
Команда из Google представила самообучаемую систему, способную «выхватывать» речь человека с помощью одновременного распознавания аудио и видеоряда, отделяя другие голоса и посторонний шум. Исследование называется «Смотреть, чтобы слышать на коктейльной вечеринке» («Looking to Listen at the Cocktail Party»).
Человек способен выделять голос нужного ему собеседника из толпы, а при необходимости — игнорировать знакомый голос и настраиваться на чужой. Исследование команды учёных Университета Куинс в Онтарио (Канада) 2013 года доказало на практике «эффект коктейльной вечеринки» с помощью теста семейных пар в возрасте от 44 до 79 лет, которые на момент исследования находились в браке не менее 18 лет. За годы совместной жизни люди настраиваются друг на друга, способны выделить информацию, сказанную голосом супруга на аудио, либо игнорировать этот голос при необходимости. Семейные пары, знакомые менее пяти лет, способны распознавать голос своей половины хуже, но это не исключает возможности фокусироваться на любом отдельно взятом говорящем в шумной комнате или слышать своё собственное имя в общем потоке информации.
Разработанная Google Research технология позволяет редактировать видео, усиливая голос основного оратора и избавляясь от постороннего шума. Метод работает с обычными видеороликами с одной аудиодорожкой. От пользователя требуется только выбрать лицо человека, которого необходимо услышать, либо дать программе сделать это автоматически, ориентируясь на обстановку. Метод может найти применение в улучшении звука и распознавании голоса из аудио в текст, в приложениях для конференций, для улучшения слуховых аппаратов, а также в других ситуациях, в которых одновременно участвует большое количество людей.

Особенность технологии состоит в одновременном использовании аудиодорожки и видеоряда. Движение губ говорящего должно соответствовать его речи. Визуальный сигнал позволяет не только выделить и усилить нужный голос, но и произвести обратный процесс – сопоставить речь с конкретным человеком на видео.
Программа работает с видео, на котором говорят одновременно несколько человек. На выходе метод позволяет получить две аудиодорожки — нужный голос и остальные звуки с шумом.

Для тренировки системы специалисты использовали 100 тыс. видео высокого качества с лекциями и монологами на YouTube. Из роликов взяли сегменты с чистой речью, без звуков и музыки на фоне, в которых при этом спикер находится в кадре. В результате получилось около 2000 часов фрагментов видео.
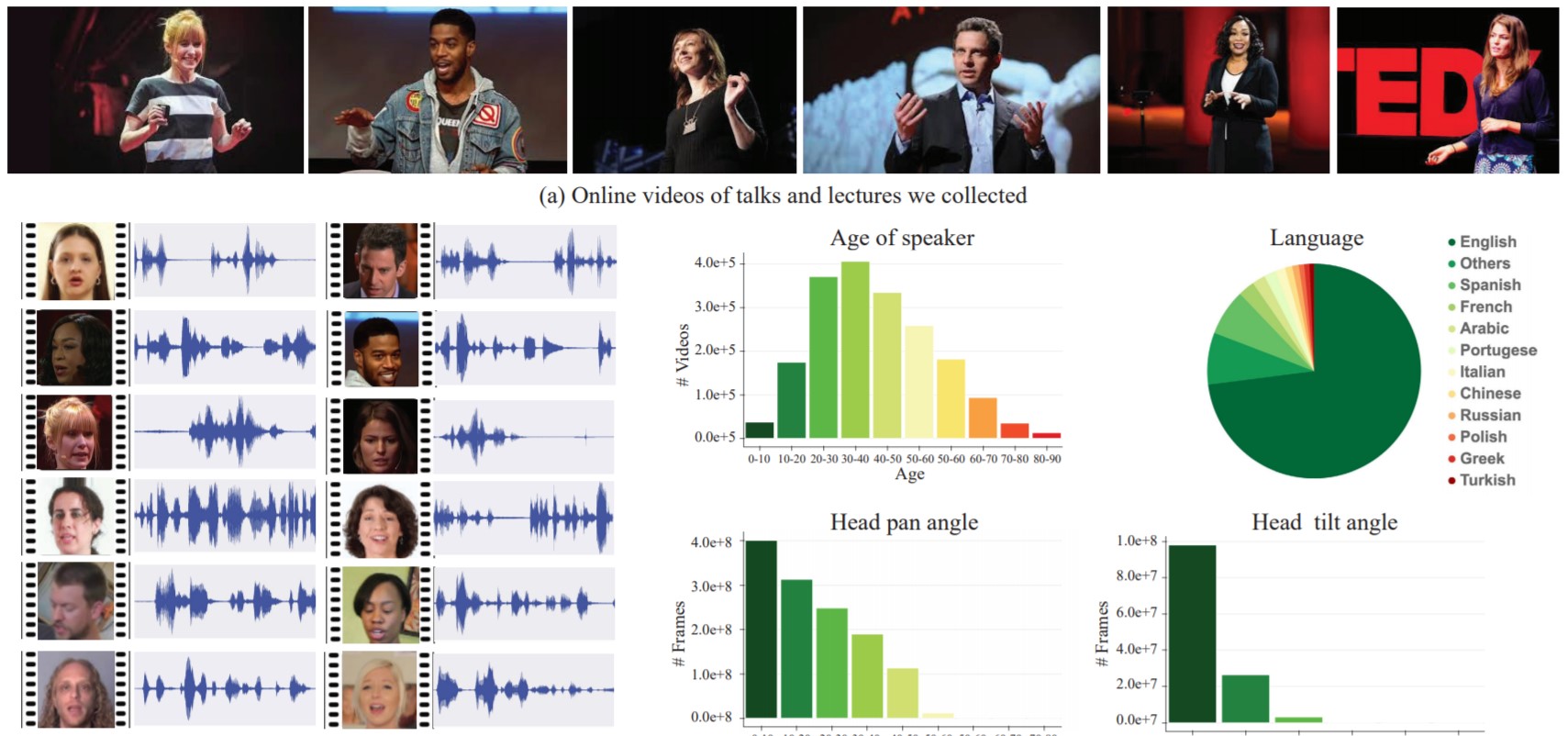
Материалы использовали для создания «искусственных коктейльных вечеринок» вместе с посторонним шумом, которые они взяли из Audioset. Результатом стал видеоряд, на котором множество людей говорят одновременно. Во время обучения сеть сопоставляла отдельные аудиодорожки с лицами и составляла «маску» для каждого из говорящих.
Среди возможных применений технологии Google Research предлагает использование для более точного автоматического составления субтитров для видео.
Работа опубликована на сайте Библиотеки Корнелльского университета.
Комментарии (9)


Rambalac
14.04.2018 14:53+1Теперь для гугл дома ещё и камеры придётся покупать. А то пока от него только раздражение.
Syzd
14.04.2018 16:39+2нужно Гуглу скормить старое немое кино, да на многих художественных фильмах артисты кривляются ничего не говоря, но на документальных AI наверно узнал бы по губам что говорят?

JohnDoe_71Rus
14.04.2018 17:26+2скормить записи митингов, что бы тов. майор знал кто, про кого и что кричал.
vassabi
14.04.2018 18:19тов. майору пофигу — он обычно всех, кто рядом стоял, заносит в автозак и все. Вот тем, кто потом в обезъяннике сидит, может пригодится: «там нет моего голоса, дяденька майор, выпустите меня пожалуйста»
vilky
14.04.2018 22:28Пытались приобщать свои видеозаписи акций или даже требовать пересмотреть и перепроверить ментовские — безрезультатно — видео остаётся на запечатанном в конверт диске (то есть судья не мог его посмотреть), но судья выносит постановление, как будто он его смотрел. Нементовские видео вообще не принимаются к рассмотрению. Так что не пригодится.

PwrUsr
14.04.2018 21:55хм… с картинкой не интересно…
вот "Ок, Гугл!" нормально можно будет пользоваться когда он научится слышать только хозяина, а то я ему — "Ок, Гугл!", а рядом дети мои играют… кричат… говорят… телек что-то бурчит… жена шипит… и Гугл от всей это радости нифига понять не может, что я от него хочу — потому я этим и не пользуюсь (сегодя редко человек находится в тишине).vilky
14.04.2018 22:51Историк будущего, наткнувшийся на этот коммент: «Люди начала XXI века не смогли воспользоваться голосовыми интерфейсами из-за постоянно работавшего телевизора.»
ru1z
Отличная штука. На youtube куча интересных видео, но со звуком обычно никто не возится. Например, если старые лекции обработать, станет намного понятнее и интереснее. Да и качественные автоматические субтитры совсем не помешают (а если субтитры будут сделаны отдельно для каждого из говорящих, по ролям, как в фильмах — фантастика).