
Чат-боты, поддерживающие общение с человеком на естественном языке, весьма популярны и востребованы. Сегодня мы хотим поделиться с вами первой частью перевода материала о разработке чат-ботов с помощью ChatScript (CS), написанного сотрудником WebbyLab на основе опыта, приобретённого им в ходе работы над одним из недавних проектов компании. Здесь, в частности, речь пойдёт об основах работы с CS, рассмотренных с точки зрения программиста-практика. ChatScript хорош тем, что на нём можно сравнительно просто разрабатывать масштабные системы с возможностями искусственного интеллекта, и тем, что его несложно интегрировать в проекты, написанные на JavaScript.

Однажды перед компанией, где я работаю, WebbyLab, встала задача по разработке интеллектуального чат-бота для страховой компании из США. На момент начала работ у клиента уже был пользовательский интерфейс для чата в Facebook. Нам нужно было сделать так, чтобы бот, который «сидит» за этим интерфейсом, понимал бы сообщения пользователей и осмысленно на них отвечал, анализируя фразы и извлекая нужную ему информацию из введённых данных. Мы решили разделить высказывания пользователей по их возможным намерениям и реализовать механизм распознавания этих намерений на основе набора фраз. Кроме того, нужно было учесть и то, что намерения могут содержать в себе различные параметры (например — площадь дома, дата, модель автомобиля), которые чат-боту тоже нужно было распознавать. В качестве платформы для реализации проекта был выбран ChatScript.
Для начала взглянем поближе на ChatScript. Это движок для создания чат-ботов, программы, созданные на котором, четыре раза получали премию Лёбнера. Его разработали Сью и Брюс Уилкокс. CS основан на правилах и работа с ним может напоминать декларативный подход к программированию, похожий на написание конфигурационного файла или грамматики для интерпретатора. Впрочем, работа с CS ближе к императивному программированию, так как тут, кроме того, приходится использовать команды для того, чтобы сообщить движку о том, как реагировать на то или иное сообщение. CS написан на C++, у движка имеются бинарные сборки для платформ Windows, Linux и MacOS.
Лучший способ освоить программный инструмент заключается в том, чтобы опробовать его на практике, создать с его помощью нечто простое и лёгкое для понимания. Именно таким проектом мы сейчас и займёмся. Кроме того, советую посмотреть эту статью о и пройти официальное учебное руководство по ChatScript.
Прежде всего стоит подготовить удобное рабочее место. Для этого советую установить инструменты разработки, поддерживающие подсветку синтаксиса CS. Вот плагины для Sublime Text 3, Visual Studio Code и Atom. Я использовал Sublime, так как иногда нужно было открывать огромные файлы, а этот редактор быстро справляется с подобной задачей, однако вы можете выбрать тот редактор, который нравится именно вам.
Для того, чтобы разъяснить базовые вещи, я рассмотрю пошаговый пример разработки действующего чат-бота. В моём примере используется Ubuntu 16.04 и CS 7.4., но вы можете пользоваться любой другой поддерживаемой платформой.
1. Клонируем репозиторий CS с GitHub:
2. Перейдём в директорию
3. Скопируем файл s
4. Добавим следующий код в файл
5. Добавим в файл
6. И, наконец, соберём и запустим бота. Для этого надо выполнить следующую команду из директории ChatScript:
7. На данном этапе можно выбрать любое имя пользователя. Далее, в консоли CS, надо выполнить две команды (первая собирает базовый уровень чат-бота, вторая настраивает его на конкретную тематику):
После выполнения всех этих шагов у нас окажется работающий чат-бот. В настоящий момент он понимает лишь несколько фраз (вроде «I need a burger» и «I want ice-cream»), но его можно расширять, добавляя новые правила и топики. После любого изменения файла
Теперь вы вполне можете приступить к работе с ChatScript. Но для начала я советую узнать немного больше об основных конструкциях CS, почитав официальную документацию. Тут я расскажу об основных механизмах CS, полагаясь на собственный опыт работы с этой средой для разработки чат-ботов.
Топик (topic) — это набор правил, которые предполагается использовать совместно. Если предложить системе задействовать конкретный топик, то, до тех пор, пока с ним работают, действовать будут лишь правила из этого топика. Топики объявляют с использованием ключевого слова (
Каждый топик обычно включает в себя множество связанных с ним правил. Переключение между топиками, или, другими словами, вызов одного топика из другого, выполняется с помощью метода
Правило (
Описания правил обычно включают в себя тип (
В данном случае входные данные будут обработаны правилами из топика, переданного функции
Переменные в CS — это механизм для хранения данных, введённых пользователем. Существуют переменные для краткосрочного хранения информации — их значения очищаются после выхода из шаблонов, и пользовательские переменные, долгосрочные хранилища информации, которые хранят значения до тех пор, пока их не очистят. Вот пример кода правила, в котором используются краткосрочные переменные:
Знак подчёркивания указывает на краткосрочную переменную (можно задать — сколько именно слов нужно запомнить в такой переменной, используя, например, конструкцию
Шаблон (pattern) используется для описания порядка и набора слов, появление которых ожидается в том, что будет вводить пользователь, общаясь с ботом. На мой взгляд, весьма примечательная возможность шаблонов CS заключается в том, что при их описании не нужно добавлять все формы каждого слова. В системе есть встроенная поддержка механизма, в ходе работы которого в шаблоне, включающем в себя лишь одну форму слова, могут быть найдены все формы этого слова.
Например, возьмём глагол «be». Добавление его в шаблон так же включит в него этот глагол во всех его формах: am, is, are, was, were, been. Однако, для обработки данных, содержащих вспомогательные глаголы (will, have, do), их надо добавлять в явном виде — CS может автоматически обрабатывать разные формы только для отдельных слов. Для этой цели я советую использовать ещё одну возможность шаблонов — необязательное слово в фигурных скобках:
То же самое касается существительных и местоимений — достаточно добавить слово в именительном падеже единственного числа, после чего CS будет искать совпадения для всех вариантов слова, используя свои внутренние механизмы. В шаблонах можно также расширять варианты фраз, которые соответствуют некоему высказыванию, используя наборы слов в определённых позициях шаблона. Расширяя наш пример, мы можем добавить в него следующее:
Данное правило будет соответствовать всем предложениям, введённым пользователем, с комбинациями указанных слов (например — «I want a hamburger», «I will take a potato», «I need ice-cream»). Ещё одна важная особенность работы мемоизации, описания которой я не нашёл в официальной документации к CS, заключается в том, как краткосрочные переменные работают в наборах (если найдёте эту тему в документации — дайте знать пожалуйста). На самом деле, в подобной ситуации в краткосрочной памяти, в переменной
Кроме того, можно контролировать начало и конец введённых пользователем фраз, используя знаки
Внутри шаблонов, на самом деле, можно делать ещё много всего интересного. Например — проверять значения на соответствие каким-то критериям. Например, вот что можно сделать, если внутри некоего диапазона нас интересуют лишь цифры:
Концепт (concept) — это набор слов или комбинаций слов, привязанных к одному ключевому слову (имени концепта). Объявление концептов похоже на объявление топиков. Список слов, относящихся к концепту, приводится в квадратных скобках:
После объявления концепта его можно использовать как псевдоним в правилах вроде этого (теперь наш шаблон обнаружит совпадения только для слов, заданных в концепте
Более того, одни концепты можно вкладывать в другие, создавая дополнительный уровень абстракции, группируя разные наборы слов в одном родительском концепте:
Если нужно выяснить, к какому именно концепту принадлежит слово, с которым обнаружено совпадение, можно использовать ключевое слово
Если нужно находить совпадения не только с отдельными словами пользовательского ввода, но и с комбинациями слов, их тоже можно добавить в концепт, заключив в кавычки, или используя знаки подчёркивания между разделяемыми словами в одной фразе (этот подход также используется, когда нужно найти совпадения со знаками препинания):
Эти подходы похожи, но я предпочитаю использовать кавычки, так как они упрощают чтение кода.
Ещё одна интересная возможность CS заключается в наличии стандартных концептов, определённых на уровне движка. Они позволяют пользоваться уже подготовленными наборами для наиболее часто используемых в естественном языке фраз и отдельных слов с одинаковым или схожим значением. Среди них — концепты
Вот раздел документации CS, где можно найти сведения обо всех встроенных концептах.
Если, по какой-то причине, вам нужно расширить существующие стандартные концепты, вы можете добавлять записи в файл
После этого достаточно перезапустить движок ChatScript и фраза «roger that» будет добавлена в концепт
Кроме того, существующие концепты можно расширить другим путём — новые значения в них можно добавлять, используя ключевое слово
Для того, чтобы обеспечить повторное использование кода, в CS имеются макросы — функции, которые разрабатывает программист, вызываемые для формирования выходных данных или для использования их в шаблонах. В нашем проекте используется JSON, в результате выходные данные должны быть соответствующим образом отформатированы для того, чтобы их можно было передать в класс-обёртку JS. Для этой цели я решил подготовить строку, которую можно легко разобрать в JavaScript. Каждый раз, когда система генерирует некие выходные данные, я преобразую их в JSON-строку. Однако, в CS есть и методы для работы с JSON. Если задействовать всё это с использованием
Использование макросов в правилах выглядит точно так же, как применение вышеописанной стандартной функции
Так как макросы можно писать для различного форматирования выходных данных в зависимости от параметров, можно создавать их и для шаблонов с похожими конструкциями для множества правил, используя
Часть шаблона, возвращённого макросом, может быть переиспользована во множестве других шаблонов, что позволяет упростить скрипт:
На следующей схеме показано место каждой из конструкций CS, о которых мы говорили, в чат-боте.
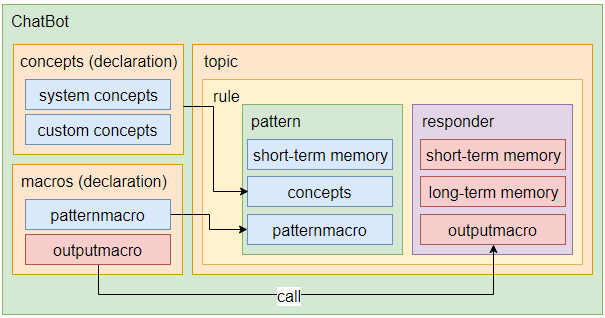
Схема чат-бота
Как видите, топики, концепты и макросы должны быть объявлены во внешнем слое бота. Правила вложены в топики. Каждое правило, в качестве входной точки, имеет шаблон, и нечто вроде респондера, или тела правила, которое выполняется только в том случае, если вызывается текущий шаблон. Концепты и макросы шаблона, объявленные за пределами топика, затем используются внутри правила с переменными для краткосрочного хранения данных, содержащими значения, необходимые для формирования ответа. В то же время, в респондере может быть вызван макрос для обработки выходных значений. Переменные для долговременного хранения данных используются для передачи данных из краткосрочных переменных в другие топики в том случае, если респондер вызывает команду вида
Сегодня вы узнали об основах ChatScript, а значит, если хотите использовать этот движок для разработки собственного бота, можете приступать к планированию проекта. Из следующей части этого материала вы узнаете об окружении CS, об отладке CS-проектов, об интеграции CS и JavaScript, и о том, как справляться с проблемами, которые могут возникать при разработке чат-ботов на ChatScript.
Уважаемые читатели! Занимаетесь ли вы созданием чат-ботов? Если да — расскажите пожалуйста о том, какими инструментами вы пользуетесь.
Постановка задачи
Однажды перед компанией, где я работаю, WebbyLab, встала задача по разработке интеллектуального чат-бота для страховой компании из США. На момент начала работ у клиента уже был пользовательский интерфейс для чата в Facebook. Нам нужно было сделать так, чтобы бот, который «сидит» за этим интерфейсом, понимал бы сообщения пользователей и осмысленно на них отвечал, анализируя фразы и извлекая нужную ему информацию из введённых данных. Мы решили разделить высказывания пользователей по их возможным намерениям и реализовать механизм распознавания этих намерений на основе набора фраз. Кроме того, нужно было учесть и то, что намерения могут содержать в себе различные параметры (например — площадь дома, дата, модель автомобиля), которые чат-боту тоже нужно было распознавать. В качестве платформы для реализации проекта был выбран ChatScript.
ChatScript
Для начала взглянем поближе на ChatScript. Это движок для создания чат-ботов, программы, созданные на котором, четыре раза получали премию Лёбнера. Его разработали Сью и Брюс Уилкокс. CS основан на правилах и работа с ним может напоминать декларативный подход к программированию, похожий на написание конфигурационного файла или грамматики для интерпретатора. Впрочем, работа с CS ближе к императивному программированию, так как тут, кроме того, приходится использовать команды для того, чтобы сообщить движку о том, как реагировать на то или иное сообщение. CS написан на C++, у движка имеются бинарные сборки для платформ Windows, Linux и MacOS.
Разработка простого бота
Лучший способ освоить программный инструмент заключается в том, чтобы опробовать его на практике, создать с его помощью нечто простое и лёгкое для понимания. Именно таким проектом мы сейчас и займёмся. Кроме того, советую посмотреть эту статью о и пройти официальное учебное руководство по ChatScript.
Прежде всего стоит подготовить удобное рабочее место. Для этого советую установить инструменты разработки, поддерживающие подсветку синтаксиса CS. Вот плагины для Sublime Text 3, Visual Studio Code и Atom. Я использовал Sublime, так как иногда нужно было открывать огромные файлы, а этот редактор быстро справляется с подобной задачей, однако вы можете выбрать тот редактор, который нравится именно вам.
Для того, чтобы разъяснить базовые вещи, я рассмотрю пошаговый пример разработки действующего чат-бота. В моём примере используется Ubuntu 16.04 и CS 7.4., но вы можете пользоваться любой другой поддерживаемой платформой.
1. Клонируем репозиторий CS с GitHub:
git clone https://github.com/bwilcox-1234/ChatScript.git2. Перейдём в директорию
ChatScript и создадим папку для чат-бота с файлом для основных топиков (о том, что это такое, мы поговорим ниже), и с файлом filesfood.txt, который содержит список топиков, включаемых в приложение:bash
cd ChatScript/RAWDATA
mkdir FOOD
touch FOOD/food.top
touch filesfood.txt3. Скопируем файл s
implecontrol.top из RAWDATA/HARRY в папку FOOD. Это — скрипт, необходимый для взаимодействия с ботом. Тут, хотя это и необязательно, можно поменять значение переменной $botprompt в 9-й строке файла simplecontrol.top на строку, которая будет подставляться перед каждым сообщением бота. Однако, можно оставить всё как есть (по умолчанию там стоит HARRY), так как на поведение бота это не влияет. В моём примере я использую следующую настройку этой переменной: $botprompt = ^"fastfood>.bash
cp HARRY/simplecontrol.top FOOD/simplecontrol.top4. Добавим следующий код в файл
food.top:topic: ~fastfood keep repeat []
t: Hello in our online fastfood. Please make your order.
u: BURGER (I [want need take] _[burger potato ice-cream])
$order = _0
Okay, you want $order . Something else?5. Добавим в файл
filesfood.txt список файлов, которые будут использоваться при сборке бота:RAWDATA/FOOD/simplecontrol.top
RAWDATA/FOOD/food.top6. И, наконец, соберём и запустим бота. Для этого надо выполнить следующую команду из директории ChatScript:
./BINARIES/ChatScript local7. На данном этапе можно выбрать любое имя пользователя. Далее, в консоли CS, надо выполнить две команды (первая собирает базовый уровень чат-бота, вторая настраивает его на конкретную тематику):
:build 0
:build foodПосле выполнения всех этих шагов у нас окажется работающий чат-бот. В настоящий момент он понимает лишь несколько фраз (вроде «I need a burger» и «I want ice-cream»), но его можно расширять, добавляя новые правила и топики. После любого изменения файла
food.top нужно снова выполнить команду :build food. Ниже мы поговорим подробнее о синтаксисе и конструкциях, использованных в этом примере.Основные конструкции ChatScript
Теперь вы вполне можете приступить к работе с ChatScript. Но для начала я советую узнать немного больше об основных конструкциях CS, почитав официальную документацию. Тут я расскажу об основных механизмах CS, полагаясь на собственный опыт работы с этой средой для разработки чат-ботов.
?Топики
Топик (topic) — это набор правил, которые предполагается использовать совместно. Если предложить системе задействовать конкретный топик, то, до тех пор, пока с ним работают, действовать будут лишь правила из этого топика. Топики объявляют с использованием ключевого слова (
topic:), за которым следует имя, начинающееся со знака «~» (~fastfood) и список функций (keep repeat), которые должны использоваться для всех правил внутри топика (функции keep и repeat нужны для возврата к этому топику после вызова каждого правила внутри него). В конце объявления идут квадратные скобки — []:topic: ~fastfood keep repeat []Каждый топик обычно включает в себя множество связанных с ним правил. Переключение между топиками, или, другими словами, вызов одного топика из другого, выполняется с помощью метода
^respond, о котором мы поговорим ниже.?Правила
Правило (
rule) — это вызов действия при совпадении шаблона внутри него с данными, отправленными чат-боту. Правила нужно размещать после объявления топиков.u: BURGER (I want ari-burger) Okay, your order is hamburgerОписания правил обычно включают в себя тип (
u:), метку (например — BURGER; это необязательно, но полезно для целей отладки и самодокументирования кода), шаблон (всё, что находится в скобках). Описание правила, кроме того, можно разделить на несколько строк для того, чтобы улучшить читаемость кода. CS не обращает внимание на переводы строки, признаком окончания правила является объявление нового правила или топика. В правиле можно пользоваться командой перехода к другому топику — функцией ^respond:u: BURGER (I want ari-burger)
^respond(~answers)В данном случае входные данные будут обработаны правилами из топика, переданного функции
^respond. Этот подход может дать нам возможность делить CS-скрипты на части, или, например, помещать форматирование ответов для фраз в отдельные топики.?Переменные и работа с памятью
Переменные в CS — это механизм для хранения данных, введённых пользователем. Существуют переменные для краткосрочного хранения информации — их значения очищаются после выхода из шаблонов, и пользовательские переменные, долгосрочные хранилища информации, которые хранят значения до тех пор, пока их не очистят. Вот пример кода правила, в котором используются краткосрочные переменные:
u: ORDER (I want _)
$order = _0
Okay, your order is $orderЗнак подчёркивания указывает на краткосрочную переменную (можно задать — сколько именно слов нужно запомнить в такой переменной, используя, например, конструкцию
_*, что соответствует всем словам, или _*2, что соответствует двум словам, и так далее). В результате, если сработает вышеприведённый код, слово из введённых данных, которое идёт после «I want», будет сохранено в кратковременной памяти. Для того, чтобы получить к нему доступ, во второй строке используется конструкция _0. Шаблон может включать в себя столько подобных переменных, сколько нужно (обычно — не более 20, но этого, как правило, вполне достаточно), в то время как получение значений из них выполняется с использованием имён, состоящих из знака подчёркивания и порядкового номера совпадения внутри шаблона. В данном примере $order — это пользовательская переменная, в которую записано то, что хранится в _0.?Шаблоны
Шаблон (pattern) используется для описания порядка и набора слов, появление которых ожидается в том, что будет вводить пользователь, общаясь с ботом. На мой взгляд, весьма примечательная возможность шаблонов CS заключается в том, что при их описании не нужно добавлять все формы каждого слова. В системе есть встроенная поддержка механизма, в ходе работы которого в шаблоне, включающем в себя лишь одну форму слова, могут быть найдены все формы этого слова.
Например, возьмём глагол «be». Добавление его в шаблон так же включит в него этот глагол во всех его формах: am, is, are, was, were, been. Однако, для обработки данных, содержащих вспомогательные глаголы (will, have, do), их надо добавлять в явном виде — CS может автоматически обрабатывать разные формы только для отдельных слов. Для этой цели я советую использовать ещё одну возможность шаблонов — необязательное слово в фигурных скобках:
u: BURGER (I {will} take _burger)То же самое касается существительных и местоимений — достаточно добавить слово в именительном падеже единственного числа, после чего CS будет искать совпадения для всех вариантов слова, используя свои внутренние механизмы. В шаблонах можно также расширять варианты фраз, которые соответствуют некоему высказыванию, используя наборы слов в определённых позициях шаблона. Расширяя наш пример, мы можем добавить в него следующее:
u: BURGER (I {will} [want need take] [_burger hamburger potato ice-cream])
$order = _0
Okay, your order is $orderДанное правило будет соответствовать всем предложениям, введённым пользователем, с комбинациями указанных слов (например — «I want a hamburger», «I will take a potato», «I need ice-cream»). Ещё одна важная особенность работы мемоизации, описания которой я не нашёл в официальной документации к CS, заключается в том, как краткосрочные переменные работают в наборах (если найдёте эту тему в документации — дайте знать пожалуйста). На самом деле, в подобной ситуации в краткосрочной памяти, в переменной
_0 будет сохранено любое совпавшее слово из набора. Пользовательская переменная $order, в любом случае, когда будет обнаружено совпадение, получит некое значение.Кроме того, можно контролировать начало и конец введённых пользователем фраз, используя знаки
< и >:u: BURGER (< I {will} [want need take] [_burger hamburger potato ice-cream] >)Внутри шаблонов, на самом деле, можно делать ещё много всего интересного. Например — проверять значения на соответствие каким-то критериям. Например, вот что можно сделать, если внутри некоего диапазона нас интересуют лишь цифры:
u: OLD_ENOUGH (I be _~number _0>21 _0<120)
You are old enough for this.
u: TOO_YOUNG (I be _~number _0<21)
$missed_age = 21 - _0
You are too young for this, come after $missed_age years.?Концепты
Концепт (concept) — это набор слов или комбинаций слов, привязанных к одному ключевому слову (имени концепта). Объявление концептов похоже на объявление топиков. Список слов, относящихся к концепту, приводится в квадратных скобках:
concept: ~food_type [burger potato salad ice-cream]После объявления концепта его можно использовать как псевдоним в правилах вроде этого (теперь наш шаблон обнаружит совпадения только для слов, заданных в концепте
~food_type):u: BURGER (I want _~food_type)
$order = _0
Okay, your order is $orderБолее того, одни концепты можно вкладывать в другие, создавая дополнительный уровень абстракции, группируя разные наборы слов в одном родительском концепте:
concept: ~dessert [ice-cream sweets cookie]
concept: ~burger [burger hamburger cheeseburger vegeterainburger]
concept: ~food_type [~burger ~dessert potato salad]Если нужно выяснить, к какому именно концепту принадлежит слово, с которым обнаружено совпадение, можно использовать ключевое слово
pattern. В следующем примере значение, сохранённое в переменной $drink проверяется на предмет его принадлежности к концепту ~alcohol. Для этой цели мы используем ключевое слово pattern и знак ? в выражении if, разделяя им то, что мы проверяем, и целевое значение концепта (CS поддерживает конструкции if-else):concept: ~drink_type [~alcohol ~non_alcohol]
concept: ~alcohol [rum gean wiskey vodka]
concept: ~non_alcohol [cola juice milk water]
u: DRINK (^want(_~drink_type))
$drink = _0
if (pattern $drink?~alcohol) {
^respond(~age_checker)
} else {
Ok, take and drink your $drink .
}Если нужно находить совпадения не только с отдельными словами пользовательского ввода, но и с комбинациями слов, их тоже можно добавить в концепт, заключив в кавычки, или используя знаки подчёркивания между разделяемыми словами в одной фразе (этот подход также используется, когда нужно найти совпадения со знаками препинания):
concept: ~vegburger ["vegeterian burger" "vegeterian’s burger" vegan_burger vegan_’s_burger]Эти подходы похожи, но я предпочитаю использовать кавычки, так как они упрощают чтение кода.
Ещё одна интересная возможность CS заключается в наличии стандартных концептов, определённых на уровне движка. Они позволяют пользоваться уже подготовленными наборами для наиболее часто используемых в естественном языке фраз и отдельных слов с одинаковым или схожим значением. Среди них — концепты
~yes и ~no, включающие в себя фразы, которые могут быть интерпретированы в естественном языке как положительные и отрицательные. Например, в концепте ~yes имеются такие слова и фразы, как yes, yeah, ok, okay, sure, of_course, alright, и многие другие (всего 183). В концепте ~no имеется 138 соответствующих слов и фраз. Вот ещё некоторые концепты, которые пригодились нам при работе над проектом:~number— помогает искать совпадения с числами.
~yearnumber— является подмножеством~number, которое содержит только значения от 999 до 10000.
~dateinfo— помогает находить в тексте даты, используя формат записи со слэшем. Например mm_dd_yy или mm_dd_yyyy будут распознаны как строки «mm / dd / yy» или «mm / dd / yyyy».
~timeword— при использовании этого концепта, например, для «1 July 2017» и для «July 1 2017» будет возвращено «July 1 2017». Кроме того, этот концепт включает в себя огромный набор слов, связанных со временем, вроде second, yesterday, already, и так далее).
Вот раздел документации CS, где можно найти сведения обо всех встроенных концептах.
Если, по какой-то причине, вам нужно расширить существующие стандартные концепты, вы можете добавлять записи в файл
LIVEDATA_ENGLISH_SUBSTITUTES/interjections.txt:<roger_that> ~yesПосле этого достаточно перезапустить движок ChatScript и фраза «roger that» будет добавлена в концепт
~yes. Угловые скобки в начале и в конце фразы означают, что совпадением будут считаться только эти два слова, и ничего больше.Кроме того, существующие концепты можно расширить другим путём — новые значения в них можно добавлять, используя ключевое слово
MORE:concept: ~food [burger potato]
concept: ~food MORE [ice-cream]?Макросы
Для того, чтобы обеспечить повторное использование кода, в CS имеются макросы — функции, которые разрабатывает программист, вызываемые для формирования выходных данных или для использования их в шаблонах. В нашем проекте используется JSON, в результате выходные данные должны быть соответствующим образом отформатированы для того, чтобы их можно было передать в класс-обёртку JS. Для этой цели я решил подготовить строку, которую можно легко разобрать в JavaScript. Каждый раз, когда система генерирует некие выходные данные, я преобразую их в JSON-строку. Однако, в CS есть и методы для работы с JSON. Если задействовать всё это с использованием
outputmacro, мы получим простой и удобный способ форматирования выходных данных для API бэкенда приложения:outputmacro: ^formated_in_json(^param_from_rule)
{
$_result = ^jsoncreate(object)
$_result.first_level_param = ^param_from_rule
$_result.nested_object = ^jsoncreate(object)
^jsonwrite($_result)
}Использование макросов в правилах выглядит точно так же, как применение вышеописанной стандартной функции
^respond:u: FOOD (I want _~food_type)
^formated_in_json(_0)Так как макросы можно писать для различного форматирования выходных данных в зависимости от параметров, можно создавать их и для шаблонов с похожими конструкциями для множества правил, используя
patternmacro:patternmacro: ^want(^appendix)
[i we] * [want need take] ^appendiЧасть шаблона, возвращённого макросом, может быть переиспользована во множестве других шаблонов, что позволяет упростить скрипт:
u: FOOD (^want(_~food_type))
If you want _0, you should get \_0 .
u: DRINK (^want(_~drink_type))
Ok, take and drink your _0 .Схема чат-бота
На следующей схеме показано место каждой из конструкций CS, о которых мы говорили, в чат-боте.
Схема чат-бота
Как видите, топики, концепты и макросы должны быть объявлены во внешнем слое бота. Правила вложены в топики. Каждое правило, в качестве входной точки, имеет шаблон, и нечто вроде респондера, или тела правила, которое выполняется только в том случае, если вызывается текущий шаблон. Концепты и макросы шаблона, объявленные за пределами топика, затем используются внутри правила с переменными для краткосрочного хранения данных, содержащими значения, необходимые для формирования ответа. В то же время, в респондере может быть вызван макрос для обработки выходных значений. Переменные для долговременного хранения данных используются для передачи данных из краткосрочных переменных в другие топики в том случае, если респондер вызывает команду вида
^respond(~another_topic). Это означает, что обработкой данных, которые затем будет выведены пользователю, займутся правила в другом топике.Итоги
Сегодня вы узнали об основах ChatScript, а значит, если хотите использовать этот движок для разработки собственного бота, можете приступать к планированию проекта. Из следующей части этого материала вы узнаете об окружении CS, об отладке CS-проектов, об интеграции CS и JavaScript, и о том, как справляться с проблемами, которые могут возникать при разработке чат-ботов на ChatScript.
Уважаемые читатели! Занимаетесь ли вы созданием чат-ботов? Если да — расскажите пожалуйста о том, какими инструментами вы пользуетесь.
Toshiro
Это все прекрасно, но снова про английский язык. Даже на конференциях вроде ДИАЛОГ-а подавляющее большинство прикладных разработок — про английский язык. Где же такие статьи и системы для русского языка?
Когда 6 падежей, а не 2 как в английском. Когда язык поддерживает все 6 базовых порядка слов, а не 2 как в английском. Когда время равномерно размазано по всему языку, и присутствуют маркеры которые контекстно могут относиться к любому времени, а не организованы в аккуратные 12 времен. Когда омонимия — это половина языка, а сам язык при этом настолько инкапсулирует контекст, что в нем что угодно можно выразить смешивая императив и декларатив, и положить болт на их противоречия. В противовес английскому, который исторически формировался как инструкция (благодаря чему и стал техническим языком).
И потом, от статей с таким названием лично я вот уже много лет ожидаю, что в них расскажут о том как красиво кто-то автоматизировал хотя бы процессы синтеза правил. А в итоге в каждой статье одно и тоже — снова и снова переизобретается интерфейс для колоссального ручного труда.
Даже под капотом IBM WATSON постоянный ручной труд, разница лишь в том что когда IBM нужно сделать Ватсону поддержку японского языка, они просто покупают японскую компанию которая присоединяется к ручному наполнению Ватсона.
И даже в отношении английского языка… ну вот есть ChatScript. И что же в нем прям радикально отличает его от хотя бы OWL/RDF? Да даже от реляционно связанных предикатов, использующихся как основа для регулярок — такое можно написать просто на Python, PHP, JS, хоть на бейсике.
Где и в чем он упрощает разработку при создании чат-ботов? А сопровождение эксплуатируемой системы? Почему система использующая ChatScript не потонет в хаосе и безумии мониторинга, оценки, ранжирования, модификации и контроля правил, когда их количество перевалит хотя-бы за 10000? А 100000? А миллион?
ChatScript только для маленьких систем? Эффективен только в системах с количеством правил в районе 100? Если у меня весь проект на Python, зачем мне тащить в маленький проект целый +1 язык ради 100 правил?
koorchik
Chatscript на самом деле расчитан именно на большое количество правил и на очень высокую скорость работы. Тысячи правил и тысячи одновременных пользователей — это совершенно нормально для ChatScript, кроме того это не просто матчинг, синтаксический разбор фраз на части речи, приведение времен — все это сильно облегчает написание правил (и сократить их количество) и позволяет сделать код более поддерживаемым и универсальным.
Относительно других языков, все сложнее. ChatScript поддерживает подключаемы синтаксические парсеры для других языков, но самих таких парсеров не так много. А что есть — слишком медленные.
Системы на базе ChatScript четыре раза получали Лёбнера. Отличная статья про это — https://github.com/bwilcox-1234/ChatScript/blob/master/WIKI/PAPERS/Paper%20-%20WinningTheLoebners.md