
Корпорация Enron — это одна из наиболее известных фигур в американском бизнесе 2000-ых годов. Этому способствовала не их сфера деятельности (электроэнергия и контракты на ее поставку), а резонанс в связи с мошенничеством в ней. В течении 15 лет доходы корпорации стремительно росли, а работа в ней сулила неплохую заработную плату. Но закончилось всё так же быстротечно: в период 2000-2001гг. цена акций упала с 90$/шт практически до нуля по причине вскрывшегося мошенничества с декларируемыми доходами. С тех пор слово "Enron" стало нарицательным и выступает в качестве ярлыка для компаний, которые действуют по аналогичной схеме.
В ходе судебного разбирательства, 18 человек (в том числе крупнейшие фигуранты данного дела: Эндрю Фастов, Джефф Скиллинг и Кеннет Лей) были осуждены.
](https://habrastorage.org/webt/te/rh/1l/terh1lsenbtg26n8nhjbhv3opfi.jpeg)
Вместе с тем были опубликованы архив электронной переписки между сотрудниками компании, более известный как Enron Email Dataset, и инсайдерская информация о доходах сотрудников данной компании.
В статье будут рассмотрены источники этих данных и на основе их построена модель, позволяющая определить, является ли человек подозреваемым в мошенничестве. Звучит интересно? Тогда, добро пожаловать под хабракат.
Описание датасета
Enron dataset (датасет) — это сводный набор открытых данных, что содержит записи о людях, работающих в приснопамятной корпорации с соответствующим названием.
В нем можно выделить 3 части:
- payments_features — группа, характеризующая финансовые движения;
- stock_features — группа, отражающая признаки связанные с акциями;
- email_features — группа, отражающая информацию об email-ах конкретного человека в агрегированном виде.
Конечно же, присутствует и целевая переменная, которая указывает, подозревается ли данный человек в мошенничестве (признак 'poi'). Загрузим наши данные и начнём с работу с ними: После чего превратим набор data_dict в Pandas dataframe для более удобной работы с данными: Сгруппируем признаки в соответствии с ранее указанными типами. Это должно облегчить работу с данными впоследствии: В данном датасете присутствует известный многим NaN, и выражает он привычный пробел в данных. Иными словами, автору датасета не удалось обнаружить какой-либо информации по тому или иному признаку, связанному с конкретной строкой в датафрейме. Как следствие, мы можем считать, что NaN это 0, поскольку нет информации о конкретном признаке. При сравнении с исходной PDF, лежащей в основе датасета, оказалось, что данные немного искажены, поскольку не для всех строк в датафрейме payments поле total_payments является суммой всех финансовых операций данного человека. Проверить это можно следующим образом: Исправить данную ошибку можно, сместив данные в ошибочных строках влево или вправо и посчитав сумму всех платежей еще раз: Выполним проверку корректности и в этом случае: Исправим аналогично ошибку в акциях: Если для данных финансов или акций NaN был эквивалентен 0, и это вписывалось в итоговый результат по каждой из этих групп, в случае с email NaN разумнее заменить на некое дефолтное значение. Для этого можно воспользоваться Imputer-ом: Вместе с тем будем считать дефолтное значение для каждой категории (подозреваем ли человек в мошеничестве) отдельно: Итоговый датасет после коррекции: На финальном шаге данного этапа удалим все выбросы (outliers), что могут исказить обучение. В то же время всегда стоит вопрос: как много данных мы можем удалить из выборки и при этом не потерять в качестве обучаемой модели? Я придерживался совета одного из лекторов ведущих курс по ML (машинное обучение) на Udacity — ”Удалите 10 штук и проверьте на выбросы еще раз”. Одновременно с этим мы не будем удалять записи, что являются выбросами и относятся к подозреваемым в мошенничестве. Причина в том, что строк с такими данными всего 18, и мы не можем жертвовать ими, поскольку это может привести к недостатку примеров для обучения. Как следствие, мы удаляем только тех, кто не подозревается в мошенничестве, но при этом имеет большое число признаков, по которым наблюдаются выбросы: Нормализуем наши данные: Приведем целевую переменную target к совместимому виду: Пожалуй один из наиболее ключевых моментов перед обучением любой модели — это отбор наиболее важных признаков. Также существует предположение, что подозреваемые чаще писали пособникам, нежели сотрудникам, которые были не замешаны в этом. И как следствие — доля таких сообщений должна быть больше, чем доля сообщений рядовым сотрудникам. Исходя из данного утверждения, можно создать новые признаки, отражающие процент входящих/исходящих, связанных с подозреваемыми: В инструментарии людей, связанных с ML, есть множество прекрасных инструментов для отбора наиболее значимых признаков (SelectKBest, SelectPercentile, VarianceThreshold и др.). В данном случае будет использован RFECV, поскольку он включает в себя кросс-валидацию, что позволяет вычислить наиболее важные признаки и проверить их на всех подмножествах выборки: Эти 7 признаков будут использованы в дальнейшем, дабы упростить модель и уменьшить риск переобучения: Изменим структуру обучающей и тестовой выборок для будущего обучения модели: Это конец первой части, описывающей использование Enron Dataset в качестве примера задачи классификации в ML. За основу взяты материалы из курса Introduction to Machine Learning на Udacity. Также есть python notebook, отражающий всю последовательность действий.
import pickle
with open("final_project/enron_dataset.pkl", "rb") as data_file:
data_dict = pickle.load(data_file)
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
source_df = pd.DataFrame.from_dict(data_dict, orient = 'index')
source_df.drop('TOTAL',inplace=True)
payments_features = ['salary', 'bonus', 'long_term_incentive',
'deferred_income', 'deferral_payments', 'loan_advances',
'other', 'expenses', 'director_fees', 'total_payments']
stock_features = ['exercised_stock_options', 'restricted_stock', 'restricted_stock_deferred','total_stock_value']
email_features = ['to_messages', 'from_poi_to_this_person',
'from_messages', 'from_this_person_to_poi',
'shared_receipt_with_poi']
target_field = 'poi'
Финансовые данные
payments = source_df[payments_features]
payments = payments.replace('NaN', 0)
Проверка данных
errors = payments[payments[payments_features[:-1]].sum(axis='columns') != payments['total_payments']]
errors.head()

Мы видим, что BELFER ROBERT и BHATNAGAR SANJAY имеют неверные суммы по платежам.
import numpy as np
shifted_values = payments.loc['BELFER ROBERT', payments_features[1:]].values
expected_payments = shifted_values.sum()
shifted_values = np.append(shifted_values, expected_payments)
payments.loc['BELFER ROBERT', payments_features] = shifted_values
shifted_values = payments.loc['BHATNAGAR SANJAY', payments_features[:-1]].values
payments.loc['BHATNAGAR SANJAY', payments_features] = np.insert(shifted_values, 0, 0)
Данные по акциям
stocks = source_df[stock_features]
stocks = stocks.replace('NaN', 0)
errors = stocks[stocks[stock_features[:-1]].sum(axis='columns') != stocks['total_stock_value']]
errors.head()

shifted_values = stocks.loc['BELFER ROBERT', stock_features[1:]].values
expected_payments = shifted_values.sum()
shifted_values = np.append(shifted_values, expected_payments)
stocks.loc['BELFER ROBERT', stock_features] = shifted_values
shifted_values = stocks.loc['BHATNAGAR SANJAY', stock_features[:-1]].values
stocks.loc['BHATNAGAR SANJAY', stock_features] = np.insert(shifted_values, 0, shifted_values[-1])
Сводные данные по электронной переписке
from sklearn.impute import SimpleImputer
imp = SimpleImputer()
target = source_df[target_field]
email_data = source_df[email_features]
email_data = pd.concat([email_data, target], axis=1)
email_data_poi = email_data[email_data[target_field]][email_features]
email_data_nonpoi = email_data[email_data[target_field] == False][email_features]
email_data_poi[email_features] = imp.fit_transform(email_data_poi)
email_data_nonpoi[email_features] = imp.fit_transform(email_data_nonpoi)
email_data = email_data_poi.append(email_data_nonpoi)
df = payments.join(stocks)
df = df.join(email_data)
df = df.astype(float)
Выбросы
first_quartile = df.quantile(q=0.25)
third_quartile = df.quantile(q=0.75)
IQR = third_quartile - first_quartile
outliers = df[(df > (third_quartile + 1.5 * IQR)) | (df < (first_quartile - 1.5 * IQR))].count(axis=1)
outliers.sort_values(axis=0, ascending=False, inplace=True)
outliers = outliers.head(10)
outliers
target_for_outliers = target.loc[outliers.index]
outliers = pd.concat([outliers, target_for_outliers], axis=1)
non_poi_outliers = outliers[np.logical_not(outliers.poi)]
df.drop(non_poi_outliers.index, inplace=True)
Приведение к итоговом виду
from sklearn.preprocessing import scale
df[df.columns] = scale(df)
target.drop(non_poi_outliers.index, inplace=True)
target = target.map({True: 1, False: 0})
target.value_counts()

В итоге 18 подозреваемых и 121 тех, кто не попал под подозрение.
Отбор признаков
Проверка на мультиколлинеарность
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set(style="whitegrid")
corr = df.corr() * 100
# Select upper triangle of correlation matrix
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(15, 11))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(220, 10)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(corr, mask=mask, cmap=cmap, center=0,
linewidths=1, cbar_kws={"shrink": .7}, annot=True, fmt=".2f")
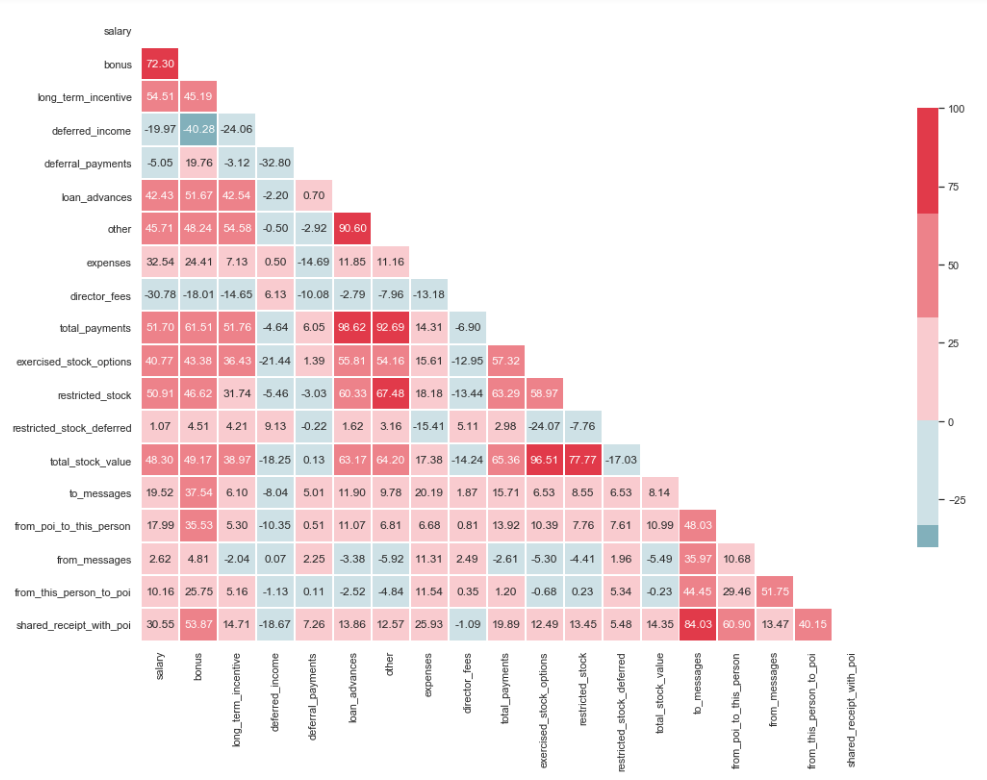
Как видно из изображения, у нас присутствует выраженная взаимосвязь между ‘loan_advanced’ и ‘total_payments’, а также между ‘total_stock_value’ и ‘restricted_stock’. Как уже было упомянуто ранее, ‘total_payments’ и ‘total_stock_value’ являются всего лишь результатом сложения всех показателей в конкретной группе. Поэтому их можно удалить:
df.drop(columns=['total_payments', 'total_stock_value'], inplace=True)
Создание новых признаков
df['ratio_of_poi_mail'] = df['from_poi_to_this_person']/df['to_messages']
df['ratio_of_mail_to_poi'] = df['from_this_person_to_poi']/df['from_messages']
Отсев лишних признаков
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df, target, test_size=0.2, random_state=42)
from sklearn.feature_selection import RFECV
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(random_state=42)
rfecv = RFECV(estimator=forest, cv=5, scoring='accuracy')
rfecv = rfecv.fit(X_train, y_train)
plt.figure()
plt.xlabel("Number of features selected")
plt.ylabel("Cross validation score of number of selected features")
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_, '--o')
indices = rfecv.get_support()
columns = X_train.columns[indices]
print('The most important columns are {}'.format(','.join(columns)))
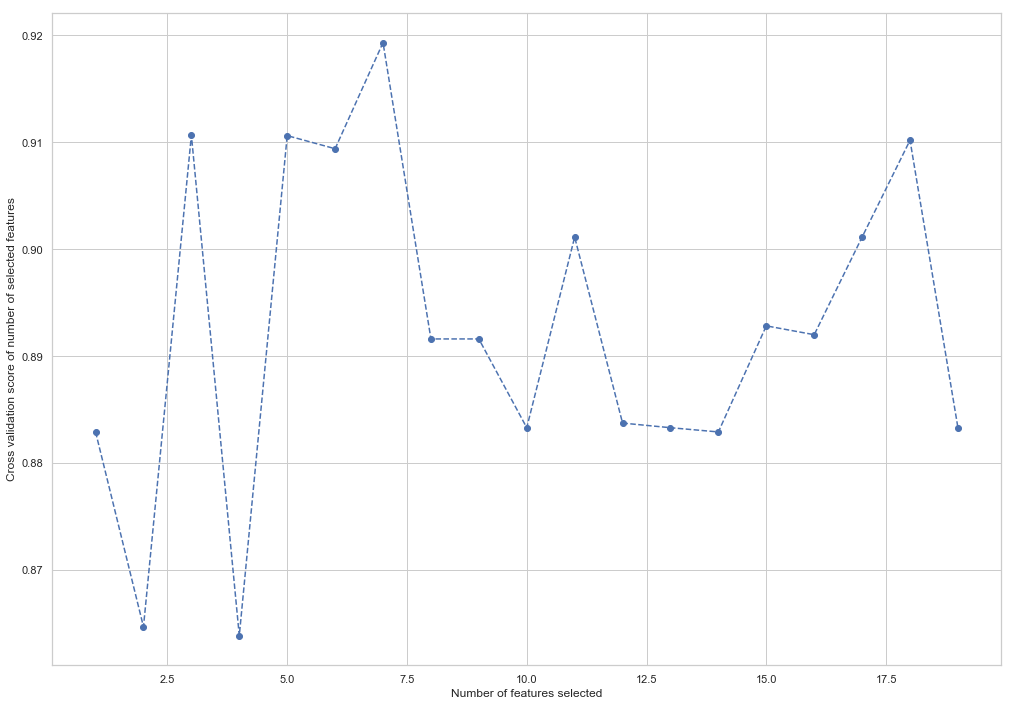
Как можно увидеть, RandomForestClassifier посчитал, что только 7 признаков из 18 имеют значение. Использование остальных приводит к снижению точности модели.
The most important columns are bonus, deferred_income, other, exercised_stock_options, shared_receipt_with_poi, ratio_of_poi_mail, ratio_of_mail_to_poi
X_train = X_train[columns]
X_test = X_test[columns]
Комментарии (3)

Andy_U
30.09.2018 23:49Возможно ли при этом посчитать корреляцию?
Конечно. Почему нет? Если для данной пары параметров есть хотя бы три случая, где есть данные в обоих столбцах, то даже и доверительный интервал можно получить. Ну а если таких случаев меньше, то это означает, что такие параметры одновременно в модель добавлять нельзя.
Но в тех же финансах нет не одной строчки что не содержит пропусков.
Это нормально, чем больше показателей, тем эта ситуация вероятней.
P.S. Посмотрел я на pdf по ссылке, вот например параметер "Loan Advances" просто подлежит исключению из рассмотрения — там одни пропуски за мелкими исключениями.
P.P.S. Глядя на pdf-файл, я не вижу в нем нулей. Положительные числа вижу, некоторые из них в скобках, а вот нолей нет. Т.е., может быть, это просто такое форматирование вывода для улучшения читабельности? Но это надо проверять. Авторов файла спрашивать, рисовать статистические распределения и смотреть, вписываются ли сюда пропуски, как нули или нет.
Andy_U
Замена пропусков на нули в самом начале работы с массивом без какого-либо обоснования — это причина, например, рецензенту в научном журнале прекратить чтение и вернуть статью автору на доработку. Просто потому что такая операция вносит в массив информацию, ранее в нем отсутствующую и искажает статистические распределения переменных, средние, дисперсии и пр.
Ну чем вам помешали пропуски при вычислении матрицы корреляций?
veesot Автор
Спасибо за Ваш вопрос. Сперва попробую пояснить почему заполнено 0.
О природе исходных данных
Как уже было упомянуто — датасет основан на на PDF отчете (также известном как Enron Statement of Financial Affairs). Компания, которая производила проверку счетов сотрудников/движений по ним — просто не нашла данных по некоторым из них. И поэтому приняла за основу что таких данных и не существует, и посчитала итоговые суммы.
Почему не заполнить средним/чем то еще? Потому что некоторые столбцы содержат очень мало данных (например данные о займах — loan advance) и заполнять пробелы на их основе — просто нелогично(не не может что у 140 человек были займы в одинаковую сумму). Также есть столбцы которые связаны с определенными людьми(director fees — жалованье для управленцев) — среднее по которым не может быть перенесена на всех людей, т.к среди них есть и рядовые сотрудники. Также есть и другие столбцы заполнение которых подобным образом внесет еще большую сумятицу в исходные данные, а как следствие придется перерассчитывать итоговые суммы, поскольку они также не будут совпадать. Иными словами — используя привычное заполнение средним/медианой — мы только исказим исходные данные, а не приблизимся к настоящим значениям.
Может возникнуть резонный вопрос — "А почему значения по email — признакам заполнены средним?" Тут дело в том что данные по ним — как раз неполные. Enron email dataset это только часть всех email сотрудников. Но часть email всё равно отсутствует. Поэтому и использовано среднее значение по всем сотрудникам.
Иными словами, тут используется принцип — "платежи, акции — мы доверяем источнику. поскольку у нас нет причин не доверять и способов доказать это", "email — мы знаем что данные неполные(в текущий момент вроде бы версия 2) — поэтому заполняем средним"
Матрица корреляций и NaN.

Да, можно попытаться посчитать корреляцию на основе данных что есть.Но в тех же финансах нет не одной строчки что не содержит пропусков.
Возможно ли при этом посчитать корреляцию? Что она будет показывать?
Исходя из этого всего и было заменено на 0, дабы сохранить изначальный строй датасета, а не исказить его.