

Пример работы нейросети после обучения на базе лиц знаменитостей. Слева — исходный набор изображений 8?8 пикселей на входе нейросети, в центре — результат интерполяции до 32?32 пикселей по предсказанию модели. Справа — реальные фотографии лиц знаменитостей, уменьшенные до 32?32, с которых были получены образцы для левой колонки
Можно ли повышать разрешение фотографий до бесконечности? Можно ли генерировать правдоподобные картины на основе 64 пикселей? Логика подсказывает, что это невозможно. Новая нейросеть от Google Brain считает иначе. Она действительно повышает разрешение фотографий до невероятного уровня.
Такое «сверхповышение» разрешения не является восстановлением исходного изображения по копии низкого разрешения. Это синтез правдоподобной фотографии, которая вероятно могла быть исходным изображением. Это вероятностный процесс.
Когда стоит задача «повысить разрешение» фотографии, но на ней нет деталей для улучшения, то задачей модели является генерация наиболее правдоподобного изображения с точки зрения человека. В свою очередь, сгенерировать реалистичное изображение невозможно, пока модель не создала контуры и не приняла «волевое» решение о том, какие текстуры, формы и паттерны будут присутствовать в разных частях изображения.
Для примера достаточно посмотреть на КДПВ, где в левой колонке реальные тестовые изображения для нейросети. На них отсутствуют детали кожи и волос. Их никоим образом невозможно восстановить традиционными способами интерполяции вроде линейной или бикубической. Однако если предварительной обладать глубокими знаниями о всём разнообразии лиц и их типичных очертаниях (и зная, что здесь нужно увеличить разрешение именно лица), то нейросеть способна совершить фантастическую вещь — и «нарисовать» недостающие детали, которые с наибольшей вероятностью будут там.
Специалисты подразделения Google Brain опубликовали научную работу «Рекурсивное пиксельное суперразрешение», в которой описывают полностью вероятностную модель, обученную на наборе фотографий высокого разрешения и их уменьшенных копиях 8?8 для генерации изображений размером 32?32 из маленьких образцов 8?8.
Модель состоит из двух компонентов, которые обучаются одновременно: кондиционная нейросеть (conditioning network) и приор (prior network). Первая из них эффективно накладывает изображение низкого разрешения на распределение соответствующих изображений высокого разрешения, а вторая моделирует детали высокого разрешения, чтобы сделать финальную версию более реалистичной. Кондиционная нейросеть состоит из блоков ResNet, а приор представляет собой архитектуру PixelCNN.
Схематично модель изображена на иллюстрации.
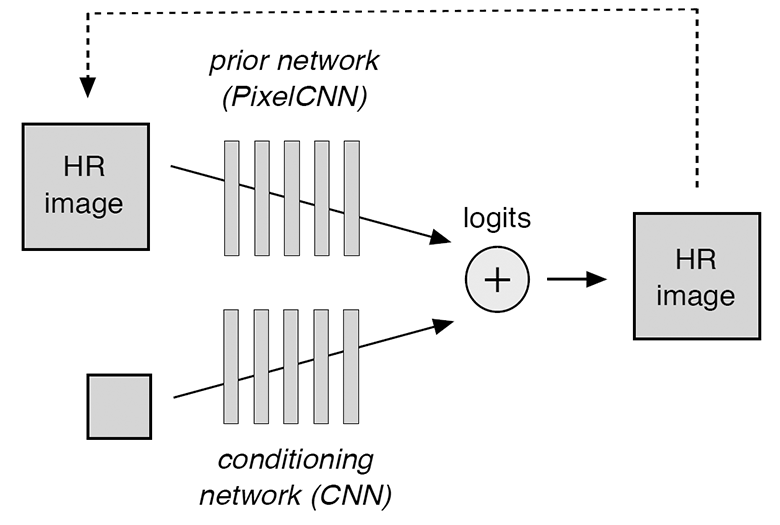
Кондиционная свёрточная нейросеть получает на входе изображения низкого разрешения и выдаёт логиты — значения, которые предсказывают кондиционную логит-вероятность для каждого пикселя изображения с высоким разрешением. В свою очередь, свёрточная нейросеть приор делает предсказания, основанные на предыдущих случайных предсказаниях (обозначены пунктирной линией на схеме). Вероятностное распределение для всей модели вычисляется как softmax-оператор поверх суммы двух наборов логитов с кондиционной нейросети и приора.
Но как оценить качество работы такой сети? Авторы научной работы пришли к выводу, что стандартные метрики типа пикового отношения сигнал/шум (pSNR) и структурного сходства (SSIM) не способны корректно оценить качество предсказания для таких задач сверхсильного увеличения разрешения. По этим метрикам выходит, что лучший результат — это размытые картинки, а не фотореалистичные изображения, на которых чёткие и правдоподобные детали не совпадают по месту размещения с чёткими деталями настоящего изображения. То есть эти метрики pSNR и SSIM крайне консервативны. Исследования показали, что люди легко отзличают реальные фотографии от размытых вариантов, созданных регрессионными методами, а вот отличить сгенерированные нейросетью образцы от реальных фотографий им не так просто.
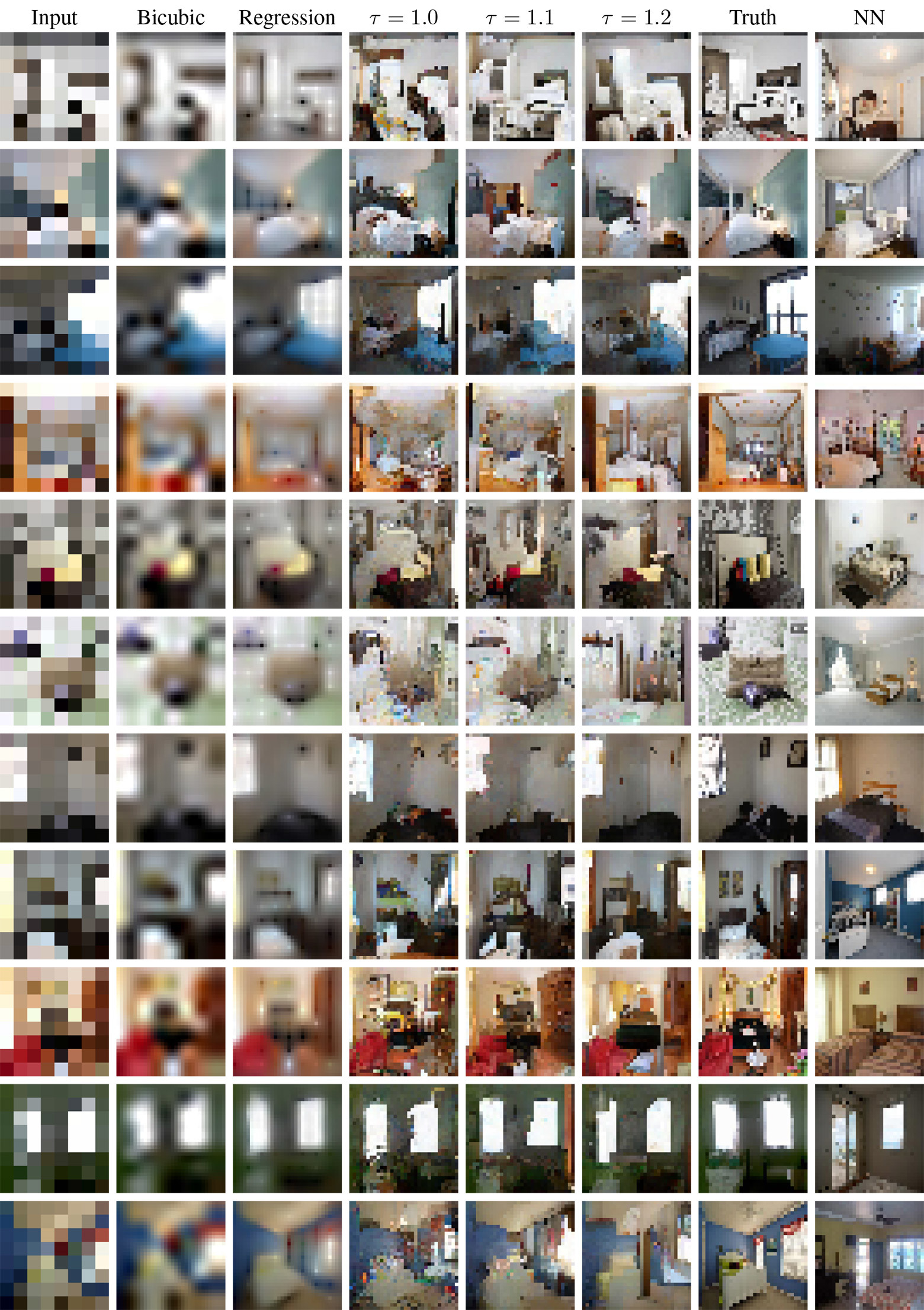
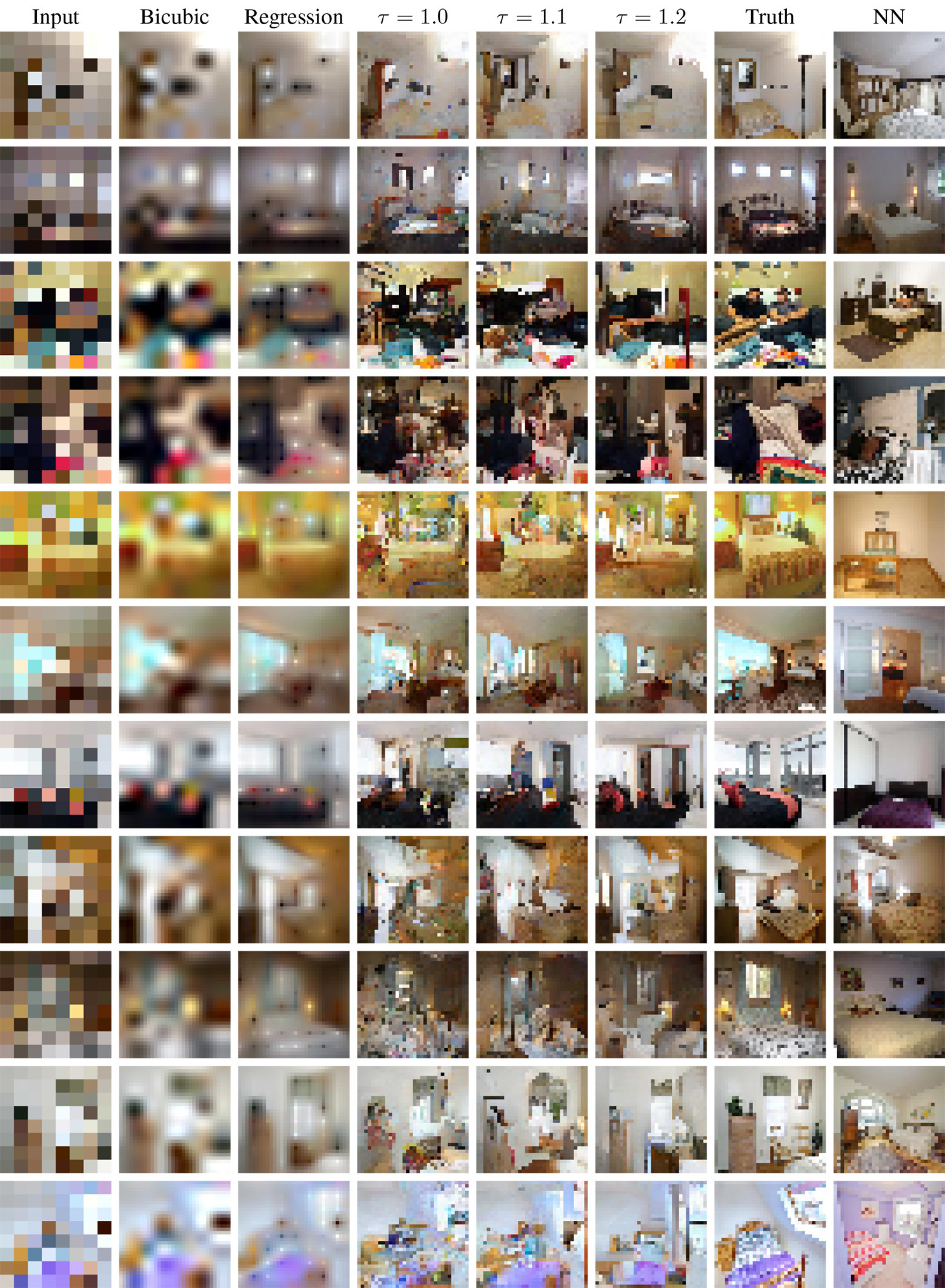
Посмотрим, какие результаты показывает модель, разработанная в Google Brain и обученная на наборе 200 000 лиц знаменитостей (набор фотографий CelebA) и 2 000 000 спальных комнат (набор фотографий LSUN Bedrooms). Во всех случаях фотографии перед обучением системы были уменьшены до размера 32?32 пикселя, а потом ещё раз до 8?8 методом бикубической интерполяции. Нейросети на TensorFlow обучались на 8 графических процессорах.
Результаты сравнивались по двум основным базам: 1) независимая попиксельная регрессия (Regression) c архитектурой, похожей на нейросеть SRResNet, которая показывает выдающиеся результаты по стандартным метрикам оценки качества интерполяции; 2) поиск ближайшего соседнего элемента (NN), который ищет в базе учебных образцов пониженного разрешения наиболее схожее изображение по близости пикселей в евклидовом пространстве, а затем возвращает соответствующую картинку высокого разрешения, из которой был сгенерирован этот учебный образец.
Нужно заметить, что вероятностная модель выдаёт результаты разного качества, в зависимости от температуры softmax. Вручную было установлено, что оптимальные значения лежат между 1,1 и 1,3. Но даже если установить , то всё равно каждый раз результаты будут разными.

Различные результаты при запуске модели с температурой softmax
Оценить качестве работы вероятностной модели можете по образцам под спойлером.








Для проверки реалистичности результатов учёные провели опрос черед краудсорсинг. Участникам показывали две фотографии: одну настоящую, а вторую сгенерированную различными методами из уменьшенной копии 8?8 и просили указать — какая фотография сделана камерой.
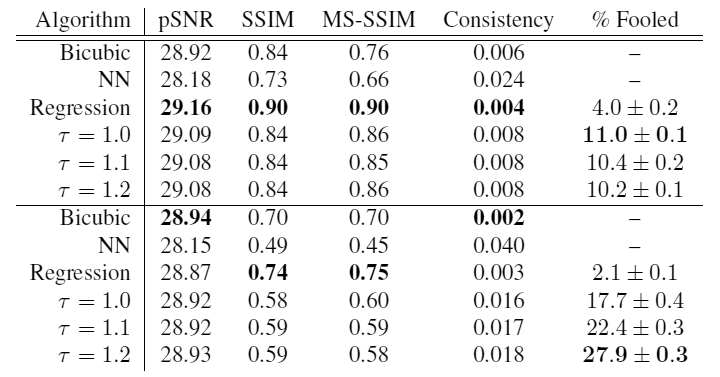
Сверху в таблице — результаты для базы лиц знаменитостей, снизу — для спальных комнат. Как видим, при температуре на фотографиях спальных комнат модель показала максимальный результат: в 27,9% случаях её выдача оказалась более реалистичной, чем настоящее изображение! Это явный успех.
На иллюстрации внизу — самые удачные работы нейросети, в которых она «побила» оригиналы по реалистичности. Для объективности — и некоторые из худших.

В области генерации фотореалистичных изображений с помощью нейросетей сейчас наблюдается очень бурное развитие. В 2017 году мы наверняка услышим много новостей на эту тему.
Комментарии (72)

xxvy
08.02.2017 04:27+7картинка_csi.jpg

gr1mm3r
08.02.2017 07:41-7Я помогу вам
Заголовок спойлераhttp://img0.joyreactor.cc/pics/post/fuuuu-auto-111812.jpegyousoufian
08.02.2017 04:31+1: Ждем когда придет кто-нибудь неленивый и подставит случайные фото в первое изображение.
yousoufian
08.02.2017 05:36+11Не дождался, наколхозил на скорую руку, как только опять добрался до компа.

xxvy
08.02.2017 05:51+6Т.е. теперь можно восстановить изображение профессора Де Кубика из Юного техника? :)

dairok
08.02.2017 12:59Да это ладно… можно будет смотреть фильмы 70-х годов в 8K+ разрешении. Правда, после такого upscaling, это будут уже совсем другие фильмы (причем, разные даже от каждого производителя TV)
GAZ69
08.02.2017 13:19+2Те фильмы на аналоговых носителях в большинстве своем четче чем первая цифра из 2000х, решающую роль там играло качество оптики… Поэтому ничего не мешает оцифровать их в 4к.
GAZ69
08.02.2017 06:32При таком подходе, например, при задаче определения автомобильного номера — в любой непонятной ситуации будут подставляться цифры и буквы с высокой частотой встречаемости. Владельцы номеров O111OO пострадают :)

betrachtung
08.02.2017 06:35И это всего лишь начало. Представьте себе перспективы.
«Восстановление» фотографии по кучке пикселей — ерунда. Вот когда начнут восстанавливать людей, в том числе вымышленных персонажей, это будет куда интересней. Да, их воспоминания окажутся аппроксимацией, не полностью соответствующей реальности, но это будут реальные живые люди, которые будут вести себя примерно так же, думать примерно так же, говорить примерно так же, как и давно умершие оригиналы.
Максимальный цифровой след оказывается нашим шансом получить бессмертие, даже если мы умрём задолго до своего воскрешения.
Bal
08.02.2017 08:20+1Насколько я предоставляю, наши воспоминания тоже работают по похожему принципу :) А ещё по тому же принципу из усиленного шума изолированных областей головного мозга формируются такие реалистичные сны :)

FiLunder7
08.02.2017 11:57+1Как обычно, перспективы колоссальные, а использоваться будет только для «де-цензуризации» японских фильмов для взрослых.

MAXInator
08.02.2017 08:00Может, я чего-то не понял, но — откуда такое различие в общем тоне губ в первом и третьем примере на КДПВ? Видно, что хоть картинка, подобранная нейросетью, похожа по положению пикселей, но цвет губ подобранной картинки отличается от цвета пикселей на 8*8 и от «оригинала».

Sadler
08.02.2017 09:47+1Эта сеть не восстанавливает изображение, она придумывает его на основе кучки пикселей. Я тоже делал аналогичную нейросетку несколько месяцев назад, и да, она неплохо придумывает детали по минимуму пикселей, но выход далеко не всегда сильно похож на оригинал.
MAXInator
08.02.2017 11:27Это понятно, мне интересно почему результат «придумывания» так сильно отличается по цвету.
Sadler
08.02.2017 11:51+1Потому что большинство лиц в обучающем наборе имеют подобные цвета, а сеть не очень успешно или совсем не разделила кластеры «розовые губы» и «красные губы»?
MAXInator
08.02.2017 12:14не разделила кластеры «розовые губы» и «красные губы»
Вооот. Как-то совсем сыро — «не заметить» такой очевидный не подходящий параметр.
AllexIn
08.02.2017 08:08+2Можно ли генерировать правдоподобные картины на основе 64 пикселей? Логика подсказывает, что это невозможно.
Логика подсказывает, что нельзя восстановить исходное. А нарисовать новое — да пожалуйста, в любом разрешении.

pudovMaxim
08.02.2017 08:15+3По сути это просто машина случайных картинок, генерирующая их по определенному правилу и заданному начальному зерну. Об "улучшении" говорить трудно, особенно учитывая, что с разными параметрами на одной картинке получаются совершенно разные лица. Единственное что угадывается — это овал лица и расположение дырок на лице. Законы природы тяжело обмануть — нельзя просто так разжать без потерь, сжатое с потерями :)
alex4321
08.02.2017 08:21+1«Можно ли генерировать правдоподобные картины на основе 64 пикселей?»
«Логика подсказывает, что это невозможно»
У вас какая-то поломанная логика. Вопрос про правдоподобные изображения, а она вам возвращает ответ о достоверных :-)

lexx_v11
08.02.2017 08:35+2Не хватает исходного изображения в хорошем качестве, чтобы понять, насколько точно нейросеть угадала.

DrZlodberg
08.02.2017 08:37А что за колонка NN в списке примеров? Картинки там сильно отличаются от остальных.

artemerschow
08.02.2017 09:50Полагаю, что на ней обучали сеть
DrZlodberg
08.02.2017 09:53Тогда немного странно. Некоторые примеры очень сильно отличаются по цвету.
artemerschow
08.02.2017 09:56А они должны совпадать?
DrZlodberg
08.02.2017 10:01В принципе нет. Однако почему в таблице именно она? Обучали же не по одной картинке. Как именно она связана с конкретным результатом? Даже если это наиболее похожая — всё равно местами странный выбор.
BabyKiller
08.02.2017 12:59+1Цитирую из текста:
«Поиск ближайшего соседнего элемента (NN), который ищет в базе учебных образцов пониженного разрешения наиболее схожее изображение по близости пикселей в евклидовом пространстве, а затем возвращает соответствующую картинку высокого разрешения, из которой был сгенерирован этот учебный образец»
dfgwer
08.02.2017 08:43Размывание изображения необратима теряет информацию, нейросеть при обратном процессе добавляет информацию, так чтобы она реалистично выглядело.

killik
08.02.2017 09:10+4Вспоминается та сеть, которую на собаках обучали, и она потом везде собак рисовала.

EndUser
08.02.2017 09:17+2Я так понимаю, что восстановление выброшенной информации происходит за счёт информации набранной в процессе обучения.
Но что я действительно не понимаю — так это то, зачем телевизионщики закрывают инкогнито пискельными масками. Они в движении дают достаточное количество информации для восстановления личности, я предполагаю.
DistortNeo
08.02.2017 17:00Да, пиксельные маски можно «взломать», так и работает многокадровое супер-разрешение.
А хорошо работать будет просто размазывание лица до неузнаваемости, когда движение не даёт дополнительной информации.
SanekPlus
08.02.2017 10:13Если приглядеться повнимательней, то получаемые изображения вообще не похожи на оригинал. По ним не возможно будет найти кого-то, а те изображения которые окажутся очень похожи в результате такого «восстановления» — скорей статистическая погрешность, чем результат.
artemerschow
08.02.2017 11:22Такое «сверхповышение» разрешения не является восстановлением исходного изображения по копии низкого разрешения. Это синтез правдоподобной фотографии, которая вероятно могла быть исходным изображением. Это вероятностный процесс.

danyaShep
08.02.2017 11:53Подскажите софт на андроид, который может склеивать несколько макроснимков в один большой документ. Хочу чтобы у телефона качество сканирования было как у планшетного сканера.
Пока весь софт, что я пробовал работает примитивно: делаем одну фотку, изменяем у ней пропорции и баланс белого — готово. Без слез на такой скан не посмотришь, печатать потом стыдно.ClearAirTurbulence
08.02.2017 12:46Есть Google PhotoScan для фотографий. Он интерполирует результат съемки с нескольких точек, ориентирован на фото — удаление бликов, в первую очередь.
Но результат — что на документах, что на фото — меня совершенно не вдохновил. Малое выходное разрешение, смазанность, особенно на неровностях (а где вы видели абсолютно плоские фото\документы?), отсутствие каких-либо внятных настроек… В общем, не то совсем.danyaShep
08.02.2017 13:51У меня с одной фотки разрешение получается выше, чем у гугла из пяти.
Как по мне, склеить такую панораму — довольно простая задача по сравнению со всякими нейросетями, которые сами дорисовывают, а никто не сделал почему-то.
Пробовал в фотошопе автовыравнивание слоев — не получилось ничего, да и неудобно.
В идеале нужен софт, который записывает видео. Поводил над листом телефоном, а потом из этого видео максимум полезной информации выжимается в один JPG.
mike_ps
08.02.2017 12:56По мне результаты регрессионного анализа в среднем больше похожи на оригинал. Нейросети много додумывают))
cb_ein
08.02.2017 12:56Если не ошибаюсь, человеческий мозг проделывает аналогичный фокус. Читал где-то, что «разрешение» человеческого глаза довольно посредственное и бОльшую часть деталей изображения того, что у нас в поле зрения, мозг достраивает сам.
DistortNeo
08.02.2017 16:57Есть даже короткое и ёмкое название для подобной техникик — hallucination.
Какая практическая польза от этого алгоритма, кроме как для синтеза реалистичных изображений?
Для видео алгоритм без серьёзных модификаций не подойдёт — будет высокая неустойчивость, на каждом кадре будет «галлюцинироваться» что-то своё. Для анализа изображений — и подавно: информации больше не стало.Sadler
08.02.2017 17:59Для видео алгоритм без серьёзных модификаций не подойдёт — будет высокая неустойчивость, на каждом кадре будет «галлюцинироваться» что-то своё.
Переносите веса из скрытых слоёв от обработки предыдущего кадра в веса текущего (конкатенация, не сложение), и будет Вам счастье.DistortNeo
08.02.2017 18:03Переносите веса из скрытых слоёв от обработки предыдущего кадра в веса текущего (конкатенация, не сложение), и будет Вам счастье.
И получим в итоге старческое слабоумие. Если человек пропадёт из видео на несколько секунд, нейросеть забудет про него, и при следующем появлении человек уже станет другим.Sadler
08.02.2017 19:16Для сжатия видео это приемлемо. Для организации долговременной памяти нужно значительно больше ресурсов.














rPman
У меня только один вопрос, присутствовали ли указанные лица (в данных примерах) в обучающей выборке?
Если да, то это не рисование а фактически поиск в базе по индексу в виде нейросети.
Потому как слишком уж выглядит неправдоподобно.
Xalium
Угу. А то по такому алгоритму «смогут восстанавливать» изображения из случайно сгенерированных картинок.
Был куча случайных кубиков, стала Памела Андерсон.
SADKO
Ну, или некое средне взвешенное лицо, плавали — знаем…
… меня удивляет другое, зачем плодить такие бестолковые работы, понты дороже денег, честное слово!
Эта байда не имеет отношения к реальному апскейлу, тк условия тут не менее синтетические чем результат, на входе не фрагмент реального изображения с шумами и артефактами, а чистинький даунскейл, и на выходе не полезные в хозяйстве линии и градиенты, а такая-же мелочь, по которой не возможно судить об адекватности реконструкции и тех диких «артефактах» которые порождаются таким подходом в больших масштабах.
… короче это игра на далёкую от темы публику, для которой не нужны не супер умы, не супер компьютеры
dipsy
улучшайзер качества фоток с ойфона как например, сможете фоткать с бодуна в темноте, а результат будет как на проф зеркалку, ещё через meitu-подобное что-то пропустить и всё, хит продаж, лучшая камера в сегменте.
pudovMaxim
ага и каждый раз фотки будут случайным образом меняться от Пугачевой до Джексона.
commensal
После предварительного анализа фотографий на телефоне владельца даже фото случайных людей будут похожи на владельца.
pudovMaxim
В моем случае, все фотки будут похожи на кота владельца)
lazywicked
вот — вот, зафотить все население и захешировать