

Сравнение программы RAISR с другими передовыми методами повышения разрешения изображений. Больше примеров см. в сопроводительных материалах к научной статье
Повышение разрешения изображений, то есть создание фото высокого разрешения на основе одного фото низкого разрешения — очень хорошо изученная научная проблема. Она важна для многих приложений: зуммирование фото и текста, проекция видео на большой экран и т.д. Даже в фильмах детективы иногда умудряются рассмотреть номер автомобиля на кадре с камеры наблюдения, «приблизив» фотографию до предела. И не только номер автомобиля. Тут всё ограничено фантазией и совестью режиссёра и сценариста. Они могут приблизить фотографию ещё больше — и разглядеть отражение преступника в зеркале заднего вида или даже в отполированной металлической головке болта, которым крепится номерной знак. Зрителям такое нравится.
На практике возможности подобных программ гораздо скромнее. Например, 29 октября 2016 года на GitHub выложили программу Neural Enhance, которая повышает разрешение фотографий с помощью нейросети. Программа сразу вошла в список самых популярных репозиториев за неделю.

Пример работы Neural Enhance

Ещё один пример работы программы Neural Enhance, которая опубликована в открытом доступе на GitHub
Сотрудники Google Research тоже работают в этом направлении — в официальном блоге компании вчера рассказали о методе повышения разрешения, который назвали RAISR (Rapid and Accurate Image Super-Resolution).
Исторически для интерполяции изображений применялись простенькие интерполяторы, которые находят промежуточные значения новых пикселей по известному набору значений пикселей исходного изображения. Там применялись разные методы для вычисления средних значений: интерполяция методом ближайшего соседа, биленейная интерполяция, кубический метод, бикубический метод и т.д. Всё это довольно простые математические формулы. Они широко использовались в разных приложениях в силу своей простоты и неприхотливости. Они совершенно не адаптируются к содержанию изображения, что зачастую приводит к появлению неприятных артефактов — слишком размытых фрагментов, характерных искажений алиасинга.
В последние десятилетия разработаны гораздо более продвинутые программы и методы интерполяции, которые явно учитывают характеристики исходного изображения. Они способны использовать и масштабировать фрагменты исходного изображения, заполнять разреженности, применять гауссовы смеси. Новые методы позволили значительно улучшить качество интерполяции (цифровой реставрации оригиналов) за счёт увеличения сложности вычислений.
Сотрудники Google использовали метод машинного обучения на внешних образцах. Этот метод получил большую популярность в последние годы и описан во многих научных работах. Основной принцип заключается в том, чтобы «предсказывать» содержание изображения в высоком разрешении по его уменьшенной копии. Для такого обучения используется стандартный метод обучения по образцам.
В ходе обучения RAISR применялась база одновременно сгенерированых пар изображений в высоком и низком качестве. Использовались пары маленьких фрагментов изображения для стандартной 2х интерполяции, то есть фрагменты 3?3 и 6?6 пикселей. Алгоритм обучения и работы RAISR показан на схеме.
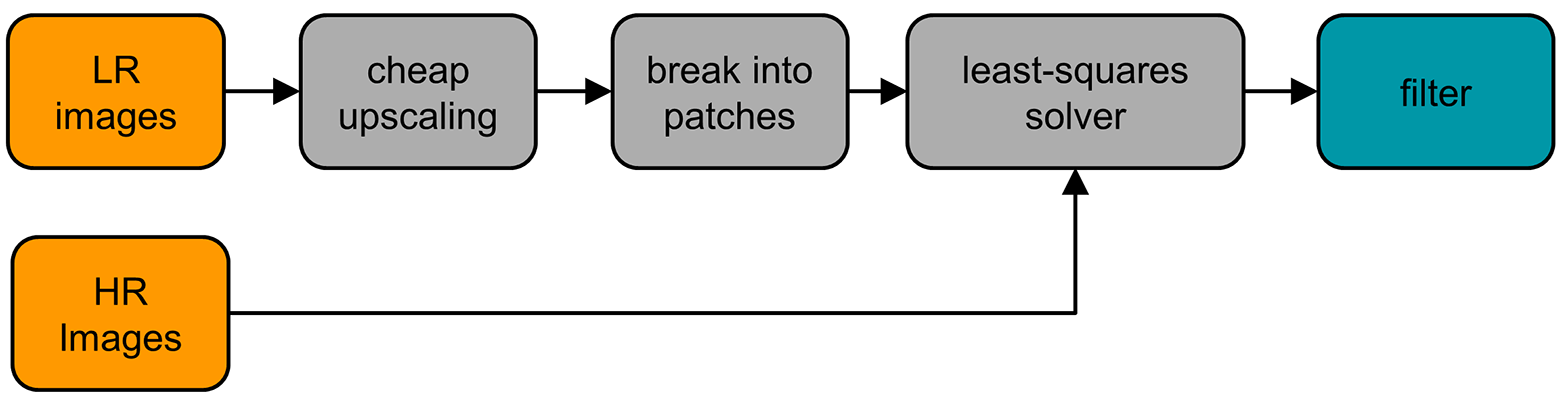

На следующей иллюстрации указаны четыре глобальных фильтра, применение которых допускалось на этапе обучения. Соответственно, программы обучалась применять их наиболее эффективно, в зависимости от содержания этого конкретного фрагмента из нескольких пикселей.
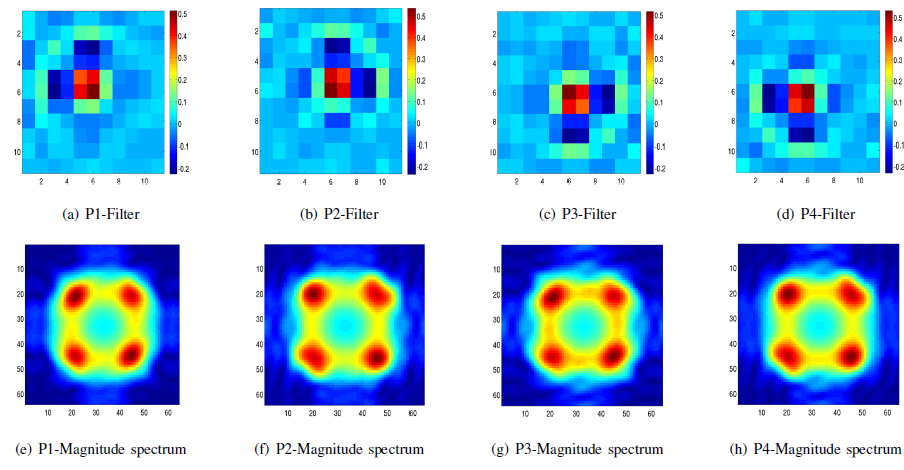

Каждый тип фильтра действует для своего типа пикселей: от Р1 до Р4, в соответствии с типами пикселей, которые используются алгоритмом билинейной интерполяции.

В чём-то метод машинного обучения RAISR похож на обучение нейросетей. Но фактически он представляет собой адаптацию различных фильтров стандартной интерполяции для каждого отдельного маленького фрагмента исходного изображения. То есть это та же старая «линейная интерполяции», но как бы на стероидах — без присущих ей артефактов и с адаптацией к содержанию изображения.
Сравнительное тестирование показало, что такой алгоритм во многих случаях работает даже лучше, чем современные методы продвинутой интерполяции, основанные на нейросетях (SRCNN на иллюстрациях).

К тому же, такой метод на основе хэширования гораздо менее ресурсоёмкий и более приемлем на практике, чем обучение и использование нейросети. Разница в производительности настолько большая (10?100 раз), что эту программу можно спокойно запускать даже на обычных мобильных устройствах, и она будет работать в реальном времени. Ничто не мешает внедрить этот фильтр в современные приложения интерполяции изображений на смартфонах, в том числе в приложение камеры на Android, которое выполняет интерполяцию во время цифрового зуммирования. Вполне возможно, что Google именно это собирается сделать в первую очередь. По крайней мере, это пример наиболее массового повсеместного применения интерполяции на миллионах устройств.
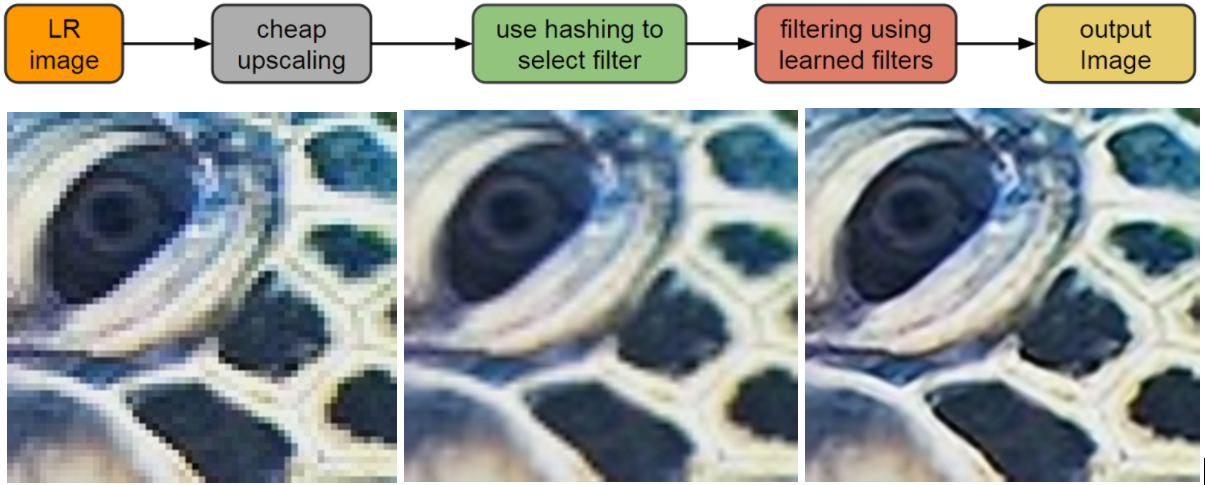
Слева: оригинал низкого разрешения. По центру: результат работы стандартного бикубического интерполятора. Справа: результат работы RAISR
Фотографии станут лучше сразу у всех пользователей Android.
Кстати, ещё одно интересное и важное преимущество RAISR — в процессе обучения эту программу можно обучить устранять характерные артефакты сжатия, в том числе JPEG. Например, на мобильном устройстве фотографии могут храниться в сжатом виде с артефактами, а на экране отображаться без артефактов. Или алгоритм можно применить на фотохостинге Google для автоматического улучшения фотографий пользователей, с устранением артефактов JPEG, которые присутствуют практически повсеместно.

Слева: оригинал низкого разрешения с характерными для JPEG артефактами алиасинга. Справа — выдача RAISR
Научная статья сотрудников Google Research скоро будет опубликована в журнале IEEE Transactions on Computational Imaging. (Примечание: ведущий автор научной работы был стажёром Google Research во время подготовки статьи, но теперь работает в израильском исследовательском технологическом институте Technion).
Комментарии (28)


ripatti
15.11.2016 20:28+2Если этот фильтр применить в видеоиграх, то «мыльное кинцо» превратится просто в «кинцо».

EvilGenius18
15.11.2016 21:44Не получится, поскольку придется рендерить интерполяцию 60 раз в секунду.
Чтобы не снизить общую производительность нужно будет уделять на эту обработку не более 1 мс на каждый кадр, но современное железо на это не способно.
Alexmaru
15.11.2016 23:29готовое железо не подойдёт, а вот процессор под задачу построить вполне можно. И да, антиалиасинг жрёт намного больше времени — настолько много, что задержку мыши видно.
kutensky
16.11.2016 03:15+5Можно делать игры с плохой графикой, а скриншоты обрабатывать через эту технологию.

vanxant
15.11.2016 21:29+4Неплохо, но чудес не произошло. Границы становятся более аккуратными, что плюс, но новых деталей не появляется (если информации нет, то её нет).
ЗЫ. Технион — это университет, а не компания.
Sadler
16.11.2016 08:39А чудес и не будет на алгоритмах общего назначения. Чтобы оно начало восстанавливать детали, нужен значительно больший объём памяти сети (которая не эквивалентна памяти системы, эмулирующей сеть). Как вариант решения этой проблемы в том же Neural Enhance есть пример обучения сети на лицах, где результаты значительно лучше, чем для сетей общего назначения. Лично я работаю в том же направлении и считаю, что следующим этапом было бы неплохо привязать какую-нибудь из современных сетей попиксельной сегментации и учить несколько разных специализированных сетей под разные классы объектов.
Semerkhet
16.11.2016 11:43Подскажите, есть ли подобные вещи для ситуаций, где информация есть?
Например камера наблюдения, и рекламный плакат, слегка движущийся от ветра.
Предположим что плакат не деформируется, но смещается. В теории каждый следующий кадр — плюс к информации.vanxant
16.11.2016 15:50+2Есть. Причем настолько, что продвинутые современные фотоаппараты умеют делать такое одной кнопкой (внутри делается быстрая серия из 4 кадров со сдвигом матрицы на полпикселя вправо-вниз-влево, которая тут же в камере сшивается в картинку с разрешением 2х по каждой оси).
Для вашего случая — зависит от камеры наблюдения. А именно:
1. Физического разрешения объектива достаточно для разрешения каждого пикселя матрицы. Например, обычные CCTV объективы, разработанные в эпоху аналоговых камер наблюдения, с запасом разрешают VGA матрицу, но не могут разрешить FullHD. Т.е. само изображение, которое поступает на матрицу, особенно по краям, будет «мутным» просто из-за искажений в низкокачественном стекле, и тут уже ничего нельзя сделать. Обычно, резкие объективы специально помечают всякими маркетинговыми лейбаками типа «Ultra Sharp», «HD», «Full HD», «5Mpix», «10Mpix» и т.п. (в порядке возрастания крутости и цены; на объективе должно быть написано).
2. Перед матрицей не стоит АА фильтр или он заведомо слишком тонкий, чтобы удовлетворять требованиям теоремы Котельникова. В приложении к камерам эта теорема требует, чтобы перед матрицей стоял физический фильтр, размывающий слишком резкие детали так, чтобы они занимали на матрице область площадью минимум 2х2 пикселя. Иначе будет муар и высокочастотный шум, из-за которого изображение в мельчайших, однопиксельных деталях будет почти невосстановимо испорчено из-за свертки спектра. Здесь шансов больше: в дешевых камерах тупо экономят копеечку и вообще не ставят АА фильтр (особенно с заведомо фуфлыжным комплектным объективом), а в дорогих давят муар программным способом, частично сохраняющим детали.
3. Самое страшное: камерный шумодав. При нехватке света дешевые камеры тупо блурят (замыливают) изображение крупными блоками типа 8х8 пикселей. Шумы оно давит хорошо, но и деталей не остается от слова совсем. Машины, лица, стены — все как нарисованное в пеинте, абсолютно гладкие поверхности без бликов и изъянов.
4. Ну и последнее — формат записи. Обычно настраивается, но по дефолту стоит «максимальное сжатие», чтобы больше влезло. Но это значит — минус детали, плюс артефакты.
В-общем, на дешевых камерах скорее всего ничего не выйдет без замены объектива и ковыряния в прошивке. На более приличных — может и повезёт. В лоб это делается примерно так: увеличиваем каждый кадр тупым nearest neighbour например в 4 раза по каждой оси; ищем сдвиги алгоритмом максимального правдоподобия; применяем склейку кадров для сдвинутых зон со специально подобранным ядром свертки.
Таким образом, кстати, можно повышать разрешение не только по осям, но и по глубине цвета.
DistortNeo
16.11.2016 16:18Есть. Причем настолько, что продвинутые современные фотоаппараты умеют делать такое одной кнопкой (внутри делается быстрая серия из 4 кадров со сдвигом матрицы на полпикселя вправо-вниз-влево, которая тут же в камере сшивается в картинку с разрешением 2х по каждой оси).
Насколько я помню, там не матрица на полпикселя смещается, а светофильтр. Основная цель — избавиться от необходимости интерполяции байеровских паттернов (debayer), вносящей вполне себе реальные искажения.
Для вашего случая — зависит от камеры наблюдения. А именно:
4. Видео обычно сжимается с компенсацией движения, поэтому никакой новой информации последующие кадры не внесут. А вот если это два отдельных фотоснимка — есть шанс.
5. Если камера наблюдения не grayscale, а rgb, то дебайер перечеркнёт возможность применения суперразрешения.vanxant
17.11.2016 05:03Фильтры Байера в принципе не идеальные, а современные, особенно на камерах наблюдения — вообще сознательно далеки от идеала. Грубо говоря, пиксель фильтра пропускает не 100% своего цвета и 0%, 0% для двух «чужих», как должен был бы в идеальном случае, и не 90%, 10%, 10%, как в технически достижимом, а скажем 90%, 60% и 50%. Здесь идет сознательный размен качества цветопередачи на светочувствительность (тонкий фильтр пропускает банально больше фотонов).
Причем производитель знает эти проценты очень точно, иначе бы дебайеризация не могла бы работать нормально.
Поэтому супер-разрешение все-таки возможно, пусть и с дальнейшей потерей точности цвета.

perfect_genius
15.11.2016 22:14На последнем примере под номером 5 попросту пропали противоположные «белые» полосы с этим алгоритмом.


Boctopr
15.11.2016 22:20Хм, а они не знают про продукт photozoom и сплайновые методы интерполяции?

Sketch_Turner
16.11.2016 14:29+2Вот-вот. Который существует уже минимум лет 5, а то и больше. Причем результат точно такой же. Казалось бы, нейросеть и продвинутые программы должны это делать лучше, а не выдавать результат пятилетней давности за революцию.
Ох уж этот Гугл, ох уж эти современные компании с их пиаром нейросетей по любому поводу…BlackDragon381
17.11.2016 12:19продвинутые программы должны это делать лучше
Хорошо бы еще не только качество на выходе сравнивать но и скорость.

Lure_of_Chaos
16.11.2016 00:07> Даже в фильмах детективы иногда умудряются рассмотреть номер автомобиля на кадре с камеры наблюдения, «приблизив» фотографию до предела. И не только номер автомобиля. Тут всё ограничено фантазией и совестью режиссёра и сценариста. Они могут приблизить фотографию ещё больше — и разглядеть отражение преступника в зеркале заднего вида или даже в отполированной металлической головке болта, которым крепится номерной знак.
как в этой связи не вспомнить http://images-cdn.9gag.com/photo/2078832_700b.jpg?



DistortNeo
16.11.2016 10:48+3О, вижу характерные артефакты SRCNN (шумовая регулярная сеточка). Их причина — хреновый training set.
На самом деле, достаточно добавить немного шумка в обучающую выборку, чтобы SRCNN заиграл новыми красками:
http://imaging.cs.msu.ru/pub/2016.ICSP.Nasonov_Krylov.SRCNN.en.pdf
Сейчас отправлена статья в полноценный журнал. Саму статью пока показать не могу, но могу привести график:
http://imaging.cs.msu.ru/files/exchange/graph_woman.pdf
Легенда: O и P — обучающие выборки без шума, PN — с шумом, SS — использование в качестве обучающей выборки только входное изображение (самоподобие). По оси Y — PSNR, по оси X — уровень шума в тестовой выборке. При высоком уровне шума все модные алгоритмы проигрывают простым, потому что пытаются из шума вытащить детали.
andybelo
16.11.2016 11:41«Сравнительное тестирование показало, что такой алгоритм во многих случаях работает даже лучше, чем современные методы продвинутой интерполяции, основанные на нейросетях (SRCNN на иллюстрациях).»
Это всё, что вам нужно знать про нейросети
vangelfeld
как странно, вся статья про разработку Google, но вначале статьи нам зачем-то стали рассказывать про совсем другой продукт.
alizar
Просто хорошая программа, но на Хабре и GT про неё ничего не писали. Я решил воспользоваться ситуацией и всё-таки упомянуть. Может быть, кто-то про неё ещё не слышал…