
 Пришло время рассказать о том, как в нашей компании следят за соблюдением SLA (Service Level Agreement — в широком понимании, это соглашение на предоставление технической поддержки, включающее время реагирования на запрос) в обращениях клиентов за технической поддержкой, какие инструменты созданы для его соблюдения и какое место этот параметр занял в нашей системе приоритезации обращений описанной в моей предыдущей статье «Ваш звонок очень важен для нас? Или как работает система приоритизации заявок в сервисных подразделениях».
Пришло время рассказать о том, как в нашей компании следят за соблюдением SLA (Service Level Agreement — в широком понимании, это соглашение на предоставление технической поддержки, включающее время реагирования на запрос) в обращениях клиентов за технической поддержкой, какие инструменты созданы для его соблюдения и какое место этот параметр занял в нашей системе приоритезации обращений описанной в моей предыдущей статье «Ваш звонок очень важен для нас? Или как работает система приоритизации заявок в сервисных подразделениях». Кому-то материал покажется тривиальным, особенно профессионалам из крупных колл-центров, но для специалистов небольших и средних организаций, где процессы предоставления сервиса только начинают «созревать», материал будет полезен.
Может показаться, что расчет показателя бэклога (англ. Backlog — накопившаяся отложенная работа), который и предназначен для отслеживания времени реакции на обращение, достаточно тривиальная вещь, не требующая больших усилий. В самом деле, ну что там считать? От времени реакции в данный момент отнимем время создания/переоткрытия обращения, выразим результат в часах или минутах и отобразим в каждой открытой заявке — бэклог готов. Чем значение больше, тем дольше заказчик ждет ответа, следовательно, выше приоритет его обращения. Но такое положение вещей сохраняется до тех пор, пока у организации не появляется несколько групп заказчиков на поддержке с отличающимися SLA, обрабатываемыми одной и той же командой специалистов. В этой ситуации считать один бэклог на всех, выражать его в часах или минутах, руководствоваться этим показателем для определения приоритета в работе с обращениями будет уже неправильно. Ведь одной группе заказчиков мы обязуемся отвечать в течение часа, другой – в течение двух часов, третьей в течение восьми часов, а четвертая группа вообще готова ждать сутки.
Напрашивается вариант разграничения запросов от различных групп заказчиков в разные очереди и назначение каждой из них по отдельному специалисту/команде. Да, пожалуй, это идеальный вариант, но зачастую он не достижим, особенно в небольших организациях или в условиях ограниченных ресурсов, где один человек/команда занимается сразу всеми группами заказчиков. Прыгать по очередям обращений и пытаться понять в какой из них бэклог конкретного обращения весомее других — удовольствие сомнительное. О том, как перестать беспокоиться о бэклоге и начать жить, мы и поговорим далее.
Итак, дано:
• Одна команда технической поддержки и клиентского сервиса, осуществляющая поддержку всех категорий заказчиков и всех категорий обращений.
• Пять групп заказчиков с разными SLA.
• CRM система SalesForce.
Необходимо:
Создать учитывающую время реакции единую систему расчета и отображения бэклога обращений в техническую поддержку, прописанном в SLA, закрепленного за организацией-заказчиком или типом обращения. Как уже было отмечено выше, вычисление бэклога «в лоб» в данной ситуации уже неприменимо. Поэтому было принято решение использовать для его отображения не абсолютные значения времени, а относительную величину, назовем её условно Bucket (корзина).
Для каждой из групп заказчиков один такой Bucket равен установленному в SLA промежутку времени ответа, то есть 1, 2, 8, 12, 24 часа выраженному в минутах. Чтобы автоматизировать правильный расчет бэклога для каждой группы заказчиков в CRM-системе было создано специальное правило, которое в зависимости от типа соглашения на техническую поддержку организации присваивало заявкам от сотрудников этой организации определенное значение Bucket.

Здесь, однако, следует отметить, что, несмотря на наличие у компании «Х» договора на сервисное обслуживание продукта с четким обозначением времени ответа по заявкам на техническое обслуживание, не всем типам обращений от сотрудников этой компании присваивается одинаковое значение Bucket. Для заявок, не связанных с техническим обслуживанием, существует отдельный SLA и таким заявкам присваивается специальный Bucket, на основании другого правила, которое срабатывает при классификации обращения как «нетехнический запрос».
Речь здесь идет о различных пожеланиях к реализациям новых функций и прочих запросах, не связанных с техническими сложностями использования продуктов. Как вы понимаете, это сделано для того, чтобы в первоочередном порядке команда технической поддержки обслуживала заявки с реальными техническими проблемами, мешающими нашим клиентам работать с продуктом.
Таким образом, финальная формула расчета бэклога выглядит следующим образом:
(X-Y)/Z
где:
X — время в текущий момент,
Y — время создания/переоткрытия заявки,
Z — Bucket присвоенный заявке на основании ее классификации или SLA организации.
Полученное значение представлено в виде числа, округленного до тысячных. Это и есть тот относительный показатель бэклога, который позволяет нам определить выполнение SLA в каждой конкретной заявке, не заглядывая в договор на сервисное обслуживание каждой организации:
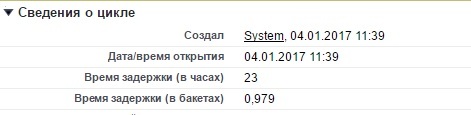
Следовательно, любое обращение, в котором значение бэклога меньше единицы обрабатывается в штатном режиме, так как SLA в этом случае не нарушен. Но стоит этому значению превысить единицу, заявка автоматически начинает повышаться в приоритете. Чем выше значение бэклога, тем выше приоритет заявки.
Как вы догадались, мы включили параметр бэклога в нашу общую систему приоритезации описанную в статье моего коллеги – «Простая математика для решения непростых задач», и нашим инженерам и менеджерам технической поддержки нет необходимости вручную отслеживать этот параметр. Он автоматически влияет на общий показатель приоритета заявки согласно установленному весу в общей системе приоритезации. На этом у меня все, буду рад пообщаться в комментариях и ответить на вопросы.
Поделиться с друзьями