

Привет! Меня зовут Паша Матлашов. Я Director of Game Server Development Department в игровой компании Plarium.
Сегодня на примере наших проектов я расскажу об особенностях кэширования, подводных камнях и о том, как их обойти.
Предпосылки
Наши сервера обрабатывают 8500 запросов в секунду и хранят информацию о 200 миллионах пользователей. Чтобы обеспечить эффективное линейное масштабирование, мы применяем сегментирование пользователей (оно же шардирование). Процесс распределения новых пользователей происходит по простому правилу балансировки: новый пользователь попадает на наименее «заселенный» сегмент. Такое сегментирование – статическое, что обеспечивает простоту в разработке. Дополнительно для упрощения архитектуры есть правило: данные пользователя могут редактироваться только на том сегменте, на котором они хранятся. Это позволяет не задумываться о таких проблемах, как распределенные блокировки и транзакции. В рамках сервера пользователь называется игровой сущностью.
Блокировка данных
Для регулирования потоков и корректного редактирования данных можно идти по принципу оптимистической или пессимистической блокировки.
Использование оптимистической блокировки не гарантирует, что до конца транзакции параллельные сущности / потоки / запросы не изменят данные. Для минимизации количества чтений данных перед редактированием мы запоминаем версию игровой сущности. Когда измененные данные сохраняются в базу, мы дополнительно сохраняем значение старой версии.
В таком подходе есть минус: могут возникнуть ситуации, когда игровую сущность придется вычитывать повторно из-за большого количества взаимодействия.
Представим, что пользователь покупает здание, и одновременно срабатывает битва. Оба эти события меняют игровую сущность. Может случиться так, что результат битвы будет высчитан в момент применения логики покупки здания. Данные сохраняются в базу, меняется ревизия пользователя. Нам нужно выбросить огромный массив данных. Дополнительно нужно учитывать, что сохранение игровой сущности в базу включает в себя этап сериализации и сжатия данных. В итоге данные отправляются в базу, но ревизия не совпадает. Нужно заново достать сущность из базы, воспроизвести логику транзакции, сериализовать, сжать данные, снова попробовать зафиксировать версию данных в надежде на то, что ничего не изменится. Такой подход усложняет код и расходует лишние ресурсы.
Мы пошли по принципу пессимистической блокировки. Перед любым действием происходит блокировка данных – это гарантирует единоличный процесс редактирования.
Выбор места блокировки данных
Постоянно ходить в базу, где хранятся данные, долго и ресурсно дорого. Блокировку легковеснее осуществлять в памяти рабочего процесса, чем в базе. Но нужно соблюдать определенные гарантии:
- Все методы идут за данными пользователя только на сервер.
- Разработчики следят за тем, чтобы данные редактировались только на том сегменте, где хранится пользователь.
- В памяти должна быть только одна копия пользователя.
В результате мы приходим к кэшу пользователей, который повышает эффективность работы с данными. Кэш отслеживает единственность копии каждой сущности и предоставляет место блокировки. В таком сценарии кэш работает по принципу сквозной записи (write-through).
Работу кэша с игровыми сущностями можно описать этапами:
- Вычитывание пользователя из базы данных в кэш.
- Получение монопольного доступа к данным путем блокирования.
- Редактирование пользователя в кэш.
- Сохранение пользователя в базу данных. Актуальные данные пользователя остаются в кэш.
«А что, если размещать кэш в другом процессе, например, в Memcached?» – скажете вы :) В такой ситуации нужно учитывать, что появятся дополнительные затраты на сериализацию и десериализацию при взаимодействии с внешним кэшем и на передачу по сети.
В случае использования многопоточности и большого количества процессов теоретически может возникнуть ситуация, в которой копия пользователя будет параллельно существовать в двух процессах кэша. Этот феномен вызван интересной особенностью ASP.NET. Когда происходит изменение сборки в развернутом сайте, некоторое время существуют 2 экземпляра сайта: первый дорабатывает старый код и старые запросы, а второй создает для новых запросов новый процесс с новой памятью. Технически игровая сущность с нового сайта может загрузиться раньше, чем завершатся все процессы на старом. Каждая копия сайта верит, что данные игровые сущности есть только у нее, из-за чего происходит потеря данных.
Мы сталкивались с такой проблемой при перезагрузке и выливании новой версии сервера. Стандартно у 2–3 пользователей «терялись» войска. Чтобы решить этот вопрос, мы запретили одновременный запуск двух приложений на уровне кода.
Для избежания взаимоблокировки потоков мы придерживаемся ряда правил:
- Блокировку брать с указанием тайм-аута.
- Не брать больше одной блокировки одновременно.
- Изменение нескольких сущностей осуществлять через обмен сообщениями в очереди.
Первое решение
Первое, что приходит на ум для организации работы с кэш, – использовать Dictionary вида <Id,User>. Но у такого решения есть минус. Dictionary хорошо подходит для однопоточных приложений. В многопоточной среде он становится непотокобезопасным и требует дополнительной защиты.
Защиту Dictionary можно реализовать за счет одной монопольной блокировки, под которой проверяется наличие нужного пользователя в коллекции. Если пользователя нет, происходит загрузка игровой сущности и возвращение ее вызывающему коду. Для обеспечения последовательного доступа вызываемый код будет блокироваться на самом пользователе. Чтобы немного оптимизировать, можно использовать ReaderWriterLock (или любой другой вариант на эту же тему).
Но всё усложняется тем, что любой кэш рано или поздно достигает порогового размера и требует вытеснения данных. Что будет происходить в этом случае?
Смоделируем ситуацию в соответствии с указанным выше решением. Кэш содержит игровую сущность. Пришел запрос, взял игровую сущность в контекст блокировки и начал ее редактирование. Параллельно происходит вытеснение игровой сущности из кэша – например, поток вытеснения успел обозначить эти данные старыми по использованию. В это время приходит еще один запрос на игровую сущность, но в кэше ее уже нет. Запрос вычитывает данные из базы, кладет в кэш, забирает контекст и тоже начинает редактировать. В результате мы получим две копии игровой сущности, а это нарушает нашу же гарантию единственности (Рисунок 1). Данные теряются, и повезет тому запросу, который сохранит игровую сущность последним.
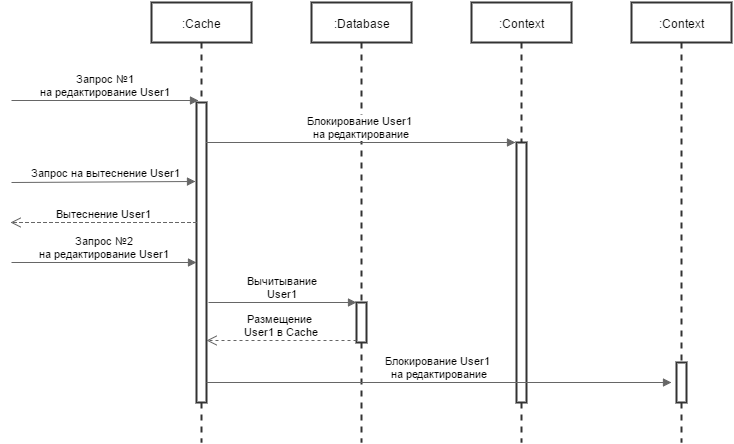
Рисунок 1
Очевидно, что нужно считаться с потоком, который уже редактирует игровую сущность. Можно блокировать все сущности, которые должны быть вытеснены, но это трудозатратно и неэффективно. Если, например, в кэше 20 000 игровых сущностей и 10 % из них нужно вытеснить, произойдет 2000 блокировок. Дополнительно, если часть блокировок занята, придется ждать их освобождения.
Операции Pin и UnPin
Мы решили реализовать операции Pin и UnPin. Вместо хранения сущности в качестве значения в Dictionary мы храним некий CacheItem, который указывает на блокировку игровой сущности, саму сущность и счетчик использований. С помощью счетчика происходит регулирование доступа во время вытеснения. При создании контекста значение счетчика увеличивается с помощью Interlocked-операции на CacheItem (операция Pin), при отпускании контекста – уменьшается (операция UnPin). Мы добавили операцию Shrink, которая вытесняет объекты с нулевым значением счетчика по дате последнего использования. Используется глобальная блокировка всего Dictionary без вхождения под индивидуальную блокировку каждой сущности. Pin выполняется в контексте этой же блокировки для сохранения атомарности получения и блокирования сущности.
// User Cache
private readonly object _lock = new object();
private Dictionary<long, UserCacheItem<TUser>> _dict = new Dictionary<long, UserCacheItem<TUser>>();
public bool TryGet(long userId, out UserCacheItem<TUser> userCacheItem, bool pinCacheItem)
{
lock(_lock)
{
if (!_dict.TryGetValue(userId, out userCacheItem))
return false;
userCacheItem.UpdateLastAccessTime();
if (pinCacheItem)
userCacheItem.PinInCache();
return true;
}
}
// Shrink
private void ShrinkOldest(int shrinkNumber) // shrinkNumber - quantity CacheItem superseded.
{
lock(_lock)
{
var orderedByAccess = _dict.OrderBy(pair =>
pair.Value.LastAccessTime).Where(pair => !pair.Value.IsPinnedInCache());
int i = 0;
foreach (var pair in orderedByAccess)
{
i++;
if (i > shrinkNumber)
break;
_dict.Remove(pair.Key);
}
}
}
// UserCacheItem
public class UserCacheItem<TUser>
where TUser : class, IUser, new()
{
private int _pinnedInCache; // _pinnedInCache prevents deletion of data from the Cache on Shrink
public object Locker = new object(); // userCacheItem blocked before user editing
public long UserId;
public TUser User;
public DateTime LastAccessTime;
public UserCacheItem(TUser user)
{
UserId = user.Id;
User = user;
UpdateLastAccessTime();
}
public void UpdateLastAccessTime()
{
LastAccessTime = DateTime.UtcNow;
}
public void PinInCache()
{
Interlocked.Increment(ref _pinnedInCache);
}
public void UnpinInCache()
{
Interlocked.Decrement(ref _pinnedInCache);
}
public bool IsPinnedInCache()
{
return _pinnedInCache != 0;
}
}
Вроде бы все красиво и весьма эффективно, но есть недостатки. Во-первых, глобальная блокировка всего Dictionary в плане защиты ресурсов очень большая – защищает слишком много данных. Это сравнимо с огромной библиотекой и одной старенькой бабушкой, которая по очереди выдает всем книги. Пока не завершится Shrink, никто не сможет взять контекст. Во-вторых, остается высокая конкуренция потоков на выполнение в устройстве самого Lock.
Классические инструменты синхронизации в Windows или Linux для захвата или освобождения блокировки требуют вхождения в режим ядра. Для блокировки в Mutex, например, даже при условии, что она свободна, нужно плюс-минус 1000 тактов процессора. В свое время были созданы оптимизации этого процесса (например, CRITICAL_SECTION в нативных приложениях, Monitor в .NET). Первоначально происходит попытка занять блокировку одной операцией Interlocked.CompareExchange, если она свободна. Если она занята, предполагается, что блокировка освободится скоро, и происходит SpinWait. Только по истечении предельного количества спинов начинается ожидание потока на блокировке. Это очень выгодно: либо не будет соревнований, либо из-за короткого промежутка времени блокирования не будут затрачены лишние такты процессора на переход в режим ядра.
Это отличная оптимизация по времени и ресурсам процессора, но теоретически можно подобрать такую степень соревнований за блокировку, которая из-за операций SpinWait приведет к излишнему или взрывному потреблению процессора. Объясню, как именно это может произойти: запрос обнаруживает, что Lock сейчас занят, и решает потратить, например, 32 цикла на SpinWait. После повторной неудачной попытки он решает идти спать. В таком соревновании каждый Lock будет тратить лишние циклы на Spin в достаточно большом количестве. У нас есть одна монопольная блокировка на весь сегмент, через которую должны пройти все запросы. В худшем случае это может привести к критической массе соревнований, которая загрузит процессор на 100 %.
Такой баг полгода назад для нас чинил Microsoft в реализации ASP.NET, и недавно мы опять нашли похожий.
Когда мы занимались новой версией кэша, возникла проблема: в период средней загруженности процессора (около 50–60 %) потребление могло резко возрасти до 100 %. Этот аномальный всплеск не был связан с повышением количества запросов по сети или резким приходом новых пользователей – сервер работал в обычном ритме.
В .NET есть масса уникальных и полезных счетчиков производительности. Один из них с помощью класса Monitor показывает, сколько происходит соревнований в секунду – то есть сколько было столкновений на классических блокировках. При обычном потреблении процессора столкновений было в среднем 70 в секунду. В момент 100-процентной загрузки – 500–600. Но самое интересное то, что показатель покрытия нашего кода при средней нагрузке составлял 90–92 %, а в момент загрузки показатель опускался до 17 %. Наш код буквально выдавливало чем-то другим.
Что мы обнаружили: в ASP.NET есть закрытый тип BufferAllocator и несколько производных от него. Внутри этого типа есть пул, который позволяет повторно использовать уже выделенные буферы, чтобы уменьшить количество создаваемых объектов. Он реализован очень просто: Stack, который защищен одной блокировкой. Проблема была в том, что на одно приложение приходилось всего по одному экземпляру каждого данного типа. Фактически мы получали несколько глобальных блокировок, которые брали все запросы, хоть и на короткое время.
После долгого рассмотрения Microsoft исправил свой баг – количество подобных аллокаторов было увеличено до одного на каждый экземпляр HttpApplication. Это значительно снизило количество соревнований за блокировки и на несколько месяцев избавило нас от аномалии.
Недавно опять возникла проблема внезапного и долгого потребления 100 % процессора. Уже зная, что примерно искать, мы обнаружили баг совсем рядом – в типе HttpApplicationFactory, который буферизирует экземпляры HttpApplication в Stack, блокируясь на нем на каждом запросе.
Заявка с таким багом рассматривается от нескольких месяцев до полугода. Мы разработали механизм, который ласково называем «ручной тормоз». Его суть проста: сервер отслеживает показатели загруженности процессора и состояние высокой нагрузки на сервер. Если в течении трех минут состояние сохраняется, мы притормаживаем все входящие запросы на короткий, случайный промежуток времени, нарушая цепную реакцию.
В результате пики стали кратковременными и незаметными для пользователей.
Поиск новых решений
Lock выступал «бутылочным горлышком» всего сервера. Это как если бы на весь город была одна дорога с одним светофором. Нам хотелось увеличить количество блокировок, чтобы снизить количество соревнований. Ведь если увеличить количество дорог и светофоров до 10, машин не станет меньше, но движение будет быстрее.
Мы нашли в .NET прекрасный класс ConcurrentDictionary. В нем есть Locks и корзины, количество которых равняется произведению имеющихся процессоров на 4. Класс реализован как Low Lock и позволяет модифицировать себя из нескольких потоков параллельно. Если 2 объекта идут в 2 корзины, они могут быть залочены одновременно, если в одну – просто ждут в очереди. Этот класс блокируется только на добавление, вычитывание происходит без блокировок.
Операция Evict
Когда мы использовали Dictionary и Lock, Pin проходил внутри Lock. С ConcurrentDictionary получение данных и Pin стали двумя неатомарными операциями. Представим, что у нас есть Item, который лежит в ConcurrentDictionary. Мы берем контекст игровой сущности без блокировки и ставим Pin, но в это же время приходит Shrink, вытесняет игровую сущность и осуществляет Remove. Получается явная гонка.
Можно избежать данной ситуации, просто поставив еще один Lock на Pin, но это будет выглядеть очень некрасиво. Это как если бы в супермаркете работало 20 касс, ты все оплатил на одной из них, но нужно еще пройти через дополнительную, чтобы тебе повторно пробили товары для сверки с чеком.
У нас возникла до банального простая идея. Мы написали операцию Evict, которая устанавливает счетчик Pin-ов в заведомо неправильное значение, равное ?1, с помощью привычной операции Interlocked.CompareExchange, если оригинальное значение равно 0.
Вернемся к ситуации, описанной выше, но уже с учетом Evict. Есть Item, который лежит в ConcurrentDictionary. Одновременно приходит запрос на изменение игровой сущности и на ее вытеснение. Если Evict успел установить значение в ?1, Shrink понимает, что сейчас эта сущность никем не занята и не будет взята в дальнейшем. Pin в это время делает вид, что объекта нет, и пытается обратно зайти в ConcurrentDictionary. Если Evict не успел изменить значение, Shrink понимает, что первым игровую сущность схватил Pin, и ничего не трогает.
В ситуации, когда Pin со значением 0 хотят одновременно взять 2 процесса, мы говорим, что 2 Items могут быть запинены больше одного раза (Pin примет значение 2). Lock при этом будет только один. Значение установится в 2.
public bool PinInCache()
{
int oldCounter;
do
{
oldCounter = this._pinnedInCache;
if (oldCounter < 0)
return false;
}
while (Interlocked.CompareExchange(ref this._pinnedInCache, oldCounter + 1, oldCounter) != oldCounter);
return true;
}
public void UnpinInCache()
{
Interlocked.Decrement(ref this._pinnedInCache);
}
public bool EvictFromCache()
{
return Interlocked.CompareExchange(ref this._pinnedInCache, -1, 0) == 0;
}
// UserCache
public bool TryGet(long userId, out UserCacheItem<TUser> userCacheItem, bool pinCacheItem)
{
if (!_dict.TryGetValue(userId, out userCacheItem))
return false;
userCacheItem.UpdateLastAccessTime();
// Return true if item was found. No need to pin or item was evicted.
return !pinCacheItem || userCacheItem.PinInCache();
}
private void ShrinkOldest(int shrinkNumber)
{
// Get N oldest elements. Evict the oldest elements from the Cache if possible
// Make additional Select call to prevent detecting sequence in LINQ as ICollection in Buffer class and prevent using CopyTo method
var orderedByAccess = _dict.Select(kvp => kvp).OrderBy(pair => pair.Value.LastAccessTime);
UserCacheItem<TUser> dummy;
int i = 0;
foreach (var pair in orderedByAccess)
{
if (pair.Value.EvictFromCache())
{
_dict.TryRemove(pair.Key, out dummy);
if (++i >= shrinkNumber)
return;
}
}
}
В итоге имеем высокоэффективную синхронизацию на Interlocked-операциях. Благодаря Evict мы получили хорошее снижение соревнований, а точкой синхронизации по вытеснению игровой сущности стал счетчик Pin-ов и Evict.
Остальные кэши, которые не требуют поддержки подобных операций для редактирования и служат только для повышения эффективности чтения данных, мы тоже переписали на использование ConcurrentDictionary.
Такой подход дал хороший дополнительный эффект: снизил нагрузку на сервер в 7 %. В периоды отсутствия критического состояния из-за бага в ASP.NET мы имеем от 0 до 2 соревнований в секунду и до 10 в короткий промежуток после полной сборки мусора.
KeyLockManager и LockManager
Мы выработали для себя интересную и достаточно эффективную тактику работы в многопоточной среде редактирования объектов. KeyLockManager по сути содержит те же идеи, что и ConcurrentDictionary, Pin, UnPin. Но сам по себе не хранит никаких данных, а позволяет синхронизировать потоки по значению ключа.
Допустим, есть цель записывать данные в файл или высылать их в сеть из двух потоков одновременно, но желания (или возможности) помещать экземпляры Stream в сам кэш нет. При использовании KeyLockManager потоки могут синхронизироваться, например, просто по имени файла, при этом Stream хранить в другом месте (или вообще инстанцировать только после того, как получат монопольный доступ по ключу).
LockManager – уже более полная производная идея от кэша. Он по сути представлен тем же ConcurrentDictionary с Pin, UnPin и Evict, но без сохранения в базу данных. Это обобщение идеи синхронизации с блокировками, куда можно поместить абсолютно любые данные.
Мы нашли применение LockManager в визуализации движения войск на глобальной карте.
Всё ли хорошо в итоге?
Благодаря ситуация с багом в ASP.NET мы стали лучше разбираться в особенностях механизма синхронизации и параллельного доступа к данным и эффективнее их использовать. ConcurrentDictionary мы теперь используем повсеместно, но хорошо понимаем наши действия и их последствия.
Единственный недостаток ConcurrentDictionary – нет полной документации по его работе. Все описания адресованы начинающему пользователю. На собственной практике мы нашли следующие моменты, которым точно стоит уделить внимание. Их нет в MSDN и в статьях по схожей тематике.
Метод Count – подсчет количества элементов в ConcurrentDictionary. Нигде не написано, что его выполнение подразумевает блокировку всех корзин и может негативно отразиться на производительности. Очевидно, что Count по контракту говорит тебе точное значение, но не во всех ситуациях это нужно. Если хочется посчитать примерно, лучше использовать связку операций LINQ .Select(..).Count().
Метод TryRemove выполняет попытку удаления объекта по заданному ключу. Для этого TryRemove блокирует корзину, после чего производит поиск. Это неплохо, но велика вероятность того, что объекта в коллекции нет. Лучше сначала проверить его наличие с помощью TryGetValue, который не блокирует ничего, а затем попробовать удалить. Две операции поиска часто могут быть выгоднее, чем постоянное блокирование корзин.
Самый интересные метод – GetOrAdd. Он либо возвращает значение, которое лежит по определенному ключу, либо добавляет значение и возвращает его. У GetOrAdd есть 2 перегруженных версии. Первая версия принимает значение, вторая – принимает функцию, которую нужно вызвать в случае, если не найдено значение, и попробует его добавить.
Парадокс, но они работают абсолютно по-разному. Вариант GetOrAdd со значением сразу блокирует корзину, определяет, что там ничего нет, и тогда только выполняет Add. GetOrAdd с функцией действует без первоначальной блокировки. Если в корзине ничего не будет, он вызывает функцию, получает значение, пробует заблокировать и добавить. В чем разница: в случае с функцией мы можем лишний раз выполнить код для вычисления значения, но синхронизаций будет меньше. В случае со значением мы будем выполнять постоянную блокировку, тем самым увеличивая соревнование. То есть из-за ошибки в написании можно принципиально изменить работу внутри. Мы используем версию GetOrAdd, принимающую функцию.
LINQ операция OrderBy. При передаче последовательностей LINQ проверяет, является ли данная последовательность ICollection. Тогда вместо прохождения по последовательности коллекция будет скопирована целиком. Но это же ConcurrentDictionary :) Внутри LINQ принимает последовательность за коллекцию, создает буфер и копирует ее туда. LINQ идет в эту коллекцию через свойство Count, которое, как мы уже определили, блокирует все корзины. Если размер коллекции уменьшится, при копировании выбросит исключение «количество элементов не совпадает». Мы специально вставили лишний Select запрос, чтобы скрывать, что последовательность может быть коллекцией.
Что дальше?
На данном этапе у нас есть только теоретические идеи по улучшению работы сервера. Они могут быть использованы, когда в какой-то из версий сервера мы решим перейти на полную асинхронность. Если показатель соревнований за ConcurrentDictionary слишком большой или процессы происходят в асинхронном режиме, можно синхронно заблокировать объект и не выходить из него до тех пор, пока объект не будет доступен. Джеффри Рихтер придумал отличные асинхронные блокировки: вместо того чтобы ждать освобождения блокировки, поток отдаст свою функцию, которая будет вызвана, когда блокировка освободится. Дождаться освобождения – это не то же самое, что заблокировать и ждать. Такой подход можно преобразовать для кэша.
P.S.
Буду рад узнать ваши идеи, мысли и обсудить их в комментариях. Расскажите, какие особенности знаете вы и о чем хотелось бы прочитать в следующих статьях?
Комментарии (5)

ZOXEXIVO
06.03.2017 22:31+2Единственный недостаток ConcurrentDictionary – нет полной документации по его работе
Довольно странно слышать такое, когда все исходники лежат в общем доступе

stickerov
07.03.2017 12:32Разрабатываю свой проект, связанный с асинхронным и многопоточным вычислением. В основном вычисления происходят в максимальной нагрузке в 10-20 копий одного процесса, около 1 млн. обменов в сек. между каждым процессом и одним приложением-сервером. Проще говоря единственный процесс — босс, остальные — подчиненные, у этих подчиненных есть еще подчиненные. Каждый занят своим делом, и между прочим это один и тот же исполняемый файл.
Почему не многопоток в одном процессе?
1. Очень усложняется архитектура приложения. 2. Исторически сложилось что программа пишется на 32 битах, память ограничена. 3. Задел на будущее, если нужно будет запускать на удаленных машинах.
Конечно пришлось избавляться от некоторых проблем винды, вроде того что ядро системы перегружало процессор до максимума из-за использования мэппинга, но факт в том что упрощая архитектуру приложения можно получить больше гибкости.

Ogoun
10.03.2017 18:55Сделал пример своей реализации для блокировки наборов ключей.
Код который использует этот подход предварительно собирает ключи сущностей которые будут затронуты в бизнес операции, затем пытается заблокировать, если не удалось, значит какая-то из сущностей будет обновлена, и нужно повторить операцию, предварительно обновив данные.
Neuyazvimy1
Сегментирование пользователей это не есть шардирование. Хорошее шардирование должно распределять все нагрузки поровну. В вашем случае я так понимаю если все старые пользователи решили одновременно поиграть в игру будет нагружаться сервер который отвечает за старых пользователей так? Могу посоветовать вам что-то типа postgres-xl. Которая имеет в себе принципы acid. И уже сверху такого шардинга можете поставить любой кэш.
Я шардировал с помошью citusdb.
https://en.wikipedia.org/wiki/ACID