
Хотим в общих чертах рассказать про первые достижения с deep learning в анимации персонажей для нашей программы Cascadeur.
Во время работы над Shadow Fight 3 у нас накопилось много боевой анимации — около 1100 движений средней длительностью около 4 секунд. Нам давно казалось, что это может быть хорошим датасетом для обучения какой-нибудь нейронной сети.
Однажды мы заметили, что когда аниматоры делают первые наброски идей на бумаге, то им достаточно нарисовать буквально палочного человечка, чтобы представить себе позу персонажа. Мы подумали, что раз опытный аниматор может хорошо выставить позу по простому рисунку, то вполне возможно, что и нейронная сеть справится. Из этого наблюдения родилась простая идея: давайте из каждой позы мы возьмем только 6 ключевых точек — запястья, щиколотки, таз и основание шеи. Если нейронная сеть знает только позиции этих точек, то сможет ли она предсказать остальную позу — позиции 37 остальных точек персонажа?
Как устроить процесс обучения, было понятно с самого начала: на вход сеть получает позиции 6 точек из конкретной позы, на выходе дает позиции остальных 37 точек, а мы сравниваем их с позициями, которые были в исходной позе. В оценочной функции можно использовать метод наименьших квадратов для расстояний между предсказанными позициями точек и исходными.
Для обучающего датасета у нас были все движения персонажей из Shadow Fight 3. Мы взяли позы из каждого кадра, и получилось около 115 000 поз. Но этот набор имел специфику — персонаж почти всегда смотрел вдоль оси X, а левая нога всегда была впереди в начале движения. Чтобы решить эту проблему, мы искусственно расширили датасет, сгенерировав зеркальные позы, а также случайно вращая каждую позу в пространстве. Это также позволило нам увеличить датасет до двух миллионов поз. Мы использовали 95% нашего датасета для обучения сети и 5% для настройки параметров и тестирования.

Мы взяли достаточно простую архитектуру нейронной сети — полносвязную пятислойную сеть с функцией активации и методом инициализации из Self-Normalizing Neural Networks. На последнем слое активация не используется. Имея по 3 координаты для каждого узла, мы получаем входной слой размером 6*3 элементов и выходной слой размером 37*3 элементов. Мы искали оптимальную архитектуру для скрытых слоев и остановились на пятислойной архитектуре с количеством нейронов в 300, 400, 300, 200 на каждом скрытом слое, однако сети с меньшим количеством скрытых слоев также выдавали неплохой результат. Также весьма полезной оказалась L2 регуляризация параметров сети, она сделала предсказания более плавными и непрерывными.
Нейросеть с такими параметрами предсказывает положение точек со средней ошибкой в 3.5 см. Это весьма высокая ошибка, но надо учесть специфику задачи. Для одного набора входных значений может существовать множество возможных выходных значений. Поэтому нейросеть в итоге научилась выдавать наиболее вероятные, усредненные предсказания. Однако при увеличении числа входных точек до 16 ошибка уменьшалась в два раза, что на практике давало очень точное предсказание позы.
Но при этом нейронная сеть не смогла выдавать полностью корректную позу, сохраняющую длины всех костей и правильное соединение суставов. Поэтому мы дополнительно запускаем процесс оптимизации, выравнивающий все твердые тела и суставы нашей физической модели.
На практике результаты оказались вполне убедительными — вы можете увидеть их в нашем ролике. Но также есть и специфика из-за того, что обучающий датасет — боевые анимации из файтинга с оружием. Например, персонаж как будто предполагает, что он повернут одним плечом к противнику, как в боевой стойке, и соответствующим образом поворачивает стопы и голову. А когда вытягиваешь ему руку, то кисть поворачивается не как при ударе кулаком, а как при ударе мечом.
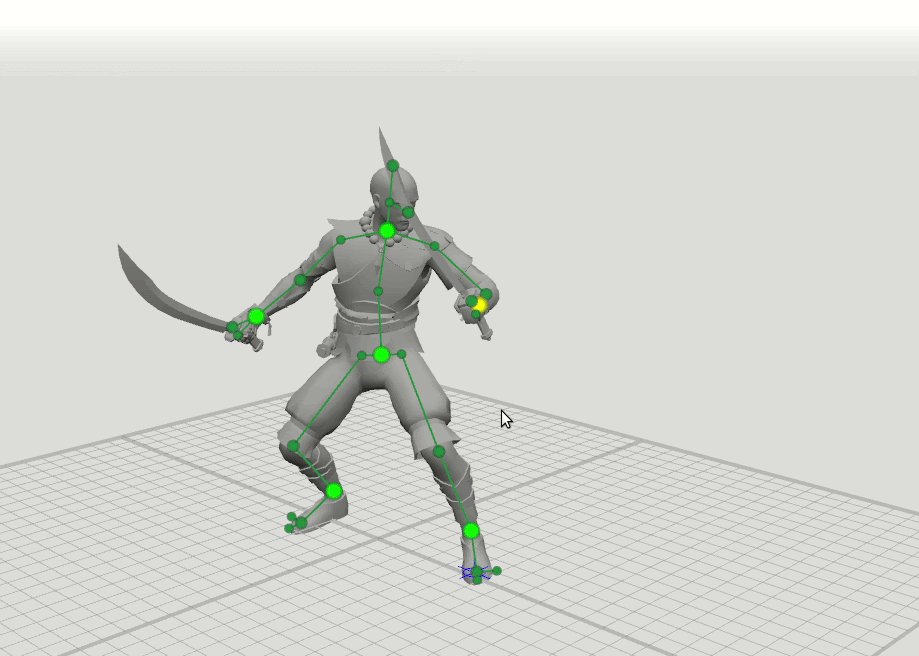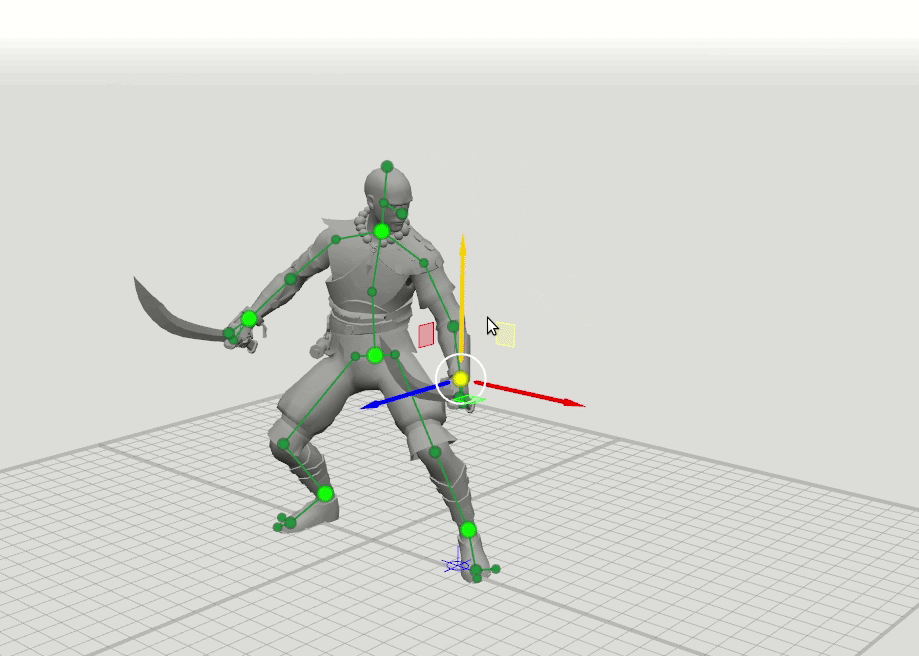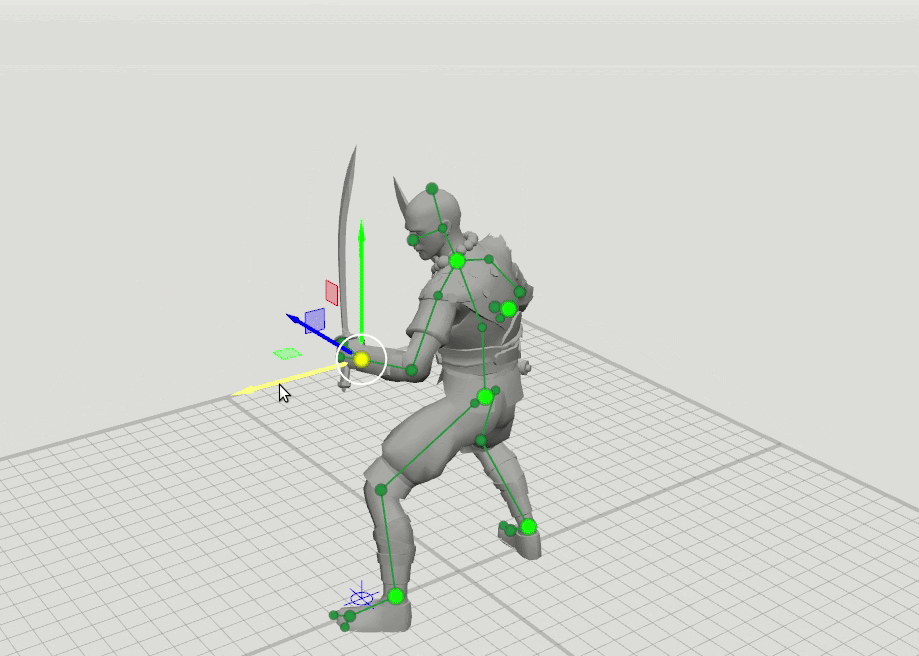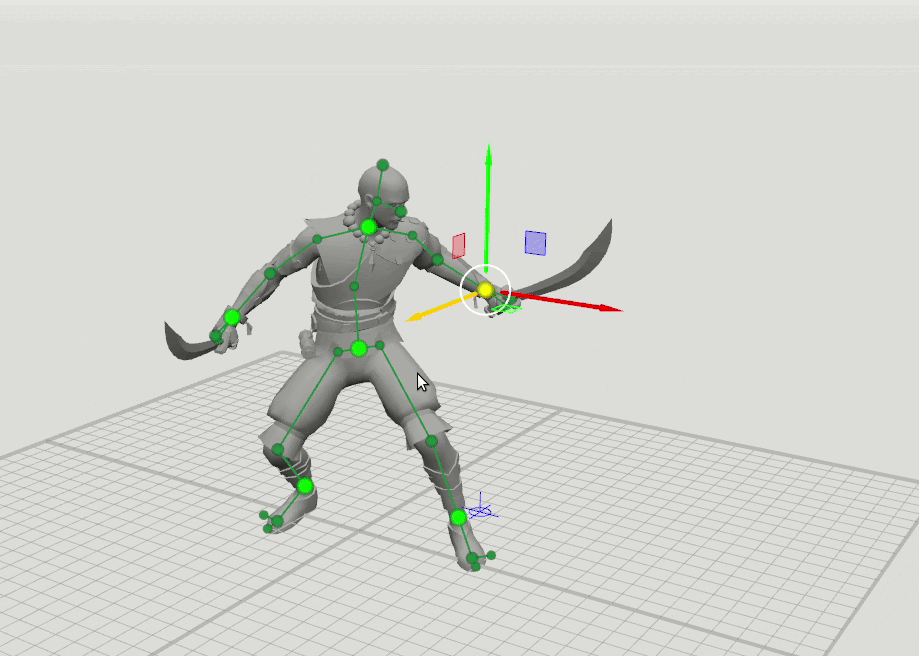
Из этого появилась логичная идея следующего шага — обучить еще несколько сетей с расширенным набором точек, задающих ориентацию кистей, стоп и головы, а также положение коленей и локтей. Мы добавили 16-точечную и 28-точечную схемы. Оказалось, что результаты работы этих сетей можно комбинировать так, что пользователь может задавать позиции произвольному набору точек. Например, пользователь решил подвинуть левый локоть, а правый не трогал. Тогда положение правого локтя и правого плеча предсказываются по 6-точечной схеме, а положение левого плеча предсказывается по 16-точечной схеме.

Похоже, из этого получается действительно интересный инструмент для работы с позой персонажа. Его потенциал еще не раскрыт до конца, и у нас есть идеи, как его улучшать и применять не только для работы с позой. Первая версия этого инструмента уже доступна в текущей версии Cascadeur. Попробовать ее вы сможете, если запишетесь на закрытый бета тест на нашем сайте cascadeur.com
Будем рады узнать ваше мнение и ответить на вопросы.
В команду Banzai Games требуется Deep learning researcher. Подробнее о вакансии можно прочитать здесь.
Комментарии (27)

Augustxeno
30.09.2019 15:14это же задача кинематики и только
vics001
30.09.2019 15:40Применение нейросети здесь, это как сравнивать аналитическое решение уравнение и приближенное. С одной стороны аналитическое решение лучшее, но его надо знать и уметь решать, а с другой стороны запихиваешь в компьютер какие-то число и он сразу тебе выдает очень хорошие аппроксимации.
С практической точки зрение, второе, конечно, лучше, так как экономит кучу сил, а первое останется для студентов и профессоров.
DesertFlow
30.09.2019 15:52+2Хорошая работа. Сделать математическую модель человеческого тела совсем не просто. Когда вы сгибаете одну часть тела, например руку, остальные части тела тоже сдвигаются. Причем по очень нелинейным зависимостям. Как из-за самой структуры тела (суставы, мышцы, связки), так и из-за подобранной эволюцией минимизации затрат энергии на поддержание позы. Более того, в позу включается также готовность к следующим действиям. Например, перед боем поза будет напряжённая, жертвуя минимизацией энергии. Потому что в этом случае для выживания выгоднее иметь преднапряженные мышцы.
В итоге почти невозможно написать математическую модель человеческого тела, чтобы позы получались реалистичными. Тут недостаточно просто описать физиологию. Позы вроде готовности к бою (или позу при ловле мяча, например) вообще никак не смоделировать в обозримом будущем.
Поэтому применять нейросети или машинное обучение правильный подход. Обучить на существующих датасетах (в идеале — на позах живых людей), и будут получаться реалистичные позы. Тут простая моделька, поэтому это может не очень видно, так как похожий результат получается более простыми методами (вроде ограничений на углы поворотов конечностей). Но в перспективе это может дать результаты, которые никакими другими методами недостижимы в принципе.

Taraflex
30.09.2019 22:25А если натравить штуки гуглящиеся по запросам «opencv human pose estimation» на боевики из 90-х с азиатами и запихнуть в эту модель?
EGregor_IV
01.10.2019 06:07Прочитал заголовок и подумал — до создания грамматона клерика осталось 10 лет…

Andrey_Rogovsky
01.10.2019 10:13Я хочу состязание с роботом-фехтовальщиком!
Роботом-фехтовальщиком!
А.Ха.Ха.
oleg_ongoza
01.10.2019 11:05Позиция точки: это только положение в пространстве? или положение и пороты?

playermet
01.10.2019 11:32Я думаю было бы интересно добавить к этому еще и дельту всех значений точек, и посмотреть что получится.
Sadenly
01.10.2019 12:27Только положения, повороты конечно дали бы очень много дополнительной информации нейросети, но потребовали бы и гораздо больше действий от пользователя
oleg_ongoza
01.10.2019 12:36Если для использования совместно с IMU (гироскоп + акселерометр), то повороты снимать проще. Там как раз рассчитать положение точки не простая задача.
Внутри 3Д, как мне кажется, без разницы, какой параметр снимать.Sadenly
01.10.2019 19:55Да, для мокапа конечно стоит учитывать всю информацию, которая есть. Но в нашем случае это именно инструмент, с помощью которого можно ставить позу, поэтому чем меньше степеней свободы приходится задавать — тем лучше и проще пользователю.
oleg_ongoza
01.10.2019 21:21Пользователь может задавать только положение, а в модели возможно учитывать углы, которые получаются с учетом ИК. Хотя в вашем случаем может быть морока ;(

Arech
01.10.2019 11:27Классное применение, молодцы!
Каким инструментарием пользовались для обсчёта НС?Sadenly
01.10.2019 12:30Сначала мы использовали напрямую tensorflow, сейчас переехали на pytorch
Arech
01.10.2019 12:35Спасибо. А что стало толчком к переходу на торч?
mcstarioni
01.10.2019 14:30Если кратко, то Pytorch гораздо более прямолинейный фреймфорк чем TF. Конечно с выходом TF 2.0 возможно что-то там поменялось, но зачем
наступать на одни и те же граблиуходить с такого интуитивного инструмента, как Pytorch.
badimao
Сейчас модно везде применять нейросети. Мне кажется, для данной задачи, хватило бы простой математики и зависимостей.
Aniro
Это же типичная задача как раз под нейросети — математика и ограничения вам дадут бесконечное множество возможных положений костей. Нейросеть выберет из них то, которое больше похоже на натуральное.
atri1
Когда в финале, в виде продакшен-решения, выйдет простая утилита куда просто вставлять картинки и оно тебе генерирует позы, то будет здорово. В таком виде это конечно выглядит как овер-килл для не такой сложной задачи анимации.
GennPen
Мне кажется, нейросеть проще переобучить или дообучить, чем переписывать или писать новые математические формулы.
atri1
Нейросеть обучается месяцами + тебе нужны уже готовые данные (если их нет то их надо подготавливать годами).
Формулы пишутся в течении дня, максимум недели.
playermet
Если формулы пишутся в течении дня-недели и дают тот же результат, то где же все эти сотни-тысячи игр с крутой процедурной анимацией персонажей в играх, где куча либ под все популярные движки делающие из пяти точек живые позы? Это ведь тот же срок что тратится скажем на код несложного UI движка, а функционал такой что его бы с руками оторвали будь он легко доступен. Быть может решение этой задачи не так просто и очевидно?
atri1
в каждой ААА игре сотни крутых процедурных техник, недавно вышел Контрол, там количестко генерируемой графики невероятно впечатляет. (генерируемая графика это и текстуры и нормал мапы итени и отражения, и сотни других приемов, а не только летающие кубики)
В Думе 2016 года сделали очень крутое освещение которого никто никогда не делал, и прочее прочее, чутьли не каждый доклад на GDC уникален и описывает чтото новое
еще во флеше были, не говоря уже про денди и более старые игры где оптимизации зашкаливали
тут уже вопрос монетизации и маркетинга, как мне кажется
очевидные недостатки сгенерированной анимации — она однообразна и неестественна, в тоже время люди устают от однообразия анимации в текущих играх, и анимация "от нейросети" будет свежим глотком, но на сколько этого хватит покажет практика, может ажиотаж спадет после первых пары продуктов…
исключительно мое предположение, может быть полный бред, сори если что
П.С. ниже пост DesertFlow верно описывает сложность
playermet
Это все очень круто, но какое все это имеет отношения к обсуждению процедурных анимаций?
Это в каких таких играх на флеше и на денди было что-то связанное с темой этой статьи? Максимум что там можно найти это 2d IC уровня «нога это два катета, давайте посчитаем угол».
Этот же вопрос не мешает существованию кучи открытых библиотек того же UI под каждый популярный игровой/графический движок.
Sadenly
Ниже DesertFlow хорошо описал, почему задача аналитического описания человеческого тела сложная.
Чтобы оценить масштаб проблемы, стоит посмотреть на пример простого классического рига: www.youtube.com/watch?v=RUvgboeR2_0&t=1200s. Видно, что контроллеров (а значит, и степеней свободы) там целая куча и умение с ними работать требует определенных навыков. Это пример рига, построенного вручную, из функций, при помощи графа зависимостей.
Наш стандартный риг в каскадере с одной стороны более интуитивен, за счет использования физики внутри рига (можно посмотреть на примере нашего тутора). С другой стороны — «сломать» позу в нем даже проще.
Проблема в том, что записать зависимости вручную так, чтобы они учли все мелочи — очень сложно. И даже сложные системы, которые долго писались, типа HumanIK от Maya все равно имеют кучу проблем. Нейронная сеть же сама учитывает все эти особенности человеческих поз, просто за счет того, что о них знают аниматоры.
ledocool
Более того, вот этот парень уже сделал. (Проект полного присутвия в VR)
www.youtube.com/watch?v=9IDhcrzJtY4