
 Мы продолжаем посты с расшифровками выступлений на конференции HighLoad++, которая проходила в подмосковном Сколково 7—8 ноября 2016 года.
Мы продолжаем посты с расшифровками выступлений на конференции HighLoad++, которая проходила в подмосковном Сколково 7—8 ноября 2016 года.Здравствуйте, меня зовут Никита Духовный, и я работаю ведущим системным администратором в проекте «Одноклассники».
На данный момент инфраструктура «Одноклассников» располагается более чем на 11 тысячах физических серверов. Они расположены в 3-х основных дата-центрах в Москве. Также у нас есть точки присутствия CDN. По последним данным в час пик мы отдаем нашим пользователям свыше 1 терабита трафика в секунду.
В отделе системного администрирования мы разрабатываем и развиваем системы автоматизации. Мы занимаемся многими исследовательскими задачами. Мы помогаем разработчикам запускать новые проекты.
Сегодня мы поговорим о балансировке нагрузки и отказоустойчивости на примере нашей социальной сети.
На заре проекта перед «Одноклассниками» стояла задача сделать балансировку нагрузки между многими фронтендами. Проект проживал взрывоопасный рост, и поэтому решение было принято следующим. Пользователь заходил на
www.odnoklassniki.ru, в ответ получал редирект на конкретное имя сервера, например, wg13.odnoklassniki.ru. Это имя было намертво привязано к физическому серверу.Такой подход обладает очевидными недостатками. Во-первых, в случае проблем с сервером, пользователь получал ошибку в браузере. Во-вторых, если мы хотели вывести сервер из ротации, мы сталкивались с тем, что многие пользователи добавляли имя этого сервера в закладки. Что-то нужно было менять.
Тогда мы решили ввести в эксплуатацию балансировщики нагрузки. Нам было достаточно использовать Layer 4 балансировку. Что это значит? Это значит, что балансировщик осведомлен об IP-адресе и порте. То есть пользователь, приходя на виртуальный IP, порт 80, будет отправлен на порт 80 реального сервера, приходя на порт 443, будет отправлен на порт 443.
Мы рассматривали разные опции. На тот момент выбор был между проприетарными решениями — причём как программными, так и программно-аппаратными — и открытым проектом LVS (Linux Virtual Server). По результатам тестирования мы не нашли ни одной причины остановиться на проприетарных решениях.
Как мы организовали схему работы LVS
Пользовательский запрос попадает на сетевое оборудование, оно отправляет запрос на LVS. LVS, в свою очередь, отправляет запрос на один из фронтенд-серверов. Причем на LVS мы используем настройки персистентности, то есть следующий пользовательский запрос будет отправлен на тот же самый фронтенд-сервер.
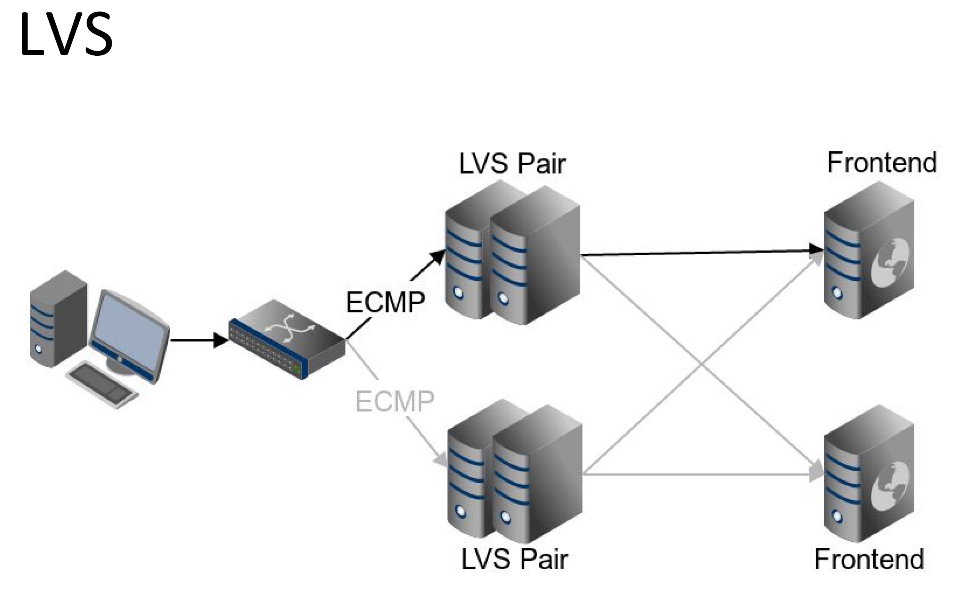
Мы хотели, чтобы наш кластер LVS был отказоустойчивым, поэтому мы организовали пары master/standby. Между парами master/standby постоянно происходит синхронизация сессий. Для чего это нужно? Чтобы при вылете master-сервера, пользователь, попадя на standby-сервер, был отправлен на тот же самый фронтенд.
Также между серверами запущен протокол VRRP средствами известного демона keepalive. Это нужно для того, чтобы IP-адрес самого сервера LVS переехал на standby. Таких пар master/standby у нас много. Между ними мы балансируем средствами протокола ECMP. Причем наше сетевое оборудование также осведомлено о настройках персистентности, и таким образом работает вся цепочка. Пользовательский запрос будет отправлен на одну и ту же пару LVS, пара LVS, в свою очередь, отправит на тот же самый фронтенд.
Нужно было каким-то образом управлять таблицей балансировки. На тот момент мы выбрали популярное решение ldirector. Демон ldirecor добавляет реальные сервера в таблицу балансировки на основании своего конфига. Он также осуществляет проверки реальных серверов. И в случае если какой-то из реальных серверов начинает возвращать ошибку, ldirector корректирует таблицу балансировки, и этот сервер выводится из ротации.
Всё выглядело хорошо, но количество серверов увеличивалось. На данный момент в каждом из наших дата-центров у нас есть двести фронтендов типа web — это те сервера, которые обрабатывают запросы
www.odnoklassniki.ru.Дело в том, что ldirector осуществляет свои проверки в однопоточном режиме. В случае неполадок, когда сервера начинают отвечать дольше, чем таймаут, происходит следующее: запрос приходит на первый сервер, ждёт время таймаута (например, 5 секунд), и только после этого проверка приступает ко второму серверу. Таким образом, при масштабной проблеме, например, когда затронута половина серверов, вывод этой половины занимает более 8 минут. Это было неприемлемо.
Чтобы решить эту проблему, мы написали собственное решение: ok-lvs-monitor. Оно обладает двумя главными достоинствами.
- Осуществляет проверки в многопоточном режиме. Это значит, что при описанной выше проблеме сервера будут выведены из ротации одновременно.
- Интегрируется с нашей системой конфигурации портала. Если раньше для изменения таблицы нам нужно было редактировать конфиги на серверах, то теперь достаточно отредактировать конфигурацию в той же самой системе, где мы управляем настройками наших приложений.
В ходе эксплуатации LVS мы столкнулись с рядом технических проблем.
- Мы наткнулись на то, что при синхронизации сессий имеется довольно большое расхождение между master и standby.
- Процесс синхронизации работал только на первом ядре процессора.
- На standby-сервере он потреблял свыше 50% этого ядра.
- Также были замечены разные мелочи. Например, утилита управления таблицей балансировки ipvsadm не различала Active/InActive сессии в случае с нашей конфигурацией.
Мы репортили баги разработчику проекта LVS, помогали в тестировании, и все эти проблемы были устранены.
Настройки персистентности
Ранее я упоминал, что у нас используются настройки персистентности. Для чего это нам?
Всё дело в том, что каждый фронтенд-сервер хранит в своей памяти информацию о пользовательской сессии. И если пользователь приходит на другой фронтенд, этот фронтенд должен выполнить процедуру логина пользователя. Для пользователя это происходит прозрачно, но тем не менее это довольно дорогая техническая операция.
LVS умеет делать персистентность на основании клиентского IP-адреса. И вот тут-то мы столкнулись со следующей проблемой. Популярность набирал мобильный интернет, и многие операторы, в первую очередь, крупнейший оператор Армении, прятали своих пользователей всего за несколькими IP-адресами. Это приводило к тому, что наши mobile-web сервера стали очень неравномерно нагружены, и многие из них были перегружены.
Мы решили обеспечивать персистентность по cookie-файлу, который ставим пользователю. Когда речь идёт о cookie-файле, к сожалению, невозможно ограничиться Layer 4 балансировкой, потому что речь идёт уже о Layer 7, об уровне приложения. Мы рассмотрели различные решения, и на тот момент самым лучшим был HAProxy. Популярный в наши дни nginx тогда не обладал должными механизмами балансировки.

Пользовательский запрос, попадая на сетевое оборудование, балансируется всё по тому же протоколу ECMP, до сих пор ничего не поменялось. А вот дальше начинается интересное: безо всякой персистентности, чистым Round-robin запрос отправляется на любой из HAProxy серверов. Каждый из этих серверов в своей конфигурации хранит соответствия значения cookie-файла к конкретному фронтенд-серверу. Если пользователь пришел первый раз, ему будет поставлен cookie-файл, если пользователь пришел второй и последующие разы, он будет отправлен на тот же самый мобильный фронтенд.
Подождите, скажете вы, то есть «Одноклассники» поставили кластер балансировщиков за кластером балансировщиков? Выглядит как-то сложновато.

На самом деле, давайте разберемся. Почему бы и нет?
В случае с нашей ситуацией процент трафика, проходящего через HAProxy, составляет менее 10% трафика, проходящего через весь LVS. То есть для нас это не какое-то дорогое решение. А вот преимущество у такого подхода налицо.
Представим, что мы проводим некую экспериментальную переконфигурацию сервера HAProxy. Мы хотим оценить эффект. И в таком случае мы заводим этот сервер HAProxy в ротацию с небольшим весом. Во-первых, мы можем собрать всю статистику перед принятием дальнейшего решения. Во-вторых, в худшем случае, лишь небольшой процент наших пользователей заметят какие-то неполадки. После успешного применения на малую часть мы можем продолжать уже со всем кластером.
?
Аварии в дата-центре
«Одноклассники» за свою историю неоднократно сталкивались с авариями. У нас была история, когда сгорели и основная, и резервная оптика к дата-центру. Дата-центр стал недоступен. У нас была история, когда из-за неправильной проектировки стала плавиться электрическая проводка в дата-центре, что привело к пожару. У нас была очень увлекательная история, когда ураган в Москве оторвал кусок крыши, а он вывел из строя систему охлаждения в дата-центре. Нам надо было принимать решение, какие сервера выключать, а какие оставлять, потому что начался перегрев.
По результатам этих аварий мы сформулировали для себя правило: «Одноклассники» должны работать в случае отказа любого из дата-центров.
Каким образом мы шли к этой цели?
- Мы подготовили наши системы хранения данных. Мы имплементировали функционал, который позволяет нашими системам данных понимать в каком дата-центре они находятся.
- Мы используем replication factor=3. Вкупе эти два пункта приводят к тому что в каждом из дата-центров появляется своя реплика данных.
- В наших системах мы используем quorum=2. Это значит, что при вылете одного из дата-центров система будет продолжать свою работу.
Нам нужно было распределить наши фронтенд-сервера по трём дата-центрам. Мы это сделали, причем с учетом запаса по мощности, чтобы фронтенды в дата-центре могли принять на себя все запросы, которые ранее приходились на тот дата-центр, который сейчас отказал.

Если вы сделаете DNS-запрос на
www.ok.ru, то вы увидите, что вам отдаётся 3 IP-адреса. Каждый из этих адресов как раз и соответствует одному дата-центру.Мы обрабатываем ситуацию с аварией в дата-центре автоматически. Здесь вы можете видеть пример такой проверки:

Видно, что в случае если 10 из 20 последних проверок были неуспешны, IP-адрес этого дата-центра перестанет отдаваться. 10 — это довольно много, вывод дата-центра — это тяжелая операция. Мы хотим быть уверенными, что правда началась авария. Здесь можно увидеть, что автоматически дата-центр будет заведен в ротацию в случае 20 из 20 успешных проверок. Да, вывод — это операция тяжелая, но мы хотим быть уверенным, что всё в порядке, перед тем как заводить пользователей.
По нашим подсчетам, при такой методике за 5 минут из дата-центра уйдет 80 % аудитории. Есть предположения, откуда взялась цифра 5 минут?
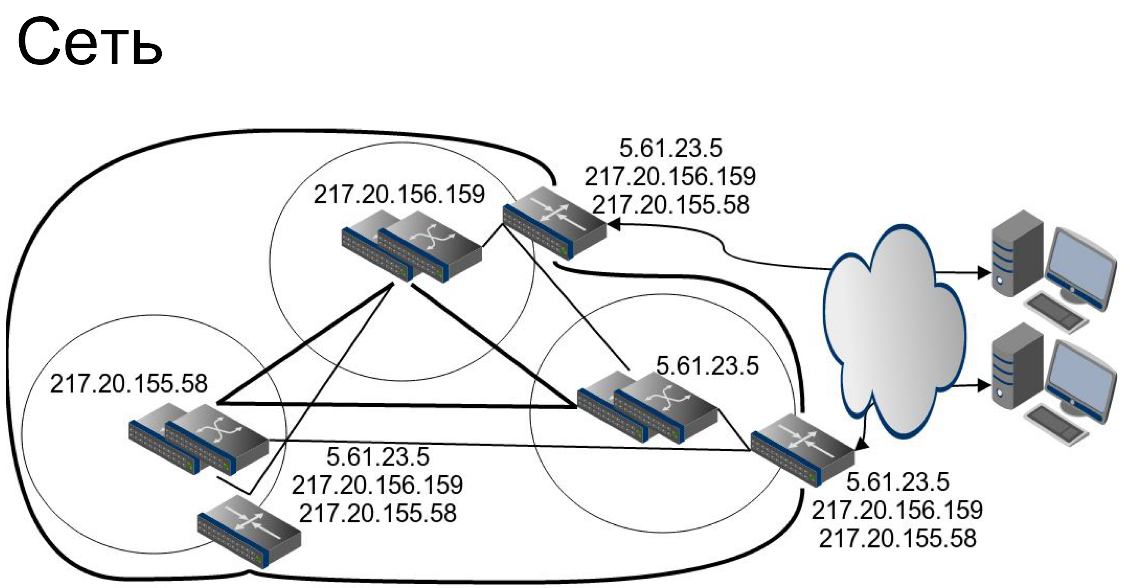
Сеть. На уровне сети мы используем довольно любопытный трюк. На самом деле пограничные раутеры каждого из дата-центров анонсируют все сети в мир.
Представим, что пользователь идёт на IP-адрес
217.20.156.159. Пользователь попадет в один из дата-центров. Другой пользователь, обращаясь к тому же самому IP-адресу, может на самом деле попасть в соседний дата-центр. Для чего это нужно? В случае отказа одного из пограничных раутеров пользователи не заметят никакого эффекта.Здесь есть тонкий момент. Я вам только что рассказывал про то, что у нас в каждом дата-центре будет свой IP-адрес для сервиса и вроде бы даю вам противоречащую информацию. На самом деле нет. На уровне ядра сети в каждом дата-центре всё-таки свой набор сетей, и просто пограничные раутеры, используя либо прямое соединение, либо своё кольцо, имеют возможность отправить запрос в нужный дата-центр.
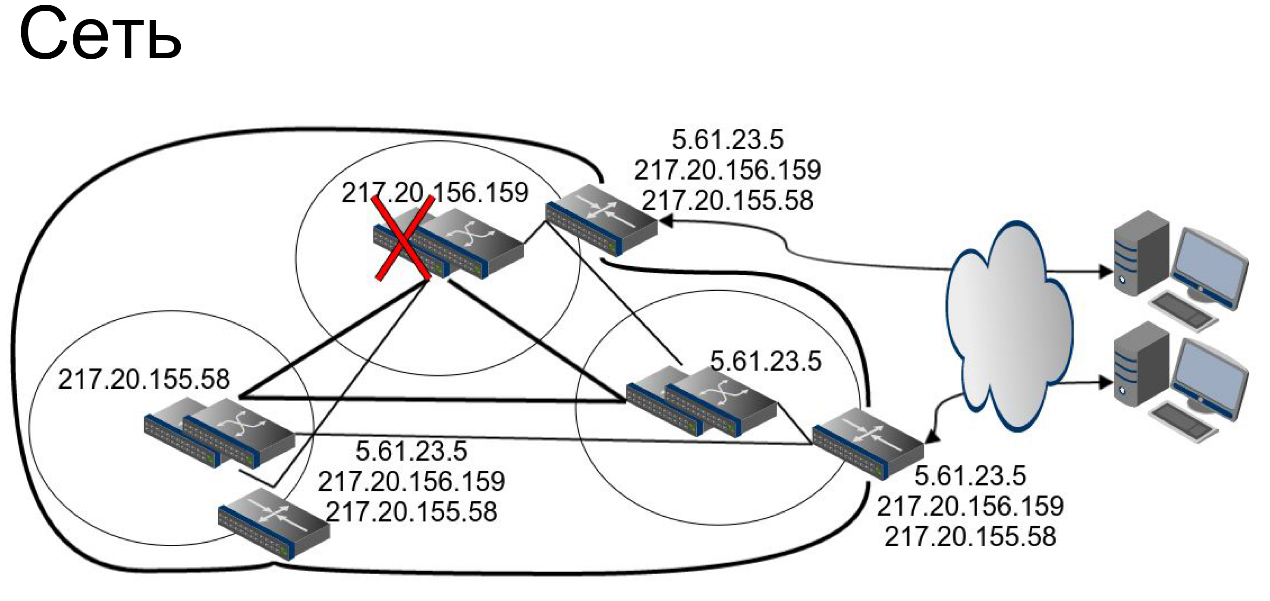
По поводу ядра сети. Всё сетевое оборудование у нас зарезервировано с таким запасом мощности, чтобы быть способным принять на себя нагрузку вылетевшего соседа. Только авария со всем ядром сети правда приведет к ситуации, когда нам придется выводить трафик из дата-центров.
Тяжелый контент
Под тяжелым контентом я подразумеваю музыку, видео и фотографии.
Дело в том, что значительная часть аудитории «Одноклассников» не может похвастаться таким же качеством Интернет-соединения, как жители столицы. Во-первых, большая часть нашей аудитории проживает за пределами Российской Федерации. Во многих странах скорость зарубежного интернета и внутреннего очень сильно различается. Во-вторых, пользователи в удаленных регионах в принципе зачастую не могут похвастаться стабильным каналом. Даже если он стабилен, это вовсе не значит, что он не медленный.
Мы хотели сделать так, чтобы пользователям было комфортно работать с «Одноклассниками». Поэтому мы задумались о собственном решении CDN.
Идея CDN довольно проста. Вы берёте кэширующие сервера и ставите их близко к пользователю. При построении CDN обычно используется один из двух классических подходов.
IP Anycast. Его суть заключается в том, что каждая из ваших площадок анонсирует в мир одну и ту же сеть, одни и те же адреса. И то, на какую площадку попадет ваш пользователь, определяет текущая топология Интернета. Плюсы такого подхода очевидны: вам не нужно имплементировать никакую логику для того, чтобы пользователь попал на оптимальную площадку.

Минусы также хорошо видны. Представим, что у вас есть CDN в Воронеже, вы хотите провести с ним серьезные сервисные работы. Для этого вам нужно отправить всех пользователей на какую-то конкретную площадку, например, в Санкт-Петербург. Используя IP Anycast в чистом виде, у вас нет прямых механизмов, как вы можете это сделать. Кроме того, вы должны будете готовить ваше приложение к такому повороту событий, как неожиданный переход пользователя. В топологии Интернета что-то изменилось, и пользователь следующий запрос отправляет на другую площадку.
Другая классическая технология основана на использовании геолокации и DNS. В чем суть?

Москвич, делая запрос за статическим контентом, за именем сервиса, который отдает статический контент к DNS, получит в ответ московский IP-адрес и будет отправлен на площадку в Москве. Житель Новосибирска, делая аналогичный запрос, получит IP-адрес площадки в Новосибирске и будет отправлен туда.
Плюсы такого подхода заключаются в высокой степени контроля. Вышеописанная задача отправить жителя Воронежа на площадку по вашему выбору становится довольно простой. Вам просто нужно отредактировать вашу базу. Но и минусы у такого подхода тоже есть. Во-первых, обычно при таком подходе используется база геолокаций вроде GeoIP, а географическая близость вовсе не значит самое быстрое соединение до этой площадки. Во-вторых, такой подход не учитывает изменение топологии в Интернете.
У «Одноклассников» была еще одна задача: мы хотели запускать проекты вида «трафик до «Одноклассников» бесплатно». То есть, выбирая, к примеру, мобильное подключение нашего партнера, всё то, что вы делаете через мобильное приложение Одноклассников, не учитывается как расход трафика. Чтобы осуществить такую задачу, наш CDN должен был обладать функционалом, позволяющим отправлять только те сети на площадку, которые хочет видеть там наш партнер.
Классические решения для такой задачи не подходят. Что мы сделали?

На площадке CDN наш сервер по BGP устанавливает соединение с Route Server провайдера, получая от него список тех сетей, которые провайдер хочет на нём видеть. Далее список префиксов передается на наш GSLB DNS, и тогда уже пользователь, обращаясь DNS-запросом, получает IP-адрес как раз в той площадке, что нужно. Площадка, в свою очередь разумеется весь контент забирает из основных дата-центров.

Внутри площадки между серверами мы балансируем, используя довольно тривиальный подход. У каждого из серверов есть свой IP-адрес, и по DNS-запросу отдаются оба IP-адреса. Таким образом, пользователи будут распределены между серверами приблизительно поровну. В случае отказа одного из серверов средствами всё того же протокола VRRP IP-адрес будет прозрачно переведен на другую ноду. Пользователи ничего не заметят.

Разумеется, мы осуществляем проверки всех наших площадок. В случае, если площадка перестает возвращать статус ОК, мы перестаем отдавать её IP-адрес. В таком случае пользователь из Новосибирска пойдет в дата-центры в Москве. Это будет немного медленнее, но это будет работать.
На наших CDN-площадках мы используем внутренне разработанные приложения для видео, музыки и фото, а также в дополнении к этому nginx. Хотел бы упомянуть основной момент оптимизации, который применятся в наших приложениях. Представим, что у вас есть несколько серверов, которые отдают тяжелый контент. Пользователь приходит на один сервер и спрашивает у него этот контент. Контента там не находится. Тогда сервер забирает этот контент с площадки в Москве. Но что будет, когда следующий пользователь придет за тем же самым контентом на второй сервер? Мы не хотели бы, чтобы сервер шел опять за тем же самым контентом в Москву. Поэтому в первую очередь он сходит на свой соседний сервер и заберет контент с него.
Будущее
Хотел бы рассказать о нескольких проектах, которыми нам было бы очень интересно заняться и которые нам было бы очень интересно реализовать.
Мы хотели бы видеть, чтобы каждый из наших сервисов, например,
www.odnoklassniki.ru, всё-таки жил за одним IP-адресом. Для чего?- В случае отказа дата-центра в таком случае для пользователей всё происходило бы прозрачно.
- Vы избавились бы от проблемы с некорректно себя ведущими кэширующими DNS, которые продолжают отдавать IP-адрес выведенной площадки, несмотря на то, что мы его уже не отдаем.
- Раз в TTL времени (то есть в нашем случае раз в 5 минут) пользователь всё-таки может перейти на другую площадку.
Это не очень сложная технически операция, но тем не менее от нее хотелось бы избавиться. Это очень амбициозный проект, в его рамках нужно решать много задач. Как обеспечивать настройки персистентности? Как незаметно проводить сервисные работы? Как выводить дата-центр? В конце концов, как подготовить наше приложение к такому повороту событий? Все эти вопросы предстоит решить.
Другая интересная тема. Это балансировщики Layer 4, которые работают в user space. В чём заключается их суть?
На самом деле, когда балансировщик использует сетевой стэк Linux, он постоянно переключается между user space и kernel space. Это довольно дорогая операция для CPU. Кроме того, network stack Linux — это универсальное решение. Как любое универсальное решение, оно не идеально подходит для данной конкретной задачи. Балансировщики user space Layer 4 самостоятельно реализуют тот необходимый функционал network stack, который им нужен. За счет этого, по слухам, всё работает очень быстро.
Раскрою вам небольшой секрет: на самом деле сейчас один из партнеров проводит для нас исследование и кое-какие доработки, и мы могли убедиться самостоятельно в огромной разнице в скорости.
Это только два проекта из возможного будущего, которые я сейчас назвал. На самом деле их намного больше. И разумеется большая их часть связана с другими темами, не только с балансировской нагрузки и отказоустойчивости.

Посмотрим куда нас эта дорога заведет. Мы всегда рады новым сильным коллегам, пожалуйста, заходите на наш технический сайт, на нем вы найдете много интересных публикаций и видеозаписей выступлений моих коллег.
Спасибо за внимание!
Последние девять минут выступления Никита Духовный отвечал на вопросы из зала.
Комментарии (20)

Karroplan
08.02.2017 22:52-7раутер? обоссы меня господь!

xcore78
09.02.2017 17:39Да, "раут". Как «маус» или «хаус».
Karroplan
09.02.2017 23:12-1вынужден огорчить, но:
router in collins dictionaryxcore78
09.02.2017 23:56Что вы, совсем не огорчили.
А ещё так говорит Jeremy Cioara :)
Правда в том, что оба варианта легитимны, и [u:], и [au].
AccessGranted
09.02.2017 01:37-5Балансировщик на балансировщике и балансировщиком погоняет, а по итогу сервис падает от сгоревшего кабеля и сорванной крыши в дата-центре.
Haproxy вроде неплохо работает в связке с keepalived. Так и непонятно зачем еще перед ними городить LVS балансировщик.
Все дата центры в Москве, не знаю может это решение продиктовано бизнесом, но отсутствует географическое распределение дата-центров, что особенно плохо в случае социальных сетей.
Двадцать небольших дата-центров лучше чем три больших. Нет проблем с резким ростом нагрузки в случае проблем в одном из них.

dmitrysamsonov
09.02.2017 12:49+4Haproxy даст вам отказоустойчивость серверов приложений, keepalived позволит пережить отказ одного из двух haproxy. Но этого решения уже не достаточно, если вам надо больше 1 haproxy — для этого и нужен LVS. И этого решения тем более не достаточно, если вам надо больше 1 датацентра — для этого нужен GSLB.
Географическое распределение датацентров — это не единственное решение, позволяющее доставлять контент быстро до удалённых уголков. Более адекватное решение — это CDN, его мы и используем.
Что касается приведённых вами аварий, то могу только процитировать доклад:
«По результатам этих аварий мы сформулировали для себя правило: «Одноклассники» должны работать в случае отказа любого из дата-центров.»
О том как мы этого добились и рассказывается в этом докладе.

m0nstermind
09.02.2017 12:58+5Балансировщик на балансировщике и балансировщиком погоняет, а по итогу сервис падает от сгоревшего кабеля и сорванной крыши в дата-центре.
Если внимательно прочитать текст, то становится ясно, что данные аварии приведены как пример того, почему Ок поставили себе цель выживать при потере ДЦ. Это давние случаи. По результатам же реализации этой цели сервис не падает при отказе ДЦ. Например, последний отказ был на прошлой неделе, например — расплавился автомат, возник пожар. Сервис работал штатно — пользователи ничего не заметили.
По ДЦ — в Москве они все потому что их так проще обслуживать, географическая близость их улучшает времена ответа при коммуникации — что важно при больших нагрузках. Для ускорения доступа клиентов по географии имеется CDN.
Иметь 20 ДЦ для обеспечения надежности не имеет смысла, дорого, медленно. 3 нам вполне хватает.AccessGranted
09.02.2017 21:06-4Иметь 20 ДЦ для обеспечения надежности не имеет смысла, дорого, медленно. 3 нам вполне хватает.
Да, только держать треть серверного парка в режиме hot standby совсем «недорого». Вы бы у бизнеса спросили что им важнее «5%» пользователей ok.ru которые уйдут на временный перекур или дополнительные расходы на содержание почти 4 тысяч серверов. Судя по всему они не в курсе дел.

5had0ff
09.02.2017 14:35Ваш сайт жутко тяжелый для старых машин и изобилует flash и gif. Может стОит оптимизировать код под слабые компьютеры? Сделать легкую версию, так сказать.
A1estro
09.02.2017 14:355 минут — TTL конечно.
А почему бы не использовать отдельные сервера для хранения сессий?

berkut3128
11.02.2017 03:13Спасибо за грамотную статью. Мне не совсем понятно с построением сети до LVS. Вот есть три дата центра, берем к примеру первый 5.61.23.5. Например, я пользователь хочу открыть страничку www.ok.ru мне ваш dns в round-robin режиме отдает первый ip 5.61.23.5 я обращаюсь к нему на порт 80, этот запрос доходит до дата центра(до пограничного роутера), и тут мне не совсем понятно, как происходит балансировка. Мое представление: На пограничном роутере поднят BGP у него маршруты 5.61.23.0/24 via что-то, таких одинаковых маршрутов много, чтобы работал механизм ECMP. И вот не понятно, как этот запрос доходит дальше до LVS балансировщика? У LVS балансировщика ip 5.61.23.5? Но если их два, то как этот запрос попадает на второй?
dmitrysamsonov
13.02.2017 13:55у него маршруты 5.61.23.0/24 via что-то
Via все 16 LVS балансировщиков этого датацентра. Т.е. именно ECMP и обеспечивает маршрутизацию пакетов на все LVS.berkut3128
13.02.2017 21:21То есть правильно ли я понимаю маршруты например:
5.61.23.0/24 via 5.61.23.8(LVS1 балансировщик)
5.61.23.0/24 via 5.61.23.7(LVS2 балансировщик)
5.61.23.0/24 via 5.61.23.5(LVS3 балансировщик)
… итд.
И в данном случае, грубо говоря ECMP размазывает все запросы в round-robin режиме по всем LVS1-16
Так вот мне не совсем понятно, пользователю DNS отдал ip 5.61.23.5 это запрос доходит до пограничного маршрутизатора, он по ECMP решает смаршрутизировать этот запрос на 5.61.23.7 этот запрос доходит до LVS(5.61.23.7) и LVS должен его отбросить потому, что запрос предназначен не ему и потому, что клиент запрашивал ip 5.61.23.5
Или я где-то запутался?
berkut3128
14.02.2017 20:52Я кажется понял, вы на каждом LVS на loopback интерфейс добавляете алиас 5.61.23.5 тогда и ядро не будет дропать пакеты и они дальше будут подыматься по стеку.
eurypterid
> Между ними мы балансируем средствами протокола ECMP
Что имелось в виду? Equal-cost multi-path все-таки не протокол, а стратегия маршрутизации.