

Аникин Денис ( danikin, Mail.Ru)
Доклад будет посвящен Tarantool. Я всегда рассказывал про use case, про что-то такое, что видит пользователь. Сегодня буду больше рассказывать про внутренности.
Когда я первый раз увидел Tarantool, когда я узнал его бенчмарки, какая у него производительность, то мне это не то, чтобы показалось подозрительным, потому что все-таки я уже до этого программировал больше чем 10 лет и примерно понимал, что можно выжать из железа при оптимальном программировании, при оптимальном коде. Но все равно мне это показалось подозрительным — как так получается, что он такой быстрый? Т.е., условно, если все базы данных могут работать со скоростью в лучшем случае в десятки тысяч запросов в секунду, а Tarantool — до сотен тысяч и вплоть до миллиона.
Поэтому, прежде чем начать применять его в продакшне, в Почте mail.ru и в Облаке, я все очень внимательно изучил и выяснил, как Tarantool устроен внутри, и что его делает таким оптимальным. И я подозреваю, что, наверное, у других пользователей Tarantool тоже есть такое же подозрение — что-то он какой-то слишком быстрый, и как-то это подозрительно…
Кстати говоря, поднимите руки те, кто ни разу не слышал про Tarantool. Почти все слышали. Кто из вас применяет его на продакшне? Не очень много. На самом деле, вы не применяете, в том числе потому, что вы не понимаете, как он так такой быстрый, а все другие медленные, и вот за счет чего. Если это действительно та причина, по который вы пока побаиваетесь его применять, тогда вы пришли в правильное место, и я надеюсь, что я сегодня вам расскажу и объясню. Конечно, не все, потому что база данных — это огромный продукт, в ней очень много фич, очень много функций и рассказать про все за 40 минут почти невозможно. Поэтому я расскажу про основное. Поехали.

Еще я кратко хотел рассказать, чего ожидать, а чего не ожидать от доклада. Ожидать — конкретику, т.е. почему Tarantool такой быстрый, почему он быстро читает, быстро пишет, быстро стартует и т.д., и какие были причины у нас в Mail.ru сделать его именно таким быстрым.

Чего не ожидать — holy wars, т.е. все базы данных хороши, каждая база данных для своего кейса, и мы не претендуем на то, чтобы быть универсальной базой данных для всего вообще. Также не стоит ожидать каких-то новых структур или новых алгоритмов, потому что основная сила Tarantool не в том, что ребята изобрели какие-то новые алгоритмы, которые до этого никто не знал, а в том, что они правильно применяют и компонуют уже существующие алгоритмы. И они пишут код очень оптимально. Вы все знаете O(N). Когда вы говорите O(N) или O(logN), то имеется ввиду, что если O(N)в 2 раза больше набора данных, в 2 раза дольше работает алгоритм, но сколько он работает конкретно — это неизвестно, т.е. можно написать его оптимально, а можно сделать кучу копирований и прочих вещей, которые не повлияют на его асимптотическую сложность, но при этом повлияют на скорость работы. Так вот, в Tarantool очень много уделено внимания этому коэффициенту, который стоит перед О, т.е. на который все умножается. Это теория, а сейчас мы переходим к практике.

Начнем с самого главного, что Tarantool хранит всю копию данных полностью в памяти. Это означает не то, что когда машина рестартится, то все теряется, а то, что копия данных есть в памяти. Данные и на диске тоже есть, естественно, но при этом все-все данные лежат в памяти и никогда оттуда не выгружаются. Тут стоит сделать оговорку, что тут речь именно про оригинальный движок Tarantool, который называется Memtx, который, по сути, все хранит в памяти и который in-memory. У Tarantool появился еще недавно дисковый движок, который позволяет не всю копию данных хранить в памяти, а только ее часть. Тут я буду касаться только оригинального движка Tarantool, т.е. только in-memory движка. Очевидно, что память быстрее, чем диск, т.е. если все лежит в памяти, то все происходит быстро.
Такая картинка, символизирующая это:

Tarantool все читает из памяти, а дисковая база данных — MySQL, Postgres, Oracle, SQL server — все они читают с диска, поэтому Tarantool быстрее. Это вроде бы очевидно, но есть нюанс.

Вы, наверное, сейчас на меня смотрите с таким прищуром: «А как же кэш, ведь у дисковых баз данных есть кэш, и почему, тем не менее, Tarantool быстрее, ведь дисковые базы кэшируют самые популярные запросы, значит они должны быть тоже такие же быстрые?». Как вы думаете, в чем отличие, когда у вас кэш, от того, когда у вас данные просто в памяти? Есть ли какое-то отличие с т.з. производительности? Устаревать может. Сейчас про это и расскажу.
Давайте посмотрим, как Tarantool взаимодействует с памятью.

Он просто читает данные из памяти, которые там всегда лежат уже подготовленные, в идеальном формате, который позволяет их быстро читать, быстро искать, быстро делать запросы по индексу.
Теперь посмотрим, как работает дисковая база:

Очень примитивная схема, естественно. Все базы разные, у всех кэш устроен по-разному, но в целом логика такая. Сначала, допустим, приходит от пользователя чтение, какой-нибудь SELECT * FROM бла-бла-бла. Сначала мы смотрим, есть ли данные в кэше. Если есть, то мы лезем в кэш и возвращаем, если нет, то мы читаем с диска, пишем то, что прочитали, в кэш. Если кэш уже забит (а кэш всегда забит по определению, потому что он всегда полный, в этом его смысл), значит, мы вытесняем старые данные и потом читаем из кэша. Т.е. если вам повезло, то на одно действие больше, если не повезло, то происходит вся эта длинная цепочка, причем, надо заметить, что это же все идет не бесплатно. Считали с диска в какой-то буфер, взяли из этого буфера, скопировали в кэш, вытеснили старое, освободили память, записали новое, выделили память. Освобождение/выделение памяти — дорого. Это все копирование, это все поиски, и это все не бесплатно. Это все тот самый коэффициент, который перед О, т.е. много-много действий нужно сделать. Обращение в хэш-таблицу, в какой-нибудь хэш-индекс по сложности возможно и константно ±, или если дерево, то логарифмическое, но вот это все — то, что умножается на О, это огромное количество работы. Плюс данные — они на диске лежат в одном виде, в кэше лежат в другом виде, потом кэшируются часто по страницам, т.о. мы загружаем чуть больше, значит, выделяем памяти чуть больше, освобождаем тоже чуть больше. Все это драгоценные циклы процессора, которые на это дело все тратятся. При этом надо понимать, что даже если вы попали в кэш, т.е. произошел read, и данные уже в кэше, то у вас процессор в фоне все равно делает все это, всю эту цепочку, она всегда делается в фоне, без остановки. Т.е. если данные даже уже в кэше, то процессор или другие его ядра чем-то заняты. А раз другие ядра чем-то заняты, то происходит блокировка, то происходят мьютексы. Много-много работы по сравнению с тем, чтобы просто считать из памяти и все.

Такая штука по поводу кэша. Почувствуйте разницу — всегда в памяти и кэш — это не одно и то же, это разные чуть-чуть вещи.

А теперь давайте про запись.

По чтению все более-менее понятно — ладно, Tarantool in-memory, он читает из памяти быстро, а что же с записью? Tarantool работает на запись почти так же, как на чтение, при этом он персистит все данные все равно на диск. Как вы думаете, почему он такой быстрый, хотя данные все равно сохраняются на диск при записи? Ключевое слово — последовательно. Сейчас я это покажу.

Что делает Tarantool, когда выполняет транзакцию? Он ее выполняет в памяти и записывает ее в log транзакции. В log транзакции он ее записывает только с целью recovery, т.е. если все упадет, чтобы подняться, из log’а все накатить и привести базу данных в то же самое состояние, в котором она была до старта.

Запись на диск происходит, как тут показано. Просто пишем в файлик, последовательно. Все вы знаете, что последовательно в файл пишется очень быстро.

Тут вопрос — это не медленно? Это достаточно быстро. На магнитных дисках — это где-то 100 Мбайт в секунду, а на SSD — это 250 Мбайт в секунду. Можете это прямо сейчас проверить. На макбуках SSD обычно стоят, это будут адские сотни Мбайт в секунду. Это на SSD. На магнитном диске чуть медленнее, но все равно, это 100 Мбайт в секунду. Что такое 100 Мбайт в секунду? Это на самом деле до фига, потому что если, например, размер транзакции 100 байт, что в принципе много, т.е. какая-нибудь там транзакция по обновлению чиселки — это просто update что-то set key =value. Нужно просто записать key и value. Если это чиселки, то это несколько байт буквально. Но даже если транзакция 100 байт, это 1 млн. транзакций в секунду. Т.е. пик производительности — 1 млн. транзакций в секунду. Это такая производительность, которая обычно никогда не нужна, она очень большая. И обычно узкое место — это даже не диск, а процессор или, например, память. Т.е. не хватает памяти, чтобы хранить столько данных, чтобы сделать столько транзакций на одной машине.

А как же дисковые базы данных пишут на диск? Почему они не могут так же оптимально писать? Они делают все то же самое, что и Tarantool, т.е. они update’тят в памяти, в кэше, они тоже пишут log транзакций, потому что как же без этого? Потому что log транзакций — это единственный способ восстановить базу данных после крэша.
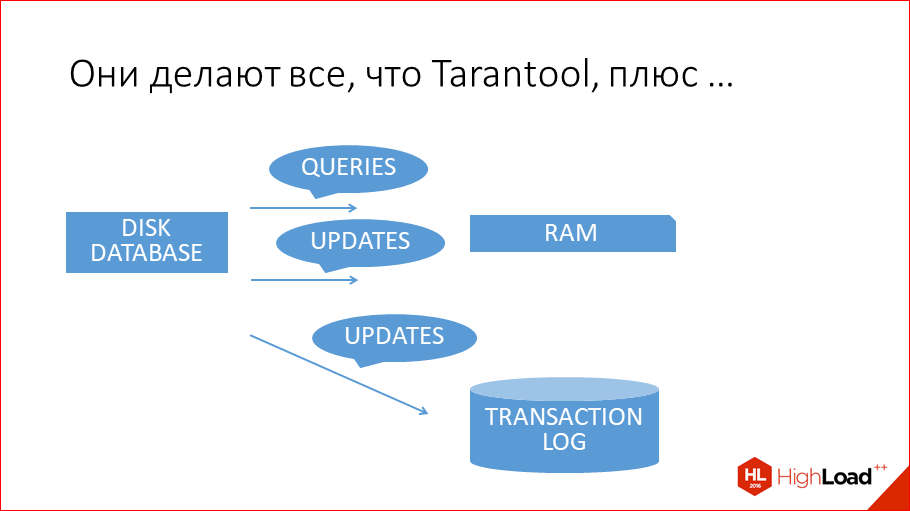
И, кроме этого, они еще обновляют данные на диске. Как они это делают?

Они обычно использую старые добрые B-деревья.
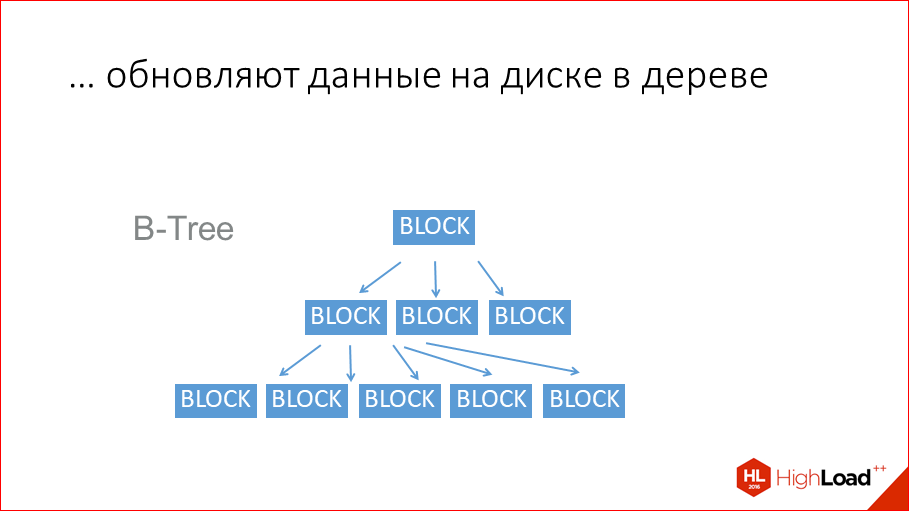
Это на сегодняшний день самая популярная структура данных для хранения на диске. Хотя, надо сказать, что появились уже новые структуры данных типа LSM-tree. Они применяются в дисковом движке Tarantool, они применяются в RocksDB от Facebook, они применяются у Google в LevelDB. В принципе, все традиционные обкатанные базы данных используют B-деревья или B+ деревья. MySQL или Postgres, Oracle — все построены на B-деревьях. B-дерево — это как дерево, только оно n-нарное, у него в каждом узле блок данных, и дальше идет много ссылок на последующие блоки. И за счет n-нарности оно очень короткое. Но все равно, чтобы считать данные, которые хранятся здесь, нужно сделать 3 чтения с диска. И эти чтения с диска происходят медленно. Тут самый главный вопрос… Правильно было сказано, что B-деревья у дисковых баз данных нужны только для того, чтобы данные потом считать. Если бы дисковые базы данных хранили бы, как Tarantool, всю копию данных в памяти, т.е. если бы они были Tarantool’ом, то им не надо было читать. А когда не надо читать, то не надо и писать. Они пишут в эту структуру, только чтобы потом считать, только ради этого. Это не для recovery. Для recovery они используют так же, как Tarantool, log транзакций. И это делает их медленнее на запись просто потому, что они дисковые, а не потому, что там плохие программисты, они там очень хорошие. А просто потому, что они дисковые.

При этом такая структура данных хороша — она не приводит к линейным поискам, но, с другой стороны, она приводит к случайным обращениям к диску. На магнитном диске это всего 100 обращений в секунду максимум. Как вы думаете, почему магнитный диск позволяет читать/писать данные последовательно 100 Мбайт/с, а случайно обращаться всего 100 раз/с? Потому что это приводит к физическому движению головки диска, и головка диска не может очень быстро двигаться. 100 раз в секунду — это и так очень много, только представьте себе. Но если вы читаете банально 100 байт, которые разбросаны по всему диску, вы будете их писать или читать со скоростью 100 байт в секунду. Тоже проведите простой тест — можете написать простую программу на C, взять какой-нибудь файлик в несколько гигов, чтобы он не поместился в page кэш, и случайно какие-нибудь байты из него почитать или пописать. У вас будет в лучшем случае 100 раз в секунду. Если фрагментировать, будет еще хуже, потому что тогда при каждом обращении будет еще несколько сиков, это будет несколько десятков раз в секунду. Это отдельная проблема, что файлы эти еще и фрагментируются. Но, вроде бы, базы данных умеют с этим бороться, они, по сути, создают какой-то там большой сразу файл заранее и правят его куски, но они его ужимают раз в какое-то время, чтобы не было фрагментации. На SSD это чуть быстрее, но то же самое, ну, 1000 раз в секунду. Опять же, почувствуйте разницу — в transaction log мы пишем 1 млн. транзакций в секунду, в table space, в B-tree мы пишем на HDD несколько десятков, 100 раз, на SSD — 1000 раз, просто разница на 3-4 порядка.
Теперь пойдем дальше. Про старт.
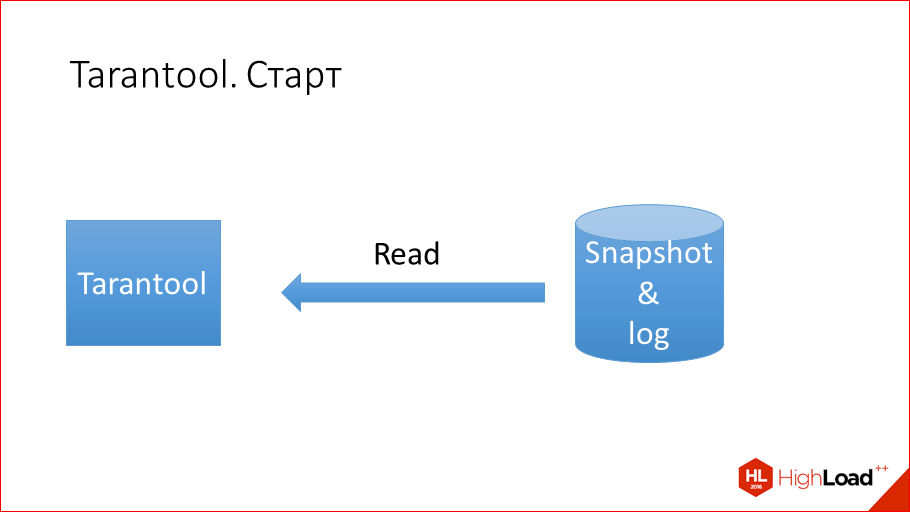
Я рассказал про чтение и про запись. Tarantool быстрее читает, потому что все in-memory, и in-memory — это не кэш, потому что это гораздо меньше работы, чем кэшить, кэшить, выделять, освобождать, менять структуру данных, копировать и т.д. И Tarantool быстрее пишет, потому что ему не нужно update’ить table space, потому что у него диск только для recovery, а не для выполнения транзакций.
Теперь про старт пойдем. Как происходит старт у Tarantool? У Tarantool есть log транзакций, есть Snapshot, про него я еще не говорил, но расскажу позже. Snapshot — это состояние базы данных на какой-то момент времени. Tarantool периодически сбрасывает все свое состояние на диск для того, чтобы log транзакций сильно не разрастался, чтобы потом можно было легко восстановиться. Соответственно, запуск Tarantool — это просто чтение 2-х файлов, причем файлы не фрагментированные и линейные, т.е. чтение из них происходит линейно. Просто от начала и до конца прочесть Snapshot, от начала и до конца прочесть log и в процессе этого чтения применить все в память. Вот, что такое старт Tarantool.
Как быстро?

Это, опять же, на магнитном диске — 100 Мбайт/с, на SSD — 200-250 Мбайт/с.

А как это происходит у дисковых баз данных? Вопрос очень интересный, потому что дисковые базы данных, надо отдать им должное, они стартуют почти моментально, потому что им не нужно считывать в память Snapshot.

Но, что происходит потом? Допустим, у вас Postgres или MySQL. Они стартовали, что дальше? Они тут же работают быстро? Прогревается кэш — это жесть. Мы сейчас находимся на HighLoad — это конференция, посвященная высоким нагрузкам. Если у вас высокие нагрузки, то у вас используется кэш вовсю, и это означает, что без кэша база данных нормально, в принципе, не работает, она просто не справляется с нагрузкой. Бывалые DBA, они умеют принудительно прогревать, разные техники и т.д. Но факт остается фактом. Как он прогревается обычно?

Как прогревается кэш? Примерно так он прогревается. Небыстро.

Пользователь идет в базу данных, чего-то у нее просит, база данных случайно читает что-то с диска (случайно, потому что данные не в кэше), и потом его отдает и кэширует. Потом приходит следующий запрос, он происходит в другое место диска, опять случайно. Да, можно прогревать, можно делать cat файлу индекса, можно делать много-много-много всего, но факт остается фактом, когда данных много, то горячие данные, те которые должны быть в кэше, где они находятся на диске, никто не знает. Как это узнать? Вы это не узнаете, пока пользователи не начнут их запрашивать. Вы знаете, что индекс — это горячие данные, но идея такая, что данные уже лежат на диске в том формате, в котором лежат, и горячие данные где-то находятся случайно. Чтобы прогреть кэш, нужно прочесть каким-то оптимальным алгоритмом эти случайно лежащие данные, что гораздо медленнее, чем просто прочесть 2 файла линейно. Вот они горячие данные, других у Tarantool и нет. Он как бы для горячих данных.
Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.
У дисковых баз данных нужно эти горячие данные как крупицы где-то выискивать. По практике Mail.ru наши супер-крутые админы все, что могли выжать из MySQL — это 1-2 Мбайта/с. На наших объемах, а у нас 100 Гбайтные, 1 Тбайтные базы, больше, чем с этой скоростью, не получается его стартовать, прогревать со всеми техниками, что неудивительно, потому что горячие данные разбросаны по диску в разных его местах. Нужно делать сики, нужно делать движения головкой. Условно вы 10 Кбайт данных прочли, сделали движение головой, потратили 1 мсек, и еще прочли пару Кбайт — еще потратили 1 мсек. Т.о., когда вы на каждую 10 Кбайт тратите 1 мсек, у вас и получается 1 Мбайт/с. Упираетесь просто в ввод/вывод. Такая ситуация. Надо заметить, эта разница в прогреве является следствием только лишь того, что кэш и «всегда в памяти» — это разные вещи. Т.е. Tarantool хранит всегда в памяти то, что надо, и оно быстро стартует, быстро чтение/запись.

А дисковые базы данных устроены по-другому, они рассчитаны на то, что данные лежат на диске, а в кэше что-то такое иногда есть, и эти данные разбросаны прямо среди дисковых данных и лежат где-то отдельно, поэтому медленный старт происходит. Разница в 100 раз где-то.

Это как раз то, что я сказал, что Tarantool группирует все горячие данные в одном месте просто by design.

Теперь давайте поговорим о latency. Latency — это время между началом запроса и получением результата. Когда я буду рассказывать про Tarantool, я буду его сравнивать не с дисковыми базами данных, потому что там все понятно, а я буду сравнивать его с другими in-memory базами данных.
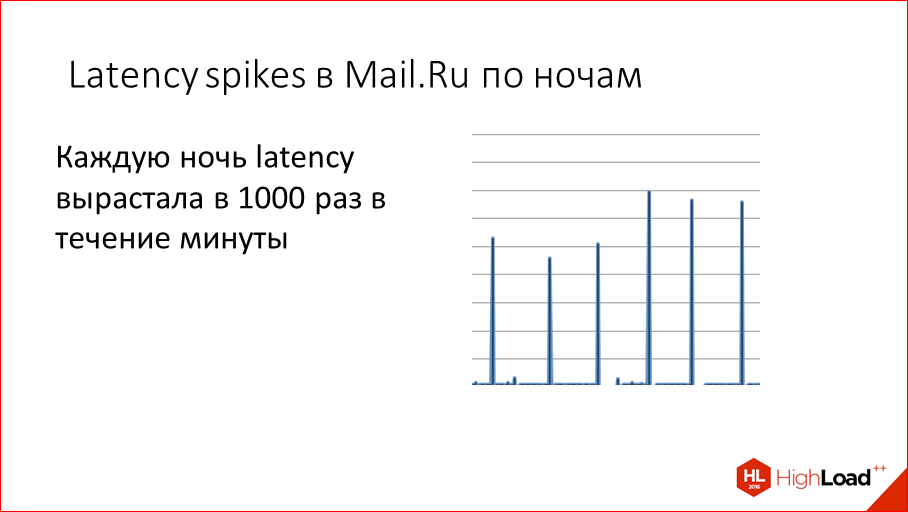
С чего все началось? Когда-то давно у нас в Mail.ru каждую ночь мы видели такие пики latency, т.е. почему-то периодически у нас вырастало в 1000 раз время выполнение запроса. Т.е. оно было не миллисекунды, а оно было секунды.
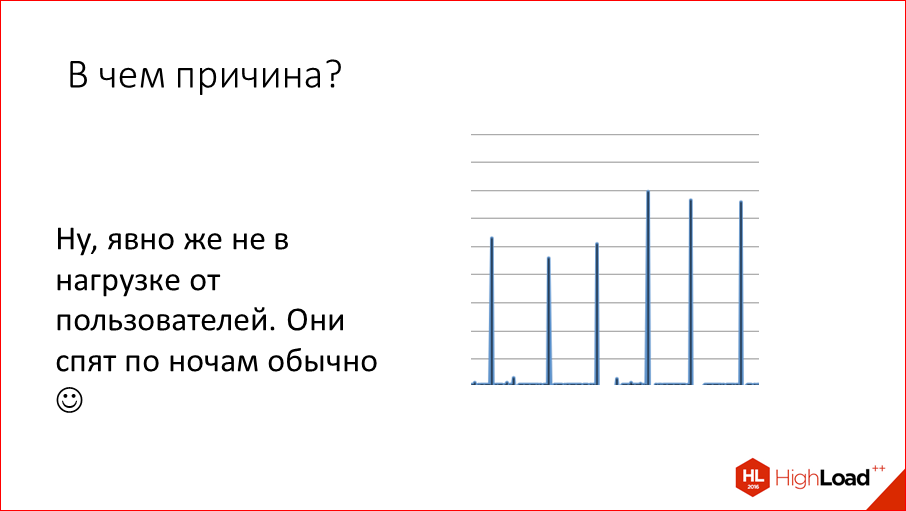
Мы стали думать, почему это происходит. Причем, происходит это по ночам, Это явно не пользователи в этом виноваты, это что-то у нас внутри. Мы стали с этим разбираться и выяснили, что причина простая — это snapshotting.

In-memory базы данных в отличие от дисковых, и это их минус очень известный, должны раз в какое-то время snapshot’иться. Т.е. если дисковая база данных не snapsot’ится, она себе работает, она изменяет данные в B-деревьях, пишет в log транзакции и ей не надо сбрасывать из памяти все состояние на диск периодически, потому что у нее данные уже хранятся и так на диске в том формате, в котором они пригодны для чтения. У in-memory баз данных не так. Они должны раз в какое-то время snapshot’иться, потому что если этого не делать, то будут скапливаться огромные логи транзакций, которые будут очень долго применяться. Вы понимаете, почему log транзакций применяется дольше, чем snapshot? Может быть 50-100-1000 операций к одному и тому же полю, и в log’e транзакций будет каждая операция идти отдельно, и это нужно все накатывать. А в snapshot она будет как одна, просто текущее последнее значение. Поэтому in-memory базы данных нужно постоянно snapshot’ить.

Как оно происходит, почему snapshoting все тормозит? Казалось бы, ну, snapshot’ится база данных и snapshot’иться, она snapshot’иться на диски, казалось бы, диск — узкое место, но она же работает с памятью, почему snapshoting может тормозить всю базу данных? Блокировка. Это очень интересная блокировка.

Чтобы не snapshot’ить с блокировкой всей базы данных мы в свое время это сделали fork’ом. Fork() — это системный вызов в Linux или Unix, который создает просто копию процесса. Т.е. он создает дочерний процесс целиком из контекста родительского процесса.
Как мы делали Snapshot? Мы делаем fork(), создаем дочерний процесс. Fork() имеет все данные, которые имеет его parent, и спокойно пишет эти данные на диск. А parent в это время обслуживает транзакции. А log при этом тормозит, почему? Copy-on-write.
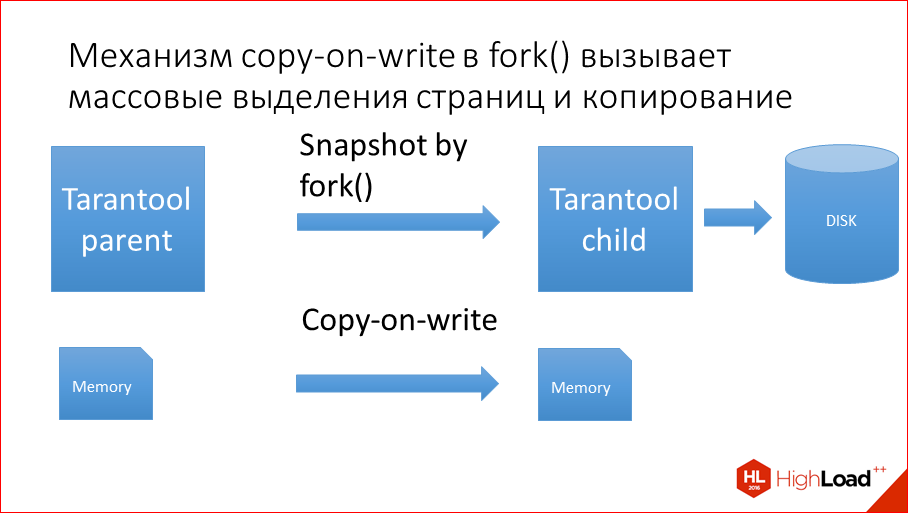
Как происходит fork()? Fork(), во-первых, копирует дескрипторы всех страниц от parent’ов child’ам, а если у вас сотни гигов памяти на машине, то десятки млн. страниц или под 100 млн. страниц 4-х Кбайтных, у каждой есть дескриптор, который сколько-то там весит, это все дело нужно скопировать первым делом. И после копирования всей этой марахайки начинает работать copy-on-write. Что это такое? Изначально child, когда стартует, он наследует все страницы памяти от parent’а, т.е. у них общая память полностью шаренная. Но как только parent или child у себя меняют хотя бы 1 байт, неважно где, эта страница полностью копируется, а страница — это 4 Кбайта. Т.о. чего происходит? В Tarantool в parent идут массовые update’ы, он update’ится там-сям, и на каждый update тех нескольких байт, которые update’ятся, вся страница 4 Кбайта копируется. Пришел update еще в какое-то место — опять страница. Т.е. она копируется в сотни раз больше, чем меняется данных. Т.о. даже от небольшой нагрузки все уходит по CPU, вся машина.

Кстати говоря, эта проблема у других in-memory баз данных, насколько мы знаем, пока не решена, они все делают так же, включая Redis, Couchbase, Aerospike. Но мы решили эту проблему в какой-то момент решить. И я надеюсь, что все остальные тоже последуют за нами, и тоже будут такие же оптимальные.
У вас есть идеи, как это улучшить? Как избавится от этого копирования, которое происходит при snapshoting’е?

По сути, это собственный механизм copy-on-write, который не подменяет системный copy-on-write, но который просто реализован внутри Tarantool, и который оперирует не со страницами, а с полями и записями. Это чем-то похоже на multiview concurrency control.

Если вы слышали такое слово, это во многих базах данных т.о. устроены транзакции, чтобы не блокировать чтение, когда идет запись. Мы тут, в принципе, делаем то же самое, наша идея — это не блокировать запись в Tarantool, пока идет чтение, и вся база данных читается и дампится на диск. Идея очень простая — во время snapshoting’а любое изменение любого элемента данных приводит к копированию этого элемента. Прямо так же, как copy-on-write. Только не вся страница копируется, а копируется только маленький элемент. И, соответственно, от этого profit. Если очень кратко. При этом нет никакого fixed cost в виде копирования таблицы дескрипторов. Просто начинается snapshoting, начинает потихоньку на каждое изменение делать копию элементов, которые меняются.

Примерно так это происходит. Есть старая версия, новая версия. Что-то изменилось, отпочковываются новые версии. Все, мы работаем с новой версией. Старую версию мы не трогаем, она участвует в snapshoting’е. Т.е. все обновления идут в новые версии. Старые версии не меняются, старая версия базы целостная и, по сути, мы не копируем всю базу, мы копируем только то, что поменялось, и только те байты, которые поменялись, те записи, те поля.

Это помогло нам решить эту проблему. Ночные спайки пропали. Это — начиная с версии 1.6.6. Это около 9 месяцев назад. Snapshot у нас был включен ночью, если бы он был включен днем, было бы все еще хуже.
Мы поговорили про чтение, про запись, про latency. Последняя тема на сегодня — это узкие места в базе данных.

На самом деле узких мест, конечно, очень много, и мы не будем все узкие места освещать, а осветим «самое узкое».

В C++, в Java и в других языках есть встроенные структуры, которые очень похожи на базу данных. Например, в С++, есть std::unordered_map — это хэш, по сути. Это как индекс, т.е. там можно писать ключ, значение, быстро читается, быстро пишется, все за О(1), и все хорошо. Это, по сути, как база данных. Только она находится внутри вашего процесса.
Эта база данных работает со скоростью (я проверял это на макбуке) 2 млн. операций в секунду на одном ядре. На самом деле можно еще больше ускорить, я просто не заморачивался сильно, но чтобы дать вам оценку — миллионы операций в секунду. Просто берете этот цикл и начинаете как-то случайно этот хэш читать/писать.
При этом индекс в базе данных, все знают, что он с такой скоростью не работает. В лучшем случае 10 тыс. операций на одном ядре, 20. Это отличие на 2 порядка. Странно получается — стандартный С++ хэш, который уже есть, используй не хочу, в 100 раз быстрее, чем такой же хэш, но внутри базы данных. Почему так? Есть одно слово, которым все объясняется, и это слово «системные вызовы».
Что такое системные вызовы? Это когда процесс обращается в ядро с целью, чтобы оно ему что-то сделало, чего он сам сделать не может — считать файл, записать файл, считать из сети и т.д. Каждый системный вызов — это зло.

Откуда системные вызовы берутся? Минимум 5 системных вызовов нужно сделать на обработку одной транзакции в базе данных, потому что обязаны считать наш запрос из сети, без этого никак. Дальше мы должны данные заблокировать — это тоже системный вызов, это mutex. Далее мы должны с ними чего-то сделать. Дальше мы должны их разблокировать, опять это mutex. Дальше мы должны обязательно записать в log транзакцию, и дальше, даже если мы не пишем ничего в table space, а пишем только в log транзакций, мы должны еще дать ответ в сеть. Т.е. меньше 5 системных вызовов сделать очень трудно. На самом деле их гораздо больше, в Postgres, MySQL, Oracle их будет на каждый запрос 10, ну, плюс-минус.
SQLite memory находится в том же адресном пространстве, т.е. SQLite — это вот std::unordered_map, которое работает в том же адресном пространстве, что и работает код. Можно долго обсуждать, что лучше, потому что, когда у вас база данных работает в том же адресном пространстве, что и код, у вас теряется сетевое взаимодействие, и вы не можете из другого места туда ходить. А если вы туда ходите из другого места по сети, то вы получаете это все.

Почему системные вызовы дорогие? Это может быть не всем понятно. Потому что происходит очень много копирований. Чтобы сделать системный вызов, нужно войти в ядро, выйти из ядра и очень много данных скопировать, потом восстановить. Можете сделать какую-нибудь программу, которая сделает read из /dev/zero, самую простую, и читает оттуда по одному байту. Чтение одного байта из /dev/zero, который на самом деле никуда на диск не ходит, а просто вам возвращает 0, оно внутри почти ничего не делает в ядре, оно будет происходить, хорошо если, 1 млн. раз в секунду. Даже простейший системный вызов работает медленнее, чем полезный std::unordered_map, который всю нашу черную работу делает. Даже 1. А их тут 5, а на самом деле больше. На log, на системный вызов, он огромный, он 90%-95% — просто огромен.

Как мы эту проблему решили в Tarantool? Мы подумали: а почему бы на один системный вызов не делать больше полезной нагрузки? Т.е. идея такая, что мы сокет используем параллельно. Например, если есть какое-то клиентское приложение, все клиенты, которые стоят на одной машине, они все пишут в один сокет параллельно. Они на клиенте делают много системных вызовов write, но Tarantool за один read, считывает все запросы из сети, которые там параллельно к нему пришли, за один read. Дальше он эти запросы параллельно обрабатывает за одну блокировку. На самом деле в Tarantool блокировок нет, там такой специальный подход, который делает его работу без блокировок. Но даже если бы они там были, мы пачку запросов приняли, заблокировали, выполнили, разблокировали, т.о. меньше системных вызовов. Дальше одной пачкой все записали на диск. Т.е. тоже один write, один syscall write на много-много транзакций. И одной пачкой все отдали клиенту тоже write в сокет.

Выглядит это примерно так. Это, по сути, несколько thread’ов, каждый из которых делает свою работу параллельно. Это клиент, он из разных процессов фигачит все в один сокет параллельно, Tarantool это все ловит одним read’ом, отдает это дальше на обработку transaction-процессору, он обрабатывает in-memory, дальше эту же пачку одним write, т.е. пачку отдает этому thread, thread пишет на диск одним write. Дальше он всю пачку отдает назад, опять же весь inter thread communication, т.е. все блокировки, которые есть, если они есть, они per пачкой, не per один запрос, а per пачкой. И оно все обратно отдается. При этом все работает параллельно, пока это обрабатывает это, этот новые принимает, новую пачку, новую пачку, новую пачку…
Это можно сравнить с тем, что автобус подъезжает к остановке, и он берет столько людей, сколько там стоят. Стоят 100 — взял 100, уехал. Стоит 1 — взял 1, уехал. На latency не влияет. Идея такая, что чем больше тут скапливается запросов от клиента, тем оно эффективней использует процессор. Если их тут мало, процессор используется неэффективно, это правда, но при этом, он и так курит, почему бы и нет?
Много машин, много сокетов, тогда мы возвращаемся в старые добрые системные вызовы. Если каждый клиент в один сокет все пишет синхронно, то мы возвращаемся в эту схему:

Оно тоже быстро, но вот этой магии нет –
Константин Осипов: У нас эта активность на много сокетов, много клиентов, все равно не будет влиять на transaction-процессор, потому что сетевой thread будет обрабатывать все эти сокеты отдельно и потом transaction-процессор патчит. Поэтому у нас и есть сетевой thread… Если сравнить нас и Redis, то когда клиентов много и нагрузка небольшая, то Redis жрет меньше CPU, это за счет подхода, что он не делает interthread-коммуникаций, у него все в одном thread. Но если нагрузка растет и клиентов много, то у нас пропускная способность этого выделенного thread, который обрабатывает транзакции, выше, потому что все остальное из него вытащено, и он делает только полезную работу.
Денис Аникин: Потому что эта хрень скейлится тут же на все ядра, они всегда будут неэффективны, потому что такой паттерн нагрузки — все используют свой сокет.
Константин Осипов: В 2-х словах, в каждом thread работает event-машина, и в каждом thread свои файберы работают, поэтому обмен сообщениями между файберами — это просто часть работы планировщика event-машины. Под капотом там используют shared memory и файловый дескриптор используется.
Денис Аникин: Это отдельная большая тема, что у Tarantool еще и файберы, кроме всего этого дела. У него параллельные запросы обрабатываются в файберах…

Тут еще есть много всего, чего я не рассказал, тут еще можно сделать 2-3 доклада, но общая идея такая, что быстрее пишем, читаем, стартуем и быстрее обрабатываем массовую нагрузку, просто потому что применяем правильные подходы, алгоритмы и всегда думаем о производительности.

И напоследок, можете зайти по адресу на слайде. У нас все open-source, не только код, но и все наши тулзы. У нас есть такая тулза (ссылка на нее), которая показывает производительность по каждому коммиту. Т.е. там по каждому коммиту происходит полный набор перформанс-тестов. И если мы видим, что какой-то коммит один из тестов уронил, то мы тут же это фиксим. Метод не технический, но это то, как мы держим себя в форме, чтобы быть всегда быстрыми.

Контакты
» anikin@corp.mail.ru
» danikin
» Блог компании Mail.ru
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++. До конференции HighLoad++ 2017 осталось меньше месяца.
У нас уже готова Программа конференции, сейчас активно формируется расписание.
Что будет в этом году о Tarantool?
- Синхронизация данных из PgSQL в Tarantool / Вениамин Гвоздиков (Calltouch);
- Хранимые процедуры в NoSQL СУБД на примере Tarantool / Денис Линник (Mail.Ru);
- Метаданные для кластера: гонка key-value-героев / Руслан Рагимов, Светлана Лазарева (RAIDIX)
- libfpta — вершина производительности между SQLite и Tarantool / Леонид Юрьев (Positive Technologies)
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Комментарии (17)

zhekappp
14.10.2017 17:521 ssd это не 1000-5000, а порядка 50000 iops
blind_oracle
14.10.2017 22:52Это сильно зависит от глубины очереди и размера io
zhekappp
15.10.2017 10:49очевидно, что тут речь идет о типовых значениях, если говорится о 100 iops на HDD



JekaMas
14.10.2017 19:38Неплохой инструмент, но каких-то преимуществ в сравнении с Aerospike не нашел.

rPman
15.10.2017 01:45Поясните пожалуйста по поводу записи лога на диск, на каждую операцию понадобится syscall, и единственное что мы можем соптимизировать, это придерживать исполнение запросов, чтобы их накопить и в виде пакета сложить в лог (после этого можно говорить что транзакции завершились) иначе упираемся во все те же 10к в секунду.
arcman
15.10.2017 19:48С Redis тоже можно работать асинхронно и обрабатывать запросы большими пачками.
Вполне ожидаемо что он при этом начинает тянуть больше миллиона запросов в секунду.
Поэтому хотелось бы больше качественных/количественных сравнений с Redis.
digore
16.10.2017 10:59Это прекрасно, когда вся база помещается в памяти, но часто это невозможно.
Хотелось бы увидеть размеры оперативной памяти для их реальных проектов.
avallac
18.10.2017 13:44Если не хранить видео с картинками в памяти, а правильно разделять данные, то хранить все в памяти проблем не составляет. Сейчас запросто можно купить сервер на несколько ТБ озу.
digore
18.10.2017 14:14Вы не поверите, но иногда данные занимают несколько десятков ТБ.
И да, вы видели сколько стоит сервер «на несколько ТБ озу»?avallac
18.10.2017 15:03Если у вас несколько десятков ТБ данных, к которым требуется быстрый доступ, то либо у вас ооооооочень много клиентов и нет проблем прикупить пару стоек, либо что-то не то храните.
[Открываем клуб нищих стартапов] Сейчас я арендую пару серверов на 128GB ОЗУ за 80 евро в месяц каждый, чтобы там крутилась in-memory база. На ебее с доставкой такой сервак можно купить c доставкой за 800 баксов.
Gemorroj
Мне лично не нравится в tarantool слишком сильная завязка на lua.
Понимаю, для чего мне субд, но не понимаю зачем мне тащить еще сервер приложений lua?
olegbunin Автор
Они уже отошли от этого, насколько я понимаю.
claygod
Если использовать Тарантул в Вашем кейсе, то без луа никак? Не опишете хотя бы в общих чертах свой кейс?
Maiami
В 1.8 (пока еще в альфе) добавили долгожданную поддержку sql для запросов
tarantool.org/ru/doc/1.8/tutorials/sql_tutorial.html