просмотрим весь текст. Сразу бросаются в глаза:

Зная координаты букв E = {2 2 2} и частотность слов в английском языке, предположим, что это определённый артикль — THE.
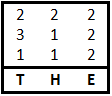
Таким образом, у нас появились новые данные T1 = 3, T2 = 1, W1 = 2, H1 = 1, H2 = 1, и подтвердились координаты E. Занесём полученные результаты во вторую ключевую таблицу и зашифрованные строки.
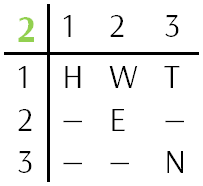






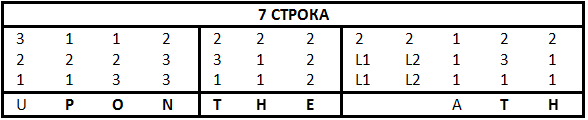

Привлекают внимание 1 слово 1 строки, 1 слово 3 строки и 1 слово 4 строки:

Учитывая все имеющиеся данные, получаем M2 = 2, L1 = 1 и L2 = 2.
Таким образом:
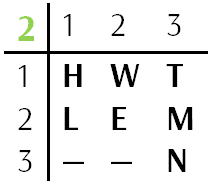







У нас осталось всего две буквы: B и V.
Воспользуемся простой подстановкой. Разместим B по координатам {2 1 3}, а V — {2 2 3}, а потом поменяем их местами, если не получится.
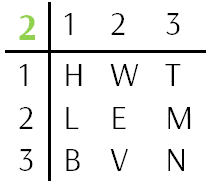
В итоге получилось, что верным был первый вариант, и мы получили расшифрованный текст, оказавшийся диалогом трёх ведьм в первой сцене первого акта одной из самых известных трагедий Уильяма Шекспира «Макбет»:
When shall we three meet again?
In thunder, lightning, or in rain?
When the hurly-burly's done,
When the battle's lost and won.
That will be ere the set of sun.
Where the place?
Upon the heath.
There to meet with Macbeth.
Когда средь молний, в дождь и гром
Мы вновь увидимся втроем?
Когда один из воевод
Другого в битве разобьет.
Заря решит ее исход.
Где нам сойтись?
На пустыре.
Макбет там будет к той поре.
(перевод Б. Пастернак)
Использованный в задаче трёхраздельный шифр Деластеля является классическим полиграфическим подстановочным шифром. В замечательной книге Дэвида Кана («Взломщики кодов») упоминается, что шифры, разработанные Деластелем, сыграли значительную роль в развитии криптографической науки. Сейчас понятно, что эти шифры ненадёжны и тяготеют к частотному анализу, несмотря на принятые меры по усложнению, однако довольно долго после своего появления этот и подобные ему шифры вполне себе служили по своему профилю.
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на заказ любого VDS (кроме тарифа Прогрев) — HABRFIRSTVDS
Zara6502
я очень далек от криптографии, но если требовалось всегда пользовался XOR и фразой-ключом. Не представляю как без полного перебора можно взломать такой способ кодирования текста. облегчающим задачу могут стать длина фразы-ключа, аналитика по знакам препинания и пробелу, но всё равно очень сложно решить в лоб.
я пользовался генератором паролей в линуксе, брал 128 байт, не ограничивался буквами, брал все печатные ascii символы, а 128 - это половина таблицы.
Ни в коем разе нельзя шифровать пустые файлы или файлы с известным контентом, но и тут можно хитрить например совмещая с этим.
Zara6502
кстати, если посмотреть в сторону сюжетов из кино и книг, то близким по невозможности взлома к XOR будет банальный шифр по словам(буквам) из определенной книги. Тем более этот вариант менее бросающийся в глаза чем таскание с собой в явном виде книги с шифрами. А чтобы сильнее запутать стартовой считать не первую страницу книги, а например 1+день недели или день месяца или номер недели в году или, что неочевидно - день рождения секретаря-машинистки Светланы из разведшколы.
в этом смысле всегда забавны киношные "взломы" шифров в духе - "так это же шифр Карпентера" и раз-два и уже всё расшифровал.
iig
Ну да, книжный шифр. Для Алисы и Боба вполне годное решение; для разведсети - не очень. 1 раскрытый агент или перебежчик - и всё. А заменить N ключевых книг может оказаться совсем непросто.
Да, у Швейка было что-то подобное. Только оно не работало, потому что из-за ошибки снабжения кому-то достался первый том книги, а кому-то второй ;)
Zara6502
человеческий фактор исключить невозможно, ошибутся если не с книгой то с чем-то другим.
шифры не обязательно делать на всю сеть, из книг можно использовать самые ходовые в этой стране, доступные даже в библиотеке, для США например актуальна библия в каждой ночлежке в некоторых штатах. это вопрос проработки, а не слабости метода.
например в нацисткой германии можно было бы в чемодане везти сборник стихов Гёте и книжку художника, который боролся. А если книжки затаскать и засалить, обвести некоторые абзацы и выучить их наизусть, то будет всё выглядеть куда правдоподобнее, чем новая книжка с еще слипшимися страницами и незнание самих произведений.
В сериале ТБВ Шелдон очень заморачивался по поводу вранья и я, например, в целом схож с ним, поэтому если в школе нужно было соврать родителям, то легенда была безупречна.
Но в целом суть ясна и я не то чтобы сильно спорю, всё же первый абзац моего опуса решает.
CrazyOpossum
Если есть под рукой компьютер - уж лучше взять проверенные современные криптосистемы. Докомпьютерная криптография - это всё же про шифры которые можно ручкой на бумажке сделать и не ошибиться при расчётах. Либо со сложнопередаваемым секретом (типа выбрить сообщение на макушке курьера, или конкретная книга из конкретного тиража). И да, шифр Виженера (xor с фразой) взламывается для паролей тех времён.
Zara6502
никто не запрещает, просто если злоумышленник знает чем у вас закодировано, то у него уже есть определенный вектор атаки. Никто не отменял уязвимости софта и отдельной реализации библиотеки.
каким образом?
CrazyOpossum
На вики всё расписано - Тест Касиски ищите. Мне приходилось ломать Вижинера для небольших паролей (<30 символов) на разных ctf'ах.
openssl, gnupg - старый проверенный софт, которым пользуются и блэкхаты и те кто их ловит для своих коммуникаций. Но конечно, у них у всех есть фатальный недостаток - сделано не нами.
А вообще, все ухищрения, которые вы писали ниже - не вопрос криптографии. Аксиома криптографии как науки - способ шифрования априори известен, задача - как найти ключ. Я же утверждаю, что при наличии компьютера и при принятии этой аксиомы - нужно брать aes, а не Виженера.
Zara6502
Если погрузиться в занудство, то длину пароля можно прировнять к длине сообщения, что даёт абсолютную криптостойкость, о которой писал Шеннон.
Я и не говорил о криптографии, о ней говорите вы.
А я утверждаю, что для третьих лиц любая неочевидная необозначенная система кодирования превращается в неосмысленный набор байтов. Мне в первую очередь важно скрыть информацию, а не дать повод для научных исследований или хрестоматийной науки.
CrazyOpossum
И мы получим ещё один известный шифр - Шифр Вернама, абсолютно криптостойкий. Только пароль придётся хранить в блокнотике.
Zara6502
Вот простой пример как отправить гулять метод Касински.
Hidden text
Соответственно слева направо: число файлов, энтропия, размер словаря в байтах, размер файла, имя файла и гистограмма распределения частот появления символов.
CrazyOpossum
Это всё здорово, только ещё раз, шифр Виженера - нестойкий, тем более на текстах в полмегабайта. Это означает, что стоимость атаки на него очень низкая. Все ухищрения со стеганографией (типа запихивания в неправильный архив) добавляют какую-то не слишком большую цену для атакующего. До тех пор, пока ценность данных ниже стоимости атаки - всё в порядке. Лично мне лень оценивать ценность своих данных, поэтому я просто шифрую всё aes256+rsa2048 и верю, что моя база паролей стоит меньше чем, например, банковские коммуникации. Мои усилия при этом - один раз настроить vim-gnupg, gitcrypt и раскидать ключи по разным устройствам.
freeExec
Он очень слаб для файлов по двум причинам. Фраза не очень длинная по сравнению с содержимом файла. Структура файла, а значит и часть открытого текста известна, это быстро раскрывает часть ключа.
Zara6502
я любое кодирование считаю контекстным, соответственно и методы выбираются исходя из содержимого. если это рецепт пирога и главная цель не дать кому-то просто подглядеть, то достаточно и фразы "Hello World!". А если надумаете закодировать например координаты клада в лесу, то можно и фразу подлиннее взять. Но я еще часто делаю обманку, например архив zip, от архива я сам делаю только заголовок, а вот содержимое оставляю после xor без сжатия. Поверьте, любой подумает что это битый архив.
это вы сейчас о чем? вот попал вам в руки мой ноутбук, вы даже знать не будете где искать. банально кодируете xor файл, называете его wmms32.ocx, подкладываете в windows\system32 и всё, можете дату и время файла сделать как у файлов винды - от 99.99% всех у кого окажется ноут информацию найти они не смогут никогда.
Шифры старые ломали еще так, что изначально понятно что там закодирован текст, если кодировать в несколько ступеней, например сначала сжать LZ77 самописным, потом xor. Никто и никогда ничего не раскодирует, потому что 1) никто не в курсе что перед ним закодированная информация, 2) никто не знает чем и как закодировано.
CrazyOpossum
Если у вас там пароль к кошельку на 100 биткоинов - найду, не переживайте.
kmeaw
Для каждого файла в System32 есть не так много источников, из которых он может там появиться. По системным журналам и реестру можно узнать, какая версия ОС устанавливалась, и какие сервиспаки на неё потом в каком порядке накатывались. Если wmms32.ocx ни в одном дистрибутиве не присутствует, то это явным образом указывает на то, что кто-то его туда руками подложил. Можно попробовать поискать в интернете хеш любого неизменённого системного файла из популярных ОС - почти наверняка он найдётся.
А как потом самому раскодировать? Каждый раз грузиться в live-систему и писать по-памяти программу-раскодировщик?