
Классический вопрос, с которым разработчик приходит к своему DBA или владелец бизнеса — к консультанту по PostgreSQL, почти всегда звучит одинаково: «Почему запросы выполняются на базе так долго?»
Традиционный набор причин:
И если блокировки достаточно сложны в поимке и анализе, то для всего остального нам достаточно плана запроса, который можно получить с помощью оператора EXPLAIN (лучше, конечно, сразу EXPLAIN (ANALYZE, BUFFERS) ...) или модуля auto_explain.
Но, как сказано в той же документации,
Как обычно выглядит план запроса? Как-то вот так:
или вот так:
Но читать план текстом «с листа» — очень сложно и ненаглядно:
Когда мы попытались объяснить все это нескольким сотням наших разработчиков, то поняли, что со стороны это выглядит примерно вот так:

А, значит, нам нужен…
В нем мы постарались собрать все ключевые механики, которые помогают по плану и запросу понять, «кто виноват и что делать». Ну, и частью своего опыта поделиться с сообществом.
Встречайте и пользуйтесь — explain.tensor.ru
Легко ли понять план, когда он выглядит так?
Не очень.
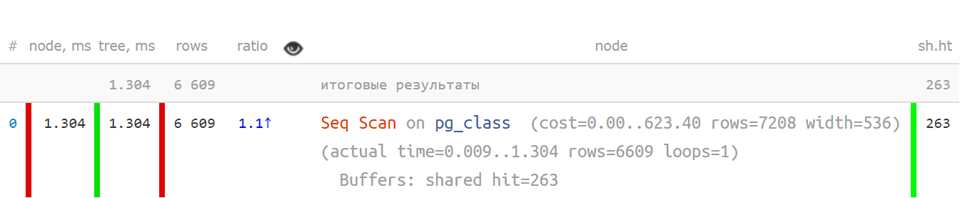
Но вот так, в сокращенном виде, когда ключевые показатели отделены — уже гораздо понятнее:
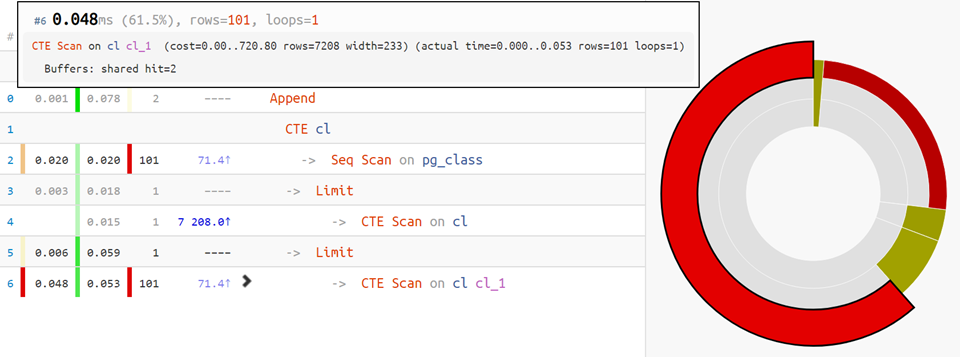
Но если план посложнее — на помощь придет piechart распределения времени по узлам:
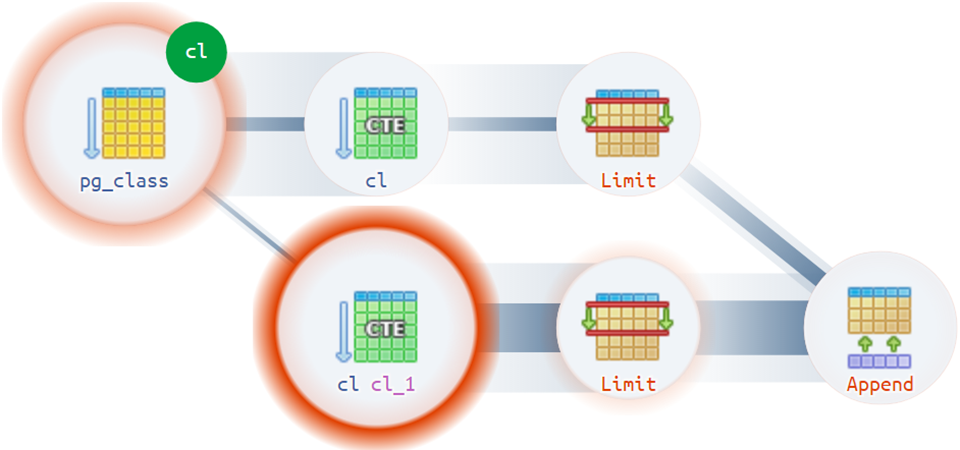
Ну, а для самых сложных вариантов на помощь спешит диаграмма выполнения:
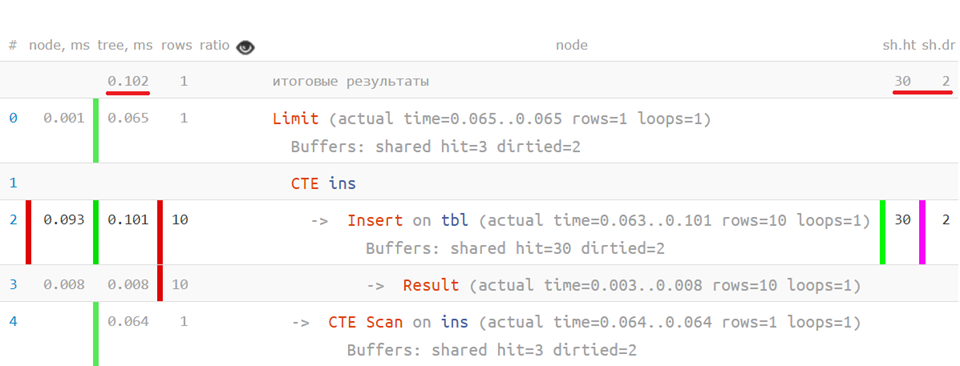
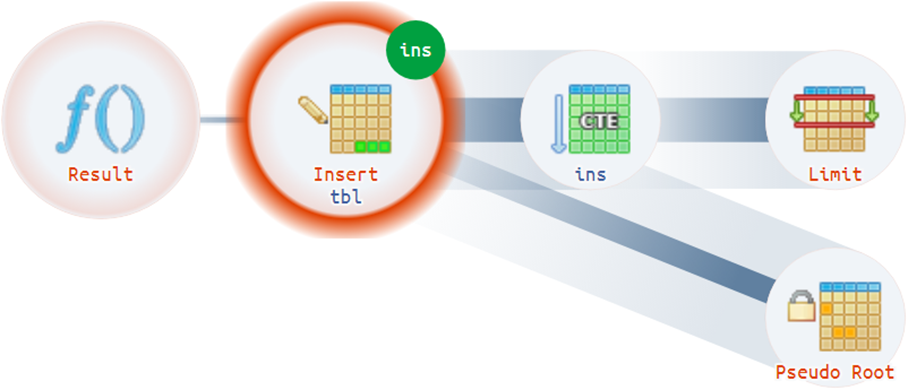
Например, бывают достаточно нетривиальные ситуации, когда план может иметь больше одного фактического корня:
Ну, а если вся структура плана и его больные места уже разложены и видны — почему бы не подсветить их разработчику, и не объяснить «русским языком»?
 Таких шаблонов рекомендаций мы собрали уже пару десятков.
Таких шаблонов рекомендаций мы собрали уже пару десятков.
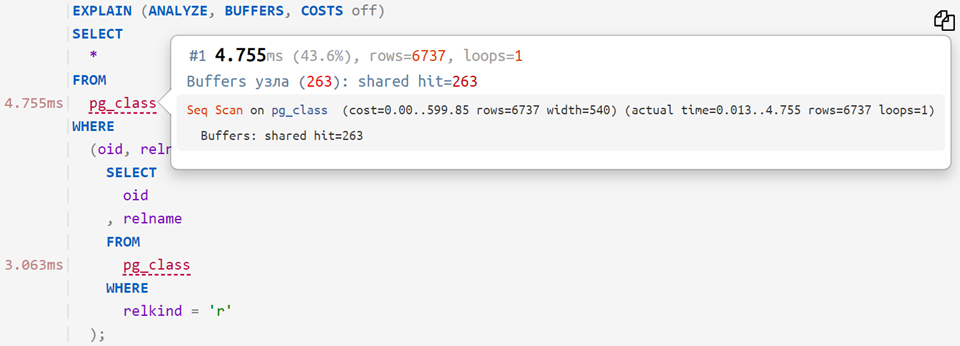
Теперь, если на анализируемый план наложить исходный запрос, то можно увидеть, сколько времени ушло на каждый отдельный оператор — примерно вот так:
… или даже так:

Если вы «прицепили» к плану не только запрос, но и его параметры из DETAIL-строки лога, то сможете скопировать его дополнительно в одном из вариантов:
Вставляйте, анализируйте, делитесь с коллегами! Планы останутся в архиве, и вы сможете вернуться к ним позднее: explain.tensor.ru/archive
Но если не хотите, чтобы ваш план увидели другие, не забудьте поставить галочку «не публиковать в архиве».
В следующих статьях я расскажу о тех сложностях и решениях, которые возникают при анализе плана.
Традиционный набор причин:
- неэффективный алгоритм
когда вы решили сделать JOIN нескольких CTE по паре десятков тысяч записей - неактуальная статистика
если фактическое распределение данных в таблице уже сильно отличается от собранной ANALYZE'ом в последний раз - «затык» по ресурсам
и уже не хватает выделенных вычислительных мощностей CPU, постоянно прокачиваются гигабайты памяти или диск не успевает за всеми «хотелками» БД - блокировки от конкурирующих процессов
И если блокировки достаточно сложны в поимке и анализе, то для всего остального нам достаточно плана запроса, который можно получить с помощью оператора EXPLAIN (лучше, конечно, сразу EXPLAIN (ANALYZE, BUFFERS) ...) или модуля auto_explain.
Но, как сказано в той же документации,
«Понимание плана — это искусство, и чтобы овладеть им, нужен определённый опыт, …»Но можно обойтись и без него, если воспользоваться подходящим инструментом!
Как обычно выглядит план запроса? Как-то вот так:
Index Scan using pg_class_relname_nsp_index on pg_class (actual time=0.049..0.050 rows=1 loops=1)
Index Cond: (relname = $1)
Filter: (oid = $0)
Buffers: shared hit=4
InitPlan 1 (returns $0,$1)
-> Limit (actual time=0.019..0.020 rows=1 loops=1)
Buffers: shared hit=1
-> Seq Scan on pg_class pg_class_1 (actual time=0.015..0.015 rows=1 loops=1)
Filter: (relkind = 'r'::"char")
Rows Removed by Filter: 5
Buffers: shared hit=1или вот так:
"Append (cost=868.60..878.95 rows=2 width=233) (actual time=0.024..0.144 rows=2 loops=1)"
" Buffers: shared hit=3"
" CTE cl"
" -> Seq Scan on pg_class (cost=0.00..868.60 rows=9972 width=537) (actual time=0.016..0.042 rows=101 loops=1)"
" Buffers: shared hit=3"
" -> Limit (cost=0.00..0.10 rows=1 width=233) (actual time=0.023..0.024 rows=1 loops=1)"
" Buffers: shared hit=1"
" -> CTE Scan on cl (cost=0.00..997.20 rows=9972 width=233) (actual time=0.021..0.021 rows=1 loops=1)"
" Buffers: shared hit=1"
" -> Limit (cost=10.00..10.10 rows=1 width=233) (actual time=0.117..0.118 rows=1 loops=1)"
" Buffers: shared hit=2"
" -> CTE Scan on cl cl_1 (cost=0.00..997.20 rows=9972 width=233) (actual time=0.001..0.104 rows=101 loops=1)"
" Buffers: shared hit=2"
"Planning Time: 0.634 ms"
"Execution Time: 0.248 ms"Но читать план текстом «с листа» — очень сложно и ненаглядно:
- в узле выводится сумма по ресурсам поддерева
то есть чтобы понять, сколько ушло времени на выполнение конкретного узла, или сколько именно вот это чтение из таблицы подняло данных с диска — нужно как-то вычитать одно из другого - время узла необходимо умножать на loops
да, вычитание еще не самая сложная операция, которую надо делать «в уме» — ведь время выполнения указывается усредненное для одного выполнения узла, а их могут быть сотни - ну, и все это вместе мешает ответить на главный вопрос — так кто же «самое слабое звено»?
Когда мы попытались объяснить все это нескольким сотням наших разработчиков, то поняли, что со стороны это выглядит примерно вот так:
А, значит, нам нужен…
Инструмент
В нем мы постарались собрать все ключевые механики, которые помогают по плану и запросу понять, «кто виноват и что делать». Ну, и частью своего опыта поделиться с сообществом.
Встречайте и пользуйтесь — explain.tensor.ru
Наглядность планов
Легко ли понять план, когда он выглядит так?
Seq Scan on pg_class (actual time=0.009..1.304 rows=6609 loops=1)
Buffers: shared hit=263
Planning Time: 0.108 ms
Execution Time: 1.800 ms
Не очень.
Но вот так, в сокращенном виде, когда ключевые показатели отделены — уже гораздо понятнее:
Но если план посложнее — на помощь придет piechart распределения времени по узлам:
Ну, а для самых сложных вариантов на помощь спешит диаграмма выполнения:
Например, бывают достаточно нетривиальные ситуации, когда план может иметь больше одного фактического корня:
Структурные подсказки
Ну, а если вся структура плана и его больные места уже разложены и видны — почему бы не подсветить их разработчику, и не объяснить «русским языком»?
Таких шаблонов рекомендаций мы собрали уже пару десятков.Построчный профайлер запроса
Теперь, если на анализируемый план наложить исходный запрос, то можно увидеть, сколько времени ушло на каждый отдельный оператор — примерно вот так:
… или даже так:
Подстановка параметров в запрос
Если вы «прицепили» к плану не только запрос, но и его параметры из DETAIL-строки лога, то сможете скопировать его дополнительно в одном из вариантов:
- с подстановкой значений в запрос
для непосредственного выполнения на своей базе и дальнейшей профилировки
SELECT 'const', 'param'::text; - с подстановкой значений через PREPARE/EXECUTE
для эмуляции работы планировщика, когда параметрическая часть может быть проигнорирована — например, при работе на секционированных таблицах
DEALLOCATE ALL; PREPARE q(text) AS SELECT 'const', $1::text; EXECUTE q('param'::text);
Архив планов
Вставляйте, анализируйте, делитесь с коллегами! Планы останутся в архиве, и вы сможете вернуться к ним позднее: explain.tensor.ru/archive
Но если не хотите, чтобы ваш план увидели другие, не забудьте поставить галочку «не публиковать в архиве».
В следующих статьях я расскажу о тех сложностях и решениях, которые возникают при анализе плана.
Envek
Что-то у меня упорно не хочет работать explain.tensor.ru — везде отдаёт пустой файл браузеру (последние стабильные версии Firefox и Chromium под линуксом).
Попробовал несколько разных планов из личной коллекции «Как не надо писать SQL».
Например такой план:
К такому запросу:
Kilor Автор
С запросом, но без analyze (то есть без реальных цифр исполнения) вставлять большого смысла нет — все равно только на cost опираться можно:

Вставку наладим немного позже.
Envek
Запрос с cost в несколько триллионов попугаев с указанием analyze будет выполняться сутки, возможно, что и не одни :-D
Kilor Автор
Не так страшны cost-попугаи, как их малюет PG. :)
Иногда погрешность между оценкой и реальностью составляет тысячи раз (а иногда и миллионы):
например
Xobotun
Я сначала думал, может, баг сайта какой, explain закешировался в браузере. Но зашёл с другого компа – нет, мой план. :D
Так и не смог понять, что надо скормить постгресу, чтобы он sequental scan превратил в index scan. Там поиск по таблице с ~1 млн фейковых записей, и фильтр по колонкам, которые в 99.5% истинны. То есть, возможно, там действительно укорять нечего.
И да, я так понимаю, что cost-попугаи – условная стоимость чтения с диска и выполнения операций, а не предсказанное время. По крайней мере, так документация говорит.
Kilor Автор
Без запроса или output-атрибута рассуждать сложно, но раз там наверху Sort Key: st_distance..., то может и не надо сортировать вообще всех user, раз хотелось наиболее близких найти?
Xobotun
Это было риторическое утверждение, без попытки получить помощь. Хотел бы я её – пошёл бы на stackoverflow. :D
Но если нечего делать и задачка интересна, то вот запрос. :)
Типы данных, кмк, и так ясны, но у фильтров и юзеров есть
TEXT[], если что.Там быстродействие не столь важно, результаты кешируются бекендом на пару минут для повторных запросов, но нет предела совершенству. И преждевременной оптимизации.
Kilor Автор
Чисто из спортивного интереса — а что за задача такая? То есть мы сортируем всех 1.1M юзеров по близости к заданному — а зачем такое может быть нужно?
Xobotun
Сервис знакомств типа Тиндера и прочих ему подобных.
На самом деле я хочу сделать более защищённый алгоритм поиска расстояния между пользователями, но не хватает времени, всё на более приоритетные задачи уходит.
Более защищённый в том плане, чтобы нельзя было вычислить настоящие координаты другого пользователя, сдвигая свои.
Сейчас расстояние до другого пользователя показывается логарифмически "<1км", «5км», «10км», «25км», ..., но простым округлением. И если сдвигать свои координаты как раз на границе округления 1км-5км, то можно очень даже неплохо триангуляцией узнать приватные данные. Просто округлять в БД координаты WGS84 до четырёх знаков после запятой нехорошо, будет много пользователей с расстоянием в 0 км. Надо почитать на эту тему научных статей.
А, и да, сортируются не все миллион пользователей, а тысяча-другая, которая осталась после фильтрации по всем условиям в WHERE. Хотя если фильтр будет крайне щадящий и пропустит всех пользователей, то, на удивление, всего 2.5 секунды выполняется. Я ожидал худшего. Хотя база на 60-гиговом ssd, external merge быстрый.
Kilor Автор
А выводится из этих 1-2 тысяч?
Если фильтр малоселективный, то не эффективнее ли будет идти от сортировки по расстоянию, отфильтровывая неподходящих юзеров вложенным запросом?
Xobotun
Да, там есть ещё limit и offset, если пользователь стал просить других пользователей за пределами кеша, выводится ещё тысяча пользователей из результата.
А вот тут моих знаний sql и опыта уже явно не хватает, я просто не представляю, как и куда это сделать.Как-то так? Или через CTE?
Kilor Автор
Как-то примерно так:
Ну и что-то типа KNN-gist в качестве индекса.
Xobotun
А, то есть вынести фильтр в отдельную sql-функцию?
Хотел задействовать типы данных и индексы из постгиса, но не дошли руки. ':)
Kilor Автор
Не обязательно в функцию, можно под CASE «спрятать» — лишь бы не перебивало сортировку по distance индексом.
Xobotun
А как прятать под CASE?
CASE WHEN TRUE THEN...? :)
UPD: Это, похоже, не то, что имелось в виду.
Kilor Автор
то есть что-то типа
Kilor Автор
Поправили вставку запроса в паре с "простым" explain (без analyze), смотрите:
https://explain.tensor.ru/archive/explain/74aca500-908b-1308-16ec-2d63ece409ba:0:2019-11-27
ADR
Мне кажеться та будет быстрее:
то есть без
sub queryвwhereкоторая исполняеться для каждой строчкиlisting.Envek
Ну я же говорил, что это из моей личной коллекции «Как не надо писать SQL» :-D
В этом примере я рассказываю людям о том, что использовать
WHERE NOT INдля логического отрицания, хоть и логически правильно, очень часто убийственно для производительности и запросы надо переписывать явно, используяINи перенося отрицание внутрь подзапроса:И, хоть это немного и контринтуитивно, но такой вариант с подзапросом работает ощутимо быстрее вашего примера с JOIN (1 секунда против 8), хотя я сам думал, что ваш будет быстрее.
vs
ADR
Не увидел, виноват (главное читал же комент))
Не знал о таком. Спасибо)
ADR
Хм. В варианте с inner join ошибка: должно быть не "IS NOT NULL", а "IS NULL".
По експлейнах вижу
Seq Scan on productsв случаи с JOIN.Интересно что будет если все условия перенести в JOIN:
Envek
С условием да — mea culpa, mea maxima culpa — условие поправил и план похорошел и стал точно таким же, как и у подзапроса.
a0fs
Вот бы эту штуку, хотя бы только с функционалом визуализации, да к себе на сервер. А то не всякий запрос можно так поразбирать, СИБ линчует…
Kilor Автор
Вряд ли СИБ за несокрытие структуры полей-таблиц и времени исполнения переживать будет. :)
А секретную информацию можно подрезать перед вставкой:
Filter: (username = 'boss' AND userpass = 'secret')
strelkan
в идеале бы в сборку bigsql
andrydl
Галочка «не публиковать в архиве» и ваш план никто не увидит )
av_in
Тулза выглядит довольно старой, если ли какие-либо нюансы для новых версий postgres?
Kilor Автор
Поддержка всех атрибутов и типов узлов v12.
Пока не делали поддержку сторонних форков типа Greenplum и спецузлов в них вроде Gather Motion/Partition Selector/Dynamic Table Scan.
А вам чего именно не хватает? Пишите — посмотрим, добавим.
Cassiopeya
а поддержка Greenplum планируется?
Kilor Автор
Если предоставите пачку планов/описание узлов — у нас Greenplum не используется, поэтому нет должного объема экспертизы пока.
Cassiopeya
Спасибо, подумаем об этом!
LPDem
Отличный инструмент, буду пользоваться!
vodopad
Какие альтернативы существуют для этого инструмента? Хотелось бы сравнить несколько и выбрать наиболее удобный.
Kilor Автор
Мы сами отталкивались от проблем, которые есть тут:
explain.depesz.com
theartofpostgresql.com/explain-plan-visualizer
Про часть из них я рассказывал на PGConf.
Kilor Автор
выше
Fragster
Кнопка развернуть свернуть все узлы работает как инверсия текущего состояния, а не как сворачивание и разворачивание всех узлов. Если некоторые узлы раскрыты, то они скрываются, зато показываются все остальные. это несколько неудобно. Пусть если хоть что-то свернуто, то разворачивает все, а потом все сворачивает.
Envek
Вот чего вам не хватает — так это флеймграфов, вот как эта тулза строит: https://github.com/mgartner/pg_flame (пример: https://mgartner.github.io/pg_flame/flamegraph.html )
Мне кажется, что это самый понятный способ визуализации происходящего. Не хотите добавить себе? Там в issues уже предлагали сделать подобное и даже js-реализацию находили: https://github.com/mgartner/pg_flame/issues/2
Kilor Автор
Хотим, очень, но на реальных хоть немного сложных запросах получается редкостная каша, если узлы CTE/InitPlan/SubPlan используются по несколько раз.
Поэтому пока остановились на piechart + граф.
Kilor Автор
По сути, piechart (справа при наведении на шеврон выезжает) — и есть flamegraph, только свернутый в кольцо.
Envek
Кабы вы не рассказали про шеврон — ни в жизнь бы его не нашёл и не навёл бы на него. Круто, красота!
Бажный он, немного, правда, на этом плане, но, надеюсь, почините как-нибудь.
Kilor Автор
В параллельных запросах Finalize-узлы отдают данные только с ведущего процесса, а остальные узлы — сумму по всем воркерам. Потому в результате отрицательные величины. :(
В v12 есть хотя бы более детальная стата по каждому воркеру, а что делать с более ранними версиями пока не придумалось.
Envek
Ну, я надеюсь, что мы вскоре обновимся на 12-ю версию ;-)
Kilor Автор
Пофиксили piechart при отрицательных значениях узлов, спасибо.
oxff
Круто! Хотя и немного непривычно после explain.depesz.com, которым вы явно вдохновлялись.
1) Под Firefox мелкие косячки, потестируйте, пожалуйста. Например, размножающиеся диаграммы и т.п.
2) Рекомендации попадаются из разряда «пальцем в небо», вот прям совсем мимо.
3) Планируется ли английская версия интерфейса? Это ведь бета для хабратестеров?
Kilor Автор
1. посмотрим, спасибо
2. ссылку на пример покажите, плз, и почему она кажется неподходящей
3. не в близком будущем
oxff
2) https://explain.tensor.ru/archive/explain/402e2dc375c7029ee792b3c4c7d6ec26:0:2019-11-28
«Таблица сильно разрежена, рекомендуется произвести очистку с помощью VACUUM [FULL]». На самом деле этот план получен на staging машине, где только что развернули свежий дамп в единой транзакции, и не выполнили ни единого DML запроса. То есть таблица ну никак не может быть разреженной.
3) Жалко, хотелось бы поделиться с коллегами. С другой стороны, правильно, пускай учат великий могучий, будет стимул :)
Kilor Автор
Это самый спорный кейс из нашей подборки. :)
На самом деле, он означает, что записи лежат сильно далеко друг от друга — (rows = 1245, RRbF = 232), но при этом 1453 buffers. То есть вычитывается практически 1 страница данных/запись, а это достаточно много.
И такое обычно бывает или если мы много-много раз апдейтили таблицу (тогда как раз VACUUM поможет), или если записи по ключу лежат «немного вначале, немного в конце» (тогда стоит посмотреть в сторону CLUSTER ON).
oxff
Эту табличку вскоре будут партиционировать среди прочих, по хэшу индексного ключа из обсуждаемого узла, а кластеризацию уже выполнили, это вы верно подметили :)
oxff
И ещё одно пожелание: кнопочка «развернуть/свернуть все узлы» инвертирует каждый узел в отдельности. Если часть из них уже развернута, то они сворачиваются и наоборот. Хорошо бы чтоб ее поведение зависело от глобального флага, и я не против кликнуть лишний раз, если флаг не отражает результат моих ручных действий. Что думаете?
Kilor Автор
Уже где-то тут в комментах проскакивало. Запилим на следующей неделе, думаю.
Kwisatz
миллионов?
то вы скорее всего уже гугл, ну или очень жадный
Есть еще вот такая шикарнейшая штука, просто невероятно полезна при анализе больших запросов
Kilor Автор
Ну как бы JOIN двух CTE по 10K записей — это 20мс на не самом плохом железе.
PEV полезен, но принимает планы только в JSON, мы пока только в Text. Но подтянемся. :)
Kwisatz
NATURAL CROSS JOIN? Вот это стоило сразу уточнить. А то я все чаще встречаю людей, которые говорят что join это очень тяжелая операция.
Envek
Чем больше переписываешь проблемных запросов, тем чаще убеждаешься, что JOIN'ы порой приносят больше проблем, чем решают. Я в последнее время предпочитаю выносить условия по другим таблицам в подзапросы со ссылкой на внешний запрос — как правило это и работает быстрее и читается лучше. Например:
Kwisatz
Нет не лучше читается. Тем более, что выбирать все комменты по всем статьям пользователя не нужно никогда. А что собственно должно было у вас получиться в результате?
Envek
Посты и комменты здесь только, чтобы показать абстрактную связь один-ко-многим. На практике часто нужно выбирать записи, у которых есть определённные связанные записи. Просто вместе с JOIN'ом придётся лепить DISTINCT, чтобы избежать дублей (некоторые ORM так любят делать), а там прощай и производительность и читабельность.
Дело вкуса, наверное
Kwisatz
Абстрактные примеры очень плохо отображают реальный мир. В реальном мире вы просто выведите список постов, плюсиков и левым джином докинете тему.
ЗЫ только у меня на хабре скролл плющит нереально? На двух разных машинах в двух разных броузерах.
Kilor Автор
Если такой JOIN вместо Merge Join вырождается в Nested Loop как раз с множественным CTE Scan, то будет еще медленнее, чем в примере выше.
Причем все время будет потрачено именно на CTE Scan-узле, а сам Join — дешевый, да. :)
Kwisatz
Вы заставляете базу прогнать 100 млн записей, тут удивляться нечему. Я бы даже сказал потрясающая производительность для такого объема. Но очень часто на фоне таких рассуждений народ начинает вытворять дичь в попытке уйти от левого джоина. В идеальном случае у вас во всех строках по джоину должна стоять единица, случаи когда это не так требуют отдельного рассмотрения.
Kilor Автор
В идеальном случае — можно без джойна. :)
Примерно так — через hstore/json:
Kwisatz
ну серьезно чтоле? Это говнокод, в чистом его виде. И работает кстати медленно.
Kilor Автор
Кстати быстро.
Достаточно представить, что в pktable 10M записей, и извлечение каждой отдельной из таблицы стоит существенно дороже, чем ее сериализация-десериализация.
А после этого допустим, что в fktable 1K записей, но всего 10 _разных_ fk-ключей.
Итого имеем:
— 10 поисков по pktable, 10 сериализаций
— 1K десериализаций
vs (если будет Nested Loop)
— 1K поисков по pktable
Так что не бывает «говнокода в чистом виде», бывают вопросы эффективности применения метода. Хочу — применяю, не хочу — не применяю.
Kwisatz
До тех пор пока вы пишите свои собсттвенные пет проект — конечно. Как только вы начинаете работать по найму — бывает. Скорость выполнения это очень нужно, очень круто, сам люблю. Однако, дорабатывать надо, поддерживать надо, извольте нормализовать и писать очевидный код.
Kilor Автор
Бывают проекты, где разница скорости в несколько миллисекунд на каждом запросе определяет разницу в стоимости железа на десятки тысяч иностранных денег.
И пока ФОТ разработчиков стоит кратно меньше, дешевле их научить таким подходам, чем вкладывать деньги в красиво написанный, но медленно работающий код.
Kwisatz
Поверьтте, я как раз такими вещами занимаюсь. У меня глаза на лоб лезут от того, какие вещи вытворяет народ с запросами. НО неподдерживаемый код нахрен никому ненужен, из-за него отдел разработки раздует так, что мало не покажется. И логика ваша не верна. Оборудование стоит _дешевле_. В том то и весь смысл.
Kilor Автор
Код не должен быть неподдерживаемым. Но он не обязан быть примитивным.
Это все рассуждения из серии «разработчики — дураки, код с умножением для них слишком сложен, пусть пользуются только сложением».
Kwisatz
Нет не из этой серии. Я предлагаю вам не делать вставок на C поперек программы.
Envek
PEV не развивается с момента создания в 2016-м, поэтому уже другие ребята сделали PEV2
Kwisatz
Хорошая штука, я как то не интересовался, меня устраивало) Спасибо.
ЗЫ а под оракл таких штук нет кстате?