
Привет, Хабр! Представляю вашему вниманию перевод статьи "Detecting Sarcasm with Deep Convolutional Neural Networks" автора Elvis Saravia.

Одна из ключевых проблем обработки естественного языка — обнаружение сарказма. Обнаружение сарказма важно в других областях, таких как эмоциональные вычисления и анализ настроений, поскольку это может отражать полярность предложения.
В этой статье показано, как обнаружить сарказм и также приведена ссылка на нейросетевой детектор сарказма.
Сарказм можно рассматривать как выражение язвительной насмешки, либо иронию. Примеры сарказма: «Я работаю 40 часов в неделю, для того чтобы оставаться бедным», либо «Если больной очень хочет жить, врачи бессильны».
Чтобы понять и обнаружить сарказм, важно понять факты, связанные с событием. Это позволяет выявить противоречие между объективной полярностью (обычно отрицательной) и саркастическими характеристиками, переданными автором (обычно положительными).
Рассмотрим пример: «Мне нравится боль от расставания».
Трудно понять смысл, если в этом утверждении есть сарказм. В этом примере «Мне нравится боль» дает знание высказанного автором чувства (в данном случае положительного), а «расставание» описывает противоречивое чувство (отрицательное).
Другие проблемы, существующие в понимании саркастических высказываний, — это ссылка на несколько событий и необходимость извлечь большое количество фактов, здравого смысла и логических рассуждений.
«Сдвиг настроения» часто присутствует в общении, где имеется сарказм; таким образом, предлагается сначала подготовить модель настроения (на основе CNN) для извлечения признаков настроения. Модель выбирает локальные признаки в первых слоях, которые затем преобразуются в глобальные признаки на более высоких уровнях. Саркастические выражения специфичны для пользователя — некоторые пользователи используют больше сарказма, чем другие.
В предлагаемой модели для обнаружения сарказма используются, личностные признаки, признаки настроения и признаки, основанные на эмоциях. Набор детекторов составляет фрэймворк, предназначенный для обнаружения сарказма. Каждый набор признаков изучается отдельными предварительно обученными моделями.
CNN эффективны при моделировании иерархии локальных признаков, чтобы выделить глобальные признаки, что необходимо для изучения контекста. Входные данные представлены в виде векторов слов. Для первичной обработки входных данных используется word2vec от Google. Параметры векторов получаются на этапе обучения. Максимальное объединение затем применяется к картам функций для создания функций. После полностью связанного слоя, идет слой softmax для получения окончательного предсказания.
Архитектура показана на рисунке ниже.
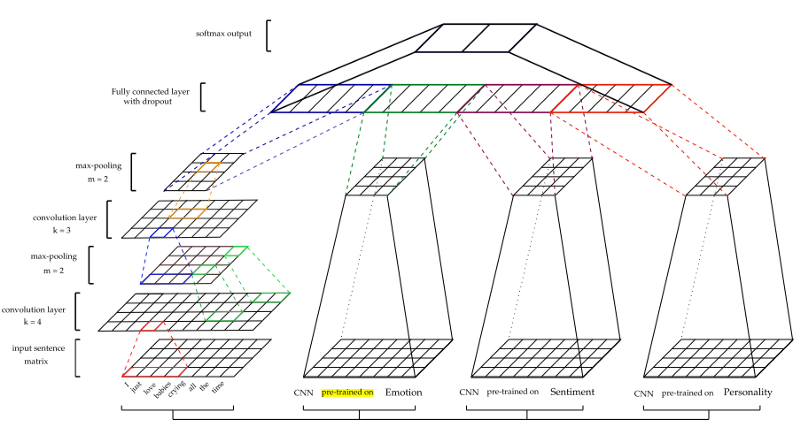
Для получения других особенностей — настроения (S), эмоций (E) и личности (P) — модели CNN проходят предварительную тренировку и используются для извлечения признаков из наборов данных сарказма. Для обучения каждой модели использовались разные учебные наборы данных. (Подробнее см. В документе)
Тестируются два классификатора — чистый CNN-классификатор (CNN) и CNN-извлеченные признаки, передаваемые в классификатор SVM (CNN-SVM).
Также обучается отдельный базовый классификатор (B), состоящий только из модели CNN без включения других моделей (например, эмоций и настроений).
Данные. Сбалансированные и несбалансированные наборы данных были получены из (Ptacek et al., 2014) и детектора сарказма. Имена пользователей, URL-адреса и хэш-теги удаляются, затем применяется токенизатор NLTK Twitter.
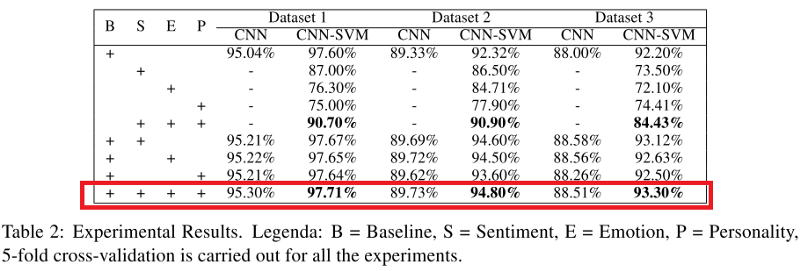
Показатели как CNN, так и CNN-SVM-классификатора, применяемые ко всем наборам данных, показаны в таблице ниже. Можно заметить, что, когда модель (в частности, CNN-SVM) сочетает в себе признаки сарказм, признаки эмоций, чувств и черты характера, она превосходит все другие модели, за исключением базовой модели (B).
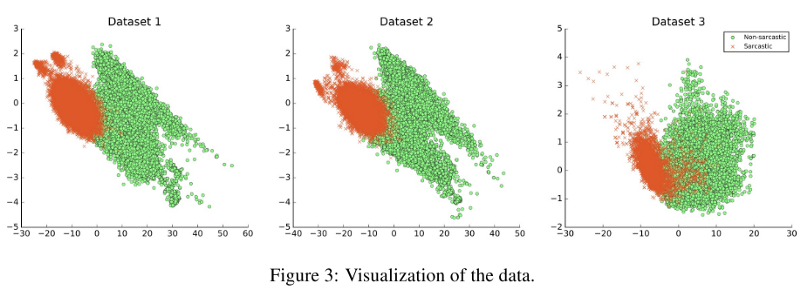
Были опробованы возможности обобщаемости моделей, и основной вывод заключался в том, что если наборы данных отличались по своей природе, это существенно влияло на результатычто показано на рисунке ниже. Например, обучение проводилось по набору данных 1 и тестировалось по набору данных 2; F1-оценка модели составила 33,05%.
Одна из ключевых проблем обработки естественного языка — обнаружение сарказма. Обнаружение сарказма важно в других областях, таких как эмоциональные вычисления и анализ настроений, поскольку это может отражать полярность предложения.
В этой статье показано, как обнаружить сарказм и также приведена ссылка на нейросетевой детектор сарказма.
Сарказм можно рассматривать как выражение язвительной насмешки, либо иронию. Примеры сарказма: «Я работаю 40 часов в неделю, для того чтобы оставаться бедным», либо «Если больной очень хочет жить, врачи бессильны».
Чтобы понять и обнаружить сарказм, важно понять факты, связанные с событием. Это позволяет выявить противоречие между объективной полярностью (обычно отрицательной) и саркастическими характеристиками, переданными автором (обычно положительными).
Рассмотрим пример: «Мне нравится боль от расставания».
Трудно понять смысл, если в этом утверждении есть сарказм. В этом примере «Мне нравится боль» дает знание высказанного автором чувства (в данном случае положительного), а «расставание» описывает противоречивое чувство (отрицательное).
Другие проблемы, существующие в понимании саркастических высказываний, — это ссылка на несколько событий и необходимость извлечь большое количество фактов, здравого смысла и логических рассуждений.
Модель
«Сдвиг настроения» часто присутствует в общении, где имеется сарказм; таким образом, предлагается сначала подготовить модель настроения (на основе CNN) для извлечения признаков настроения. Модель выбирает локальные признаки в первых слоях, которые затем преобразуются в глобальные признаки на более высоких уровнях. Саркастические выражения специфичны для пользователя — некоторые пользователи используют больше сарказма, чем другие.
В предлагаемой модели для обнаружения сарказма используются, личностные признаки, признаки настроения и признаки, основанные на эмоциях. Набор детекторов составляет фрэймворк, предназначенный для обнаружения сарказма. Каждый набор признаков изучается отдельными предварительно обученными моделями.
CNN Framework
CNN эффективны при моделировании иерархии локальных признаков, чтобы выделить глобальные признаки, что необходимо для изучения контекста. Входные данные представлены в виде векторов слов. Для первичной обработки входных данных используется word2vec от Google. Параметры векторов получаются на этапе обучения. Максимальное объединение затем применяется к картам функций для создания функций. После полностью связанного слоя, идет слой softmax для получения окончательного предсказания.
Архитектура показана на рисунке ниже.
Для получения других особенностей — настроения (S), эмоций (E) и личности (P) — модели CNN проходят предварительную тренировку и используются для извлечения признаков из наборов данных сарказма. Для обучения каждой модели использовались разные учебные наборы данных. (Подробнее см. В документе)
Тестируются два классификатора — чистый CNN-классификатор (CNN) и CNN-извлеченные признаки, передаваемые в классификатор SVM (CNN-SVM).
Также обучается отдельный базовый классификатор (B), состоящий только из модели CNN без включения других моделей (например, эмоций и настроений).
Эксперименты
Данные. Сбалансированные и несбалансированные наборы данных были получены из (Ptacek et al., 2014) и детектора сарказма. Имена пользователей, URL-адреса и хэш-теги удаляются, затем применяется токенизатор NLTK Twitter.
Показатели как CNN, так и CNN-SVM-классификатора, применяемые ко всем наборам данных, показаны в таблице ниже. Можно заметить, что, когда модель (в частности, CNN-SVM) сочетает в себе признаки сарказм, признаки эмоций, чувств и черты характера, она превосходит все другие модели, за исключением базовой модели (B).
Были опробованы возможности обобщаемости моделей, и основной вывод заключался в том, что если наборы данных отличались по своей природе, это существенно влияло на результатычто показано на рисунке ниже. Например, обучение проводилось по набору данных 1 и тестировалось по набору данных 2; F1-оценка модели составила 33,05%.
Комментарии (8)

Lazytech
10.08.2018 22:32Примеры сарказма: «Я работаю 40 часов в неделю, чтобы быть этим бедным», либо «Если больной очень хочет жить, врачи бессильны».
Прокомментирую одну из поговорок (см. подчеркнутый текст). В оригинале сказано следующее:
Examples include statements such as “Is it time for your medication or mine?” and “I work 40 hours a week to be this poor”. (Find more fun examples here)
Я бы перевел эту поговорку, например, так:
Мне приходится работать по 40 часов в неделю только для того, чтобы оставаться настолько бедным/бедной.
Возможно, это отсылка к «Алисе в Зазеркалье» (см. отрывок ниже).
Большой отрывок (на английском)Through the Looking-Glass
by Lewis Carroll
She glanced rather shyly at the real Queen as she said this,
but her companion only smiled pleasantly, and said, `That's
easily managed. You can be the White Queen's Pawn, if you like,
as Lily's too young to play; and you're in the Second Square to
began with: when you get to the Eighth Square you'll be a Queen
— ' Just at this moment, somehow or other, they began to run.
Alice never could quite make out, in thinking it over
afterwards, how it was that they began: all she remembers is,
that they were running hand in hand, and the Queen went so fast
that it was all she could do to keep up with her: and still the
Queen kept crying `Faster! Faster!' but Alice felt she COULD NOT
go faster, thought she had not breath left to say so.
The most curious part of the thing was, that the trees and the
other things round them never changed their places at all:
however fast they went, they never seemed to pass anything. `I
wonder if all the things move along with us?' thought poor
puzzled Alice. And the Queen seemed to guess her thoughts, for
she cried, `Faster! Don't try to talk!'
Not that Alice had any idea of doing THAT. She felt as if she
would never be able to talk again, she was getting so much out of
breath: and still the Queen cried `Faster! Faster!' and dragged
her along. `Are we nearly there?' Alice managed to pant out at
last.
`Nearly there!' the Queen repeated. `Why, we passed it ten
minutes ago! Faster! And they ran on for a time in silence,
with the wind whistling in Alice's ears, and almost blowing her
hair off her head, she fancied.
`Now! Now!' cried the Queen. `Faster! Faster!' And they
went so fast that at last they seemed to skim through the air,
hardly touching the ground with their feet, till suddenly, just
as Alice was getting quite exhausted, they stopped, and she found
herself sitting on the ground, breathless and giddy.
The Queen propped her up against a tree, and said kindly, `You
may rest a little now.'
Alice looked round her in great surprise. `Why, I do believe
we've been under this tree the whole time! Everything's just as
it was!'
`Of course it is,' said the Queen, `what would you have it?'
`Well, in OUR country,' said Alice, still panting a little,
`you'd generally get to somewhere else — if you ran very fast
for a long time, as we've been doing.'
`A slow sort of country!' said the Queen. `Now, HERE, you see,
it takes all the running YOU can do, to keep in the same place.
If you want to get somewhere else, you must run at least twice as
fast as that!'
Подчеркивание мое.
Daddy_Cool
10.08.2018 23:15+2Коротко.
1. Чтобы понять сарказм, надо понять сарказм.
2. Чтобы понять сарказм, программа использует разные способы.
3. Получается таки плохо.phenik
11.08.2018 05:40Обнаружить сарказм не трудно, в тексте по тегу сарказм, в разговоре, по возгласу собеседника — Это сарказм? Не отмеченный сарказм считать неудачными шутками.
greabock
очень интересно
Creature
Сарказм?
greabock
Подождите, сейчас сеть дообучится — без нее не разобраться