

Мы с командой вернулись тут с Хайлоада, и там даже CTO крупных компаний задают много вопросов про разработку с LLM. Наша компания занимается прикладной разработкой всего того, что касается GPT/LLM.
Расскажу про очевидные вещи, о которых у меня там спрашивали CTO и разработчики.
Самый частый вопрос: можно ли подключать свою базу документов и можно ли по ней нормально работать?
Можно. Для этого нужно две вещи:
- OpenAI может работать с вашей базой, например, вики техподдержки, но её надо векторизовать. Получится, что модель только ищет по ней и может отвечать фрагментом исходника, но может его обрабатывать как текст (то есть сравнивать, анализировать и тому подобное).
- Дальше можно использовать подход QA Retrieval Chain для работы с векторной базой. Работает это так: задаём вопрос, LLM формируют запрос к векторной базе, мы вынимаем из неё данные, подкладываем их в вопрос как контекст и передаём в LLM, а они формируют ответ.
Но давайте начнём сначала. Основное:
- Какого размера промпты могут быть, сколько, какие лимиты, как их частично обходить.
- Как подключается база, как закидывать реально большие документы, как эмбеддится вектор, на каких языках это происходит и тому подобное.
- Разные API.
- Агентная модель GPT Engineer и АutoGPT.
- Фреймворк лангчейн (построение цепочек запросов и разбиение макрозапроса на сотни).
Поехали!
Совсем ликбез. Что такое ChatGPT и как он «думает»?
Изначально языковую модель создавали для того, чтобы она умела общаться. В итоге всё началось с моделей продолжения текста и закончилось тем, что эта штука научилась писать код, играть в шахматы, заказывать реактивы и уговаривать кожаных проходить капчу там, где есть недостающие ей данные.
Условно предполагалось два пути развития искусственного интеллекта. Первый — полным копированием человеческого мозга. Для этого взяли мозг мелкого млекопитающего, заморозили, послойно тонко нарезали и начали собирать карту связей нейронов, чтобы получить полную копию и запустить копипастом, не разбираясь, как она работает. Это ветка, которая пока не дала значимых результатов, но всегда считалась перспективной.
Второй путь — создать модель, которая оперирует знаниями всего человечества и «угадывает» ответ на вопрос, не понимая, что делает. Именно этот подход и был реализован. Модель не «знает», что такое чувства, мораль или этика, и генерирует ответы на основе статистических зависимостей, выявленных в ходе обучения. Это означает, что иногда она может давать неточные или даже ошибочные ответы.
Как работает запрос к ChatGPT?
В общем случае вы задаёте вопрос, а модель ищет наиболее правильное продолжение текста по своим правилам. При этом процесс повторяется итеративно, каждое новое дополнение (каждое новое слово для упрощения) увеличивает ваш запрос. То есть количество токенов, используемых для генерации ответа, растёт во время исполнения с каждым шагом и анализируется целиком. В интерфейсе подкладываются предыдущие сообщения через Chat, как мы могли бы это сделать через API. Модель помнит несколько последних промптов.
Сколько их будет, зависит от длины самих сообщений и размера контекста. А всё, что в контекст не влезает, забывается.
В базовой модели ChatGPT без дополнительных модулей модель плохо разбирается в математике, она оперирует глобальными взаимосвязями, которых достаточно для базовых задач. Чтобы решить этот вопрос, OpenAl сделали через плагины для работы на сайте чата интеграцию с вольфрамом и Code Interprete, с ними математические задачи решаются хорошо.
Кроме того, для разработчиков существуют способы добавить математические библиотеки самостоятельно с использованием системных LLM-промптов или сторонних библиотек, к примеру calculator tool из LangChain-фреймворка.
Техники
- Tree of Thoughts (ToT).
- Self-Consistency.
- Chain-of-Thought Prompting.
- Few-Shot Prompting.
Модели оперируют токенами, а это слова, части слов или символы конкретного языка.
Основной корпус обучения для многих из них (в т. ч. ChatGPT) состоит из текстов на английском, но другие языки они тоже умеют обрабатывать. Правда, в зависимости от объёма доступных обучающих данных для каждого конкретного языка делают это с разной степенью эффективности. При этом «сохранять» информацию или знание в связке с каким-то конкретным языком они не могут. Но зато создают статистические связи между токенами на основе своего обучения. То есть, если вы научили модель значению слова «перестройка», она создаст статистические связи между токенами и будет «понимать», о чём идёт речь.
Каковы ограничения на размер промпта, лимиты по токенам и деньгам?
Размер промпта считается в токенах. Они могут быть разной длины в зависимости от языка и токенизатора. Русский язык занимает большое количество токенов, потому что сложен морфологически. И ещё из-за некоторых особенностей работы токенизатора ChatGpt. То есть два одинаковых запроса на русском и английском будут отличаться почти в четыре раза. В один токен на английском языке влезает в среднем четыре-пять букв. На русском это одна буква.
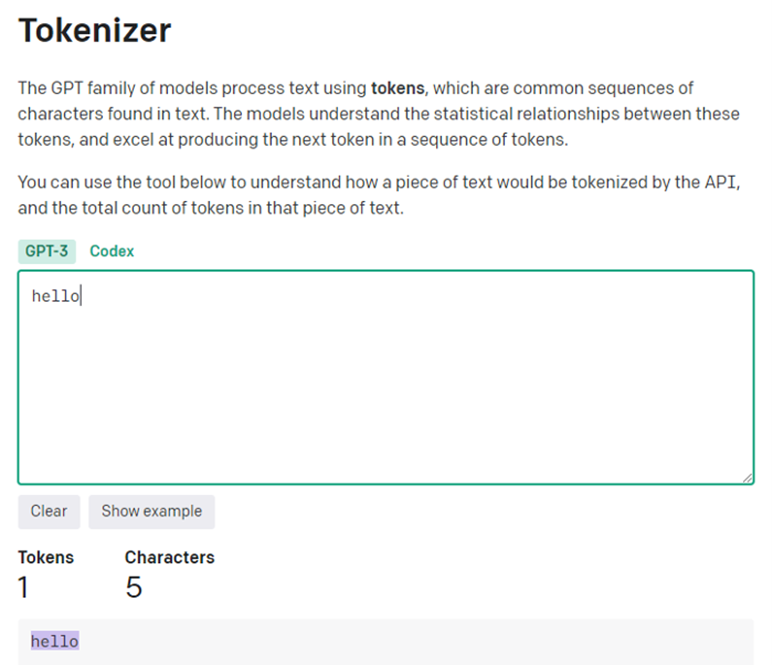
Например, слово «hello» занимает всего один токен
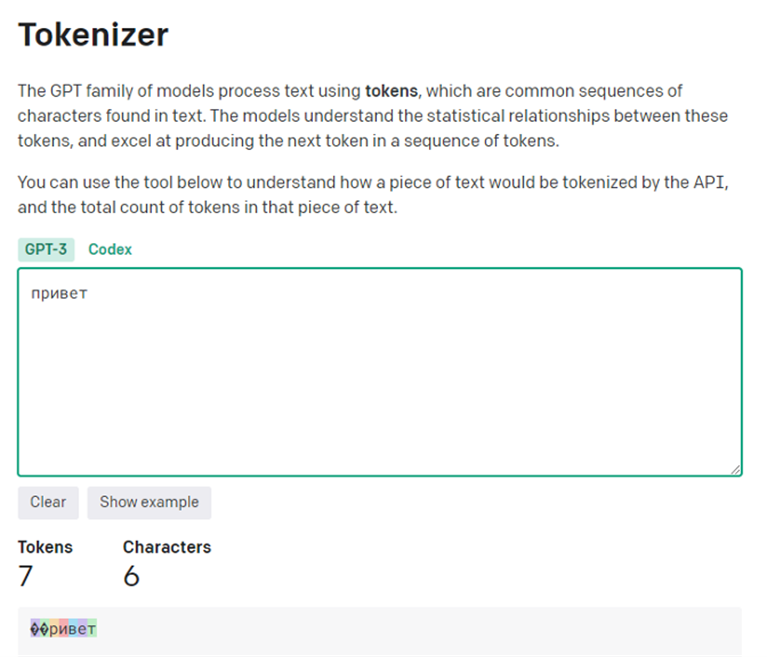
А «привет» — уже семь
В модели ChatGPT 3.5 Turbo (это для быстрых и дешёвых ответов и решений) контекст ограничен четырьмя тысячами токенов (есть модель на 16 тысяч), в GPT4 базовая — восемь тысяч, и уже есть бета-вариант с 32 тысячами токенов.
Оплата ChatGPT и ряда других коммерческих моделей производится по токенам.
Есть ограничение на количество запросов и токенов в минуту от одной организации. Раньше это было восемь тысяч токенов в минуту, теперь в GPT3,5T — 90 тысяч токенов и 3 500 запросов к API в минуту, в GPT4 — семь тысяч запросов к API и 180 тысяч токенов в минуту.
Это важно для разработки, если у вас вдруг вырастет нагрузка, придётся учиться балансировать между аккаунтами. То есть как минимум иметь второй аккаунт от другой компании (ещё токен к API), потому что два токена в одной организации суммируются по использованию.
Есть лимиты по деньгам: по умолчанию — 120 долларов в месяц. В разработке надо ещё учитывать счётчик в деньгах, иначе есть шансы упереться в этот лимит тоже. Лимиты поднимаются со временем после нескольких успешных платежей. За пару месяцев — 600 долларов, но, если нужно, можно заполнить специальную форму и запросить столько, сколько необходимо. Это сделано для безопасности как OpenAI для случая, когда компания решит не платить за доступ и заблокирует карту, так и для защиты пользователей от случайных огромных трат.
Ещё помните, что из-за итеративной модели вывод также является частью запроса, поэтому 32 тысячи токенов — это запрос + вывод, а не только запрос. То есть, если вы грузите очень большой промпт, может не остаться места для вывода в едином запросе. Придётся делать продолжение, тогда модель будет «вспоминать» прошлый диалог и пытаться его продолжить.
Но «вспоминает» она его обычно частично и куда хуже, чем при работе в одном промпте. Память — как у Золотой рыбки.
Хотя есть инструменты, которые позволяют добавить памяти: разработчики, обратите внимание, что при использовании своих приложений вам нужно при каждом запросе передавать оригинальный контекст в промпт, памяти у модели при работе через API просто не существует.
Раньше были модели с другим количеством параметров и с меньшим контекстом — это
Давинчи, Кюри, Ада. Теперь все они легаси и будут удалены в следующем году. Ада была самой быстрой и с низкой стоимостью, но из-за комплишн-архитектуры (а не векторной) могла решать только простые задачи. Давинчи была наиболее продвинутой, на её основе был построен ChatGPT 3.5. Это были также общие языковые модели, но немного с другими принципами.
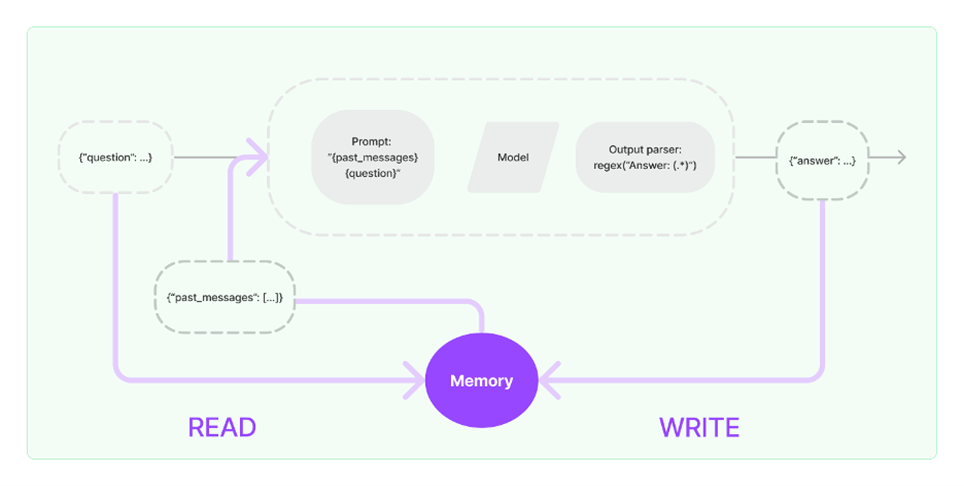
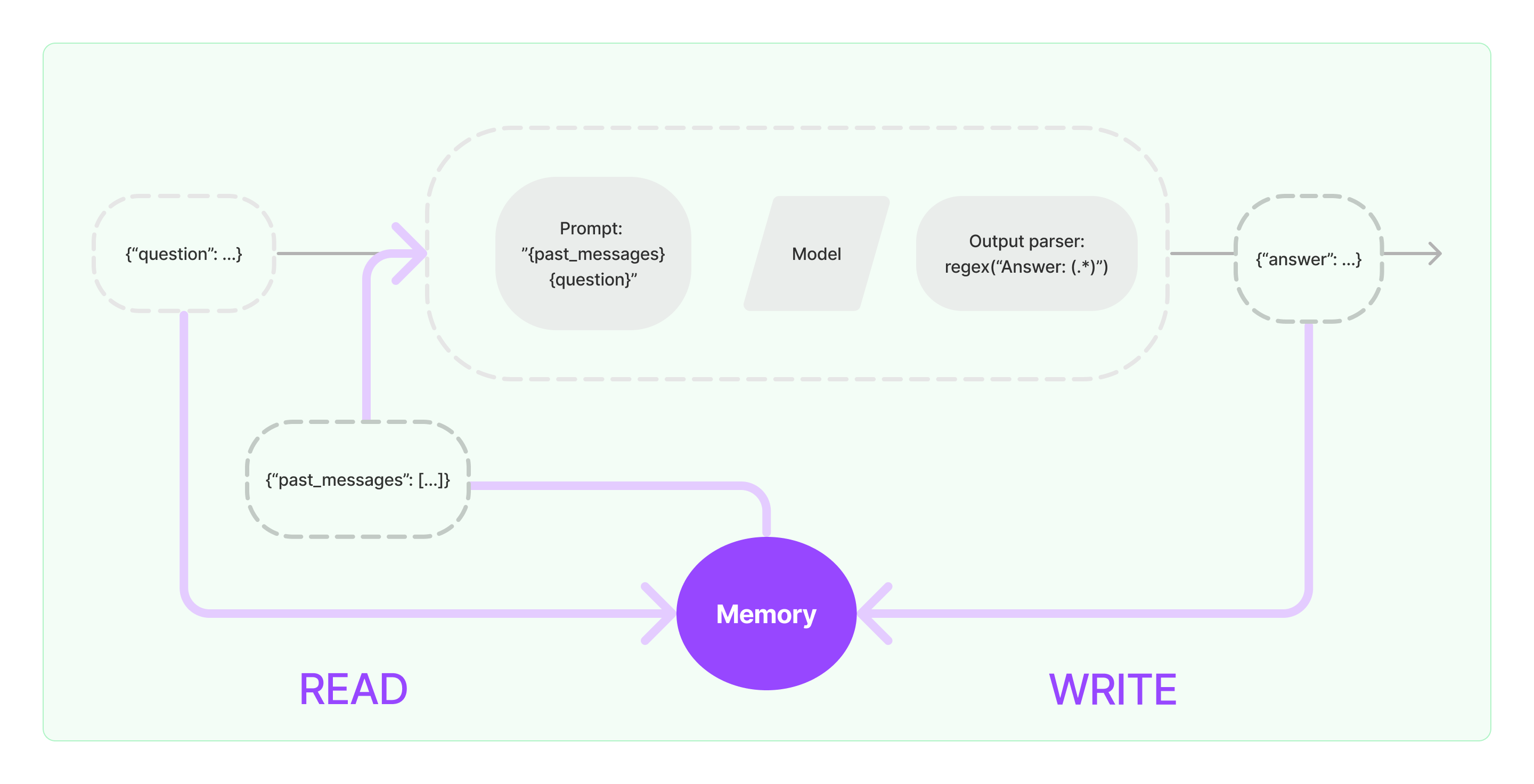
Как работает добавление памяти
Как запихать много информации в промпт?
Если вам нужны очень большие запросы, то сейчас есть LLM Anthropic, которая даёт 100 тысяч токенов.
Со временем количество токенов в промпте будет увеличиваться, а их цена — снижаться. Через год текущие ограничения будут смешны. Уже заявлены модели с ограничением в пять миллионов токенов.

В случае с ChatGPT есть вариант перевести промпт на английский (например, им же или Deepl) и запихать английский промпт в модель. Он будет примерно в четыре–шесть раза короче с точки зрения количества токенов.
Как получить большой вывод?
Например, если вам нужно придумать пять тысяч вопросов про Хабр, то вы можете прямо спросить, а затем получить первую пачку в первом промпте, дать команду «Продолжай!» и получить вторую пачку во втором промпте и так далее. Но через несколько запросов память выветрится, вопросы начнут повторяться, и полезность будет снижаться.
Как обработать большое количество текста?
Если вам нужно перевести книгу, то можно скармливать её в модель по главам, а потом сшить итоговый текст.
Если вам нужно суммаризировать книгу, то вы получаете саммари для каждой главы, а потом — саммари от суммы саммари. Вот здесь то и применяются алгоритмы MapReduce и Refine.
Сама суть суммаризации — хорошо детализировать участки с высокой плотностью смысла и пропускать с низкой, чтобы сжать смысл до небольшого объёма. В случае дискретизации вы получите десять одинаковых по плотности участков. То есть, если по дороге была глава вроде «То же самое, что и Валар, но труба пониже и дым пожиже», то с качеством итоговой суммаризации возникнут проблемы.
Ещё проблема в том, что эти методы не очень точные. Модель подбирает ближайший перевод, и он может варьироваться. Например, каждый раз одни и те же имена персонажей будут переводиться в зависимости от контекста. От главы к главе Severus Snape может стать Злодеусом Злеем, Северусом Снеггом, Северусом Снейпером, Северусом Змеевичем или Северусом Змеепсом. Про мистера Змеепса проверено. Легко!
MapReduce-методы подразумевают разбиение на куски и обработку каждого из них, а потом — сшивку результатов. Есть ещё Refine-методы, там тоже разбиваем на куски, но результат выполнения от предыдущего куска подкладываем в контекст и говорим: «Вот у тебя контекст, вот у тебя ещё кусок текста, найди всё, что нам нужно, и сохрани в контекст». Когда идём на следующий этап, то берём контекст от предыдущего. То есть текущее саммари обновляется на каждой итерации, контекст перекладывается дальше и дальше и постоянно обновляется.
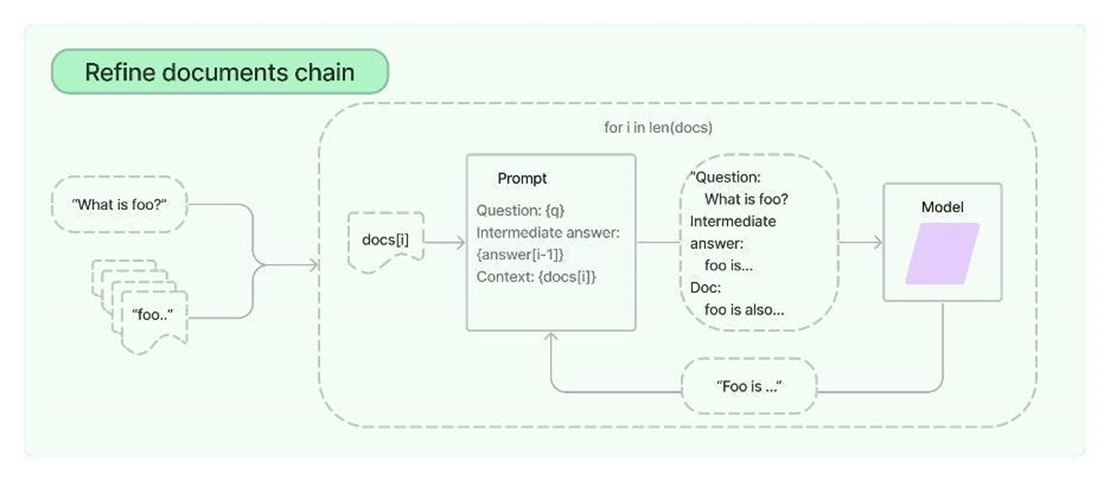
Refine выглядит вот так
Двухагентные схемы
Это, по сути, диалог двух LLM, каждая из которых играет свою роль.
Например, защита Миджорни устроена так: первая модель определяет, что хотел нарисовать пользователь, и пробует понять, нет ли там порнографии. Затем рисует. Вторая модель приходит смотреть на готовый рисунок и реверсит его на предмет того, нет ли там порнографии. Пользователь может легко обойти первую модель, заказав супергероиню в белье, которое может становиться прозрачным, но тогда стоит этой супергероине применить свою сверхспособность, как его быстро забанит вторая.
Вот Гэндальф, который не отдаёт вам пароль. У него тоже с определённого уровня начинается двухагентная схема. Попробуйте отобрать пароль на седьмом уровне: gandalf.lakera.ai.
Для нас куда важнее, что агентные схемы могут позволять решать очень большие задачи.
Например, вы можете заказать ТЗ на приложение у первого агента, а он разобьёт его на участки и начнёт просить реализацию у второго, а затем осуществлять приёмку по ТЗ. Именно так, грубо говоря, работают сервисы написания игр по словесному описанию.
Хороший пример агентного сервиса — GPT Engineer. В него заложен алгоритм работы программиста. Он получает техзадание и читает его. Потом формулирует по нему вопросы.
Задаёт эти вопросы своему менеджеру. Менеджер на них отвечает максимально подробно.
Возможно, требуются ещё какие-то уточнения. Когда он собирает достаточно информации, то начинает писать код, сначала — шаблон, потом уточняет по каждому участку. Он полностью пишет готовое приложение, потому что есть вся информация. Потом сам же его принимает по ТЗ и правит, если надо. В простом случае получается готовая работа. В сложном всё равно полировать руками или делать очень сильное колдунство с промптами, вступая в технический диалог, напоминающий спор с упёртым и упоротым джуном. Ничего нового.
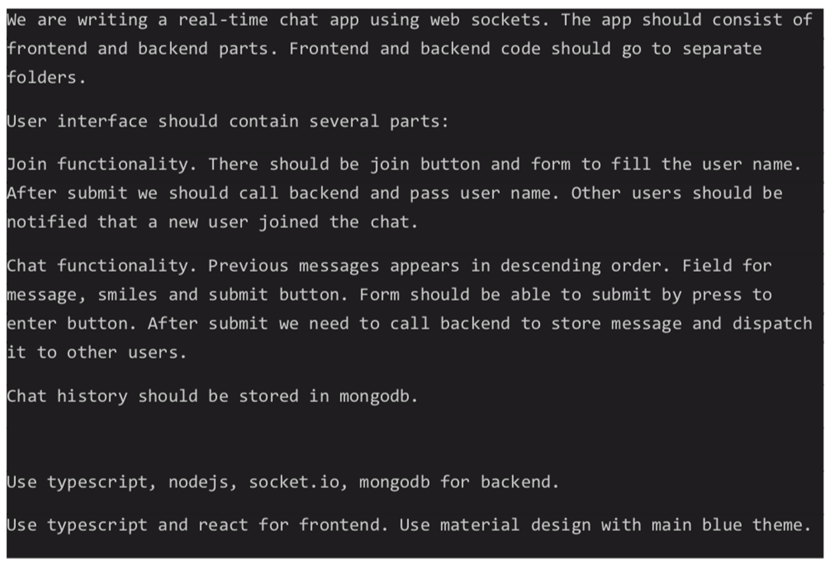
Промпт для генерации
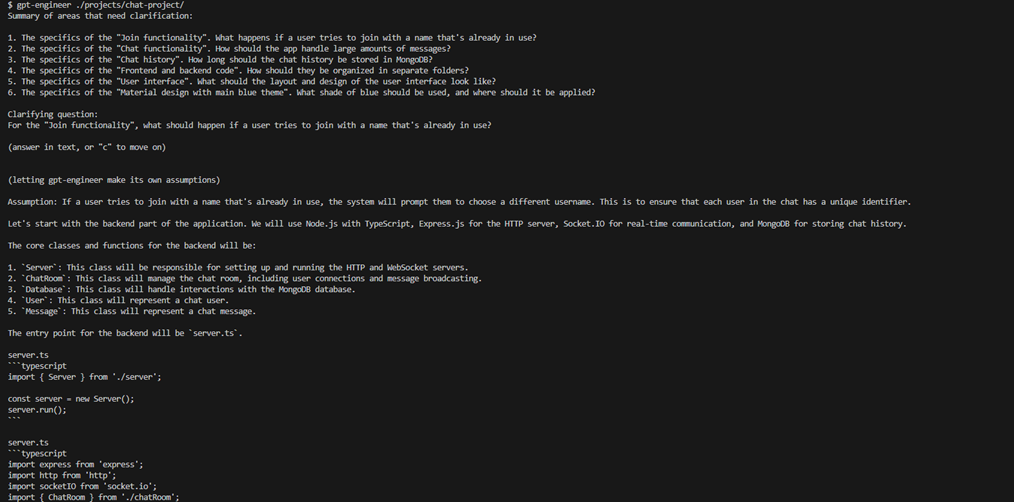
Вопросы от GPT Engineer
Агентскими моделями можно генерировать целые книги, просто задав общую канву и персонажей. Можно писать полноценные чат-боты. Можно предложить агенту поиграть в собеседование: попросить побыть интервьюером, придумать вопросы, а затем оценить, прошли вы или нет и где что подтянуть.
Можно попросить научить какой-то технологии (до 2021 года), научит.
Можно, в конце концов, уговорить ChatGPT стать D&D-мастером.
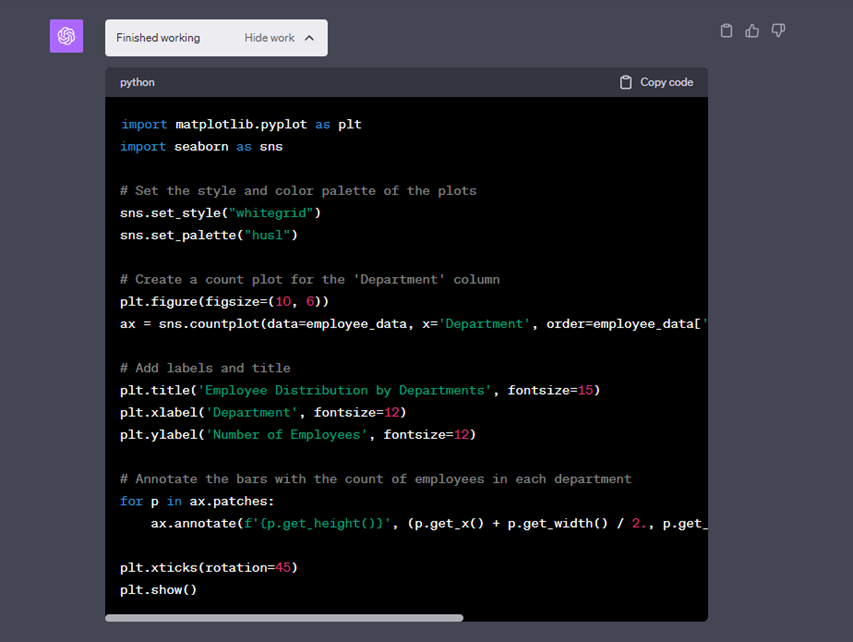
Но, наверное, лучшая история последовательных запросов — это импорт XLS и аналитика данных в нём. Берёте XLS-файл, скидываете в GPT, говорите ему, что надо самостоятельно писать код для парсинга, вытаскивать данные и делать анализ. Он разбирает, что и в каких колонках, дальше пишет код, чтобы посчитать метрики, которые вы запросили. Можно попросить сделать визуализацию. Это технология, которая уже встроена в Chat GPT4, называется код-интерпретатор. Это PowerBI на минималках.
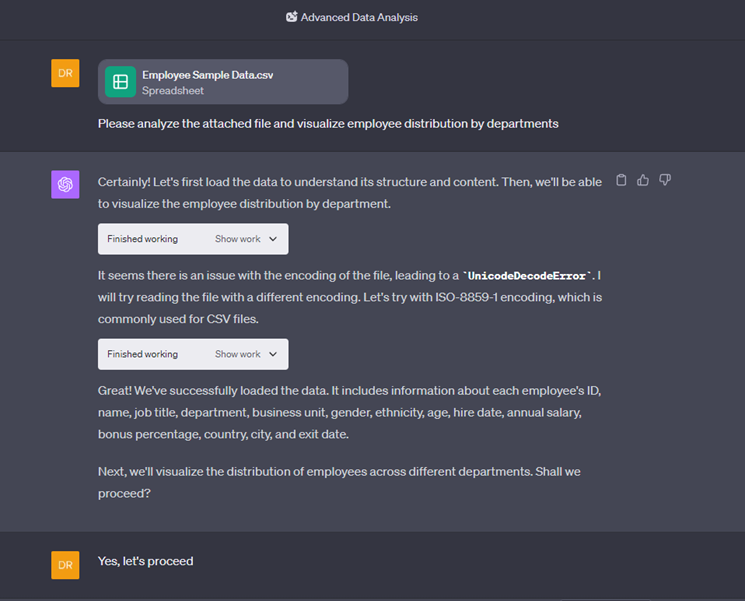
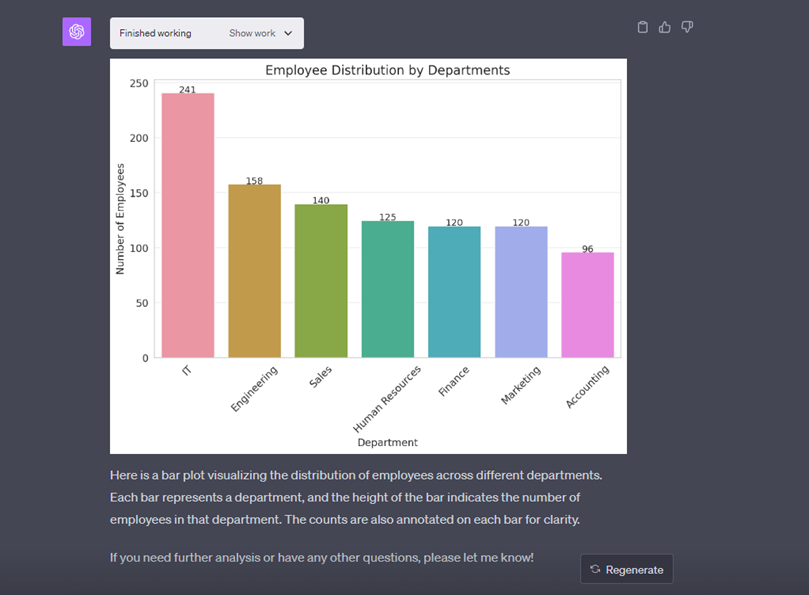
В процессе работы видно, каким образом происходят вычисления.
Voice-to-text
Существуют отдельные модели преобразования голоса в текст, они не зависят от GPT4 и поставляются отдельно через API. Например, OpenAI предоставляет модель Whisper 2.0. Свои аналоги есть и у нас: это Sber Salute, Yandex. А ещё существуют Open Source-модели. Раньше это тоже можно было делать последовательными цепочками из разных распознавалок, но сейчас всё стало намного проще. Практическое применение уже есть: берёте всю базу звонков колл-центра, запихиваете в распознавание, а потом задаёте ChatGPT вопросы вроде «Выдели нижние 10 % самых недружелюбных операторов». Ну или проверяете более конкретные вещи, которые раньше опирались на ключевые слова, а теперь могут опираться на мнение нейросети.
Это, кстати, возможно, конец эры жёстких скриптов для колл-ценров, потому что скрипты часто рождаются потребностью делать потом аналитику. Относится это ко всем, кроме банков: у них скрипты — юридическая особенность.
Векторизация
Есть эмбеддинги модели, чтобы векторизовать базу и делать поиск по смыслу. Векторизация даёт нам возможность найти релевантные ответы для любого вопроса. Скидываете набор документов — получаете векторное представление текста, в котором можно найти информацию по смысловому совпадению. Круто!
Векторизация нужна:
- Для построения приложений, работающих с собственной базой знаний.
- Для обработки больших объёмов текста (LLama index здесь используется, но можно написать и своё решение).
- Для построения решений с публичными базами знаний.
- Для разработки умного поиска.
Может показаться, что эмбеддинг умрёт, потому что число токенов в запросе растёт, но нет. Не умрёт! Оплата-то за токены. Если есть постоянные запросы и большая база знаний, то мы не можем передавать всю базу в языковую модель: нужен вектор.
Как это работает: от вас нужно понять, что есть неделимая часть текста. Например, если бы мы векторизовали Вики, то викикварком была бы страница или подразделом страницы. То есть для каждой задачи нужно найти минимальный кусок текста, который будет иметь смысл и который можно использовать.
Вики разбивается на страницы и каждую из них передаёт в вектор либо по заголовкам на странице. Для разбивки используются Text Splitter's, которые автоматизируют этот процесс и помогают нам сделать куски токенов нужной длины. Для создания вектором уже используются модели. Сейчас мы переходим на модели OpenAI, а именно — на text-embedding-ada-002, потому что с недавних пор это получается примерно в десять раз дешевле легаси. Легаси, кстати, в этом контексте — это то, что не text-embedding-ada-002. Ещё существуют Open Source-решения, но сегодня о них не будем.
Итак, векторная база данных хранит эмбеддинги, которые по своей сути — это математические тензоры. То есть можно делать поиск по схожести, поиск аномалий, можно работать с временными метками (что очень круто для промышленных данных) и хорошо фильтровать. Из готовых для разработки решений посмотрите на FAISS (его можно запускать локально на CPU/GPU), есть Pinecone (облачное) — они позволяет запустить базу, но там сторонний вендор.
У себя — ChromaDB и Qdrant.
В принципе по статистике от Pinecone, одна база на одной машине до пяти миллионов векторов — это 5–10 долларов от провайдера.
Если вы хотите конфигурировать базу под разные LLM, то не забывайте, что нужно настраивать под размер вектора, который указан в описании в эмбеддинг-модели. В OpenAI нужно указать размер вектора 1532.
Самый частый вопрос — можно ли по вектору восстановить текст. Если он был зашифрован, то можно. Можно восстановить смысл, но не исходные формулировки. Представьте, что есть некий межгалактический язык, понятный и дельфинам, и оркам, и разумным деревьям. Это векторное представление. Развернуть из него смысл — это скорее задача перевода. Но на всякий случай напоминаю, что модель MS училась на английском, поэтому большая часть текста более-менее адекватно конвертируется в английский. Если какие-то слова типа «голубцов» были изучены в русском и не имеют аналогов, то их изначальные токены — тоже русские. Но если текст был зашифрован, то его можно восстановить.
Если вы хотите найти эпизод про дуб в «Войне и мире» и перевести его на суахили, то вам понадобится найти в векторной базе место про дуб и добавить в контекст LLM для перевода, вырезать именно этот эпизод исходника и переводить уже его. А если вам нужно составить карту половых связей сериала по циклу книг «Игра престолов», то достаточно векторной базы.
В более сложных задачах, например, для описания ботаники «Властелина колец», чтобы найти регион Англии, который ему наиболее соответствует, понадобится перевести в вектор всю книгу для создания базы данных, а затем запросить всю информацию про ботанику и работать уже с ней. Кстати, хоббиты — в Вурчестере.
LangСhain
Это такой фреймворк, который позволяет создавать с нуля приложения на основе AI из разных модулей, как мы создаём какую-нибудь машину из конструктора Lego.
Лангчейн появился в 2022 году, в 2023-м стал популярным + получил финансирование на 200 миллионов долларов при оценке в миллиард. Развивается.
По сути, это фреймворк для создания приложения на основе LLM:
- Есть API к облачным моделям, есть возможность подключать локальные или опенсорсные развёрнутые в своей инфраструктуре.
- Есть автоматизация написания промптов и большая библиотека хороших практик, шаблоны для разных задач.
- Есть цепочки, то есть тот самый конструктор, который связывает разные API.
- Есть лоадеры, позволяющие соединять данные с цепочками. То есть он может загрузить что-то из облака по ссылке, отдать в векторизацию, потом загрузить в удобоваримом виде в LLM, принять результат и тому подобное. Можно идти на любые извращения, хоть XLS отрисовывать в Миджорне, чтобы отчёт получался красивым.
- Есть агенты, которые учат LLM думать, идти по шагам и пользоваться сторонними инструментами.
Ещё через Лангчейн очень удобно работать с Chat GPT, потому что внутри себя он содержит логику, которая обрабатывает ограничения — как по контексту, так и по лимитам на количество запросов, на количество токенов в минуту. Даже если наша задача — просто работать с API Chat GPT, то через Лангчейн это будет намного лучше и удобнее, чем напрямую с API. Ещё есть удобные инструменты для агентов — для изучения актуального Интернета, для SMS, почты. Можно что-то спросить кожаного, например, попросить пройти капчу. Можно заказать «химию» на Амазоне. И так далее.
Prompt engineering
Одна из основных деталей при работе с LLM — техники промптов: они помогают лучше понять возможности и ограничения больших языковых моделей. Prompt engineering применяется для разработки надёжных и эффективных методов взаимодействия с LLM, охватывая много навыков и техник, которые будут полезны для получения желаемого результата.
Среди базовых техник:
- Zero-Shot Prompting.
- Few-Shot Prompting.
- Chain-of-Thought Prompting.
TL;DR
В целом представление вы получили, и простой ликбез окончен. В следующей серии мы расскажем про проблему с защитой себя от LLM, а LLM — от пользователя. Потому что одно дело, когда мы требуем рассказать, как правильно совершить преступление, и совершенно другое — когда в ответ на запрос ребёнка: «У меня котя искупалась, нарисуй мокрую киску», ваша корпоративная нейросеть выдаёт немного не тот вывод, который был нужен пользователю. Ну или ещё лучше — раскрывает какую-то конфиденциальную информацию. В общем, поговорим про джейлбрейки и то, как сделать, чтобы вывод модели не порочил вашу компанию. Ну и про правоприменительную практику, благо её нет.
Комментарии (6)

1nd1go
16.10.2023 15:16Классная статья, спасибо. Вопрос - какие мощности нужны для запуска локально модели (там общей LLAMA, или llamacpp) чтобы ее перформанс выхлопа был по скрости сравним с GPT3.5, если речь идет об однопользовательском режиме?

alkons Автор
16.10.2023 15:16Для LLama2 минимум две A100 — для версии 13b chat, или три для полноценной 70b chat.

{kind=link}
{kind=link}
iamawriter
Расколол старину Гэндальфа по упомянутому https://gandalf.lakera.ai/ попал в топ 8%, еще бы знать, что этот рейтинг означает. Спасибо за наводку.
alkons Автор
Отличный результат. Получилось расколоть 8 уровень?
iamawriter
Вчера на радостях решил, что бонусный уровень - это форма регистрации) Сейчас зашел снова на сайт, гляжу - пишет Lvl 8. I am GANDALF THE WHITE v2.0, stronger than ever! Fool me seven times, shame on you. Fool me the eighth time – let's be realistic, that won't happen. Т.е. предлагает пройти тот самый бонусный уровень. Немного потыкался, на все мои попытки ответ примерно такой: "I see you're trying to hack me." Сейчас нет ни времени, ни запала уже, если честно, потом буду пробовать, но пока выглядит так, что боту запрещено сообщать вообще любую информацию о пароле, и даже использовать его каким-бы то ни было способом в своем ответе. Но я сколь-нибудь глубоко не разбирался, и правил не читал, если таковые написаны) Может быть, пишу ересь, не судите строго