
Привет, Хабр!
Как говорится, по традиции раз в год мы в Яндекс.Погоде выкатываем что-нибудь новенькое. Сначала это был Метеум – традиционный прогноз погоды с помощью машинного обучения, затем наукастинг – краткосрочный прогноз осадков на основе метеорологических радаров и нейронных сетей. В этом посте я расскажу вам о том, как мы сделали глобальный прогноз погоды и построили на его основе красивые погодные карты.
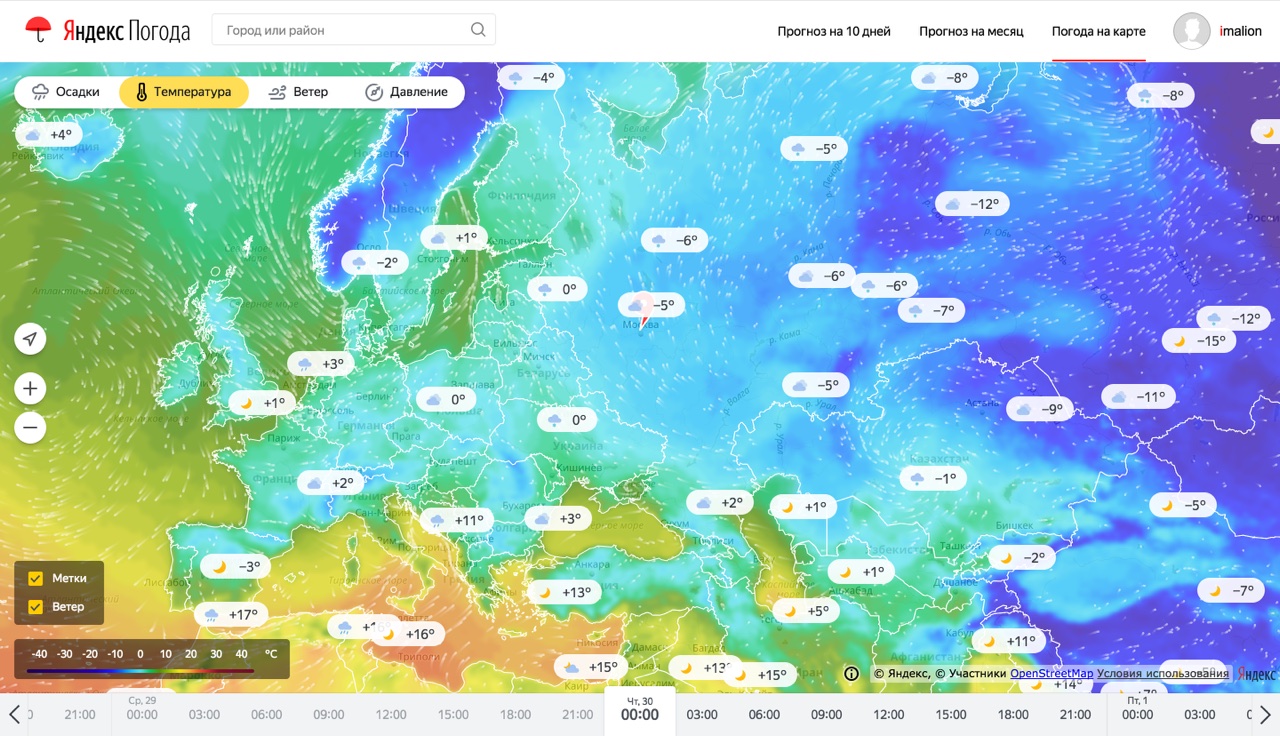
Сперва пару слов про продукт. Погодные карты — способ узнавать погоду, очень популярный на западе и пока что не очень популярный в России. Причиной тому является, собственно, сама погода. Из-за особенностей климата наиболее населенные регионы нашей страны не подвержены внезапным погодным катаклизмам (и это хорошо). Поэтому интерес к погоде у жителей этих регионов скорее бытовой. Так, людям в центральной России важно знать, например, какая погода будет в Москве в выходные или что в четверг в Питере будет дождь. Такую информацию проще всего узнать из таблицы, в которой будет дата, время и набор погодных параметров.
С другой стороны, жителям Восточного Побережья США важнее знать траекторию очередного урагана с красивым женским именем, а фермерам из Дакоты — следить за распространением града по полям, на которых растет кукуруза. Такую информацию гораздо проще узнавать из карты, чем из множества таблиц. Так и получилось, что погодные сервисы в России — это скорее таблицы, а на Западе — скорее карты. Однако, и в России существуют паттерны потребления погоды, когда пользователю нужно знать где именно будет погода, которая ему нужна: это люди, выбирающие место для пикника в выходные, спортсмены, особенно с приставкой "винд" и "кайт" и, наконец, дачники. Именно для этих категорий пользователей мы и сделали свой продукт. А теперь я расскажу о том, что у него под капотом.
Расчет прогноза: персональный и глобальный
Мы сразу решили, что для построения карт наш прогноз должен стать глобальным. Ну хотя бы потому, что карты, покрывающие не весь земной шар, отдают средневековьем. Таким образом, нам нужно было расширить Метеум до глобального покрытия. Однако, предыдущая архитектура системы плохо поддавалась горизонтальному масштабированию.
Краткое содержание предыдущих серий. Как помнит внимательный читатель, в первой реализации Метеума мы рассчитывали прогноз погоды по мере необходимости. Как только пользователь попадал к нам на сайт, мы собирали для его координат список факторов и передавали в обученную модель Матрикснета. За сбор факторов отвечал микросервис, который мы называли vector-api. Микросервис был хорош всем, кроме одного: при добавлении новых факторов и/или при расширении географии покрытия, мы приближались к лимиту памяти физических машин, на которых микросервис работал. Кроме того, само по себе формирование ответа итогового погодного API содержало дорогую по времени и по нагрузке на процессор операцию с применением модели Матрикснета. Оба фактора сильно препятствовали построению глобального прогноза. Плюс к тому, в нашем бэклоге образовалась целая очередь из факторов, которые увеличивали точность прогноза в экспериментах, но не могли поехать в продакшен в связи с ограничениями, описанными выше.
Также мы столкнулись с недостатками выбранной архитектуры для карты осадков, горячо полюбившейся многим пользователям. Для хранения и обработки данных, необходимых для построения информации об осадках, использовалась СУБД PostgreSQL с расширением PostGIS. Во время летних гроз количество запросов в тяжелые ручки в секунду молниеносно превращалось из сотен в десятки тысяч, что влекло за собой высокое потребление процессоров и сетевых каналов серверов баз данных. Эти обстоятельства послужили дополнительным стимулом задуматься о будущем сервиса и применить иной подход в обработке и хранении погодных данных.
Альтернативой расчету погоды в рантайме был предварительный расчет прогнозов для большого набора координат по мере обновления факторов. Мы остановились на глобальной сетке, покрывающей сушу с разрешением 2x2 км, а воду – с разрешением 10x10 км. Сетка разбита на квадратики 3 на 3 градуса – эти квадратики позволяют нам параллельно готовить факторы для модели и обрабатывать результаты. Вот как это выглядит на карте.
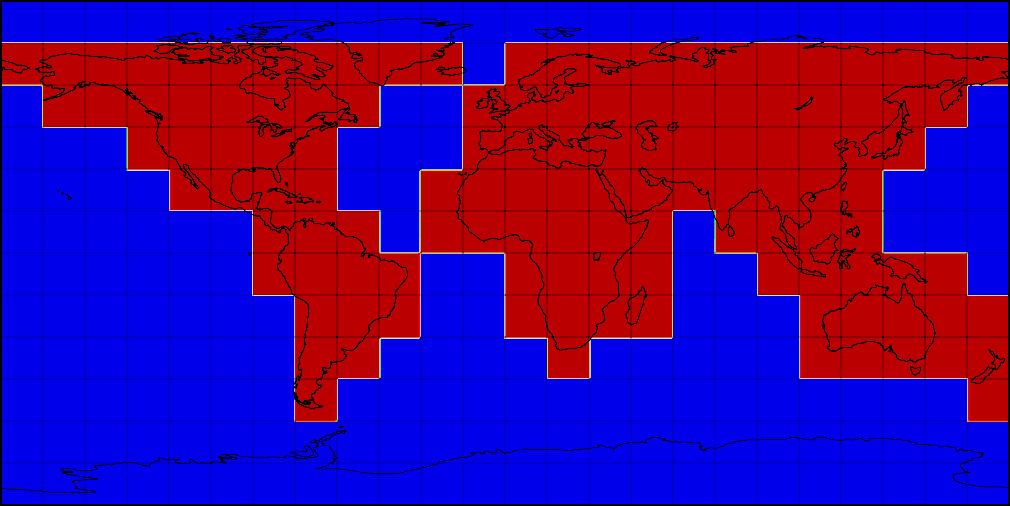
Разбиение областей глобальной регулярной сетки
Процесс подготовки погодных факторов начинается с кластера Meteo. В соответствии с названием, на этом кластере происходит «классическая метеорология». Здесь мы скачиваем данные наблюдений и прогнозы моделей GFS (США), ECMWF (Англия), JMA (Япония), CMC (Канада), EUMETSAT (Франция), Earth Networks (США) и многих других поставщиков. Здесь же происходит расчет погодной модели WRF для наиболее интересных для нас регионов. Метеорологические данные, полученные от партнеров или в результате расчетов, обычно запакованы в форматы GRIB или NetCDF с разными уровнями сжатия. В зависимости от поставщика или способа расчета, эти данные могут покрывать Московскую область или весь мир и весить от 200Мб до 7Гб.
Из метеокластера файлы с прогнозами погоды попадают сначала в MDS (Media Storage, хранилище для больших кусков бинарной информации), а потом в YT — нашу Яндексовую Map-Reduce систему. Работа в YT делится на два этапа, условно названные "подвоз" и "применение". Подвоз — это подготовка факторов для последующего применения обученной модели. Факторы надо корректно переинтерполировать на итоговую сетку, привести к единым единицам измерения и разрезать на квадратики 3 на 3 градуса для параллельной обработки и применения. Сложность процедуры здесь состоит в больших объемах данных и в необходимости проделывать упражнение каждый раз, когда пришли новые данные о прогнозе для какой-либо области.
После того как первая ступень отработала, начинается применение заранее обученных моделей машинного обучения. В первой реализации Метеума мы могли прогнозировать только два основных погодных параметра с помощью машинного обучения: это температура и наличие осадков. Теперь, когда мы перешли на новую схему расчетов, мы можем использовать тот же подход для вычисления остальных параметров погоды. Применение машинного обучения дает ощутимый прирост в точности для новых параметров: давления, скорости ветра и влажности. Ошибка прогнозирования этих параметров на 24 часа вперед падает на величину до 40%. Помимо того, что для многих пользователей важны максимально точные показатели ветра и давления, это улушение позволяет нам более точно рассчитывать еще один популярный параметр — температуру по ощущениям. Он складывается из обычной температуры, скорости ветра и влажности. Еще одним заметным новшеством стал новый способ расчета погодных явлений. Теперь в его основе лежит мультиклассификационная формула — она определяет не только наличие или отсутствие осадков, но также их тип (дождь, снег, град), а еще наличие и балльность облачности.
Все эти модели нужно применить за ограниченное время для каждой точки регулярной сетки. После того, как модели применились, есть еще один слой обработки данных — бизнес-логика. В этом разделе мы приводим переменные, спрогнозированные с помощью машинного обучения, к нужным нам единицам, а также делаем прогноз консистентным. Поскольку прямо сейчас модели ML достаточно мало знают о физике процессов, в основном опираясь на факторы, полученные из метеомоделей, мы можем получить неконсистентное состояние погоды, например "дождь при температуре -10". У нас есть идеи как делать более правильно в этом месте, однако прямо сейчас это решается формальными ограничениями.
Сложность при применении обученных моделей состоит в том, что для каждого прогноза надо выполнить порядка 14 миллиардов операций. Факторов, необходимых для каждого расчёта — сотни, и список этих факторов весьма подвижен: мы постоянно с ними экспериментируем, пробуем новые, добавляем целые группы, выкидываем слабые. Далеко не все факторы берутся напрямую от поставщиков. Мы экспериментируем с факторами-функциями нескольких параметров. Правила формирования такого количества фичей очень сложно поддерживать в виде кода на Python: громоздко, трудно делать ленивые вычисления, трудно анализировать и диагностировать, какие фичи (или исходные данные для фичей) уже не нужны. Поэтому мы изобрели свой аналог LISP. Строго говоря, это не LISP, а уже готовое AST, которое очень похоже на диалект LISP, в котором учтена специфика наших данных. Процессор этого LISP-а мы сделали таким, как нам надо: ленивым и кэширующим. Поэтому мы, во-первых, не вычисляем факторы, которые стали уже не нужны, во-вторых, не вычисляем дважды, то, что нужно дважды. Эти механизмы автоматически распространяются на все расчёты. А благодаря тому, что это формальное AST мы можем: легко анализировать что нужно, а что не нужно; сериализовать и хранить отдельно части логики, писать бизнес-части в логи, формировать большие части логики автоматически (минуя представление в виде кода), версионировать их для проведения экспериментов и так далее. Оверхед же получился совершенно незначительный, так как все операции выполняются сразу над матрицами.

Общая схема поставки данных в API
После расчета прогнозов мы записываем их в специальный формат – ForecastContainer и загружаем эти контейнеры в микросервис отдачи данных из памяти. Дело в том, что на весь мир с нашей сеткой в 0.02 градуса получается около 1 166 400 000 значений с плавающей точкой, а это 34Гб данных только на один параметр. Таких параметров у нас больше 50 – поэтому держать эти данные полностью в памяти одной физической машины не представлялось возможным. Мы начали искать формат, поддерживающий быстрое чтение сжатых данных. Первым кандидатом стал HDF5 – у которого есть функциональность чанкования данных и поддержки буфера распакованных чанков. Вторым кандидатом стал наш --самописный-- проприетарный формат – матрицы float'ов сжатые LZ4 и записанные в Flatbuffer. Результаты тестов показали, что открытие файла с данными для работы занимает в два раза меньше времении у Flatbuffers, чем у HDF5, как и чтение произвольной точки из кеша. В итоге сейчас данные для 50 переменных занимают 52.1Гб.
Так как требования к потреблению памяти и времени ответа были очень высоки еще с постановки задачи, старый микросервис написанный на Python мы решили переписать на C++. И это дало свои результаты: Время ответа сервиса в 99 квантиле упало со 100мс до 10мс.
Перевод сервиса на новую архитектуру бэкендов позволил нам отдавать прогнозы погоды нашим внутренним и внешним партнерам напрямую, минуя кэши и расчеты моделей в рантайме, дал возможность при срочной необходимости с легкостью масштабировать нагрузки с использованием облачных технологий Яндекса.
Итого, новая архитектура позволила нам уменьшить тайминги ответов, держать бОльшие нагрузки и избавиться от рассинхрона данных, отдаваемых разным партнерам. Данные Яндекс.Погоды представлены в большом количестве сервисов Яндекса и не только: главная страница Яндекса, плагин погоды в Яндекс.Браузере, погода на Рамблере и так далее. В результате все они получили возможность отдавать именно те значения, которые в этот момент видят пользователи основной страницы Яндекс.Погоды.
Ближе к людям: тайл-сервер и фронт
Для того, чтобы отрисовать прогнозы на наших новых картах, необходимо достаточно много дополнительной обработки. Сначала мы запускаем MapReduce операции на тех же данных, что отдаются микросервисом и API для формирования данных на весь мир на регулярной широтно-долготной сетке с разрешением в 0.02 градуса. На выходе для каждого параметра: температуры, давления, скорости и направления ветра, а также для каждого горизонта: времени прогноза в будущее или времени факта в прошлое мы получаем матрицы размером 9001*18000.
После этого мы строим проекцию Меркатора по этим данным и нарезаем их на тайлы в соответствии с требованиями API Яндекс.Карт. Здесь мы встречаемся с одной из самых больших сложностей в цепочке подготовки погодных карт: количеством тайлов, которые нужно оперативно обновлять при генерации каждого нового прогноза. Так каждый следующий уровень приближения карты (zoom) требует в 4 раза большего количества тайлов чем предыдущий. Несложно прикинуть, что для всех уровней приближения от 0 вплоть до 8 нужно подготовить
картинок. Всего для каждого из четырёх параметров мы показываем 25 горизонтов, из них прогнозов в будущее 12. Поэтому каждый час требуется обновить 1048560 картинок.
По мере готовности картинок мы загружаем их во внутреннее хранилище файлов Яндекса с высокой параллельностью. Как только весь слой карты для всех зумов загрузился, мы подменяем значение индекса, по которому фронт понимает, куда идти за новыми тайлами. Таким образом достигается достаточно высокая скорость появления новых прогнозов на карте и консистентность данных в пределах времени прогноза.
Даже несмотря на серьезную подготовку на бэкенде, отрисовка и анимация погодных карт тоже представляет собой сложную задачу. Рассказать все в одной статье не получится, поэтому здесь мы сделали акцент на самой заметной фиче — отрисовке анимированных частиц, показывающих направление втера.
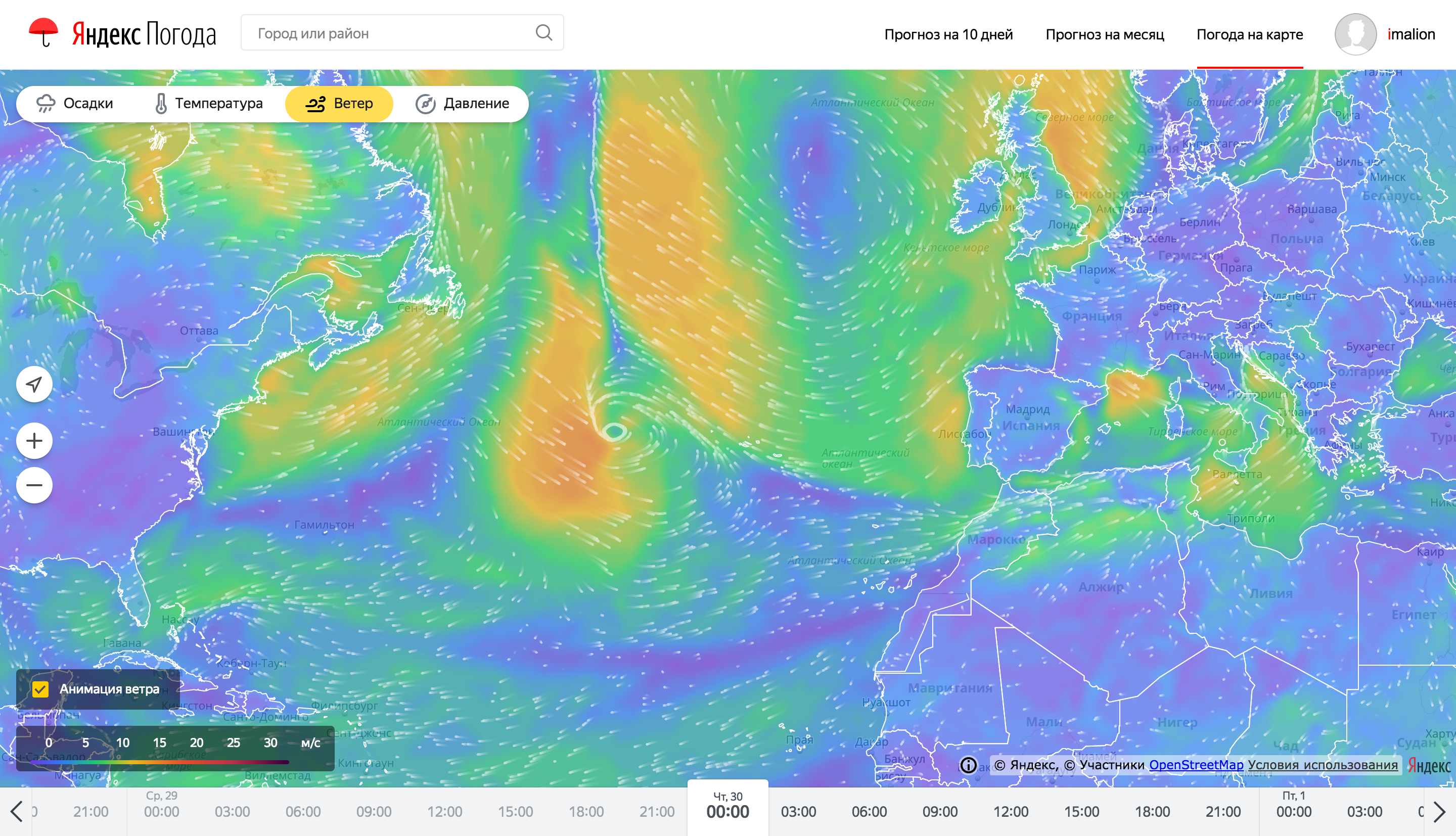
Так выглядят частицы анимации ветра на картах погоды
Для оптимизации потребления ресурсов клиентского устройства, анимация ветра выполнена с использованием WebGL. WebGL позволяет задействовать значительные ресурсы графического адаптера, разгружая процессорный поток выполнения кода, а также оптимизируя расход аккумулятора. Задачей процессора в этом случае становится установка аргументов выполнения шейдерных программ. Для перемещения частиц используется подход хранения положения частицы в 2х цветовых каналах текстуры для каждой оси (x/y). Таких текстур положения две: одна хранит текущее положение частиц, вторая предназначена для сохранения нового состояния.
Процесс отрисовки частиц описан несколькими WebGL программами. Для большей совместимости использована первая версия этого стандарта. В браузере использование WebGL выполняется через соответствующий контекст элемента canvas. Так как графический ускоритель способен выполнять в несколько раз больше параллельных операций через процессор, то перемещение частиц следует выполнять через программу WebGL. Выходной результат выполнения такой программы представляет набор точек в заданном пространстве. Это пространство по умолчанию является видимой областью своего canvas, то есть, экраном пользователя. Однако есть возможность указать целью отрисовки текстуру, используя фреймбуферы.
При старте слоя ветра процессор генерирует начальное положение частиц, создавая типизированный массив элементов в диапазоне 0...255, в количестве (частицы * компоненты) (RGBA). Из этого массива создаются две WebGL текстуры положения. Данные по скорости ветра также записываются в текстуру, чтобы видеокарта имела к ним доступ. Красный и зеленый канал этой текстуры содержат значение параллельной и меридиональной скоростей соответственно, причем значение 127 соответствует отсутствию ветра, значения меньше 127 задают скорость ветра в отрицательном направлении по оси, значения больше — в положительном. С помощью подготовленных текстур происходит отрисовка текущего положения частиц. После отрисовки, одна из текстур положения обновляется, используя вторую текстуру как источник данных по текущему состоянию. Следующие видимые кадры будут сформированы при помощи отрисовки предыдущего снимка положения частиц с увеличенной прозрачностью, поверх которого будет нанесено текущее положение частиц. Таким образом получаются частицы с затухающими хвостами.

Так выглядят частицы анимации ветра в процессе их создания
Как оказалось, текущий алгоритм кодирования положения частиц в пикселях текстуры для качественной визуализации требует поддержки на аппаратном уровне высокой точности вычислений и float-значений в самих текстурах, чего зачастую нет на мобильных устройствах, поэтому алгоритм будет переработан и улучшен.
Заключение и планы
Вот примерно все, что я хотел рассказать вам об архитектуре Яндекс.Погоды. За этот год мы полностью переделали сервис изнутри (об этом рассказано выше) и снаружи (практически все платформы, на которых присутствует Я.Погода были существенно перерисованы). Финалом этих изменений стали интерактивные погодные карты, которые вы можете попробовать на нашем сервисе.
Однако, мы никогда не останавливаемся на достигнутом. В следующем году вас ждет много интересных продуктовых и технологических апдейтов: от сервиса, позволяющего исследовать климат в разных уголках Земли до ответа на вопрос "чем дышит человек". И это, разумеется, далеко не все. Оставайтесь с нами.
Всегда ваша,
Команда Яндекс.Погоды
Комментарии (86)

derwin
30.11.2017 11:39Я вчера письмо в фидбек отправил. Похоже, что то сломали. Суть проблемы: яндекс-погода стал показывать температуру и осадки, совершенно оторванные от реальности. Яндекс показывает -20, по факту на улице -5 и на дорогах лужи. Это не единичный день, это тенденция. Барнаул.
DROS
30.11.2017 11:52-5 и лужи? Это Барнаул что-то сломал по моему.
Прогноз Яндекса всегда нагло врал, меняя показания в день по нескольку раз, при чем весьма кардинально. Про прогноз на несколько дней вперед — вообще речи не идет. Там то солнечно и тепло, то на сл. день уже дубак с осадками. Еще день спустя — вообще что-то третье может легко всплыть. Хотя Вы похоже про текущее отображение погоды говорите.
overtest
30.11.2017 12:20Помнится, ещё в 2006 или 2007 прогноз Яндекса постоянно врал, причем очень сильно (на улице ливень, а у Яндекса солнечно и ясно). С тех пор пользовался Гисметео. Думал, что Яндекс уже давно исправился, а тут вот как.
imalion Автор
30.11.2017 12:41Мы получили ваше письмо, спасибо. Некоторое время назад мы действительно испытывали некоторые трудности с прогнозом в вашем регионе, однако теперь ситуация должна нормализоваться. Пожалуйста, посмотрите на сервис в течение нескольких дней — стало ли лучше? Буду благодарен за ваш фидбек.

Evgenym
30.11.2017 13:44Мне очень нравится погода на www.meteoblue.com
На мой взгляд, показывает точнее всех. Иногда, конечно, есть несоответствия, но достаточно близко к реальности.
SchmeL
30.11.2017 13:46У меня так виджет один обновился погодный, вместо цельсия стал показывать по фаренгейту.
Хочу узнать погоду, открываю смартфон — а там +30 пасмурно, в ноябре… в поволжье… ага :)
imalion Автор
30.11.2017 12:40Поскольку фидбек достаточно однотипный, отвечу всем в общей ветке.
Действительно, анимация частицами ветра — хороший способ показать сразу несколько параметров на одной карте. Собственно, поэтому мы им и воспользовались, сделав самостоятельную реализацию на Яндекс.Картах.
Однако, на этом внешнее сходство заканчивается. Под капотом у нас собственный прогноз, рассчитанный с помощью ML. Наш прогноз значительно более точный, чем сырые модельные данные, показанные на приведенных сервисах. Именно расчету этого прогноза посвящена большая техническая часть статьи.
А кроме полей температуры и ветра, у нас есть наукастинг, которого ни у одного из наших конкурентов нет ;)
ParaPilot
30.11.2017 12:57Наш прогноз значительно более точный, чем сырые модельные данные, показанные на приведенных сервисах.
Я бы не был так катигоричен с точностью. Ваши прогнозы ошибаются по силе ветра часто. И направление бывает не совсем точным. Тот же windity гораздо точнее и чаще попадает в реальную картину.imalion Автор
30.11.2017 13:07Как я написал в тексте, только с сегодняшним релизом в продакшен поехали модели, которые используют ML для прогноза силы и направления ветра. Теперь точность прогнозов
по этим параметрам заметно выросла. Раньше наш прогноз улучшался машинным обучением только в плане температуры и осадков.
В любом случае, буду благодарен за ваш фидбек при дальнейшем использовании сервиса.
OLS
30.11.2017 23:25Feedback: изучаю карту для текущих даты/времени, отметил на карте интересующую меня точку, прочитал сведения в открывшемся всплывающем меню, переместил ползунок на завтрашнее утро — упс, всё, окошка нет, точки нет и, как я понимаю, пользователю снова предлагается искать и «кликать» эту точку на карте.

ehabi
01.12.2017 10:10У где-где, а во Владивостоке прогноз ветра актуален, как нигде. Так вот, на планшете стоит Винди, на смартфоне Яндекс. Показатели ветра похожи, но Яндекс, мне кажется, точнее. Ребята проделали большую работу, спасибо.

dom1n1k
30.11.2017 13:04начинается применение заранее обученных моделей машинного обучения
Самое важное и самое непонятно описанное. На основе каких данных модели обучались? Я просто не вполне понимаю, как можно обучить модель для условной деревни Малые Бугры, если у нас нет для неё достоверных данных для обучающей выборки? Просто проинтерполировать от соседних узлов сетки метеомоделей? Окей, часто так и делается, но при чем тут тогда обучение.erwins22
30.11.2017 13:12А чем матмоделирование отличается от использования нейронных сетей?
ничем…
и там и там все сводится к конечноразностной схеме.dom1n1k
30.11.2017 13:16Я имею в виду, что обучать нейросеть на основе интерполированных или ещё каких-либо «искусственных», а не реальных, данных — это заведомо попахивает отсебятиной. Как можно утверждать, что такой прогноз будет «значительно точнее»?
erwins22
30.11.2017 14:50А вы думаете конечно разностные схемы не врут особенно в граничных условиях?
А вот что такое «значительно точнее»… вопрос метрики.
imalion Автор
30.11.2017 13:52Да, целью этого поста было описание архитектуры, а не ML части, поэтому этот кусок получился коротким. Попробую тот также коротко ответить.
Наши модели обучаются к показания метеостанций и другим надежным источникам метеорологических наблюдений. При этом вы совершенно правы, плотность таких измерений неравномерна. Однако, первым фактором, который влияет на точность, даже в самых удаленных регионах — это полнота данных, на которых мы обучаемся. Для того, чтобы модель спрогнозировала приход антициклона в деревню Малые Бугры, нужно показать модели много вариантов движения антициклона при определенных локальных особенностях — рельефа, подстилающей поверхности и так далее. При этом необязательно, чтобы примеры, которые видит модель при обучении, находились именно в Малых Буграх. Важно только чтобы пространство факторов было достаточно репрезентативно представлено в обучающей выборке. Так большие данные помогают моделям обобщать ситуацию, не полагаясь только на локальные измерения а-ля «циклон в Гадюкино всегда приходит с запада и уходит на восток».
При этом я нисколько не отрицаю важность локальных наблюдений. Мы много работаем для того, чтобы получать как можно больше достоверных измерений к себе в систему.

fediq
30.11.2017 13:15А как вы измеряете качество своего прогноза и собираете эталоны для обучения? Проводите ли сравнение с другими метеослужбами?
imalion Автор
30.11.2017 13:55Я немного ответил выше про это. Эталоны для обучения в основном — данные с метеостанций или других настолько же надежных приборов. На них происходит обучение, кросс-валидация и валидация на отложенной выборке, все как в обычных data science процессах, с учетом некоторых особенностей. Например, при обучении и тестах важно не «залезть в будущее», чтобы данные о целевых значениях не просочились в факторы.
Все модели, которые работают в продакшене, автоматически и каждый день валидируются по всему набору станций. Мы сравниваем их прогнозы с несколькими моделями-кандидатами, а так же с чистыми прогнозами поставщиков погодных моделей, которые участвуют в формировании факторов.

arxont
30.11.2017 14:16Доступ к API также приватный? И работать с яндексой.погодой всё так же парсингом для обычных людей?
imalion Автор
30.11.2017 14:20Условия доступа к API зависят от целей использования и всегда обсуждаются индивидуально. Напишите нам на api-weather@yandex-team.ru и мы сможем обсудить ваш кейс.
Насчет парсинга хочу отдельно напомнить что EULA еще никто не отменял. Например, в нашем EULA написано, что парсить данные с сайта — незаконно.
erwins22
30.11.2017 14:59Т.е. просмотр пользователем вашего сайта незаконен? так как браузер перед просмотром парсит ваш сайт.

evnuh
30.11.2017 18:16Ну детский сад, ей богу. Давайте не будем играть в юристов, у Яндекса их всё равно больше.
3dcryx
01.12.2017 04:29Давайте. Пользователь забив адрес парсит сайт средствами браузера? Парсит. Значит незаконно пользуется сайтом.
Дайте мне определение того что значит "Парсить сайт — незаконно". А то знаетели при наивных определениях и множество всех множеств существует.
balexa
01.12.2017 10:43+1Тогда весьма странно слышать что «нашем EULA написано, что парсить данные с сайта — незаконно». Закон он на то и закон, чтобы его нормы не могли установить все подряд с помощью EULA. Думаю юристы яндекса должны это знать. Законно или нет парсить данные — это не яндексовской еулой определяется, к счастью.
Если я не принимал соглашение с яндексом, либо там не прописана ответственность (а даже если прописана — я физическое лицо и нельзя прописать то, что противоречит закону) — то я могу парсить что хочу совершенно законно.
Mirdin
01.12.2017 10:10Ну там же прямо на странице внизу ссылка:
2.2. Данные, используемые в Сервисе, предназначены исключительно для некоммерческого использования. При этом любое копирование информации и/или материалов, их воспроизведение, переработка, распространение, доведение до всеобщего сведения (опубликование) в сети Интернет, любое использование в средствах массовой информации и/или в коммерческих целях без предварительного письменного разрешения правообладателя запрещается, за исключением случаев, прямо предусмотренных настоящими Условиями, условиями использования других сервисов Яндекса или документами, указанными в п. 1.2. настоящих Условий.
balexa
01.12.2017 11:41Это как в объявление «проход в магазин с сумками запрещен». Он, как мы выяснили только для сотрудников. Вы можете просто забить на эти требования.
arxont
04.12.2017 09:58Смотрите — я исключительно для себя лично использую погодные данные. Чтобы выводить их на планшет в коридоре, чтобы знать, какая погода в данный момент + какая будет днём-вечером. Можно было бы сайт или приложение вывесить, но я использую около 10 разных источников и привожу к среднему. На самом деле парсить легче, так как не надо заморачиваться с токенами, доступом и прочим таким. Ну и под эти правила я никак не попадаю. Но всё равно доступ не дают :) Я бы даже был согласен на 4-5 запросов к API в сутки, но даже такого нет. Про коммерческое использование как раз всё легко и просто — платишь и пользуешься ))
Mirdin
04.12.2017 10:12Вопрос, конечно, лучше задать юристам яндекса, но вроде как Вы попадаете под ограничение:
любое копирование информации и/или материалов, их воспроизведение, переработка
А по поводу API, думаю яндексу просто лень заморачиваться ради 4-5 обращений в сутки. Возни с пользователями много, а прибыли нет.


ViacheslavMezentsev
30.11.2017 14:45Мне, как инженеру, всегда было интересно посмотреть статистику ошибок прогнозов. Т.е. среднюю ошибку, минимальную, максимальную хотя бы по температуре в нескольких городах в течение года. Где есть эта информация сведённая в графики или хотя бы таблицы?
imalion Автор
30.11.2017 18:46Вы удивитесь, но эта информация достаточно ценная в смысле бизнеса, поэтому она много кому в отрасли интересна. Мы ведем такую статистику для себя и для своих партнеров. В США есть сайт www.forecastwatch.com, где можно найти примеры такой статистики (правда по их городам и провайдерам).

lucius
01.12.2017 04:29Некоторое время назад я проводил небольшое примитивное исследование прогноза Яндекс.погоды. Выводы не очень.
По моему мнению, для прогнозов лучше подойдет использование моделей из гидродинамики, а не ML.ViacheslavMezentsev
01.12.2017 08:07Я так и думал. Теперь понятно почему этой информации нет в общем доступе и похоже не будет ещё очень долго.
П.С. Интересно, а за неправильно предсказанную погоду штрафы существуют? Или обязательства?encyclopedist
01.12.2017 13:19Если я правильно помню, прогноз погоды, как и картография, является лицензируемым видом деятельности. Так что где-то есть регулятор, который должен за этим следить. Я не знаю, получил ли яндекс лицензию или обошел это, например назвав официально не "прогнозом" а например "предсказанием", как раньше онлайн-карты официально назывались "схемами".
epyatyshev41
30.11.2017 15:27Про паттерны потребления погоды в России стоит отметить, что карты погоды очень популярны у дальнобойщиков. При прокладке маршрута очень часто удается «объехать» ливень или снегопад.

TimsTims
30.11.2017 15:30А я всё жду, когда на pogoda.yandex.ru будет возможность посмотреть историю за последние дни и фактическую погоду.
Чтобы можно было самому прикидывать, насколько сильно обычно изменяется погода за 30дн, 7дн, 3дня, 1день в конкретном регионе от прогнозируемого.
Особенно это актуально для отпуска — когда планируешь на недельку куда-то слетать, тебе приходится за 1 месяц до этого начинать мониторить прогноз на месяц вперед и факт, и как-то из памяти соотносить эти данные, помнить что обещали вчера, неделю, месяц назад, и что в итоге сегодня. Спасибо

KirillFormado
30.11.2017 16:13А точная карта облачности планируется? Очень полезная вещь для любительской астрономии.
Rumlin
30.11.2017 16:54Пользуйтесь weather.com — точность погоды в большинстве случаев до 30 минут. Если ошибается, то в каком-то редком погодном явлении. Данные со спутников и метеостанций.И большой опыт в предсказании и моделировании. Если в поисковой строке Google ввести "погода", то будет прогноз этой компании.

peacemakerv
30.11.2017 17:58А вот такая идея: отслеживание погоды в выбранной точке. И предупреждение на email\SMS\push о резком изменении, например, направления ветра на 45 градусов, давления на 7 мм.рт.ст и др.
Рыболовы оценили бы… или скалолазы…
saddy
30.11.2017 18:08А что за серая хрень на половине полной карты осадков, не меняющая свои очертания при выборе любого времени внизу страницы? Это дождь? А почему на миникарте осадков (на главной странице) дождь выглядит иначе и сразу понятно что это дождь?
Или это просто глюк моего браузера (Яндекс.Браузера если что)?
Скриншот «хрени»: screenshot.ru/01e41651c6f4eed986b9770f2a071bb2imalion Автор
30.11.2017 18:54Это не хрень и не дождь, это граница области видимости радара. Радиус измерений этого инструмента ограничен и для серой области у нас нет данных об осадках. Мы хотим расширить область покрытия осадков, но это происходит постепенно.
mitrym
30.11.2017 18:43-1Зашибись конечно, вещь крутая, но… в Питере завтра — осадки, послезавтра осадки… и потом тоже осадки. Зачем портить себе настроение.
almazsr
30.11.2017 18:43Что за фигня с давлением? Для сравнения:
Яндекс.Погода: joxi.ru/MAj16bES4q7zV2
Windy: joxi.ru/Rmzq7bEC0kZ6Wr
Я так понимаю учитывается высота, в которой указано значение. Только зачем? Влияние высоты на давление достаточно велико. Карта распределения давления теряет смысл.imalion Автор
30.11.2017 18:56Для давления мы добавим величину, приведенную к уровню моря, чтобы было удобнее отслеживать циклоны и все такое.

Evgeny42
30.11.2017 19:47На фаерфоксе (57) очень сильно тормозит. На хроме лучше, но тоже не идеально. При этом аналоги которые кидали выше, практически не тормозят.
Железо почти топовое.imalion Автор
01.12.2017 12:49Знаем про проблемы с загрзкой железа, будем оптимизировать вместе с добавлением новых слоев.

SlavikF
30.11.2017 20:37Я в Сиэттле (это штат Вашингтон).
Зашёл на карту, меня сервис определил как «Вашингтон».
Но на карте показал на Востоке! Я долго соображал, пока понял, что мне показывается Washington, DC вместо Washington state
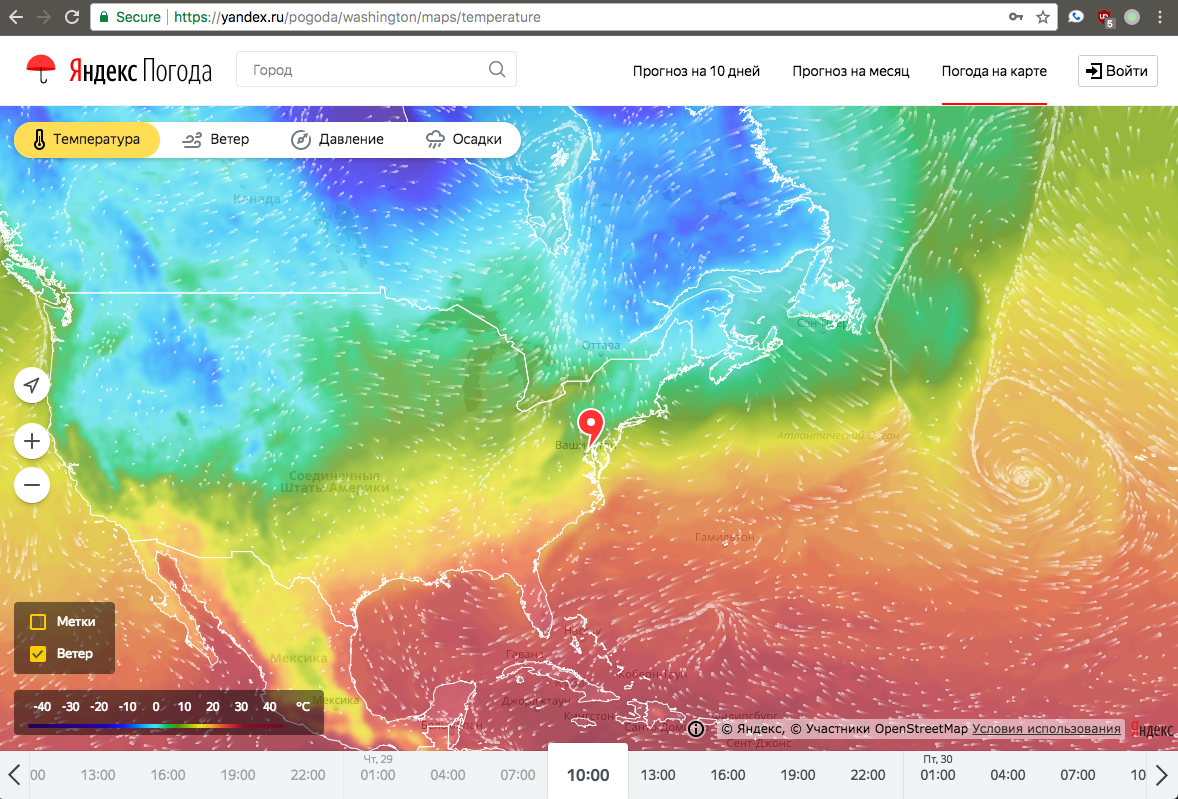
justboris
30.11.2017 20:55У меня аналогично. Я сейчас нахожусь в Берлине, а точка на карте показывает куда-то в середине Германии. И в заголовке страницы пишется прекрасное: "Погода undefined undefined"

imalion Автор
01.12.2017 12:17Пришлите, пожалуйста, ссылку на страницу, на которой такое получается.
justboris
01.12.2017 13:36- Открываю страницу https://yandex.ru/pogoda/berlin/maps/temperature. Точка указывает на Берлин, все верно.
- Жму на кнопку "определелить мое местоположение": вот эту
- Маркер перемещается в какое-то странное место, а в заголовке появляется undefined.
Воспроизводится каждый раз, как я это делаю.
imalion Автор
01.12.2017 13:42Скопируйте ещё, пожалуйста, ссылку, которая после уточнения местоположения получилась — там будут координаты, на которые произошло перемещение.
{kind=link}
Hixon10
30.11.2017 20:40Удивительно, но интересен бизнес вопрос. А какая миссия/цель проекта Яндекс.Погода? Заработок? Или вы делаете этот проект для полноты, чтобы «и погода у нас была, и телевизионная программа»?

4knowledge
01.12.2017 11:08В интервью на TJ — говорили, что хотят внедрить погоду в свою рекламную сеть, тк от погоды зависит конверсия
imalion Автор
01.12.2017 12:57Мы обычно не делаем проекты из соображений «чтобы было». Погода важна как пользовательский сервис, у нас большая и стабильная аудитория, которая регулярно возвращается. Мы поняли, что, чтобы принести им пользу, погодные данные должны быть максимально точными. Так начался проект Метеум — применение ML к погоде, в широком смысле этого слова. После многочисленных тестов мы поняли, что данные получились и правда качественные, поэтому их можно предлагать погодозависимым бизнесам. Мы начали с рекламы, однако спектр применений точных погодных прогнозов в сегменте b2b чрезвычайно широк.

AndrewSu
30.11.2017 23:11+1Интересная статья.
А почему вторым кандидатом стал свой формат хранения данных Flatbuffers?
Тот же tiff умеет и чанкование, и сжатие, и пирамиды, и float, и кэшировать удобно. Мы в своих задачах (со сходными объёмами данных) его используем. Скорость работы ограниченна только системой хранения.

deniskin
30.11.2017 23:14Мой второй по частоте использования сервис Яндекса после карт. Вы большие молодцы, карта движения осадков летом очень часто спасала от мокрой одежды и обуви.
KiloLeo
01.12.2017 00:04Любопытно, какова мощность оборудования, которое всё это обрабатывает? Можно дать какие-то количественные параметры?
encyclopedist
01.12.2017 03:42Интересно, используете ли данные сетей краудсосинга, вроде Blitzortung или других каких-то? И планируете ли?
imalion Автор
01.12.2017 13:01+1Конкретно для молний мы берем данные из другого источника. Вообще тема краудсорсинга в погоде богатая. Если говорить коротко, то некоторые из этих данных крайне полезны, но далеко не все.

kelvinist
01.12.2017 10:11Вторым кандидатом стал наш --самописный-- проприетарный формат – матрицы float'ов сжатые LZ4 и записанные в Flatbuffer
Подскажите, а данный проприетарный формат не планируется стать свободным, т.е. не планируете его выложить в свободный доступ? Очень бы хотелось посмотреть. Также сталкиваюсь в работе с большими объемами данных в памяти и прямого доступа к ним в связи с необходимостью большой скорости.
Спасибо

VJean
01.12.2017 12:57Данные предоставляются поставщиками на платной основе? Есть данные ли в свободном доступе для собственного академического ковыряния и изучения? Если есть, то с какой точностью и ограничениями?
imalion Автор
01.12.2017 13:02Это зависит от поставщиков. Данные GFS, например, доступны бессплатно в той самой точностью, которую используем мы.
bearenok
01.12.2017 13:45А как у вас с метеоданными от поставщиков в Индонезии? Стоит ли полагаться на точность в масштабе пары километров (в частности на о. Бали)? Учитывается ли рельеф Индонезийских островов?
d-sky
Круто! Но что-то похожее я уже видел.
mnbck
Windity
В копилку.
konservs
И ещё windy.com :-)
drsheff
Или вот
Devgru
Скорее всего это первая такая визуализация, ей 4 года недавно исполнилось, судя по гитхабу.
dom1n1k
Самое первое было это — hint.fm/wind
Правда, там ещё без глобуса, но именно с такими ветряными потоками